
Abstract
A false alarm rate of online anomaly-based intrusion detection system is a crucial concern. It is challenging to implement in the real-world scenarios when these anomalies occur sporadically. The existing intrusion detection system has been developed to limit or decrease the false alarm rate. However, the state-of-the-art approaches are attack or algorithm specific, which is not generic. In this article, a soft-computing-based approach has been designed to reduce the false-positive rate for hierarchical data of anomaly-based intrusion detection system. The recurrent neural network model is applied to classify the data set of intrusion detection system and normal instances for various subclasses. The designed approach is more practical, reason being, it does not require any assumption or knowledge of the data set structure. Experimental evaluation is conducted on various attacks on KDDCup’99 and NSL-KDD data sets. The proposed method enhances the intrusion detection systems that can work with data with dependent and independent features. Furthermore, this approach is also beneficial for real-life scenarios with a low occurrence of attacks.
Introduction
The rapid development of network systems has a big threat from the intrusions. Intrusion detection systems (IDS)1,2 are widely used to mitigate the various types of attacks. Broadly, IDS can be classified into three categories: network-based intrusion detection systems (NIDSs), distributed intrusion detection systems (DIDSs), and host-based intrusion detection systems (HIDSs). The NIDS’s objective is to defend against the threats related to network, HIDS’s aim is to figure out the local system anomalies, and DIDS is responsible for improving the performance based on IDS agents’ information.
The detection methods for these IDSs are of three types: signature-based detection, anomaly-based detection, and hybrid detection. An anomaly-based IDS 3 can figure out abnormal network/system behavior from the comparison of normal profile with the current system. If deviation is found beyond a certain threshold, then the event is declared as abnormal. A signature-based IDS 4 identifies the attack by comparing the stored signatures with the current incoming event. Here, the signature is a description of some features for a known attack. An alarm would be triggered by the absolute match. The combination of signature-based detection and anomaly-based detection is called a hybrid IDS.5,6
The IDS effectiveness can be calculated from the probability of a positive detection on actual anomaly occurrence. In the application domain, the IDS effectiveness is considered from its capability to lower down the false-positive rate (FPR) instead of increasing the true-positive rate (TPR). 7 Therefore, the crucial challenge is to lower down FPR with a minimum decrement in TPR to maintain the detection quality at a practical level.
Generally, the normal class is comprised of various disjoint subclasses. The application protocol (Simple Network Management Protocol (SNMP), File Transfer Protocol (FTP), Hypertext Transfer Protocol (HTTP), etc.), transport protocol (User Datagram Protocol (UDP), Transmission Control Protocol (TCP), Internet Control Message Protocol (ICMP), etc.), and other network communication traffic have various subclasses. The accounting of subclasses can increase the performance of IDS.8,9. After that the subclasses are decomposed into more specific subclasses, which is mentioned in various studies.10,11 The user-defined multi-level hierarchy has the potential to maximize the accuracy of the anomaly detection system. These research studies are efficient to improve the anomaly detection system for multi-level subclass hierarchy. However, the limitation of these methods is of their practical implementation because of certain reasons.
Users required expert knowledge. The users need to explore the hierarchal data structure to define the subclasses. They need to know the working of IDS thoroughly, which needs training and regular interactive session.
Specific for certain IDS. Most of the IDS are applicable for specific domain only. It is critical to choose the most relevant IDS where the system is comprised of different domains.
So the fundamental issue is to minimize the FPR of IDS in practical solutions. In this study, we develop an autonomous system called soft-computing-based anomaly detection (SCAD) for hierarchical data.
SCAD generates fundamentally distinct “points of view” for ordinary information to which are compared with test cases. With contextual anomalies in comparison to the whole data set as ordinary, but an anomaly provided some context, 12 we have an especially reverse notion that we called contextual inlier. In this regard, we have a special focus on the contextual anomalies. Some test cases are normal but appear to be anomalous to few information subclasses. The principle of our technique is that only after comparing an anomaly to every subclass, it should be declared normal or anomalous. SCAD takes all subclasses into account, which strengthens the proposed technique in efficient anomaly detection. Our contribution is as follows:
We designed a general-purpose IDS to improve the FPR, where the data could be represented with a hierarchical structure.
SCAD is more practical than most of the previously developed techniques which benefit from a hierarchical framework due to the following reasons: It is a generic approach for an anomaly detection system which is designed to work with various black-box methods. The exploration of hierarchy algorithm is fully automated and the user does not need to be domain-specific or to create an algorithm for the hierarchy.
We evaluated the SCAD-RNN and existing IDSs capacity to increase the efficiency with benchmarking data sets.
Related work
Recent IDS13–16 extracts the characteristics from payload packets to train the one-class classifiers which are capable of identifying abnormal network traffic. Mirsky et al. 15 suggested Kitsune, the devised model fetch the implicit traffic on the network at runtime based on contextual characteristics with a tiny storage footprint to build one-class auto-encoders automatically. They demonstrate that Kitsune can almost tackle the problem well, but offline or batch IDSs are even better in some instances. The extracting functions for the IDSs suggested by Nguyen et al. 13 and Duessel et al. 14 constitute typical octets and enable syntactic connect to the communication protocol for incorporation. Here, the author extracted functional vector and used in both the IDS with the one-class support vector machine (OCSVM) kernel (radial basis function (RBF)) and other IDSs9,15 in a similar way. Ying et al. 17 presented an IDS for cloaking attack with clock skew-based IDS as a solution for controller area network.
The above IDSs supposed that information can be processed separately. The distinct information in the documents may be linked, which can provide an effective context for anomaly detection as per their relative order of occurrence. 18 Therefore, sequential IDSs are another significant category of IDSs. IDS operating on byte sequences in a packet or on packet continuation instead separate function vectors. Recently, this type of IDS has become more important because of the ever-increasing abundance of sequential information in numerous real-life scenarios. Gupta et al. 19 analyzed that large-scale and Internet processing requirements usually make it more demanding to analyze anomalies than in non-sequential information. In Wang et al., 20 Swarnkar and Hubballi, 21 and Wang and Stolfo, 22 the sequential IDSs are suggested for the detection of anomalous sequences containing subsections of which their inherent frequency is unexpected. The latest is an IDS known as Rangegram, 23 which effectively produces a Normality model within ordinary sequences of the high-order n-grams with a maximum and minimum range of frequency. In a test sequence, the author analyzed that the n-grams increased from the normal range in case network intrusion.
The sequential IDSs like Tian et al., 23 Michlovský et al., 24 and Haddadi 25 analyzed based on the sequences they contain to identify ordinary sequences with much difference. These IDSs use a version of the SSK 26 to implicitly map sequence into a large function space where distances between sequences are equivalent. For instance, in a semi-supervised situation, Tian et al. 23 applied the SSK along with OCSVM for intrusion detection in computer scheme that is described in abnormal system subsequences. Because of their capacity to combine various base detectors with a view to optimizing the bias-variance trade, anomaly detection ensembles have grown popular in latest years.13,18,27,28 The IDSs suggested in Perdisci et al. 28 and Nguyen et al. 13 have been designed with the support of a set of OCSVM basic detectors, trained with various function subsets to obtain distinct information representations and thus to improve detection precision. Likewise, auto-encoder detectors in the Kitsune 15 set model distinct function subsets of ordinary network packets in their auto-encoders. In this research, the mentioned technique is the detection of anomalies, even though the base detectors of our ensemble are not represented by distinct types of ordinary information, as opposed to the ensembles outlined in literatures,13,15,28,29 and are driven by the hierarchy. Furthermore, our approach can be implemented automatically to any soft-computing technique and does not just concern a particular recurrent neural network (RNN) type. The user can use any soft-computing-based technique with the first stage of the proposed SCAD model.
The existing techniques applied the single hierarchical system to enhance intrusion detection based on anomalies. In order to enhance detection precisely under a controlled framework, Peddabachigari et al. 30 employed the support vector machines (SVMs), decision trees (DT), and a fusion classifier of DT-SVM. The group of three incorporated into a hierarchy of classifier. Kim et al. 9 designed a hybrid IDS by integrating misuse detection with anomaly detection. The author broke down ordinary information into a hierarchical subclass tree and OCSVM is created for each subclass. These techniques need to attack information labeled. However, it is challenging to break down the ordinary data into subclasses only on account of their resemblance to recognized attack classes. However, our strategy requires no marked information and records a more natural decay based exclusively on the similarity between ordinary data cases. In combination with the unchecked clustering algorithms, Xiang et al. 31 have created a hierarchical classification 32 process that improves the initial training label as per original data set composition. However, user assumptions required the clustering algorithm needs to define the user assumptions for the distribution detail of data. The initialization of the number of classes required is a costly numerical optimization in the convergence process. The hierarchical exploration is conducted based on correlations clustering (CC). 33 As CC has been designed to autonomously discover the maximum amount of classes, it automatically decomposes the ordinary class into subclasses by our hierarchical clustering algorithm. The method defined in this process is not a hierarchical approach for classification since every hierarchical node is not being taken as a decision-maker compared with route node; 32 indeed, instances which are ultimately identified as anomalies by our method will have been passed through and checked at all nodes. Although, the cloud-based techniques are designed for load balancing by enhancing bat algorithm, Luhach and colleagues34,35,36 presented an effective framework based on service-oriented architecture (SoA) for e-commerce applications and Internet-of-things (IoT) applications. The benefits of hierarchical anomaly detection are also reported by Robinson et al. 11 The anomaly detection process is the sum of unsupervised learning and discovery of hierarchical data in the training set. Similar to the proposed approach, this model enables the user to select anomalies with a wide variety of definitions.
The structure is meant for sequential data processing which can limit the new anomalies exploration. As opposed, the sequential as well as non-sequential information can be processed by our structure. Therefore, the proposed model is indifferent to the information type and can be helpful in every field of abnormal identification where the information is hierarchical, as long as it is an equally similar example, graph data can also be processed on it. 27 In addition, the strategy of Robinson and other parties need consumers who are not necessarily known to enter semantic hierarchy, such as moment (e.g. days, months and years) or place hierarchy (e.g. state, city, town), particularly in a dynamic situation. Of course, this limits their usability for customers who have expert knowledge of the hierarchical interactions in the information and the method of identification of anomalies. Therefore, the customer should provide the connections between information characteristics, ontology, and the interaction between anomaly detectors to detect any anomalies. Instead, we do not require customers to be domain specialists in our system. However, if consumers have a helpful knowledge of the data set, they can transmit in the form of pairwise features. Our approach has strong evidence to become more practical and applicable to the existing black-box-based IDS.
Deep learning, a machine learning branch, has become increasingly common in the latest years. The performance of a deep learning approach is far better than traditional approaches in intrusion detection. In Javaid et al., 37 the authors detect the anomalies on the basis of the neural network, and the experimental results demonstrate that deep learning can be used to detect anomalies in networks. In Tang et al., 38 the authors applied the self-taught learning (STL) with deep learning and propose in an NIDS. The method is shown to be more efficient when comparing its performance with those found in past research. However, the authors focused on the capacity of deep learning to reduce features. For prior-training, it primarily utilizes deep learning techniques and conducts classification through the traditional supervisory model. Applying the deep learning technique to directly conduct classification is not prevalent, and very few articles are researched on multi-class classification. RNNs are regarded to be reduced-size neural networks, according to Sheikhan et al. 39 The author recommended documenting a three-layer RNN architecture with the input of 41 characteristics and output of four categories of intrusion for IDS based on misuse. However, layer nodes are partially connected, features of high-dimension did not study for deep learning for hierarchical data with binary classification. Deep learning techniques have flourished rapidly with the ongoing growth computing power and big data. It has been commonly used in multiple fields. RNN used for intrusion detection via deep learning method presented in this document followed similar thinking. We use the hierarchical exploration and RNN-based model for classification based on static and dynamic training rather than pre-training only. In addition, NSL-KDD data set has used with the separate training set and testing set to assess their performance in identifying binary and multi-class network intrusions and the comparison performed with Naive Bayesian, J48, artificial neural network (ANN), SVM, Random Forest, and other machine learning techniques mentioned in previous studies.
Anomaly detection in hierarchical data
The data sets with meaningful hierarchical structure can be used to minimize the FPR in the IDS. Here, the SCAD for IDS is presented for hierarchical data. This process is accomplished in two steps: (1) explore the hierarchical structure of data and (2) deep-learning-based anomaly detection to reduce the FPR in a discovered hierarchical structure.
Exploration of hierarchical structure
In this stage, the normal data

Exploration of level of hierarchical structure.
Since no prior information is available for the data, we conduct the CC
33
to classify the number of subsets in the data set
We employed the settings of anomaly detection as semi-supervised learning;
18
in this, normal data instances
In CC, we used supervised classification at the first stage to define the available labeled training objects. After that, we insert the unlabeled clusters in the base of the representative cluster on similarity calculation. The input to Algorithm 2 is a pairwise similarity calculated as per Algorithm 1.

The similarity of

The pairwise similarity matrix values are calculated with equation (1) and input to Algorithm 2. But, while deciding the similarity function, we follow equation (2),


The objective of CC is to achieve the maximum pairwise agreement with the calculation of the highest value of agreement objective function

where

The assignment of
Considering the set

SCAD
The IDS is usually working in two phases. The IDSs which are working on
Numerical conversion and normalization
The NSL-KDD data set has a total 41 observations, out of which 3 are non-numeric features and 38 are numeric features. The proposed SCAD technique used RNN, which takes the numeric values. We must convert non-numeric values in the form of numeric values such as “service,”“protocol types,” and “flag.” The “protocol type” is of three types ICMP, UDP, and TCP, we encode them into binary form vector (0,0,1), (0,1,0), and (1,0,0), respectively. Similarly, we convert the “flag” and “service” types in 122 and 11 attributes, respectively. Furthermore, the numerical values have a large scope in the data set, there is a large difference between the highest and lowest values. Furthermore, we normalize the values as per the following equation
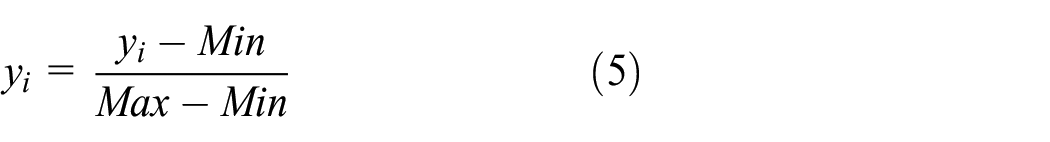
In recent neural networks, the most important research is to be done for inputs, output units, and concealed units. The RNN model has information from the entrants in one-way to the cache units essentially. The summary of information from the preceding time clock unit to the current time clock unit is shown in Figure 2. One-way information is carried out by RNN.

Recurrent neural networks.
RNN
Hidden devices can be seen as the entire network storage, which remembers the end of data. We can find that the RNN will embody the profound learning when we unfold as shown in Figure 3. For monitored classification, learning an RNN strategy can be used as shown in Figure 2. The directional loop is implemented by current neural networks and remember the prior data to be applied on present output. This is the main difference in traditional and fuzzy neural network (FNN).
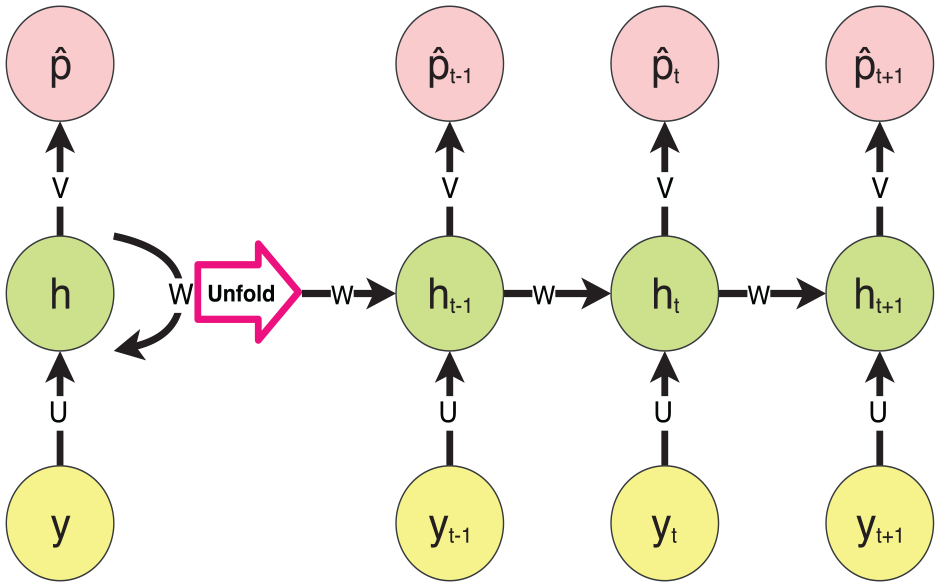
The unfolded recurrent neural network.
The previous output also has to do with the present output sequence, the nodes are no longer connected but concealed states has a link with each other. In addition to the output of the input layer as well as the output of the final concealed layer, we can look at hidden units as the entire network storage reminiscent of the end-to-end information. We can say that when we unfold RNN, it embodies profound learning. An approach to RNNs can be used for monitoring classification learning. Recent neural networks have initiated a directional belt, it has an essential distinction from conventional feed-forward neural networks, able to record and apply previous information. This represents the key distinction. The output from the previous iteration is connected with the sequence of current output. Hidden layers between the nodes are not connected; otherwise, the hidden layer has connections. The SCAD-RNN model working is shown in Figure 4.
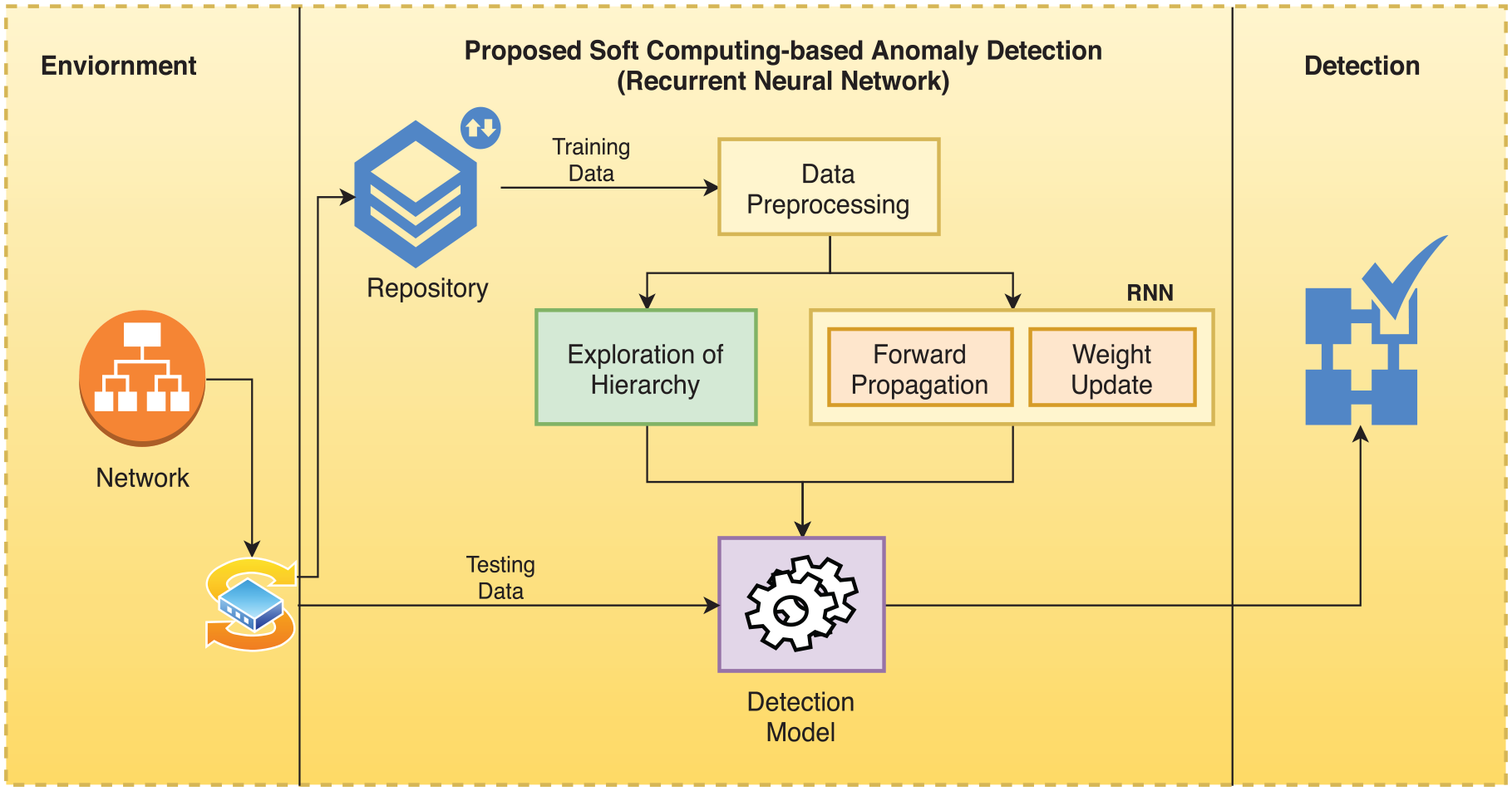
Proposed SCAD-RNN intrusion detection system.
Methodology of SCAD-RNN model
It is evident that the SCAD-RNN model is the combination of two modules: forward propagation and back propagation. In forward propagation, the output value is calculated, and in back propagation, the output value is deployed to pass the residuals to update the weights, which is similar to the formation of ordinary neural network. The RNN model present in the methodology could further replace with other black-box methods.
As per Figure 3, we applied the unfolded RNN. To formalize the standard RNN, the training samples are
As per Figure 4 and Martens and Sutskever, 45 Algorithm 4 is a pseudocode for forward propagation. Algorithm 5 is a pseudocode for weight update.


A single training pair
The detection model is shown in Figure 4 is the combination of hierarchical exploration and RNN model. At this stage, the hierarchical data
Data set
In the field of intrusion detection studies, the 2009 produced NSL-KDD46,47 data set is widely used. This is a benchmarking data set used by most of the authors.48–50 The data set is vital in solving the inherent redundant records issue in KDDCup’99 data set. The most frequent record does not favor the classifier in training and testing data set. The KDDTrain+ covers the training data set and testing data set are KDDTest+ and KDDTest-21. Table 1 shows the different types of attacks and normal records in the data set. The KDDTest+ subset is designed named as KDDTest-21, which is more difficult to classify. The data set is classified in four categories based on the types of attacks: U2R (User to Root attack), R2L (Root to Local), Probe (Probing attack), and DoS (Denial of Services). The testing data contain some attack which is disappearing in the training set, which strengthens the testing process of IDS.
List of NSL-KDD and KDDCup’99 data set normal and attack classes.

DoS: Denial of Services; R2L: Root to Local; U2R: User to Root attack.
Evaluation
For the measurement of the results of the SCAD-RNN model, the largest performance indicator is accuracy, 51 used in our model. We implement the detection rate (DR) and FPR concerning the accuracy. The true positive (TP) corresponds to the correctly rejected documents, and it refers to the number of anomaly documents recognized as an anomaly. This is the equivalent of erroneously refused false positive (FP), which indicates the number of ordinary documents recognized as an anomaly. The true negative (TN) corresponds to the properly recognized ones and refers to the number of ordinary logs recognized as usual. The false negative (FN) corresponds to the wrongly admitted ones and it refers to the number of anomaly records recognized as usual. The confusion matrix is calculated for binary and multi-class classification. Our note is as follows:
Accuracy. It is calculated as a percentage of the total number of records versus classified TP and TN data. It can be calculated as per the following equation

TPR. It is similar to the DR, it is calculated as a total number of anomalies versus data identified correctly. It can be calculated as per the following equation

FPR. It is the percentage of several rejected records versus normal records in the data set

Thus, the objective of this study is to reduce the FPR while maintaining the TPR.
Experiment results and discussion
We have used one of the latest and widest profound frameworks in this study 52 for deep learning in Python. The experiment conducted in a private notebook with an Intel Core i5-3210M CPU @ 2.50 GHz, 4 GB of memory. Two experiments for binary category (Normal, Anomaly) and 5-category classification such as Normal, R2L, DoS, Probe, and U2R have been conducted for performance analysis of the SCAD-RNN model. Contrasting experiments are conceived simultaneously to compare with other machine learning techniques. We contrasted the output with a naive Bayesian, ANN, random forest, multi-layered perceptron, support vector machines, and other machine learning techniques in binary classifications, as stated in Tavallaee et al. 46 and Ingre and Yadav. 53 Likewise, we analyze the SCAD-RNN model’s multi-class classification using the data set of NSL-KDD. By comparison, in the five-category classification, we studied the J48, naive Bayesian, SVM, random forest, multi-layer perceptron, ANN and support vector machine, and other machine learning models performance for intrusion detection. Finally, with the traditional methods, we combine the efficiency of proposed SCAD-RNN model. In addition, we build a used data set referred to as Sheikhan et al. 39 and Yin et al. 54 and compare the output with the SCAD-RNN method of reduced size.
Binary classification
In data preprocessing, the 41-dimensional characteristics have been mapped to 122-dimensional characteristics. In binary classification, the SCAD-RNN model has two output nodes and 122 input nodes. The epoch count is 100. In order to train this better pattern, allow 240, 120, 80, 60, and 20 hidden nodes. The learning rate is set as 0.5, 0.1, and 0.001, and then comply with the NSL-KDD data set classifications precision. The experiment result indicates that the learning rate and hidden nodes are directly related to the accuracy of the model.
The KDDTest+ test set for the two-category experiment for classification. The confusion matrix is shown in Table 2. In this experiment, the proposed model gives higher efficiency with 0.1 learning rate and 80 hidden nodes. The results indicate that when 100 periods are provided for the KDDTest+ data set, SCAD-RNN operates at a good DR (84.03%). For KDDTest-21, we receive 69.75% performance.
KDDTest+ confusion matrix for binary classification.

The comparison has been conducted on various machine learning techniques such as Naive Bayesian, J48, Multi-layer Perceptron, Random Forest, Support Vector Machine, and other classification algorithms in Tavallaee et al., 46 and an algorithm in the ANN which is also 81.2% given in Ingre and Yadav. 53 All these findings are conducted on the same NSL-KDD benchmark data set. The proposed SCAD-RNN model is more efficient as compared to other binary classification models as shown in Figure 5.

Binary classification comparison of SCAD-RNN and other models.
Multi-class classification
It has been found from the experiment on KDDTest+ that the SCAD-RNN model has high accuracy as we set learning rate as 0.5 and hidden node as 80.
Tcomparison of proposed SCAD-RNN model with machine learning model such as Naive Bayesian, J48, Support Vector Machine, Multi-layer perceptron, and other with 10-layer cross-validation using Python libraries. The hierarchal model and RNN model uniformly discover the detection model. The combination of SCAD and RNN tested on the testing data. The performance of binary classification is better as compared to multi-class classification as shown in Figures 5 and 6.

Multi-class classification comparison of SCAD-RNN and other models.
The SCAD-RNN confusion matrix for multi-class classification is shown in Table 3. The test demonstrates that for the KDDTest+ test set at 82.61% and for KDDTest-21 at 65.89% are better than those achieved using other machine learning models as mentioned in Figure 6. The proposed model performs better than the ANN algorithm, 53 which give the accuracy 79.9%. The FPR and TPR of normal and attacks are shown in Table 4.
KDDTest+ confusion matrix for multi-class classification.

DoS: Denial of Services; R2L: Root to Local; U2R: User to Root attack.
Multi-class classification evaluation metrics.

DoS: Denial of Services; R2L: Root to Local; U2R: User to Root attack; TPR: true-positive rate; FPR: false-positive rate.
Performance of multi-class classification of SCAD-RNN with RNN of reduced size 39 with KDDCup’99 data set with same testing and training sets gives the following results given as follows. According to the experiment conducted, the SCAD-RNN model achieves the higher accuracy of 98.02% on the test set, which is higher than 94.1% accuracy achieved by Sheikhan et al. 39 The SCAD-RNN has a strong model with hierarchical exploration and soft-computing technique as compared to RNN with reduced size. The training time of the proposed model is higher, which can further reduce with GPU acceleration and parallel processing.
Conclusion and future scope
The proposed SCAD-RNN model has a powerful intrusion detection modeling capability and high precision in binary as well as multi-class classification. The hierarchy of data sets developed using CC. Furthermore, deep learning approach is applied to compare the test case with subclasses to decide whether the test case is anomaly or normal. Compared with traditionally classified techniques like naive Bayesian, J48, random forests, and SVM, the achievement is attained by greater accuracy rates and a small FPR, particularly under the KDDCup’99 and NSL-KDD data set classification. The model improves both the TPR for intrusion detection and the capacity to detect the intrusion class efficiently. In future, the potential research continues to reduce the time for training using GPU and parallel processing to prevent explosion and gradients removal studies to improve the classification efficiency of hierarchical discovery, long short-term memory (LSTM), and the bidirectional RNN intrusion sensing algorithm.
Footnotes
Handling Editor: Iftikhar Ahmad
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.