
Abstract
Smart grids have recently attracted increasing attention because of their reliability, flexibility, sustainability, and efficiency. A typical smart grid consists of diverse components such as smart meters, energy management systems, energy storage systems, and renewable energy resources. In particular, to make an effective energy management strategy for the energy management system, accurate load forecasting is necessary. Recently, artificial neural network–based load forecasting models with good performance have been proposed. For accurate load forecasting, it is critical to determine effective hyperparameters of neural networks, which is a complex and time-consuming task. Among these parameters, the type of activation function and the number of hidden layers are critical in the performance of neural networks. In this study, we construct diverse artificial neural network–based building electric energy consumption forecasting models using different combinations of the two hyperparameters and compare their performance. Experimental results indicate that neural networks with scaled exponential linear units and five hidden layers exhibit better performance, on average than other forecasting models.
Keywords
Introduction
Smart grids, which are known to have features including reliability, flexibility, sustainability, and efficiency, have emerged as a solution for numerous current problems, including energy shortage and environmental pollution.1–3 A smart grid is a platform for exchanging real-time power information supported by wired/wireless communication, control, and sensors between suppliers and consumers to enable innovative power management.1,2 Typical smart grids comprise smart meters, energy management systems (EMSs), energy storage systems (ESSs), and diverse renewable energy resources. In particular, an EMS determines ways to save energy on the demand side by collecting and analyzing data related to building energy consumption within an electric power system. 3 On the supply side, an EMS generates schedules for power generation and ESSs by considering a number of factors, including storage costs and the amount of energy to be used in the future. 4 In order to generate more effective schedules, an EMS requires accurate short-term load forecasting (STLF).5,6
The aim of STLF is to ensure the reliability of the electric power system equipment and prepare for losses caused by power failures and overloading by controlling electricity reserve margins.7–9 STLF is typically used to predict the electric load on an hourly basis up to 1 week in advance for daily operation and cost minimization.10,11 For instance, accurate STLF can provide economic benefits by storing energy at night when electric costs are relatively low and emitting electricity during the day when electric costs are high. 9 STLF includes daily peak electric load, total daily electric load, hourly electric load, and very short-term load forecasting (VSTLF; e.g., 15-min and 30-min interval load forecasting). 12
STLF is not an easy task because energy consumption patterns are complex, and uncertain external factors can cause a shift in the demand curve.13,14 Factors affecting the fluctuation in building electric energy consumption include architectural structure, thermal properties of physical materials, time zones, electricity rates, special events, resident schedules, climatic conditions, and lighting.14,15 In addition, when forecasting electric loads, complex energy consumption correlations between the current time and the previous time should be appropriately considered.16,17 To date, numerous artificial neural network (ANN)–based STLF models have been constructed to predict exact electric loads and have exhibited favorable performance.18–35 To further improve their performance, it is critical to effectively tune their hyperparameters. All ANN models have various hyperparameters (i.e. the number of hidden layers (HLs), number of hidden nodes, activation functions, number of epochs, learning rate, batch size, optimizers, loss function, and so on) to specify the structure of the network itself or to determine how to train neural networks (NN).36,37 Of these, the two most essential hyperparameters are the activation function and the number of HLs. 37
Activation functions assist the network in separating useful data from noise38–41 and are also used to introduce nonlinearity to models, which allows ANN models to learn nonlinear prediction boundaries. As their forecasting results are highly dependent on the activation function, selecting a proper activation function is critical for improving forecasting performance. Increasing the number of HLs does not always improve forecasting accuracy.42,43 In addition, a too-large increase in the number of HLs can decrease accuracy in the test set because of overfitting the training set. 42 In other words, when the ANN model with too many HLs learns the training data, it is difficult to generalize to new unseen data. 43
Although these hyperparameters are critical in the performance of ANN models, no studies have compared the prediction performance by considering various activation functions and number of HLs for STLF. Therefore, in this study, we construct an ANN-based STLF model for forecasting electric energy consumption of building or building clusters accurately. In order to apply our STLF model for other building or building clusters, we consider general factors such as calendar data, weather information, and historical electric loads and perform data preprocessing using them. Then, we perform extensive experiments to compare the performance of various activation functions and number of HLs for selecting an optimal ANN-based STLF model.
The primary contributions of this study can be summarized as follows.
For day-ahead energy scheduling in a smart grid, we build an ANN-based STLF model with a focus on electric energy consumption of a building or building clusters.
We consider general factors such as calendar data, weather information, and historical electric loads to apply our STLF model as the baseline model for other building or building clusters.
We predict the 30-min interval electric load for five different types of buildings by setting several cases as test sets.
We extensively compare overall prediction performances of activation functions and the number of HLs for constructing an optimal ANN-based STLF model.
The rest of this article is organized as follows. In section “Related studies,” we review related studies on STLF. In section “Data collection and preprocessing,” we describe the data preprocessing procedures that transform the historical load data and external information to input vectors of the ANN-based model. In section “ANN-based energy forecasting modeling,” we demonstrate the 30-min interval electric load forecasting model based on ANNs. In section “Experimental results,” we describe the experimental design and present the experimental results. Finally, in section “Conclusion,” we conclude the results and proposed future study directions.
Related studies
In this section, we review a number of STLF studies (including those on VSTLF) that have been conducted for the efficient operation of smart grid systems. To date, several ANN-based electric load forecasting models have been developed. Table 1 presents the STLF-related studies based on ANN.
Summary of short-term load forecasting based on ANNs.

ANN: artificial neural network; NN: neural networks; FFNN: feedforward neural network; RNN: recurrent neural networks; NARX: nonlinear autoregressive exogenous; RVFL: random vector function link; BPNN: backpropagation neural networks; GRNN: generalized regression neural networks; ELM: extreme learning machine; RBM: restricted Boltzmann machine; LM: Levenberg–Marquardt; DBN: deep belief networks; DNN: deep neural network; DAE: deep auto-encoder; CNN: convolutional neural network; ReLU: rectified linear units.
Park et al. 18 compared three NN-based electric load forecasting models: feedforward neural network (FFNN), recurrent neural network (RNN), and neural network-based nonlinear autoregressive exogenous (NARX) models. The forecasting results indicated that the NN-based NARX model is superior to the other models because it can reuse the predicted load data for reflecting the forecast trend. Mordjaoui et al. 19 proposed a dynamic NN-based electric load forecasting model and compared it to the Holt–Winters exponential smoothing (ES) and seasonal autoregressive integrated moving average (SARIMA) models. They reported that their model could achieve better mean absolute percentage error (MAPE). Qiu et al. 20 proposed an STLF model based on empirical mode decomposition (EMD) and a random vector function link (RVFL) network. They used EMD to decompose the electric load data into a number of intrinsic mode functions and one residue. The RVFL network was then trained for each intrinsic mode function, including the residue. They reported that their model performed best of six benchmarking models (i.e. Persistence, support vector regression (SVR), single-HL feedforward NN, RVFL, EMD, and EMD-based SVR). Reddy 21 proposed a Bat algorithm-based backpropagation approach for forecasting short-term electric loads considering weather factors (i.e. temperature and humidity). Their approach significantly reduced the trial and error effort in the training phase and also produced an STLF technique that was more efficient, adaptive, and optimized than the ANN-based approaches. Hu et al. 22 proposed an STLF model based on a generalized regression neural network (GRNN) and reported that the prediction accuracy of the model was higher than that of the backpropagation neural network (BPNN). Ertugrul 23 reported a 15-min interval electric load forecasting model based on recurrent extreme learning machine (RELM). In RELM, extreme learning machine (ELM) was adapted to train a single hidden-layer Jordan RNN. The RELM exhibited better performance than other machine learning methods, such as traditional ELM, linear regression, and GRNN, in terms of root mean square error (RMSE). Zeng et al. 24 proposed a hybrid hourly electric load forecasting model based on ELM and switching delayed particle swarm optimization (SDPSO) methods. In the model, input weights and ELM biases were optimized by the SDPSO method. The model significantly improved the forecasting accuracy compared to the radial basis function NN. Li et al. 25 proposed an ensemble hourly STLF model based on wavelet transform, ELM, and partial least squares regression (PLSR). Their wavelet-based ensemble approach employed different wavelet specifications to create an ensemble of individual predictors. For each subcomponent obtained from the wavelet decomposition, a parallel forecasting model of 24 ELMs was established. To improve the accuracy of the model, individual outputs were combined using the PLSR method. They reported that their model could provide superior forecasting accuracy compared with other forecasting models. Mocanu et al. 26 suggested two STLF models based on the conditional restricted Boltzmann machine (CRBM) and factored conditional restricted Boltzmann machine (FCRBM). In terms of forecasting accuracy, FCRBM outperformed ANN, SVR, RNN, and CRBM. Raza et al. 27 compared the ability of backpropagation and Levenberg–Marquardt (LM) training method of ANN for STLF. They considered historical electric load, time factors, and weather information as an input variable of the ANN-based STLF model. They used their forecasting models to predict the hourly electric load of the ISO New England grid. Their experimental results indicate that LM showed better results than the backpropagation in terms of MAPE. Elgarhy et al. 28 proposed an hourly electric load forecasting model based on LM-based ANN. They applied to multiple datasets and the results obtained were compared to the published results. Singh et al. 29 presented hourly electric load forecasting model of New England Power Pool (NEPOOL) at ISO New England using LM-based ANN. They used historical electric load, time factors, and weather information as input variables and hourly electric load as output variable to train ANN. Separate training and forecasting have been done for working days, weekends only, and weekends including holidays. Since the ISO New England dataset used in previous studies27–29 has extensive geographical coverage of the collected electric load, it showed uncomplicated electric energy consumption patterns. Therefore, ANN with one HL showed satisfactory prediction performance by training simple patterns adequately. However, our goal is to predict the electric energy consumption of buildings or building clusters that exhibits complex energy consumption patterns. Hence, we consider not only ANN with one HL but also a deep neural network (DNN) with two or more HLs to reflect the complex energy consumption patterns effectively.
A DNN was recently used in electric load forecasting.44–46 For instance, Dedinec et al. 30 proposed an STLF model using deep belief networks (DBN), which comprised multiple layers of restricted Boltzmann machine (RBM). The forecasting results of the DBN were compared with those of the FFNN and the forecasting load data provided by the Macedonian system operator. The MAPE of the proposed model was higher than the other forecasting models. Qiu et al. 31 reported an ensemble deep learning method based on EMD and DBN for STLF. They compared nine benchmark methods (i.e. Persistence, SVR, ANN, DBN, random forest, ensemble DBN, EMD-based SVR, EMD-based single-HL feedforward NN, and EMD-based random forest) to verify the effectiveness of their proposed method. They evaluated the prediction performance of forecasting models using RMSE and MAPE. Their EMD-based ensemble deep learning approach exhibited superior performance in statistical testing. Ryu et al. 32 proposed two DNN-based load forecasting models using pre-training RBM and rectified linear units (ReLU) without pre-training. The forecasting results indicated that their models were more accurate and robust compared to other forecasting methods, such as shallow NN, double seasonal Holt-Winters, and SARIMA. Fan et al. 33 developed deep learning-based methods for achieving accurate and reliable day-ahead building cooling load forecasting. The deep learning-based methods (DNN; supervised learning, deep auto-encoder (DAE); unsupervised learning) were compared to seven benchmark methods (supervised learning) and existing feature extraction methods (unsupervised learning), used in the building field, in terms of accuracy and computation efficiency. The results indicated that deep learning-based methods could enhance the prediction performance, particularly when the DAE was used to construct high-level features as forecasting model inputs. Din and Marnerides 34 built two STLF models based on feedforward deep NNs and recurrent DNNs and reported that they enabled the extraction of a feature from the original “raw” power measurements by exploiting the joint time–frequency representation of the load signals. Their method could model the most dominant factors that affected the electric load patterns. Kuo and Huang 35 proposed a deep convolutional neural network (CNN)-based STLF model, in which the input layer denoted information of previous electric loads, and the output values represented the forecast electric load. They reported that the most critical feature could be extracted by the designed one-dimensional (1D) convolution and pooling layers and that their model was more accurate than five artificial intelligence methods, including SVR, random forest, decision tree, multilayer perceptron (MLP), and long short-term memory (LSTM) network.
In addition, the LSTM-based RNN exhibited favorable performance in real-time STLF.2,44–46 However, the LSTM networks could reflect the previous point for the forecasting of the next point. 10 As the day-ahead building electric energy consumption forecasting of a smart grid should be scheduled until after 1 day, LSTM networks are not suitable for 30-min interval electric load forecasting because there is a gap of 47 points. Therefore, we focus on the ANN-based electric load forecasting model for efficient day-ahead scheduling in smart grids.
Data collection and preprocessing
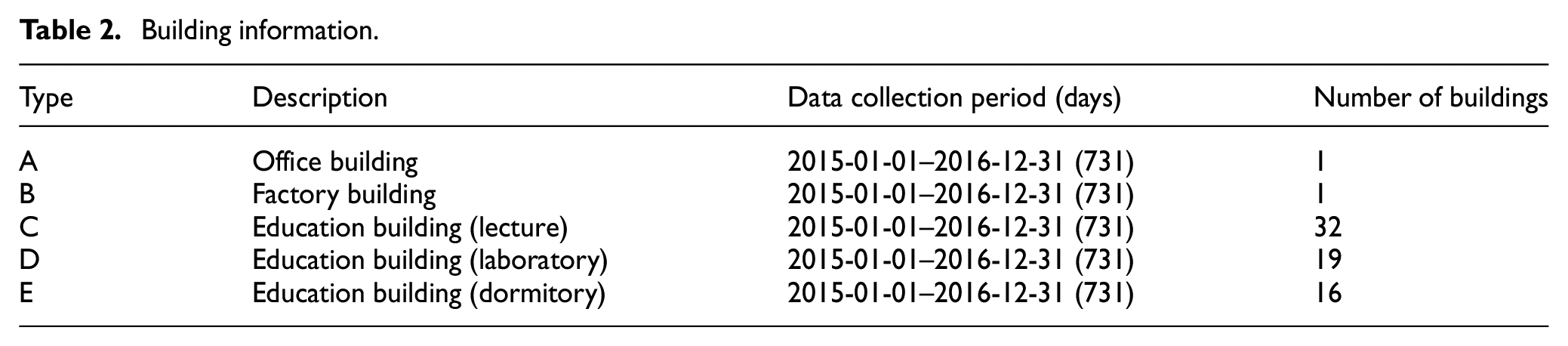
In this study, we use electronic Watt-hour meter data collected from the Korea Electric Power Corporation (KEPCO) for five different building types in South Korea. Table 2 presents the data collection periods and information about the buildings. Data were collected every 30 min.
Building information.
The building electric energy consumption patterns show different characteristics depending on building types. For instance, a university campus shows high electric energy consumption during the office hour, class hour, and special events. 47 However, if these factors are reflected in the forecasting model, it is challenging to utilize for typical building electric energy consumption forecasting model because it cannot be applied to other buildings and building types. Hence, we used 120 input variables comprising calendar data, weather information, and historical electric load to construct the typical ANN-based STLF model. These factors can be easily collected and applied to other buildings and building types. More detailed explanations for the selection of input variables are given in the next section.
Calendar data
As time series data represent trends in electric loads, we consider all input variables that could express calendar data: month, day, hours to minutes, days of the week, and holidays, as presented in Table 3. In particular, as the month, day, hour, and minute have periodic properties, they were not represented by sequential values. For instance, although 11 p.m. and midnight are adjacent, their sequence difference in the sequence format is 23. In addition, although 31 March and 1 April are adjacent, their difference is 31 in the sequence format. To reflect such period properties, we transform time data using equations (1)–(7). These equations enhance the sequence data in 1D space to continuous data in two-dimensional (2D) space. 47







Calendar data input variables.

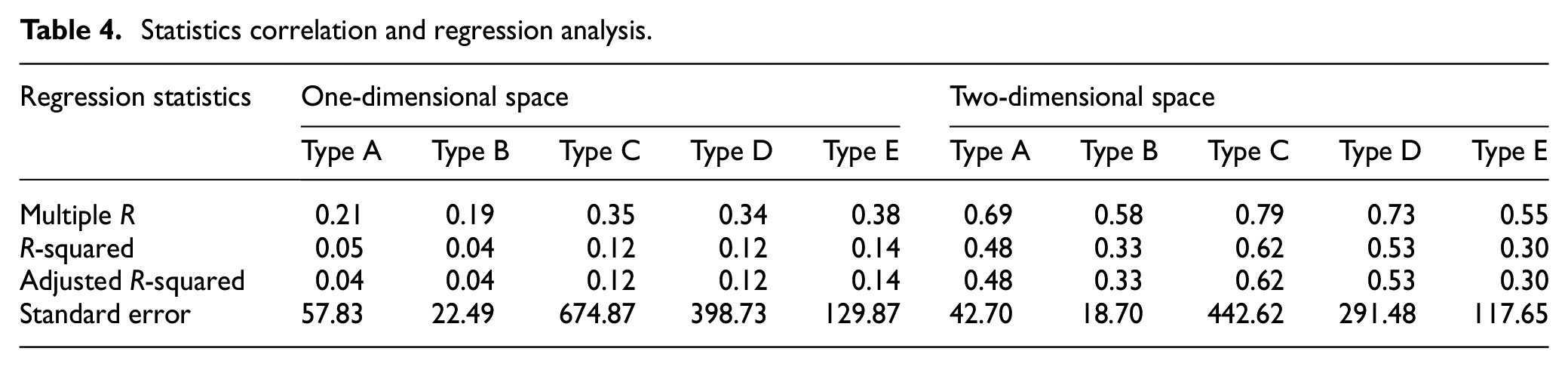
In the case of minutes, there are only two cases (0, 30). Therefore, the hour and minutes can be reflected in the corresponding time as shown in equation (1) and then applied to equations (2) and (3). Figure 1 shows hour information in 2D space using equations (2) and (3). Using this representation, we can make 11:30 p.m. and 12:00 a.m. adjacent, which is similar to the clock shape. Similarly, we can represent the day and month data in 1D space to continuous data in 2D space using equations (4)–(5) and (6)–(7), respectively. To verify the validity and applicability of 2D representation, we calculated several regression statistics on the electric loads in 1D space (month, day, hour, and minute) and in 2D space as shown in Table 4. In the table, we can see that 2D representation can explain their correlation more effectively than 1D representation. Therefore, equations (2)–(7) give a total of six input variables to represent the date and time of the prediction time points.

Two-dimensional representation of a day based on 30-min interval.
Statistics correlation and regression analysis.
The bulk of buildings or building clusters have electric load patterns by days of the week according to the building type.6,10 For instance, hotels and retail premises, such as department stores and shopping malls, exhibit similar electric load patterns on weekdays and weekends. However, typical office buildings and industrial buildings have significant energy consumption on weekdays and low energy consumption on weekends. In South Korea, electric loads and energy consumption are typically low on national public holidays, such as the Lunar New Year holiday and Korean Thanksgiving days, called Chuseok.10,17 Therefore, various electric load patterns can be observed according to weekdays and holidays. To reflect these factors, days of the week and holidays should be considered in the forecasting models. In this context, holidays include Saturdays, Sundays, and national public holidays. We collected the holiday information in South Korea at Time and Date (https://www.timeanddate.com/holidays/) that can confirm national public holidays information in many countries. Therefore, we define an 8D feature vector of 0 or 1, comprising 7 days of the week and holidays.
Weather information
The use of products with high-energy consumption, such as heating, ventilation, and air conditioning systems, is closely related to weather conditions.8,48 Therefore, input variables derived from weather information are commonly used for STLF in numerous studies. 49 The Korea Meteorological Administration (KMA) provides various weather forecasting information, which include temperature, humidity, wind speed, daily maximum temperature, daily minimum temperature, and amount of precipitation data for every region in South Korea as shown in Figure 2. 50

Example of weather forecasting by KMA.
We use the aforementioned weather variables in this study. However, since the weather forecasting information is collected at 3-h resolution unlike electric load data, it is difficult to apply the forecasting model directly. In order to make the same time resolution of energy consumption, the weather forecasting information is estimated at 30-min resolution using linear interpolation. In particular, to establish a more direct association with energy consumption, we calculate the discomfort index (DI) 51 and wind chill (WC) 52 with equations (8) and (9), respectively. Then, we use these calculated values as input variables


where T and H are the temperature and the humidity, respectively, and WS is the wind speed. Hence, we use eight weather variables (i.e. temperature, humidity, wind speed, daily maximum temperature, daily minimum temperature, amount of precipitation, DI, and WC) for building STLF models.
Historical electric load
Electric load forecasting models aim to forecast day-ahead electric loads. In addition to the 24 input variables described earlier, we also use recent historical electric loads as input variables to reflect recent trends in energy consumption. To predict one point in the day later, we consider a total of 98 input variables as the 30-min electric load data and holiday information of the previous 2 days. 16 Figure 3 shows an example of historical electric loads of Type A as input variables. For instance, if the forecast time is 4:00 p.m. 4 January, we then use 96 historical load data (2 measurements/h × 24 h/day × 2 days) from 4:30 p.m. 1 January to 4:00 p.m. 3 January and two-holiday information (same point of previous 1 and 2 days) from 2 January to 3 January.

Example of historical electric load as input variables.
As mentioned earlier, we consider 120 input variables; however, they have different scales. For smoothing the imperfection of ANN training, normalization is required to place all inputs within a comparable range. Therefore, we performed minimum–maximum normalization to all input variables 16 as follows

ANN-based energy forecasting modeling
An ANN, which is also known as an MLP, is a type of machine learning algorithm that is an FFNN architecture with an input layer, one or more HLs, and an output layer. 53 Each layer comprises a number of nodes. Each node receives values from nodes on the previous layer, determines its output, and passes it to nodes on the next layer. As this process is repeated, the nodes of the output layer provide the desired values. Figure 4 shows a typical ANN structure for STLF.

ANN structure for short-term load forecasting.
The HL has numerous factors that affect the performance of the network, including the number of layers and nodes and the activation function of the nodes. Therefore, the performance of the network is dependent on how the HLs are configured. In particular, the number of HLs determines the depth or shallowness of the network. For instance, when the number of HLs is two or more, the network is a so-called DNN.32,33 Typically, an increase in the number of HLs is known to improve network performance. However, the increase could cause problems such as overfitting on the training data or difficult generalization on the new data. 43 In this case, the accuracy of the prediction decreases. Therefore, it is essential to determine the correct number of HLs to solve the given problem.
A sigmoid function has been an excellent activation function in NNs. However, it has a significant disadvantage, the so-called vanishing gradient problem. 34 The values of a sigmoid function fall within the range [0, 1] and, because of its nature, small and large values passed through the function will become close to zero and one, respectively. This means that its gradient will be close to zero and learning will be slow. As ReLU was proposed as an activation function to solve the vanishing gradient problem, 38 numerous other activation functions have been proposed including LReLU, PReLU, ELU, and SELU, which will have described in more detail in the following section.
Activation function
In numerous studies on the ANN-based STLF, the most fundamental ANN structure had one HL, and sigmoid functions were typically used.21,23,25,26,29 However, DNNs have been consistently adopted in numerous real-world applications because of their high predictive power,38,41 and ReLU has been used when the number of HLs was two or more.32–35 However, using ReLUs can cause the following two problems: it can result in deactivated neurons and the learning can be slow. To solve these problems, diverse activation functions have been introduced, including LReLU, PReLU, ELU, and SELU. There are numerous cases of performance comparisons of activation functions in several fields. However, there are insufficient cases in the field of STLF, and to consider all the data is time-consuming. We consider five activation functions shown in Figure 5, which have been used before for constructing STLF models.

Plots of five activation functions.
ReLU
This is one of the most popular activation functions because it can solve the vanishing gradient and overfitting problems.38,40 Therefore, it allows for effective training of ANN architecture and can be defined as follows

Leaky rectified linear unit
Leaky rectified linear unit (LReLU) allows a small, non-zero gradient when the unit is not active. 38 If ReLU is used as the activation function, a number of neurons might not be activated, which could lead to poor results. By using a non-zero gradient, we can alleviate this type of problem and improve the training speed. LReLU can be defined as follows

Parametric rectified linear unit
The parametric rectified linear unit (PReLU) is inspired by LReLU. It increases the learning speed by not deactivating a number of neurons. 39 Compared to LReLU, PReLU substitutes the non-zero gradient values by a parameter α, as shown in the following equation

Exponential linear unit
The exponential linear unit (ELU) is another type of activation function based on ReLU. As in other rectified units, ELU speeds up the learning and alleviates the vanishing gradient problem. 40 As the shape of the function is smooth, the learning speed is faster than when the neuron is deactivated or has a non-smooth slope. The equation for the ELU is as follows

Scaled exponential linear unit
The scaled exponential linear unit (SELU) activation function is a type of ELU that uses two parameters. Learning by using two parameters improves the performance of a model because the variance of the activation function is constant. 41 As SELU also has a smooth slope, its learning is fast. The equation for the SELU is as follows

where, α, which is about 1.67326, is a stochastic variable sampled from a uniform distribution at training time and fixed to the expectation value of the distribution at test time. λ is an extra parameter involved, which is about 1.0507.
Other hyperparameters tunings
We construct ANN-based load forecasting models using all possible combinations of HLs from 1 to 10 together with activation functions. We consider five activation functions, including ReLU, LReLU, PReLU, ELU, and SELU. From the studies by Heaton 53 and Sheela and Deepa, 54 the number of hidden neurons should be 2/3 the size of the input layer, plus the size of the output layer. Therefore, we use 81 nodes for our forecasting model. In addition, we used Xavier initialization55,56 to sort initial weights for individual inputs in a neuron model. When constructing an ANN model, two important hyperparameters are the learning rate and learning epoch. 57 Learning rate indicates how much the weights of the network are adjusted with respect to the loss gradient.37,57 If the learning rate is too large, the average loss will increase. 54 Conversely, if the learning rate is too small, it might take a long time to converge the performance goal due to more exploration in the parameter space. 52 Learning epoch indicates the period that the network learns all training data once. 32 As the number of epochs increases, the weights are changed accordingly in the NN and the learning curve goes from underfitting to optimal and eventually to overfitting. 57 However, since the network is overly focused on the training data, it could show low performance for unseen data. As with the learning rate, increasing the number of epochs requires a longer time to converge the performance goal. To construct more accurate learning model, we used a learning rate of 0.000001 and learning epoch of 10,000 based on our previous experiences with these hyperparameters. 58 In addition, we set the batch size to 144 and used the RMSProp optimizer 59 and Huber loss function, which is less sensitive to outliers than the mean square error (MSE) loss function. 56
Experimental results
Data description
For the experiments, we performed preprocessing for the dataset in the Python environment and performed forecast modeling using TensorFlow. 60 Table 5 presents the statistics of the building electric energy consumption data. The electric load data were collected from 1 January 2015 to 31 December 2016. In order to obtain sufficient prediction results for each forecasting model, we set the ratio of the dataset to the training (in-sample) and test (out-of-sample) sets at approximately 50:50. Among them, we used electric load data from 1 January 2015 to 3 January 2015 to configure input variables for a training set. The data from 4 January 2015 to 3 January 2016 were used as a training set, and 4 January 2016 to 31 December 2016 were used as a test set.
Statistics of building energy consumption data.

Performance measurement
To compare the performance of forecasting models, we used a coefficient of variation of the root mean square error (CVRMSE) and MAPE, which are easier to understand than other performance metrics such as RMSE or MSE because they represent accuracy as a percentage of the error. However, it is known that CVRMSE and MAPE increase significantly when the actual value tends to zero.
10
The CVRMSE and MAPE equations are shown in equations (16) and (17), respectively, where


Comparison of activation functions
Tables 6–10 present the forecasting results when different numbers of HLs and activation functions for five building types are used. It can be seen that building type B exhibits poor prediction accuracy compared to the other building types. This is because its electric loads are close to zero. In order to confirm the overall prediction performance of the activation functions, we present the averaged accuracy of the activation functions for different building types with the best accuracy in bold. A cooler color (blue) indicates a lower CVRMSE/MAPE value, while a warmer color (red) indicates a higher CVRMSE/MAPE value for each activation function in building types. As can be seen in the tables, ANN models with one HL generally have poor predictive performance.
Comparison of CVRMSE and MAPE for building type A.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; HL: hidden layer; ELU: exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
Bolded values represent the best values.
Comparison of CVRMSE and MAPE for building type B.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; HL: hidden layer; ELU: exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
Bolded values represent the best values.
Comparison of CVRMSE and MAPE for building type C.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; HL: hidden layer; ELU: exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
Bolded values represent the best values.
Comparison of CVRMSE and MAPE for building type D.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; HL: hidden layer; ELU: Exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
Bolded values represent the best values.
Comparison of CVRMSE and MAPE for building type E.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; HL: hidden layer; ELU: exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
Bolded values represent the best values.
Tables 11 and 12 present the averaged CVRMSE and MAPE results of the activation functions and rank of activation functions for different building types. It can be seen that SELU and ELU exhibit the best and worst performances in bulk of the cases, respectively. ANN models with SELU repeatedly exhibit a higher frequency than other activation functions. Herein, we provide reasoning on why the ANN models with SELU show better prediction performance as follows. 41
Compared with ReLU, SELU solves the problem of off-state as zero gradients by passing negative values to the next layer. This enables SELU to train deep NNs effectively because there is no vanishing gradient problem.
Unlike LReLU and PReLU, the shape of SELU function shows a continuous curve when x < 0 by using an exponential function. Due to this function, a gradient can get close to 0, which can shift the mean of each layer’s output values to 0. Since this enables SELU to have a superior self-normalization quality, SELU can be trained faster and better than other activation functions that are combined with batch normalization.
SELU is an activation function that multiplies ELU by λ > 1 to ensure the gradient greater than 1. To adjust the variance of each layer’s output values effectively, two regions are required: one with a gradient larger than 1 and the other with a gradient close to zero. Since SELU function satisfies these two conditions by multiplying ELU by λ, it shows better performance than ELU.
Average CVRMSE and rank of activation functions (the best in bold).

CVRMSE: coefficient of variation of the root mean square error; ELU: exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit
Average MAPE and rank of activation functions (the best in bold).
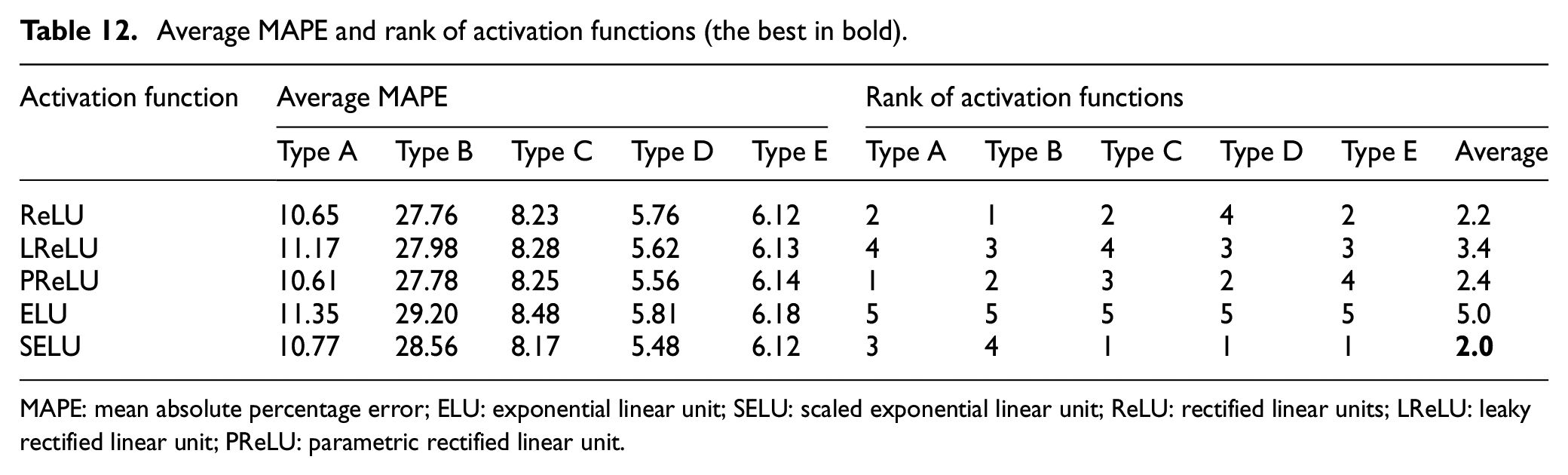
MAPE: mean absolute percentage error; ELU: exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
Comparison of number of HLs with SELU
In the previous section, we showed the excellent performance of SELU. Therefore, in this section, we focus on the effect of the number of HLs. Tables 6–10 show the prediction performance of all activation functions depending on the number of HLs. However, as the ranges of the performance measurement values are too diverse for each building type, it is not appropriate to calculate their average for performance comparisons. Therefore, we counted the rank of the number of HLs by building types and presented these results with CVRMSE/MAPE values of the SELU in Tables 13 and 14, respectively. A cooler color (blue) indicates a lower CVRMSE/MAPE value for each building type, while a warmer color (red) indicates a higher CVRMSE/MAPE value for each building type.
CVRMSE results of the number of hidden layers for SELU.

CVRMSE: coefficient of variation of the root mean square error; SELU: scaled exponential linear unit.
MAPE results of the number of hidden layers for SELU.

MAPE: mean absolute percentage error; ELU: exponential linear unit; SELU: scaled exponential linear unit
The average ranking values of all CVRMSE and MAPE values for each number of HLs are shown in Figure 6. In the figure, the SELU model with five and six HLs exhibits the lowest average ranking values of CVRMSE and MAPE, which indicate excellent prediction performance, respectively.

The average ranking value of number of hidden layers for SELU.
In order to demonstrate that ANN with SELU and five HLs is the most effective, we represented average ranking values and ranking of these values, by considering CVRMSE and MAPE values for each building type as shown in Tables 15 and 16, respectively. In Table 15, a cooler color (blue) indicates a lower CVRMSE/MAPE value, while a warmer color (red) indicates a higher CVRMSE/MAPE value. Clevert et al. 40 concluded that ELU leads not only to faster learning but also to significantly better generalization performance than ReLU and LReLU on networks with more than five layers. SELU is some kind of ELU due to the constant factor α. As a result, Tables 15 and 16 show that significant values for ANN with SELU obtained on networks with more than five layers. In addition, an ANN with SELU and five HLs was found to be the best.
The average ranking value of CVRMSE/MAPE values for each building type when the different number of hidden layers and activation functions are used.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; ELU: Exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
The average ranking value of CVRMSE/MAPE values for each building type when the different number of hidden layers and activation functions are used.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; ELU: exponential linear unit; SELU: scaled exponential linear unit; ReLU: rectified linear units; LReLU: leaky rectified linear unit; PReLU: parametric rectified linear unit.
Comparison of prediction performance via statistical techniques
To verify the validness and applicability of the ANN model with SELU and five HLs, we compare the predictive performance of the ANN model with other statistical techniques such as Persistence, moving average (MV), ES, and multiple linear regression (MLR). Persistence model assumes that the conditions at the predicted value (48-step ahead) are the same as the current values, which has good accuracy due to the highly periodic characteristic of energy consumption.20,31 The MV method is commonly used to smooth out short-term fluctuations and highlight longer-term trends for time series data. While the MV method gives equal weights to include values, the ES method assigns exponentially decreasing weights as the observation get older, a more reasonable approach. Based on previous electric loads only at the same point, we set to 2 (interval) and 0.3 (attenuation factor) for constructing MV and ES methods, respectively. 17 MLR is used to determine a mathematical relationship among a number of random variables. In other terms, MLR examines how multiple input variables are related to one output variable. We set to 120 input variables applied by ANN models for MLR model construction. We compared the prediction performance of five methods, by considering the test periods and learning model in the same environment. As shown in Table 17, the ANN model has the best prediction performance.
CVRMSE/MAPE values when the statistical techniques and ANN with SELU and five hidden layers are used.

CVRMSE: coefficient of variation of the root mean square error; MAPE: mean absolute percentage error; ANN: annual neural network; SELU: scaled exponential linear unit; MV: moving average; ES: exponential smoothing; MLR: multiple linear regression.
Bolded values represent the best values.
Conclusion
In this study, we constructed diverse ANN models using different numbers of HLs and diverse activation functions and compared their performances in a 30-min STLF resolution. We considered ReLU, LReLU, PReLU, ELU, and SELU as activation functions, and the number of HLs from 1 to 10. To compare the prediction performance with two hyperparameters for the STLF model, we considered electric load data collected from five different types of buildings for 2 years, and two performance metrics, CVRMSE and MAPE. The experimental results indicated that an SELU-based model with five HLs exhibited better average performance than other ANN-based STLF models. In order to apply for every building, our proposed model is sufficient as a baseline model due to simply input variables and model configuration. In addition, our proposed model can be used to predict several time-resolution building energy consumptions in the future. For instance, if an hourly building electric energy consumption forecasting model is constructed, the input variables can be constructed by applying equations (2)–(7) in the calendar information and the rest as described earlier (14 time factors, 8 weather information, and 50 historical electric loads holiday information). Then, 49 hidden nodes can be used for constructing an SELU-based model with five HLs. Otherwise, if a 15-min interval building electric energy consumption forecasting model is constructed, the input variables can be constructed by applying equations (1)–(7) in the calendar information and the rest as described earlier (14 time factors, 8 weather information, and 194 historical electric loads holiday information). Then, 145 hidden nodes can be used for constructing an SELU-based model with five HLs.
Although we have proposed a typical building electric energy consumption forecasting model, a more accurate forecasting model can be constructed by adding new input variables that can reflect the characteristics of target building energy consumption. In addition, tuning of other hyperparameters in the SELU model can expect to improve prediction performance for the target building.
In future studies, we plan to collect additional datasets and perform experiments to investigate the robustness of our results. In addition, we will build a more sophisticated forecasting model such as multi-step ahead or probabilistic load forecasting, considering other external variables that are closely related to electric loads.
Footnotes
Handling Editor: Pascal Lorenz
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by the Korea Electric Power Corporation (grant number: R18XA05) and in part by Energy Cloud R&D Program (grant number: 2019M3F2A1073184) through the National Research Foundation of Korea (NRF) funded by the Ministry of Science and ICT.