
Abstract
Large and dense mobile ad hoc networks often meet scalability problems, the hierarchical structures are needed to achieve performance of network such as cluster control structure. Clustering in mobile ad hoc networks is an organization method dividing the nodes in groups, which are managed by the nodes called cluster-heads. As far as we know, the difficulty of clustering algorithm lies in determining the number and positions of cluster-heads. In this article, the subtractive clustering algorithm based on the Akaike information criterion is proposed. First, Akaike information criterion is introduced to formulate the optimal number of the cluster-heads. Then, subtractive clustering algorithm is used in mobile ad hoc networks to get several feasible clustering schemes. Finally, the candidate schemes are evaluated by the index of minimum of the largest within-cluster distance variance to determine the optimal scheme. The results of simulation show that the performance of the proposed algorithm is superior to widely referenced clustering approach in terms of average cluster-head lifetime.
Introduction
A mobile ad hoc network (MANET) is a self-organizing and self-configuring multi-hop wireless network consisting of a group of mobile nodes which can move freely and mutually cooperate to send relaying packets on behalf of one another. 1 The nodes of MANET have to be collaborated and organized to offer both basic network services as routing and management for security. Now, due to the convenience of MANET settings and its developments, the scale of MANET is unimaginably increasing and the performance of the network is degrading. As a key issue of MANET and its applications, the importance of the clustering can be summarized in two aspects. 2 First, clustering is the most efficient method to manage hundreds of mobile nodes to solve the scalability problems faced in the flat network infrastructure as the network scale increases. Second, clustering serves as the foundation for many other key issues in MANETs, such as routing intrusion detection, topology control, backbone construction, and so on, 3 which are all well performed based on an appropriate clustered network structure.
The objective of clustering in MANETs is to divide all nodes into groups, which are exclusive and any instance of the network is belonged. 4 . Cluster-heads are special nodes responsible for the formation of clusters including maintenance of network topology and allocation of nodes in the cluster. 5 Due to the dynamic nature of the mobile node, the configuration of the cluster-heads is constantly changing, and in order to save resources, it is necessary to minimize the number of cluster-heads. The main concept of clustering is to establish a hierarchy between nodes, and the clusters of network are connected whenever one node in a cluster is directly connected to another node in another cluster at least. The difficulty of clustering lies in how to determine the number and positions of cluster-heads optimally, 6 which is a non-deterministic polynomial-time (NP)-hard problem. 7 In this article, Akaike information criterion (AIC) is proposed to calculate the optimal clustering number, then a theoretical analysis is made for solving the contradiction between compactness of clustering and the increased number of cluster-heads.
The organization of this article is as follows. Related works are reviewed in section “Related work.” Subtractive clustering algorithm based on Akaike information criterion (SCAA) in MANETs is proposed and described in detail in section “SCAA.” The simulations conducted to evaluate the performances of SCAA and lowest ID clustering method are presented in terms of average cluster-head lifetime in section “Simulation.” Finally, the conclusion and the future work of the research are outlined in section “Conclusion.”
Related work
Most centralized clustering algorithms proposed for MANETs are typically aiming to determine the number and position of cluster-heads to prolong network lifetime. 8 Clustering algorithms can be divided into the following categories: partitioning methods, hierarchical methods, graph-based methods, density-based methods, and grid-based methods. In previous research work, the lowest ID and its variants are the most commonly used in many research papers, in which distinct ID is assigned to each node; 9 if a node has the lowest ID of all the neighbors directly connected, then it is the cluster-head node, otherwise it is an ordinary node; and when two cluster-heads encounter, the one with higher ID should give up its role of cluster-head. The main disadvantage of this algorithm is that it only considers the node ID without the qualification of a node being elected as a cluster-head, and some nodes easily run out of power. 10 The highest connection cluster (HCC) and its variants also are commonly used clustering methods, each node is assigned a degree according to the number of neighbor nodes within its one-hop communication range, the cluster-head is elected by the value of node degree, the disadvantage is that it only considers the number of neighbor nodes without the overall node layout. MAPLE is another clustering algorithm that infers the host mobility by the signal strength received, 11 the election of the cluster-head is mostly a random procedure and without considering node distribution and mobility. 1
The subtractive clustering algorithm (SCA) is an unsupervised clustering method based on automatic extraction rules, 11 which fully considers the distribution and mobility of nodes to determine the rules of cluster-head selection: each node is regarded as a potential cluster-head and the cluster-heads are determined by calculating the density of nodes, whose principle is to consider each node as potential cluster-head, the clustering rules can be automatically determined by calculating the density of nodes. However, there is no theoretical direction on how to choose the optimal subtraction clustering parameters in the fuzzy system. In Kim et al.’s 12 work, the input membership function of the fuzzy neural network is obtained by fuzzy space partition at first, and then the kernel rules of clustering are obtained by the SCA. In Torun and Tohumolu’s 13 work, genetic algorithm (GA) is used to construct compact fuzzy model and to determine the optimum clustering rules by selecting efficient inputs and finding the optimum subtractive clustering radius. In Bagheripour and Asoodeh’s 14 work, the optimal parameters of fuzzy clustering (membership function) are extracted by differential clustering method based on hybrid GA-PSO (particle swarm optimization) technology, and the optimal clustering rules are obtained. In Ghane’i-Ostad et al.’s 15 work, the subtractive clustering method is used to determine the clustering center by probability according to the potential of each data point, and then the clustering rules are determined. In Ahmed et al.’s 16 work, subtractive clustering is used as an optimization tool to determine the optimal number of fuzzy membership functions and obtain the kernel rules of clustering. The effects of subtractive clustering parameters such as squash factor, cluster radius, acceptance, and rejection rate of fuzzy models are discussed. 17 The performance of the model is very sensitive to the cluster radius, while the acceptance and rejection rate have little effect. 18 These above-mentioned works almost study the parameter optimization with prior knowledge of a certain number of cluster-heads. However, the condition of the parameter optimization with unknown number of cluster-heads is rarely considered.
In the above cases, the number of clusters needs to be specified before the optimization initial parameters of clustering algorithm. There are two methods to solve the problem of determining the optimal number of clusters. The heuristic approaches are used in the first method, the number of clusters gradually increases from an initial value to an appropriate threshold by running the clustering algorithm frequently leading to poor flexibility and low computational efficiency. In the second method, the finite mixture models are used to formulate cluster number before the clustering which is more efficient and convenient. Belong to the second method are the AIC and its extended criterion that are widely used to optimize fitting order, model parameter, and sample dimension. In the works of Yunlong and Qi et al., the AIC is used to set the fitting order of resistive-capacitance (RC) model at different state of charge (SOCs) to improve the accuracy and practicability of the model. In Ren Chao’s work, the AIC is used to optimize the parameters of radial basis function (RBF) neural network for global position system (GPS) height fitting to improve fitting accuracy. Extending Akaike’s original work, in the work of Bengtsson and Cavanaugh, 19 AICc with normal errors of linear regression is proposed to adjust AIC propensity to favor high-dimensional models when the sample has a smaller maximum order relative to the model in the candidate class. Song et al.’s 20 work show that under small sample regression conditions, AICc is significantly better than the AIC model and further extended to a Gaussian autoregressive model containing univariate. However, the optimization of number of clusters based on the AIC is rarely researched, especially with the SCA method to divide the nodes in MANETs to prolong network lifetime.
SCAA
Akaike gives an information on theoretical interpretation of the likelihood function and extends it to define a criterion which is used to test the goodness of assumed models. The criterion is known as the AIC, which is used for selecting linear models and other statistical problems widely. In this article, AIC is used to determine the number of cluster-heads for clustering algorithm, the original formula is expressed as follows,
21
where

The network with

The maximum within-cluster deviation

According to the distribution theory of sampling statistics, the likelihood function of the within-cluster deviation with


where
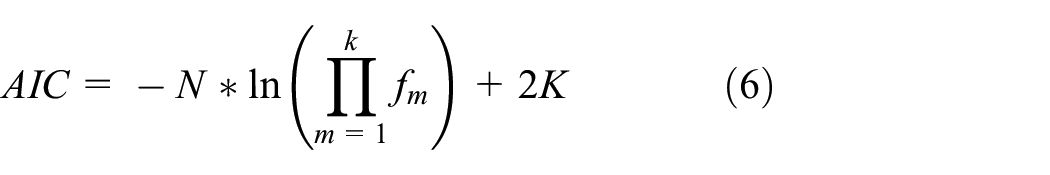


After obtaining the optimal number of clusters
Step 1. As above all, there are

where
Step 2. After calculating the mountain function for each node,

where
Step 3. Repeating Step 2 to calculate the density of each node in the network until
Step 4. Repeating from Step 1 to Step 3 with different combinations of parameters
Step 5. If there are more than one feasible clustering schemes, evaluation index should be established to identify the optimal clustering scheme. For each clustering scheme, every node will be assigned to the nearest cluster-head according to the nearest distance principle, the within-cluster variance

Frame of subtractive clustering algorithm based on AIC.
Simulation
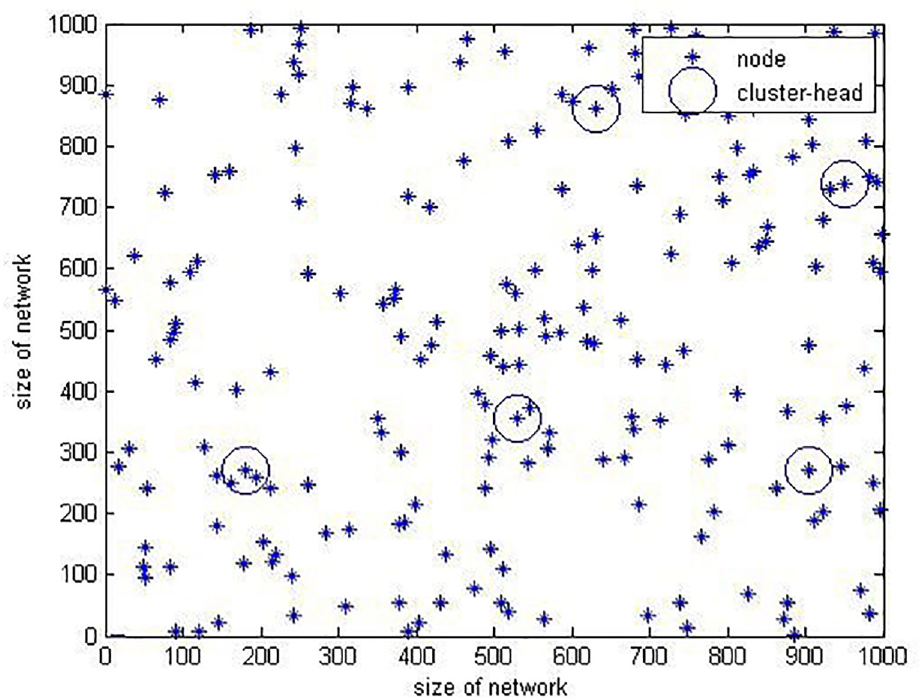
To demonstrate the effectiveness of the proposed algorithm, the SCAA and lowest ID clustering scheme are applied to a

Distribution of network node.
Through equation (6), the AIC value with different number of cluster-heads from 1 to 8 are calculated, the result is shown in Figure 3, the optimal number of cluster-heads is

AIC index of different numbers of cluster-heads.
Applying SCAA,
Clustering schemes.


SCA parameters of different numbers of cluster-heads.
From Table 1, the first clustering scheme with the maximum within-cluster variance is the worst scheme

The first clustering scheme.

The second clustering scheme.

The third clustering scheme.
The fourth clustering scheme.

The fifth clustering scheme.

The sixth clustering scheme.
There are two aspects to analyze Figures 5–10. The first is the distance between the cluster-heads, and if two cluster-heads are too close, it may cause significant difference of the cluster-members. The second is the distance from the cluster-head to the boundary, and if the cluster-heads are too close to boundary, it may cause great pressure to the data communication in the cluster and network. Therefore, the sixth clustering scheme is more reasonable than other clustering scheme.
The optimal scheme obtained by SCAA is more stable and reliable, that can reduce the time sending data to the base station of each node and the number of nodes to participate in the channel competition for saving the network energy consumption and prolonging the survival time of the network. Mean lifetime of cluster-heads, also known as cluster lifetime is calculated by cumulating the duration of nodes being cluster-heads and dividing the total number of cluster-heads in one simulation run. A longer mean lifetime implies a longer period of time a cluster may exist. In network simulation, the initial energy of the cluster-head node is set as 1 J, the energy consumption of nodes for receiving information and sending information obeys the first-order energy consumption model, the mean cluster lifetime after 500 business simulation is shown in Figure 11 with four kinds of clustering schemes.

The mean cluster lifetime of different clustering schemes.
As shown in Figure 11, with the increase of business time, the energy of network is declining. The clustering effect influences the network energy consumption, the network divided with the best clustering scheme (SCAA) has the slowest energy consumption, the network with fourth clustering scheme is superior to first clustering scheme, which is the same as the evaluation of clustering scheme based on the criterion of minimizing maximum distance variance within-cluster, and all the networks divided with SCA clustering scheme are better than the conventional lowest ID clustering method. Therefore, the SCAA protocol can logically divide the network independent of priori knowledge, which makes the bottleneck cluster-head energy security and improve the network survival time effectively.
Conclusion
An improved SCAA is proposed for MANET in the article, first, the AIC is used to calculate the optimal number of cluster-heads, and then SCAA clustering model is established to select the optimal clustering scheme using the minimum maximum within-cluster variance as the evaluation index, and finally, the simulation results show that the network divided by the clustering algorithm proposed can reduce the energy consumption and can improve the network lifetime more effectively than the classical clustering algorithm.
Footnotes
Handling Editor: Sergio Toral
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the support of the Zhejiang provincial Public Welfare Technology Application and Research Projects of China (LGF18F010005 and LQ18F030006).