
Abstract
We proposed an approach for temporal event detection using deep learning and multi-embedding on a set of text data from social media. First, a convolutional neural network augmented with multiple word-embedding architectures is used as a text classifier for the pre-processing of the input textual data. Second, an event detection model using a recurrent neural network is employed to learn time series data features by extracting temporal information. Recently, convolutional neural networks have been used in natural language processing problems and have obtained excellent results as performing on available embedding vector. In this article, word-embedding features at the embedding layer are combined and fed to convolutional neural network. The proposed method shows no size limitation, supplementation of more embeddings than standard multichannel based approaches, and obtained similar performance (accuracy score) on some benchmark data sets, especially in an imbalanced data set. For event detection, a long short-term memory network is used as a predictor that learns higher level temporal features so as to predict future values. An error distribution estimation model is built to calculate the anomaly score of observation. Events are detected using a window-based method on the anomaly scores.
Keywords
Introduction
Social network services (SNSs) such as Twitter and Facebook have been widely used in recent years, and they have become a potential data source for data mining as social sensor. In fact, social networks have come to dominate the daily activities of people (entertainment, online shopping, distance learning, etc.). People use social networks as a means to express their opinions and emotions about what they are experiencing. Due to the natural real-time characteristic of social data, users can be considered social sensors and posted messages (tweets) can be considered the response signals called social data. Although SNS messages posted by Twitter users are short sentences of less than 140 characters, they contain useful information in many contexts, especially in cases of emergency situations. Therefore, these big data from social media can be used as social sensors to explore vital knowledge.
Although social data are the vital source of data for mining events, opinions, or trends, we need to filter out noise or irrelevant data. Any automatic classification system of social media data to extract useful information is faced with a number of challenges, such as the fact that the sentences are short; it is hard to understand the content; and the messages contain abbreviations, lingo, and spelling mistakes. Due to the requirement of noise filtering, many studies introduce the classification of social media messages. There have been several works on detecting or identifying informative messages in a pre-processing phase. Naïve Bayer is an easy technique for text classification that is commonly used in spam detection, 1 recommendation systems, 2 topic detection, 3 finding trending topics, 4 and summarizing social media blogs. 5 In the social context, the support vector machine (SVM) has been used to solve many problems such as opinion mining for the purpose of reviewing user satisfaction with a product 6 or classifying tweet messages to infer trending topics. 7 The main problem involves extracting the features of the linguistic unit and conducting composition over variable-size sequences.8–10
Neural network–based models naturally enable the learning of features that make them more efficient than traditional feature-based methods because of the fact that they have no requirement of complicated feature engineering. Convolutional neural network (CNN)-based methods have achieved impressive results8,11 in sentence level classification. CNN is based on learning distributed representation that is derived by projecting words to lower dimensions and dense vector space. It encodes the semantic and syntactic features of words. 12
An event can be generally defined as a real-world occurrence when it requires unfolding over space and time aspects. 13 Social media–based event detection is associated with increasing numbers of messages related to some topics. Therefore, events can be derived from anomaly detection methods. In order to discover temporal features, collected data are processed through two approaches: contents of message14–18 or features (handcraft generator or learned feature).19–21 In particular, keyword-based pre-processing is often used to focus on event data. Several studies have attempted to use discrete signals to find high frequency or “burst” features in time series data.19,20,22–24 He et al. 25 use features associated with power spectrum and periodicity to group keyword signals. A discrete Fourier transformation (DFT)-based method involves finding the peak in the frequency domain, while Weng and Lee 26 use a wavelet transformation. For situations involving disasters, Avvenuti et al. 22 and Nguyen et al. 24 use a burst detection algorithm based on the occurrence of a larger number of events within some time window. Sakaki et al. 27 use a temporal model considering the number of event-related tweets as an exponential distribution. The exponential distribution occurs naturally when describing the lengths of the inter-arrival times in a homogeneous Poisson process.
In this article, we propose an approach that automatically identifies informative messages on social sensors by taking advantage of neural network techniques. It learns text features from embedding vectors. An improved version of the standard CNN on diverse word embedding is introduced in order to overcome the shortcomings of CNN-based methods, which use multichannel word embedding. Standard multiple word embeddings appear as separated channels red, green, and blue (RGB) in image processing. Since the standard approach of diverse word embeddings requires the same dimension, it is not convenient when we use pre-trained word embeddings from different corpora. As we directly work with the noisy environment as the social network, our approach of filtering “non-informative data” to obtain “informative data” for event detection is necessary. In the scope of event detection, there are many traditional methods for this task, but feature-based methods require complicated feature engineering.19,20,22,27 In this article, we introduce a way to take advantage of both CNN on word embedding and variable sizes of multiple embeddings under the classifier in order to identify informative messages.
In our work, there is no limit to either the types of embeddings or the number of embeddings. The contributions from the improved CNN are as follows: (1) it overcomes the limitation of multichannel embeddings requiring the same dimension. Therefore, it is easy to implement in terms of training models and practical applications due to the availability of pre-trained word embeddings for use. (2) The multi-word embeddings-based approach is investigated in order to explore sentence features. These show an improved performance of the classifier as compared to the baseline methods. (3) It does not require complicated feature engineers, as do traditional machine learning methods.
In order to detect the temporal occurrence of the considered event, we accumulate topics related to informative messages in order to transform them into time series data. The time series data is analyzed by long short-term memory (LSTM)-based 28 event detection approach. An error distribution estimation model is employed to calculate the anomaly score of the observations. A window-based method is used to detect events with the anomaly score. This approach also performs well on many context applications, where balanced data are not always available and real-time disaster event detection is required. We conducted experiments on earthquake data set to obtain the time response.
The rest of the article is organized as follows: the section “Related works” provides a brief discussion of the background and related works, including text classification and event detection in social network data. Section “Proposed approach” focuses on our proposed approach with multiple word embeddings for sentence-level classification and the LSTM recurrent neural network (RNN) for event detection. Then, the experiments on the benchmark data set as well as earthquake signals are conducted in the section “Experimental results” so as to evaluate the performances. We presented the general architecture of the Hadoop-based event detection system as well. Finally, the section “Conclusion” describes the conclusion and future works.
Related works
There have been some attempts to use social network data to detect events such as trends, opinions, or disasters. For example, Sakaki et al. 27 mined Twitter data for the purpose of real-time earthquake detection and to send warnings faster than the Japan Meteorological Agency. This system used a SVM classifier to remove irrelevant tweets, and a probabilistic model was constructed for temporal analysis. The Poisson process is the core of the temporal model, which is used to estimate the time moment as the earthquake happened in real time. Chatfield and Uuf 29 used Twitter data involving the context of the three earthquakes that occurred at the Sumatra coast, Indonesia from 2010 to 2012. Avvenuti et al. 22 developed a system for earthquake data in Italy. It initially considered both tweets and replies from Twitter. In order to filter out irrelevant information, a classification-based sophisticated filter was employed on uniform resource locator (URL), mentions, words, characters, punctuation, and slang/offensive words. For temporal analysis, they created a burst detection method, which observed the number of messages in time windows. The limitations of Sakaki et al. 27 and Avvenuti et al. 22 are that some set of features for input must be predefined. Therefore, the performances of these detection systems depend on how strong features are collected.
CNN has become a popular technology for solving classification tasks. The intuition behind CNNs is that the convolutional layer can automatically learn a better representation of text data, and the fully connected layers finally classify this representation based on a set of labels. It can also be more generic and adaptive to domain and context with the support of embeddings that represent each word as a dense vector. Recently, word embeddings have been exploited for a sentence classification task using CNN. Kim 8 reports a CNN architecture on top of the pre-trained work vector that is static (fixed input) or non-static (tuned during training) for specified tasks: sentiment analysis and question classification. It presents multichannel representation and a variable-size filter. However, it uses two copies of a single version of pre-trained embeddings with initial parameters so as to prevent overfitting. Yin and Schutze 12 show the feeding of multiple word embeddings as separated channels, similar to RGB channels in image processing. This architecture works well on multi-sentence classification. However, it requires additional mutual learning and the embeddings to have the same dimensions; the latter is a limitation on using more than one pre-trained embedding, since pre-trained embeddings can vary widely in dimension.
Chen et al. 30 and Nguyen and Grishman 31 address the problems related to the event detection in sentence levels using a CNN based on word embeddings. While Nguyen and Grishman 31 use a CNN based on multiple channels (word embedding, position, and entity) to identify the event trigger, Chen et al. 30 argue that a sentence may contain two or more events and propose an architecture using a dynamic multi-pooling layer according to event triggers and arguments in order to extract more crucial information. In contrast to the above works, in this research, we investigated a CNN approach over multi pre-trained word embeddings to support the pre-processing stage in event detection. Our architecture is also inspired by the use of various region windows of convolutional filters to learn features well when bigram-, trigram-, or five-gram-based features are considered simultaneously.
Many studies employ burst detection algorithms24,27,32 to observe event-related messages so as to verify the occurrence. Unexpected growth in the frequency of messages associated with a category of an event can refer to happening. As in Avvenuti et al., 22 the sensitivity of the event system is interfered by the noise generated from non-informative messages. In order to tackle this problem, classifiers are adopted as a necessary pre-processing stage. For the temporal model in event detection, an event is considered as an anomaly from normal time series data.
Proposed approach
In this section, we introduce the deep learning–based event detection system, which consists of an improved CNN classifier to identify informative messages and an LSTM-based event detection method, which are shown in Figure 1.

Overview architecture of our approach.
CNN
In CNN, local convolution operation is performed over inputs (e.g. image, embedding features matrix, etc.). As shown in Figure 2, we begin with a tokenization task to convert input sentences into a sentence matrix. The standard CNN learns from observed data which are in the form of a word vector representation of each token of the input sentence, expressed as
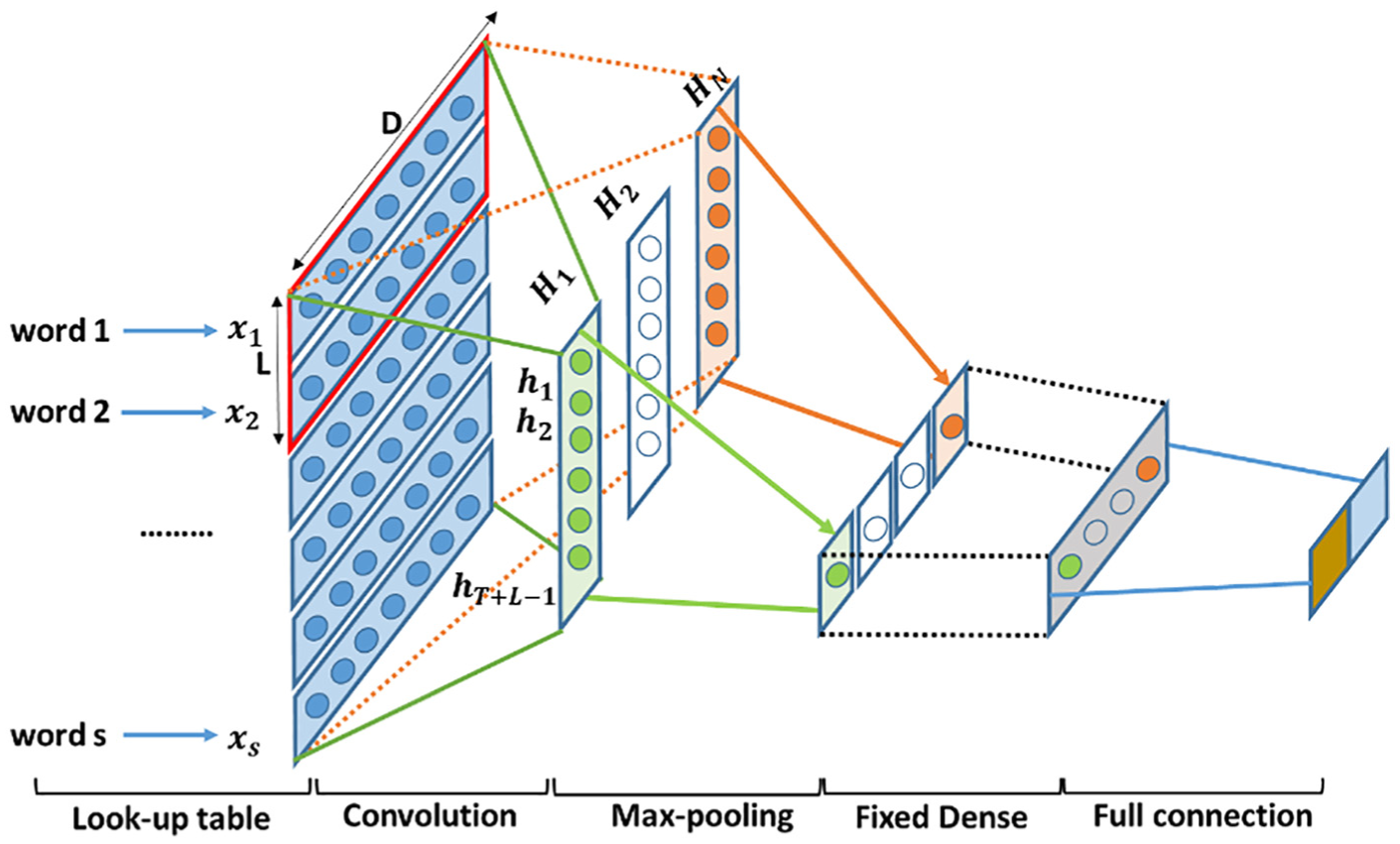
Standard CNN on text classification.
Because text sentences are sequences of words, every full sentence is represented via concatenated rows. It uses filters with widths equal to the size of the word embedding vector. However, these filters correspond to the different sizes of the vertical local region

where
The CNN-based model uses multiple filters for the same region to learn complementary features from the same context of sentences. Multiple kinds of filters associated with different sizes L can be used, and for each filter size, there are N different filters.
The size of the feature map of each filter depends on the input sentence length as well as the height of the considered filter, so 1-max pooling operation is selected to apply to each feature map. As a result, the largest number is extracted as equation (2)

where
Improved CNN with concatenation of multiple word embeddings
The multichannel idea and variable-size filters are proposed by Kim. 8 However, it just uses a single version of pre-trained embeddings that are initialized with two copies (each considered a channel). One is kept stable, while the other is fine-tuned by the backpropagation algorithm during training. Inspired by the multichannel, we developed this idea with the support of diverse embedding version. With an idea similar to that of the diverse version, Yin and Schutze 12 also propose a method, namely multi-view convolutional neural network (MVCNN), to classify text sentences. Although different word-embedding versions are used as separated channels, it still requires the same dimensionality on input embeddings.
In order to satisfy this requirement, the word embedding should be trained on the same model or same corpus. This is not convenient, as we want to use pre-trained word embeddings, which are often available for downloading. Furthermore, such a model seems very complex to interpret, since it requires a mutual learning phase as a trick to enhance its performance. Therefore, we proposed a method to solve the limitations with the architecture shown in Figure 3. It is easy to implement, and it retains the idea of the variable-size filter of convolution operation.
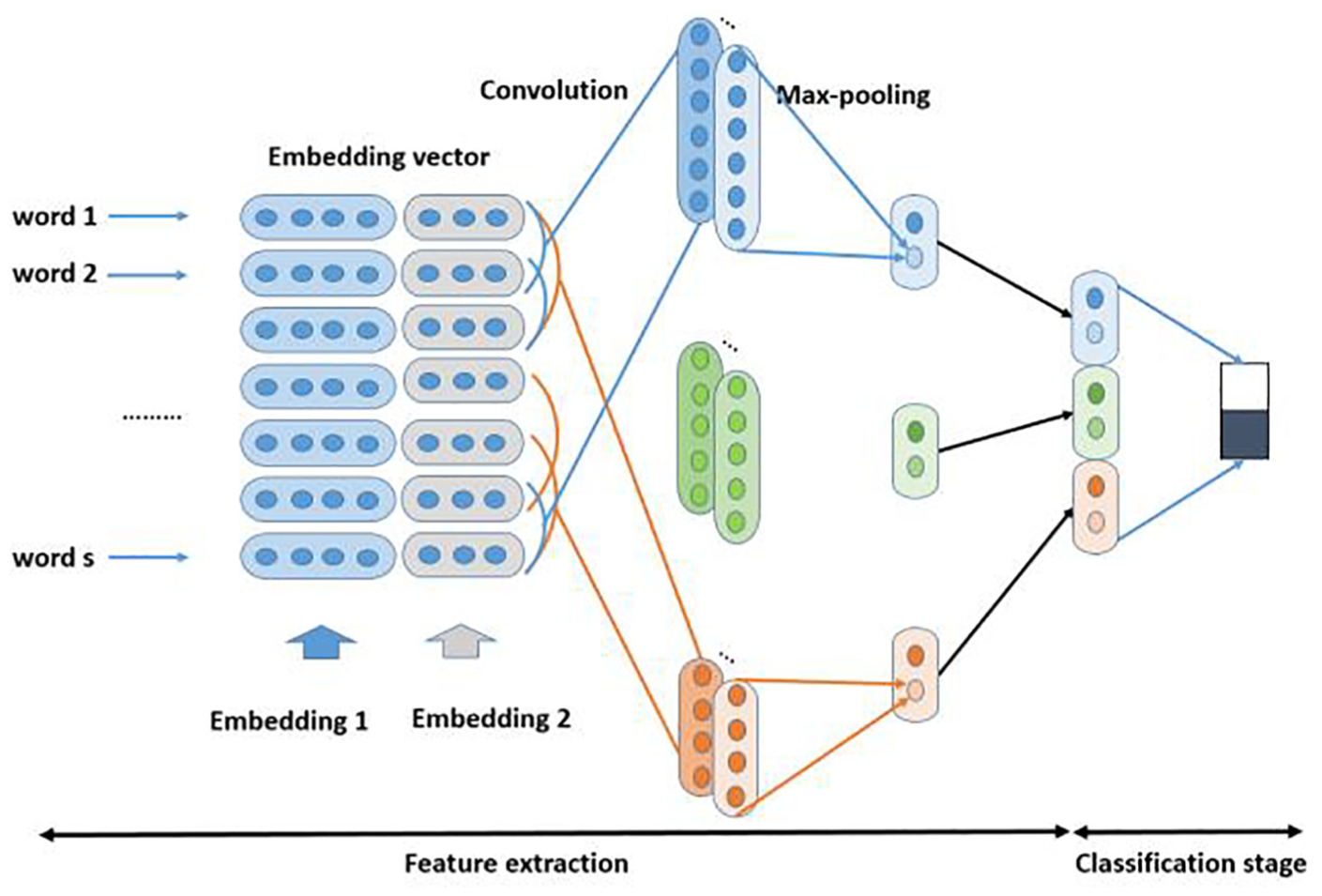
Proposed CNN on multiple word embeddings: concatenated at embedding layer.
The performance of the sentence classification can be affected by the input representation, called word embeddings. Kim
8
shows that the multichannel CNN architecture would prevent overfitting in the case of small data. We propose an improved CNN-based classifier with the support of concatenating multiple word embeddings in the input layer. Figure 3 is a visualization of the use of multi-word embedding CNN based on concatenation at the embedding layer. Assuming that we have
Pre-trained vectors may not always be available for specific words (either in embeding1, embedding2, or both); in such cases, it is optimal that a missed vector for rare words can be supplemented by the sub-vector of others. Unfortunately, in the worst case, we have to randomly initialize them. In particular, for a common word, frequent tokens can have many representations in the embedding layer, instead of only representations. This situation leads to more available information that can be extracted by filters for improving performance at the classification layer.
Applying multi-word input embeddings to the sentence classification task has some advantages. 12 For example, a frequent token can have more representations in input matrix or learned features on the penultimate layer, instead of only one. This means we can obtain more available information. Even though a rare token is missed in some embedding versions, it will be supplemented by others. Our architecture contributes to the development of a diverse version of pre-trained word embeddings and extracting features of sentences with many variable-size convolutional filters.
LSTM-RNN-based event detection
The LSTM architecture is an improved version of the RNN which solves the vanishing gradient problems in RNN. Recently, the use of a recurrent network to form a predictable model or classification model on time series data sets has become popular. LSTM is the core part of our event detection system, which feeds input data underlying time series form. It is capable of predicting several time points ahead (the future data) using input data (the past and the current data).
In this article, the trained model is used to compute the distribution of prediction error as a Gaussian distribution (normal). The prediction error model verifies the likelihood of anomaly (event) behavior. Our approach offers several advantages in that these networks do not require knowledge of abnormalities, handcrafted features, or pre-processing such as fast Fourier transform 25 or wavelet transform. 26
Consider a time series data

The function
Similar to Malhotra et al.,
37
the normal time series are divided into four sets of sequences, namely,

Proposed LSTM-RNN-based predictor model for event detection algorithm.
The architecture is composed of three LSTM layers with the number of LSTM cells as

where P is precision and R is recall on the validate sequences in
In order to detect events in real time, we proposed a real-time event detection algorithm (Figure 5) to deal with the streaming data using the classifier model (improved CNN), the predictor model (LSTM), and the error distribution estimation model (using MLE) from previous parts. We have to transform a textual data set of social sensors into a data set of discrete signals for application of the event detection algorithm, that is, time series data underlying discrete signals, which are accumulated from the output of the classifier. Values are the frequency of informative SNS messages in the given interval. Our problem is similar to the anomaly detection of time series signal, in which disaster event detections are experimented.
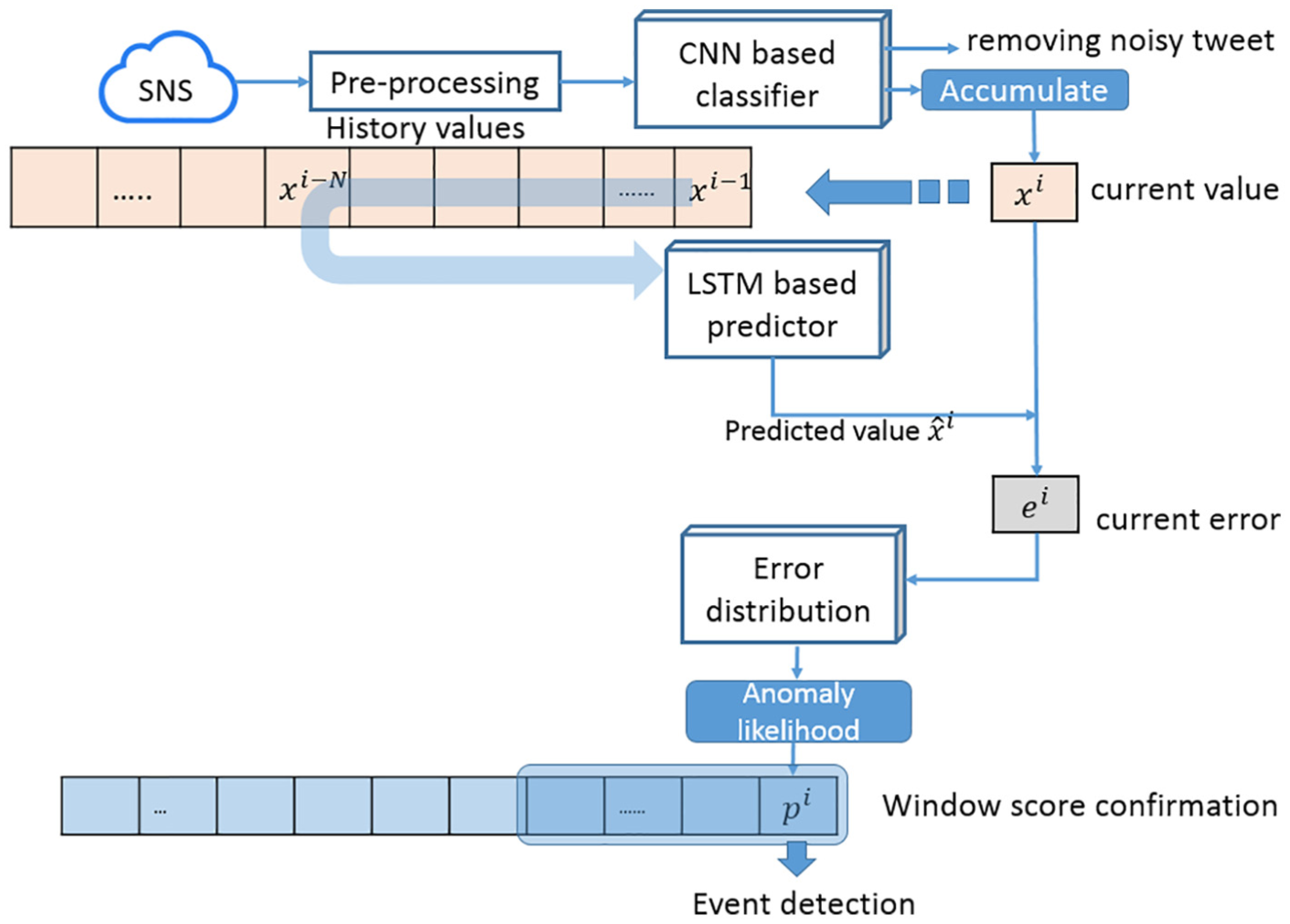
Workflow for real-time event detection.
Algorithm 1 is the real-time event detection algorithm, in which we use both the prediction model and error distribution model to detect temporal information of events. Before running the real-time event detection, the LSTM-RNN-based predictor model and error distribution model are trained as described. Informative data are verified by multi-word embedding CNN, and these signals are then approached with the window-based method to be transformed into time series data (sliding window = time interval

Experimental results
Data set
In order to evaluate the performance of our approach using a CNN on multi-embedding for identifying informative disaster messages from a social network, we used public data sets from the CrisisLex Project 38 and CrisisNLP project, 39 in which data are manually annotated by crowdsourcing, as shown in Table 1. Since the input data are Twitter messages posted on a social platform, we first preprocess the raw data such as tokenization, language detection, and remove stop-words. These operations also include the normalization of all characters to their lower-case forms, truncating, and punctuation marks. We can annotate some common parts such as user and hyperlink as a special token.

We also conduct the classification on some more benchmark data sets, as detailed in Table 2. CR is the customer review of various products such as cameras and mp3s. They contain positive and negative reviews that are used in Hu and Liu. 40 Subj is the Subjectivity data set, 41 where the task is to classify a sentence as either subjective or objective. MPQA is the opinion polarity data set. 42
Sentence classification data set.

CR: customer review; Subj: subjectivity data set; MPQA: opinion polarity data set.
In this work, we consider Word2vec 33 and global vector for word representation 34 (GloVe) as pre-trained word embeddings, as shown in Table 3. Google Word2vec is trained on part of a Google News data set with around 100 billion words with the use of a local context window. 33 GloVe is an embedding version based on global world co-occurrence statistics, 34 which is trained on a corpus of 840 billion tokens from web data, Common Crawl.
Description of each single version of word embeddings.

Performance of proposed method
Classification performance
The classifier model on the sentence classification was trained with multiple versions of word-embedding vectors from GloVe and Word2vec. All word vectors are not kept static, but we trained parameters of the model, and the pre-vector is fine-tuned for each problem. Table 4 shows the performance of our model against those of the other state-of-the-art methods. We recorded the average accuracy using 10-fold cross-validation (CV).
Performance of the proposed method (accuracy measure (average)) on balanced data set using 10-fold cross-validation.
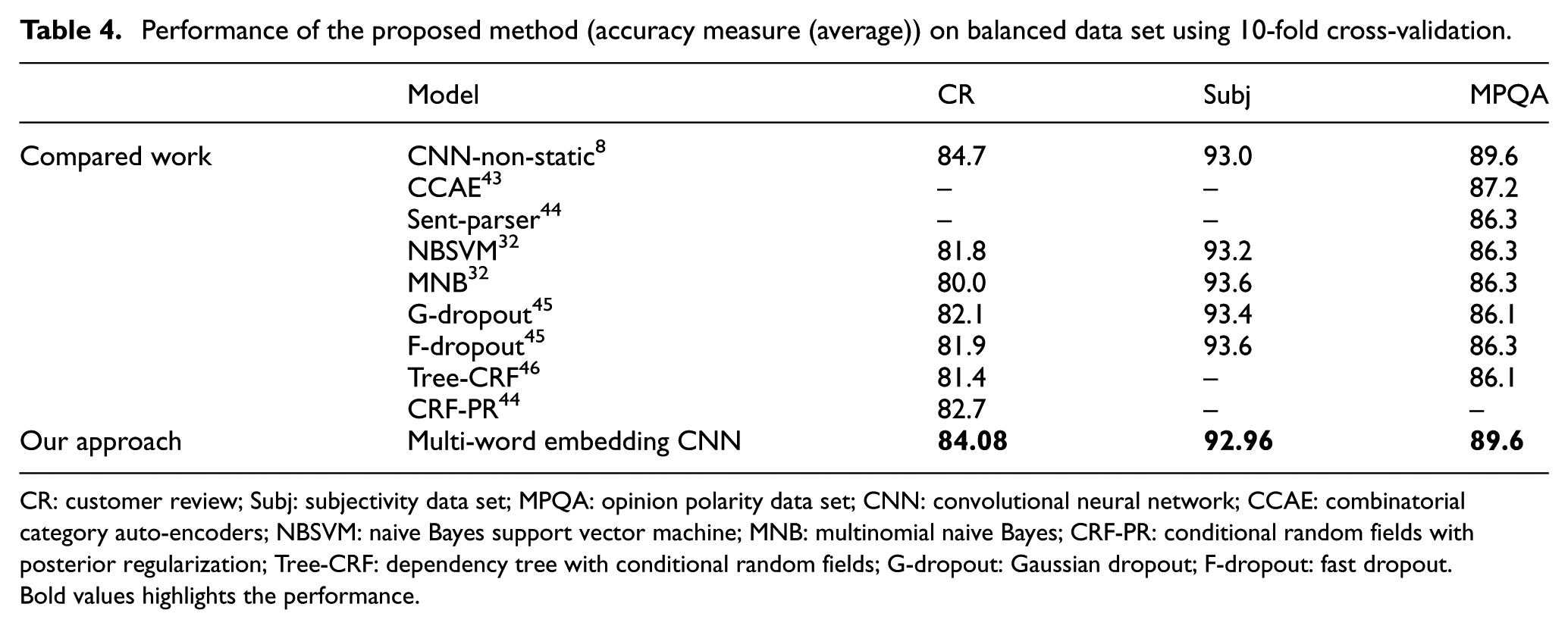
CR: customer review; Subj: subjectivity data set; MPQA: opinion polarity data set; CNN: convolutional neural network; CCAE: combinatorial category auto-encoders; NBSVM: naive Bayes support vector machine; MNB: multinomial naive Bayes; CRF-PR: conditional random fields with posterior regularization; Tree-CRF: dependency tree with conditional random fields; G-dropout: Gaussian dropout; F-dropout: fast dropout.
Bold values highlights the performance.
CCAEs are combinatorial category auto-encoders with combinatorial category grammar operators. 43 Sent-parser is the sentiment analysis-specific parser. 44 NBSVM and MNB are naive Bayes SVM and multinomial naive Bayes with uni-bigrams, respectively, from Wang and Manning. 32 G-dropout and F-dropout are Gaussian dropout and fast dropout, respectively, from Wang and Manning. 45 Tree-CRF refers to dependency tree with conditional random fields. 46 CRF-PR refers to conditional random fields with posterior regularization. 44
The results proved that our approach is a useful tool for sentence classification. Our approach based on the improved CNN with pre-trained embedding features enables the automatic learning of text features without hand-generation feature engineering. We compared our proposed method with that of standard CNN 8 that feeds single word embeddings (GloVe or Word2vec), as shown in Table 5. We concatenate more than one single word embedding (GloVe and Word2vec) in order to form a diverse word-embeddings version (GloVe–Word2vec). Since the data sets are imbalanced between the numbers of each class, we mainly considered area under curve (AUC) rather than accuracy score under 10-fold Cross-validation (CV). The imbalanced training data set always appears in disaster situations; therefore, it is better if we use a multiple word-embedding CNN-based classifier in a disaster detection system.
Performance of the proposed method (average AUC measure) on imbalanced disaster data set using 10-fold cross-validation.
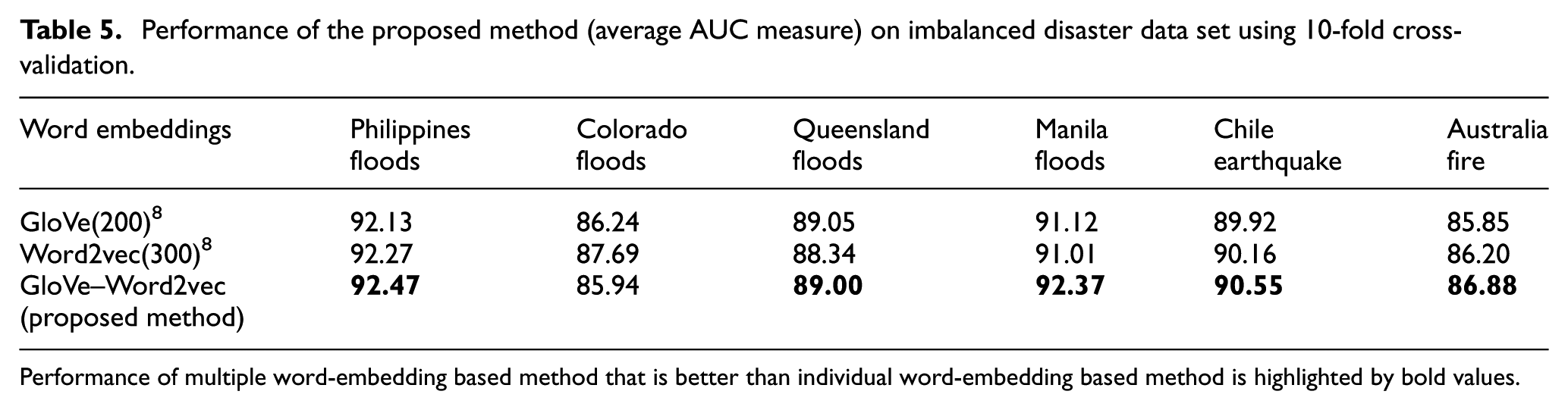
Performance of multiple word-embedding based method that is better than individual word-embedding based method is highlighted by bold values.
As shown in Table 5, the combination of two embeddings with different dimensionalities is the better point of the proposed approach as compared to the multichannel model, 4 as that requires the same size of dimensionality. Furthermore, it automatically learns sentence features better and thus obtains a better result in AUC, as highlighted in the last row. We also reported the AUC of the proposed approach in identifying informative messages in the case of imbalanced available data on disaster situations such as flood, earthquake, and fire.
We also compared the result of our approach on embedding features to supervised classification such as SVMs, artificial neural networks (ANNs), and CNNs on bag of word (BoW), as well as in Table 6. The SVM, ANN, and CNN classifiers are trained on both unigrams and n-grams (n > 1 defined as a sequence of n contiguous words), and these are reported in Caragea et al. 47
Performance of the proposed method (accuracy) as compared with several methods on flood data set.
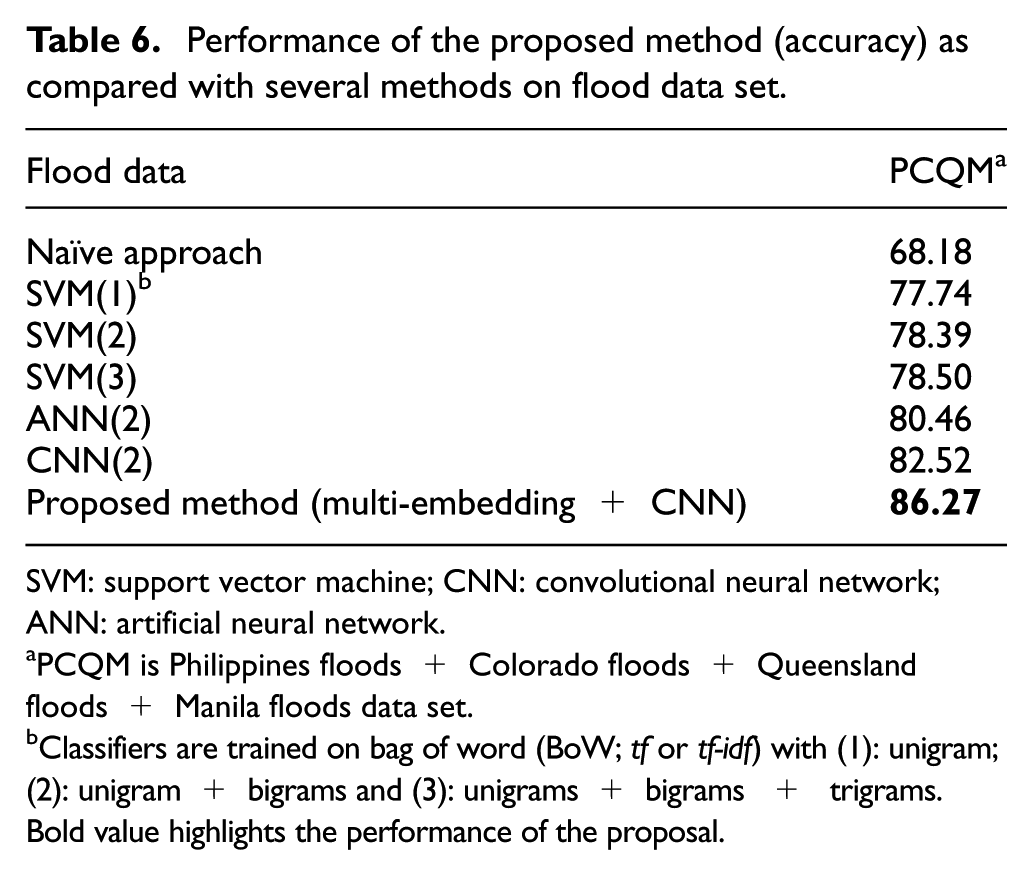
SVM: support vector machine; CNN: convolutional neural network; ANN: artificial neural network.
PCQM is Philippines floods + Colorado floods + Queensland floods + Manila floods data set.
Classifiers are trained on bag of word (BoW; tf or tf-idf) with (1): unigram; (2): unigram + bigrams and (3): unigrams + bigrams + trigrams.
Bold value highlights the performance of the proposal.
We use three convolutional operations on word embeddings with various size windows in the set
Temporal event detection performance
Figure 6 illustrates the process of an event detection algorithm using an LSTM-based predictable model and error estimation model on earthquake-related data. From the top down, each sub-figure presents actual time series

Event detection on earthquake data.
From an earthquake data set without labels of events, only the time of actual earthquake occurrence is available. In this case, the threshold is pre-defined with a value close to zero. In practice, if an event-related data set is available, we can learn this threshold by maximum score metric (F-score). We experimented the event detection algorithm on earthquake-related tweets in order to obtain the time delay information, as shown in Table 7.
Experiments on earthquake-related tweets.
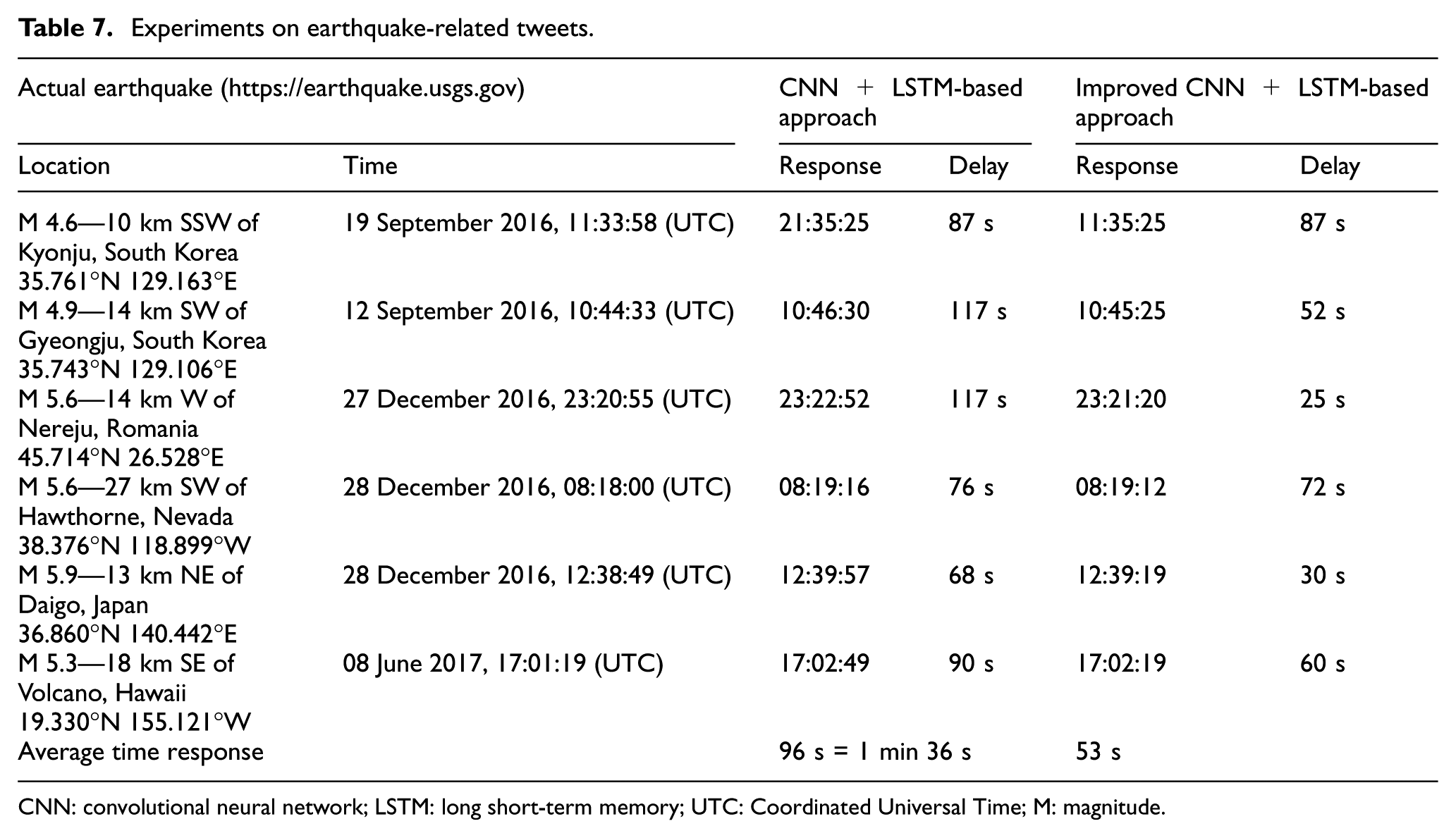
CNN: convolutional neural network; LSTM: long short-term memory; UTC: Coordinated Universal Time; M: magnitude.
Figure 7 illustrates the performance of event detection in a disaster situation. For obtaining the time delay of our system, we calculate the difference between the response of event detection and the actual earthquake (https://earthquake.usgs.gov) on time aspect. The figure below denotes (blue color) the results from considered references.

Time delay of real-time event detection systems.
Implementation of event detection system
In order to implement the application in a real environment, we should handle some problems related to big data and real-time response. For the acquisition, distribution, and integration of large-scale multi-source information, along with the demand for real-time responses of the whole system, we implemented a Haddoop-based 50 system, as shown in Figure 8. In this system, the social data are collected by a Flume tool according to a specific topic. An Apache Flume-owning ingestion mechanism is used for collecting, aggregating, and transporting large amounts of streaming data from various sources. Hive serves as a data warehouse infrastructure to access data, Structured Query Language (SQL) in Hive facilitates the reading, writing, and managing of large data residing in distributed storage (Hadoop distributed file system (HDFS)). The convolution neural network–based model is used to determine informative data or sorting before moving to LSTM-based anomaly detection. Hadoop streaming is a utility that comes with the Hadoop distribution, so we will use this aid to run executable or script as the mapper or reducer for performing classification and event detection. Sqoop is a tool designed to transfer data between HDFS and the relational database. The analyzed social data are then visualized using many solutions (Zeppelin-based dashboard, desktop-application). Visualizations are very useful and informative for management in both local and remote locations.

Hadoop-based event detection architecture.
Conclusion
Recently, since social media has emerged as a dominant channel for gathering and spreading information during the occurrence of some event, social networks have become a useful means of communicating information. For streaming event detection, we introduced an event detection approach composed of CNN and LSTM models. The CNN augmented with multiple word embedding performs well on short text sentences for identifying informative messages as pre-processing procedure. This overcomes the limitation of multichannel CNN while retaining the simple implementation and increased flexibility in the domain of disaster detection application. We can combine many pre-trained word embeddings with different sizes so as to obtain better results as compared to standard CNN on individual word embedding. The LSTM-based predictor is proposed on time series data to learn temporal signal features that are used to detect anomaly patterns. This anomaly detection model shows potential for application in different time series data such as electrocardiogram (ECG) and sensor signal. The proposed method showed that the time response of detection is acceptable, and the system can adapt many domains.
This work proposed a general application framework for social sensor–based event detection systems such as disaster events, sports events, social events, and even political events. The current limitation of our event detection system is to just focus on a single topic–based tweet collection using relevant keywords. In order to improve the convenience of the system for different events, we will investigate the automatic cluster or classifier-based method using the semantic map technique. The content of Twitter will be represented in form of semantic maps, from which the main topics as well as hot events of the social network may easily be read. In the future, we can implement our approach on a big data framework, as well as the integration of Global Positioning System (GPS) information for visualization over a dashboard.
Footnotes
Handling Editor: Gianluigi Ferrari
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was supported by the MSIP (Ministry of Science, ICT and Future Planning), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2017-2016-0-00314) supervised by the IITP (Institute for Information & communications Technology Promotion). The work was also supported by the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2017R1A2B4011409).