
Abstract
In order to facilitate effective crime prevention and to issue timely warnings for the sake of public security, it is important to pinpoint the accurate position of particular pedestrians in crowded areas. Face recognition is the most popular method to detect and track pedestrian movement. During the face recognition process, feature classification ability and reliability are determined by the feature extraction methods. The primary challenge for researchers is to obtain a stable result while the targeted face is subject to varying conditions—particularly of illumination. To address this issue, we propose a novel pedestrian detection algorithm with multisource face images, which involves a face recognition algorithm based on the conjugate orthonormalized partial least-squares regression analysis under a complex lighting environment. Statistical learning theory is a research specialization of machine learning, especially applicable to small samples. Building upon the theoretical principles used to solve small-sample statistical problems, a new hypothesis has been developed; using this concept, we integrate the conjugate orthonormalized partial least-squares regression with the revised support vector machine algorithm to undertake the solution of the facial recognition problem. The experimental result proves that our algorithm achieves better performance when compared with other state-of-the-art methodologies, both numerically and visually.
Keywords
Introduction
Owing to the rapid development of the economy, an increasing number of people like to participate in various activities in public areas. Therefore, the issue of public security is attracting increasing attention. In order to achieve effective crime prevention and to facilitate timely warnings to the public when there are security risks, a pedestrian detection and tracking system is widely used in crowded areas, such as airports, rail stations, shopping centers, and football stadiums. 1 Existing pedestrian detection can be categorized into two groups: one group is characterized by a manual detection of pedestrians through visual inspection techniques and algorithms such as local binary patterns (LBP) 2 and histogram of oriented gradients (HOG); 3 another group is characterized by data-driven features which use learning models based on data to distinguish pedestrian features such as convolutional neural network (CNN) 4 and deep belief network (DBN). 5 Face recognition is the most important technique in the implementation of pedestrian surveillance and tracking. It will help find particular pedestrians of interest in crowded areas. In recent years, face recognition research has made great progress.6–9 Face recognition extracts, and then uses, personal features from a facial image to identify the person. A simple automatic face recognition system consists of the following four aspects: (1) face image standardization, which performs feature point calibration and image cutting; (2) face detection, which uses a variety of different scenarios to detect the existence of the human face and determine its position; (3) face representation, which uses some way to detect the human face and a database of known faces to complete a match; and (4) face recognition, which is the matching of the face against the database of known faces to obtain the relevant information.
In face recognition, the factors to consider in determining the feature extraction method are the feature classification ability, algorithmic complexity, and its feasibility. The extracted features have a decisive impact on the final classification results, while the upper limit of the resolution that the classifier can achieve determines the maximum degree of differentiation between different kinds of characteristics. Regarding the feature extraction modes for faces, we can summarize the existing methodologies as follows:10–19
The nonlinear projection feature extraction. The kernel method is an effective tool to transform the low-dimensional space point sets into high-dimensional space sets, to attain the goal of lineal separability. It also has some weaknesses, in that the geometric meaning is not clear, owing to which samples cannot be explicitly mapped into distribution patterns; furthermore, the selection of the kernel function has no well-defined selection criteria, but instead relies on experience to select parameters, which is not suitable for a large training sample.
Linear projection feature extraction. The subspace method based on linear projection is the most influential step in the feature extraction process of facial recognition. It extracts original sample distribution information or a low-dimensional characteristic of basic classified information contained within an image matrix or vector, through the corresponding algebraic method, and thus completes the process of face recognition.
Feature extraction based on prior knowledge. The feature extraction method based on prior knowledge mainly utilizes the shape of the face and characteristics such as the distance between the various facial organs to help classify facial characteristics. This is one of the earliest, most traditional, and effective methods in use.
Even with the same target object, the image acquisition system may capture entirely different images due to various factors. In particular, lighting conditions play an important role in the images. The appearance of the face under different lighting conditions is shown in Figure 1. Given a certain device or sensor, it is difficult for the human eye to distinguish if the two images from that sensor represent the same object under different lighting conditions, or represent two entirely different objects. Therefore, in automatic target recognition system design, the elimination or suppression of the effect of light is a challenging task.

Demonstration of facial appearances under different lighting conditions.
In this situation, the traditional algorithms deal with the challenge through the following approaches: (1) A single face sample image is derived using the gray histogram equalization algorithm for the object. Histogram equalization converts the gray-scale distribution of an image to become more even. Through histogram equalization, the gray-level distribution is more balanced and the details of the image are more clearly visible. However, after the gray-level histogram equalization, the illumination in the facial sample has no correlation with the light in the images used to train the system. (2) Then the training sample gray-scale distribution mean and variance based on gray normalization were used. For the faces to be recognizable, the mean and variance of their image’s gray-level distribution must be consistent with that of the face training sample’s gray-scale distribution mean and variance; only then can we achieve accurate identification by matching the brightness of the face image to that of the training sample in the library. However, in this method, the images themselves may be overwritten due to the impact of gray distribution and the illumination normalization of pixels. A method to match the content of the corresponding pixels of the same image after compensating for the illumination normalization effect is better. In Figure 1, we show the sample demonstration of the appearance of the face under different lighting conditions. Pedestrian detection is a crucial task in crowded areas. Even though intensive studies about human detection have been carried out for decades, most of the existing algorithms are not appropriate for pedestrian detection under complex illumination conditions. In this study, to deal with the illumination change challenges, we propose a novel face recognition algorithm based on the conjugate orthonormalized partial least-squares regression analysis algorithm under a complex lighting environment. The experimental results indicate that the facial recognition rate of the proposed method is better than that of other methods.
Illumination modeling
The nonparametric kernel density model is one of the most common background models in use. It provides a description of the background sample space distribution pattern of the effective means and overcomes the traditional issues with parameter estimation. The problem here is the dependency on an a priori knowledge of the background; however, often there are not enough background samples for the premise. This issue will result in an increased amount of calculation at the probability density estimation stage. The method employed to weigh the detection accuracy and computational efficiency of the algorithm is the key to an accurate kernel density estimate.
Consider an image sequence with basic variation in illumination. Its observed brightness values change along with the change in time that together constitute a time series

where


According to the update mechanism of the Gaussian mixture model (GMM) that usually incorporates Gaussian scene matching, the reference weight will keep increasing; it does not match the values derived from the model which predict a decreasing weight. In this case, we conclude that creating a new Gaussian distribution rather than maintaining an old Gaussian distribution will take longer. Therefore, the deletion of the Gaussian distribution is not reasonable when the weight of the Gaussian model is the sole deciding factor. However, if other factors are taken into account, it will greatly increase the time complexity of the algorithm. The Gaussian probability density function can be expressed as follows

We may conclude that, from a subset of the original sample set sampling, when subset capacity and window width are suitable, the subset probability density can be close to the original probability density and may have nothing to do with the original sample set capacity. Based on the above theory, if key background information is selected, we can completely remove the participation of the general original sample in the background estimation calculation, resulting in the implementation of a low-cost high-precision approximate estimation. In the situation where color features are not considered, the histogram gray classification of the Gaussian kernel density estimation of probability density can be expressed as follows
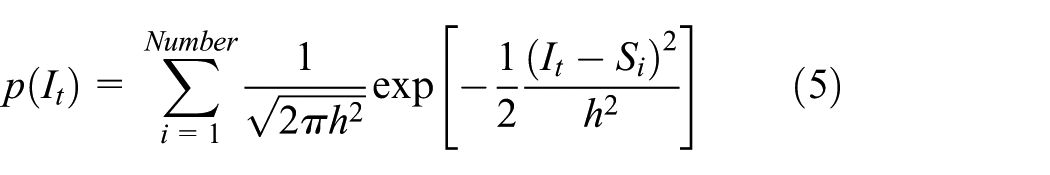
where h represents the bandwidth,
Facial feature extraction paradigms
Gabor feature extraction
A Gabor filter is sensitive to direction and its choice of spatial local features is not sensitive to posture, both of which are barriers rather than global features. 20 Extracting the characteristics of the training data can obtain a larger compression dictionary that can be defined by
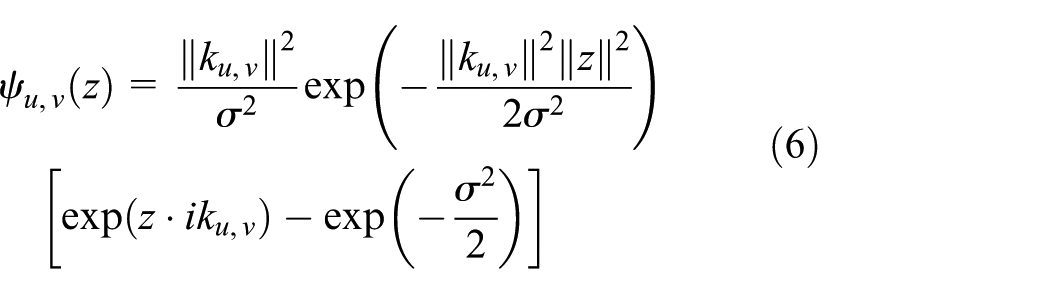
In the formula,
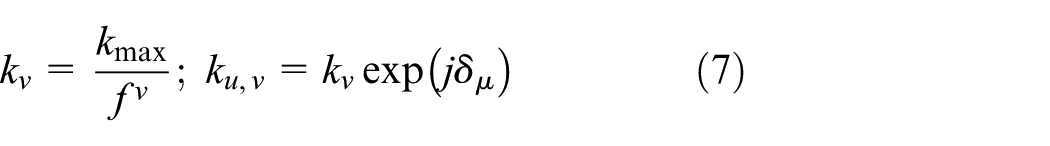
In order to improve the robustness of sparse representation in face recognition, we assume that the encoded residual meets the criteria of a random distribution. Suppose

Revised LBP feature
The LBP operator, based on pixels of the image, is described in this section. A size of 3 × 3 squares is assumed to represent a cell; the central pixel values are taken as the baseline reference. Approximately eight of the central pixels have a value greater than the reference value; if the value is greater than the baseline, then the LBP operator assumes it to be binary 1, or else the operator reduces the value to binary 0

The LBP extraction has high integrity and less faults; however, it is sensitive to noise. Hence, this article has adopted the consistent pattern of block LBP of the facial image that is described here. To improve the recognition performance, consistent patterns of LBP 0 to 1 or 1 to 0 that occur at least twice in succession are considered. This reduces the characteristics of noise sensitivity. Accordingly, we show the local pattern of the faces in Figure 2.

General illustration of the local pattern of the faces.
HOG feature extraction
HOG is the gradient direction histogram and is based on pixel points; each pixel point is calculated and the gradient in the direction of the gradient of amplitude 21 is computed. The HOG calculation method of the image is performed according to the size of a 16 × 16 block of pixels; the sub-blocks are divided into 2 × 2 cells, while each pixel point within the cell block gradient direction histogram is calculated. It will block all the small-cell block histograms in turn that are connected into the large block histogram. Next, we derive each block histogram for the combination and finally obtain the image of the whole histogram. Accordingly, we show the HOG calculation term as follows


Extension locality preserving projection
This projection is located in the high-dimensional Euclidean space

The traditional LPP that is used in unsupervised learning methods failed to extract the discriminant information for the samples. Therefore, we define the enhanced locality preserving projection (ELPP) criterion function as

Local and global combined feature extraction method
Many scholars at home and abroad showed great concern for learning manifolds, proposed from mapping the locally linear embedding. Laplace characteristics and the local projection of the manifold learning method can learn low-dimensional manifold structures hidden in the high-dimensional data space. However, these methods are trying to stay in the low-dimensional subspace local manifold structure of high-dimensional data space and ignored the study of discriminant information in high-dimensional data space. 22
In the later experiment in this study, we will adopt this method as the feature extraction step. The same approach by building the intrinsic relation graph

Conjugate orthonormalized partial least-squares regression analysis
Principles of partial least-squares regression analysis
Suppose that we have the dependent variable y and the general independent variable set
Accordingly, the question could be solved by

If the above conditions are met, then
In Figure 3, we demonstrate the use of the PLS regression model. After the prior modeling, we express the regression as follows

where the regression coefficient can be generally expressed as follows


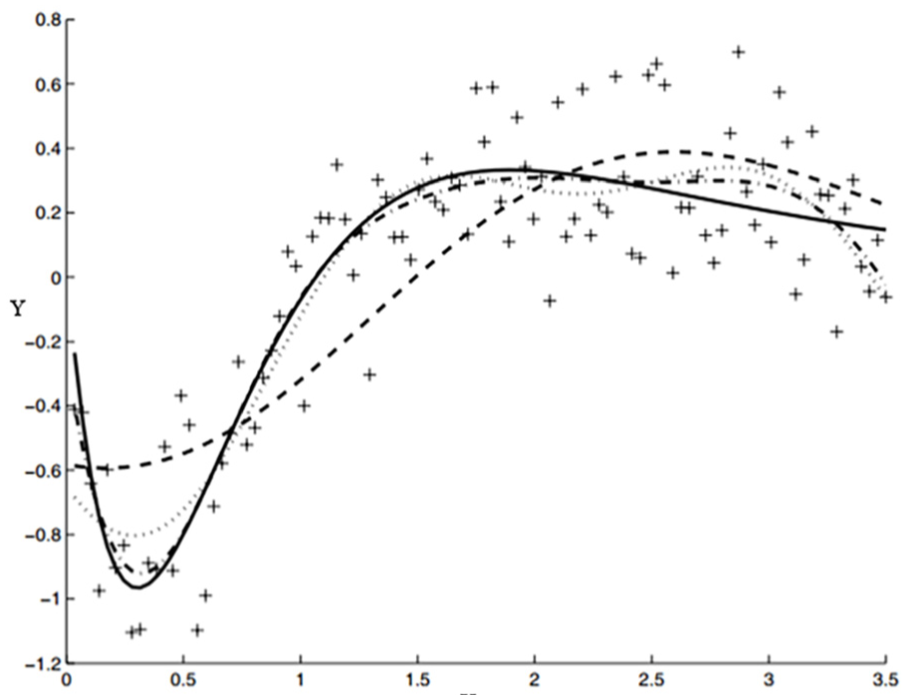
Demonstration of the partial least-squares regression.
Accordingly, we build the least-squares regression model as follows

For that model,

While using the PLS method for face recognition, training of the concentration of each face image is in accordance with the method that employs column stacking into a vector
The least-squares support vector machine
By the least-squares curve fitting, and with about the same amount of error in the determination of good performance as in the objective function of standard support vector machine (SVM), we introduce the error variance law that puts forward the concept of least-squares SVM. 23 This method uses the least-squares linear system as the loss function, in contrast to the classical SVM. Owing to all the equality constraints, the solution reduces to understanding a set of equations. Such a quick solution provides a new train of thought.
Statistical learning theory systematically studied the various types of basic function sets as the relationship between the empirical risk and actual risk, namely, as an extension of the boundary conditions. Investigating the two kinds of classification problems leads to the same conclusions: the indication functions focus all the functions and meet at the certain probability between empirical risk and the actual risk type as shown in formula (21)

The SVM scheme has good classification performance, but it can only act on two kinds of samples that are to be classified; practical applications often need multiple categories in the classification, and therefore we attempt to enhance it via (1) “Binary tree” method, (2) “One against many” method, and (3) directed acyclic graph (DAG) method.
With the background as discussed previously, we combine the PLS regression with the SVM scheme to provide a better model. The optimization problem can be represented as follows

The restriction condition can be expressed as follows

For the solution of the optimization problem, we convert equations (22) and (23) into the Lagrange function as follows

With the integration being completed, we propose the PLS regression combined function that can be expressed as

For this target, the training procedure can be expressed as

Illumination adjustment and influence elimination
To deal with light, there are two basic ideas: remove the lighting or accept the lighting. We use the difference of Gaussian (DoG) face image expansion method to solve the problem of face recognition under the condition of extreme light, rather than accepting the conditions of extremely bright light

Luminance component

We must now consider the question of how to solve the problem of severe changes in the gray illumination estimation. In order to evaluate the relative intensities of the light entering both the eyes and the number of visual features, this article puts forward a logarithmic form of the conduction function as follows
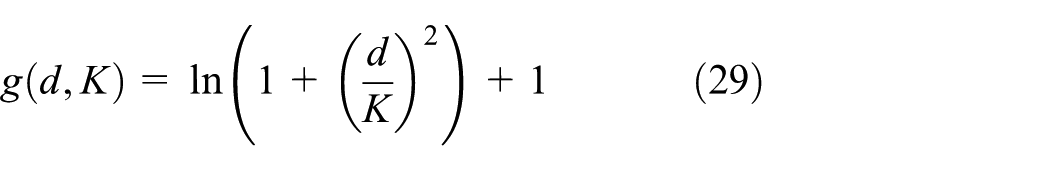
The DoG acts like a band-pass filter and it can also reduce the use of facial image information. The picture shows a face under normal lighting conditions. Using the DoG filter can reduce the quality of the general image itself. In Figure 4, we illustrate the appearance of the face under different conditions of illumination.

Facial appearance under different illumination.
Experiment and results
In order to illustrate the effectiveness of the proposed method, we experimentally simulate the pedestrian detection algorithms with numerical analysis. The sample databases used for calibration were obtained from four public datasets: AT&T, Georgia, University of California—San Diego (UCSD), and MoBo. A total of 20 different facial images from each database were used in the experiment, to simulate the effectiveness of detection under different illumination conditions. In Figure 5, we show the sample database used for experiment. In Figure 6, we show the systematic implementation of the proposed recognition algorithm. It can be concluded that our algorithm can recognize the face well within the red labeled regions. In Table 1, we numerically simulate the proposed algorithm under complex illumination conditions with the dataset from AT&T, and the result indicates that our algorithm performs well with satisfactory robustness and efficiency. The proposed method achieves a mean recognition rate of 90.9%. In Table 2, we show the result of the comparison of simulation performance. We conclude that our method outperforms the principle component analysis (PCA), SVM, neural networks (NN), sparse-based representation classification (SRC), GMM, and LBP methods. The average recognition rate of our method is 92.7%.

Sample database used for our experiment.

Systematic implementation of the proposed recognition algorithm.
Simulation results of the proposed algorithm from the AT&T database.

Comparison of simulation performance between our method and other algorithms.

UCSD: University of California—San Diego; PCA: principle component analysis; SVM: support vector machine; NN: neural networks; SRC: sparse-based representation classification; GMM: Gaussian mixture model; LBP: local binary patterns.
Conclusion
In order to prevent crime and warn the public of security risks in crowded areas, effective surveillance and tracking methods to find particular individuals assume great importance. Face recognition is widely used in airports, shopping centers, and football stadiums. With the rapid development of computer science techniques, face recognition research has been an active research area. In this study, we propose a novel face recognition algorithm based on the conjugate orthonormalized partial least-squares regression analysis, which is suitable for the detection of pedestrians under complex lighting environments. The experimental simulation reflects that our algorithm achieves better recognition rate under complex illumination conditions compared with other state-of-the-art approaches; the average recognition rate of the proposed method reached 92.7%. Pedestrian detection is widely used in crowded areas to find particular individuals, such as criminals. Besides, it is expected that the detection of humans via facial recognition will be extensively used in the field of intelligent transportation systems. In future research, we plan to use mathematical optimization to enhance the conjugate orthonormalized partial least-squares regression analysis to obtain a better model for more in-depth analysis.
Footnotes
Handling Editor: Daming Zhou
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Science and Technology Project of Minjiang University (MYK18039), Fujian College’s Research Base of Humanities and Social Science for Internet Innovation Research Center, Minjiang University (IIRC20180103), and the Natural Science Foundation of Fujian Province (2016J01757).