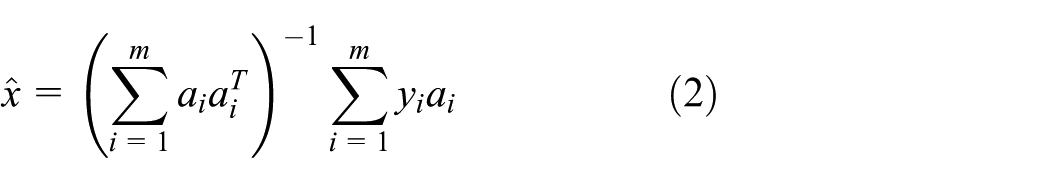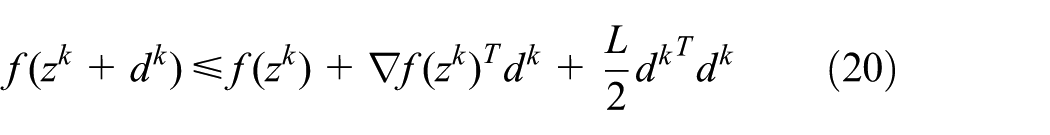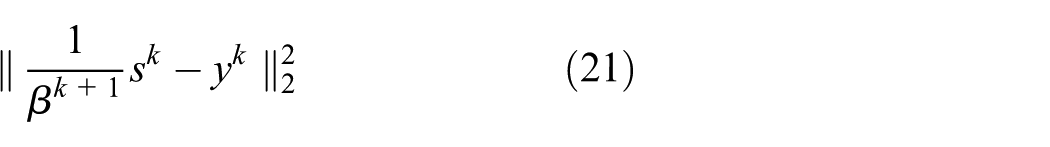In this article, we consider the sensor selection problem of choosing sensors from a set of possible sensor measurements. The sensor selection problem is a combinational optimization problem. Evaluating the performance for each possible combination is impractical unless and are small. We relax the original selection problem to be a convex optimization problem and describe a projected gradient method with Barzilai–Borwein step size to solve the proposed relaxed problem. Numerical results demonstrate that the proposed algorithm converges faster than some classical algorithms. The solution obtained by the proposed algorithm is closer to the truth.
With the wide application of sensor networks in many fields (robotics, target tracking, medical health monitoring, traffic control, etc.),1–8 all kinds of technologies related to sensor networks have been highly concerned by researchers. When sensor networks are used for target tracking, sensors communicate and process information for tracking targets. Due to the limited energy of sensors themselves, unnecessary energy consumption caused by communication and information processing will lead to premature paralysis of sensor networks. At the same time, excessive use of a few sensor nodes to track the target leads to the exposure of the node, which is attacked by the enemy (such as the radar sensor network). Therefore, in order to reduce the energy consumption of sensor nodes and increase the concealment, it is necessary to study the sensor selection problems.
Sensor selection problems study how to select sensors from sensors, which makes the fusion center based on these sensors observation data estimates the most accurate state of the target system. There are possible combinations when we choose sensors from sensors. When and are small, the optimal solution can be obtained by the exhaustive search, but the time spent on the optimal solution when both are larger is unbearable by the current computer. For example, when and , the search times will be , which requires very high computational efficiency.
For the objective of estimating the state of a given system, there has been growing literature in the past few years that study how to dynamically select sensors at run time to minimize certain metrics of the error covariance. The information theoretic framework and Bayesian framework for sensor selection problems are formulated in previous works.9–14 In Chepuri and Leus’15 work, the sensor selection problem is formulated to nonlinear measurement models using the Cramer–Rao bound as the sensor selection criterion. Global optimization techniques, such as branch and bound,16,17 are important approaches for solving the sensor selection problem exactly. Other approaches such as exploiting the submodularity of the objective function, heuristics based on genetic algorithms,18–20 and greedy algorithms21 are proposed to solve the sensor selection problem approximately. In Patan,22 the author studies the estimation of distributed system parameters through the sensor observation data. The goal is to use the fewest sensor nodes to obtain the most accurate estimate, and the authors establish a multi-objective optimization model and solve the model with sequential quadratic programming based on branch and bound strategy. Joshi and Boyd23 propose a heuristic algorithm based on convex optimization and give the optimal sensor selection subset and optimality of upper bound. Numerical results show that the gap between the obtained solution and the optimal solution is small in most cases.
In this article, our goal is to minimize the volume of the associated confidence ellipsoid, which equals to the determinant of the estimation error covariance matrix. We propose to use projected gradient method, which requires less memory and is practical, for the relax sensor selection problem. We formulate the projection subproblem into searching the root of the piecewise continuous function. What is more, we introduce the Barzilai–Borwein (BB)24,25 step size to avoid line search in traditional gradient method.
The article is organized as follows. In the next section, we introduce the sensor selection problem and give the corresponding optimization problem. The proposed algorithms are presented to solve the relax sensor selection problem in Section 3. Section 4 describes the compared results with traditional algorithms for sensor selection problem. Finally, the article is concluded in Section 5.
Sensor selection problem
Consider the problem of estimating a vector from linear measurements, corrupted by additive noise
where , is the observation from the th sensor, represents the zero-mean Gaussian noise with variance , and is a vector of parameters to estimate. The maximum-likelihood estimate probability (MLP) estimate of is given by
The estimation error has zero mean and covariance
The ellipsoid for , which is the minimum volume ellipsoid that contains with probability , is given by
where , and is the cumulative distribution function of a squared random variable with degrees of freedom. A scalar measure of the quality of estimation is the volume of the ellipsoid
where is the gamma function. Another scalar measure of uncertainty that has the same units as the entries in the parameter is the mean radius, defined as the geometric mean of the lengths of the semi-axes of the ellipsoid
We will be interested in volume ratios, and so it is convenient to work with the log of the volume
where is a constant that depends only on , , and . The log volume of the confidence ellipsoid, given in equation (7), gives a quantitative measurement of how informative the collection of measurement is.
The task of sensor selection is selecting a subset of sensors from the set of sensors such that the estimation error is minimized. We introduce a binary vector to represent the selection scheme
where indicates whether or not the th sensor is selected. The corresponding sensor selection problem is formulated as the following optimization
where the vector is the vector with all entries one. We note that the problem in equation (9) is a Boolean-convex problem, since is convex for , the first constraint is linear, and the selection vector is restricted to be or .
The proposed method
The Boolean constraints in problem of equation (9) make it difficult to solve directly. By relaxing each Boolean variable to its convex hull , we obtain the following convex relaxation problem
where is the variable.
Joshi and Boyd23 propose a Newton’s method for solving the approximate relaxed sensor selection problem of equation (9), which is
where is a positive parameter that controls the quality of approximation.
Let ⊗ denote the Hadamard product and be the measurement matrix
The dominated cost of computing the Cholesky factorization in Newton step is . When the number of is small, Newton’s method has high efficiency in solving equation (11). With increases, the memory requirement and computational cost become critical in Newton’s method. It brings about numerical difficulty when computing the inverse of when is large.
In this article, we propose a projected gradient method for solving equation (10) directly. Let be the feasible region of equation (10). At iteration , projected gradient method computes the next point as follows
where and
is the projection of onto the feasible region, that is, is the solution to
Let be the Lagrangian penalty function of , that is
where is a penalty parameter. For any given , the solution to the following box-constrained problem
is
where , and supplies the median of three componentwise arguments.
According to the Karush–Kuhn–Tucker (KKT) conditions for equation (16), is the KKT point of equation (16) if makes
Since is strongly convex, is the unique global minimizer. Now, we consider how to find the root of . When
is a monotone increasing function. Thus, is either constant or a monotonically increasing function of . A feasible approach for the solution of is the half-interval search (Algorithm 1). Once is located, the next point .
Algorithm 1. Half-interval Search
1: Initial interval . 2: whiledo 3: 4: ifthen 5: 6: 7: else 8: 9: 10: end if 11: 12: end while 13:
It is well known that gradient method is often the only practical option in many engineering problems, but it has been observed that the sequence converges quite slowly to a solution. Nesterov26 proposes to use multistep version of an accelerated gradient method for constrained optimization problems with an attractive iteration complexity of for achieving optimality. Let be the lipschitz constant26 of , Algorithm 2 is the framework of Nesterov algorithm for solving equation (10).
Algorithm 2. Nesterov Algorithm
1: Choose , set , . 2: while not convergent do 3: 4: 5: 6: 7: end while
Algorithm 2 is feasible if lipschitz constant is known. In fact, global convergence can be guaranteed if satisfies
In Amir and Marc’s27 work, is estimated with backtracking. Let and , then , where is the smallest non-negative integer making equation (20) hold and . Backtracking method will cost heavy computational efforts since function value and projection needs to be calculated a lot of times.
In this article, we introduce BB step size as for equation (10). Let the vectors and , the BB formula can be obtained by solving the following problems
The BB formula can be seen as an approximation of Quasi-Newton condition. Due to its simplicity, efficiency, and low memory requirements, BB formula has been used in many applications. There are some other spectral methods that alternate between equations (23) and (24). is updated with an average of the most recent iterations information. Since the performance of these variants in our experiments is close to the standard formula for equations (23) and (24), we will use equations (23) and (24) as step size .
Since the solution for equation (10) can be interpreted as the probability of selecting sensor , we can use to generate the sensors. Let denote the elements of rearranged in descending order. The selection is the indexes corresponding to the largest elements of , that is
Let , , and be the optimal value of equations (9)–(11), respectively, then the associate objective value
where U is an upper bound of . and are a lower bound of .
Experimental results
In this section, we report the numerical results of the proposed projected gradient methods for sensor selection problems in this article. All tests are conducted on a Windows 10 with MATLAB 2014. For sensor selection problems, we set and . Linear measurements are generated randomly by Gaussian function, that is, . We compare our BB algorithm with Newton algorithm and Nesterov algorithm for sensor selection problems. We choose equation (24) as the step size in BB algorithm. Newton algorithm solves equation (11) with , and Nesterov algorithm solves equation (10) with . We choose the best hyperparameters in Newton and Nesterov algorithms by grid search methods. The initial point .
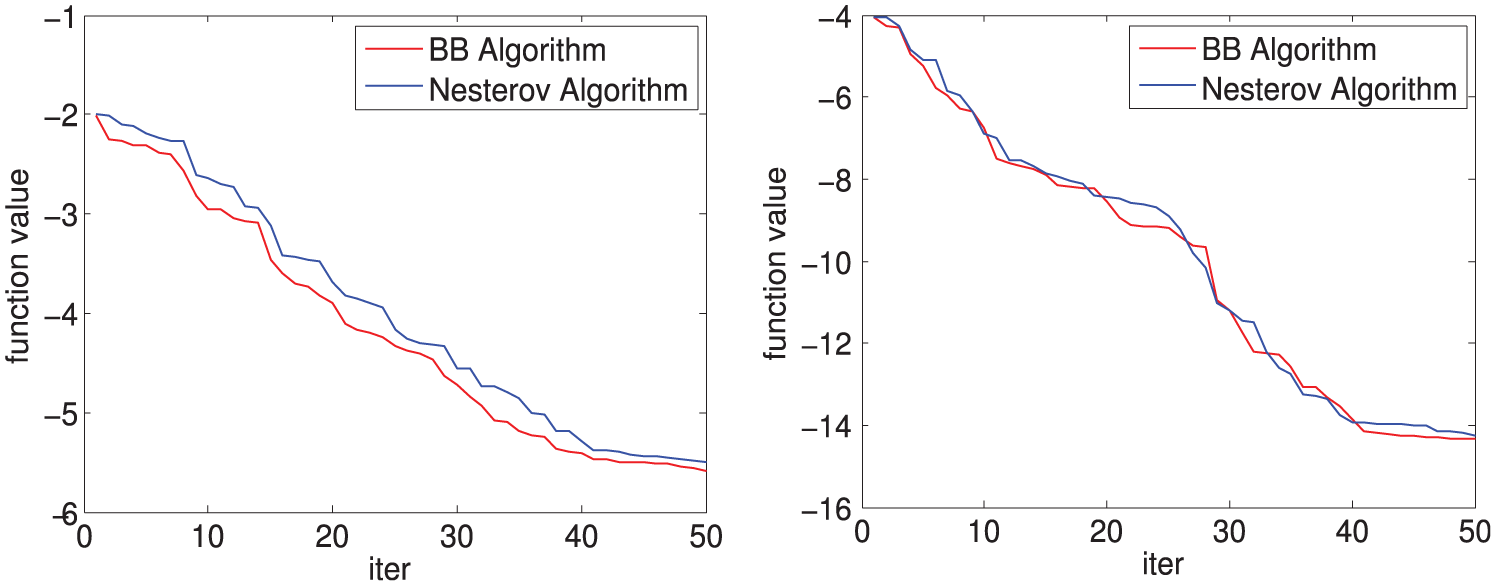
Figure 1 plots the function value of BB algorithm and Nesterov algorithm with and for equation (10), respectively. For , the proposed BB algorithm converges faster and gets lower function value than Nesterov algorithm. For , the proposed BB algorithm does not behave better than Nesterov algorithm in iterations. However, the proposed algorithm shows advantage in the last iterations.
Function value with different in iterations: left: and right: .
Figure 2 shows the upper and lower bounds of the compared algorithms with . From Figure 2, we can see that the bounds decrease as , since bigger means more observation is accumulated in . When , the upper bounds of BB algorithm is lower than the other two algorithms.
Lower and upper bound of sensor selection problems: top left: Newton algorithm; top right: Nesterov algorithm; and bottom: BB algorithm.
Figure 3 plots the gaps between upper bounds and lower bounds as increases. On the whole, the gaps tend to decrease as increases. If the gaps is zero, the lower bound equals to upper bounds. In this case, the optimal indexes of sensor selection problem is equation (25). From Figure 3, we can see that the gaps of the proposed BB algorithm is lower than the other two algorithms, which means that the result of BB algorithm is closer to the optimal selection than the result of Nesterov algorithm and Newton algorithm.
Gaps of the upper and lower bounds with Newton algorithm.
Conclusion and future work
We describe a projected gradient method with BB step size for the relax sensor selection problem. Numerical results also show that the new algorithm performs well on sensor selection problem. In this article, we consider only the volume of the confidence ellipsoid as the measure of estimation quality. Actually, there are other measures that can be used instead of this one, such as worst-case error variance. In the future, we will consider extending our BB algorithm for sensor selection problem based on other kinds of measures.
Footnotes
Handling Editor: Daming Zhou
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iD
Mingqiang Li
References
1.
OliveiraLMRodriguesJJ. Wireless sensor networks: a survey on environmental monitoring. J Communicat2011; 6(2): 143–151.
2.
HeTVicairePYanTet al. Achieving real-time target tracking using wireless sensor networks. In: 12th IEEE real-time and embedded technology and applications symposium (RTAS’06), San Jose, CA, 4–7 April 2006, pp.37–48. New York: IEEE.
3.
WangHPottieGYaoKet al. Entropy-based sensor selection heuristic for target localization. In: Third international symposium on information processing in sensor networks, Berkeley, CA, 27 April 2004. New York: IEEE.
4.
HovlandGEMccarragherBJ. Dynamic sensor selection for robotic systems. In: IEEE international conference on robotics and automation, Albuquerque, NM, 25 April 1997, pp.272–277. New York: IEEE.
5.
ZhouDAl-DurraAFeiGet al. Online energy management strategy of fuel cell hybrid electric vehicles based on data fusion approach. J Power Sources2017; 366: 278–291.
6.
ZhouDAl-DurraAZhangKet al. Online remaining useful lifetime prediction of proton exchange membrane fuel cells using a novel robust methodology. J Power Sources2018; 399: 314–328.
7.
ZhouDNguyenTTBreazEet al. Global parameters sensitivity analysis and development of a two-dimensional real-time model of proton-exchange-membrane fuel cells. Energy Convers Manage2018; 162: 276–292.
8.
LiMHanCWangRet al. Shrinking gradient descent algorithms for total variation regularized image denoising. Computat Optimizat Appl2017; 68(3): 643–660.
9.
ChuMHausseckerHZhaoF. Scalable information-driven sensor querying and routing for ad hoc heterogeneous sensor networks. Int J High Perform Comput Appl2002; 16(3): 293–313.
10.
ManyikaJDurrant-WhyteH. Data fusion and sensor management: a decentralized information-theoretic approach. Upper Saddle River, NJ: Prentice Hall, 1995.
11.
ErtinEFisherJWPotterLC. Maximum mutual information principle for dynamic sensor query problems. In: Second international workshop on information processing in sensor networks (IPSN 2003), Palo Alto, CA, 22–23 April 2003, pp.405–416. New York: IEEE.
12.
CrarySB. Optimal design of experiments for sensor calibration. In: International conference on solid-state sensors and actuators 1991 (Digest of technical papers, transducers), San Francisco, CA, 24–27 June 1991, pp.404–407. New York: IEEE.
13.
GiraudCJouvencelB. Sensor selection: a geometrical approach. In: IEEE/RSJ international conference on intelligent robots and systems 95 (Human robot interaction and cooperative robots), Pittsburgh, PA, 5–9 August 1995, pp.555–560. New York: IEEE.
14.
Mytum-SmithsonJ. Wireless sensor networks: an information processing approach. Sens Rev2004; 25(2): 269–270.
15.
ChepuriSPLeusG. Sparsity-promoting sensor selection for non-linear measurement models. IEEE Trans Signal Process2015; 63(3): 684–698.
16.
WelchWJ. Branch-and-bound search for experimental designs based on D optimality and other criteria. Technometrics1982; 24(1): 41–48.
17.
LawlerELWoodDE. Branch-and-bound methods: a survey. Catonsville, MD: INFORMS, 1966.
18.
JohnRCSDraperN. D-optimality for regression designs: a review. Technometrics1975; 17(1): 15–23.
19.
KincaidRKPadulaSL. D-optimal designs for sensor and actuator locations. Comp Operat Res2002; 29(6): 701–713.
20.
NguyenNKMillerAJ. A review of some exchange algorithms for constructing discrete D-optimal designs. New York: Elsevier Science Publishers, 1992.
21.
ShamaiahMBanerjeeSVikaloH. Greedy sensor selection: leveraging submodularity. In: 49th IEEE conference on decision and control, Atlanta, GA, 15–17 December 2010, pp.2572–2577. New York: IEEE.
22.
PatanM. Resource-aware sensor activity scheduling for parameter estimation of distributed systems. In: 18th IFAC world congress, Milan, 28 August–2 September 2011, pp.9984–9989. New York: IEEE.
23.
JoshiSBoydS. Sensor selection via convex optimization. IEEE Trans Signal Process2009; 57(2): 451–462.
BarzilaiJBorweinJM. Two-point step size gradient methods. IMA J Numer Anal1988; 8(1): 141–148.
26.
NesterovYStichSU. Efficiency of the accelerated coordinate descent method on structured optimization problems. Core Discuss Papers2017; 27(1): 110–123.
27.
AmirBMarcT. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans Image Process2009; 18(11): 2419–2434.