
Abstract
A feature subset discernibility hybrid evaluation method using Fisher score based on joint feature and support vector machine is proposed for the feature selection problem of the upper limb rehabilitation training motion of Brunnstrom 4–5 stage patients. In this method, the joint feature is introduced to evaluate the discernibility between classes due to the joint effect of both candidate and selected features. A feature subset search strategy is used to search a set of candidate feature subsets. The Fisher score based on joint feature method is used to evaluate the candidate feature subsets and the best subset is selected as a new selected feature subset. From these selected subsets such as obtained by the above process, the subset with the best performance of support vector machine classification is finally selected as the optimal feature subset. Experiments were carried out on the upper limb routine rehabilitation training samples of the Brunnstrom 4–5 stage. Compared with both the F-score and the discernibility of feature subset methods, the experimental results show the effectiveness and feasibility of the proposed method which can obtain the feature subsets with higher accuracy and smaller feature dimension.
Keywords
Introduction
With the increasing number of aging population in the world, the number of stroke patients is increasing; 85% of stroke patients have upper limb dysfunction in the early stage of the disease, 1 which seriously affects their quality of life. 2 Traditional rehabilitation training is mostly assisted by physiotherapists and large training equipment. 3 This method can effectively complete the training. However, it is monotonous and difficult to evaluate the recovery effect in real time. 4
With the continuous innovation and development of human sensing technology, more and more scholars have applied the human motion sensing technology to the rehabilitation training of stroke patients. 5 However, the method is not suitable for all rehabilitation stages. According to the Brunnstrom stage theory, in the 4–5 stage, the patients begin to disengage from the common movements. 6 At this time, the range of the movement of patients is increased, and some training can be completed independently, so it is valuable to use the body sensing technology to provide effective information for evaluation on training motions.
The key to the evaluation method of rehabilitation training is how to use the human body sensing technology to identify the motions of patients, in which the motion recognition algorithm is used to recognize the rehabilitation training motions of the patient and determine whether these motions meet the standard of rehabilitation training. If these motions done by the patients meet the requirements, they are identified qualified, otherwise unqualified.
Support vector machine (SVM) is popular among many classification methods because of its excellent characteristics and generalization ability. 7 Although it has many outstanding advantages, its classification and generalization performance are often affected by the high-dimension feature vectors of samples.
Feature selection is an important tool to improve the performance of SVMs. It can eliminate redundant features, reduce model complexity effectively, avoid over-fitting, and improve the classification and generalization performance of SVM. It can also effectively reduce the calculation and improve the real-time performance of remote health treatment system.
In the feature selection methods, the Filter method is popular among researchers, but most studies of feature subset which involve Filter method only consider the effect of individual candidate feature on the discernibility between classes, but ignore the impact of the joint effect of candidate features and selected features.
For this problem, this article introduces the distance between joint features into the framework of F-score method, and proposes a feature subset discernibility hybrid evaluation method by using Fisher score based on joint feature and support vector machine (FSJF-SVM). In this method, FSJF is used as the evaluation criteria in Filter method, and SVM is used as the learning algorithm for evaluation in the Wrapper method.
This article starts with a brief introduction of the basic framework of F-score feature subset evaluation method, the multi-class F-score evaluation method, and the discernibility of feature subset (DFS) method. The “Problem formulation” section describes the existing problems of the DFS method. The “FSJF evaluation method” section describes the proposed method. The “Experimental design” section presents the rehabilitation training data collection and experimental design. The “Experimental results and analyses” section performs analyses on the experimental results, and conclusions are given in the “Conclusion” section.
Related work
Feature selection includes two main steps: feature subset search strategy and feature subset evaluation criterion. 8 Commonly used feature subset search strategies include sequential forward search (SFS) and sequential backward search (SBS). 9 The feature subset evaluation criterion can be further divided into three categories: Embedded method, Filter method, and Wrapper method. 10 The Embedded method embeds the process of feature selection into the construction of a learning model. For example, the decision tree algorithm, Induction of Decision Tree 3 (ID3), itself is an embedded feature selection algorithm. 11 The Embedded method avoids the relearning of the learning machine to evaluate every feature, which is more efficient but difficult to construct a suitable function to optimize the model. 12
The Filter method defines the importance of each feature according to its effect on the discernibility between classes and selects the important features to constitute a feature subset. Dash and Liu 13 proposed an inconsistent computing method which is independent of feature search process and can improve the efficiency of feature selection. Battiti 14 first applied the information theory to feature selection and proposed a feature selection algorithm for neural networks, Mutual Information Feature Selection (MIFS). Kwak and Choi 15 proposed the feature selection algorithm based on Parzen window’s mutual information. The Filter method is independent of the learning process and the time efficiency is high, but it does not interact with the classifier.
The Wrapper method is closely related to the learning algorithm, and it uses the performance of learning algorithm as the evaluation criterion of the feature subset. The Wrapper method is first proposed by Kohavi and John; 16 then Yang et al. 17 proposed the Wrapper feature selection algorithm based on the output random disturbance, which sorts the features by the importance of the sensitivity measurement attribute generated by the random disturbance; and then selects the feature subset that meets the requirement of the dimension. The Wrapper method is interactive with the specific classifier and has a high accuracy, but it needs to retrain the classifier for each candidate feature subset. Its computational complexity is high and the efficiency is low.
Both the Filter and the Wrapper methods have their own advantages and disadvantages. The hybrid feature evaluation method combining the two methods integrates the efficiency of the Filter method and the high accuracy of the Wrapper method, which can lead to obtaining a better feature subset.
Problem formulation
The Filter evaluation method in the hybrid method has great influence on the final feature selection result. The classic Fisher feature subset evaluation criterion (F-score method), hereinafter referred to as the F-score method, has set up a framework of Filter-type evaluation method. This section will introduce the related research of F-score method and its existing problems.
F-score method
F-score can measure the separating capacity of a single feature between two sets of samples.
18
Given a binary classification problem on m-dimensional space
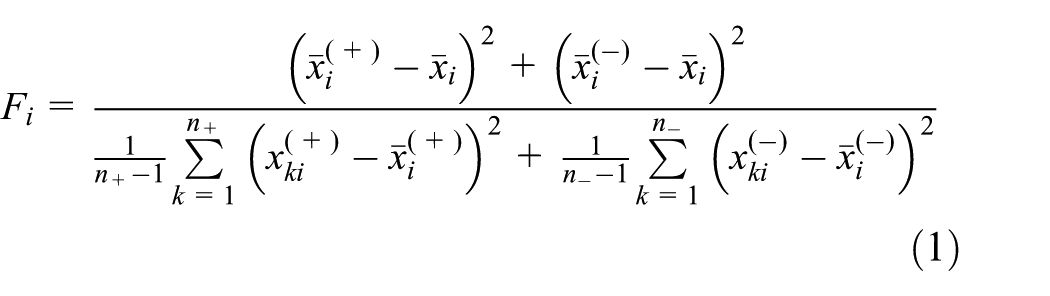
where
The F-score method cannot be directly used for multi-class classification problems (MCPs), and a multi-class F-score method is proposed to solve,
19
which is described as follows. Given an MCP on m-dimensional space
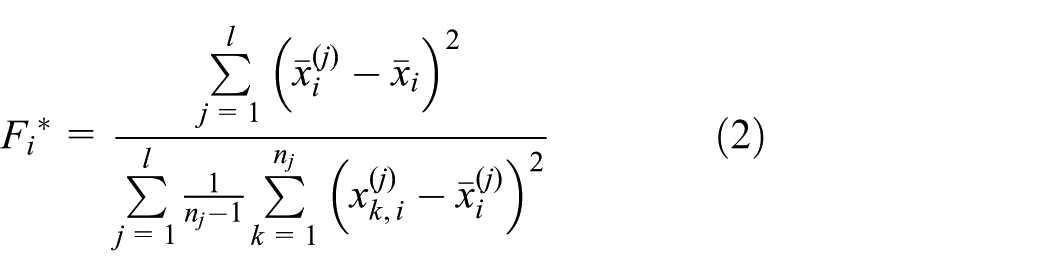
where
The F-score method has successfully established a framework of the Filter method, but this F-score method and most studies of feature selection involving Filter method only consider the effect of individual candidate feature on the discernibility between classes, but the joint effect of candidate features and selected ones on the discernibility between classes is ignored. Xie and Xie 20 proposed the DFS method, which attempts to introduce the joint effect into the feature subset evaluation method.
Given a l-class classification problem on m-dimensional space

where each variable is the same as in equations (1) and (2).
Problem description
The DFS method proposes a way to introduce the joint effect of the candidate and selected features into the evaluation method, but there are still some defects.
We transform the DFS method of equation (3) into that of equation (4) as shown below

By comparing equation (4) with equation (2), it is easy to find that the numerator and the denominator of DFS are derived from the addition of numerator and denominator of F-score method of each feature, respectively. Especially, when I = 1, the DFS method is completely equivalent to the multi-class F-score method.
When the forward search strategy is combined with the DFS method and I = 1, we assume that

Assume that

when I = 2, the DFS method is as follows

where
Therefore, the DFS method does not introduce the joint effect of features into the feature subset evaluation method but the magnitude information of features instead. In addition, when DFS faces the problem of more than two classes, it will appear as shown in Figure 1. In such condition, the result of DFS method is not too bad, but the distinction ability of this feature subset between these four classes is not good.
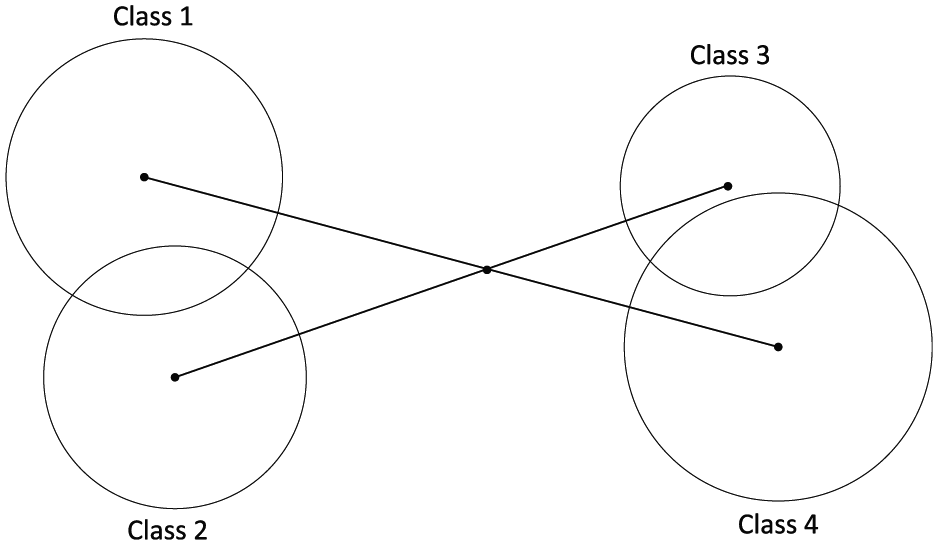
Multi-class overlapping problem.
FSJF evaluation method
From the previous discussion, we can see that the above method fails to introduce the joint effect of the candidate and selected features on the discernibility between classes into feature subset evaluation. To solve this problem, we put forward an FSJF evaluation method, in which we first introduce the concept of joint feature and then we use the distance between joint features to measure the distinction ability of joint feature between classes.
Set candidate feature value
In calculating the distance between joint feature vectors, the concept of Euclidean distance is introduced. Set two m-dimensional joint feature vectors

We introduce the joint feature and the distance between the joint feature vectors into the F-score framework to form our FSJF method, and the joint feature distance is used to measure the degree of inter-class density and the degree of density within classes. The joint contribution of the candidate and selected features can be successfully introduced into the evaluation on the feature subset. In addition, the decomposition and ensemble methods (DEMs) are often used to solve the MCP. This method decomposes an MCP into a set of binary classification problems and then integrates the results of each binary classification to solve the MCP. Therefore, when choosing features of MCPs, the feature selection can be carried out, respectively, to each of the binary classifiers, which will increase the computation but can get better performance of multi-class classifier. While FSJF is used as a feature subset evaluation method for binary classification problems, it can also be used to solve the MCPs. Each feature selection of the FSJF method involves only positive and negative classes, so there will not be multi-class overlapping cases in the DFS method. Assuming that the feature subset contains I features, the FSJF method is defined as follows

where
As shown in equation (9), the numerator is the sum of the distance between the joint feature mean vectors on the whole and positive sample datasets, and the distance between the joint feature mean vectors on the whole and negative sample datasets, which is used to measure the degree of inter-class density between the feature subsets. The denominator is the sum of the average distance between the joint feature mean vector and each joint feature vector in positive and negative class sample datasets, which is used to measure the degree of intra-class density of each class on joint feature subset. The larger the numerator value is, the lower the density between the two classes on the joint feature subset is. The smaller the denominator is, the higher the intra-class density on the joint feature subset is. Therefore, the larger the value of equation (9) is, the better the distinction ability of the candidate feature subset between classes is. Figure 1 as shown before plots the schematic diagram of equation (9). For the two-class problem, the mean points of the candidate feature and the feature subset of the selected features on the whole dataset are located on the line of the mean point of the two-class sample dataset. Therefore, we can further simplify equation (9), remove the candidate features and the mean points of the feature subset of the selected features on the whole dataset, and directly use the Euclidean distance between the mean point vectors on the two class of sample datasets as shown in equation (10), and the meaning of each variable is the same as in equation (9)
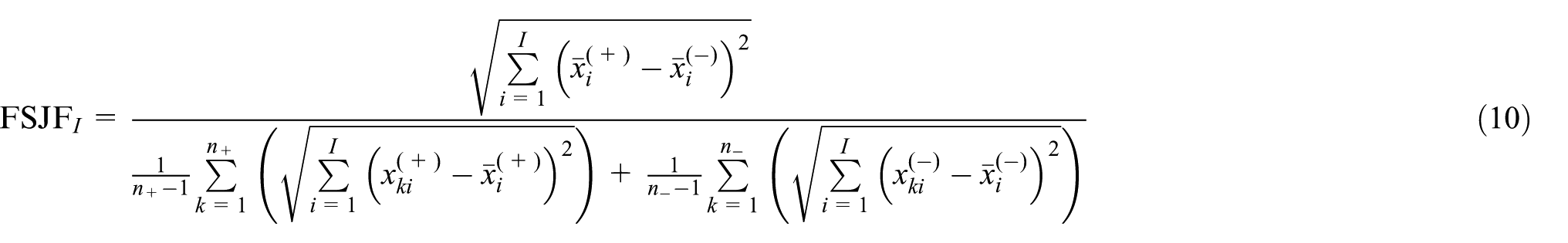
FSJF-SVM we proposed is a hybrid evaluation method for DFS based on joint feature Fisher criterion and SVM. Combining the feature subset search methods, FSJF is used as the evaluation criterion in the Filter method, SVM is used as the learning algorithm in the evaluation of the Wrapper method, and both of them are used to form the hybrid evaluation method. Algorithm 1 is given as follows.

Experimental design
In this article, our FSJF-SVM hybrid feature subset evaluation method aims at the feature selection for the upper limb rehabilitation training motions in the Brunnstrom 4–5 stage. Based on the six kinds of training motions, we use the human upper limb motion collection suit designed by ourselves to collect motion samples of six kinds. F-score-SVM, DFS-SVM, and the proposed method are combined with the SFS and SBS feature search strategies, respectively, to form different feature selection methods. Comparison experiments are carried out to verify the effectiveness of our method.
Motion data acquisition
The motion data of the rehabilitation training are obtained by a wearable human motion acquisition system we developed to acquire the motion data of each joint of human body. 21 Figure 2 shows the wearing demonstration of the acquisition system, which consists of eight inertial measurement modules which include one head, one waist (or back), two forearms, two upper arms, and two hand modules, respectively. Two data gloves can acquire the actions of 10 fingers, but they are not used in this article. Each acquisition module as shown in Figure 2(c) is mainly made up of a nine-axis inertial measurement unit (IMU) consisting of a three-axis gyroscope, a three-axis accelerometer, and a three-axis magnetometer, which can be used to measure the velocity and accelerate values and magnetic intensity, respectively, and finally the angle values can be calculated. The direct IMU output quaternion is used to represent the human motion data for the real-time calculation process, which can be calculated into the joint angles, including the pitch, yaw, and the roll angles of the neck, waist, and the shoulder joints, and the pitch and roll angles of the elbow joints, respectively.

The motion acquisition system: (a) and (b) front and back wearing conditions, and (c) one acquisition module of the system.
In the 4–5 stage of Brunnstrom theory, six commonly used sitting training exercises used for training the shoulder, elbow, and waist joints are selected to build motion dataset. Figure 3 shows the starting motion and six groups of training motions, in which the left is the starting motion of all the movements, followed by m1, m2, m3, m4, m5, and m6 movements from left to right. The handshake in the six movements known as Bobath handshake is a common method of neurophysiological therapy, which is widely used in the clinical rehabilitation treatment of stroke and is suitable for most of the upper limb rehabilitation training.

Start action and six groups of training actions.
We invited 20 subjects (13 men and 7 women, average 170 cm tall and 71 kg) to participate in the experiment and set up a motion sample dataset on the upper limb rehabilitation training. Each motion was performed 10 times per person, and 200 samples were collected for each motion. There were 1200 motion samples in the sample dataset.
Feature extraction
Extracting effective features from the joint angles we collected lays a foundation for feature selection and classifier building. From the 13 angle data of human upper limbs, we extract four time domain features, including mean value (mean), standard deviation (std), peak and peak value (ppv), and above mean point (aboveMean), in which mean represents the mean position of the data of joint angles, std represents the degree of deviation from the average of the joint angles, and ppv represents the range of the variation of the data of the joint angles. The three features and the above mean point (aboveMean), respectively, are expressed as follows




where
The data we need are the pitch, yaw, and roll angles of the left shoulder joint; the pitch and roll angles of the left elbow joint; the pitch, yaw, and roll angles of the right shoulder joint; the pitch and roll angles of the right elbow joint; and the pitch, yaw, and roll angles of the waist joint. In this order, we number them from 1 to 13 and construct the feature vector as follows

Experimental schemes
In order to verify the effectiveness of the FSJF-SVM feature subset discernibility hybrid evaluation method, we first combine the F-score and DFS with SVM algorithm to form F-score-SVM and DFS-SVM hybrid evaluation method, and we combine the F-score-SVM, DFS-SVM, and FSJF-SVM with the SFS and the SBS feature search strategy, respectively, to form two groups of feature selection methods, and then we carry out two groups of comparative experiments.
The first group uses the SFS feature selection search strategy to conduct feature selection as shown in Scheme 1. In the first group of experiments, the FSJF feature subset discernibility hybrid evaluation method is changed into the corresponding evaluation one to form the experimental scheme of the comparative methods mentioned above.

As shown in Scheme 2, the second group uses the SBS feature selection search strategy to perform feature selection. In the second group of experiments, the FSJF feature subset discernibility hybrid evaluation method is changed into the corresponding evaluation one to form the experimental scheme of the comparative methods.

Experimental results and analyses
As described above, the rehabilitation training motion sample dataset contains six kinds of motions:
We use the implementation schemes proposed in the “FSJF evaluation method” section and carry out the feature selection experiment on the above six binary classification problems separately. In order to compare the performance of different feature subset evaluation methods more objectively, the SVM classifier used in the experiment uses the radial basis function (RBF) kernel, and the penalty parameter C and the RBF kernel function parameter g are set to 1 and 0.5, respectively.
In order to obtain the random experimental data, we randomly disorder 1200 samples. Each class of samples is added to five empty sample sets one by one, so that the collected samples are divided into five parts randomly and evenly. Four samples were taken as the training set and the other was taken as the test set. Starting from the first sample, each sample is sequentially used as a test set to finish five experiments. We get the average of accuracy of five experiments to get the result of fivefold cross-validation.
Characteristics of FSJF method
The feature selection process of the 1v2 class by FSJF In the first comparison experiment is taken as an illustration to show the characteristics of the FSJF method. In this process, all the optimal feature subsets of different dimensions from 1 to 52 are chosen out and their corresponding FSJF scores are calculated as shown in Table 1, respectively. For example, when the feature subset capacity is 7, the subset with the highest FSJF scores is {50, 5, 10, 18, 23, 31, 36}, and its score is 3.638946577. It can be seen from Table 1 that when the selection of n + 1 dimension subset is selected, the selected optimal subset of n dimension will be selected as the selected feature subset, and then the candidate features which can constitute the optimal subset of n + 1 dimension are added to the selected feature subset to form the new n + 1 dimension selected feature subset. Finally, according to the SVM classification accuracy of the best feature subset of each dimension on the test set, the subset with the best classification rate is selected as the final optimal feature subset.
The best feature subsets and scores for FSJF of class pair 1v2 of the first experiment.

FSJF: Fisher score based on joint feature.
Comparison experiment with SFS method
In Figure 4, four classes of 1v3, 1v5, 1v6, and 3v4 in the experiment are taken as examples to show the classification accuracy curve of the feature subset selected by the F-score-SVM, DFS-SVM, and FSJF-SVM methods that vary with the number of features in selected subset. The change curve of classification accuracy rate is the result of fivefold cross-validation experiment. The classification accuracy and the number of features of the selected optimal feature subset of FSJF-SVM, DFS-SVM, and F-score-SVM methods are given in Tables 2 and 3, respectively.

Feature selection of three methods in the first set of experiment.
The accuracy of best feature subset of SFS-FSJF-SVM, SFS-DFS-SVM, and SFS-F-score-SVM methods (%).

SFS: sequential forward search; FSJF-SVM: Fisher score based on joint feature and support vector machine; DFS: discernibility of feature subset.
The number of feature in the best feature subsets of SFS-FSJF-SVM, SFS-DFS-SVM, and SFS-F-score-SVM methods.

SFS: sequential forward search; FSJF-SVM: Fisher score based on joint feature and support vector machine; DFS: discernibility of feature subset.
From Figure 4, we found that the accuracy rate of the FSJF-SVM method increases faster but then falls more slowly than the other ones, and particularly the curve of 1v3 is the most obvious.
For 1v5, 1v6, 3v6, and 4v5 class pairs as shown in Table 2, the classification accuracy on the optimal feature subset selected by FSJF-SVM is 10%, 8.87%, 12.44%, and 3.33% higher than F-score-SVM, and 3.33%, 2.20%, 5.55%, and 3.33% higher than DFS-SVM, which is superior to the two others. For 1v3, 1v4, 3v4, and 3v5 class pairs, the accuracy of the FSJF-SVM method is the same as that of DFS-SVM, which is 6.90%, 10.00%, 6.90%, and 3.45% higher than that of F-score-SVM.
As shown in Table 3, most of the number of features contained in the optimal subset selected by the FSJF-SVM method is smaller than the number of features contained in the optimal subset selected by DFS-SVM. For 1v2, 3v6, and 4v5 class pairs, while the dimension of the feature vectors selected by FSJF-SVM is not smaller than that of DFS-SVM, the classification accuracy of the optimal feature subset selected by FSJF-SVM is 3.33%, 5.55%, and 3.33% higher than DFS-SVM.
Comparison experiment with SBS method
In Figure 5, the four class pairs of 1v3, 1v5, 1v6, and 4v5 are taken as examples to show the classification accuracy of the feature subset selected by the F-score-SVM, DFS-SVM, and FSJF-SVM methods that vary with the number of features in selected subset. The classification accuracy rate is the result of fivefold cross-validation experiment. The classification accuracy and the number of features of the selected optimal feature subset of FSJF-SVM, DFS-SVM, and F-score-SVM methods are given in Tables 4 and 5, respectively.
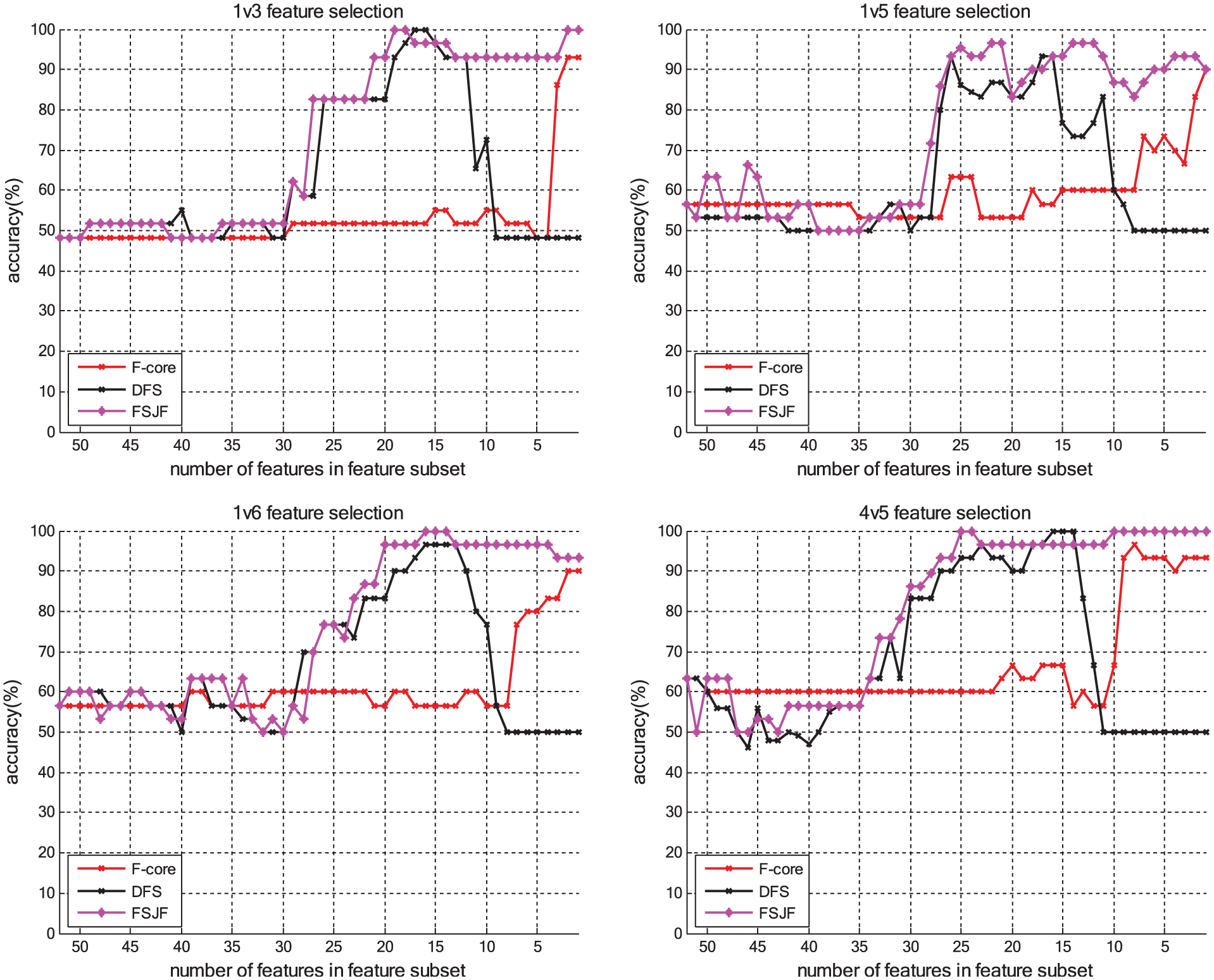
Feature selection of three methods in the second set of experiment.
The accuracy of best feature subset of SBS-FSJF-SVM, SBS-DFS-SVM, and SBS-F-score-SVM methods (%).

SBS: sequential backward search; FSJF-SVM: Fisher score based on joint feature and support vector machine; DFS: discernibility of feature subset.
The number of feature in the best feature subsets of SBS-FSJF-SVM, SBS-DFS-SVM, and SBS-F-score-SVM methods.

SBS: sequential backward search; FSJF-SVM: Fisher score based on joint feature and support vector machine; DFS: discernibility of feature subset.
From Figure 5, we found that the accuracy rate of the FSJF-SVM method increases faster but then falls more slowly than the other ones, and particularly the curve of 1v5 is the most obvious.
For 1v5, 1v6, 3v4, and 3v6 class pairs as shown in Table 4, the classification accuracy on the optimal feature subset selected by the FSJF-SVM method is 6.67%, 10%, 6.90%, and 10.34% higher than that of F-score-SVM, and 3.34%, 3.33%, 3.45%, and 3.45% higher than that of DFS-SVM, which is superior to the other two methods.
For the class pairs other than 1v4, 1v6, 3v4, and 3v5 as shown in Table 5, the number of features contained in the optimal subset selected by the FSJF-SVM method is smaller than that contained in the optimal subset selected by DFS-SVM. For 1v6 and 3v4 class pairs, while the dimension of the feature vectors selected by FSJF-SVM is 1 and 10 bigger than that of DFS-SVM, the classification accuracy on the optimal feature subset selected by FSJF-SVM is 3.33% and 3.45% higher than that of DFS-SVM.
The two groups of experiments above prove that the proposed FSJF-SVM hybrid feature subset evaluation method can obtain the feature subsets with higher accuracy and smaller feature dimension, which improves its effectiveness and feasibility. Comparing the two sets of experiments, we can also find that this method can get better performance when combined with SBS subset strategy.
Conclusion
In this article, an FSJF-SVM feature subset discernibility hybrid evaluation method for Brunnstrom 4–5 stage upper limb rehabilitation training is presented. The FSJF evaluation method is used as the evaluation criterion in the Filter method, and SVM is used as the learning algorithm in the Wrapper method to form the FSJF-SVM hybrid feature subset evaluation method. The FSJF-SVM, DFS-SVM, and F-score-SVM methods are combined with the SFS and the SBS subset strategy, and the comparison experiments were carried out on the six kinds of upper limb rehabilitation training datasets in the Brunnstrom 4–5 stage. The results show that the hybrid feature subset evaluation method proposed in this article can improve the classification accuracy of the classifier and reduce the dimension of the selected optimal feature vector, and this method can get better performance when combined with SBS subset search strategy.
Footnotes
Handling Editor: Antonio Lazaro
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by National Natural Science Foundation of China (61873008) and Beijing Natural Science Foundation (4182008).