
Abstract
Thermal issues in microprocessors have become a major design constraint because of their adverse effects on the reliability, performance and cost of the system. This article proposes an improvement in earliest deadline first, a uni-processor scheduling algorithm, without compromising its optimality in order to reduce the thermal peaks and variations. This is done by introducing a factor of fairness to earliest deadline first algorithm, which introduces idle intervals during execution and allows uniform distribution of workload over the time. The technique notably lowers the number of context switches when compare with the previous thermal-aware scheduling algorithm based on the same amount of fairness. Although, the algorithm is proposed for uni-processor environment, it is also applicable to partitioned scheduling in multi-processor environment, which primarily converts the multi-processor scheduling problem to a set of uni-processor scheduling problem and thereafter uses a uni-processor scheduling technique for scheduling. The simulation results show that the proposed approach reduces up to 5% of the temperature peaks and variations in a uni-processor environment while reduces up to 7% and 6% of the temperature spatial gradient and the average temperature in multi-processor environment, respectively.
Introduction
With the innovation in complementary metal oxide semiconductor (CMOS) technology, the size of the chip is constantly decreasing. However, the operating voltages of circuit are not decreasing at the same proportion. It has resulted in elevated chip power densities and high temperatures. High chip temperatures not only challenge the system’s reliability but also increase the total power consumption. 1 Hotspots (localized increase of temperature of any particular core due to concentrated on-chip computation activity) and thermal cycles (temperature variations on a chip between upper and lower bounds) are two common thermal issues. Hotspots can cause problems like electro-migration, dielectric breakdown and ultimately permanent device failure while thermal cycles cause accelerated package fatigue and material deformation. 2 Moreover, the costly packaging solutions and cooling mechanisms required to diminish these effects increase the cost of the system. The power and energy management is even more crucial in embedded systems, since they are mostly battery operated with few cooling mechanisms. Moreover, tremendous growth of Internet of things (IoTs) in recent years and the respective role of embedded system applications have increased the importance of optimal utilization of processing resources in the constrained environments. This is especially critical in case of real-time applications where the processing is strictly time-constrained.
Sensing the sensitivity of the problem, numerous temperature-aware management techniques have been proposed in the previous work. These techniques are either based on hardware approach or software approach or a combination of the two. Some state-of-art scheduling-based thermal management techniques have been highlighted here.
Dynamic power management (DPM) 3 and dynamic voltage and frequency scaling (DVFS) 4 are commonly used techniques to solve the thermal as well as power issues at operating system level. DPM reduces the static power by putting the processor in low power state (sleep mode, deep sleep mode etc.) during idle time depending on workload. DVFS is used where the processor has an ability to operate at different pairs of voltage and frequency to minimize the power usage while still guaranteeing the deadlines. By operating the device at lower voltage and frequency, the dynamic component of the power is reduced. Numerous research works have targeted the modification of DPM and DVFS techniques to optimize the temperature. Lee et al. 5 present a thermal control solution based on DVFS. The scaling of voltage and frequency is done on the prediction of local chip temperature. Baati and Auguin 6 use a DVFS-DPM-based temperature-aware technique, using some heuristics, to address the problem of both thermal peaks and thermal variations at the same time. Mahmood et al. 7 propose a combination of genetic algorithm (GA) and stochastic evolution algorithm to allocate and schedule real-time tasks over a DVFS-enabled processor to reduce energy and power. Nogues et al. 8 introduce a framework to design energy and temperature efficient systems. This framework allows the adaption of both DVFS and DPM according to the requirements of the application.
Scheduling based on load balancing is a very popular approach, where the tasks are shifted to relatively less busy cores to avoid temperature peaks. 9 Kursun and Cher 10 introduce a temperature-estimation technique for multi-processor systems using already available thermal sensors. The technique reduces the thermal heating without degradation of performance. The technique reduces the thermal imbalances between the cores by using the on-chip thermal sensor’s generated temperature variation map in multi-core system. The information is used to address the variation in temperature at run time. It lowers the overall temperature by 4.5°C. Salamy 11 presents a temperature-aware scheduling technique for multi-core embedded systems. The technique uses an optimal integer linear programming (ILP) formulation and sub-optimal solutions based on a GA. Merkel et al. 12 present a temperature-aware scheduling that balances the energy consumption among the cores in order to avoid the thermal gradients in the multi-core system. The technique observes the nature of the tasks, and the workload is shifted on the bases nature of tasks to avoid processor throttling. Bashir et al. 13 present a thermal-aware technique using the principal of load balancing that addresses the thermal emergencies while reducing the switching time between the cores. This is done by estimating the temperature patterns based on the recorded thermal history of similar task sets. However, this is a static technique and cannot be used for an unknown set of tasks. The authors modified this static method into a dynamic technique where the temperature is measured at run time. 14 This online temperature measurement is consequently used for prediction of temperature for reducing the switching time as well as the thermal emergencies.
Due to increasing use of heterogeneous architecture in multi-processor systems, a number of researchers have addressed the thermal issues in such systems. Zhou et al. 15 present a thermal-aware task-scheduling technique for energy minimization in heterogeneous multi-processor system on chip. The first stage of this technique analyses the energy optimality, and the second stage investigates the peak temperature and leakage power. Alsubaihi and Gaudiot 16 propose a thermal and power-aware technique named PETRAS for heterogeneous environment. It improves the system performance by considering task mapping, core utilization, and threads allocation in the scheduling policy. Alsafrjalani and Adegbija 17 present a temperature- and energy-aware scheduling algorithm names TaSaT for heterogeneous and re-configurable hardware. The algorithm reduces the thermal issue without any prior knowledge of the task set without compromising the performance. The technique allows an intelligent selection of available cores to reduce static and dynamic power.
A number of power-aware techniques have been proposed for directed acyclic graph (DAG)-based applications. An energy-efficient scheduling approach on multi-core systems for real-time tasks is proposed by Guo et al. 18 It efficiently assigns the workload and controls the execution pattern for economizing the power without violating any deadline. The authors also extended the same concepts on sporadic DAG-based tasks with implicit deadline. 19 The technique reduces the power consumption by more than 60% when compare to the simple DAG-based schedulers.
Iranfar et al. 20 propose a scheduling technique to avoid thermal emergencies in multi-core systems. In this approach, core consolidation and deconsolidation is performed by considering power and peak temperature. These constraints are also used to find optimal voltage and frequency settings. It improves the mean time to failure of device when compared to state-of-the-art techniques by 47%. Ahmed et al. 21 present the idea of task set characterization on the basis of their thermal utilization. They consider the increase in temperature due to the execution of a task set and use this information for providing a solution that does not cause any thermal violations in a uni-processor environment. Thereafter, they use speed-scaling technique in order to minimize the system temperature. In the extension of their work, Ahmed et al. 22 derive the sufficient and necessary condition for thermal feasibility on a single-core system and extended some results on a multi-core system. They proposed that if the computational and thermal utilization is less than or equal to 1, then a schedule is possible where all the tasks meet their deadlines without avoiding temperature thresholds using a global positioning system (GPS)-inspired fluid-scheduling algorithm. They used the PFair algorithm 23 for scheduling of tasks on a single core while ignoring the pre-emptions overhead. PFair is an optimal multi-processor algorithm based on fairness; however, it incurs a lot of overhead due to the task migrations and context switches. Although Ahmed et al. 22 used PFair algorithm in the uni-processor environment, where no migration issues are faced, but still it causes a lot of context switches due to the strict fairness limits applied to each task.
In this article, we address the problem of scheduling for a set of real-time periodic tasks over a single and multi-processor system while minimizing the temperature peaks and variations without missing the deadlines. To accomplish it, we propose a modification in earliest deadline first (EDF), the most successful optimal algorithm in uni-processor environment to address the thermal issues without disturbing the optimality of the algorithm. This is done by introducing a factor of fairness in the algorithm. The proposed algorithm achieves the same level of fairness as proposed by Ahmed et al.; 22 however, it significantly lowers the task switching. Although the technique is proposed for the uni-processor platform, the results can eventually be used in partitioned scheduling algorithms for the multi-processor environment. Partitioned scheduling converts the multi-processor scheduling problem in multiple uni-processor scheduling problems and then solve it using a uni-processor scheduling technique.
The main contribution and significance of this work are as follows:
The proposed technique reduces the temperature peaks, temperature temporal and spatial gradients in the multi-core system.
The proposed technique incurs less computational overhead than the techniques based on the same amount of fairness.
The proposed technique does not require any specific hardware for implementation and thus can be used in different type of computational resources which are quite likely in IoTs.
The rest of the article is organized as follows. Section ‘System model’ presents the system and power model. Section ‘Relevant terminologies’ describes necessary terminologies while the proposed Fair-EDF algorithm is discussed in section ‘Fair-EDF’. Section ‘Results’ discusses the simulation setup and results. Concluding remarks are outlined in section ‘Conclusion’.
System model
Task model
We consider a set τ, composed of N independent, synchronous and periodic tasks, to be scheduled on a single processor. The tasks have implicit deadlines, that is, the time period is equal to the deadline. Each task Ti is characterized by a worst case execution time Ci and a time period Pi. It means that the arrival of two successive jobs of Ti is exactly separated by Pi time units, and each job must be executed for Ci time units before the next job arrives. The utilization factor of Ti is defined as ui = Ci/Pi. U is regarded as the total utilization factor of the system and is equal to the sum of individual utilization factor of all the tasks in the system as expressed in equation (1)

Power model
The power model by Jejurikar et al. 24 is used in this research work. The power of each core in this model is expressed by equation (2)

The dynamic part of the power is the function of operating frequency and the voltage used in the system and is given by equation (3)

where C represents the switching capacitance, F is the switching frequency, and V is the supply voltage. The static component of power is also termed as leakage power. The leakage power is significantly increased by high temperature. The effect of temperature on leakage power is expressed in equations (4) and (5)

where IL is the leakage current, IL is a function of temperature and is expressed in equation (5)

where a is the switching capacitance, T is the temperature of the operation; IO is the leakage current at reference temperature TO. Leakage current has an exponential relation with the temperature that results in an exponential increase in the static power. Moreover, the total power consumption of system also is enhanced. Therefore, the chip temperature is directly affected by variation in ambient temperature.
Energy consumption on any given period of time [g, h] can be calculated by using equation (6)

Thermal model
We have used the thermal model of the chip as defined by analytical model of temperature in microprocessors (ATMIs). 25 Like most other temperature models, ATMI is a linear temperature model. It defines two layers of chip, one of silicon and the other layer consists of L × L metal dimension. User must define the necessary parameters including the dimension of each layer, their thermal conductance and value of their thermal diffusivity. The parameters corresponding to silicon and metal layers are also set. The impact of edges and interface material between layers is not considered in ATMI. It is modelled by conductance as expressed in equation (7)

where ki and hi denote the thermal conductivity and conductance of interface material, respectively, while di denotes the measured thickness of the interface. The ambient temperature is assumed to be uniform. The ambient temperature is not the part of the ATMI model and is added to get absolute value of temperature.
ATMI uses core functions to get transient temperature response against power and steady-state response is obtained by applying principle of superposition. Heat equations are introduced to model steady-state and transient temperatures

where b is specific value of thermal parameter which is dependent on hardware, and TS is the steady-state temperature. By solving equation (8) for T(0) = TAMBIENT and T(∞) = TS

After the calculation of thermal parameters, the temperature of each core is estimated in the model based on the principle of superposition. We can notice that the thermal behaviour of each core is different from that of other cores depending on application task set. Furthermore, to limit the temperature from exceeding a certain temperature, the feature of throttling thermal mechanism is also included in ATMI.
Relevant terminologies
The following concepts will be helpful to understand the proposed algorithm.
Server
A server S is a virtual task in the system with maximum utilization factor US of 1. The concept of the server was first introduced by Regnier et al. 26 It comprises the real tasks as its clients. When a server is running, actually one of its client tasks is using the processor. The utilization factor of server US is sum of individual utilization factor of the clients. If there are n client tasks in a server then utilization factor of the server US is given by the following equation (10)
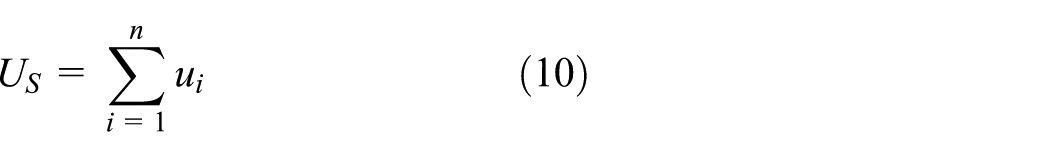
Fairness
The concept of fairness is basically derived from the idea of fluid schedule. The core idea of fairness is to enforce task execution by controlling the deviation from the (ideal) fluid schedule. Such deviation is measured for a task by a parameter lag which is equivalent to an allocation error 23 .
Definition (fluid schedule): a scheduling plan is said to be fluid if at any time t ≥ 0, a task Ti has been executed for exactly ui × t units of time.
Definition (lag): The lag of task Ti at time t is the difference between the amount of time units actually executed by Ti until time t (i.e. Ci (t)) and the amount of time units it would have executed in the fluid schedule by the same instant t

where
The fairness can be varied by relaxing or tightening the value of lag as per requirement.
Fair-EDF
Fair-EDF is an improved form of EDF algorithm. It works in two steps:
The execution of task set in Fair-EDF is considered as execution of server task S. Since the EDF is an optimal uni-processor algorithm, the maximum load cannot be higher than the capacity of a single processor. Hence, only one server is required for the whole task set on a single processor.
The condition of lag is applied to utilization factor of the server US at each time unit during the execution. If US is the total utilization factor of a server, the value of the lag of the server can be written in the form of following equation

where
Definition (Fair-EDF): a schedule is called Fair-EDF if at any time t ≥ 0, for a server S,
The introduction of fairness by controlling the value of lag in Fair-EDF results in uniform distribution of workload over time which lowers the temperature peaks and temperature variations at the same time. Each task in the task set executes at approximately uniform rate inside the umbrella of a server. This causes the Fair-EDF to work as non-work-conserving algorithm in different to that of EDF which is work-conserving algorithm. The scheduling decisions, which define the sequence of execution of client tasks, are taken under the principal of EDF. In Fair-EDF, the number of pre-emptions and context switches will less than the PFair 22 because the constraint of the lag is applied to each task at every instant of time in PFair. However, in the case of Fair-EDF, it is applied only to the server that reduces the number of context switches. The pseudo code of Fair-EDF is defined in Algorithm 1. In classical EDF, the tasks are sorted with respect to earliest deadline at each scheduling event and the task with lowest deadline is assigned the processor. In Fair-EDF, the lag value for the server task is computed at each tick of time and thereafter the decision is taken whether to continue execution or to pre-empt it. This is mentioned at line 6 of the algorithm. The control on the execution pattern by adjusting the lag value results in uniform execution of time. Figure 1 shows the scheduling of a task set mention in Table 1 on a single processor. The value of US is 0.5. The workload is concentrated in EDF while Fair-EDF is uniformly distributed over the time. The uniform execution of the workload in Fair-EDF is achieved at the rate of higher computational overhead and the raised number of pre-emptions than that of basic EDF scheduling. The cost of pre-emption is assumed to be zero in this work.


Schedule under EDF and Fair-EDF at 50% utilization factor on a single processor.
Task set configuration.

Properties of Fair-EDF
Theorem 1
Fair-EDF is optimal in all scheduling problems where the EDF is optimal

The Fair-EDF performs the scheduling of a task set on a processor such that at any given time t, accumulated time allocated to a server with utilization factor US is either
Corollary 1
The server S will meet the deadline if it follows Fair-EDF.
When a server is running, actually one of its client tasks is running on the processor. Suppose, H is the hyper period of the task set in the server which can be regarded as the time period of the server. The sever S requires US*H, units of time at t = H. The lag function can be rewritten as equation (14)

where E is the total number of task set units to be completed in hyper period H. Both E and
Corollary 2
All the client tasks of server S will meet their individual deadlines by following Fair-EDF.
The individual utilization factor of any client task ui cannot be more than the server utilization factor US, and EDF is used for their internal scheduling. Therefore, each client task will definitely meet its deadline if the server meets the deadline.
Results
A statistical approach has been used to evaluate the strength of Fair-EDF by testing it over different target applications in uni-processor as well as multi-processor environment. In the multi-processor environment, a partitioned algorithm based on Fair-EDF has been evaluated. The performance has been evaluated on the basis of efficiency of an algorithm to reduce temperature peaks, variation and averages for the same set of task sets. A parameter of the spatial gradient is added in case of multi-processor environment. The spatial gradient is defined as the temperature difference between the hottest and the coolest cores at any given time.
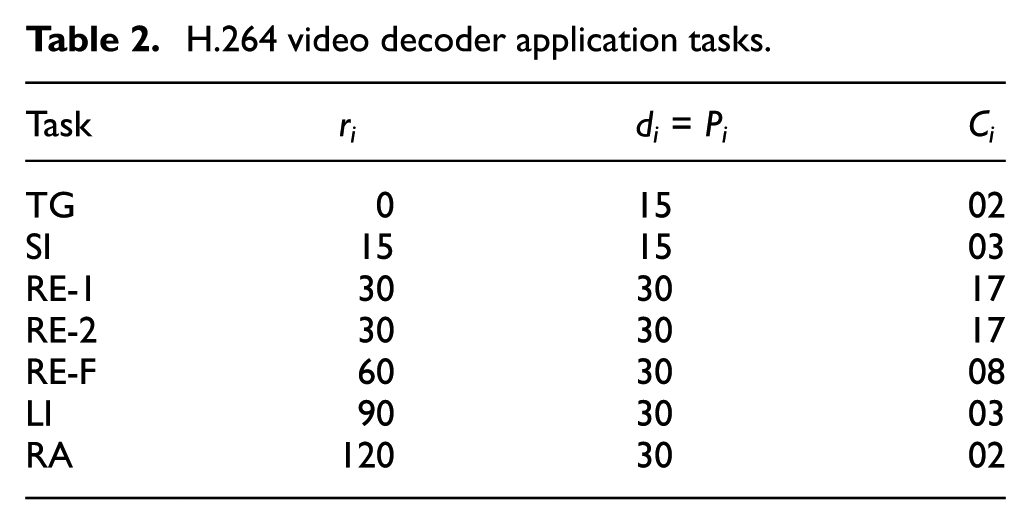
The simulation setup comprises a scheduling Simulation TOol for Real-time Multi-processor scheduling (STORM) 27 and a thermal modelling tool ATMI. 25 The duration of each simulation is 800 s. We used Roger Stafford’s 28 randfixedsum algorithm to generate the task set of variable total utilization factor for the evaluation process. A MATLAB implementation of the algorithm is publicly available with all necessary documentation. We also tested the algorithm on for H.264 video decoder application with eight tasks. Table 2 gives the complete task set of H.264 and their parameters.
H.264 video decoder application tasks.
Uni-processor platform
Figure 2(a) and (b) shows a comparison of average thermal behaviour of EDF and Fair-EDF on synthetic task set at 45% and 60% total utilization factors U, respectively. The results show that Fair-EDF always gives equal or better performance than EDF algorithm in controlling the thermal issues. Fair-EDF reduces the temperature peaks up to 5% at different values of total utilization factor U. The Fair-EDF also always incurs less or equal temperature variations when compared with the EDF. This is due to the work-conserving behaviour of EDF which introduces large idle intervals after completion of assigned workload. The Fair-EDF gives better performance when the processor is relatively less busy. With an increase in the value of total utilization factor U, Fair-EDF has less room for improvement. The performance of Fair-EDF is better at 45% in Figure 2(a) than at 60% in Figure 2(b). When the processor utilization becomes U = 1, the processor always remain busy and Fair-EDF works exactly the same as EDF algorithm.

(a) Thermal profile of EDF and Fair-EDF at 45% workload and (b) thermal profile of EDF and Fair-EDF at 60% workload.
Figure 3(a) shows the comparison between EDF and Fair-EDF at 75% total utilization factors, while Figure 3(b) shows the comparison between the two same algorithms for H.264 video decoder application with eight tasks at 45% total utilization factor. The results show that Fair-EDF outperforms EDF in both cases. However, the performance of Fair-EDF is relatively better at lower utilization factor.

(a) Thermal profile of EDF and Fair-EDF at 70% workload and (b) thermal profile of EDF and Fair-EDF with video decoder application.
Multi-processor platform
Figures 4 and 5 show a comparison of average thermal behaviour of partitioned algorithm based on proposed Fair-EDF with thermal balancing policy algorithm, 29 predictive thermal management policy 30 and global EDF at 25% and 45% total utilization factors U over four cores system. We have compared the algorithms on the basis of temperature temporal gradient, temperature spatial gradient and average core temperature.

(a) Thermal profile of partitioned algorithm (Fair-EDF) at 25% workload on four cores multi-processor system, (b) thermal profile of global EDF at 25% workload on four cores multi-processor system, (c) thermal profile of PDTM at 25% workload on four cores multi-processor system and (d) thermal profile of TBP at 25% workload on four cores multi-processor system.

(a) Thermal profile of partitioned algorithm (Fair-EDF) at 45% workload on four cores multi-processor system, (b) thermal profile of global EDF at 45% workload on four cores multi-processor system, (c) thermal profile of PDTM at 45% workload on four cores multi-processor system and (d) thermal profile of TBP at 45% workload on four cores multi-processor system.
Temperature temporal gradient
Temperature temporal gradient is the variation of temperature on any core with respect to time. It negatively affects the performance of the system. The thermal variation on any single core of the multi-core system in case of partitioned algorithm is comparable with thermal balancing policy. Moreover, partitioned algorithm incurs significantly less temporal gradient than both global EDF algorithm and predictive thermal management policy. This trend is valid both for 25% and 45% total utilization factors. However, the lesser the workload the higher the performance gap between the partitioned algorithm and other algorithms. The temporal gradient/100 s for partitioned algorithm based on Fair-EDF is 1.5°C and 2°C at 45% and 25% total utilization factor, respectively, which is better than the performance of other algorithms in this regard. These results are summarized in Table 3.
Maximum value of temporal gradient/100 s interval in any of the four cores.

TBP: thermal balancing policy; PDTM: predictive thermal management policy; EDF: earliest deadline first.
Temperature spatial gradient
Spatial gradient is the temperature difference between the hottest and the cooling cores of multi-core systems at any particular moment. The results in Figures 4 and 5 show that partitioned algorithm based on the proposed Fair-EDF outperforms all the other algorithms in this regard. The reason being that Fair-EDF ensures stable thermal problem of each core; hence, lowers the value of spatial gradient. This trend is valid both for 25% and 45% total utilization factors. Table 4 gives the maximum value of spatial gradient at any given time. The spatial gradient for partitioned algorithm is 3.5°C and 2°C for 45% and 25% total utilization factors, respectively, which is better than the performance of other algorithms in this regard.
Maximum value spatial gradient in four core multi-processor system.

TBP: thermal balancing policy; PDTM: predictive thermal management policy; EDF: earliest deadline first.
Average core temperature
Table 5 gives the average temperature of all the four cores in multi-processor system after 100 s. The partitioned algorithm based on the proposed Fair-EDF algorithm gives equal or lower average temperature than other algorithms. The partitioned algorithm gives an average temperature of 56°C when total utilization factor is 25% and 60°C when total utilization factor is 45%.
Average temperature of four cores in multi-processor system.

TBP: thermal balancing policy; PDTM: predictive thermal management policy; EDF: earliest deadline first.
Conclusion
This article presents Fair-EDF, a temperature-aware scheduling algorithm for uni-processor platform. It improves the thermal stability of EDF algorithm by adding the fairness for smooth execution of workload without violating the optimality of the classical EDF algorithm. The proposed algorithm is evaluated for temperature peaks, variations and the average temperature in uni-processor system and is assessed for temperature temporal gradients, temperature spatial gradients and average temperature in a multi-processor environment. The results verify the efficiency of the proposed algorithm. It reduces the temperature variations, average temperature and temperature peaks up to 5% in uni-processor environment. In the case of multi-processor environment, it performs better than the predictive thermal management policy, thermal balancing policy and the global EDF. It gives maximum 2°C per 100 s temporal gradient, and maximum 3.5°C of spatial gradient. The algorithm is more effective at lower values of utilization factor and become lesser efficient at higher values of utilization factor. Moreover, the technique is pure software-based solution and does not require any specific hardware which makes it suitable for use in diverse environment of IoTs.
Footnotes
Handling Editor: Suleman Khan
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.