
Abstract
Mobile application (simply “app”) identification at a per-flow granularity is vital for traffic engineering, network management, and security practices. However, uncertainty is caused by a growing fraction of encrypted traffic such as Hypertext Transfer Protocol Secure. To address this challenge, we have carefully analyzed mobile app traffic (mainly including Domain Name System, Hypertext Transfer Protocol, and encrypted traffic such as Secure Sockets Layer and Transport Layer Security) and observed that (1) the sets of server hostnames queried by different apps are distinguishable; (2) mobile apps may query multiple server hostnames simultaneously, that is, apps may send several Domain Name System lookups within a short time interval; and (3) the encrypted traffic may be similar to various other network flows generated by the same app. Based on these three observations, in this article, we propose a novel app identification methodology for encrypted network flows. To be specific, temporal, lexical, and metadata similarity are investigated to select correlated traffic and information retrieving techniques are adopted to identify apps. We ran a thorough set of experiments to assess the performance of the proposed approaches. The experimental results show that the identification accuracy can be as high as 95%, and the proposed methods have low storage requirements as well as fast training speeds.
Keywords
Introduction
In the era of mobile edge computing and the Internet of Things (IoT), the mobile platform is becoming the gateway to the IoT. The sensors and numerous wireless radios installed on mobile devices help us seamlessly communicate with various other IoT devices. The IoT devices can further be conveniently controlled by mobile apps. As an example, the Samsung Smart Home app provided in the Google Play Store enables users to easily connect with various Samsung home appliances, including refrigerators, washers, air conditioners, and more through mobile phones. 1 Indeed, almost all new IoT products come with smartphone apps to control them. 2 Today, these feature-rich mobile apps are the center of the IoT world. 3
However, since a majority of mobile apps access the Internet (the mobile apps already account for 49% of Internet traffic 4 ), they are bringing new challenges to end-to-end security protection for IoT and mobile devices. 5 For instance, mobile apps use obfuscated but not encrypted communications to change smart plugs’ states, and thus they are vulnerable to device spoofing attacks. 6 Mobile apps may also threaten IoT user privacy and data security. As reported by Check Point, 7 the suspicious app (DU Antivirus Security 3.1.5) collects unique identifiers, the contact list, call logs, and the location of the device, and then encrypts these data and sends them to a remote server for later use by another app. In addition, malicious mobile apps can also have a dramatically increasing influence on traffic and potentially lead to network congestion incidents. 8 In fact, as illustrated in the recent Android malware survey, 9 mobile devices are exposed to more infection venues than traditional PCs and mobile worms are capable of propagating across network domains more easily. Therefore, to perform key network management tasks and IoT security protection, it is vital to be able to identify mobile apps from network traffic for further security analysis, which is also known as the app identification problem. 10
For traditional computers, network traffic classification and identification is not a new area of research.11,12 However, for mobile devices, app identification on the network, especially identifying for each flow, is more difficult. The most important challenge is that apps deliver their data predominantly using Hypertext Transfer Protocol (HTTP)/Hypertext Transfer Protocol Secure (HTTPS) and may contact the same content or ad servers, so port-based and Internet Protocol (IP)-based methods will fail. For the same reason, traditional approaches13,14 for identifying desktop applications are too coarse grained for mobile apps. To address this problem, several recent studies15–19 have been conducted and various types of identification techniques have been proposed. However, most of them have been focused on plaintext flows (e.g. HTTP) and have attempted to extract identification features from HTTP headers. For encrypted network traffic such as HTTPS, the packet payload is encrypted and thus cannot be inspected to help identify the app that the traffic originated from. AppScanner, introduced in the literature 19 and extended in the literature, 20 attempts to identify mobile apps from their encrypted network traffic by machine learning algorithms. However, the classification models’ training and updating are costly tasks.
In this article, we propose a novel app identification methodology for encrypted network flows. The basic idea of the proposed methodology is traffic correlation, and it is based on several facts that have been observed in practice: (1) the sets of server hostnames queried by different apps are distinguishable; (2) mobile apps may query multiple server hostnames simultaneously, that is, one app may send several Domain Name System (DNS) lookups within a short time interval (usually less than 1 s); and (3) the encrypted traffic may be similar to various other network flows generated by the same app. In this work, we define the network traffic generated by the same app as correlated traffic. Generally, for an encrypted flow, we can use its correlated traffic (e.g. DNS and HTTP flows) to identify the corresponding mobile app. And the correlated traffic for each encrypted network flow can be determined based on these three observations.
To be specific, temporal, lexical, and metadata similarity are investigated to select correlated traffic and information retrieving techniques are adopted to identify apps. For encrypted network flows, the server-side IP addresses of which are resolved by DNS lookups, we use temporal and lexical similarity to cluster correlated DNS queries and extract server hostnames. For encrypted flows established directly via IP addresses, we first retrieve correlated network flows by considering similar flow metadata, such as the IP address, flow starting time, packet sizes, and intervals. After that, the server hostnames of these correlated network flows are obtained. With these server hostnames, we propose the use of keyword matching techniques to identify apps efficiently. We ran a thorough set of experiments and the experimental results show that the identification accuracy is as high as 95% with low false positives (FPs). Our main contributions are the following:
Provision of a lightweight and efficient framework for identifying the corresponding mobile apps of encrypted network flows by traffic correlation;
Exploitation of DNS queries as identification features and use of information retrieval techniques to determine a match;
Outlining of a method for clustering correlated DNS queries with traffic timing characteristics and lexical similarity of hostnames;
Proposal of a flow-based method for retrieving similar network traffic.
Compared with our previous work, 21 we add necessary background information, give a more detailed description and illustration of the proposed methodology, refine the process of DNS clustering and similar traffic retrieval, and conduct more performance evaluation in this article.
The rest of this work is structured as follows. The preliminaries, including the app identification problem, general mobile app structure, and network communication steps, are introduced in the section entitled “Preliminaries.” In the section “Related work,” we discuss relevant related work in detail. The section “Mobile app traffic observations” uses a few examples to illustrate the mobile app traffic observations and motivate the development of our approaches. The basic idea, challenges, and specific methods are presented in the section entitled “Methodology.” Experimental evaluation of the proposed methods from an accuracy standpoint is presented in the section “Evaluation.” Our observations throughout this work are also discussed in this section. Finally, in the section “Conclusion,” we conclude the article.
Preliminaries
App identification problem
Formally, the app identification problem can be described as follows. Denote
In particular, we study the problem of app identification for encrypted network flows in this work. Suppose that
Mobile app structure
Analysis of the mobile app structure can help us understand the characteristics of mobile apps network traffic, which will be described in the section entitled “Mobile app traffic observations.” As investigated by Statista, Android accounts for more than 86% of the global mobile OS market as of the first quarter of 2017. 22 Therefore, in this work, we mainly focus on the Android platform since its popularity and huge market share.
Typically, an Android app consists of separate screens called activities. Shortly, an activity is a single, focused thing that the user can do. Each activity contains a set of graphical user interface (GUI) elements, such as pop-ups, text boxes, text view objects, check boxes, and so on. Activities are the main interfaces presented to an end user. To interact with a mobile app, users navigate different activities by tapping and swiping, which incur transitions between activities. As an example, in Figure 1, an activity home screen shows the list of current breaking news; tapping the brief introduction of a news story will trigger the transition to another activity that displays the full news item.
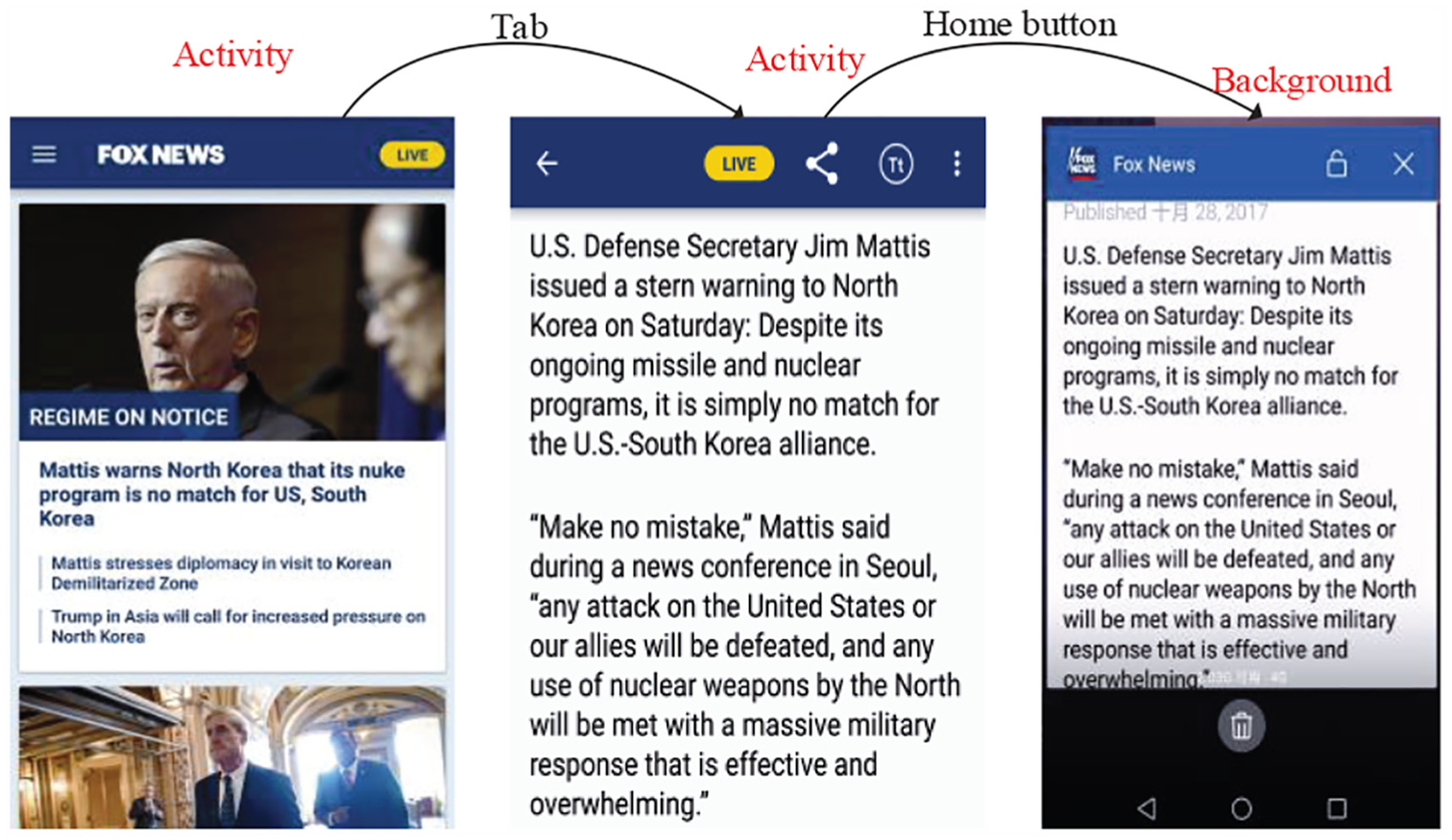
Example of the Android app structure.
When the user decides to close the current app, she may tap the home button and return to the home screen or switch to another app. Note that the exited app is still running in the background. The Android platform offers a number of ways, such as background services, for an app to perform work while it is in the background. The user can use task killers to force-quit apps, but this is not recommended since Android is designed to keep the closed app in memory to be able to quickly return to its prior state. 23
Network communications of Android apps
As described on the Android Developers website, most Android apps use HTTP and HTTPS to send and receive data. 24 Therefore, their network communications are similar to typical Internet applications such as web browsing. For mobile apps, a successful data transmission commonly consists of four steps, as depicted in Figure 2. To communicate with the remote App server, an app first resolves the server’s domain name with DNS servers. With the returned IP addresses, the app then establishes a Transmission Control Protocol (TCP) connection with the App server. This can be accomplished by Java socket programming. Finally, the HTTP or HTTPS protocol is adopted to transmit application data between the app and the corresponding servers. If the app knows the App server’s IP address beforehand, it can skip step 2 and perform steps 3 and 4 straightforwardly. That is, the process of DNS querying is optional. For the sake of distinction, in this article, we define the TCP (or User Datagram Protocol (UDP)) connection preceded by DNS lookups as common-data traffic. Note that an Android app can also adopt UDP for communication, and in step 4 an app can transmit the application data with a self-designed protocol. However, TCP and HTTP(s) are the main protocols utilized.
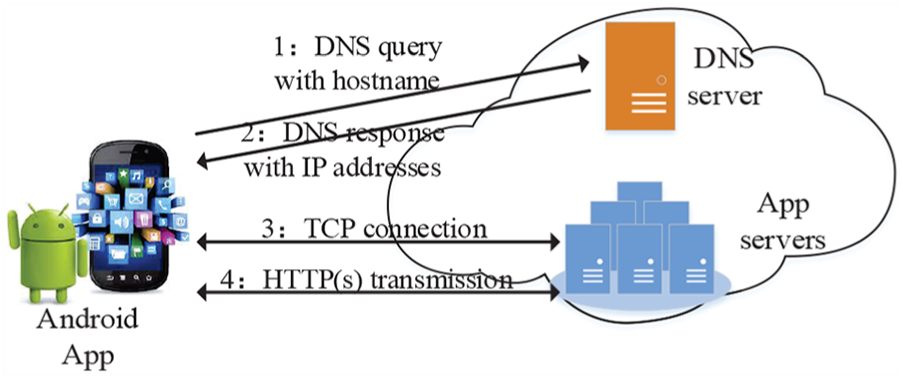
Illustration of the main steps of an Andorid app’s network communication.
Related work
Recent years have seen an increasing number of research works that analyze network traffic to identify mobile apps. As shown in Figure 2, Android apps mostly use HTTP and HTTPS to send and receive data, and thus the analysis of HTTP traffic is the popular method for identifying apps.
Xu et al. 25 used the HTTP header’s User-Agent field to identify mobile app. However, the User-Agent information is limited because it is very common to see the case where multiple apps are hosted on the same third-party hosts. To overcome this problem, Dai et al. 26 proposed a method of constructing a state machine from HTTP traffic to identify app. They first break HTTP request into method, page, and query and tokenize the HTTP flows. Then they perform agglomerative clustering of HTTP requests within each group of requests by finding structural similarities between tokens. Finally, Prefix Tree Acceptors are generated by considering the method, page-components and query-keys. Their method is accurate, but it is complicated to deploy in practice.
Recently, Xu et al. 15 proposed FLOWR, a self-learning system for identifying mobile application traffic. Similar to Dai et al.’s 26 method, FLOWR also uses metadata (the key–value pair) in the HTTP header as identification features. Key–value pairs in ad and analytic services traffic were considered as seeds, and flow regression was devised to eliminate irrelevant key–value pairs and infer app identities by scoring ambiguous key–value pairs. Ranjan and colleagues16,17 transformed the mobile app identification problem into an information retrieval problem. In their work, a per-app index document was first designed as a structured XML file with fields such as APPID, host domain name, URI, key–value pairs in the HTTP header, and misc. After that, a search engine was employed as a kernel function to generate a score distribution vis-à-vis the index documents and finally determine a match. Sun et al. 18 extracted identification features from the HTTP method, request URI, and host field and used nonnegative matrix factorization to cluster similar features into groups.
All of the research studies mentioned above were focused on HTTP flows. However, few works had been performed to identify mobile apps from encrypted network traffic. Taylor et al.19,20 proposed AppScanner to identify smartphone apps from their encrypted network traffic. In AppScanner, raw packet lengths and the statistical properties of network flows are considered as classification features. With these features, different supervised machine learning methods such as support vector machine (SVM) and random forest were further investigated for pattern recognition on flows. With postprocessing strategies, the accuracy was 96% in the best case and 73% in the worst case. However, the classification models’ training and updating tasks are costly, and need sufficient network traffic samples for model training and retraining. A previous study 27 investigated whether Android apps can be identified from their launch-time network traffic using only TCP/IP headers. Thus, their method can be applied to encrypted network traffic. However, it cannot be used at per-flow granularity.
In this article, for encrypted network flows, we provide a lightweight and efficient framework to identify the corresponding mobile apps by traffic correlation. Unlike previous work, we do not identify the encrypted network traffic directly. Instead, we try to identify its correlated traffic such as DNS and HTTP flows and the corresponding mobile app will be identified eventually. Thus, it is notably lightweight and can be deployed conveniently. The work presented in this article is an extension of our earlier conference paper. 21 We expand the previous work with a more detailed description and illustration of the proposed methodology. The DNS clustering and similar traffic retrieval are refined in the section entitled “Methodology.” The section entitled “Preliminaries” is added to formulate our research problem and elaborate the operating mechanism of mobile apps. More performance evaluation is conducted, and the proposed method is fully discussed in this article.
Mobile app traffic observations
In this section, we introduce our observations of mobile app network traffic. By cooperating with one of the biggest telecom operators in China, we have collected a large amount of mobile device network traffic (traffic of 3G and 4G networks). The traffic dataset mainly includes DNS lookups, HTTP(s) requests, and the recording timing. The total data size is more than 160 GB. To seek identification features for encrypted network flows, we first identified mobile apps by the features of HTTP requests (deep packet inspection (DPI) technology). Then we analyzed the mobile app traffic one by one and tried to identify some common features. In summary, three main observations of mobile apps traffic are obtained and they form the basis of this work.
Observation 1
The sets of server hostnames queried by different apps are distinguishable. For brevity, the term server hostnames will be abbreviated to hostnames in the following. As illustrated in Figure 3, even though the apps (com.baidu.BaiduMap and com.baidu.searchbox) are developed by the same organization (Baidu company), their hostnames are still distinguishable since the third-level domains are different. Note that different apps may query the same hostnames as reported in previous work.10,19 However, we argue that there are no different apps that will interact with all of the same servers. This is also validated by our experiments presented in the section entitled “Evaluation.” Inspired by this observation, in this article, we use the sets of hostnames as mobile apps’ identification features.
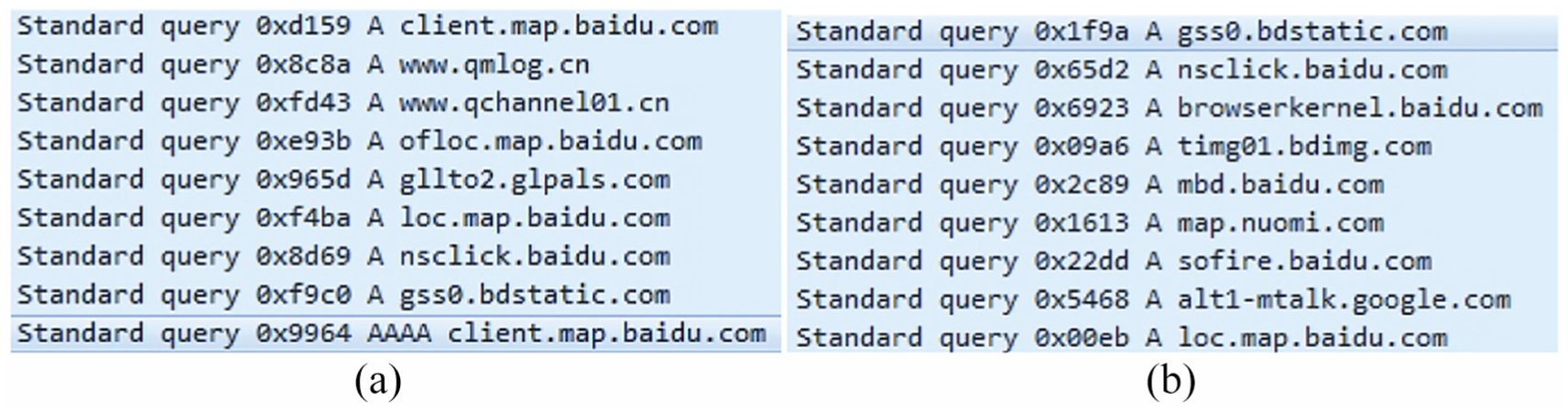
Example of DNS queries of two Android apps com.baidu.BaiduMap and com.baidu.searchbox provided by the same organization (Baidu company). Obviously, the server hostnames are distinguishable since the third-level domains are different. (a) com.baidu.BaiduMap and (b) com.baidu.searchbox.
Observation 2
Mobile apps may query multiple hostnames simultaneously, namely, an app may send out several DNS lookups within a short time interval. As shown in Figure 4, the app com.baidu.BaiduMap issues nine DNS lookups and the time intervals between them are all less than 1 s. One of the reasons could be that mobile apps should request different servers to complete their full functions. For example, an app such as com.baidu.BaiduMap might contact the servers owned by the app developers to get basic functionality. The app might also contact third-party services and in-app advertisement providers such as qchannel01.com . Meanwhile, similar to web browsing, apps may issue several DNS queries when encountering references to embedded objects, such as graphs and videos. This characteristic allows us to cluster DNS queries from the same app efficiently. Namely, we can safely assume that the concurrent DNS queries may come from the same app.

Example of DNS queries of the app com.baidu.BaiduMap. In the figure, the time intervals between successive queries are all less than 1 second. Namely, these queries are transmitted almost simultaneously.
Observation 3
The encrypted traffic may be similar to various other network flows generated by the same app. Take com.baidu.BaiduMap as an example again, a fraction of its network flows is depicted in Figure 5. In the figure, the flow “61.135.185.197” (in this example, we only use the server’s IP address to represent a network flow) was connected with a server’s IP address directly, so we cannot resort to the hostname to infer which app generated this Secure Sockets Layer (SSL) traffic. However, one can observe that its starting time is almost the same as that of the flow “119.75.222.71” (hostname: client.map.baidu.com) and that the IP address is close to “61.135.186.151” (hostname: nsclick.baidu.com). In other words, the flow “61.135.185.197” is similar to flow “119.75.222.71” and “61.135.186.152.” Taking advantage of this, one can reasonably infer that the encrypted flow “61.135.185.197” is created by com.baidu.BaiduMap because the hostnames client.map.baidu.com and nsclick.baidu.com are the identification features of com.baidu.BaiduMap (it is indeed generated by com.baidu.BaiduMap; in our experiments, we use the app Packet Capture to obtain perfect ground truth of what flows came from what app).

Example of network flows of the Android app com.baidu.BaiduMap. Note that there are several SSL and HTTP flows and that their starting times are very close.
Recall that, in this article, we try to deal with the mobile app identification problem for encrypted network traffic. More specifically, given an encrypted network flow observed from a mobile device, we try to identify which app generated this flow. Inspired by the traffic observations described above, in this article, we will achieve this by traffic correlation. The technical details will be clarified in the next section.
Methodology
In this section, we will present all of the details of the proposed method. First, the basic idea, existing challenges, and main procedure of the proposed methods are introduced in the subsection entitled “Method overview.” Then, the most important technical details including DNS clustering and similar traffic retrieval are presented in the subsections entitled “DNS clustering” and “Similar traffic retrieval.” Finally, the hostname matching for app identification is illustrated in the subsection entitled “Hostname matching and app identification.”
Method overview
Basically, the main idea of our methods can be stated as follows: the app of an encrypted flow will be the same as its correlated traffic, and the correlated traffic (such as DNS and HTTP flows) can be easily identified. Namely, if the correlated traffic of an encrypted flow can be obtained, it will be identified eventually. Therefore, the app identification problem for encrypted traffic is transformed into how to select its correlated traffic.
For our work, the correlated traffic of an encrypted network flow is defined as follows:
Definition 1. For an encrypted network flow whose server-side IP address is resolved by DNS lookups, the correlated traffic is defined as the DNS lookup flows generated by the same app.
Definition 2. For an encrypted flow established directly via an IP address, its correlated traffic is defined as similar common-data traffic generated by the same app.
In Definition 2, the common-data traffic and the similarity of traffic are defined as follows:
Definition 3. The common-data traffic is defined as TCP or UDP flows preceded by DNS lookups. Namely, its server-side IP address must be resolved by the DNS protocol, as illustrated in Figure 2.
Definition 4. The similarity of two network flows is defined as the proximity of their external features, such as IP addresses, flow starting time, packet sizes, and packet time intervals.
Because our research mainly focuses on encrypted network traffic, the flow contents are not considered in Definition 4. Based on the above definitions, for an encrypted network flow, we can extract hostnames from its correlated traffic and use hostname matching to identify the app, as supported by the traffic observation 1 described in the section “Mobile app traffic observations.”
The traffic observations 2 and 3 provide clues for the investigation of correlated traffic. For example, one can assume that traffic occurring within a short time interval is correlated. However, there are several challenges in practice. The first one is the background traffic. As illustrated in the section “Preliminaries,” background apps are still running and can connect to remote servers for purposes such as content updating. Therefore, the background traffic will be mixed with the traffic of the foreground app. This creates barriers to discovering the actual correlated traffic.
The second challenge is that different apps may connect to some of the same servers and thus query some of the same hostnames, although the entire sets of DNS queries are distinguishable. For instance, Google Ads has been found in nearly 12,000 apps in a dataset of 55,000 free apps from the Google Play Store. 28 That means that these 12,000 apps will connect to some of the same Ad servers and have overlapping DNS queries. Obviously, this complicates the hostname matching for app identification. If an encrypted flow is followed by the DNS queries of these Ad servers, it can be identified as any one of these 12,000 apps. To overcome these challenges, in this article, we investigate temporal, lexical, and metadata similarity to select correlated traffic and adopt information retrieving techniques to identify apps.
The main procedure of our proposed methodology is illustrated in Figure 6. Generally, the proposed method consists of offline training and online identification steps. In the figure, the red circled numbers are labels of the most important parts of the proposed method, that is, identification feature construction, DNS clustering, similar traffic retrieval, and hostname matching are the key functionalities for identifying apps for encrypted mobile network traffic. Also note that in Figure 6 there is a loop in the online identification, which means that the captured encrypted flows can be identified one by one.

The main procedure of the proposed method for identifying apps for encrypted mobile network traffic.
In the offline training phase, mobile apps are run on the physical devices or simulators to generate DNS queries. Meanwhile, the traffic is collected and hostnames are extracted and disposed of to create identification features. The specific steps of identification feature construction are as follows.
Identification feature construction
First, the hostnames are split by the period (“.”) except the second-level domains, thus forming domain words. We do not split the second-level domains since the top-level domains, sucn as .com are very common and cannot distinguish different apps efficiently. The repeated hostnames are also omitted. After that, these domain words are written into text documents as lines, as depicted in the right corner of Figure 6 (label ①). We refer to each line as a domain words record. Finally, for each mobile app, we will obtain a short-text document as its identification features, as illustrated in Figure 7.
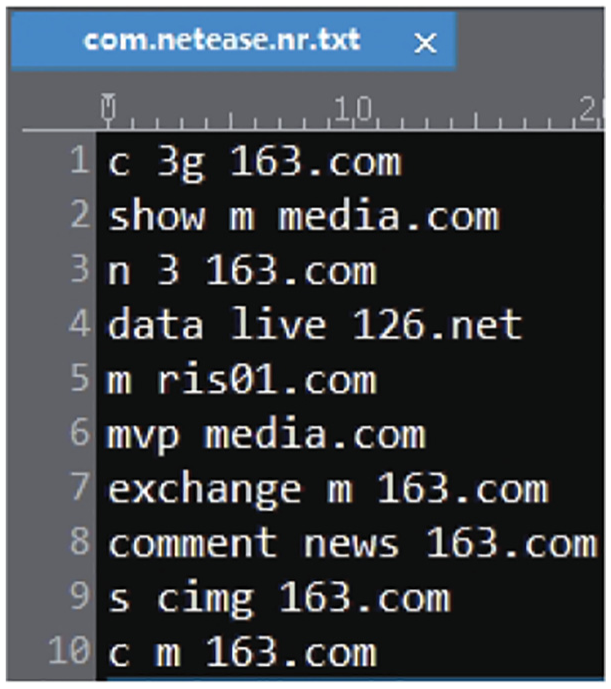
Example of identification features (short-text document) of the app com.netease.nr. Only portion of the hostnames are listed.
In the online identification phase, for the analyzed encrypted flow, we first check whether the server-side IP address is resolved by the DNS protocol or not. If it is resolved by DNS, the DNS clustering algorithm will then be applied to select correlated DNS queries. Otherwise, we will retrieve correlated common-data traffic by considering flow metadata, such as the IP address, flow starting time, packet sizes, and intervals. Finally, the app is identified by matching hostnames against short-text documents (identification features). The details of DNS clustering (label ②), similar traffic retrievial (label ③), and hostname matching (label ④) will be described in the next subsections.
DNS clustering
The clustering of DNS traffic has been studied in recent work29,30 to detect malicious domains and model client behaviors. However, the clustering purpose is unique in our work. We use DNS clustering to find the correlated DNS queries of encrypted network flows, and the main challenge is how to overcome the background traffic, as illustrated in the section “Mobile app traffic observations.” Therefore, the typical clustering methods, such as the X-means 31 and the DBSCAN algorithm 32 used in previous work,29,30 are improper for our purpose (we have tested the X-means and the DBSCAN algorithm in our experiments, and the clustering accuracies are both less than 40%).
Consequently, in this work we propose a novel DNS clustering algorithm as described in Algorithm 1 based on the mobile app traffic observations (observations 1 and 2). Generally, the main steps of Algorithm 1 are temporal and lexical similarity checking. For clustering, we repeatedly check the time interval and lexical similarity between DNS queries starting at query

Obviously, the time complexity of Algorithm 1 is
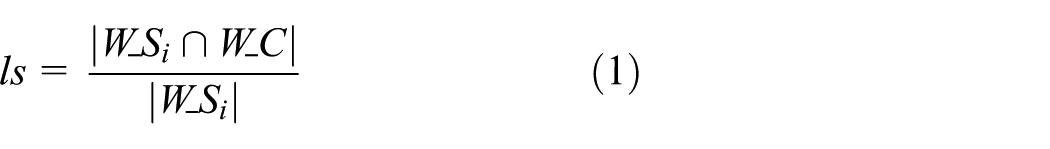
Similar traffic retrieval
For the encrypted network flow established directly via IP address, we use similar traffic retrieval 34 to choose the correlated flows, that is, the similar TCP or UDP flows that are preceded by DNS lookups. The concept of traffic retrieval is first proposed in the literature, 34 and fundamentally it is a type of similarity search based on comparing flow vectors in a feature space. Therefore, how to represent the network flows as feature vectors is one of the primary tasks, similar to typical traffic classification 35 and clustering. 36
In this work, we use the m

where
Flow statistical features.

IP: Internet Protocol.
In Table 1, the first two features are selected according to the mobile app traffic observations 2 and 3. The traffic generated by an app can be connected to different servers located in the same organization, so the server-side IP addresses may belong to the same or similar subnet. Meanwhile, mobile apps will establish several connections simultaneously, and therefore the flow starting time is close. The left features are proved efficiently in traffic retrieval. 34 In particular, we eliminate the maximum packet size and the minimum inter-packet time from flow features. In our experiments, the maximum packet size is always 1360 (the network maximum transmission unit (MTU) is 1500 bytes) and the minimum inter-packet time is always nearly 0. That means that the maximum packet size and the minimum inter-packet time are undistinguishable and should be excluded. Therefore, compared to previous work, 34 our chosen features are more optimized.
For similarity search, weighted Euclidean distance 37 is used to measure the similarity. Before calculating the distance, we use a scaling technique to bring all feature values into the range [0,1]. Feature scaling can be represented by

where
The distance between the encrypted flow

where
In equation (4), a small distance means high similarity. All TCP and UDP flows preceded by DNS lookups are ranked in ascending order according to their distance to the encrypted flow
Hostname matching and app identification
After determining the correlated DNS queries or common-data flows, the hostnames can be extracted and split, and matched against the identification features for app identification. Recall that for each app its identification features are kept as a short-text document, as shown in Figure 7. Therefore, the typical information retrieval technologies can be used and the hostname matching will work such as a search engine.
Denote the domain words record for a hostname as



Thus, the score of the domain words record W against the matching document

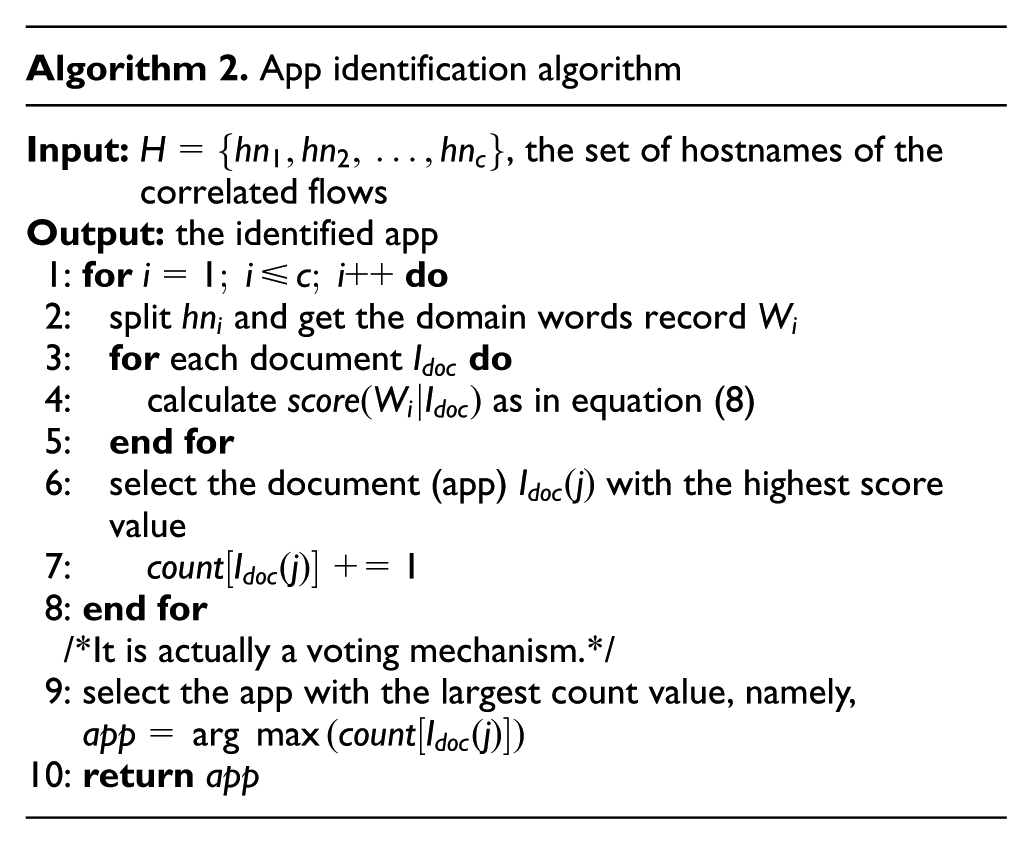
With the score value, we can implement the app identification. To be specific, for each domain words recordW, the document (app) with the highest score value will be selected as the true match. Therefore, we will have a collection of candidate apps and that with the largest counts will be the final identified app. The entire procedure of app identification is illustrated in Algorithm 2. In this algorithm, the function is completed by two for loops, and thus the time complexity is
Evaluation
Data collection
Experimental setup
Since the encrypted traffic cannot be identified by DPI technology and thus there is a lack of ground truth labels, we did not include the data collected by the telecom operators in our evaluation. Instead, we carried out the evaluation in a controlled environment. The experimental setup used for the deployment of the proposed methods is shown in Figure 8. We have configured a Ubuntu 16.04 computer as the access point and used tcpdump (http://www.tcpdump.org/) to collect network traffic. The data analysis was also completed by the Ubuntu 16.04 computer (with 4 GB memory and an Intel Pentium Dual-Core T4500 CPU). In the training phase, we installed apps on the Android Virtual Device 38 and ran a UI-fuzzing tool to simulate tap operations. Because the main goal of training is to generate identification features for apps, only the DNS traffic was collected at the access point. In the testing phase, we installed apps on an android smartphone (HUAWEI Mate 8). We chose a real phone instead of the Android Virtual Device for testing because the real phone can yield background traffic as illustrated in the section “Traffic generation.” Therefore, the experimental results will be closer to reality.

Experimental setup for the app identification of encrypted traffic.
Implementation
In our experiments, the apps were downloaded by Evozi App Downloader (https://apps.evozi.com/apk-downloader/) from Google Play and by a Python program from Wandoujia (http://www.wandoujia.com/), respectively. The downloading URLs for apps in Wandoujia are of the format http://www.wandoujia.com/apps/package-name/download , so they can be batch-processed. After that, we used the adb install command and ran a script to install the apps conveniently. The UI-fuzzing was accomplished with the help of Monkey (https://developer.android.com/studio/test/monkey.html). For details, several Monkey options including -p, –pct-majornav, –pct-syskeys, and –pct-appswitch were invoked to simulate a user’s clicks, touches, and gestures. In this way, we can obtain enough DNS traffic for each app to build its identification features. The network traffic was collected at the access point by tcpdump and the data were saved as .pcap files. Each .pcap file was fixed up to 100 MB. When packet capturing finished, the TCP and UPD flows were split by SplitCap (https://www.netresec.com/?page=SplitCap) from these .pcap files. The DNS traffic was analyzed and the hostnames were extracted by the Dshell tool (https://github.com/USArmyResearchLab/Dshell). For similar traffic retrieval, we first used tshark (https://www.wireshark.org/docs/man-pages/tshark.html) to extract the IP address, flow starting time, packet sizes, and packet interval times from network flows. Then a Python program was written to calculate the statistical features. The hostname matching was realized with the help of Solr (lucene.apache.org/solr/). We also installed the app Packet Capture (https://apkpure.com/packet-capture/app.greyshirts.sslcapture) on the phone to obtain perfect ground truth of what flows came from what app.
Traffic generation
To test the proposed methods, we need to choose several Android apps that will generate encrypted traffic. In our experiments, this was done by manual checking. We first downloaded the most popular 100 free apps from the Google Play Store and the different top 900 apps from Wandoujia, the famous app store in China. Then we installed and ran the apps one by one to check whether they had encrypted traffic. For each app, we only inspected the traffic generated at the startup to make sure that the selected apps will produce at least one encrypted flow. Finally, 100 apps were selected and tested. The categories of these 100 apps are listed in Table 2.
Categories of tested apps.

As mentioned above, the DNS traffic for identification feature construction was triggered by the automation tool Monkey. It is efficient and effective. For identification testing, the apps were installed on the phone and they were clicked one by one by human to generate network traffic. We ran each app with random clicks for 3 min. When finished, the tested app would be killed and another new app was selected to run. We repeated the entire process five times. Note that the background traffic including weather forecasting, system updating, email checking, QQ, and Webchat (QQ and Webchat are the most famous apps in China) was allowed to match the mobile user habits well. In total, there are 2305 encrypted network flows for experimenting. The data used in the experiments are summarized in Table 3. In the table, the number of DNS query flows is the data collected for training. Number of encrypted flows and Number of TCP and UDP flows represent the data quantity of encrypted and all flows captured for identification testing, respectively.
Data summay.

DNS: Domain Name System; TCP: Transmission Control Protocol; UDP: User Datagram Protocol.
Experimental results
Generally, the experimental results are divided into the following three parts:
Efficiency of using hostnames as apps’ identification features;
Accuracy, true-positive rate (TPR), and FPs of DNS clustering for app identification;
Accuracy, TPR, and FPs of similar traffic retrieval for app identification.
Here, the accuracy, TPR, and FP metrics are defined as in equations (9)–(11), respectively, where




First, we examine the efficiency of using hostnames for app identification. Recall that for each app in our experiments there is a .txt file containing domain words as its identification features, as shown in Figure 7. Therefore, the concept of distance commonly used in information retrieval is proper for our purpose. To be specific, we calculate the distance of features according to equation (13) for examination. In equation (13),

We have calculated the distances of features between the selected 100 apps by equation (13) and the typical results are listed in Table 4. In the table, the first column is the benchmark. We compare the features of the same app (com.baidu.BaiduMap) and, consequently, the result is 0. com.baidu.BaiduMap and com.baidu.searchbox are representatives of apps developed by the same organization. These types of apps may connect to the same servers. As shown in Table 4, the distance result is 0.343. This implies that their hostnames are indeed similar. However, the value is still significantly larger than that of the same app (the distance is 0). The third column stands for completely different apps and the fourth column is the apps that may share the same content distribution networks (CDNs). Obviously, their distances are both high.
Typical results of feature distance.

We have also tested the stability of hostnames as identification features. To this end, we captured DNS queries of the same apps at different times and the same apps with different versions. For testing the stability of time, we capture DNS queries with the time interval of 2 weeks. To examine the stability of different app versions, two different versions of each app are installed and ran. Similarly, the distance is calculated via equation (13). The typical experimental results are shown in Table 4. In the table, one can see that the distance values are almost close to 0, and this can be explained as the resource servers for apps are rarely changed. All the numerical results as shown in Tables 4 and 5 prove that the hostnames are efficient for the identification of apps.
Distances of the same apps for different captured time and version.

Second, the accuracy, TPR, and FPs of DNS clustering for app identification are evaluated. In total, in the captured 2305 encrypted flows, there are 1873 flows preceded by DNS lookups and 432 flows were connected directly. Thus, the experiments were carried out for these 1873 flows. Note that in Algorithm 1 there are three thresholds that need to be determined beforehand, that is, the threshold of DNS query time interval

Accuracy of DNS clustering.

True-positive rates of typical apps for DNS clustering.

False positives of typical apps for DNS clustering.
As depicted in Figure 9, the highest detection rate is 95% (correctly identified 1780 flows) when
From Figures 10 and 11, one can see that the encrypted traffic of com.zhihu.android can be most easily identified, while the encrypted traffic of com.baidu.searchbox is hard to be identified. This may be because com.baidu.searchbox has multiple partners, that is, apps developed by the same organization (BAIDU company). These apps may connect to some same servers, and thus the requested hostnames are overlapped and confused.
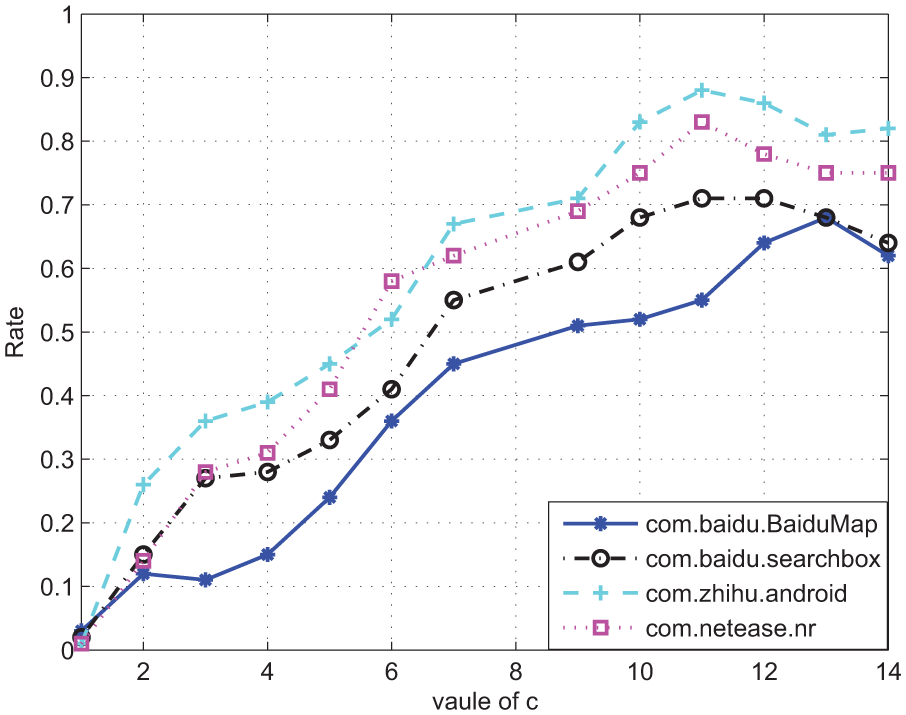
Finally, we set different values of c (from 1 to 14) in Algorithm 2 to test the accuracy of the similar traffic retrieval method. The experimental results are shown in Figure 12. As shown in the figure, the highest accuracy is 81% when

Accuracy of similar traffic retrieval.
True-positive rates of typical apps for similar traffic retrieval.

False positives of typical apps for similar traffic retrieval.
Improving performance
Accelerating the process of training
As described in the section “Traffic generation,” we generate the DNS traffic by Monkey in the training step. To make the identification features more representative, we have to run the training program long enough to collect sufficient hostnames. Although the process is automated, it is still time-consuming. In practice, we realize that we can extract hostnames from apk files directly, and thus the training process will be accelerated. In detail, we first decompile the .apk file to Java source code. This can be accomplished by a tool such as dex2jar (https://sourceforge.net/projects/dex2jar/). Then we search for the keywords “http://” and “https://” in all Java source code files and html files in the assets. Finally, we extract hostnames from the search results. Note that the static code searching is not complete, since some URLs are constructed by Java code such as “http://”+str.substring(“*.”.length()).m3587f(). Therefore, dynamically running the app is necessary, though its process can be shortened. The results before and after the improvement are shown in Table 6. The apps’ running time is significantly reduced and the dataset sizes are almost the same.
Comparison of the running time and the number of hostnames.

Improving the accuracy of the similar traffic retrieval method
As shown in Figure 12, the accuracy of the similar traffic retrieval method for app identification is significantly lower than that of DNS clustering. Inspired by recent works,15,17,18 we can further use the identification features contained in the HTTP header to improve the accuracy. To be specific, if the correlated flow (TCP or UDP flow preceded by DNS lookups) is the HTTP protocol, we identify its app by both the key–value matching 15 and hostname matching techniques. Figure 15 shows an example of key–value pairs used in our experiments. With the identification result, Algorithm 2 is changed to the following: when the domain word matching finished, the key–value matching continues. The entire process is presented in Algorithm 3.
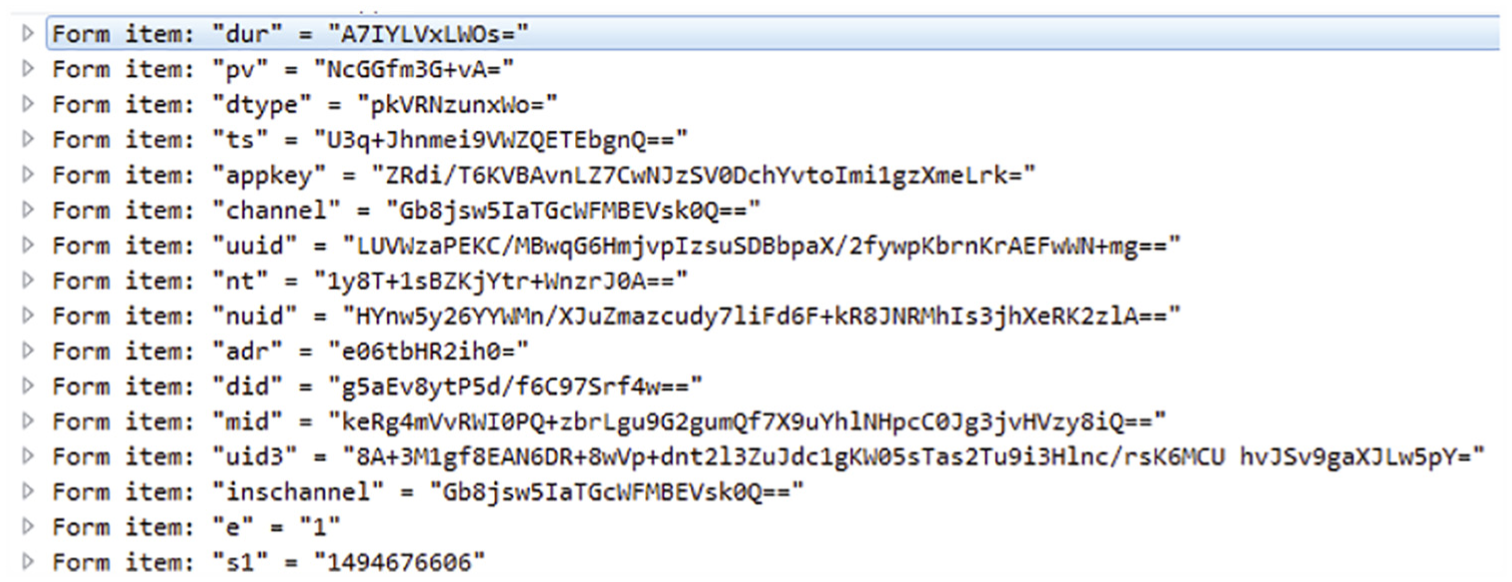
Example of key–value pairs.

We have implemented Algorithm 3, and the experimental results are depicted in Figure 16. Apparently, when compared to Figure 12, the accuracies are dramatically improved and the highest accuracy is increased from 81% to 93%.

Improved accuracy of similar traffic retrieval.
Comparison and limitations
When compared to the state-of-the-art work AppScanner, 20 the highest accuracy is almost the same, 95% versus 96%. We have also evaluated AppScanner in our dataset, and the highest accuracy is 94.7%. Thus, the accuracies of both methods are comparable. However, our method is more lightweight than AppScanner. In the training phase, we only use hostnames as identification features, and thus it is very convenient to collect and save training samples. Taking the time needed to collect training samples and the dataset size as criteria, our method and Taylor’s method are compared in Table 7. In the comparison, we use the static code search and dynamical running to collect apps’ hostnames. The needed time is nearly 120 min. Notably, the dataset size is less than 5M. We run Taylor’s method to generate data satisfied with the statistical characteristic described in the literature, 20 that is, approximately 80% of apps had 500 or more flows. The results are shown in the right column of Table 7. Obviously, our method is more lightweight and efficient. The CPU and memory consumption of our method are also limited. The CPU consumption peaks occurred while performing Algorithm 2 and were in the interval of 7% ± 1.5%. The memory consumption changes in intervals from 4042 ± 5 kB when carrying out DNS clustering and from 10,038 ± 7 kB when running Algorithm 3. Thus, the identification process has little effect on the consumed CPU and memory.
Comparison of our method and Taylor et al.’s 20 method.

Despite the high identification accuracy, low storage requirement, and fast processing speed, our proposed method has limitations. The proposed method cannot deal with encrypted flows in real time. We have to wait a period of time before searching for the correlated flows. In addition, if some background apps, such as email checking, generate few encrypted network connections in a fixed time interval, our method cannot identify them well. This is because there is almost no correlated traffic. In addition, for repackaged apps, our method will misidentify its newly added traffic.
Conclusion
In this article, we have proposed a novel traffic correlation methodology for identifying mobile apps for encrypted network traffic. Based on traffic characteristics of mobile apps, we exploited server hostnames as identification features. To determine correlated hostnames, we proposed a new DNS clustering method by considering both the flow time interval and lexical similarity. For encrypted flows without DNS lookups, a flow statistical feature–based method was outlined to retrieve similar network traffic. We have tested our methods on Android apps and the experimental results show that the identification accuracy can be as high as 95%. This demonstrates the efficacy and feasibility of our methodology. A preliminary study of iOS and Windows Mobile gives us confidence that the proposed approaches can be extended to these platforms. We propose these as future work.
Footnotes
Handling Editor: Gary Leavens
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Technologies Research and Development Program of China under grant no. 2018YFD0401404, by the National Natural Science Foundation of China under grant nos 61702282, 61802192, 61502250, and 71801123, by the Natural Science Foundation of the Jiangsu Higher Education Institutions of China under grant nos 17KJB520023 and 18KJB520024, by NUPTSF under grant no. NY217143, and by Nanjing Forestry University under grant nos GXL016 and CX2016026.