
Abstract
In order to solve the problem of multi-tag anti-collision in radio frequency identification systems, a multi-tag anti-collision protocol based on 8-ary adaptive pruning query tree is proposed in this article. According to Manchester code, the highest collision bit can be detected. In the process of tag identification, the protocol only locks the target on the three consecutive bits which start from the highest collision bit. The protocol has two tag identification mechanisms, and which one is chosen is determined by the value of collision coefficient. Using the collision information characteristics of the three bits, idle timeslots are evitable, and some collision timeslots are eliminated at the same time. The 8-ary adaptive pruning query tree protocol fully takes into account several important performance indicators such as the number of query timeslots, communication complexity, transmission delay, and throughput. Both theoretical analysis and simulation results show that this protocol performs better than other tree-based anti-collision protocols. The throughput of 8-ary adaptive pruning query tree protocol remains approximately 0.625.
Keywords
Introduction
Radio frequency identification (RFID) 1 is one of the most crucial technologies for the Internet of Things (IoT). Applications of RFID are very extensive, especially in the fields of warehouse management, smart environments, 2 treatment, 3 bank cards, industrial surroundings, 4 medical device positioning, 5 and so on. The technology has been incorporated into our daily life and work. Though it has a wide range of applications, there are still many challenges to be tackled. In an RFID system, there are usually one or more readers and multiple tags. Every reader has its own specific communication frequency channel. Since tags cannot communicate with each other, they send their information merely on their own schedule. It leads to collisions when readers and tags transmit data on the same channel simultaneously.
There are usually two types of collision in an RFID system, including reader collision and tag collision. The former is more detailed and classified into two types: reader-to-tag collision and reader-to-reader collision. Reader-to-tag collision, as is shown in Figure 1(a), occurs when a single tag exists in the working area of more than two readers. 6 These readers communicate with the tag simultaneously. In this case, the tag is confused about which reader it should respond to. And then, according to Figure 1(b), frequency interference among readers may occur if there are several readers in an RFID system and their working areas are overlapping. In other words, when a reader transmits data to a certain tag, the data are interfered by the communication of the other readers within the reader’s interference range. 7 This kind of collision is called a reader-to-reader collision. The last one, in Figure 1(c), is tag collision, which is also available to call it a tag-to-tag collision. This case occurs when several tags are located in the working area of one reader and communicate with the reader at the same time. Therefore, the reader cannot identify any tag. These three kinds of collision can trigger identification delay, system throughput decline, and other issues. 8 Thus, proposing an effective anti-collision strategy is crucial for improving the performance of RFID systems.

Three types of collision in RFID systems: (a) reader-to-tag collision, (b) reader-to-reader collision, and (c) tag-to-tag collision.
This article focuses on the tag collision. In the scene of mobile RFID systems, some researchers proposed many excellent protocols, such as the efficient bit-detecting (EBD) protocol which was proposed by LJ Zhang et al. 9 has a high identification efficiency. However, in many scenes of life, it is also important to ensure a great identification performance for non-mobile RFID systems. Taking the system complexity and application cost into consideration, the anti-collision protocol based on time division multiple access (TDMA), which is the most widely used protocol, has more practical application value and can detect the collision among multi-tag. It is mainly categorized into two types: probabilistic anti-collision protocols based on Aloha10,11 and deterministic anti-collision protocols based on trees. 12 The former includes slotted Aloha, 13 frame-slotted Aloha (FSA), 14 dynamic frame-slotted Aloha (DFSA), 15 and so on. The latter contains binary search (BS) protocol, 16 query tree (QT) protocol, 17 collision tree (CT) protocol, 18 and so on. For the Aloha-based anti-collision protocols, many improved protocols have been proposed in these years. M Mayer and N Goertz 19 designed a novel scheme of RFID tag identification with compressed sensing techniques, and simulations show that this new scheme significantly outperforms FSA protocol regarding identification speed and noise robustness. YR Chen et al. 20 proposed a novel sub-frame-based DFSA protocol, which can improve the system utility to approximately 0.36 and reduce the computation complexity. V Namboodiri and LX Gao 21 proposed three novel protocols which combine the idea of binary tree search protocol with that of FSA protocol and developed an analytical framework to predict the performance of their protocols in terms of the average reader energy consumption, average tag energy consumption, and so on. Through simulation analysis, these three protocols can significantly reduce reader and tag energy consumption. P Solic et al. 22 studied a valid tag quantity estimation method and an early frame interruption strategy to significantly improve the throughput. However, the Aloha-based anti-collision protocols exist the problem of tag starvation, 23 and the deterministic protocols can identify tags one by one according to a certain rule which avoids the occurrence of tag starvation. Simultaneously, in another aspect, the deterministic protocols increase the total number of tag identification timeslots to a certain extent.
In this regard, many scholars in related fields proposed many excellent tree-based anti-collision protocols. XL Jia et al.
24
proposed an improved protocol based on QT protocol, which is named CT protocol. CT protocol only focuses on collision bits and group tags according to the highest collision bit in each query. This protocol improves the identification efficiency of RFID systems and reduces some unnecessary idle timeslots. Since CT protocol only adds one bit after each original query prefix to form a new query prefix in each query, the identification process is slow and requires the transmission of a large number of redundant bits. L Pan and HY Wu
25
proposed the smart trend-traversal (STT) protocol which uses a smart trend-traversal method to reduce the number of collisions in QT protocol. Although STT protocol improves the disadvantages of tree- and Aloha-based protocols, it also increases the number of idle timeslots. Then, 4-ary pruning query tree (A4PQT) protocol
26
sought to improve 4-ary QT protocol. After pruning the 4-ary tree, to some extent, it reduces some idle timeslots and collision timeslots, but for the case of the reader receiving two consecutive collision bits, there also exist many extra idle timeslots. J Shin et al.
27
proposed an M-ary query tree (MQT) scheme. The first m bits except query prefixes are converted to
Aiming at the shortcomings of the existing tree-based protocols, a multi-tag anti-collision protocol based on 8-ary adaptive pruning query tree (EAPT) is proposed in this article. EAPT protocol is applicable to the RFID systems operating in the frequency band of 860– 960 MHz. In this article, the concept of collision coefficient should be the first attempt to be proposed. Two query mechanisms are used in EAPT protocol, and which one is chosen is determined by the value of collision coefficient in each query. Thus, the reader can adaptively select the bifurcation method, and using the collision information characteristics, XOR operation grouping rules, and the code conversion mechanism, the protocol can generate effective query prefixes, thoroughly prune plenty of extra idle timeslots adaptively, and reduce some collision timeslots. At the same time, the newly generated query prefixes end up with the bit before the next highest collision bit in each query and the total number of bits transmitted is significantly reduced. These can further optimize the existing tree-based protocols. Therefore, EAPT protocol greatly improves the identification efficiency of RFID systems.
The rest of this article is organized as follows. Section “Related work” introduces the related work of this article, including Manchester code, A4PQT, OQTT, BAT, and MQT protocols. Section “The proposed EAPT protocol” elaborates the implementation process of EAPT protocol. Section “Performance analysis” theoretically analyzes the performance of EAPT protocol. Section “Simulation and result” analyzes the experimental results and compares EAPT protocol with several other protocols such as A4PQT, OQTT, BAT, and MQT. Section “Conclusion” draws a conclusion for this article and puts forward the prospect.
Related work
In this section, we introduce the Manchester code and four tree-based protocols proposed in recent years. Through analyzing their shortcomings, the improved protocol of EAPT is introduced.
Manchester code
Manchester code26–30 is widely used in tree-based RFID multi-tag anti-collision protocols. It is mainly used to accurately detect the positions of collision bits. For Manchester code, the value of a bit is determined by the voltage conversion within the bit window. The negative transition represents the bit 0 and the positive transition represents the bit 1. In an RFID system, if more than two tags which are within the working range of a reader simultaneously transmit bits of different values to the reader, and after the reader decodes the received information, the positive and negative transitions are counteracted. Manchester code does not allow this state to happen, so the technique can be used to accurately locate the collision bits to efficiently identify each tag. However, the premise of using Manchester code to detect collision bits is that all responded tags need to be transmitted synchronously. In this article, it is assumed that data transmission is performed under the condition of an ideal communication channel, 28 regardless of other factors in the channel that affect synchronous transmission and bit errors.
Figure 2 shows an example of Manchester code in an RFID system. Suppose there are two tags within the working range of a reader, and their IDs are 1001011 and 1101101, respectively. Both of them send their IDs to the reader simultaneously after using the Manchester coding method. After being decoded, the information received by the reader is 1X01XX1(X represents a collision bit). Then, the positions of collision bits are detected, which are the second, fifth, and sixth bits. In this way, tags can be divided into smaller subsets according to the collision bits.

Example of Manchester code.
A4PQT protocol
A4PQT protocol is proposed on the basis of 4-ary QT protocol. The collision bits are detected by Manchester code. According to the characteristics of the highest collision bit and its following bit, the reader obeys the corresponding rules of A4PQT protocol to prune the 4-ary tree. In this way, some branches can be cut. The specific rules are as follows:
If the following bit is 0, which is X0, the two branches of 01 and 11 can be pruned;
If the following bit is 1, which is X1, the two branches of 00 and 10 can be pruned;
If the following bit is still a collision bit, which is XX, the original query prefix is appended with 00, 01, 10, and 11, respectively, and then they are sequentially pushed to the top of the stack, without pruning any branches.
Suppose there are five tags in an RFID system, Tag A(0010), Tag B(0100), Tag C(0111), Tag D(1001), and Tag E(1010), respectively. The query tree structure obtained using A4PQT protocol is shown in Figure 3. First, the reader sends an empty command, and all tags respond. The reader receives the bit strings sent by tags and detects the collision bits using Manchester code. Therefore, the reader gets the collision information XXXX. Then, it generates four new prefixes which are 00, 01, 10, and 11 according to the specific rules and pushes them to the top of the stack. When the query prefix is 00, Tag A is successfully identified. Next, when the query prefix is 01, the reader receives the collision information XX and generates four new prefixes which are 0100, 0101, 0110, and 0111. The reader sends these four query prefixes in turn, and Tag B and Tag C are successfully identified. However, two idle timeslots are also generated. The next identification process is the same as above until the stack is empty.
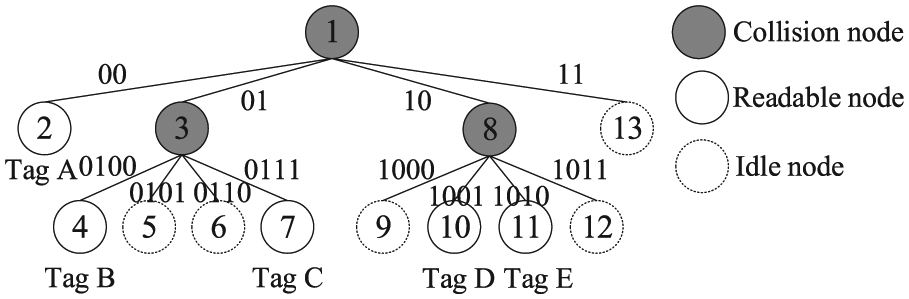
Example for A4PQT protocol.
Through careful analysis, we reach a conclusion that A4PQT protocol can reduce a part of idle timeslots. However, the information received by the reader is XX when the two tag IDs are 11 and 00, or 10 and 01, and four branches of 00, 01, 10, and 11 are still generated. In this case, the protocol also introduces many extra idle timeslots. According to this shortcoming of A4PQT protocol, one of the improvements of EAPT protocol compared with A4PQT protocol is that EAPT protocol proposes an XOR grouping rule which can completely avoid the generation of idle timeslots and further optimize the performance of A4PQT protocol. As a result, it is better to improve the system identification efficiency and the throughput.
OQTT protocol
OQTT protocol primarily optimizes the beginning of the tag identification process in the CT protocol. It mainly adopts three methods of bit estimation, optimal partition, and query tracking tree.
First, the protocol uses the method of bit estimation to estimate the number of tags based on the locations of collision bits. Each tag randomly selects the value Q between 0 and
OQTT protocol can significantly reduce the number of collision timeslots and improve the identification efficiency of RFID systems. However, there is a problem of estimation accuracy in the bit estimation process, and some idle timeslots are also generated. The EAPT protocol proposed in this article selects the type of grouping mechanisms by collision coefficient. Each query can generate accurate query prefixes, which completely avoids the generation of idle timeslots and further reduces the number of collision timeslots. At the same time, OQTT protocol only optimizes the initial number of collisions, and the subsequent process is still carried out in accordance with the rule of CT protocol. EAPT protocol adds at least three bits after the original query prefix to update the stack in each query, further accelerating the process of system identification. Therefore, EAPT protocol further improves the performance of RFID systems.
MQT protocol
MQT protocol uses m-bit arbitration, where
This protocol innovatively proposes a new mapping table, which is generated by a mapping function, and it is a mapping from m bits to
Assume that in an RFID system, there are two tags whose IDs are 110110 and 111001. In one query, both tags with the prefix of 11 are responded with 001010 and 010001, respectively. After decoding, the reader gets 0XX0XX and infers that the new query prefixes are 1101 and 1110.
MQT protocol can accurately infer query prefixes in each query according to the mapping table, effectively avoiding the occurrence of idle timeslots of the full M-ary tree, and thus the throughput can be significantly improved. However, the price it pays is the increase in communication complexity. The information responded by tags includes not only the
BAT protocol
BAT protocol is based on A4PQT protocol. It is the anti-collision protocol which proposed two-rule definition.
Definition 1
Suppose there is a tag with three successive bits
If
If
Definition 2
If there are two collision bits in the three successive bits, the combinations of the two bits are inferred according to the known bit and the value of RGC.
The combinations of query prefixes are effectively obtained using the two-rule definition. BAT protocol can reduce some idle timeslots and improve the throughput of RFID systems to a certain degree. However, one or two extra idle timeslots are generated if the value of the reader’s counter RGC is X, and this protocol also introduces some collision timeslots. Compared to BAT protocol, the improvement of EAPT protocol in this article is that tags are adaptively grouped by choosing one of the grouping mechanisms according to the proposed collision coefficient. When there are only two collision bits in three consecutive bits, the query prefix combinations of the current timeslot are accurately determined according to the XOR grouping mechanism using the two collision bits, completely avoiding the occurrence of idle timeslots of BAT protocol when it is in this case; when there are three consecutive collision bits, the code conversion method is used to completely avoid the occurrence of idle timeslots and reduce many collision timeslots; in addition, each new prefix ends up with the bit before the next highest collision bit, further reducing the number of redundant transmission bits. Therefore, the identification efficiency of BAT protocol is improved.
The proposed EAPT protocol
According to the shortcomings of the above four protocols, a new multi-tag anti-collision protocol of EAPT is proposed. As we all know, for the tree-based anti-collision protocols, there are three types of timeslots, namely:
Readable timeslot. There is only one tag responding to the query command of a reader in a timeslot, and the reader can directly identify this tag;
Idle timeslot. There is no tag responding in a timeslot;
Collision timeslot. There are multiple tags in a timeslot responding to the reader’s query command. Even if the reader can decode the Manchester code to determine collision bits, it cannot identify each tag.
In order to improve the identification efficiency, it is inevitable to reduce the number of idle timeslots and collision timeslots. In this article, there are two mechanisms in the proposed protocol of EAPT. The value of collision coefficient of the successive three bits which start from the highest collision bit is used to determine which mechanism is chosen to follow to identify tags. Then, according to the characteristics of the three bits, the possible query prefixes are inferred. EAPT protocol completely avoids idle timeslots and significantly reduces the total number of timeslots, thereby the system throughput is further improved.
Description and commands of EAPT protocol
In an RFID system, the reader is a powerful entity with abundant memory and computation power, while the tags are limited in memory and computation power. The RFID system adopts the way of Reader Talks First (RTF), and the tags send their information only after receiving the commands sent by the reader. Each tag has a unique ID. To read the IDs of the tags, the reader needs to have the same air interface protocol as the corresponding tags.
In this protocol, the reader has a stack which is used to store query prefixes, and it also has a counter named HOG. The counter is used to receive group numbers which are sent by tags. Newly generated query prefixes are stored in the stack in line with last-in-first-out (LIFO) rule. Each tag has a group-number counter named HOG(i) and also has a register which is used to store eight binary numbers to predict collision prefixes. The proposed protocol is compatible with the existing standard of EPCglobal specification. The commands of EAPT protocol are described as follows.
REQUEST(PRE)
It is an RFID reader request command. PRE denotes a query prefix. When the reader broadcasts this command, the tags whose prefixes are the same as PRE respond. The responded tags send the rest of the bits of their IDs except PRE to the reader. Generally, at the beginning of the process of tag identification, the reader sends REQUEST(ε). All tags in the reader’s working range respond and send their IDs to the reader.
REQUEST(PRE, HOG)
It is an RFID reader request command. PRE also denotes a query prefix. HOG denotes a group number. When the reader broadcasts this command, the tags, whose prefixes are the same as PRE and whose values of HOG(i) are the same as that of HOG, send the remaining bits of their ID except PRE to the reader.
REQUEST(PRE, 111)
It is a lock-bit and collision-prefix prediction command. When the reader sends this command, the tags whose prefixes are the same as PRE respond. These tags convert their own first three consecutive bits after PRE into the corresponding decimal numbers and return an eight-bit binary number to the reader. Thus, the reader can predict the prefixes.
PUSH(PRE)
It is a read-and-write command. When a new query prefix (i.e. PRE) is generated, the reader sends this command to push it to the top of the stack.
POP(PRE)
In this command, PRE as a new query prefix is popped from the top of the stack.
SELECT(ID)
It is a select command. The reader selects a certain tag whose ID is the same as “ID.”
READ-DATA(ID)
It is a read command. The reader reads the ID of a selected tag.
SILENCE
It is a silent command. When a tag ID is identified, the reader makes the tag silent by sending this command, and the tag does not take part in the next identification process.
| |
It is a bit string connection command, where 110
Basic idea of EAPT protocol
In this protocol, Manchester code is used to detect collision bits. If collisions occur, the reader updates query prefixes in the stack. Suppose that the three consecutive bits are

where
Type 1
When the value of
If
If
LOC settings.

Grouping rule under the case of

For example, if the reader receives X1X00XX1 in a query, the consecutive bits
If HOG is 0, there are only two possible combinations, namely, 010 and 111. Then, the original query prefix and two possible combinations are combined in different ways. The two new prefixes end up with the bit before the next highest collision bit, and the reader sends PUSH(PRE | | 010 | | 00) and PUSH(PRE | | 111 | | 00).
If HOG is 1, there are only two possible combinations, namely, 011 and 110. The next process is similar to case 1. The reader sends PUSH(PRE | | 011 | | 00) and PUSH(PRE | | 110 | | 00).
If HOG is X, the reader sequentially sends REQUEST(PRE, 0) and REQUEST(PRE, 1). The possible combinations are inferred in each group, and the reader pushes them to the top of the stack.
Type 2
When the value of
For example, if there are three tags whose IDs are 00000, 00101, and 00111, respectively. In a query, the reader decodes the information using Manchester code and gets the collision sequence as 00XXX. Then, the reader sends REQUEST(00, 111). Because the prefixes of the three tags are the same as 00, the three consecutive bits after 00 are converted into a decimal number. Thus, the tags obtain the decimal numbers 0, 5, and 7, respectively, and set the zeroth bit, the fifth bit, and the seventh bit of the 8-bit binary number sequence as 1 (i.e. 00000001, 00100000, and 10000000). Subsequently, the tags send them to the reader. After decoding, the reader gets X0X0000X, and the positions of the collisions are the zeroth bit, the fifth bit, and the seventh bit, respectively. Then, the reader converts them into binary form (i.e. 000, 101, and 111). Finally, 00000, 00101, and 00111 are pushed onto the stack.
Flow of EAPT protocol
Assuming that there are M tags in an RFID system, and the length of each tag ID is N bits, which is
Step 1. The reader initializes the stack and HOG.
Step 2. The reader sends REQUEST(ε). All tags within the reader’s working range respond, meanwhile sending their IDs to the reader.
Step 3. The reader receives the tag ID information and decodes the received data using Manchester code. At the same time, the reader identifies all the collision bits. If there is no collision bit, the reader directly sends SELECT(ID) and READ-DATA(ID) to the only one tag. Then, the tag is identified. The reader sends SILENCE to set the identified tag in the silent state, and the process turns to step 5. If there are some collision bits, the process turns to step 4.
Step 4. The reader detects the three successive bits from the beginning of the highest collision bit and then calculates the collision coefficient (i.e. If If
If the reader receives less than three bits, there exist two cases:
If the reader receives only one bit, since there is a collision, the bit that the reader receives is X. Then, the reader combines the original prefix and 0 or 1, respectively, and the two new prefixes are pushed to the top of the stack.
If the reader receives two bits and there is only one collision bit, the two combinations are inferred. Then, the two new prefixes are pushed to the top of the stack. However, if there are two collision bits, the next step is similar to the case when
Then, the process turns to step 5.
Step 5. The reader determines whether the query stack is empty. If it is not empty, a new query prefix is popped from the top of the stack, and the reader sends REQUEST(PRE). Then, the process turns to step 3. Otherwise, if the stack is empty, the query ends.
Next, an example of EAPT protocol is given. Suppose that there are six tags within the range of a reader’s working area, Tag A(1110101100), Tag B(1010001000), Tag C(1010111000), Tag D(1010101000), Tag E(1010101110), and Tag F(1010101101), respectively. The process of identification of the RFID system is shown in Table 3, and the query tree structure is shown in Figure 4.
Process of identification of six tags using EAPT protocol.


Query tree structure obtained using EAPT protocol to identify the six tags.
The specific identification process can be described as follows:
Step 1. The reader initializes the stack and HOG, and it sends REQUEST(ε) to all tags. Then, all of the tags respond to the reader with their IDs. The reader receives 1X10XX1XXX, and there is only one collision bit in the three successive bits, thus,
Step 2. The reader sends the request command whose prefix is 1010, and Tag B–Tag F respond. The reader receives XX1XXX. Since there are two collision bits in XX1,
Step 3. The reader sends REQUEST(1010, 0), and Tag B and Tag C respond. The reader receives XX1000. Since these two tags belong to the zeroth group, the reader can directly infer two new combinations of prefixes which are 1010001000 and 1010111000. Then, the reader pushes them to the top of the stack.
Step 4. The reader sends REQUEST(1010, 1), and Tag D–Tag F respond. The reader receives 101XXX. Then, a new prefix which is 1010101 is generated, and the reader pushes it to the top of the stack.
Step 5. The reader sends the request command whose prefix is 1010101, and Tag D–Tag F respond. The reader receives XXX, so
Step 6. The reader sends the request command whose prefix is 1010101000, and only Tag D responds. Thus, Tag D is identified. The reader reads and writes the tag and then sends a command of SILENCE with the ID of Tag D to set the tag to the silent state so that it no longer participates in subsequent queries. Next, the reader pops the remaining prefixes out from the stack in turn until the stack is empty, and Tag F, Tag E, Tag B, Tag C, and Tag A are identified, respectively.
Performance analysis
As we all know, the total number of timeslots, communication complexity, transmission delay, and throughput are the most important indicators in an RFID system. In this section, we prove the performance of EAPT protocol through theoretical analysis.
Suppose there are M tags and a reader is in an RFID system, and all tags are within the working range of the reader. For a full R-ary tree
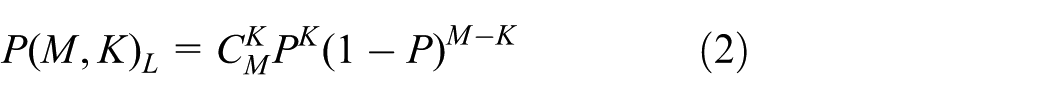
And then, we conclude that the probability of an idle node, which means that no tag selects the node, is

The probability that the node is successfully identified is

Therefore, from formulas (3) and (4), the probability of a collision node, which means more than one tag is in the node, is

In addition to the root node, if the prerequisite of any other node is queried, then the node’s parent node is a collision node.

The probability that a certain node is queried is

The total number of timeslots of a full R-ary tree is the sum of the probabilities that are based on all nodes being queried. By considering the formulas (5)–(7), we conclude that the total number of timeslots is
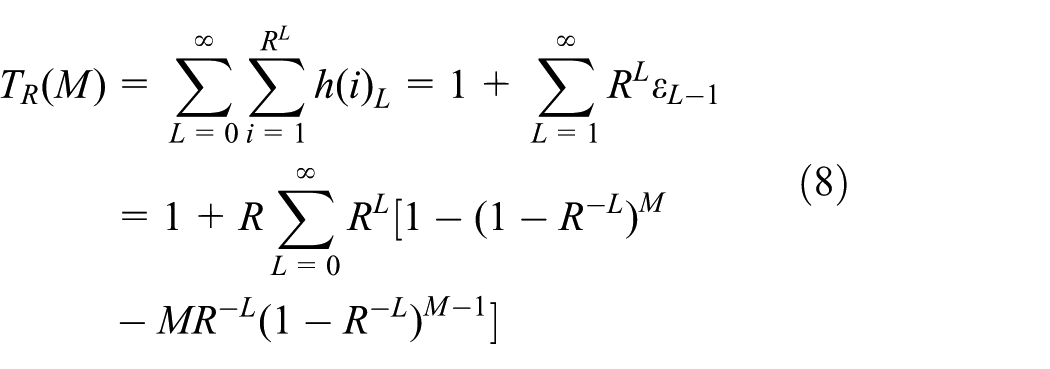
The number of collision timeslots is the sum of

Thus, the number of idle timeslots is
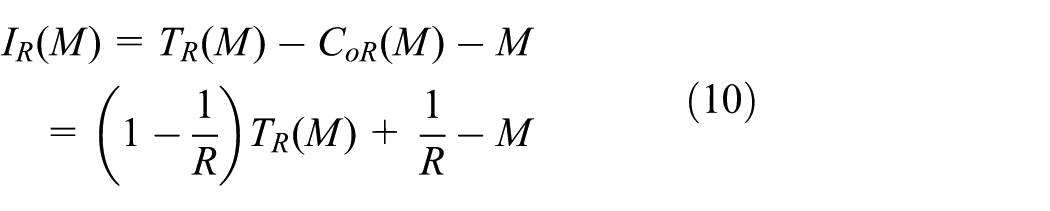
In this article, the structure of the query tree is an 8-ary tree, so

and the number of idle timeslots of a full 8-ary tree is

Next, we analyze the performance of EAPT protocol. EAPT protocol completely avoids the occurrence of idle timeslots, and there are two mechanisms in the process of identification. The mechanism taken to identify the tags is determined by the collision coefficient
If If the result of HOG does not collide (i.e. HOG = 0 or 1), then the reader does not need to send REQUEST(PRE, HOG); If HOG = X, the reader needs to send REQUEST(PRE, HOG) two times.
If


Number of extra query commands using EAPT protocol.
Since each collision node has the same probability to choose each mechanism, it is expressed as

If a collision node chooses the mechanism of Type 1, the structure of the query tree is the same as the 4-ary tree, and the total number of the child nodes is reduced by half of the 8-ary tree. If there are N0 tags in the collision node,

Thus, the probability that the collision node in the
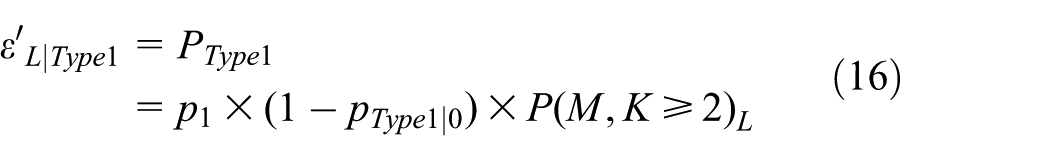
If a collision node chooses the mechanism of Type 2, the probability that no tag chooses one of the eight child nodes is

Thus, the probability that the collision node in the

In this way, we prune off some extra branches for 8-ary QT protocol. Since EAPT protocol starts with the root node for each time of tag identification, the probability that the root node is being queried is 1. The total number of timeslots has become

Because EAPT protocol has no idle timeslots, the extra idle timeslots need to be calculated first. The derivation of the number of idle timeslots is similar to the formulas (8)–(10). We conclude the number of idle timeslots is

Then, by considering formulas (13), (19), and (20), we get the total number of timeslots of EAPT protocol, which is

Therefore, the throughput of EAPT protocol is

Communication complexity is another important performance indicator of multi-tag identification in RFID systems.

Then,
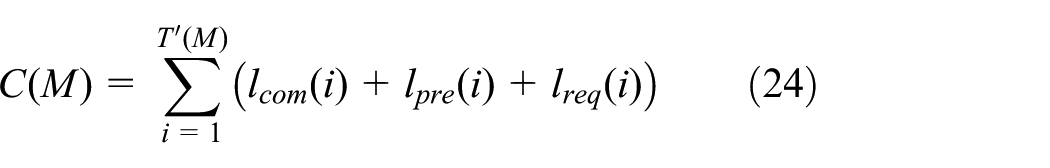
Then, another important indicator of RFID systems, which is the transmission delay, is taken into consideration. It is related to the number of queries of the reader and the amount of data transmission during each query. That is to say, the transmission delay is related to the amount of data

Simulation and result
In order to verify the performance of EAPT protocol, we select several excellent protocols for comparison, namely, QT, CT, A4PQT, OQTT, 8-ary QT, BAT, and MQT protocols. According to the related requirement of EPCglobal Class 1 (C1) Generation 2 (G2), the data transmission rate is from 26.7 to 128 kbit/s, 31 so we set the data transfer rate between the reader and tags as 100 kbit/s. Besides, we use the MATLAB R2016a simulation software to simulate the identification of 100–1000 non-duplicate tag IDs. Two necessary communication commands are selected: Query command (22 bits) is for a reader to query tags, and ACK command (18 bits) is used to notify a successfully identified tag. To ensure the accuracy of the simulation results, we run 50 times in each simulation and take the average of the results. The transmission channel is ideal, without path-loss effect, capture effect, or other effects. Since the length of tag ID is typically 96 bits in the EPCglobal C1 G2 standard, 4 we simulate the process of tag identification with 96 bits from Figures 6–12.
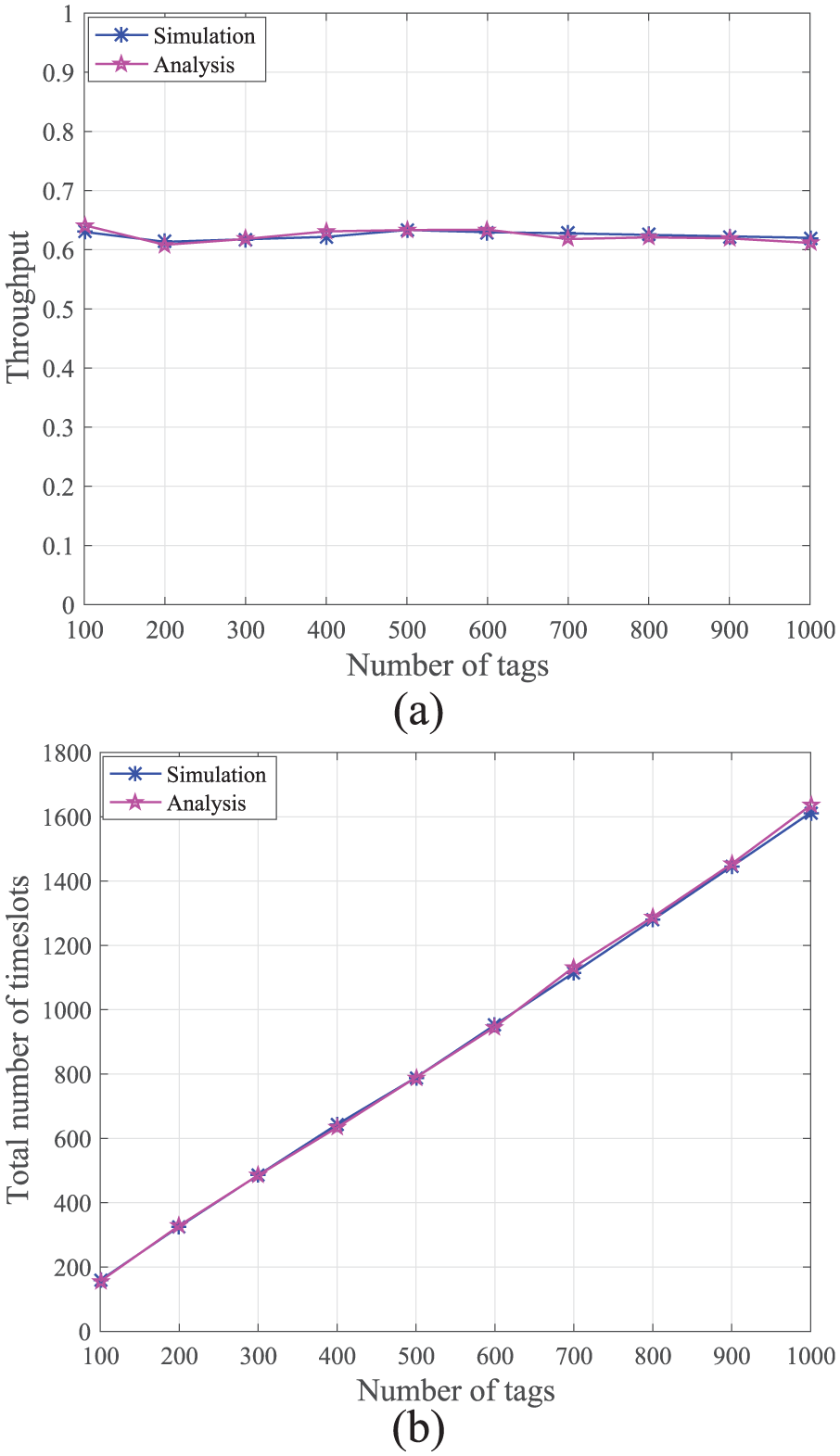
Comparison of theoretical and simulation results of EAPT protocol: (a) throughput and (b) the total number of timeslots.

Comparison of number of idle timeslots of different protocols.
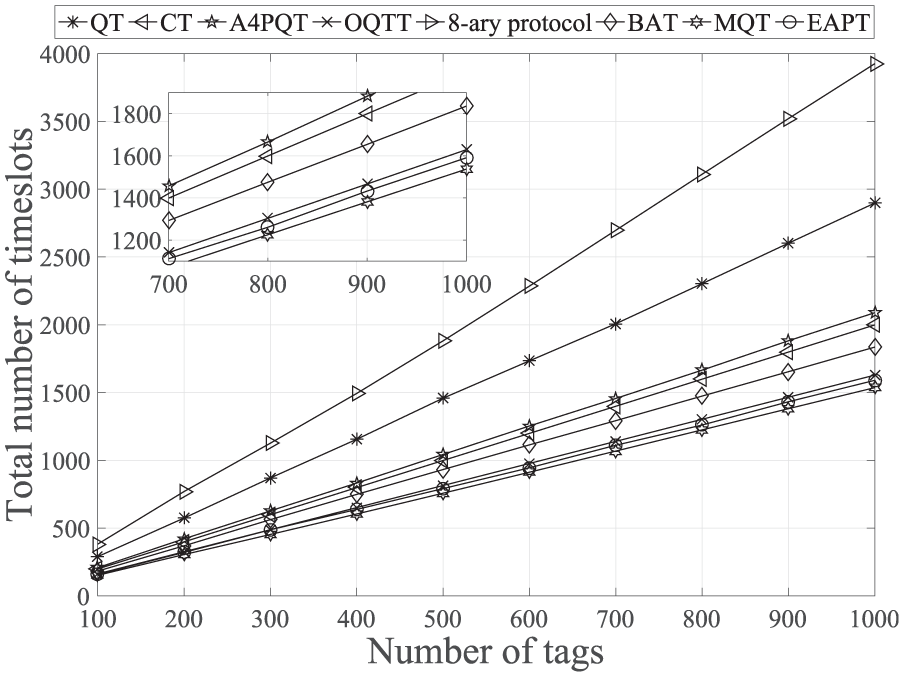
Comparison of total number of timeslots of different protocols.

Comparison of throughput of different protocols.

Comparison of communication complexity of different protocols.

Comparison of transmission delay of different protocols.

Comparison of throughput of different protocols in the case where the number of tags is massive.
Currently, there are many improved tree-based anti-collision protocols, among which the QT protocol is the most typical tree-based protocol. It introduces the concept of a query stack and uses the stack to store newly generated query prefixes. CT protocol is based on QT protocol, which only locks the target on collision bits, and each collision bit is divided into two branches of 0 and 1. OQTT protocol is based on CT protocol. It attempts to divide all tags into smaller collections to reduce collisions at the beginning of identification. Subsequently, the next identification process is performed following the rule of the CT protocol. This protocol significantly reduces the number of collision timeslots. The A4PQT and EAPT protocols also use the query stack. Similar to CT protocol, the target is locked on the highest collision bit during each query. However, for A4PQT protocol, the 4-ary tree cannot be well pruned when two consecutive collision bits appear, and many extra idle timeslots are introduced. The mapping method used by MQT protocol is similar to the second query mechanism Type 2 used in this article. For fairness, MQT protocol uses a 3-bit arbitration method to compare with EAPT protocol in the simulation. BAT protocol uses the rules of collision bits to accurately infer the transmitted bit string. To a certain extent, it reduces some idle timeslots, but it also increases the number of collision timeslots. In the query process, BAT protocol needs to send a large number of additional grouping request commands. Thus, in this article, the proposed EAPT protocol chooses the query mechanism by the value of collision coefficient, completely avoiding the occurrence of idle timeslots and also reducing many grouping request commands. Besides, each newly generated prefix ends up with the bit before the next highest collision bit, further reducing the number of redundant transmission bits. As for 8-ary QT protocol, it updates the stack by adding three bits to query prefixes. Similarly, EAPT protocol updates the stack by combining original query prefixes with at least three consecutive bits in each query, further speeding up the process of tag identification. Through simulation experiments, the improvement of the performance of EAPT protocol is confirmed.
First of all, the correctness of the performance analysis is verified from the simulation experiment point of view. Through theoretical analysis and simulation experiments, the results are shown in Figure 6. It can be seen that the results of the performance analysis are highly close to the simulation results. Figure 6(a) shows the throughput of EAPT protocol, and the biggest error between the theoretical and the experimental values is 0.01. Therefore, within the allowable range of error, the results of performance analysis are consistent with the theoretical analysis. The two main reasons for the error are as follows:
The IDs of tags are randomly generated, and the results that the tag IDs are identified by each simulation are different. The IDs of tags are not theoretically evenly distributed, thereby affecting the throughput of the RFID system. Therefore, errors exist each time in the results of experiment.
Figure 7 shows the number of idle timeslots of different protocols. It can be seen that CT, MQT, and EAPT protocols completely avoid the occurrence of idle timeslots in the process of tag identification. That is to say, their idle timeslots always remain at 0. This is because, for EAPT protocol, the result of collision coefficient determines which mechanism is chosen to identify the tags in each query. By selecting a different branch method for each node, the combinations of query prefixes are precisely predicted without generating any idle timeslots. CT protocol only locks the target on collision bits and sets the highest collision bit as 0 and 1 during each query. Then, the protocol combines the original query prefix and 0 or 1 to form new query prefixes and pushes them onto the stack. Thus, it completely avoids the generation of redundant query prefixes. For MQT protocol, each responded tag converts the first m bits in the remaining ID information except the query prefix according to the mapping table. This can accurately generate new query prefixes and eliminate all redundant query prefixes, thereby avoiding the generation of idle timeslots. Due to the complexity of calculating the number of idle timeslots of OQTT protocol, this article only analyzes the situation in which idle timeslots are generated. OQTT protocol divides the tags into multiple subsets based on the estimated number of tags, which inevitably generates some idle timeslots. Obviously, 8-ary QT protocol has the largest number of idle timeslots. This is because the protocol adds three bits to the original query prefix to form a new query prefix whenever a collision occurs during the execution of the protocol, and there are eight types of combination ways. Undoubtedly, a large number of idle timeslots are inevitably generated. The number of idle timeslots of A4PQT protocol is close to that of CT protocol. Although BAT protocol reduces the number of idle timeslots due to the collision bit rules, there are still some idle timeslots.
The total number of timeslots is one of the most important indicators for evaluating system performance. As shown in Figure 8, it can be seen that, for EAPT protocol, the total number of timeslots is significantly less than that of most protocols. For OQTT protocol, the total number of timeslots is the third smallest in the figure. A bit estimation method is used to estimate the number of tags based on the locations of collision bits before performing the query, and then the estimated number of tags is used to determine the number of query prefixes of the initial set. After that, CT protocol is used to perform subsequent queries. Thus, the collisions are effectively reduced at the beginning of the identification. Query prefixes of 8-ary QT, BAT, MQT, and EAPT protocols are increased by three binary bits during each query, further speeding up the process of identification. However, 8-ary QT protocol generates eight branches each time a collision occurs and introduces a large number of idle timeslots. BAT protocol uses an effective way to group, so it reduces the number of timeslots. The total number of timeslots of MQT protocol is slightly less than EAPT protocol. This is because for EAPT protocol, the reader needs to send some additional query commands to tell tags how to respond, resulting in a slight increase in the total number of timeslots. However, EAPT protocol uses the collision coefficient result to determine the mechanism adopted in order to predict the query prefixes more accurately. By taking full advantage of the numerical characteristics of the three consecutive bits, tags are accurately grouped to avoid idle timeslots and reduce some collision timeslots. Since the total number of timeslots is the sum of idle timeslots, collision timeslots, and readable timeslots, and the readable timeslots are the same for all protocols, EAPT protocol significantly reduces the total number of timeslots. QT protocol adopts a bit-by-bit query, further slowing down the process of identification, and it also introduces a lot of idle timeslots. It can be seen from the figure that the total number of timeslots of A4PQT and CT protocols is very approximate. When the number of tags is 1000, the total number of timeslots for QT, CT, A4PQT, OQTT, 8-ary QT, BAT, MQT, and EAPT protocols is 2897, 1999, 2089, 1628, 3930, 1837, 1536, and 1585, respectively.
Figure 9 shows the throughput of different protocols. Since the throughput is the ratio of the number of tags to the total number of timeslots and the number of tags is the same for each protocol during execution, the throughput rate is only related to the total number of timeslots. As can be seen from Figure 9, the throughput of EAPT protocol always remains approximately 0.625, which is slightly smaller than MQT protocol. Because, the smaller the total number of timeslots, the higher the throughput. The total number of timeslots of EAPT protocol is smaller than most protocols, so its throughput is higher among these protocols. Then, the throughput of OQTT protocol is the third highest, which is close to 0.614. However, 8-ary QT protocol has the lowest throughput due to the largest number of total timeslots, and the throughput only remains approximately 0.26. EAPT protocol’s throughput is 0.075 higher than that of BAT protocol. The throughput of the other protocols is ranked from high to low as CT, A4PQT, and QT protocols, which are 0.5, 0.48, and 0.35, respectively.
Figure 10 shows the communication complexity of several protocols. As can be seen, the communication complexity of EAPT protocol is minimal when identifying the same number of tags, and the total number of transmitted bits of OQTT protocol is higher than the EAPT protocol. Although MQT protocol has the highest throughput, tags return both the mapping part and the remaining ID part except the mapped bit string in each query and a large number of bits need to be transmitted, thereby significantly increasing the communication complexity. For EAPT protocol, the newly generated query prefixes end up at the previous bit of the next highest collision bit in each query, which can significantly reduce the number of bits transmitted. However, for several other protocols, each newly generated prefix ends up at the last bit of the speculative bit string, thereby adding a large number of redundant transmission bits. At the same time, the query prefixes of EAPT protocol can be accurately generated according to the two mechanisms, which eliminate the number of idle timeslots and also reduce the number of collision timeslots to some extent. Therefore, it has more excellent performance compared with the other protocols. The communication complexity of CT, A4PQT, and BAT protocols is very similar. Since the total number of timeslots required for 8-ary QT protocol far exceeds that of the other protocols, the communication complexity is very high.
As can be seen from formula (25), since the data transfer rate between the reader and the tags is the same for every protocol, the transmission delay of the system is only related to the communication complexity. As shown in Figure 11, the transmission delay of EAPT protocol is the smallest, while the transmission delay of MQT protocol is the largest. This is because the total number of transmitted bits of EAPT protocol is the smallest, and the smaller the communication complexity, the smaller the transmission delay. When the number of tags is 1000, the transmission delay of EAPT and MQT protocols are 1773 and 5009 ms, respectively. When the number of tags increases from 100 to 1000, the transmission delay of OQTT protocol is the second smallest, and the transmission delay of QT protocol is always about twice as much as that of EAPT protocol. A4PQT, QT, and BAT protocols are very close.
There must be massive RFID tags in the future of the IoT, and the problem of tag collision will be more serious. In order to verify whether EAPT protocol can still guarantee its performance in the face of future mass tags, we conduct simulation experiment in the presence of a large number of tags in the RFID system, and the length of each tag is 96 bits. It can be seen from Figure 12 that as the number of tags increases from 1000 to 10000, the throughput of the system remains approximately 0.625. This simulation experiment shows that EAPT protocol can be applied to the identification of large quantities of tags.
To verify whether the performance of EAPT protocol is affected by the change of tag ID’s length, we simulate the throughput of EAPT and QT protocols with different tag ID’s length, as shown in Figure 13. It can be seen that as the length of tag ID varies, the system throughput of the two protocols hardly changes. The throughput of QT protocol is between 0.32 and 0.37, while EAPT protocol remains approximately 0.625. Meanwhile, as can be seen from the figure, when the length of the tag ID changes, the amplitude of variation of the throughput of EAPT protocol is less than that of QT protocol, and the performance of EAPT protocol is more stable. This is because QT protocol is a bit-by-bit lookup, and the total number of timeslots is related to the length of tag ID. EAPT protocol locks the target on the three consecutive bits which start from the highest collision for each query and determines the different query mechanisms according to the value of collision coefficient to make the prefix prediction more accurate. Besides, from formulas (21) and (22), the total number of timeslots for EAPT protocol is independent of the length of tag ID.

Throughput with different length of tag IDs.
Conclusion
In this article, we propose a multi-tag anti-collision protocol based on EAPT through analyzing the shortcomings of other tree-based anti-collision protocols. The concept of collision coefficient is proposed innovatively. Two kinds of query mechanisms are adopted. In each query, the value of the collision coefficient determines which mechanism to perform, and the prefixes are accurately predicted. In this way, EAPT protocol completely avoids the occurrence of idle timeslots, and the 8-ary tree can be completely pruned. Both theoretical analysis and simulation experiments show that EAPT protocol significantly improves the identification efficiency of RFID systems. At the same time, to a certain extent, the performance of EAPT protocol is not affected by the length of tag ID and the number of tags and is superior to the performance of the existing protocols. Moreover, the throughput of EAPT protocol remains approximately 0.625, an increase of 13.6% compared to the throughput of BAT protocol and an increase of 1.8% compared to the throughput of OQTT protocol. EAPT protocol also has the lowest communication complexity and significantly reduces the communication overhead of RFID systems. In addition, EAPT protocol has superior performance which addresses the problem of massive tag identification in the future application of the IoT. In the future, we will focus on the energy consumption and capture effect of EAPT protocol and improve the research of the protocol to better adapt to the application of RFID anti-collision in real life.
Footnotes
Appendix 1
There are many symbols and variables in this article. To make it easier and more intuitive to know the meaning of each symbol or variable, we summarize them in Table 4. The symbols and variables in the table are listed in the order in which they appear in this article.
Handling Editor: Shigeng Zhang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was financially supported by the Fundamental Research Funds of Jilin University (SXGJQY2017-9, 2017TD-19), the Funds of Jilin and Changchun Science and Technology Department (16SS02), and the National Natural Science Foundation of China (no. 61771219).