
Abstract
Although Internet of Things (IoT) has been recently receiving attention from the research community, undoubtedly, there still exists several privacy concerns about those devices. In particular, IoT devices in the cyberspace are reachable and visible through IP addresses. This article uniquely exploits to qualify the distribution of owner information of IoT devices based on the observation; consumers may write relevant details into the application-layer service on the IoT devices, such as company or usernames. We propose to automatically extract owner annotation by utilizing a set of techniques (network scanning, machine learning, and natural language processing). We use the probing and classifier to determine whether the response data come from an IoT device. The natural language-processing technique is used to extract owner information from IoT devices. We have conducted real-world experiments to evaluate our integrated approach empirically. The results show that the precision is 97% and the coverage is 96%. Furthermore, our approach is running on a more larger unlabeled dataset consisting of 93 million response packets from the whole IPv4 space. Our analysis has drawn upon nearly 4.3 million IoT devices exposed to the public, and it is a typical trail effect of the owner information distribution.
Introduction
The Internet of Things (IoT) device is about consumer-oriented equipment (i.e. routers, webcams, net-printers, and industrial control devices), which is deployed across many industries, including home, manufacturers, transportations, and companies. Gartner 1 reports that the number of devices increases nearly 5 million every day in the cyberspace and will achieve 20 billion by the end of 2020. To adapt to the rapidly increasing number of IoT devices, research professionals actively proposed fingerprint to discover those online devices,2–6 which requires a set of response data and a classification function. However, prior work did not further study the characteristic of these devices. In this article, we attempt to investigate the owner information of IoT devices, that is, who exposes and owns devices.
The conventional method to obtain owner information (i.e. the organization and contact) is to send an online query to existing databases, such as DNS and WHOIS. 7 The rationale is that an IoT device is alive on an IP address which is associated with the registration information stored in the database. Antonakakis et al. 4 used active and passive DNS data to parse the domain names of malicious network infrastructures, which sent command&control (C&C) to IoT devices. Fachkha et al. 5 proposed to obtain the registration information of devices through querying the WHOIS database, 7 which contain many attributes including Classless Inter-Domain Routing (CIDR), organization, description, email, and modification date. However, the online database does not work in the following cases: sub-allocation and null registration information. First, the allocation of IP addresses is hierarchical, from the international organization to the national organization and to the local services. Furthermore, the sub-allocation usually occurs among Internet service providers (ISPs). The registration information about the IP address may not be the real owner information for IoT devices, leading to false positive of the online query. Second, many IoT devices do not have the registration information of their IP addresses because they are consumer-oriented devices. In this case, the online query would return the null registration information for devices’ IP. Therefore, the conventional method cannot solve the analysis to the owner information of IoT devices.
To address this issue, we propose to utilize the payload of the response data from IoT devices. The key insight behind our work is that consumers or manufacturers may write correlated information in the application-layer services after installing an IoT device, such as owner names or company names. We would send a request to those IoT devices in the application-layer protocols (i.e. HTTP, FTP, and Telnet) and receive their response data. If the payload contains the relevant information about the device owner, we extract it as the annotation; otherwise, we use the online query to the existing database like prior work.
While the idea is relatively straightforward, there are two challenges that need to be handled in practice. First, the response data may come from non-IoT devices, because the cyberspace includes various types of information. For instance, there are much redundant and interference information from non-IoT devices, such as commercial websites and cloud servers. We cannot directly extract the owner information from all response packets from the Internet, leading to a high false positive. Second, the payload is written in natural language, and owner names are typically informal. It is impossible to emulate all owner names by human efforts.
In this article, we propose to automatically extract owner information of IoT devices through network scanning, machine learning, and natural language processing (NLP) techniques. For a chunk of IP addresses, the network scanning finds the live hosts and filters out unreachable hosts. We send the application request to live hosts for obtaining the payload of the response data. Machine learning algorithm is used to infer the classifier, where the input is the response packet and the output is whether it belongs to the IoT device. Specifically, the response packet would be converted into a feature vector; we propose an iterative approach to expand the feature space. The NLP is used to extract owner information from the response payload of IoT devices. If the owner belongs to an organization (i.e. company, school, government), we use the regex to identify owner annotation. If the owner belongs to an individual (i.e. home, residential), we use the name entity recognition (NER) to find owner annotation.
To validate the effectiveness of our approach, we have conducted real-world experiments. The results show that the classifier can recognize IoT devices in precision (97%) and coverage (97%). The extraction process of owner annotation would automatically find owner information in a real-time manner. Moreover, our approach is running in an unlabeled dataset (nearly 4 billion IPv4 addresses) to extract owner information automatically. In the comprehensive analysis, we find that there are 4.3 million IoT devices exposed to the public, causing the underlying security risks, and the distribution of owner information of IoT devices is a typical long tail.
Overall, our contributions are summarized as follows:
We propose to extract the owner information of IoT devices automatically. As best we know, it is the first work to explore IoT device owners from the response payload.
We have conducted real-world experiments for evaluating the approach, and the results show its performance is promising.
Our approach has found millions of public IoT devices and a long-tail distribution of owner information on the whole IPv4 space.
The remainder of this article is structured as follows: section “Background” describes the background and motivation of our work. Section “System design and implementation” presents the details of system design and implementation for automatically extracting IoT device information. Section “Evaluation” details the implementation and real-world experiments, and section “Related work” surveys related work. Finally, section “Conclusion” concludes.
Background
In this section, we first present the background of the online query about owner information extraction (IE). Then, we describe the motivation of IE from the packet payload.
Online query
As aforementioned, the IoT device is alive on the IP address, and we can obtain the owner information through querying the IP address from the existing database. Here, we have presented two impacts affecting the accuracy of the online query, including the mechanism of IP address allocation and the manner of IP registration.
The allocation of the IP address system is a hierarchical manner. Figure 1 depicts the hierarchical structure of IP allocation. Initially, the Internet Assigned Numbers Authority (IANA) 8 is responsible for allocating all IP addresses, including IPv4 and IPv6. IANA assigns regional Internet Registry (RIRs), a chunk of IP addresses. Second, RIRs would allocate IP addresses to National Internet Registry (NIR) and Local Internet Registries (LIR). Third, ISPs would obtain the IP addresses from either NIR or LIR. Finally, ISP would further allocate IP addresses to customers (device owners) in two manners: direct allocation and sub-allocations. Direct allocation is that the ISP can assign users an IP address. Sub-allocation is that a reseller buys IP addresses from ISP and sells it to consumers. It is importantly noted that the online database would only store those organizations (NIRs, LIRs, and ISPs) with IP registration information.
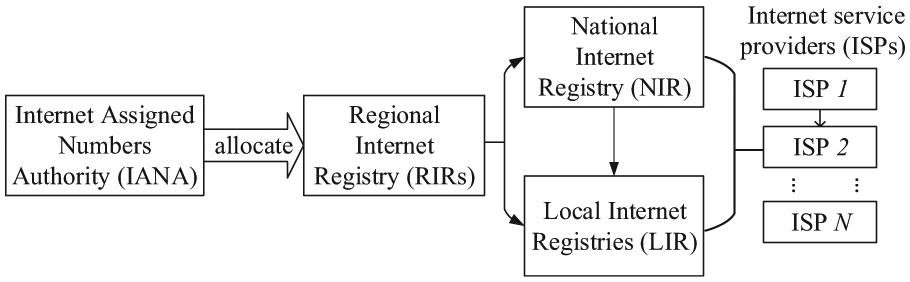
The allocation of the IP address system.
It is commonly seen that users will not register their devices with IP addresses. The registration information usually contains CIDR, description, allocation-type organization, the person, and contact. However, an IoT device is the consumer-oriented equipment and users may directly use a changing IP address allocated by ISPs with Dynamic Host Configuration Protocol. In this case, the online query just provides the information without the owner information of IoT devices.
In brief, the IP address allocation and registration make online query insufficient to identify who uses IoT devices. In this article, we propose to utilize the payload of response data from IoT devices, as the supplementary way to the online query, to extract owner information.
Motivation
The intuitive observation in our work is that users or manufacturers would embed the correlated information into the application service in IoT devices. As an example, Figure 2 shows the payload content of four packets from IoT devices. We use rectangle within red color to emphasize the owner information in the payload. We observe that Figure 2(a) belongs to the individual in the Modbus protocol, and Figure 2(b)–(d) belongs to the organization in HTTP and FTP. To extract owner information, we leverage a set of existing tools (network scanning, machine learning, and NLP) to address several practical problems at practice. We introduce these techniques below.

The payload content of four packets of IoT devices.
Network scanning
IoT devices are sparsely distributed across the cyberspace. It is impossible to determine every address, which would take a long time. For example, there are 4 billion IPv4 addresses. We leverage the network scanning technique to filter out unqualified hosts and preserve live hosts in the cyberspace. The network scanning technique is to send a probing packet to determine whether there is a live host on an IP address within a particular port. In this article, we have assumed that IoT devices run their application-layer services associating with a particular port, such as HTTP with 80, FTP with 21, and Telnet with 23. The state-of-art network scanner tools (Zmap 9 and Masscan 10 ) could actively scan the IPv4 space for discovering alive hosts within 1 h.
Machine learning
After network scanning, we can obtain the response data from all live hosts in the cyberspace. We propose to utilize machine learning algorithms to determine whether a packet comes from an IoT device. Machine learning algorithms are used to infer a classification model for mapping the input data to the class labels. The input data are the response data, and the IoT label is the output. The machine learning technique would derive the parameters of the model that maps the input into the output. It is importantly noted that there is no training data for IoT devices, and we need to collect dataset manually.
NLP
After identifying the response data of IoT devices, we need to extract owner information from their payload. It is noted that the description of owner information is typically informal and in natural language. We cannot manually extract all owner annotations of IoT devices. We leverage NER, as a typical technique for processing natural language, to find the labels of every word in the payload. In this article, we divide owner annotation into two categories: the organization type and the individual type. For the organization type, we use the regex matching to extract owner annotation of IoT devices. For the individual type, we use a rule-based NER to extract owner annotation.
System design and implementation
In this section, we leverage common characteristic of IoT devices to learn the classifier and present NLP to extract owner information. Below we present the high-level design of our approach and illustrate how it works through an example.
Architecture. Figure 3 illustrates the overview of system design about automatical owner IE, including (1) data collection (DC), (2) IoT device classification (IDC), and (3) IE. The DC first collects (“probe”) the response data from a network block and removes irrelevant packets according to the status codes and length size. Then, those packets (response data) are inspected by the IDC, using machine learning techniques to filter out those unlikely to come from IoT devices. Specifically, for every packet, the IDC converts all its content, including audio, videos, and external links to text and uses token to present the character in the response data. The IDC utilizes an iterative process to select features for IoT devices and to infer the classifier based on the machine learning algorithms. Every response packet here is automatically divided into IoT devices and non-IoT devices. The IE analyzes the payload of response packets from IoT devices and determine whether it connects the context (the predefined string) by the regex, which contains commonly seen organization names. If so, the IE marks the organization annotation to the IoT devices. If not, the IE leverages name recognition entity (NER) to extract owner information as the labeled to the IoT device.

The overview of the system design.
An example. Here, we use an example (Figure 2(b)) to go through the whole architecture procedure. We have sent the HTTP request to the host with IP address and received the HTTP response data with 200 OK status code. We obtain the textual content from response data in HTML format. The classifier finds that it comes from an IoT device. Then, we find the predefined string (“school”) in the payload within the regex. We mark the “Bedminster Township Public School” as the owner annotation of the IoT device. It is noted that we will use the NER to extract owner information if the regex matches fail.
DC
We present the design and implementation to explain how the DC collects the application-layer data in the cyberspace. IoT devices are running application services for remote access and convenient management. Application protocols are supported by those IoT devices, such as HTTP, FTP, Telnet, and Real-Time Streaming Protocol (RTSP). As aforementioned, the correlated information may be written into those application services. We use
The DC contains two components, including request packet encapsulation and probing module. To facilitate adding request packet in the application layer, the DC provides standalone functions that allow craft fields for encapsulating packets. The payload in the request packet is set as “NULL” because it is unnecessary to interact with remote hosts. The probing module in the DC explicates how to send the request to the cyberspace. The number of IP address space is enormous (e.g. 4 billion IPv4). The time cost would be impractical if sending the request needs a three-hand connection for every IP address. The probing module proposes a two-stage approach for accelerating the speed of collecting response data in the application layer.
In the first stage, the probing module utilizes the network scanning technique to filter out unqualified hosts. Devices are sparsely distributed among the address space, causing many unnecessary hosts. The network scanning technique has two tricks to improve the probing module: (1) one packet and (2) stateless. For every address, the probing module only sends one packet to determine whether there is a live host. For every address, the probing module does build the stateless connection for accelerating the speed of sending requests. After the first stage, the probing module would obtain the set of live hosts in the cyberspace.
In the second stage, the probing module would build the three-hand connection with every live host in the first set. The probing module utilizes the encapsulated packet in the application layer to receive the response data from the remote hosts. It is noted that the response data would carry with status codes, 11 which is a three-digit integer result code of the request. The probing module would handle three cases:
The status code is 2XX, indicating that the client can successfully obtain the data. The probing module would receive the response data and store it as files.
The status code is 4XX, indicating that the request has failed and we do not obtain the exact data. The probing module would remove it.
The status code is 3XX, indicating that the redirect appears. The probing module would attempt re-send the request to the new address extracted from the response data.
Implementation. In this section, we have implemented a simplified collector, which can be deployed in various network environments. We have crafted three request packets in the application protocols, including HTTP, FTP, and Telnet. The probing module uses one Transmission Control Protocol (TCP) packet with SYN to find the live hosts. The rule is heuristic: if the host returns the response to TCP-SYN, we add it to the set of live hosts. The probing model stores the response data in the JSON format for extracting owner information in the next stage.
IDC
The DC collects the response data mixed with various information, including commercial websites, cloud servers, and personal computers. If we directly extract owner information from the response data, the interference information would decrease the performance of our approach. The IDC determines whether the response data come from an IoT device.
The IDC leverages the machine learning techniques to infer the fingerprint of IoT devices, consisting of four components: (1) the input, (2) features, (3) the classification function, and (4) the output. The input is the response data from the DC, denoted as
Hence, we propose an iterative approach to infer the relevant features for the IDC. In the initial, the IDC selects several features based on the intuitive observation: IoT devices usually belong to the consumer-oriented devices with limited resources. Compared with other devices, the size of response data is much smaller, and context terms (scripts, links, pictures, and videos) are little. Table 1 presents the initial features that the IDC selected. We empirically set the field value of those features working well at practice. The IDC uses the statistical metric to tune features for increasing coverage.
The initial features that the IDC selected.

IDC: IoT device classification.
Figure 4 shows the feature expansion process in the IDC through the Chi-square test.
12
A Chi-square test can determine whether variables in the dataset are related. We use the seven features as the initial seeds (Table 1) which are relevant features for determining the IoT devices. We collect 11,000 response packets, where 1,000 ones come from IoT devices in the positive set and 10,000 from others in the negative set. We also expand the set of the dictionary to the candidate features. If the payload contains ith word, then

In the initial features, the IDC uses the Chi-square test for picking up the related features within the labeled training dataset.
After feature expansion, the IDC converts the input data into the feature vector. We utilize the machine learning algorithms 13 to infer the parameters of the classification model. We have investigated four learning algorithms including Support Vector Machines (SVM), Random Forest (RF), Naive Bayes (NB), and k-Nearest Neighbors (KNN) for presenting the performance of classifier (illustrated in section “Performance”). The classification model is the bi-classifier of the IoT devices. In particular, for an unknown packet that the DC collects in the cyberspace, the classification model can determine whether it comes from an IoT device.
Implementation. We have implemented the IDC model based on open-source libraries. If the format of the response payload is HTML, we extract words through utilizing the BeautifulSoup 14 which is a library in Python to parse HTML documents. In other formats, we directly use the Python parser to obtain the words of the response payload. The IDC uses the Chi-square test 12 to expand relevant features and leverages scikit-learn library 15 to infer the classification model of the IoT devices. It is noted that the classifier would be hardcoded in our system and automatically find those IoT devices.
IE
As aforementioned, the payload of the response data is written in natural language, mixing with various interference information. We cannot directly apply the NLP to extract owner information because NLP is brittle and domain-oriented leading to low precision. A key observation is that the organization name may be followed by a fixed set of context terms (company, government, and education), and the individual name may be non-dictionary words. We have divided owner annotation of IoT devices into two categories as follows.
Organization type. Typically, we use organization definition from Wikipedia, which consists of a group of people with specific cooperation, such as governments, educational institutions, and corporations.
Individual type. We use individual as the reference to a distinct entity without cooperating others in the social concept. When an IoT device belongs to the individual type, it can be deployed at home/residences.
In the organization category, the IE utilizes the regex matching to extract the owner information of IoT devices. The regex is a sequence of characters for searching words that satisfy with the pattern. Here, we manually present 155 different context terms for presents following organization names. Many websites (i.e. “*edu?” and “*gov?”) would contain those string matching with the regex, which would decrease the accuracy of the IE. Fortunately, the response packets belong to IoT devices—those are filtered out by the IDC. The rule is heuristic: if the regex matches a string with a position, the IE will extract the 20 characters around the position. The IE would preserve the non-dictionary words as the owner annotation of IoT devices.
In the individual category, the IE uses NER to extract name entities in the response payload. NER is a typical NLP technique to determine words into predefined class. Differing from organization entities, there are no relevant context terms for individual entities. In addition, it is impossible to emulate all possible entities by human efforts. The IE uses rule-based NER to find the position of individual entities. The IE would calculate the dictionary density of every word in the payload. The IE choose top 90 words according to the reversal ratio of dictionary density. For NER, the IE defines one class to present the individual entity. If the word in the payload has related to the individual annotation, it would be classified as one label; otherwise none. The IE extracts the word labeled as the individual annotation for IoT devices.
Discussion. We propose the IE to extract owner information of IoT devices. However, it suffers the limitation that the payload does not contain any owner information because consumers do not write any related information into application services when they install IoT devices. In this case, the IE cannot extract any owner information in the payload for IoT devices. We attempt to address the limitation by querying the existing database. If our approach cannot solve the owner annotation of IoT devices, we send the online query to the most popular database WHOIS. 7 Notedly, we cannot guarantee that the return result from the WHOIS database is a real owner information. So far, our work is first to extract owner information for IoT devices in a best-effort manner.
Implementation. We have implemented the IE model for extracting owner annotation of IoT devices. We use regular expression patterns in Python to handle the predefined context terms in the response payload. The IE finds dictionary words and calculates their ratio by employing the enchant library. 16 We use the Stanford NER 17 in the IE to mark the annotation of words in the payload.
Evaluation
In this section, we present the real-world experiment to validate our approach, including DC, the classifier, and IE module. Then, we run the trained classifier and IE module on the unlabeled dataset from the whole IPv4 space. We further quantify and show the distribution of owner information of IoT devices at Internet-wide scale.
Performance
DC. To evaluate the effectiveness of the DC module, we deploy it in two network environments: a random /12 network block (1,048,576 IPv4 addresses) and a campus network block (65,536 IPv4 addresses). In the first stage, we send a TCP-SYN packet to every IP address and receive the reply packet. The time cost of the collection module is 20.97 and 1.31 s, respectively. The overhead of the collection module is acceptable in practice. In the second stage, we would build the three-hand connection with every live host and send HTTP request for obtaining the response data. As aforementioned, the status code illustrates the action sent by the service of live hosts. Figure 5 presents the distribution of HTTP status code in two network environments. We observe that the number of packets with 200 status code is largest. Redirection is commonly seen for receiving HTTP response data, where the percentage of 302 status code has reached nearly 15%. We need to re-send the request to the redirect address for obtaining the response data.

The distribution of status codes in the data collection.
Classifier on the labeled set. To evaluate the effectiveness of the classifiers, we have manually collected the dataset with labeled tags. The DC has collected all live hosts in the /8 network block. We mark the label to every response packet by human effort. If it belongs to an IoT device, the label would be marked with the IoT device; otherwise with the non-IoT device. The dataset contains 1100 packets from IoT devices and 14,000 packets from non-IoT devices. We experiment to validate the performance of the classifier in the following settings:
Model chosen. We experiment with four classifiers: Support Vector Machines (SVM), 18 Random Forest (RF), 19 Naive Bayes (NB), 20 and k-Nearest Neighbors (KNN). 21 They belong to supervised learning in the machine learning task that maps an input set to a smaller output set.
Parameter selection. We select different parameters for four classifiers. Kernel functions in SVM consist of linear, poly, sigmoid, and radial basis. RF contains two parameters, including the number of trees and tried attributes. The parameters in KNN are several distance, including Euclidean, Hamming, and Cosine. NB uses three distributions as its parameters, including Gaussian, Multinomial, and Bernoulli.
Training data size. We would further validate the impact of the training size upon the classification performance.
We perform a 10-fold cross validation on the labeled dataset for the IoT classifier. We use two evaluation metrics, precision and coverage (recall), since their counterparts

where
Figure 6 presents the performance of IoT device recognition according to different models and parameters. The x-axis is the coverage of the device identification, and y-axis is the precision. We observe that four classifiers have, on average, achieved 93% at the precision and 90% at coverage. The black circle represents the best performance of the classification and parameter, achieving 98% precision and 95% coverage. Table 2 shows the overview of device recognition performance in four classification models. We observe that RF has the performance with 99% precision and 99% coverage. SVM classifier with radial basis kernel function has achieved 97% precision and 97% coverage. SVM can generate a hyper-plane (a maximum margin) separating the packets between IoT devices and non-IoT devices. In the following experiments, we would use the SVM with radial basis kernel function as the classification model because of its robustness.

The performance of IoT device recognition in terms of different models and parameters.
The overall performance of four classification models.

SVM: support vector machines; RF: random forest; NB: Naive Bayes; KNN: k-nearest neighbors.
Furthermore, we have experimented to validate the impact of training dataset over the classifier. Here, we use the F1-score to describe the device recognition. F1-score is used to integrate the precision and coverage as follows

Figure 7 shows the changing of F1-scores of the classifier along with the size of training data. When the data size is larger than 5000, the performance of the classifier would keep stable and achieve at 96% F1-score.

The changing performance of IoT device recognition along with training data size.
IE. Finally, we have experimented to validate the component of IE. As aforementioned, the regular expression is used to find the organization owner, and NER is to identify the name of the individual owner. We have manually collected the owner information from the payload. If we are not able to determine whether the word belongs to organization entities, we use Google engine search to guarantee its correctness. There are 1.5k organization entities from IoT devices.
We cannot extract owner information of IoT devices when the payload does not contain it. Therefore, the number of false negatives (FN) is unknown, and we cannot calculate the coverage of the IE. For organization owner information, the regex matching reaches 98% precision. For individual owner information, the NER also reaches 98% precision.
We further experiment to measure the components overhead of IE. Table 3 presents its overhead, including memory usage, CPU and time latency. As we observe, the overhead of the regex matching is negligible compared with other two components. NER processes the whole payload to extract owner information, which needs highest computing resource. The time cost of online query focus on the network transmission delay. The overhead of the IE is acceptable in practice.
The overhead of information extraction.

CPU: central processing unit; NER: name entity recognition.
Analysis on the unlabeled set
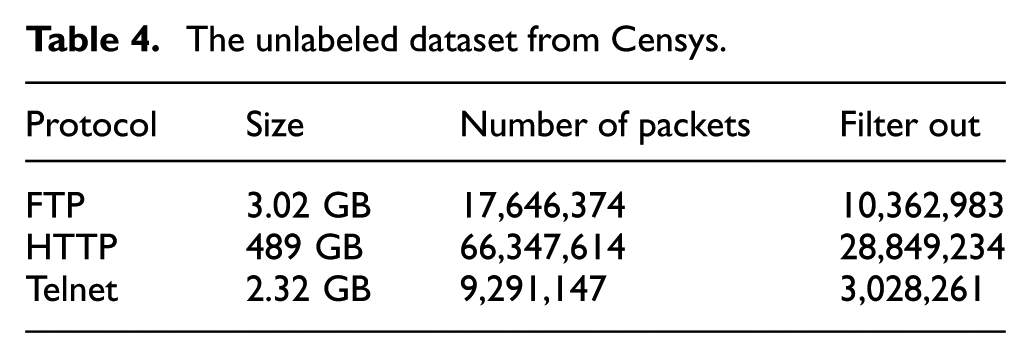
We have deployed the IDC and IE modules on a much larger unlabeled dataset, which comes from Censys. 6 We use the IDC to identify all response packets that belong to IoT devices and the IE module to extract owner information (manufacturer names) from those IoT devices. Censys is an open-source platform for collecting packets in the application protocols, consisting of industrial control protocols, HTTP, FTP, and Telnet. Here, we use one snapshot (7 December 2017) to analyze the owner information of IoT devices, as shown in Table 4. We use the status codes and length size to filter 28 million HTTP packets from 66 million packets. In addition, we obtain 10 million FTP response packets and 3 million Telnet packets.
The unlabeled dataset from Censys.
For the IoT device recognition, the IDC module uses the feature vectors with 30 dimensions and the SVM classifier with radial basis kernel function. The IDC runs those response packets and finds nearly 4.3 million (4,359,647) packets that come from the IoT devices. It is noted that every packet was collected from an IPv4 address, and there are at least 4.3 million IoT devices that are exposed in the cyberspace. Compared with the estimated amount from the Gartner report 1 (20 billion), the exposed IoT devices only have a subtle portion (0.02%). The reason is that most devices are hiding behind the private networks (i.e. home or enterprise networks), and the dataset from Censys contains devices in the public IPv4 space. However, the number of exposed IoT devices is still significant. In the security perspective, those consumer-oriented devices should not be visible or reachable from the public space. Malicious users and attackers may exploit those exposed IoT devices.
After discovering IoT devices, the IE module is used to extract the owner (manufacturers) information from those devices. The IE runs those 4.3 million response packets of IoT devices. Specifically, the IE uses the regex and NER to identify the individual(organization) annotation. Figure 8 presents the cumulative distribution function (CDF) curve of the numbers of owners across those IoT devices. We observe that nearly 71% owners only have one IoT device exposed in the cyberspace. Totally, there are 602,941 owner annotation among 4.3 million IoT devices. On average, a device owner would expose nearly 7.1 IoT devices to the public. Typically, the distribution of device owners is a typical trail effect in the cyberspace. Furthermore, we extract the owner (manufacturer) annotation that has largest number of IoT devices. Table 5 depicts the 10 owner annotations among the IoT devices. The first column is the name of owner annotation, and the second column is the number of IoT devices with the percentage. Particularly, we have found that the organization Amazon Technologies Inc. has more than 60,000 exposed IoT devices.

Cumulative distributions for device owners in the IPv4 space.
The top 10 device owner (manufacturer) information.

Related work
In this section, we review the literature by providing two distinct taxonomies in IoT from both the network measurement perspective and from the IE perspective.22–28 We attempt to shed light on the state-of-the-art of those research areas for pinpointing the different place which our paper addresses.
Network Measurement. Discovering devices needs to measure the network, due to the increasing number of IoT devices in the cyberspace. There are two categories of the network measurement, including active probing and passive monitoring. In the active probing, previous works focus on reducing the latency of the network measurement. Heidemann et al. 29 were first to survey the reachable and visible hosts in the IPv4 space, which took 30 days, while Leonard and Loguinov 30 proposed the URL scanner for demystifying three factors influencing the latency of the network measurement, including scan order, scan origin, timeouts, and duration. IRLscanner would probe the IPv4 space within 24 h. Durumeric et al.6,9 proposed Zmap, which would finish the measurement within 45 min at Internet scale. However, Zmap cannot achieve the theoretical upper bound because the response packet would contain loss quickly when the speed of probing exceeds 50k packets/s. In contrast, we re-use Zmap to collect the live hosts in the cyberspace and infer the classifier to recognize IoT devices from the candidate set.
In the passive monitoring, analyzing the traffic from vantage points to conduct the network measurement. The UCSD network telescope 31 is the biggest traffic monitoring system, consisting /8 networks, which is used for detecting malicious attacks in the cyberspace. Prior works used data mining techniques to analyze the telescope data for finding the relationship between attacks and abnormal traffic. 32 Rossow 33 used the telescope data to qualify the amplification attacks in the cyberspace. Antonakakis et al. 4 analyzed Marai Botnet, composed of IoT devices, that attacked the domain name system (Dyn), causing Internet service disruption across Europe and the United States. Hao et.al. 34 utilized application-layer traffic to detect redirection hijacking in content delivery networks (CDN), and Jin et al. 35 further provided a comprehensive analysis about the protection mechanism against DDoS. Our work would determine whether those malicious attacks come from IoT devices, as the supplement to the passive monitoring.
IE. WHOIS 7 is the most popular database for obtaining organization of IP addresses, requiring the registration with RIRs. Online reverse DNS (rDNS) and GeoIP 36 would parse the mapping between IP addresses and their locations (organizations) at the coarse gain. Shodan 37 is the world’s first search engine for Internet-connected services, which utilizes the WHOIS to find owner information. Feng et al. 38 utilized the semantic information from industrial control systems (ICS) protocol packets to provide the characteristics of the critical infrastructure in the cyberspace. Li et al. 39 further extracted the different implements of filesystems among IoT devices for generating their fingerprints. However, their work 39 would send dozens of packets to obtain the device fingerprints rather than our work. In this article, we propose the online query when the payload does not contain owner information. Today, NER is usually used to extract predefined entities from the text content. X Feng et al. 40 proposed the Stanford NER to discover the entity from webpages for identifying device annotation for extracting relevant information of IoT devices. However, NER relies on the specific domain, which cannot be directly used in other domain. They are different from our work, which leverages rule-based NER to extract individual name entities and the regex to match organization name entities.
Conclusion
As IoT devices become pervasive in many industries, managing and protecting those devices would be essential for security professionals and administrators. In this article, we are seeking the question who owns those IoT devices and investigating why exposes them to the public. Based on the assumption, relevant information existing in the application-layer service of IoT devices, we leverage machine learning and NLP to extract device owner information automatically. Specifically, the classifier determines whether the response packet comes from an IoT device, and NER extracts owner annotation from the data payload. We have conducted the real-world experiments, and results show that our approach has achieved 97% precision and 97% coverage. Furthermore, our approach is running in the unlabeled dataset to analyze the IoT devices from the whole IPv4 space. Based on the analysis, we have found that there are 4.3 million IoT devices exposed to the public, and the distribution is a long-tail effort.
Footnotes
Handling Editor: Junggab Son
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Key R&D Program of China (2017YFB0802804) and National Natural Science Foundation of China (61602029 and 61702503).