
Abstract
In ubiquitous streaming data sources, such as sensor networks, clustering nodes by the data they produce gives insights on the phenomenon being monitored. However, centralized algorithms force communication and storage requirements to grow unbounded. This article presents L2GClust, an algorithm to compute local clusterings at each node as an approximation of the global clustering. L2GClust performs local clustering of the sources based on the moving average of each node’s data over time: the moving average is approximated using memory-less statistics; clustering is based on the furthest-point algorithm applied to the centroids computed by the node’s direct neighbors. Evaluation is performed both on synthetic and real sensor data, using a state-of-the-art sensor network simulator and measuring sensitivity to network size, number of clusters, cluster overlapping, and communication incompleteness. A high level of agreement was found between local and global clusterings, with special emphasis on separability agreement, while an overall robustness to incomplete communications emerged. Communication reduction was also theoretically shown, with communication ratios empirically evaluated for large networks. L2GClust is able to keep a good approximation of the global clustering, using less communication than a centralized alternative, supporting the recommendation to use local algorithms for distributed clustering of streaming data sources.
Introduction
Nowadays, information is generated and gathered from distributed data sources, at a very high rate, stressing communications and computing infrastructure. Basically, data are being produced continuously everywhere. To make sense of these ubiquitous data streams, knowledge discovery techniques, which try to extract patterns and concepts from raw data, have become a major tool for all sorts of applications. One of the most popular knowledge discovery techniques is clustering, the process of finding groups in data such that data objects clustered in the same group are more alike than objects assigned to different groups.
Clustering streaming data sources is the task of clustering different sources of data streams, based on the data series similarity. 1 Algorithms aim to find groups of data sources that behave similarly through time, which is usually measured in terms of the distance between the data series or the data distribution. The goal of an incremental clustering system for streaming data sources is to find (and make available at any time t) a partition P of those sources, where data sources in the same cluster tend to be more alike than data sources in different clusters. 2 But classical methods tend to become obsolete for application in streaming and (especially) ubiquitous settings, due to their high time and space complexity. Hence, new machine learning algorithms are being developed to cope with this new demanding scenario, and different quality indices and evaluation strategies are being considered. 3
The aim of our work is to enable the clustering of distributed streaming data sources without a centralized control process, building on the following research question: can local algorithms approximate the global clustering of the entire network without a centralized server? Specifically, we intend to define a general approach to achieve a global clustering definition locally at each node, without a central server and validate whether quality clustering can be achieved with such procedure. The test setting of our study is sensor networks, given their distributed and resource-demanding characteristics. Moreover, in this article, we will focus on sensors producing univariate streams of data, performing clustering based on the moving average of each sensor’s data, but restraining communication to direct neighbors in order to avoid message forwarding, thus improving energy savings. We should stress that our problem is not to cluster sensor nodes for transmission purposes in wireless sensor networks, 4 rather find groups of sensors that generate similar data.
The aim of the evaluation is to assess quality in terms of agreement between local clustering definitions and the global clustering definition. Also evaluated is the communication reduction and robustness to communication incompleteness.
Rationale
Data are often ubiquitously produced. For example, data are generated by web clicks or network package routing on each machine; global positioning system (GPS) devices produce and process data locally; peer-to-peer applications even disregard centralized server processing; cellphone applications produce data from phone calls, text messaging, and wireless connections; and deep sky data are now being generated by telescope ensembles. The amount of data being produced in information and industrial systems is so high that no single database can hold all information. Rather, these data are produced, possibly stored, and definitely should be processed in distributed locations.
Paradigmatic examples of distributed streaming data sources are sensor networks and health information systems. Also, mobile computing devices like personal digital assistants (PDAs), cell phones, wearables, and smart cards play an increasingly important role in our daily life. The emergence of powerful mobile devices with reasonable computing and storage capacity is ushering an era of advanced data and computationally intensive mobile applications. 5 Our world is evolving into a setting where all devices, as small as they may be, will be able to include sensing and processing ability. 6 However, different types of devices present different levels of resources, and care should be taken in data mining methods that aim to extract knowledge from such restricted scenarios. 7 Given their ubiquitous characteristic (spatially distributed and continuous monitoring) and resource management requirements (e.g. battery), in the remainder of this article, we will focus on sensor network scenarios as an example of ubiquitous data sources.
Clustering data-stream sources
Clustering is probably the most frequently used data mining algorithm, used as exploratory data analysis. 8 The main problem in applying clustering to data streams is that systems should consider data evolution, being able to compress old information and adapt to new concepts. Two different clustering problems exist: clustering streaming data points and clustering streaming data sources. Clustering streaming data points is the task of clustering data flowing from a continuous stream, based on data points similarity, 9 aiming to discover structures in data over time. 10 Algorithms usually search for dense regions of the data space, identifying hot-spots where streaming data sources tend to produce data. 6 Clustering streaming data sources is the task of clustering different sources of data streams based on the data series similarity. 11 Algorithms aim to find groups of data sources that behave similarly through time, which is usually measured in terms of the distance between the data series or the data distribution. The goal of an incremental clustering system for streaming data sources is to find (and make available at any time t) a partition P of those sources, where data sources in the same cluster tend to be more alike than data sources in different clusters. 2
Distributed clustering of streaming sources
Several issues emerge in the development of new techniques to efficiently and effectively perform clustering of distributed streaming data sources. 1 This is an emerging area of research which has been already studied in various fields of real-world applications.11–13 However, algorithms previously proposed tend to deal with data as a centralized multivariate stream. 6 They are designed as a single process of analysis, without taking into account the locality of data produced by sources on a distributed scenario, the transmission and processing resources of the network, and the breach in the transmitted data quality.
Most works on clustering analysis for distributed sources (e.g. sensor networks) actually concentrate on clustering the sources by their geographical position14,15 and connectivity, mainly for power management 16 and network routing purposes. 17 However, in this topic, we are interested in clustering techniques using the data produced by the sources, instead.
In previous work, 18 the requirements of clustering distributed streaming data sources have been discussed and enumerated: (a) the requirements for clustering streaming data sources must be considered, with more emphasis on the adaptability of the whole system; (b) processing must be distributed and synchronized on local neighborhoods or querying nodes; (c) the main focus should be on finding similar data sources irrespective to their physical location; (d) processes should minimize different resources (mainly energy) consumption in order to achieve high uptime; and (e) operation should consider a compact representation of both the data and the generated models, enabling fast and efficient transmission and access from mobile and embedded devices.
Many algorithms have been developed for distributed clustering in peer-to-peer environments and sensor networks settings. However, they do not target our problem, as they might operate with a central server,19,20 are directed toward data clustering and not data sources,21,22 address homogeneous distributed clustering—each node having a sample of the same data23,24—or, if they target clustering of streaming data sources, they take into account the network infrastructure in the process of finding a clustering definition. 25 The final goal is to infer a global clustering structure of all relevant data sources. Hence, approximate algorithms should be considered to prevent global data transmission.
Advantages of application
Although transversely relevant to most ubiquitous applications, the advantages of distributed clustering of streaming data sources are better analyzed in specific real-world applications.
On real-world domains
In electricity supply systems, the identification of demand profiles (e.g. industrial or urban) by clustering streaming sensors’ data decreases the computational cost of predicting each individual subnetwork load. 26 This is a common scenario with thousands of different sensors distributed over a wide area. As sensors are naturally distributed in the electrical network, distributed procedures which would focus on local networks could prevent the dimensionality drawback.
A common problem in geoscience research is the monitoring of natural phenomena evolution. Several techniques are currently being used to address these problems, and given their increasing availability, sensor-based approaches are now hot topics in the area. Sensor nodes can be densely deployed either very close or directly inside the phenomenon to be observed: 27 ocean streams or river flows, a twister or a hurricane, and so on. Sensors deployed in the objective area can monitor several measures of interest, such as water temperature, stream gauge, and electricity resistance. Clustering the data produced by different sensors is helpful to identify areas with similar profiles, possibly indicating actual water or wind streams.
The GPS is commonly used to monitor location, speed, and direction of both people and objects. Identifying similar paths, for example, in delivery teams or traffic flow, is a relevant task to current enterprises and end users. 28 Embedding these systems with context information is now a major research challenge to be able to improve results with real-time information. 29 However, the amount of data produced by each GPS receiver is so huge, and the allowed latency so narrow, that performing centralized clustering of GPS tracks becomes too expensive. If each receiver is used to perform a distributed procedure for the clustering task, the same goal should be achieved faster with better resource management.
In medical environments, clustering medical sensor data (such as electrocardiogram (ECG) and electroencephalogram (EEG)) is useful to determine association between signals, 30 allowing better diagnosis. Detecting similar profiles in these measures among different patients is one way to explore uncommon conditions. Mobile and embedded devices could interconnect different patients and physicians, without revealing sensible information from patients while nevertheless achieving the goal of identifying similar profiles.
On sensor network management
Distributed clustering of streaming data sources presents advantages for everyday processing in sensor networks. We can point out the implications in three areas: message forwarding, deployment quality, and privacy preservation.
One of the highest resources consuming tasks in sensor networks is communication. Moreover, information is usually forwarded through the network into a sink node. With sensors increasing in number, redundant information is also more probable, so message forwarding will become a heavy-resource leak. If a distributed clustering procedure is applied at each forwarding node, usual data aggregation techniques could be data-centric, in the sense that one node could decide not to transmit a message, or aggregate it with others, if it contains information which is quite similar to other nodes.
When sensor networks are deployed in objective areas, the design of this deployment is most of the times subject to expert-based analysis or template-based configuration. Unfortunately, the best deployment configuration is sometimes hard to find. Applying distributed clustering of sensors’ data streams, the system can identify sensors with similar reading profiles, while investigating whether the sensors are in the same geographical cluster. If similar sensors, with respect to the produced data, are placed in a dense, with respect to the geographical position, cluster of sensors, then resources are spoiled as some of the sensors would give the same information. These sensors could then be assigned to different positions in the network.
The privacy of personal data is most of the times important to preserve, even when the objective is to analyze and compare with other people’s data. Anonymization is the most common procedure to ensure this but experience has shown that it is not flawless. This way, centralizing all information in a common data server could represent a more vulnerable setup for security breaches. If we can achieve the same goal without centralizing the information, privacy should be easier to preserve. Furthermore, the system could achieve a global clustering structure without sharing sensible information between all nodes in the network, somewhat similar to clustering using the fractal dimension. 31
On sensor network comprehension
Sensor network comprehension tries to extract information about global interaction between sensors by looking at the data they produce. 6 However, common applications usually inspect behaviors of single sensors, looking for threshold-breaking values or failures. To increase the ability to understand the inner dynamics of the entire network, deeper knowledge should be extracted.
The distributed setup proposed in this section enables a transient user to query a local node for its position in the overall clustering structure of sensors, without asking the centralized server. For example, a query for a given sensor could be answered as “this sensor and sensors 2 and 3 are highly correlated” in the sense that when one’s values increase, the other sensors’ values also increase or “the answering sensor is included in a group of sensors that has the following profile or prototype of behavior.” Hence, the comprehension of how sensors are related in the network is also greatly improved by using distributed sensor clustering techniques.
Consider mobile sensor networks where each sensor produces a stream with its current GPS location. Clustering the examples would give an indication of usual dispersion patterns, while clustering the sensors could give indication of physical binding between sensors, forcing them to move with similar paths. Another application could rise from temperature/pressure sensors placed around geographical sites such as volcanoes or seismic faults. Furthermore, the evolution of these clustering definitions is also relevant. If each sensor’s stream consists of IDs of the sensors for which this sensor is forwarding messages, changes in the clustering structure would indicate changes in the physical topology of the network, as dynamic routing strategies are commonly encountered in current sensor network applications. Overall, the main goal of sensor network comprehension is to apply automatic unsupervised procedures to discover interactions between sensors, trying to exploit dynamism and robustness of the network being deployed. 6
L2GClust—local-to-global clustering
A local algorithm is proposed to approximate the global clustering of sensors on ubiquitous sensor networks, based on the moving average of each node’s data over time. There are two main characteristics. On one hand, each sensor node keeps a sketch of its own data. On the other hand, communication is limited to direct neighbors, so clustering is computed at each node. The moving average of each node is approximated using memoryless fading average, while clustering is based on the furthest-point algorithm applied to the centroids computed by the node’s direct neighbors. This way, each sensor acts not only as data stream source but also as a processing node, keeping a sketch of its own data and a definition of the clustering structure of the entire network of data sources.
On one hand, local algorithms are one of the most efficient family of algorithms developed for distributed systems. Local algorithms are in-network algorithms in which data are never centralized, but rather, computation is performed by the peers of the network. In a local algorithm, it often happens that the resources needed to compute the function are independent of the size of the system, therefore exhibiting high scalability, in comparison with their global counterparts. 32 On the other hand, averages can be viewed as the values minimizing quadratic cost functions. Quadratic optimization problems are very special since their solutions are linear functions of the data, in which case a simple accumulation process leads to a solution. 33 Hence, there is a relevance in monitoring average values.
In this work, we search for a definition of k clusters of sensor nodes, with k previously known by the system. Although this simple problem statement lacks some of the common characteristics of real-world scenarios (e.g. unknown number or clusters or unbalanced data), its extension is straightforward. Figure 1 presents a simple and illustrative toy example of the outcomes that such a local algorithm should achieve, using incremental average computations and incremental k-means clustering at each node.
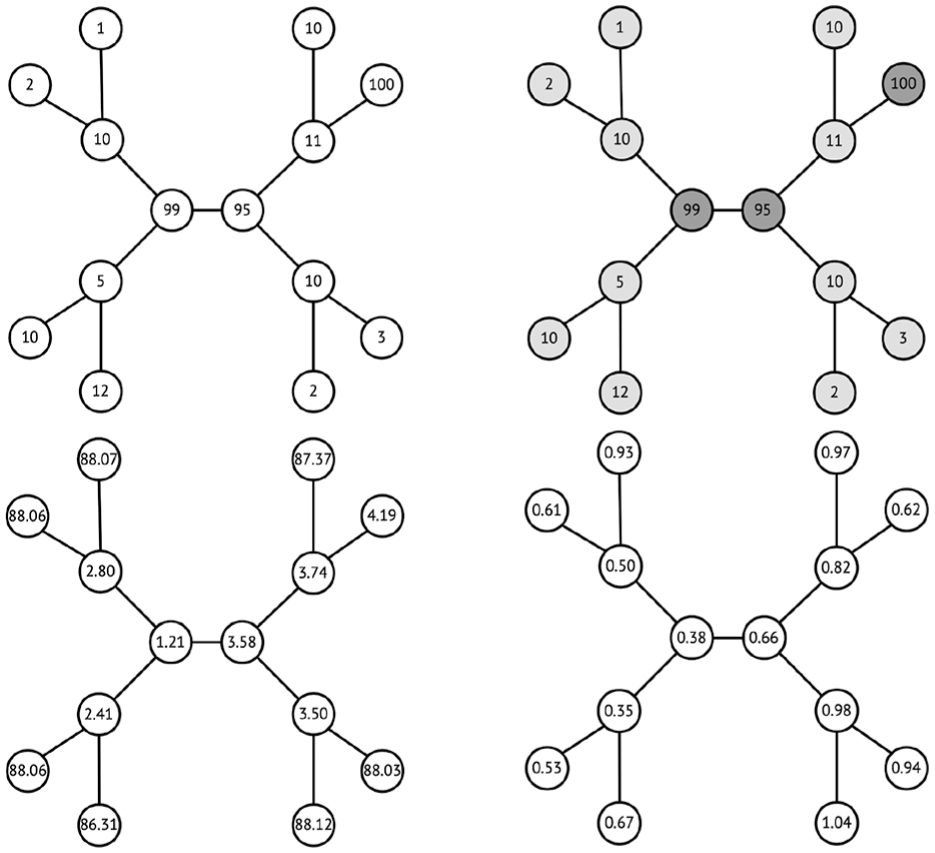
Toy example of a sensor network: in top plots, each sensor s produces a stream
Local data stream sketches
As previously stated, we consider that each sensor produces a univariate stream of data, and we want to define a clustering structure for the sensors, where sensors producing streams which are alike are clustered together. Hence, we should consider techniques that project each sensor’s data stream into a reduced set of dimensions which suffice to extract similarity with other sensors. These estimates can be seen as the sensor’s current view of its own data, giving a sign of where in the data space this sensor is included.
6
One simple way to summarize a data stream x is by computing its sample mean
Memory-less fading average
Each sensor produces data continuously. Given this, each sensor s is responsible of keeping its own estimate of the sample mean
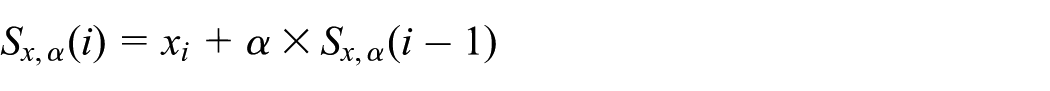
where

where

Each value of

Comparison of the evolution of the moving average (thick black line, window size
Impact on ubiquitous processing
We propose to use the
Sensors produce readings asynchronously, so sketch update needs to be triggered with the arrival of a new data point, irrespectively of the time elapsed since the previous point. Future developments should take time into account, if more complex sketches are to be computed. In resource-restricted streaming scenarios, such as sensors and embedded devices, memory is also scarse. Certainly, the biggest advantage of using the
Local clustering of stream sources
The goal is to have at each local site an approximation of the global clustering structure of the entire sensor network. Each sensor should include incremental clustering techniques which operate with distance metrics developed for the dimensionally reduced sketches of the data streams. Also, and although in several real-world scenarios this is not true, we should not assume the sample mean of each sensor to be correlated with its physical location and connectivity, as the matching between data clusters and physical clusters is a promising strategy for sensor network comprehension, so we should not bias the clustering solution. 6
Dissimilarity measure
Given the simple sketch definition, the dissimilarity between two sensors x and y is the absolute distance between their sample means,
Neighborhood communication
Each sensor x is not only able to sketch its own data in a dimensionally reduced definition (the fading average
Neighborhood ensemble
At first observations, each sensor node x has only access to its own sketch
The idea behind this step is to aggregate all the locally defined centers and apply a clustering procedure on these centers, considering them as points for the clustering. This way, if next time this sensor uses or transmits its estimate
Furthest-point clustering
In the general task of finding k centers given m points, there are two major objectives: minimize the radius, the maximum distance between a point and its closest cluster center, or minimize the diameter, the maximum distance between two points assigned to the same cluster.
20
The Furthest Point algorithm
37
gives a guaranteed two approximations for both the radius and diameter measures. It begins by picking an arbitrary point as the first center,
Algorithm overview
Figure 3 presents the procedure executed in each local node. Nodes are in sleep mode. When a new observation is produced, the local sketch (

L2GClust procedure executed at each local node.
As previously shown in Figure 1, the proposed local algorithm should be able to, using only local communications in a network where each node generates data according to a univariate distribution (top left) and where nodes could be clustered according to that distribution (top right), generate local estimates of the global clustering which, during initial iterations (bottom left), might be still locally biased far from the real centroids, but iteratively converge toward them (bottom right).
Space, time, and communication complexity
It is simple to assess that while the sketching procedure, at each node, takes
Given the defined methodology for communication in the local algorithm, at each transmission, each node broadcasts one message of k values. Hence, at each iteration,
Evaluation methodology
The global aim of this work is to assess the feasibility of computing local approximations of the global clustering structure of a ubiquitous network of streaming data sources.
Simulation environment
UC Berkeley’s project Ptolemy 38 produced an open-source, Java-based, software framework called Ptolemy II, with tools for the modeling, simulation, and design of concurrent, real-time, embedded systems. The main underlying software abstraction is the actor, software components that execute concurrently and communicate through messages sent via interconnected ports. Application-specific models can then be represented as hierarchical interconnections of actors coordinated by special components called directors. Visual Sense 39 was developed under this common framework specifically to allow the modeling of wireless sensor networks. In particular, each sensor can be implemented as one or more actors that communicate with each other. The tool allows very sophisticated modeling of features like communication channels, hardware sensor devices, networking protocols, Medium Access Control (MAC) protocols, and energy consumption in sensor nodes. Figure 4 presents an example of sensor network simulated on Visual Sense. All experiments in this article were implemented using the Visual Sense sensor network simulation environment. In order to implement L2GClust, we defined three Java classes that define the behavior of the “sink actor,” the “sensor actor,” and the “data actor.” These classes extended Ptolemy’s base class “atomic actor.”

An example of a Visual Sense simulation environment with 128 sensors, where circles denote the range of transmission, hence defining links between nodes.
The data actor
This actor produces a new random value upon receiving a signal from the clock actor. The value is sent to the “sensor actor” which processes it. Each sensor node is uniformly assigned to one of the k clusters. Each data actor keeps the information about which cluster it belongs to (given my the mean
The sensor actor
This actor is responsible for receiving and parsing messages from its neighbors, adding the values contained in those messages (cluster’s centroids) to a buffer. It also receives values produced by the “data actor,” which are the values produced by the sensor node. Each time one of those values is received, it is used to update the
The sink actor
The sink actor is only needed here for evaluation purposes. In actual execution, all processing is done at local nodes. The sink computes a global clustering definition, based on the raw data streams transmitted by the sensor nodes, and compares it to the local clustering derived by each sensor, quantifying the level of agreement between local and global clustering definitions (explained later in next sections).
Evaluated scenarios
In order to assess the quality of our proposal, evaluation was done considering two different scenarios. First, artificial data were created and used on simulations of sensor networks. Then, real data from electricity demand sensors were used as input to the simulated networks.
Description of artificial data
Although in real world, data are seldomly random or normally distributed, a first validity check was designed with a synthetic sample of such data. In this experiment, we follow the scenario design used in Domingos and Hulten,
40
where data are generated in the unit hypercube. Each scenario was produced according to three parameters: the number of clusters K, the number of sensor nodes D, and the standard deviation
Description of real electricity demand data
Sensors distributed all around electrical-power distribution networks produce streams of data at high speed. From a data mining perspective, this sensor network problem is characterized by a large number of variables (sensors), producing a continuous flow of data, in a dynamic non-stationary environment. 26 In this context, one important task is to define profiles of consumers, to better predict their behavior in the near future. The log of data from active power sensors was fed to our simulator to check whether these profiles would rise. The log has hourly data from 780 sensors for more than 2.5 years (22,364 timestamps). Since no information exists on the actual electricity distribution network, the simulator used this dataset as input data to a random network and monitored the resulting clustering structures.
Description of simulated networks
Each data scenario is applied to several network configurations. These differ on network size and network configuration. Each network is generated by a cascade procedure within the Visual Sense 1000 × 1000 pixel square: first, a random point is selected for the first sensor node; then, each sensor node is placed at a time in the network geographical space by uniformly sampling a previous sensor node and randomly choosing a point within the predefined range of that chosen sensor node (in our experiments, range = 300). Sensors which are placed closer than 150 from any previously placed node are relocated. For each network size, three different configurations are generated.
Studied parameters
To determine the sensitivity of our approach to the random effects produced by the evaluation setting, the analysis is done in three dimensions: network size
Comparison
Our goal is to assess the feasibility of computing local approximations of the global clustering structure. This way, we will compare the clustering definitions of each sensor node
Measured outcomes
When dealing with clustering algorithms, several validity measures exist that can fulfill any researcher’s desire (see Halkidi et al. 8 for a comprehensive study on this topic). They are usually segmented in internal, external, and relative validity criteria. When evaluating the clustering quality of an algorithm, only internal and relative criteria should be used, as they are as unsupervised as clustering is. However, when the goal is to compare clustering definitions, external validity might then be used, as long as the comparison is agreed to be the gold-standard for that problem.
Agreement as quality assessment
More than computing a loss function or a validity index for each sensor’s clustering definition, the goal of our work is to achieve a local clustering definition at each sensor that would agree with the global clustering definition, if queried to assign each pair of sensors in the network to the same or to different cluster centers. Several external validity indices are based on the agreement of clustering assignments, such as the Jaccard coefficient, 41 but they are biased toward a strict comparison.
In this work, we propose to use the agreement theory directly, as different agreement proportions give different insights of clustering comparisons. To compute agreement between clustering definitions
by both
by
by
neither by
Note that
Sanity
A first check that needs to be performed is whether the agreement found in the observations is not just due to random effects. The

with

being the observed proportion of agreement and
Validity
Comparing clustering definitions according to improvement from agreeing only by chance is rather poor and is only used as sanity check. More interesting than
The goal is to have
Compactness
Positive agreement is interpreted as the conditional probability of agreement considering that one of the clustering definitions has already stated that the pair of sensors should be clustered together and is defined as
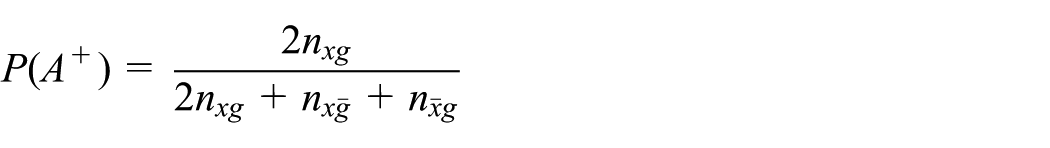
From our point of view, this clearly relates to the proportion of agreement on compactness of the clustering structure, focusing on the pair of points that both clustering definitions state should be together.
Separability
Negative agreement is interpreted as the conditional probability of agreement considering that one of the clustering definitions has already stated that the pair of sensors should be separated and is defined as
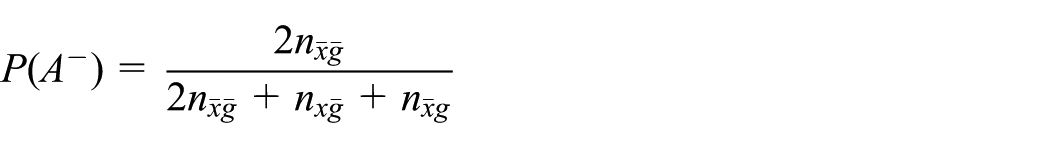
From our point of view, this clearly relates to the proportion of agreement on separability of the clustering structure, focusing on the pair of points that both clustering definitions state should be separated.
Robustness to data incompleteness
In adverse settings, as deployed sensor networks, communication is not flawless. In any installation, packet loss is more or less probable. Given this, one outcome that we also assess in this exposure is the robustness of the system to communication incompleteness.
For a given network setup, with fixed number of sensors
Communication reduction
The main outcome that local algorithms try to improve is communication. In our setting, we should assess whether our solution reduces the overall communication when compared to the amount that would be required if data were gathered centrally.
For each evaluated network setup, with fixed number of sensors
Global assessment
Globally, next section will try to answer the following research question: Can L2GClust deliver in terms of cluster sanity, validity, compactedness and separability, communication reduction and robustness to communication incompleteness, when compared to the centralized stream clustering procedure which uses all sensor data directly, if Gaussian data are produced at each node according to a given mean, which was randomly and uniformely sampled from a set of Gaussian clusters?
Each experimental run results in a learning curve for each validity index. Left plot of Figure 5 presents the evolution of the average

Evolution of the average proportion of agreement between sensors and the global clustering definition (one experimental run with
Since for each data scenario (k, σ, and d) 10 runs are executed for each of the three configurations of the sensor network, results are presented as mean values (and the corresponding 95% confidence interval) over the 30 runs. Given the convergence empirical observation (different scenarios converge at different number of node interactions), we compare the means (over all runs) for the fading average of each measure at the end of each run.
Evaluation results
In this section, we present the empirical results obtained from the evaluation setup previously presented. First, in terms of the agreement to the global clustering and then considering robustness to data incompleteness and communication reduction.
Agreement with global clustering
Tables 1 and 2 present the complete set of results from which most of the following interpretations can be drawn. The first result to extract is that all scenarios passed the sanity check, as
Clustering validity results, in terms of

CI: confidence interval.
Clustering validity results, in terms of

CI: confidence interval.
After confirming the sanity of our approach, we can stress that a high level of average agreement is achieved for most of the scenarios. Focusing on the lower limits of the 95% confidence intervals,
Regarding the direction of agreement, we should stress that our approach clearly gives more relevance to separability. In all scenarios where the average proportion of positive agreement (compactness) is different (under the 95% confidence level) from the average proportion of negative agreement (separability), the separability index is always higher than the compactness index.
Moreover, even for scenarios with lower average proportion of agreement, separability tends to stay high (
Finally, it became clear that at least for harder scenarios, it is very difficult to achieve networks where all nodes agree with central clustering on 100% of pairs of nodes. From our observation, this might result from different node connectivity (nodes placed on the outer ribbon of the network could have more difficult to converge to global clustering). Nevertheless, results put the agreement at a high level, stating that local clustering gives a good approximation of the global clustering.
Robustness to data incompleteness
Figure 6 presents the average proportion of agreement for the evaluated setups, averaged over 10 runs, and the corresponding 95% confidence intervals. Although the setting is one of the hardest that was studied in this evaluation (

Impact of communication incompleteness on average proportion of agreement. Lines represent the average result of 10 runs for each setup (
Given the stability of the studied scenarios, and for at least a reasonable quality of service, it is expected that following transmissions should compensate the lost messages. However, we expect that the speed of convergence will be more sensitive to message lost. For the same setup, Figure 7 presents the evolution of the average proportion of agreement, at the very beginning of each run, for each level of communication incompleteness. The reader can note that, as expected, although at the end there might not be a difference in the agreement (besides extremely high levels of incompleteness), there is a difference in the speed at which the system converges to that level of agreement.

Impact of communication incompleteness on the evolution of the average proportion of agreement. Lines represent the average result of 10 runs for each setup (
Communication reduction
Figure 8 presents the estimates of the average number of hops that messages need to traverse in order to reach the sink. Our objective was to show the average number of point-to-point data transmissions that the system would need to perform so that a single message containing the data of one node could reach the sink. We do this in three different scenarios where the sink is chosen as the best possible one, the worst possible one, and on average, all in a randomly generated network of 128 nodes. The reader can note that even if the deployment enables a perfect routing path, and the definition of the best possible sink node is possible, in the evaluated scenario the average number of hops to the sink is 4. Hence, the local-to-global communication ratio for

Average number of hops to sink, for networks with
Certainly, the local approach must send multiple-valued messages (actually, k values per message), while the global solution sends single-valued messages. In terms of the number of transmitted values, only for scenarios where
Sensitivity to the number of sensors
Figure 9 presents an average assessment of the quality of the proposal, with the analysis of sensitivity according to different number and overlap of clusters, for an increasing number of sensors. A more detailed analysis on sensitivity to network configuration is out of the scope of this presentation. However, we can argue that agreement levels are robust to an increase in the number of clusters, being, however, a bit more sensitive with respect to network size (

Sensitivity of
Real data from electricity sensors
Real data are never clean, and half of the sensors have more than

Experimental results. Evolution of clustering agreement for a real active power sensor data log, where not only does the agreement tend to increase with more observations, but also changes on the clustering structure are apparently possible to detect.
Limitations and future work
Averages can be viewed as the values minimizing quadratic cost functions, hence there is relevance in monitoring average values. However, in streaming settings, deeper sketches are often needed. The convergence and validity properties of an extension of L2GClust to online histograms or other sketches are still to be proved. Also, asynchronous processing is often (if not always) the case in sensor networks. Other scenarios are also prone to synchronousness issues. Although the proposed local algorithm seems robust in those settings, a deeper evaluation of this issue is required.
If the concept of the data being produced in the network is stable, then the clustering estimates will converge, and transmissions will become redundant. We should include mechanisms to allow each sensor to decide to which neighbors it is still valuable to send information. However, the world is not static. It is possible that with time, the sketches of each sensor will change, adapting to new concepts of data. On a long run, the communication management strategy could prevent the system from adapting to new data. Sensors should include change detection 45 mechanisms that would trigger if the data change, either univariately at each sensor or in the global interaction of sensors.
As possible extension, since each node clusters its neighbors’ centroids as single points, the node could fit a clustering definition with different number of clusters. Moreover, it could fit three clustering definitions (e.g. with
The analysis on whether the quality of the local clusterings are related with their position in the network should be addressed in future work. It seems reasonable to expect that edge sensors have lower quality than central sensors, but this was not assessed. Also, internal validity indices should be used to assess the quality of a given local clustering, since no external comparison is possible in real world. Furthermore, the implementation on real sensors should be evaluated soon in a laboratorial environment.
Findings and recommendations
A local algorithm was proposed to perform clustering of sensors on ubiquitous sensor networks, based on the moving average of each node’s data over time. There are two main characteristics. On one hand, each sensor node keeps a sketch of its own data. On the other hand, communication is limited to direct neighbors, so clustering is computed at each node. The moving average of each node is approximated using memoryless fading average, while clustering is based on the furthest-point algorithm applied to the centroids computed by the node’s direct neighbors. Each sensor acts not only as a data stream source but also as a processing node, keeping a sketch of its own data and a definition of the clustering structure of the entire network of data sources.
From our empirical observations, we can argue that performing local clustering at each node, without a centralized server aggregating data from the network, is a valuable approximation of the global clustering that a centralized algorithm would gather. Local algorithms present an extremely high level of agreement with the global clustering, especially in terms of separability agreement: if according to the global clustering two nodes should be separated, local approximations will also state that with high probability. Moreover, the results on stable concepts are robust to communication incompleteness, supporting its application in adverse settings such as sensor networks. Furthermore, the gain in communication by disregarding a routing path and forwarding schema seems an important resource booster.
Even though processing may be concentrated on local computations and short-range communication, the final goal is to infer a global clustering structure of all relevant sensors. Hence, approximate algorithms should be considered to prevent global data transmission. Given this, when querying a given sensor for the global clustering, we allow (and known beforehand that we will have) an approximate result within a maximum possible error with a certain probability. Each approximation step (local sketch, local clustering update, merging different cluster definitions, etc.) should be restricted by some stability bound on the error. 46 These bounds should serve as balancing deciders in the trade-off between transmission management and resulting errors.
Moreover, if the concept of the data being produced in the network is stable, then the clustering estimates will converge, and transmissions will become redundant. We should include mechanisms to allow each sensor to decide to which neighbors it is still valuable to send information. However, the world is not static. It is possible that with time, the sketches of each sensor will change, adapting to new concepts of data. On a long run, the communication management strategy could prevent the system from adapting to new data. Sensors should include change detection mechanisms that would trigger if the data change, either univariately at each sensor or in the global interaction of sensor data.
We have presented a local algorithm to cluster ubiquitous streaming data sources produced in distributed sensor network settings. The proposed local clustering algorithm presents high level of agreement with a global clustering algorithm which could have been run in a centralized fashion, while reducing communication throughout the network and being robust to communication incompleteness. This local approach brings benefits for real-world applications and sensor networks, creating a research path with near-future improvements and applications, which enables the improvement of sensor deployment, might reduce message forwarding, preserves privacy of observed data, and improves network comprehension, in the sense that each sensor is able to tell where in the sensor data domain it is located.
Footnotes
Acknowledgements
This work has been developed under the scope of projects Nano STIMA (NORTE-01-0145-FEDER-000016) and SMILES (NORTE-01-145-FEDER-000020), both financed by the North Portugal Regional Operational Program (NORTE 2020), under the PORTUGAL 2020 Partnership Agreement and through the European Regional Development Fund (ERDF).
Handling Editor: Amiya Nayak
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This publication has been financed by project NanoSTIMA (NORTE-01-0145-FEDER-000016) which was financed by the North Portugal Regional Operational Program (NORTE 2020) under the PORTUGAL 2020 Partnership Agreement and through the European Regional Development Fund (ERDF).