
Abstract
Trust is an important criterion for access control in the field of online social networks privacy preservation. In the present methods, the subjectivity and individualization of the trust is ignored and a fixed model is built for all the users. In fact, different users probably take different trust features into their considerations when making trust decisions. Besides, in the present schemes, only users’ static features are mapped into trust values, without the risk of privacy leakage. In this article, the features that each user cares about when making trust decisions are mined by machine learning to be User-Will. The privacy leakage risk of the evaluated user is estimated through information flow predicting. Then the User-Will and the privacy leakage risk are all mapped into trust evidence to be combined by an improved evidence combination rule of the evidence theory. In the end, several typical methods and the proposed scheme are implemented to compare the performance on dataset Epinions. Our scheme is verified to be more advanced than the others by comparing the F-Score and the Mean Error of the trust evaluation results.
Keywords
Introduction
Online social networks (OSNs) are platforms or systems that people can interact with others by sharing or posting blogs online. 1 Social networking is very common, such as Facebook, Tweeter, Weibo and CyVOD. 2 These platforms provide a free space for everyone to unleash their mind and thoughts. However, it makes information leakage possible. 3 The spammers spread malicious links and annoying messages to OSN users without target, and privacy information is unsafe for the cheating actions 4 and blackmails. 5 To prevent the malicious activities, many schemes such as Access Control 6 and digital rights protection7–9 are proposed. In these schemes, trust degree is usually viewed as the main criterion for security policies to make the privacy management more feasible and effective.
As it is important to privacy preservation in OSNs, trust evaluation has become a research focus in recent years.10–13 Researchers try to find the relationship between user features and trust decision. It is no doubt that trust decision is not only affected by objective features of each user but also affected by the subjective options of the user. For example, some people think the one who has a lot of fans in the OSNs is trustworthy, while others would rather choose the people who have higher credit or reputation. So, just a single model without individualization is insufficient to evaluate trust degree between users in OSNs.
Besides, most present schemes evaluate trust degree based on present state of each user. If user u has been judged to be trusted, the message transferred to him will be deemed safe. Because message propagation takes time and the state of the user is not constant, privacy leaks may occur during message propagation due to changes in the state of the user. Therefore, trust evaluation should take the information flow risk into consideration to avoid privacy leakage in OSNs. The last but not the least, people trust has ambiguity; however, most present methods ignore it and give an absolute probability degree for Trusted or Untrusted. It is unreasonable unless there is no uncertainty in trust decision made by users and the result of trust evaluation is totally correct.
Aiming at the above problems, we provide an improved scheme to evaluate the trust between the users in OSNs. In our scheme, user features and information flow prediction result are mapped into trust evidence, and then combined based on evidence theory to obtain trust evaluation result.
The article is organized as follows. The “Related works” and “Preliminary” sections introduce the related works and the preliminary separately. In the “Trust evaluation based on the combination of evidence” section, the proposed scheme is illustrated in detail, including its design idea and practical implement approach. The performance of the scheme is mainly evaluated in the “Experiment and analysis” section. Finally, in the “Conclusion” section, we make some concluding remarks.
Related works
In most trust evaluation schemes, the inputs are user features such as similarity, intimacy, and reputation. 14 Zhao and Pan 13 proposed a trust evaluation method based on classifying user features. Brown and Feng 15 proposed a trust degree calculation scheme based on user influence and a K-shell algorithm. Similar to Brown’s work, Silva et al. 16 proposed another method based on user influence and information diffusion. Based on user credit and reputation, Tsolmon and Lees 17 proposed a trust calculation scheme using the features, such as follower number, tweet number, and reputation, as the input of their algorithm. Relatively, Mármol and Pérez 18 proposed a trust calculation method based on user behavior, user rating, and personal rewards.
Usually, users in real OSNs usually aggregate into communication groups to make their interactions facilitated. And the small world theory 19 which divides users into groups is used in some present trust computing methods to improve the accuracy and efficacy of the result. Zhang and Wang 20 proposed a scheme based on community group, feedback, and trust decay. According to Yang et al., 21 users in a topic circle trend to trust the leaders in this circle and be likely to transmit the message sent by other users in the same circle, and trust degree can be evaluated by computing the degree of influence between users.
Moreover, trust decisions made by users may affect the leaders and the experts in the OSNs. 21 Tsolmon and Lee 17 provided a leader-find method named hyperlink-induced topic search (HITS) based on computing the context transmitting in OSNs, ignoring the attributes such as follower number or favor count. In the work of the document, 22 the problem of selecting top-k expert users in social group based on their knowledge about a given topic is addressed. Chiregi and Navimipour 12 proposed a trust evaluation scheme based on the leader and expert in the OSNs.
Furthermore, trust degree is also affected by the flow of information. 23 If the probability that a requestor shares privacy message to a malicious user is high, the server will consider denying the transmission to avoid a privacy leakage. Ranjbar and Maheswaran 24 proposed a method for computing information flow probability in OSN. Jiang et al. 25 proposed a scheme for generating the trust graph of an OSN. Later, with the trust graph, he proposed a novel trust evaluation method based on information leakage. 11 However, some researchers believe that predicting information flow in the future precisely is non-deterministic polynomial (N/P) hard, and the real value can never be approached. 26 In this article, Monte-Carlo simulation (MCS) 27 is used to predict the information flow probability between each two users to make the result infinitely close to the real value.
Preliminary
Evidence theory
Evidence theory is an effective tool to make decision from information with ambiguity.28,29 It is widely used in decision making,30–32 target recognizing,33,34 and OSNs analyzing.35–37 In evidence theory, the set of all the possible decisions is called discern-frame θ. The element in θ is named as focal-element. A brief example is shown to illustrate the difference between single-element focal-element and multi-element focal-element in evidence theory. Assuming three suspects Jim, Tom, and Kate are involved in a murder case, three officers hold different views based on the existing trace just as Table 1 shows.
View of each officer.

In the last column, Tom, Jim, and Kate are single-element focal-elements, and the other ones are multi-element focal-element. In the first three columns of Table 1,
All the BPAs that came from a same officer will constitute the body of evidence (BOE):
Sometimes, another evidence weight set
Classify based on user features
In our scheme, classification is a necessary step to generate trust evidence, and the method we used is classification based on SVM (Support Vector Machine) 39 in RBF (Radial Basis Function) 44 type. Items in the training set are mapped into high dimension vectors, and the classification is realized by finding the optimize panel h that can tell all the vectors apart.
Denoting the normal vector of h as
MCS
Just as mentioned in the “Related works” section, the probabilities of message propagation among users are calculated to measure the risk of privacy leakage. However, the number of paths between two users is tremendous, and the flow path may not be the shortest path. That is to say, information flow prediction based on computing flow probability on every edge is infeasible. 26 Even though it is hard to get the probability of information flow between two users in every detail, an approximate value can be obtained based on MCS. MCS 27 is a kind of method that rely on repeated random sampling to obtain the calculation result. The essential idea is to find undiscovered laws through a lot of experiments, and it is very useful when the solving process of traditional approach methods is too difficult or too complex. By modifying the network topology and detecting the existence of the path for many times, the probability of information flow is obtained based on the concept of MCS.
Trust evaluation based on the combination of evidence
There are four parts in our schemes. In the first part, the individualization of trust evaluation is computed. We name this kind of individualization as User-Will, which is constituted by a set of weights and a set of value scopes to generate trust evidence. In the second part, features of user being evaluated are converted into a set of trust evidence based on User-Will. In the third part, another piece of trust evidence is obtained based on predicting the risk of information flow in future. In the last part, trust decision is made based on the combination of evidence and User-Will. Table 2 is the summary of symbols used in our scheme:
Summary of symbols.

Determination of User-Will
Just as mentioned in the “Related works” section, different users may care about different features when making trust decision; we denote this kind of trust-making individualization as User-Will. It contains two parts, weight set and scope set. Weight set is the importance degree of each user features and scope set is a set of value range to generate trust evidence. The method for generating value range and trust evidence will be introduced later, but the way to determine weights will be introduced in the following part.
To compute the weight set in the User-Will of
Define the function
To generate trust evidence, divide us into

In Algorithm 1, the training set is separated into two parts in lines 1 and 2. Trust scope, distrust scope, and ambiguity scope are generated in lines 3 to 8. A random weight set and function g are set in line 9. In lines 10 to 24, trust evidence is generated and combined. Similarity between scopes is defined as
Trust evidence based on User-Will
We assume that F is constituted by activity degree, Bi-Jacard degree, group degree, and reputation degree. Activity degree is defined as
To any feature
Trust evidence based on risk of information flow leakage
Besides, with user features mentioned, trust degree may be affected by the flow of information in the future. Privacy information may be available to the blacklist of the resource owner after being transmitted many times. And we take the scenario that if the probability that information flow between

Information flow threat.
In Figure 1, circles in dotted line and circles in solid line are the users in OSNs. The former one represents the remote users and the later one stands for the adjacent ones. User
In the process of information flow, the flow between any two points is not unique. Even though

Trust evidence combination
Taking trust evaluation between
Experiment and analysis
Experiment
In experiment part, we implement methods AveR-MaxT, AveR-WAveT, MaxR-MaxT, MaxR-WAveT, SWTrust*, 25 and GFTrust 11 which are proposed recently, and the experiment is based on the dataset Epinions, which is available on http://www.trustlet.org/extended_epinions.html. There are three files in the dataset, and the first file is the record of trust decision between each two users. Column MY_ID stands for the ID of the user who made the decision and column OTHER_ID is the ID of the user being evaluated. And VALUE column is the trust decision, where 1 stands for trust and −1 stands for distrust. In the second file, there are three columns CONTENT_ID, AUTHOR_ID, and SUBJECT_ID in it. CONTENT_ID is the ID of the comment or blogs that send by AUTHOR_ID. SUBJECT_ID denotes the ID of items being commented by user AUTHOR_ID, and the ID of this comment is COMMENT_ID. In the third file, there are eight columns in it but only three of them, OBJECT_ID, MEMBER_ID, and RATING, are useful. OBJECT_ID is the comment or blogs ranked by the user with its ID MEMBER_ID; the score of ranking is RATING which is ranging from 1 to 6. We use the same method in Jiang et al.11,25 to extract the same subset of this dataset, which is used in this experiment.
Just as mentioned in the “Trust evaluation based on the combination of evidence” section, trust evaluation result is based on User-Will and trust evidence. User-Will of each user is extracted by Algorithm 1, and BOE of each trust evidence is shown in Table 3.
Trust evidence and combination result.

The first column “MY_ID” in Table 3 stands for the ID of the user who made the trust decision and the weight of each user features belongs to “MY_ID.” And the value in column “OTHER_ID” stands for the ID of the user being evaluated. Based on Algorithm 2, weight of each evidence is determined, which is shown in the third column. Evidence
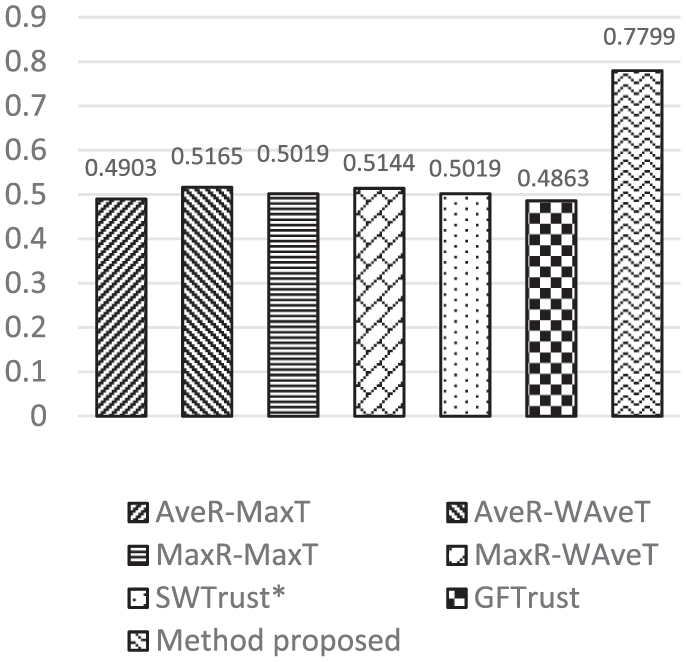
By counting the correct decisions that each method made, the comparison of accuracy and the comparison of F-Score are shown in Figures 2 and 3.
Accuracy of each method.

F-Score of each method.
From Figures 2 and 3, it is apparent that the accuracy and F-Score of our scheme are the largest. As the trust decisions made by users are Boolean, both two trust evaluation results may be correct even though they are not same. Taking trust degree between

Mean Error of each method.
Mean Error and F-Score of each method.

According to Table 4, the F-Score of our method is the largest and the Mean Error of our scheme is the smallest, which means the trust evaluation is more precise and accurate.
Analysis
In the above experiments, we compared the performance of methods proposed in Jiang et al.11,25 and our method from such aspects as Accuracy, Recall, F-Score, and Mean Error. It shows that our scheme has better performance in these aspects. For this result, we think the reason is mainly as bellows.
All the methods above, including ours, try to build the model of the mapping relationship between the trust decision and the user features, which is a classification process to divide the users into “trusted” and “untrusted” by their features, in essence. However, as we all know, trust is very subjective, that is, the same person usually has different trust values in the eyes of different people. If the trust decisions in the training set are made by different users, it will be very difficult to build the classification model, because the trust criterion is different from person to person. In our scheme, we choose the sample data from one user’s trust decisions to build the training set and obtain the classification model for himself. Since the inclination of one person is much more obvious, the classification model is easier to be built correctly, and, at the same time, one model for one user embodies the individualization and subjectivity quite well. The experiments prove it as we expect.
The F-Score and Mean Error of our method are 0.675 and 0.205, respectively. And the max F-Score and min Mean Error of methods being compared are 0.651 and 0.247. The experiment result shows that the trust decisions obtained through the proposed scheme are more accurate and better agreed with the real decisions according to the data from Epinions.
Conclusion
In this article, a new trust evaluation scheme based on evidence theory is proposed.
Our study achieved a better performance by focusing the issues as follows:
Determine the importance degree of each user features that each user cares about in making the decision to realize the individualization of trust evaluation.
Quantifying the risk of privacy leakage by information flow prediction to make the trust evaluation more comprehensive.
Use trust evidence to indicate the probability of trust, probability of distrust, and probability of ambiguity at the same time.
Compared with the existing methods, our proposed method achieves the highest accuracy and minimal error in the dataset Epinions. However, the weight part of User-Will does not contain the weight of trust evidence based on information flow risk, and the weight determination of this evidence will be our future work.
Footnotes
Handling Editor: Shaojie Tang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was sponsored by National Natural Science Foundation of China, Grant No. 61772174 and Grant No. 61370220; Plan for Scientific Innovation Talent of Henan Province, Grant No. 174200510011; Program for Innovative Research Team (in Science and Technology) in University of Henan Province, Grant No. 15IRTSTHN010; Program for Henan Province Science and Technology, Grant No. 142102210425; Natural Science Foundation of Henan Province, Grant No. 162300410094; and Project of the Cultivation Fund of Science and Technology Achievements of Henan University of Science and Technology, Grant No. 2015BZCG01.