
Abstract
As the integral part of the new generation of information technology, the Internet of things significantly accelerates the intelligent sensing and data fusion in different industrial processes including mining, assisting people to make appropriate decision. These days, an increasing number of coal mine disasters pose a serious threat to people’s lives and property especially in several developing countries. In order to assess the risks arisen from gas explosion or gas poisoning, wireless sensor data should be processed and classified efficiently. Due to the fact that the “negative samples” of coal mine safety data are scarce, least squares support vector machine is introduced to deal with this problem. In addition, several swarm intelligence techniques such as particle swarm optimization, artificial bee colony algorithm, and genetic algorithm are applied to optimize the hyper parameters of least squares support vector machine. Using the popular deep neural networks, convolutional neural network and long short-term memory model, as comparisons, a number of experiments are carried out on several UCI machine learning datasets with different features. Experimental results show that least squares support vector machine optimized by swarm intelligence techniques can effectively handle classification task on different datasets especially on those datasets with limited samples and mixed attributes. The application of least squares support vector machine optimized by swarm intelligence techniques on real coal mine data demonstrates that this algorithm can process the data accurately and timely, therefore can warn of the accidents early in mining workplace.
Keywords
Introduction
Although clean energy has been universally promoted in recent years, coal is still important energy in almost all developing countries. Even in developed countries, coal resource also plays an important role in industrial production and people’s daily life. For example, as released from Energy Information Administration (EIA), coal is the single largest primary energy for electricity generation in the United States during the first half of 2017. 1 It is reasonable to say that coal mining will continue in a long period. In the mining workplace, a huge number of accidents are arisen from gas explosion or gas poisoning which pose serious threats to people’s life and properties. In order to prevent coal mine disasters and have a good use of sensor data, researchers all around the world have carried out several valuable works such as designing accurate chemical or electrical sensors, 2 building effective wireless sensor networks, 3 and developing efficient online machine learning algorithms so as to deal with wireless sensor data appropriately and bridge the gap between cyber world and physical world in “intellimine system.” 4
Wireless sensor data processing is the key task to monitor gas composition and evaluate the safety status in mining workplace. 5 In the current decade, although deep learning models such as convolutional neural networks (CNN) 6 and recurrent neural networks (RNN) 7 show strong ability in image classification, 8 text processing, 9 and speech recognition 10 areas, they still have a lot of room to improve in risk assessment task. On one hand, deep learning is “data-thirsty.” Sometimes, deep neural networks need thousands of labeled samples in one task while the negative samples about coal mine safety situation, mine disasters, must be small and limited. On the other hand, we need fast response speed in this scenario but the computation time of deep neural networks is relatively long.11,12 We hold the opinion that classic algorithms represented by support vector machine (SVM), 13 least squares support vector machine (LSSVM), 14 and Bayesian Classifier 15 are more suitable and effective for risk assessment on the condition that mining background can be perceived comprehensively. Generally, deep learning can fulfill this assignment. For example, CNN can be used to recognize the damage type in workplace; time series acquired by different sensors (especially gas sensors) can be analyzed by RNN effectively.
SVM is one of the most popular statistical learning methods. Different from neural networks which use multiple hidden layers to fit non-liner system, SVMs utilize kernel trick.16,17 The implementation of SVM is based on the idea of finding the “max margin” and follows the structural risk minimization principle. 13 In order to improve the performance of SVM, scholars proposed various developed structures such as combining SVM with fuzzy control 18 and ensemble learning. 19 LSSVM is the main variant of SVM. In LSSVM, the loss function is improved using the quadratic terms of errors and the inequality constraints are replaced by the equality constraints. 14 The calculation process of LSSVM is relatively simple and fast so it is more suitable for coal mine gas monitoring task.
For algorithms like SVM and LSSVM, the selection of hyper parameters directly impacts algorithms’ performance. Sometimes, engineers need to have a good understanding of the data and determine parameters for the classifiers by experience. Normally, this manual method is time-consuming, experience dependent, and cannot achieve the optimal parameters. How to use intelligent optimization algorithms to choose suitable parameters has long been a research hot spot. YS Ji proposed a scheme based on ensemble Kalman filter which can optimize the characters and parameters of SVM; 20 XF Yuan applied chaos algorithm to achieve the parameters of SVM for function approximation. 21 As the main optimization approach, evolutionary computation techniques such as genetic algorithm (GA) 22 and differential evolution (DE) algorithm, 23 or more broadly defined, ant colony optimization (ACO), 24 artificial bee colony (ABC) algorithm, 25 artificial fish-swarm (AF) algorithm, 26 artificial immune (AI) algorithm, 27 and particle swarm optimization (PSO) 28 are widely used in different tasks. These swarm intelligence algorithms are inspired by natural phenomena and biological behaviors. The “colonies” in algorithms can update appropriately through the evolution from one generation to another, therefore can find the optimal solution gradually. As a result, swarm intelligence algorithms are always employed to optimize parameters and select effective attributes for SVM and LSSVM. This hybrid strategy has been widely utilized in pattern recognition, 29 fault diagnosis, 30 and other detecting or forecasting works.31,32
In this article, we try to introduce three classic swarm intelligence algorithms, GA, PSO, and ABC, to determine the parameters of LSSVM so as to enhance its learning ability. CNN 6 and a special kind of RNN, long short-term memory (LSTM), 33 are used as comparisons to evaluate the performance of different models in different datasets. The article is organized as follows. In section “Background,” related work such as SVM, LSSVM, GA, PSO, and ABC are briefly explained. In section “LSSVM optimized by swarm intelligence techniques: SI-LSSVM,” LSSVM optimized by different evolutionary computation techniques (SI-LSSVM), together with deep learning models, are employed to solve several public classification tasks. Experiments about typical coal mine gas data are presented in section “Gas monitoring based on SI-LSSVM.” The conclusion is given in section “Conclusion.”
Background
SVM and LSSVM
Fundamentals
SVM is initially designed to deal with binary classification tasks. For a typical binary classification problem on the dataset


where
Ideally, this hyper-plane can classify samples correctly as equation (2)

In order to make sure that this plane can implement the “maximum margin,” the basic mathematical form of SVM can be transfer into a constrained minimization problem as equation (3)


Using Lagrange multiplier method, we can get the “dual problem” of equation (3). The Lagrange function can be written as equation (4)


where
Setting that the partial derivatives of equation (4) on


Then, the “dual problem” can be written as equation (7)



where
The expression of final classifier is equation (8)

It should be mentioned that the derivation process above meets the Karush-Kuhn-Tucker (KKT) conditions. If we introduce the “soft margin” punishment factor C, the slack variable

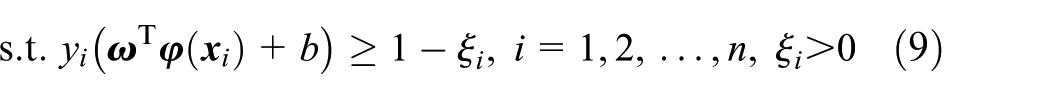
Different from SVM, in LSSVM, inequality constraint is replaced by equation constraint and least-squares loss function is selected. The LSSVM model can be written as equation (10)


where
The major calculation methods of SVM or LSSVM include quadratic programming, sequential minimal optimization, and incremental strategy.
Classifiers for multi-class classification
Generally speaking, the sensor data about coal mine gas status can be classified into two groups: safe and dangerous. In special cases, we need to grade the mine into one of several security levels. In this situation, a multi-class classifier is needed. “One Vs Rest” method designed N classifiers for a multi-class task with N categories.34,35 One category and others are classified by a binary classifier. Similar to “One Vs Rest,”“One Vs One” method trained
Swarm intelligence techniques
Commonly, the main swarm intelligence algorithms can be divided into three types. The first kind of algorithms are based on evolutionary theory such as GA, DE, and AI. The population renew themselves by sharing information with each other. Another type of algorithms are represented by PSO. These algorithms, such as frog leaping algorithm and so on, search better solutions by the utilization of local information so as to upgrade the fitness. ABC is an improved algorithm with mixed features such as the local searching like PSO and the selection operation like GA. The last kind of algorithms, such as ACO, are not suitable for the optimization task for LSSVM. ACO has good performance in discrete and combinatorial optimization problems such as Traveling Salesman Problem, but it cannot deal with continuous numerical optimization tasks. Therefore, GA, PSO, and ABC are selected as the representatives in this article.
In evolutionary computation algorithms like PSO, ABC, and GA, one individual in the colony such as a bird, a chromosome, or a bee is relative to a solution of the problem to be optimized.25,28 For instance, we can define an “N-dimensional particle” in PSO as a solution set,
PSO
The thinking of PSO derives from the special behavior of birds. In nature, the animals in a group can exchange their information about the environment and the food source. Each group of birds has a “leader” who is nearest to the food source. In one generation, all the birds in the group will follow the “leader” and search locally. If another bird gets a better position (closer to the food), this bird will become the new “leader.” In this way, those birds can move to the food finally.
We define the “particle,” also “the location of particle” as mentioned above. In addition, the “speed” of each particle also needs to be designed and calculated in PSO. At first, all the particles should be initialized in some ways such as random initialization or average initialization. Each particle has a “fitness” which is determined according to the optimization problem and can evaluate the quality of each particle. For the optimization problem aiming to search the minimum value for a function, the “fitness” can be designed as equation (11)

The speed of a particle determines its moving direction and displacement. In PSO, the speed can be calculated as equation (12)
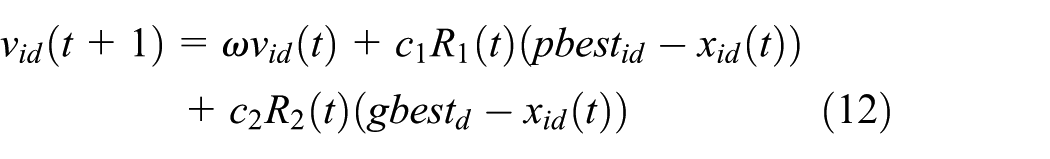
where v is the speed and x is the location of a particle; i is the serial number the particle; t is the serial number of the iteration; w is the inertia factor which illustrates the impact from the speed of the previous generation;
After the speed is achieved, the new location of a particle can be computed as equation (13)
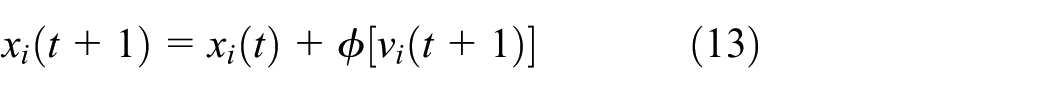
where
PSO can have a good use of valuable information both from the current individual and the whole colony. These days, PSO has already become one of the most popular optimization methods for its significant advantages such as simple algorithm structure and high robustness.
ABC
Similar to PSO, ABC is inspired by the biological behaviors of bees. The main development of ABC is that the bees are divided into different groups with different characters: the exploiting bees, the onlooker bees, and the scouters. The roles of bees can be changed by certain rules.
In ABC, each exploiting bee is correlated with a solution set, also a location of food source, as mentioned in the beginning of section “Swarm intelligence techniques.” Normally, the number of exploiting bees equals to the number of onlooker bees at the beginning. After initialization, the exploiting bees search locally as equation (14)
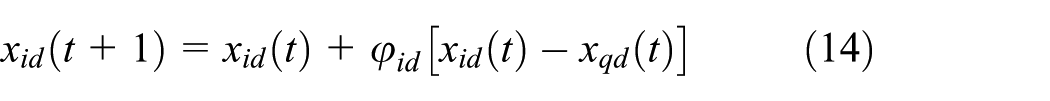
where x is the location of food source; i is the serial number of the bee; d is one dimension in D dimensional solution set; t is the serial number of the iteration;
To evaluate the quality of each bee, the “fitness” can be designed as equation (11). If one exploiting bee finds a better location, the older one will be replaced. According to the information, the quality of food source candidates, the onlooker bees will select candidates by a probability as equation (15). This method is also called roulette wheel selection method

where
The onlooker bees also search as equation (14). If one food source cannot be improved in continuous Limit iterations, the exploiting bee related to this food source will be changed into a scouter. In this situation, the food source is abandoned and the scouter search food as equation (16)

where
GA
GA is the cornerstone of all the swarm intelligence algorithms. The optimization of GA follows the principle of “survival of the fittest” in natural selection. Different from PSO and ABC, ordinary GA utilizes binary coding strategy. Other coding strategies such as float coding are also very common. Generally speaking, GA consists of three operators: selection, crossover, and mutation.
The selection operator adopts the individuals with higher “fitness” as equation (11). Roulette wheel selection is also the most popular selection method in GA. Those individuals with higher fitness are more likely to copy their “gene” and join in the crossover process so as to keep their information in the next generation.
The aim of crossover operator is to combine the information from two different individuals so as to produce new and better offspring. According to the coding method, those two individuals will crossover with each other in different ways. Take the “binary coding” and “single point crossover” as the example. Normally, the matching individuals and crossover points are determined randomly. The crossover process can be illustrated as Table 1.
The crossover operator.

Gene mutation can introduce more randomness in the population. Mutation operator gives GA a possibility to find an individual with a higher fitness. The mutated individuals and the mutation points can be determined by some heuristic knowledge or just stochastically. The example of mutation process is shown in Table 2. In this example, we also use “binary mutation.”
The mutation operator.

LSSVM optimized by swarm intelligence techniques: SI-LSSVM
Parameter optimization using PSO, ABC, and GA
Algorithm details
PSO-LSSVM, ABC-LSSVM, and GA-LSSVM algorithms can be written as Algorithms 1–3, respectively.



Kernel experiments
At first we carried out a group of experiments to evaluate different kernels for LSSVM: RBF kernel, linear kernel, and polynomial kernel. Heart, Wine, and Glass datasets (shown in Table 3) are taken as detailed examples. In PSO,
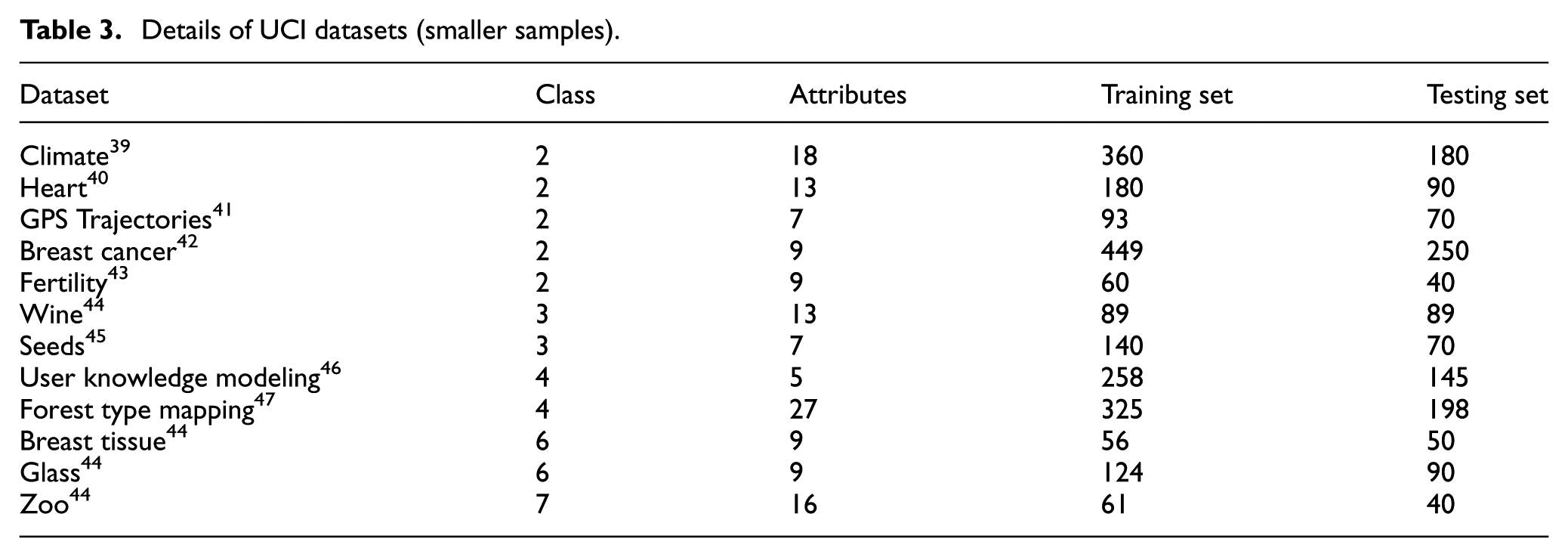
Details of UCI datasets (smaller samples).
Since the performance of polynomial kernel is worst in cross-validation experiments as Table 4, we only compare SI-LSSVM models with RBF kernel (17) or linear kernel (18)


The performance of three kernels in cross-validation experiments.

For this model optimization task, we adopt the accuracy of LSSVM as the fitness of swarm intelligence algorithms. In PSO and ABC, floating-point encoding method is selected, therefore the population can be defined as

At the beginning, all the individuals can be initialized as equation (16). Samples can be normalized as equation (20)

Particularly, in GA, we use the classical binary encoding strategy. In GA-LSSVM, one individual can be encoded as a 2-line matrix with 0 and 1 for RBF kernel or a vector for linear kernel. Besides, in PSO, the speed of one individual can be initialized as equation (21)

where
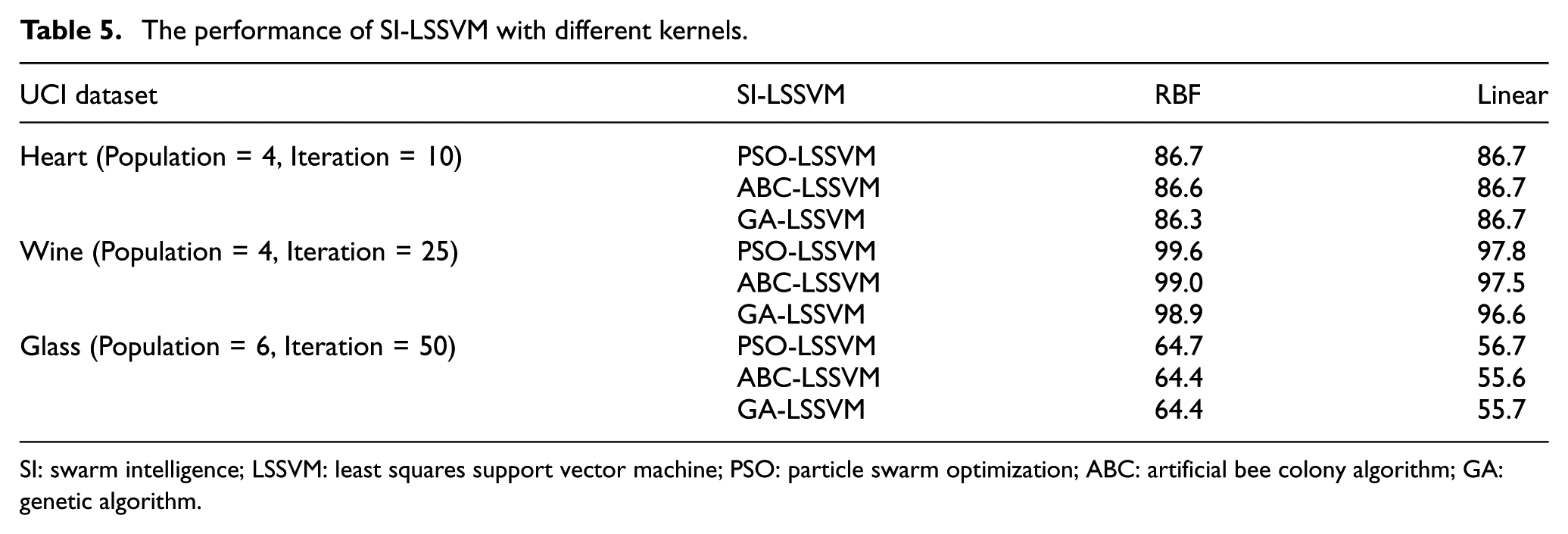
All the experiments are carried out nine times, the average accuracies are recorded in Table 5.
The performance of SI-LSSVM with different kernels.
SI: swarm intelligence; LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony algorithm; GA: genetic algorithm.
As shown in Table 5, the performance of RBF kernel is similar to that of liner kernel in binary classification dataset. In multi-class classification tasks (Wine, Glass), PSO-LSSVM with RBF kernel can obtain the best accuracies and it is far better than that of liner kernel. Considering the experimental results comprehensively, SI-LSSVM (especially the PSO-LSSVM) with RBF kernel is the preferred model. In this article, we use RBF kernel (17) as kernel function
Experiments on datasets with small samples
We use some abbreviations in the article as Table 6.
The abbreviations of some terms.

In this section, we use datasets with relatively small samples to evaluate the performance of SI-LSSVM models. The details of these datasets can be described in Table 5.
In this section, all the experiments are conducted on a PC with Intel core(TM) i5-5300U CPU @ 2.30 GHz processor and 8 GB RAM. Software developing environment is MATLAB R2016a on 64 bit windows 7 system.
Parameter determination experiments
It should be mentioned that the introduction of swarm intelligence algorithms will bring some new hyper parameters. We carried out several experiments to evaluate different parameter sets in PSO, ABC, and GA and then determine the appropriate parameters. Generally speaking, these parameters do not have very direct impacts to classification accuracy and they are relatively easy to adjust compared with those parameters in LSSVM. Since the population size is mainly relative to the complexity of the problem, we do not analyze it along with other parameters. Taking Heart, Wine, and Glass datasets as examples, statistical results are recorded in Table 7. In these experiments, we set the swarm size at 4 for Heart and Wine datasets and 10 for glass dataset.
Parameter determination of swarm intelligence algorithms.

AA: average accuracy; OA: optimal accuracy; LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony; GA: genetic algorithm; CP: crossover probability; MP: mutation probability.
Bold values are those parameter sets with better performance and the relative accuracies.
As shown in Table 7, in binary classification tasks, GA-LSSVM is more parameter sensitive. PSO-LSSVM and ABC-LSSVM are more parameter sensitive in multi-class classification tasks.
Detailed comparative experiments
As detailed examples, the performances of SI-LSSVM models on Heart, Wine, and Glass datasets are listed in Tables 8–10, respectively. In our experiments, the hyper parameters of LSSVM, γ and
Experimental results of algorithms on Heart dataset.

LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony; GA: genetic algorithm.
Experimental results of algorithms on Wine dataset.

LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony; GA: genetic algorithm.
Experimental results of algorithms on Glass dataset.

LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony; GA: genetic algorithm.
As illustrated in Table 8 and Figure 1, on Heart dataset, all these three algorithms can achieve good classification accuracies. When population is 6 as Figure 2, ABC has a better performance than GA. If the swarm size is 4, PSO can find the parameters in a shorter time. In the LSSVM optimization task, PSO and ABC perform better than GA. All the SI algorithms obtain better solutions than cross-validation method and man-made method.

Fitness curves of three algorithms on Heart dataset (best fitness in the median run of 9 runs).

Fitness curves of three algorithms on Wine dataset (best fitness in the median run of 9 runs).
The training time of GA-LSSVM is shorter than other models. Compared with PSO, ABC needs more training time. There is no obvious difference in the testing time of three models.
SI-LSSVM performs best on wine dataset. These models can completely classify the samples correctly and have 100% accuracies. PSO optimizer also performs best and has a highest average accuracy, 100%. ABC has a similar performance to GA. As shown in Figure 3, PSO can get the optimal parameters quicker. In the limited training cycles, 50 cycles, this optimizer is more likely to have a good performance. In a longer training time, GA can also obtain the expected parameters.

Fitness curves of three algorithms on Glass dataset (best fitness in the median run of 9 runs).
On this dataset, PSO even has a shorter training time than GA in one specific experiment. From the perspective of average training time, GA performs best. The training time of ABC is longer than that of PSO and GA.
As shown in Table 10 and Figure 3, on glass dataset, SI-based LSSVMs obtained the accuracies greater than 60%; while the accuracies gained by cross-validation method or man-made method are only more than 50%. Specifically, PSO-LSSVM gets the highest classification accuracy; ABC can also find those better parameters in a relatively long iteration (300 cycles). Similar to the experiments on other datasets, the training time of ABC is longer than that of PSO and GA.
Swarm size analysis
We also analyze the impact of swarm size to SI-LSSVM models. Experimental results on Wine and Glass datasets are illustrated in Figure 4. In PSO, w = 0.6, c1 = 2, c2 = 2; in ABC, limit = 20; in GA, CP = 0.8, MP = 0.1. All the iteration numbers are set at 100.
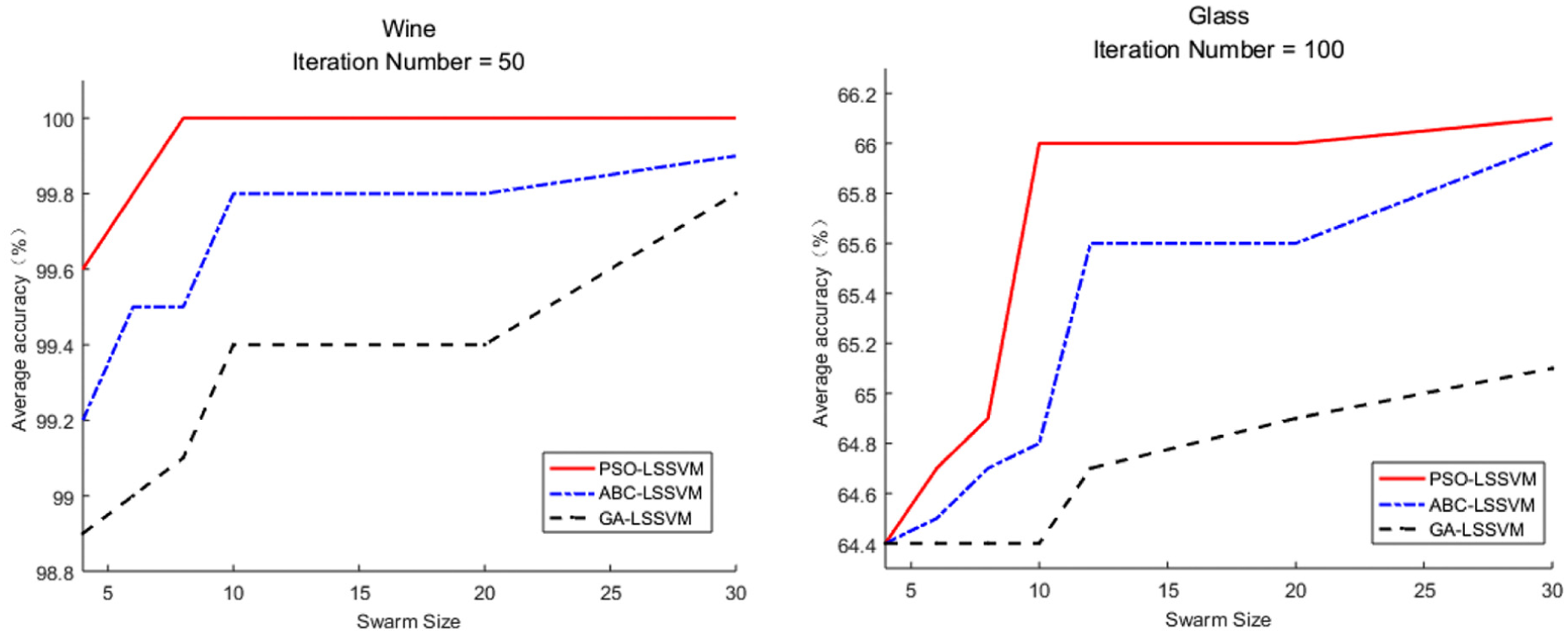
Fitness curves of three algorithms on Wine and Glass datasets with different swarm sizes.
Figure 4 shows the performance of these models with different swarm size. Obviously, the performance of all the models becomes better when swarm size is increased. For the SI-LSSVM model in this article, the increase in population will lengthen the running time proportionally. In some large scale datasets, time overhead would be huge. This is the reason why the comparative analysis on small swarm size is conducted in this article. If the computational resources are sufficient, larger swarm size can improve the classification ability of SI-LSSVM significantly. It should also be mentioned that although the training time of SI-based models is a little long, the testing time of these algorithms is around or even less than 1 s. This means that LSSVM model can react quickly in emergency.
Statistical results
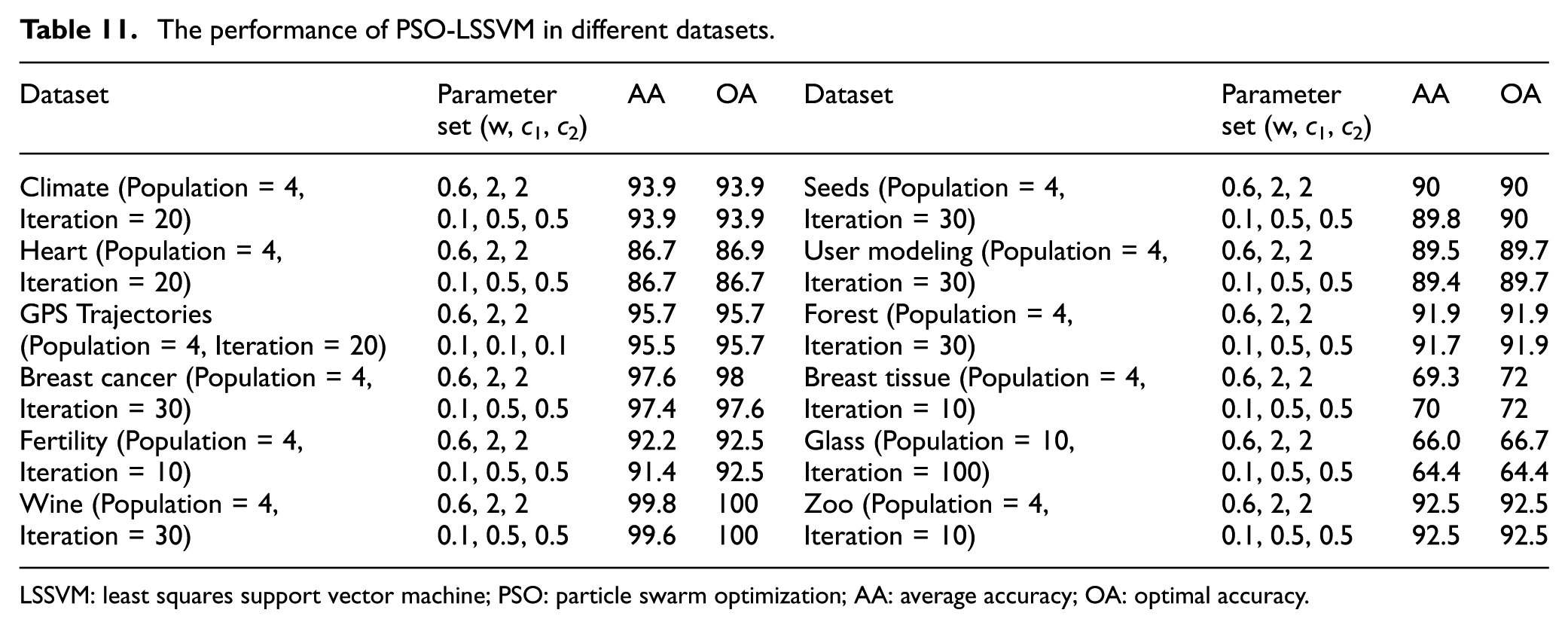
Statistical results on 12 datasets are recorded in Tables 11–13.
The performance of PSO-LSSVM in different datasets.
LSSVM: least squares support vector machine; PSO: particle swarm optimization; AA: average accuracy; OA: optimal accuracy.
The performance of ABC-LSSVM in different datasets.

LSSVM: least squares support vector machine; ABC: artificial bee colony; AA: average accuracy; OA: optimal accuracy.
The performance of GA-LSSVM in different datasets.

LSSVM: least squares support vector machine; GA: genetic algorithm; AA: average accuracy; OA: optimal accuracy; CP: crossover probability; MP: mutation probability.
As shown in Tables 11–13, PSO-LSSVM has the best performance in almost all the datasets with smaller iterations. ABC-LSSVM can also achieve a good accuracy with higher iterations. The performance of GA-LSSVM is acceptable with fast running speed. For binary classification tasks, SI-LSSVM has good performance (with an average accuracy around 90%). For multi-class classification tasks, SI-LSSVM also has good performance except “Breast Tissue” and “Glass” datasets. These two datasets have more categories but less attributes. This reveals that SI-LSSVM is not suitable for complex multi-class classification with lower attribute dimension. In binary classification and multi-class classification tasks with enough attributes, SI-LSSVM can achieve outstanding performance. PSO-LSSVM can obtain a better accuracy in shorter running time.
Comparative experiments with deep learning models on datasets with more samples and mixed features
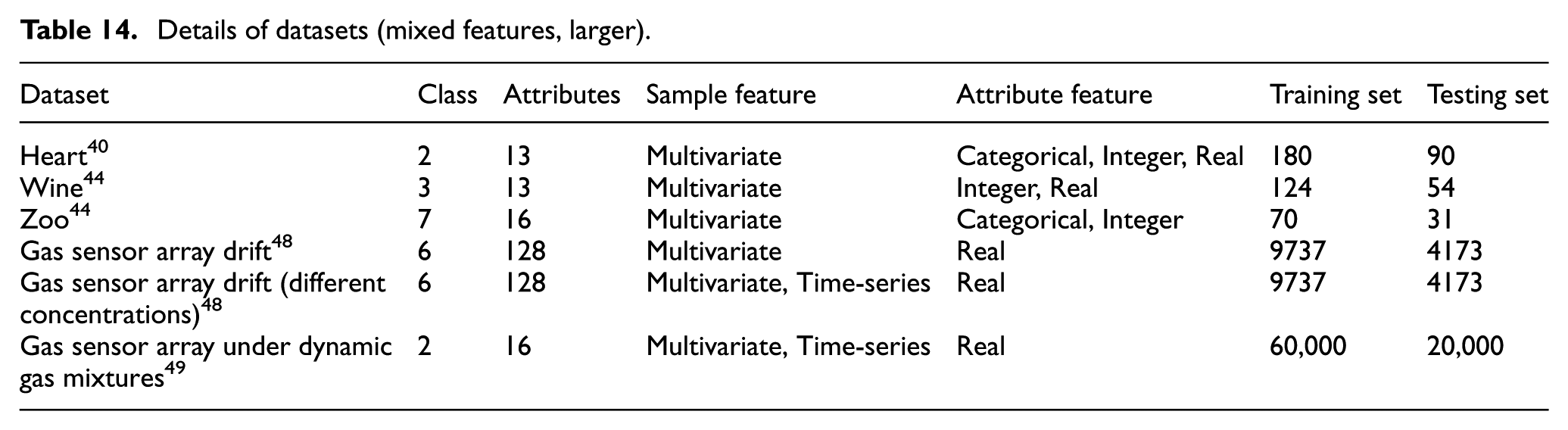
We carried out more experiments on larger scale datasets with certain special features in this section. Details of these datasets are shown in Table 14. For “Gas sensor array under dynamic gas mixtures” dataset, stratified sampling method is used to select 80,000 instances.
Details of datasets (mixed features, larger).
CNN and LSTM are selected as the comparisons. Considering the strong sequence analysis ability of LSTM, in experiments on time-series datasets like “Gas Sensor Array Drift (Different Concentrations)” dataset and “Gas sensor array under dynamic gas mixtures” dataset, every continuous five samples constitute a group with determined label. This strategy can help LSTM to exploit time information effectively.
In this section, all the experiments are conducted on a work station with Intel core(TM) i7-6700K CPU @ 4 GHz processor and 64 GB RAM. Software developing environment is Pycharm on 64 bit windows 7 system. For deep learning models, Keras with tensorflow backend is utilized as the development platform. CNN is built as a 9-layer structure: 2 convolution layers (64 convolution kernels with 1 × 3 size for Heart, Wine, Zoo and “Gas sensor array under dynamic gas mixtures” datasets; 512 convolution kernel with 1 × 3 size for “Gas Sensor Array Drift” and “Gas Sensor Array Drift (Different Concentrations)” datasets), 1 max-pooling layer, 2 convolution layers (128 convolution kernels with 1 × 3 size for Heart, Wine, Zoo and “Gas sensor array under dynamic gas mixtures” datasets; 1024 convolution kernel with 1 × 3 size for “Gas Sensor Array Drift” and “Gas Sensor Array Drift (Different Concentrations)” datasets), 1 global-average-pooling layer, dropout = 0.3, 2 dense layers (with 50 and 2 nodes respectively). relu function is selected as activation function, and binary cross entropy is selected as loss function. On time-series datasets, LSTM model with two LSTM layers and two dense layers are constructed. dropout = 0.25; sigmoid function is selected as activation function; binary cross entropy is selected as loss function. We use adaptive moment estimation optimizer. For large-scale datasets, batch_size = 20, nb_epoch = 200. In PSO,
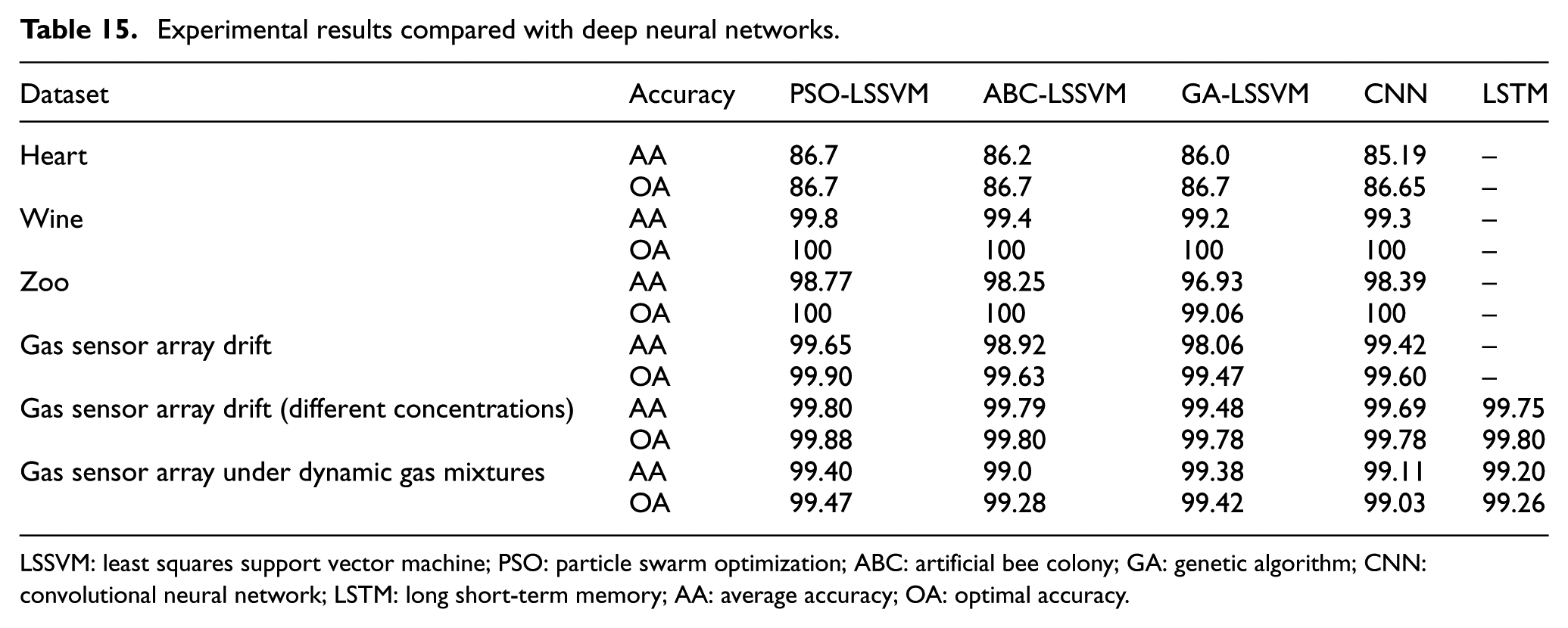
As shown in Table 15, SI-LSSVM and deep learning models show different performance on datasets with different features:
On datasets with small samples such as Heart, Wine, and Zoo datasets, SI-LSSVM performs outstandingly;
For those datasets with different attribute features such as categorical or integer, PSO-LSSVM performs best;
CNN is very suitable for large-scale datasets. Along with the increase in sample size, the performance of CNN becomes better (Such as “Gas Sensor Array Drift” datasets); SI-LSSVM also has good performance on large-scale gas sensor data;
LSTM can obtain a better performance on “real” attribute and time series samples than CNN.
SI-LSSVM shows strong classification ability on relatively high-dimensional datasets such as Heart, Wine, Zoo, and Gas sensor datasets. On datasets with more categories and low dimension such as Glass datasets, SI-LSSVM has more room to be improved;
If the training set of LSTM becomes bigger, its performance will become better; on gas sensor datasets, when training set constitutes 60% of the dataset, average accuracy is 99.2%; when it constitutes 80%, average accuracy is 99.8%; this model can have a nearly 100% accuracy when it has 90% training set.
Experimental results compared with deep neural networks.
LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony; GA: genetic algorithm; CNN: convolutional neural network; LSTM: long short-term memory; AA: average accuracy; OA: optimal accuracy.
We hold the opinion that SI-LSSVM is more suitable than current deep neural networks in coal mine gas monitoring tasks due to the following reasons:
Deep learning is “data-thirsty.” Sometimes, deep neural networks need thousands of labeled samples in one task while the negative samples about coal mine safety situation, mine disasters, must be small and limited;
We always need fast response speed in this scenario but the computation time of deep neural networks is relative long;
Deep learning models have good performance in perceptual tasks especially good at numeric and continuous data such as speeches and images. In our data as Table 17 in this article, there is a nominal attribute, “damage type.” For data like this, SI-LSSVM is more effective.
Computational time complexity analysis of SI-LSSVM
In SVM, since the algorithm needs to handle the quadratic convex optimization, the computational time complexity is
For swarm intelligence algorithms, the time complexity is closely correlated with the problem to be optimized. In SI-LSSVM, {γ,
In PSO, the main program statement in the loop is the speed updating formula for particles. In this formula, 5 multiplication operations and 5 addition operations are needed. For a PSO with n particles and m iterations, the computational time can be written as equation (22)

where
The computation time of ABC-LSSVM can be illustrated as equation (23)

where
In GA-LSSVM, similarly, the time can be approximately represented as equation (24). The complexity of selection, crossover, and mutation operations is regarded as

where
Thus, we can conclude that computational time complexity of SI-LSSVM is
Gas monitoring based on SI-LSSVM
The description of coal mine data
In this article, SI-LSSVM models are applied to evaluate the safety status of two real coal mines in china. Statistical features of these two datasets, “obvious risk assessment” dataset 52 and “coal mine gas and environment” dataset, 53 are shown in Table 16. Detailed samples are listed in Tables 17 and 18, respectively.
Statistical features of two real coal mine datasets.

Samples of obvious risk assessment dataset.

Samples of coal mine gas and environment dataset.

Experiments and analyses
In order to prevent mine disasters, SI-LSSVM models are utilized to monitor safety status of these two mines. We use the similar experimental setting as written in section “Detailed comparative experiments.” The performances of SI-LSSVM on obvious risk assessment dataset can be illustrated in Table 19 and Figure 5.
Experimental results of SI-LSSVM on obvious risk assessment dataset.

SI: swarm intelligence; LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony; GA: genetic algorithm.

Fitness curves of three algorithms on obvious risk assessment dataset.
As listed in Table 10, apart from man-made strategy, almost all the models perform outstandingly in obvious risk assessment dataset. This is probably because those features for risk assessment are more distinct and notable. All the SI-LSSVM models can obtain the best parameters and classify samples correctly in a short time, as shown in Figure 5.
On “coal mine gas and environment” dataset, as illustrated in Table 20 and Figure 6, SI-LSSVM also performs better than other optimization methods. Among those models, PSO is the best optimizer which can easily gain the suitable parameters for LSSVM. ABC-LSSVM also has an outstanding performance although its average accuracy is a little lower than PSO-LSSVM. GA-LSSVM can get an acceptable classification accuracy with the shortest training time.
Experimental results of algorithms on coal mine gas and environment dataset.

LSSVM: least squares support vector machine; PSO: particle swarm optimization; ABC: artificial bee colony; GA: genetic algorithm.

Fitness curves of three algorithms on coal mine gas and environment dataset (best fitness in the median run of 9 runs).
The testing time is around 0.5 s, which illustrates that those models can monitor gas status timely.
Conclusion
In this article, we studied LSSVM optimized by three major swarm intelligence techniques: PSO, ABC, and GA. A number of comparative experiments and analyses are conducted on public testing dataset. Experimental results show that swarm intelligence techniques can effectively select the hyper parameters for LSSVM. This SI-LSSVM model can sort samples both from UCI datasets and real coal mine datasets fast and accurately, thereby can prevent coal mine disasters validly. In our experiments, these optimization methods perform differently in different datasets:
PSO is the best optimizer which can obtain better parameters with smaller swarm size and shorter time.
ABC also performs outstanding with a longer training time.
GA has a better performance than cross-validation and default parameters; the training time of GA is shortest.
SI-LSSVM has several special features compared with deep learning models:
This model can effectively deal with those datasets with smaller samples and categorical attributes.
On the datasets with more categories and lower dimension, SI-LSSVM has room to be improved.
We hope to make more improvements in our future work and introduce deep models appropriately:
Suitable training strategies and improved deep models are expected so as to deal with those datasets with small samples appropriately. A feasible solution is the application of transfer learning techniques.
The results of deep neural networks can be used as the inputs of SI-LSSVM. For example, we can determine the damage type by the use of CNN to perceive the visual information of coal mine workplace; we can also predict the concentration of certain gas in future by the use of RNN to deal with time-series arisen from gas sensors. These outputs can constitute the input vector of SI-LSSVM and help the algorithm fulfill gas monitoring task.
This model can also be developed by other data processing strategies such as principal component analysis (PCA) 54 or SI-based feature selection, 55 entropy-based evaluation, 56 and hybrid SI algorithms 57 so as to handle more complex coal mine gas sensor data.
Overall, as the classical statistical learning strategy, LSSVM can be widely applied in risk assessment tasks in mining workplace.
Footnotes
Handling Editor: Wenbing Zhao
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Key Research and Development Program of China under Grants 2017YFB1002304 and the University of Science and Technology Beijing–National Taipei University of Technology Joint Research Program under Grant TW201705.