
Abstract
The combination of social networks and the Internet of Things has raised a new wave of network technology application. However, the presence of malicious social network users poses a potential threat to Internet of Things security, and the research on social network user geolocation technology is of great significance. The accuracy of existing geolocation methods for WeChat users depends on the stable correspondence between the reported distance and actual distance. In view of the difficulty to pinpoint users’ location in the real world due to WeChat location protection strategy, a WeChat user geolocation algorithm based on the reported and actual distance relation analysis is proposed. The proposed algorithm selects the target reported distance and determines the initial target space based on statistical characteristics of the relation between the reported distance and actual distance. What is more, stepwise strategies are taken to improve the accuracy rate of space partition. Experimental results show that, on the premise that target users can be discovered, the proposed algorithm could achieve higher accuracy compared with the classical space partition–based algorithm and the heuristic number theory based algorithm. The highest geolocation accuracy is within 10 m and 56% of geolocation results are within 60 m.
Keywords
Introduction
In recent years, the Internet of Things (IoT) has developed rapidly with various applications such as industry, agriculture, transportation, logistics, and smart home, 1 which provide convenient and intelligent services for people’s production and life. Location information is one of the basic elements of information interaction in IoT, and the basis of location based services (LBS) provided by IoT.2–4 With the rapid development of mobile Internet and the wide application of smart hardware devices, more and more social media platforms are trying to associate mobile social system with IoT. 5 The social network is extended to be a broader concept beyond the people-to-people interaction, which also includes the people-to-thing and thing-to-thing interactions. 6 Tencent, for example, one of the largest Chinese social media platforms, which owns WeChat, QQ, and other mobile messaging systems, launched WeChat hardware platform in 2014 which provides IoT solutions for connecting things and things as well as people and things. 7 WeChat is a popular social network application in China with 963 million active accounts in over 200 countries by June 2017. 8 In the same year, Facebook released its own IoT platform, Parse. The combination of mobile social networks and IoT makes mobile social networks can not only meet the demand of users for people-to-people interaction,9–11 but also promote further development of IoT. As there are a great number of mobile social network users, malicious users among them may conduct rumor spreading, virus dissemination, and other malicious behaviors,12–14 which seriously endanger the health of network environment and the security of IoT. Carrying out the research on mobile social network user geolocation technology is significant to provide time-efficient support for pinpointing the location of malicious users as well as geolocating IoT security busters from social networks. Meanwhile, the research can raise awareness of location privacy protection for ordinary users and help service providers afford more secure services.15,16 Such research, combined with network application technologies such as multimedia steganography detection17,18 and key nodes discovery of anonymous communication networks,19–21 can discover and geolocate Internet-sensitive targets, so as to provide technical support to maintain the network security.
For the advantage that mobile social network applications can access the location of devices conveniently, a wide variety of location-based social networks (LBSNs) and particular LBSs sprang up,22–24 which make it possible to geolocate social network users. It has been reported that the Egyptian government used the trilateration geolocation method based on the location-based characteristics of gay dating apps to geolocate imprison users. 25 This article is focusing on WeChat to explore whether WeChat users can be geolocated based on the provided LBS. The existing WeChat user geolocation algorithms can be divided into two categories: number theory based geolocation algorithm and successive approximation–based geolocation algorithm.
Number theory based geolocation algorithm abstracts the relation between the reported distance and actual distance as an ideal mathematical model. By setting probes equidistantly with certain rules in the region where the target user is located, the reported distances of the target user collected from multiple probes are constraint solved, and therefore the location of the target user is pinpointed. Xue et al. 26 have proposed one-dimensional adversarial method first to detect the target user’s location along a line and further extended the method to two-dimensional space. What is more, the method is proved theoretically that it can geolocate WeChat users with high accuracy under ideal conditions. Peng et al. 27 analyzed the influence of noise on the reported distance based on hypothesis, and a heuristic number theory based geolocation algorithm was proposed. By deploying multiple probes along the horizontal and the vertical edge, middle probes which get the minimum reported distance in each edge are selected as the predicted coordinates. Cheng et al. 28 pointed out that the existence of noise makes geolocation errors of number theory based algorithm increase as the actual distance between the probes and the target user increases. In addition, placement strategies for the first probe were proposed to improve the practicality of the number theory–based geolocation algorithm. Number theory based geolocation algorithm has high geolocation accuracy in theory, but in practical as there is no stable relation between the reported distance and actual distance, the gap between the actual results and theoretical precision is large and the theoretical precision is hard to achieve.
Successive approximation–based geolocation algorithm first determines the target user’s location within a certain region. Then the region is divided into several subregions by collecting target users’ reported distance from different positions. By determining in which subregion the target user is located, the size of the potential region is reduced. Constantly repeating the procedure so that the real location of the target user is limited within a small region. Ding et al. 29 geolocated WeChat user based on the improved triangle geolocation algorithm, which utilizes the band-like reported distance characteristic of WeChat. The center of the intersection of rings determined by several probes was taken as the location of the target user. In order to break the minimum reported distance limit of WeChat, Li et al. 30 have proposed a geolocation algorithm based on space partition. The algorithm first determines the target user within the minimum reported distance, delimits the target space based on the minimum reported distance, and then partitions the target space until the threshold is achieved.
Space partition–based geolocation algorithm is less time consuming and easy to implement. As shown in a previous paper, 30 the algorithm is able to geolocate 50% of users in less than 40 m and the average geolocation accuracy is about 51 m. However, actual tests show that, affected by the location protection strategy update of WeChat, there is no stable correspondence between the reported distance and actual distance. The algorithm is difficult to geolocate target users with high precision under the current conditions. To analyze the correspondence between the reported distance and actual distance and, furthermore, improve the geolocation accuracy for WeChat users in actual environment, a geolocation algorithm based on the relation between the reported distance and actual distance is proposed.
In this article, we improve space partition–based geolocation algorithm by selecting optimization parameters based on statistical characteristics of the relation between the reported distance and actual distance, and stepwise strategies are proposed to improve the accuracy rate of space partition. Experimental results show that the proposed algorithm can geolocate WeChat users with higher accuracy compared with the classical space partition–based algorithm and the heuristic number theory based algorithm, and the highest geolocation accuracy is less than 10 m.
The novelty and contributions of this work are summarized as follows:
We perform real-world test of WeChat “People Nearby” service. Based on the test, we find that there is an unstable relationship between the reported and actual distances, which makes the existing method ineffective to geolocate WeChat users precisely.
We perform statistical analysis of the relation between the reported and actual distances, and determine the target reported distance and the initial target space based on the statistical characteristics.
We propose stepwise strategies to deploy probes, which improve the accuracy of finding subspace where the target user is located.
The proposed algorithm is potentially effective for LBSNs, the reported distance of which is highly confused and has segmented properties.
The rest of the article is organized as follows: In section “Problem statement,” LBSN and the related work are discussed. Section “WeChat user geolocation algorithm based on optimization parameter selection of space partition” describes the proposed geolocation algorithm. Critical steps of the algorithm are analyzed in detail in sections “Determining the initial target space based on statistical characteristics of reported distance” and “Partitioning target space based on stepwise strategies,” respectively, which is followed by section “Experimental results and analysis” describing the geolocation experiment. Finally, section “Conclusion” concludes the article.
Problem statement
In this section, LBSNs are classified according to the way users’ location is shared; what is more, location-based social discovery (LBSD) services and location protection strategies of WeChat are introduced. Then theories and shortcomings of the classical space partition–based geolocation algorithm are discussed.
Classification of LBSNs
In LBSN, users get LBSs such as restaurant recommendation, friend suggestion, and navigation by sharing mobile device’s location to the server. According to the way in which users’ location is disclosed by the server, existing LBSNs can be divided into two categories: direct location sharing and indirect location sharing.
In direct location sharing LBSN, a normal user can get the exact location information of the user whose location is submitted to the server, such as Foursquare, Weibo, and other check-in applications. Taking Weibo for example, users can add a location tag in the published content. Other users will see the location tag when they browse the content, so as to know where the content was published. Some direct location sharing LBSNs also support sharing their location to a specific set of users, instead of exposing their location to all users, such as Google Latitude.
In indirect location sharing LBSN, the server hides the exact location information of users by utilizing methods such as obfuscation or setting granularity, for instance, WeChat, Momo, and Skout. WeChat is a typical kind of indirect location sharing LBSN. When a WeChat user is querying to the server to find nearby people, the exact location of the nearby user is hidden and coarse-grained distance information is provided by the server, such as user A is within 300 m. Based on the reported distance information, the exact location of users cannot be determined directly.
LBSD services and location protection strategies of WeChat
WeChat provides users with LBSD services based on the location of mobile devices. WeChat can obtain the user’s location using the positioning system embedded in the mobile device. When the current location of the mobile device is needed to provide LBS for users, WeChat issues a locate request to the operating system and get a position result from the operating system based on the available location source (global positioning system (GPS), WiFi, or Cell ID).
LBSD is an important kind of LBSs, which provides service for users to find others close to their geographical location, and relative distances between them are reported by the server.31–33“People Nearby” service in WeChat is one typical kind of LBSD service. By querying “People Nearby,” users can find other users (friends or strangers) with geographic proximity and get the reported relative distance. After that, the user can be discovered by other users in the same way if his location is not cleared manually. WeChat reports the relative distance between users in bands of 100 m until the reported distance is within 1000 m, and then in bands of 1000 m. The screenshot of “People Nearby” in WeChat is shown in Figure 1.

“People Nearby” service in WeChat.
To defend against the traditional triangle geolocating attack and protect users’ location privacy, most LBSD services of social network applications such as WeChat report the relative distance between users in concentric bands. By setting the minimum reported distance (100 m) and reporting relative distance in bands, the server does not report accurate relative distance directly. What is more, there is no stable correspondence between the reported distance and actual distance. The reported distance is not always correct. For example, if the actual distance between two users is 350 m, the reported distance may be 300 m or smaller. In this way, it is difficult to determine the location of users even if the reported distance is known.
Analysis of original space partition–based geolocation algorithm
Space partition–based geolocation algorithm is designed to break the minimum reported distance limit of LBSD and further enhance the geolocation accuracy. Implementation of the algorithm should meet the following prerequisites:
The reported distance of the target user from the probe is the minimum reported distance, which is 100 m for WeChat.
WeChat reports the relative distance between the probe and the target user in bands of

where K = 100 when
The illustration of space partition–based geolocation algorithm is shown in Figure 2. Noting that the moving direction in the figure does not represent the actual trajectory of the probe, it just shows the difference of orientation before and after the changing of probe’s location. The arrows in the following figures have the same meaning unless otherwise specified.

Illustration of space partition–based geolocation algorithm.
For the simplicity of problem presentation, the algorithm considers the space determined by the minimum reported distance as a box rather than a circle. What is more, fake location provider–based location spoofing method is used to fake the location of probes, which is a virtual Android machine. To avoid redundant presentation, in the rest of the article, probes will query WeChat server to find nearby users after its location is changed, unless otherwise specified.
First, the location of probes is dynamically changed to scan the potential area where the target user is located, until the target user occurs in the query result list with the minimum reported distance. So the initial target space is determined as a box with 200 m side length. The current position of the probe is taken as the intermediate geolocation result. Second, the position of the probe is shifted relative to the last intermediate geolocation result; consequently, the space determined by the minimum reported distance overlaps half of the initial target space. Third, the half space where the target user is located is determined by judging whether the reported distance of the target user from the shifted probe changes. If it changes, it is derived that the target user is in the non-overlapped half. Otherwise, the target user is located in the overlapped half. In this way, the potential area is reduced to half after each round check. The intermediate geolocation result is modified to make it in the center of current potential area. Repeating the partition procedure for multiple rounds until the expected accuracy is achieved. The last intermediate result is taken as the geolocation result of the target user.
The space partition–based geolocation algorithm takes the region determined by the minimum reported distance as the target space and decides the subspace where the target user is located by checking whether the reported distance of the target user is increasing when probe’s location is shifted. The geolocation accuracy of the algorithm depends on the strict correspondence between the reported distance and the actual distance, given by formula (1). If the correspondence is satisfied, the algorithm will achieve high geolocation accuracy. However, actual test shows that there is no strict correspondence between the reported distance and actual distance. The situation that the reported relative distance is 200 m or higher is frequent even if the actual distance between two users is less than 100 m. Under the current conditions, the initial target space delimited by the algorithm may have failed to cover the location of the target user. What is worse, the algorithm may identify the target user’s location in wrong subspace easily even if the initial target space covers the target users’ location, which will enlarge the geolocation error. So there are some challenges that we must face: (1) How to select the reasonable target reported distance as the beginning of the geolocation? (2) How to delimit the initial target space that covers the location of the target user with high probability? (3) How to find the right subspace with high success rate?
In this article, we select the target reported distance and determine the initial target space based on the statistical characteristics of the reported distance instead of the minimum reported distance. What is more, we adopt different query point selection strategies during different procedures to improve the accuracy of subspace judging. In this way, the geolocation accuracy can be significantly improved.
WeChat user geolocation algorithm based on optimization parameter selection of space partition
The update of privacy protection policy of WeChat can be taken as the possible reason for the fact that there is no strict correspondence between the reported distance and actual distance in “People Nearby” service. In this section, we select optimal parameters that determine the more valid target space and decrease the probability of misjudgment by analyzing the relation between the reported distance and actual distance. In addition, stepwise strategies are adopted to improve the accuracy rate of space partition.
Assuming that the algorithm takes
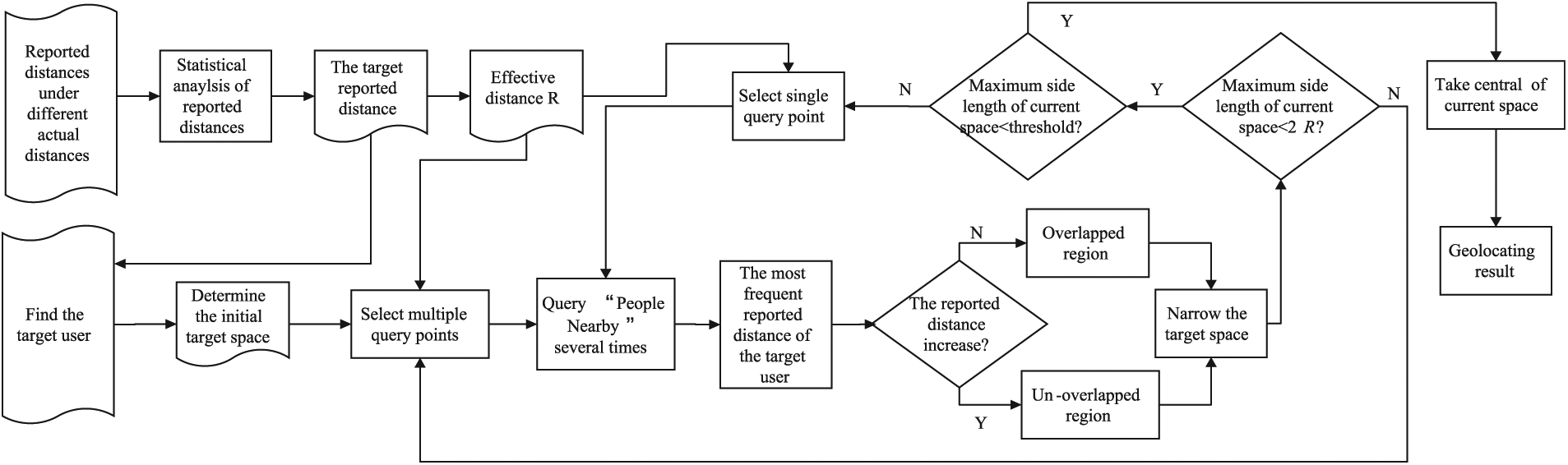
Framework of WeChat user geolocation algorithm based on the relation between the reported and actual distances.
Data collection
This step includes recording the reported distance under different actual distances by dynamically adjusting the location of WeChat users at even intervals. The target reported distance
Initial target space determination
This step includes scanning the potential area by modifying the probe’s location until the probe finds the target with the target reported distance. Utilizing the statistical characteristics of the probability distribution of the actual distance upper limit corresponding to the reported distances, the maximum actual distance
Narrowing the initial target space
First, multiple query points are selected on one side of the initial space and the distance between the adjacent query points is
If and only if the reported distances obtained by all the probes are higher than the target reported distance, the location of the target user is judged in the non-overlapped region; otherwise, the target user is determined in the overlapped region. This procedure is repeated until the larger side length of the current target space is less than
Geolocating the target user
This step includes selecting a single query point in each round, just as the original space partition–based algorithm, and partitioning the space based on the strategy of taking the most frequent reported distance as the reported distance of the target user. Iterating this step until the side length of the current target space is reduced to the preset threshold and the central point of the final target space is selected as the geolocation result.
Particularly, the key points of the proposed algorithm are as follows: how to determine the target space and how to partition the target space correctly, which will be discussed in sections “Determining the initial target space based on statistical characteristics of reported distance” and “Partitioning target space based on stepwise strategies,” respectively.
Determining the initial target space based on statistical characteristics of reported distance
How to determine the target reported distance and the corresponding geographical spatial scope are the first problems to be solved geolocating the target user. In this article, we determine the initial target space range based on the statistical characteristics of the actual distance upper limit corresponding to each reported distance (from 100 to 900 m).
Selection of target reported distance
The selection of the target reported distance should follow the following principles:
The upper limit of actual distances corresponding to the target reported distance is relatively stable.
The smaller reported distance should be selected under the same condition.
The target reported distance affects the scale of the initial target space range directly. The more stable the interval of actual distance corresponding to the target reported distance is, the easier it is to determine the initial space range.
The original space partition–based geolocation algorithm selects the minimum reported distance as the target reported distance and finds the subspace by checking whether the reported distance of the target user obtained by shifted probe is changed. The geolocation accuracy depends heavily on the stability between the minimum reported distance and the actual distance, as shown in formula (1). To verify the rationality of the algorithm, a real-world test is made. In our test, two WeChat accounts running on the mobile phone are deployed. As GPS could achieve the highest localization accuracy, the location of both accounts is faked by the same fake GPS application, Traveling Around. So we can set the location of WeChat accounts by inputting the latitude and longitude of the desired location, instead of moving in the real world. The experimental setting of the test is shown in Figure 4.

Experimental settings of the minimum reported distance test.
The actual distance between two WeChat users, user A and user B, is adjusted at the intervals of 10 m. The actual distance when the reported distance of user A from user B is changed from 100 m to 200 m is recorded first, as X[i] in Figure 4. Taking the above process as one round test, 100 rounds of test are made. The frequency of the recorded actual distances is shown in Figure 5.

The frequency of the recorded actual distances.
We can see from Figure 5 that, in practice, the minimum reported distance of WeChat is highly obfuscated. About 68% of the recorded actual distance is less than 100 m, which means that, in original space partition–based geolocation algorithm, when the reported distance of the target user is changed, the target user may be determined in the wrong subspace with a high probability. So it is not appropriate to select the minimum reported distance as the target reported distance under current conditions.
To solve the problem, we determined the target reported distance according to statistical characteristics of the reported distance. We take the variance of the actual distance upper limit distribution as the measure and the reported distance with minimum variance is taken as the target reported distance, which makes it easier to determine the target space range and reduces the possibility of misjudgment on geolocation procedure. Selecting the smaller reported distance if there is more than one reported distance with the minimum variance can reduce the side length of the initial space as well as the geolocation error caused by miscarriage of justice.
This study does not consider the actual distance lower limit distribution corresponding to the target reported distance and takes the target space as the box rather than a concentric ring, which can reduce the complexity of determining the initial space range and increase the possibility that the user’s location is covered by the determined space. What is more, if the reported distance is not too large, the determined box is approximately equal to the concentric ring.
Determination of initial target space range
As discussed in section “ Problem statement,” the original space partition–based geolocation algorithm takes the initial target space as a box with double reported distance (200 m) as the side length, when the reported distance of the target user is 100 m. However, for there is no stable correspondence between the reported distance and actual distance and we determine the target reported distance according to statistical characteristics of the reported distance, it is not suitable to select side length based on the same strategy.
To find the reasonable boundary of the initial target space, the cumulative probability of the actual distance upper limit distribution is used. The actual distance upper limit is the largest actual distance corresponding to the target reported distance in each round test. Table 1 shows the example of actual distance upper limit selection based on one round real-world test data.
The example of actual distance upper limit selection.

As shown in Table 1, if the target reported distance is 200 m, 170 m is taken as one actual distance upper limit record because it is the largest actual distance that makes the reported distance 200 m in this round test.
Calculating the value

where
The value of
Partitioning target space based on stepwise strategies
Since the initial space is determined, we get the rough range where the target user is located. To geolocate the target user, we must partition the initial space to achieve higher accuracy. This study delimits the effective space range of the target reported distance and proposes stepwise strategies to improve the accuracy rate of space partition.
Delimiting effective space of target reported distance
For the value
To mitigate this kind of misjudgment, we delimit the effective distance
Improving the accuracy of space partition by stepwise strategies
The effective space with a side length of
The union region of effective spaces defined by all query points can cover half of the current target area.
Users in the overlapped region have a lower probability that the reported distance from at least one query point is larger than
Users in the non-overlapped region have a higher probability that the reported distances from all query points are larger than
This article selects query points with the intervals of
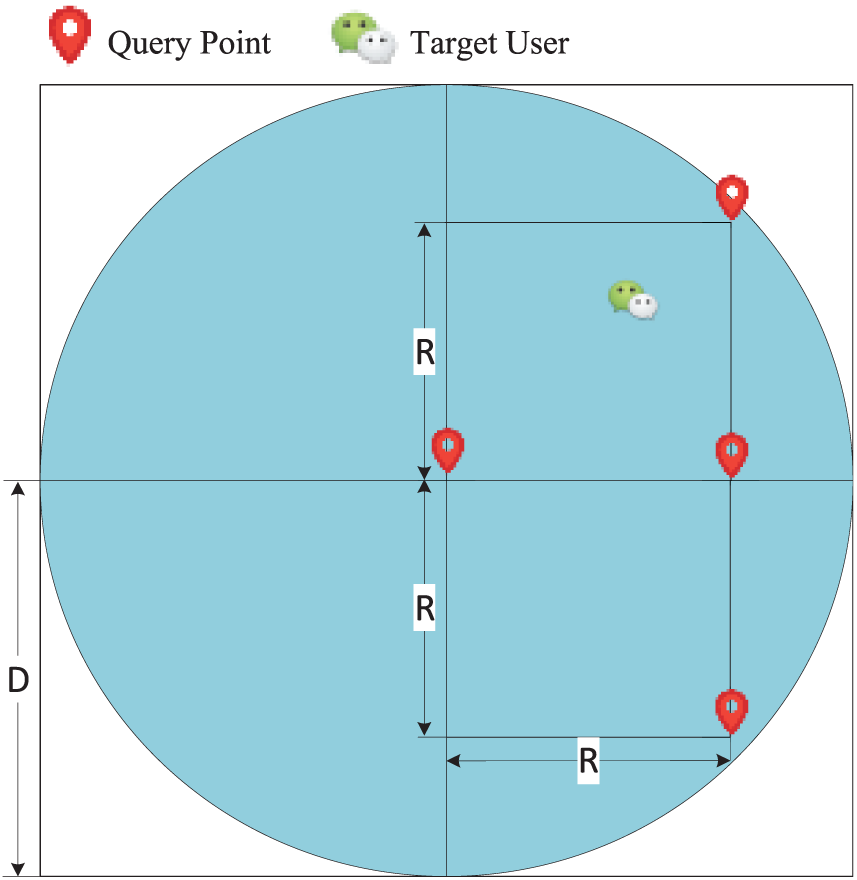
The diagram of query point selection.
Deploying probes at the location of query points, the actual distance between the adjacent probes is

The diagram of single-probe geolocation procedure.
Only one probe is deployed in each round and the probe is shifted by
Adopting the same subspace judgment strategy as in the previous procedure can reduce the rate that the location of the target user is predicted in the wrong subspace.
Experimental results and analysis
To verify the effectiveness of the proposed algorithm, we implement real-world geolocation experiments using three Xiaomi mobile phones running different WeChat accounts. In the procedure of data collection, we use two of these devices to collect reported distances under different actual distances. In the procedure of geolocation, two devices are taken as the target users and the other one is taken as the probe. We successively changed the locations of the devices to simulate different target users and probes. Traveling Around, a fake GPS location application in Android, is used to fake geographic locations of probes and target users. The parameters of the proposed algorithm are determined by statistical analysis of the collected reported distance data, and the comparison with the original space partition–based geolocation algorithm and the heuristic number theory based algorithm 27 is reported.
Experimental settings
In terms of parameter determination, the geographic locations of two WeChat accounts are faked by the same application, just as in the minimum reported distance test in section “Determining the initial target space based on statistical characteristics of reported distance.” The location of user A is set first, and user A leaves a record in the position using “People Nearby” service. Then, the location of user B is changed dynamically to make the actual distance between users A and B enlarge in increments of 10 m. User B queries nearby users to obtain the reported distance of user A after each changes the location. In this way, the reported distances of user A under different actual distances are recorded.
In terms of geolocation comparison, the proposed algorithm is compared with the original space partition–based algorithm and the heuristic number theory based algorithm. We select a geographical area of size 1000 m × 1000 m as our test field. The location of two devices is faked within the test field randomly using the fake location application. WeChat accounts running in the corresponding devices are taken as two target users with known GPS coordinates. After the two users are geolocated, the locations of the two devices are faked randomly again with new GPS coordinates, until 50 target users are deployed. In order to ensure the fairness of the experimental comparison, we employ the same scanning strategy with the original space partition–based algorithm and query over the test field at particular intervals of 100 m, as shown in Figure 8.

The diagram of test field scan.
If the target user is found in the querying result list and the reported distance of the target user is the respective target reported distance for each algorithm, the geolocation procedure is triggered. The threshold for partition is 5 m. Experimental setting of the heuristic number theory based algorithm is in accordance with Peng et al., 27 and we deploy 41 edge probes along the longitudinal edge and 41 edge probes along the latitudinal edge of the test area. What is more, 100 query points along the longitudinal axis and 100 query points along the latitudinal axis are selected.
Parameter determination
Taking it as one round test when the actual distance between users A and B is changed from 0 to 1000 m, and 100 rounds of test are carried out. The maximum actual distance corresponding to
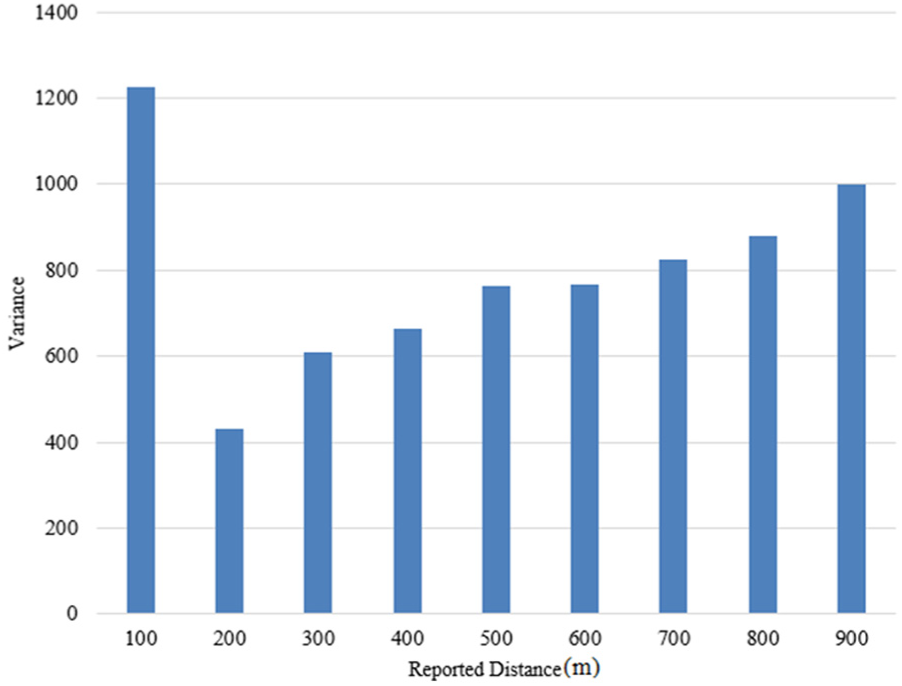
The variance of actual distance upper limit for each reported distance.
The figure shows that variances for each reported distance are fairly large, and variances have an increasing tendency with the increase of the reported distance. The value of 200 m is taken as the target reported distance because it has smaller variance. It is worth noting that the variance of 100 m reported distance is abnormally large. This abnormal phenomenon is caused by frequent appearance of the following situation: even if two users are geographically close to each other, the reported distance of user A from user B is 200 m or higher, rather than 100 m, which agrees well with the result of tests in section “Selection of target reported distance.” The reason for this may be that WeChat thought it privacy-threating if report relative distance with 100 m when the actual distance between users is short. Hence, the reported distance of 100 m will be avoided deliberately.
The probability distribution of the actual distance upper limit for the reported distance of 200 m is shown in Figure 10. It is observed that the actual distance upper limit of 200 m reported distance obeys the normal distribution approximately, and the upper value has the maximum probability at about 170 m. The probability that the reported distance changes to 300 m is higher when the actual distance between users is larger than 170 m. Based on the strategy of parameter selection, the values that make the cumulative probability of the actual distance upper limit probability distribution up to 95% and 50% are calculated, respectively, and the corresponding actual distances are taken as the initial target space range
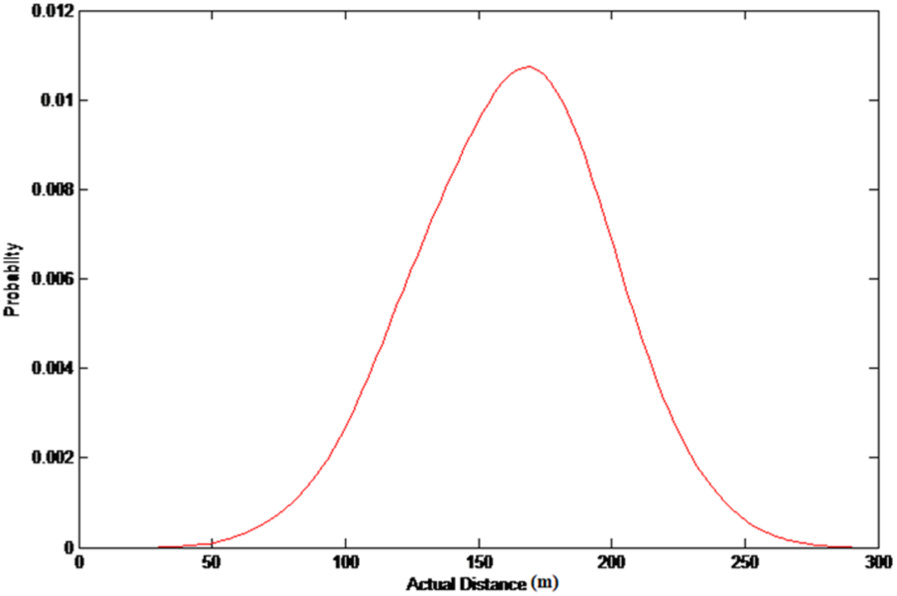
Probability distribution of actual distance upper limit for the target reported distance.
Comparison of experimental results
In the experiment of geolocating 50 target users, the original space partition–based algorithm discovers 46 target users within the minimum reported distance successfully, and 46 results are obtained. Nevertheless, all target users appear in the querying result list with 200 m reported distance.
The reason for the fact that four target users are failed to be found by the original space partition–based geolocation algorithm may be that the existence of noise makes the WeChat server reported 200 m or higher to the probe when the probe is scanning the test field, even if the actual distance between the target users and the probe is less than 100 m. When the location of probes is shifted, the same situation comes up again until the potential area is fully scanned. For the proposed algorithm, as the shifting distance is 100 m, there are at least two query points, the actual distance of which to the target user is less than
The geolocation error distribution is shown in Figure 11 and the geolocation result comparison is shown in Table 2.

Geolocation error distribution.
Geolocation result comparison.

As shown in Figure 11 and Table 2, under the same experimental conditions, the minimum positioning error of the proposed algorithm is less than 20 m; however, all the positioning errors of the original algorithm are higher than 20 m. The average error of the proposed algorithm is 56.6 m, which is lower than 68.9 m for the original algorithm and 63.1 m for the heuristic number theory based algorithm. Moreover, 56% of the localization error for the proposed algorithm is less than 60 m, which is higher than 34.8% of the original algorithm and 42% of the heuristic number theory based algorithm. The middle error of the proposed algorithm is 55.4 m, which is lower than 69.7 m for the original algorithm and 63.3 m for the heuristic number theory based algorithm. It is an interesting phenomenon that the difference between the middle and average errors is very small, which means that the distribution of geolocation errors for the three algorithms is both quite uniform.
The possible reason for the high geolocation error of the original space partition–based algorithm is that, even if the reported distances of the target users are the minimum reported distance, the actual relative distances between the target users and the probe are greater than 100 m. The initial target space has failed to cover the location of target users. What is more, frequently misjudge during space partition enlarges the deviation between geolocation results and actual location of target users. For the heuristic number theory based algorithm, the unstable relationship between the reported and actual distance makes the probes determine biased position on each dimension, which makes it hard to get accurate coordinates of target users. What is more, the procedure of deploying probes along the longitudinal and latitudinal axes will enlarge the geolocation error. It is obvious to see from the geolocation result that the proposed algorithm can geolocate WeChat users accurately in practical environment. The factors that affect the geolocation accuracy of the proposed algorithm includes errors of fake location applications, location providers of the device, low-probability misjudgment during space partition, and the time that users’ location is cached in the WeChat server.
Conclusion
The combination of social networks and IoT makes the security of IoT vulnerable to the threat of malicious users from social networks. So it makes sense to study how to geolocate malicious social network users. LBSD services of mobile social networks report the relative distance of nearby users in concentric bands. However, there is no strict correspondence between the reported distance and the actual distance. In this article, the relationship between the reported distance and actual distance of WeChat is analyzed. We improve space partition–based geolocation algorithm by selecting optimization parameters based on statistical characteristics of the relation between the reported distance and actual distance, and stepwise strategies are proposed to improve the accuracy rate of space partition. Experimental results show that the proposed algorithm has higher geolocation accuracy compared with the original space partition–based geolocation algorithm and the heuristic number theory based geolocation algorithm in several ways. It should be noted that the proposed algorithm is effective only when the target user uses the LBSD service and can be discovered by other users. In future work, we will focus on the difference of the relation between the reported and actual distances in different orientations, as well as the relation between the proximity of users in query result lists and the actual relative distance to the probe. The research hopes to provide time-efficient technical support for geolocating malicious LBSN users and raise the awareness of ordinary users for location privacy protection.
Footnotes
Handling Editor: Gary Leavens
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work presented in this paper was supported by the National Key R&D Program of China (Nos 2016YFB0801303 and 2016QY01W0105), the National Natural Science Foundation of China (Nos U1636219, 61379151, 61572052, 61572445, 61672354, and 61772549), the Key Technologies R&D Program of Henan Province (No. 162102210032), and the Plan for Scientific Innovation Talent of Henan Province (No. 2018JR0018).