
Abstract
Wireless sensor networks are being the focus of several research application domains, and the concept of sensing-as-a-service is on the rise in wireless sensor networks. Large service repositories comprising more services and functionalities usually impose new challenges to users while identifying their preferred services and may incur higher costs. Thereby, service recommendation systems have become important and integral tools of service models to provide personalized products for consumers. However, many existing methods of sensor service recommendation focus only on service discovery. To this end, this article proposes a novel hybrid recommendation method, named new hybrid recommendation method. First, latent Dirichlet allocation model is used to compute the similarity of the latent topics of the services, and the user’s latent semantic themes are used to extract the potential interest services. Moreover, the relevance of neighbourhood services is considered, which can improve the accuracy of quality of service prediction. Experiments conducted on real datasets demonstrate that the proposed method is more accurate than the existing methods of service recommendation.
Introduction
Given the rapid development of service computing in the recent years, the way of offering computing services has taken various dimensions such as infrastructure as a service (IaaS), 1 software as a service (SaaS) 1 and platform as a service (PaaS). 1 And, service computing attracts much study,2–8 including researches on the environment of wireless sensor networks (WSNs).9–12 WSNs are typically composed of energy-constrained sensor nodes and a higher performing sink node. Several concepts of service offering have been previously proposed in WSNs. The concept of sensing-as-a-service has been proposed, in which the sensor devices for Internet of things (IoT) are treated as service providers and applications are treated as clients of such services. In service-oriented architecture, each node is sharing some services while each service consists of a set of functions. 13 Users access published services or data generated by sensors through Internet for monitoring temperature, humidity and air quality (air quality index (AQI)). Sensor services are being the focus of a wide range of research works.9,10,13–19 Existing researches mostly focus on service discovery in services, for instance, efficient searching methods by exploiting the geographical properties of devices. However, the study of recommendation, which aims to return semantically equivalent services in the discovery process, has not been studied adequately. Furthermore, service discovery on its own may not be effective for availing efficient services owing to the deployment of large number of distributed and similar services. In addition, the increasing heterogeneity among the user demands and requirements further imposes various challenges in achieving effective service discovery. To this end, availing relevant recommendation services form an essential component of service offering to user requests. Most of the existing methods exploit information of services such as detailed service descriptions or quality of service (QoS) information for availing relevant services to users. But, obtaining the real values of QoS for services is often difficult. To this end, this article proposes a recommendation method based on predicting the QoS values of user requests in order to help clients to select the most relevant services to the extent of their satisfaction.
In general, a recommendation system can be defined as a system that actively recommends items to users depending on the specific application areas. 2 The recommendation system is an important tool for providing personalized products to consumers. In general, the success of service offering in services lies in the effectiveness of the recommendation system. An excellent personalized recommendation system should recommend specified items to user requests, in order to meet the user’s personalized needs.
Service recommendation based on QoS can facilitate an automated process of discovering and recommending a number of services to clients by the way of ranking the QoS properties of the services and behaviours of the client. However, due to the complexity of services, recommendation for services still faces various challenges. An efficient service recommendation should necessarily include the following properties.
Accuracy
A recommendation system should recommend desired services and avoid unpopular services for users, in particular when there is minimal QoS information for services. QoS attributes are usually associated with the server, network conditions, location, time and other factors.
Diversity
Not only the popular services but also the unpopular yet relevant services in accordance with the user’s preferences should be recommended to users. Returning unfamiliar yet relevant services can help users to find their desired services effectively.
Cold-start problem
Cold-start problem often occurs in memory-based recommendation systems where no rating record is available or only a small number of rating records are available for some new items or users in the system. For new users and new services, recommendation system should still make recommendations.
Data sparsity
Data sparsity can occur when a single user invokes a marginal portion of several services, resulting in very sparse QoS data. In reality, datasets usually suffer sparsity up to 99.24%. 20 Data sparsity usually imposes greater influences on the accuracy and effectiveness of the recommendation system, especially in the cases of high-sparsity data. Data sparsity may include a lot of zero entries in the data matrix of services, thus it is very important to resolve the problem of data sparsity.
QoS data usually represents the non-functional features of the services. QoS data of services can be exploited to provide users with their preferred non-functional features similar to the functionalities of services. Wu et al.21,22 use QoS data as to analysis the performance of WSNs. However, under normal circumstances, the actual QoS values of the services are often implicit. Kodali and Malothu 23 consider QoS as one of the two critical issues in any WSN to measure the performance parameters. Thereby, predicting the QoS values can further enhance the effectiveness of the service recommendation methods.
With this in mind, this article proposes a novel method of QoS-aware hybrid recommendation for services to improve the prediction accuracy of missing QoS values. The proposed model not only considers the relevance of neighbourhood services but also uses the latent Dirichlet allocation (LDA) 24 topic model to mine the implicit semantic similarity of services. First, the relationship between neighbouring services is calculated based on the list of users whom invoked common services, and the value is used to generate a correlation matrix of services. Second, the similarities among the services in latent topics probability are computed using the LDA topic model. In this way, QoS prediction accuracy can be improved and latent topics of services can effectively satisfy user requirements.
The main contributions of this article are listed as follows:
A novel hybrid approach for service recommendation has been proposed that combines correlation-based and content-based recommendation of services.
Unlike other conventional service recommendation approaches, our approach considers the correlation between services based on the co-invocation of similar services by different consumers and further exploits the LDA model that considers the similarities of users and content of services to extract the latent topic of services.
Extensive experiments have been conducted based on real-world services to verify the effectiveness of the proposed method. The experimental results demonstrate that our approach achieves better recommendation performance than the conventional correlation-based and content-based methods.
The remainder of this article is structured as follows: section ‘Related work’ reviews the related works, and section ‘Hybrid recommendation for SWS’ details our proposed model. Section ‘Experiments’ presents and discusses the conducted experiments, and section ‘Conclusion and future work’ concludes this article along with outlining our future research plans.
Related work
A Web Service can be defined as a remote method that is accessed through the Internet. Therefore, Sensor Web Services (SWS) describe the procedure of implementing a Web Service in certain WSNs, where the centre node works as a service, which is able to provide a tool for data exchange with nodes. 9 Recently, a range of researches1,2,4,25 on Web Service recommendation are increasing in popularity. These researches can be applied in the recommendation for SWS. The current methods of Web Service recommendation are mainly divided into the following categories:
Correlation-based service recommendation method mainly uses the association between services based on the relationship between services, and the advantage of this method is it is easy to recommend a high-quality service and make recommendation diversity. But the recommendation system faces several challenges while making recommendations when new items or users become susceptible to data sparsity.
Content-based service recommendation method uses the content similarity between services. The advantage of this method is that it can overcome the start-up issues of new items and users.
Hybrid service recommendation method combines the features and advantages of the above two methods. This hybrid method aims not only to resolve the problem of cold start but also to achieve diversity; this combinational method can be much effective in recommendation systems. But the issue prevails in effectively balancing trade off between the two model-based service recommendation methods.
Zheng et al. 25 exploited the information of similar Web consumers and services to predict the missing QoS parameters. Q Xie et al. 2 considered the relationship of SWS based on the number of services those have been invoked by each pair of Web Service users. IPCC, UPCC, and WSRec 4 have been proposed by Zheng et al., and such approaches are based on user-based collaborative filtering method, an item-based collaborative filtering method, a QoS-aware hybrid Web Service recommendation approach by combining both UPCC and IPCC with confidence weight, respectively. BiasSVD, 26 a latent factor model, uses the singular value decomposition (SVD) method and adds additional biases to users and items. GM, 27 is a greedy method for ordering items. CloudRank2, 5 is a cloud service ranking method which uses the confidence levels of different preference values. 2RHyRec 6 is a ranking-oriented hybrid approach which combines collaborative filtering and latent factors. CloudPred 28 a neighbourhood-based approach enhanced by feature modelling on both users and components. Few learning techniques have been adopted in the model-based approaches like clustering models, 29 neural networks 30 and latent semantic models.31,32
Most of the existing researches on Web Services recommendation1–4,9,33 considered only the relationship between Web Services based on neighbourhood to predict the QoS attributes, but they ignored the user’s latent interest in Web Services. This causes the existing recommendation methods for services to fall below the expectations of user requirements, despite the services characterizing higher QoS values. Moreover, in an extreme situation, making recommendations is impossible for such methods when new users and new services arrive.
The mining of user interested services is mainly based on topic models, a type of unsupervised generative probabilistic modelling. Several models have been proposed; M Ahmed et al. 34 proposed a novel hybrid approach to make recommendations by combining the approach in Xie et al. 2 with the LDA topic model to obtain the user-service probability matrix. The advantage of this method is that it considers both the correlation between services and the content of services. Thus, it can successfully recommend new items to users and also improves the accuracy of QoS prediction. Because of the fact that this approach treats users as words, this method suffers the lack of interpretability.
Several models of service offering have been recently proposed in the context of sensor service discovery. Some notable research works in this area includes IrisNet, wide-area architecture for pervasive sensing services in distributed and heterogeneous environments; 15 discovery and on-demand provisioning of services for IoT-based business applications; 16 IoT-based service discovery using distributed hash table 17 and geographical indexing. 18 However, the problem of ranking sensor services has not received much attention and has not been well investigated.
Existing research mostly focuses on service discovery, ignoring the recommendation of relevant services. Incorporating recommendation system in SWS can provide better sensor services up to the satisfaction of the consumer’s requirements, which is yet to be comprehensively investigated.
To this end, a hybrid approach of recommendation for SWS has been proposed in this article as an extension to our previous work. 34 The novelty beyond the state-of-the-art techniques lies in the fact that our model not only considers the relevance of neighbourhood services but also uses the LDA 24 topic model to mine the implicit semantic similarity between sensor services. The similarity between SWS in the probability of latent topics is computed using the LDA topic model. With the similarity between SWS in the probability of latent topics being computed, the diversity of recommendation for SWS has been improved, and the latent topics of SWS with higher QoS values are exploited to satisfy the user requirements in terms of both content and quality.
Hybrid recommendation for SWS
The proposed hybrid recommendation method for SWS comprises the following cascaded functionalities: first, a correlation matrix between services is extracted using the correlation-based Top K SWS recommendation method based on the number of SWS co-invocated by different consumers. Then, the missing values of QoS are predicted based on the correlation matrix. Then, based on the relationship between the user’s preferred interests of latent content and hidden topics of SWS, recommendation method based on LDA model obtains the topic probability distribution of the services, so as to predict the missing QoS values. Finally, the weighted linear module makes the final recommendation.
The application of LDA topic model is effective in enhancing the prediction accuracy of QoS values. Moreover, the semantic association among the mining services is exploited to overcome the problem of cold start for new items. To recommend services to new users, popularity recommendation method has been adopted to recommend higher rating services or relevant number of invoked services.
Correlation-based recommendation for SWS
Our previous work 2 proposed a correlation-based recommendation for Web Services, which exploits the number of SWS, co-invoked by different users to calculate the correlation degree between services, and further makes use of the propagation and attenuation using the PageRank 35 method to rate services and finally predicts the missing QoS values.
First, according to the one-dimensional (1D) vector
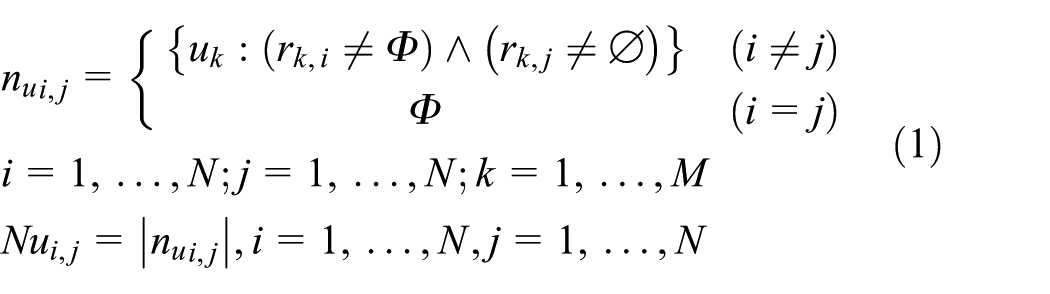
where M and N are the number of service users and services, respectively.

where Ci, j represents the ratio of the number of common users of service i and j and the number of common users of service j and all services. When Ci, j > 0, Ci, j constructs the correlation graph.
Then, according to the PageRank 35 method, the rating matrix SR(n) of the user u to the Web Service n is constructed and calculated as follows

where

Finally, the predicted QoS value is obtained. From the service rating matrix (SRM) Top K service set, we can form the Dev (absolute deviation between services) in search of the S matrix (K) dataset (k top rating service), the absolute deviation and then obtain S′(K), S(K) is the absolute deviation in SRM ranking.
Calculation of the service j and i absolute deviation is obtained as in equation (5):

where
Calculation of SRM is presented in equation (6)

where

where
Calculation of QoS prediction matrix is presented in equation (8)

where
Content-based recommendation for SWS
LDA topic model was proposed in 2003, 24 it is a typical model of bag of words, where a document is composed of a group of words, with no order in place and words comprise a typical relationship between one another. A document can contain multiple topics, and each word in the document is generated from one of the topics.
We use the intermediate outcome θ (shown in Figure 1) in the graph to compute the subject similarity of the services and then to predict the QoS values. Finally, a service set with similar functions and QoS values will be obtained. The procedure of content-based recommendation is described as follows.

LDA probabilistic graphical model.
First, service-topic probability distribution is computed using LDA topic model. For realizing the LDA topic model, Gibbs sampling estimation (service-topic probability distribution) is used in the experiment, which is a topic probability composition of each service description document.
Then, given the existing topic probability distribution of the services, the cosine similarity between the topics of SWS can be computed using equation (9)

Table 1 shows a part of the topic similarity between services, in which each entry represents the similarity of topics between services i and j.
Similarity between Web Services (a selection of).

Before calculating the predicted QoS values, the existing QoS values are normalized using equation (10)

where
The normalized user rating matrix for the services can be computed using equation (11)

where
Hybrid recommendation for SWS
The hybrid recommendation method for SWS integrates the correlation of services with the content of services to predict the QoS values, by balancing the trade-off between correlation and content. By predicting the QoS values those represent the quality attributes of the services, this model recommends the services with better QoS values to users whom are more concerned with particular aspects of QoS properties. Eventually, the hybrid recommender system returns the Top K candidate list of services to the users, depending on how well the QoS attributes of the services fit and satisfy the user requirements. Figure 2 illustrates the process for the hybrid recommendation method.

The process for the hybrid recommendation method.
The hybrid recommendation method not only can accurately associate services using the correlation-based recommendation method but also can mine the potential similarity among the content of services. Moreover, it avoids the cold-start problem of items and users. When new items are added to the system, the hybrid recommendation model can quickly recommend these new items to the users who have similar topic preferences according to the similarity characteristics of the content of services. For new users entering into the system, popular recommendation methods can also be applied to provide a list of diversified services with better QoS. The model of the hybrid recommendation method is expressed in equation (12)

Experiments
In this section, experiments based on real-world QoS dataset are conducted to evaluate the efficiency and accuracy of the proposed approach. We compare our approach with seven other well-known approaches which include the following:
UPCC: 4 which is a user-based collaborative filtering method using Pearson correlation coefficient to measure the similarity between users.
IPCC: 4 which is an item-based collaborative filtering method using Pearson correlation coefficient to measure the similarity between items.
WSRec: 4 which is a QoS-aware hybrid Web Service recommendation approach by combining both UPCC and IPCC with confidence weight.
Hybrid: 34 which is a hybrid Web Service recommendation approach using the three-layer service-topics-users model.
The rest of this section describes the dataset, experimental steps and setups, metrics, the performance comparison and result analysis.
Dataset
In the experiments, we used real-world QoS dataset collected by Zheng et al.,4,25 comprising more than 1,700,000 QoS values from 339 users and 5825 Web Services distributed in 30 different countries. These Web Services Description Language (WSDL) files of Web Services are first crawled and then the rating matrix with 339 users and 908 Web Services over 300,000 QoS values is built. Every entry
Steps and settings
We run the experiments with the following steps. First, the missing values of QoS are predicted using the number of Web Services co-invocated by different consumers. Then, we extract the stem words from WSDL through files crawled from the uniform resource identifier (URI). Then, stop words not helpful to extract semantics are removed from the word lists. After that, Gibbs sampling 36 is applied to calculate the topic probability distribution of Web Services. Cosine similarity is then used to compute the topic similarity between services and then to obtain the predicted QoS values. Finally, we combine the missing QoS values with those predicted by correlation-based and semantic content-based recommendation.
To evaluate the performance of prediction, we randomly divide the 339 × 908 rating matrix into training and testing dataset, respectively, to construct a new sub-matrix as training dataset and the remaining entries of the rating matrix constitute the test dataset. Because users usually invoke a small number of services, we set different density range from 0.01 to 0.05 in order to mimic a real-world dataset distribution. Other parameters settings include c = 0.85, k = 30, α = 50/T and β = 0.1 in the performance comparison. c represents the sparsity of training data. k is the Top K number of correlation degree of a service. α and β are parameters of Dirichlet distribution. Higher α results in centralized topics of documents, and higher β results in centralized words of a topic. Furthermore, we study the impact of Top K up on the accuracy of the hybrid model by setting the value of Top K from 5 to 60.
Metrics
The precision of the recommendation for Web Services is measured by mean absolute error (MAE) and normalized mean absolute error (NMAE) metrics.3,4 Lower values of MAE and NMAE represent higher prediction accuracy of corresponding approaches. The definitions of the metrics are presented in equations (13) and (14)

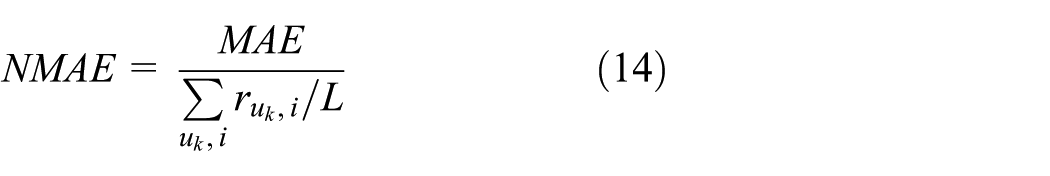
where
Performance comparison
Tables 2 and 3 present the MAE and NMAE values for the evaluated approaches of recommendation based on response time, respectively. As shown in Tables 2 and 3, our approach achieves higher performance both in terms of MAE and NMAE values than the other methods. This is due to the fact that our approach effectively balances the trade-off between the correlation of users and semantic similarities of the Web Services.
MAE values for performance comparison of different methods.

MAE: mean absolute error
NMAE values for performance comparison of different methods.
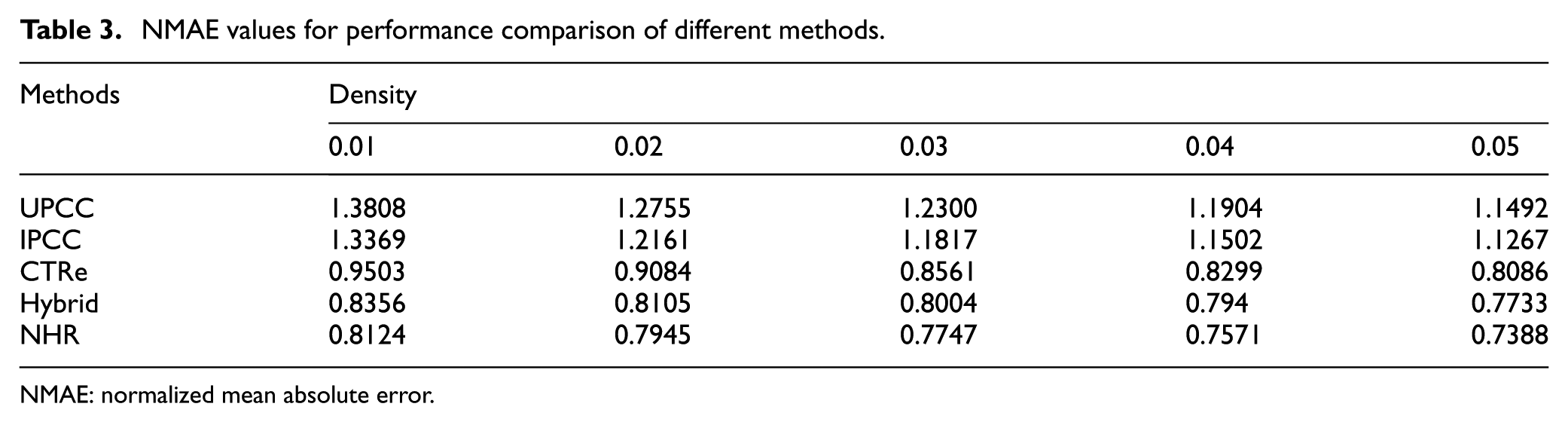
NMAE: normalized mean absolute error.
For all the methods, the prediction shows better accuracy with gradually increasing matrix density values from 0.01 to 0.05 accordingly. This observation depicts that fact that increasing the density of training matrix has a positive influence on prediction accuracy.
Effects of matrix density
In reality, the rating matrix is usually highly sparse 37 due to a small number of services invoked by users. Hence, investigating the density of the matrix is necessary. As shown in Figures 3 and 4, all the evaluated approaches exhibit better prediction accuracy in terms of both MAE and NMAE, respectively, when the density increases from 0.01 to 0.05 accordingly. This observation shows that highly denser knowledge data can provide us with higher accuracy of prediction.

Effects of matrix density for MAE.

Effects of matrix density for NMAE.
Effects of Top K neighbours
A minimum number of Top K is an important factor to achieve adaptive accuracy. Now, the models are simulated with different Top K neighbours to study the corresponding impacts up on adaptive accuracy. As shown in Figures 5 and 6, the accuracy of predicted QoS values increases by around 17% when the Top K value is increased from 10 to 60. Clearly, from Figures 5 and 6, the recommendation system suffers more difficulties while predicting the QoS values with less Top K overlay. In the case of highly sparse data, increasing the Top K value does not improve the prediction accuracy; on the contrary, it will reduce the speed of operation. When density is greater than or equal to 0.02, increasing the Top K gradually decreases the prediction error and the prediction accuracy is saturated at a certain K value. This is because, when Top K value is small, similar services might have been missed. However, largely increasing the Top K value may result in increasing prediction errors due to including some less similar or even unrelated services. Thus, selecting the most appropriate Top K value is important to improve the accuracy of the prediction.

Effects of Top K neighbours for MAE based on different matrix densities.

Effects of Top K neighbours for NMAE based on different matrix densities.
Conclusion and future work
This article proposed a hybrid approach for recommendation systems by incorporating the complementary advantages of correlation-based recommendation and content-based recommendation models for the purpose of improving the prediction accuracy of missing QoS values in sparse matrix. Correlation-based recommendation for Web Services calculates the correlation degree between services based on the number of co-invoked Web Services by different users. Meanwhile, the LDA topic model calculates the similarity of SWS in the content. The proposed approach not only considers the user’s correlation but also the content of services, by which the problem of data sparsity existed in real-world dataset has been effectively resolved to improve the accuracy of prediction.
Experiments are conducted on real-world datasets to evaluate the performance of the proposed model of hybrid recommendation and demonstrate that the proposed approach accurately predicts the QoS values even when dataset comprises increased sparsity.
As a future work, we intend to conduct more experiments in large-scale datasets and plan to include other attributes of services such as location, networks and so on to study the performance and scalability of the proposed approach in a larger scale.
Footnotes
Handling Editor: Wenbing Zhao
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the National Natural Science Funds of China under grants nos 61502209 and 61502207, the Natural Science Foundation of Jiangsu Province under grant BK20170069 and UK–China Knowledge Economy Education Partnership.