
Abstract
In order to rapidly process large amounts of sensor stream data, it is effective to extract and use samples that reflect the characteristics and patterns of the data stream well. In this article, we focus on improving the uniformity confidence of KSample, which has the characteristics of random sampling in the stream environment. For this, we first analyze the uniformity confidence of KSample and then derive two uniformity confidence degradation problems: (1) initial degradation, which rapidly decreases the uniformity confidence in the initial stage, and (2) continuous degradation, which gradually decreases the uniformity confidence in the later stages. We note that the initial degradation is caused by the sample range limitation and the past sample invariance, and the continuous degradation by the sampling range increase. For each problem, we present a corresponding solution, that is, we provide the sample range extension for sample range limitation, the past sample change for past sample invariance, and the use of UC-window for sampling range increase. By reflecting these solutions, we then propose a novel sampling method, named UC-KSample, which largely improves the uniformity confidence. Experimental results show that UC-KSample improves the uniformity confidence over KSample by 2.2 times on average, and it always keeps the uniformity confidence higher than the user-specified threshold. We also note that the sampling accuracy of UC-KSample is higher than that of KSample in both numeric sensor data and text data. The uniformity confidence is an important sampling metric in sensor data streams, and this is the first attempt to apply uniformity confidence to KSample. We believe that the proposed UC-KSample is an excellent approach that adopts an advantage of KSample, dynamic sampling over a fixed sampling ratio, while improving the uniformity confidence.
Introduction
A data stream refers to a continuous form of data that is constantly generated.1,2 In particular, when a stream has a large capacity, such as sensor data, 3 its real-time processing is very costly. 4 Thus, it is effective to extract and use samples that reflect the characteristics and the pattern of the sensor data stream well. 5 In this article, we address an effective sampling method in the stream environment of large sensor data.6,7
Specifically, we address the problem of improving the uniformity confidence8,9 in KSample. KSample is a random sampling method that dynamically increases the sample size to maintain the fixed sampling ratio for the data stream, 10 and the uniformity confidence is an important measure of how uniformly the sampling algorithm produces samples. In stream sampling, it is impossible to consider all the sensor data continuously due to the problem of memory limitation. Thus, it is important to determine how uniformly the given algorithm generates samples for reliability measurement of the samples. This means that uniformity confidence is an important indicator of the performance of the stream sampling algorithm itself. However, in the case of KSample, which extracts a sample element from a certain-sized stream unit, the range of an element extracted in a memory slot is very limited, and it may also incur low uniformity confidence due to the invariant characteristic of previously selected samples. Also, as the sensor data flows continuously, the increase in amount of “the number of sample cases generated in KSample” becomes smaller than that of “the number of statistically generated sample cases,” so that the relative ratio of two cases decreases gradually, resulting in a problem where uniformity confidence continuously decreases. As described above, uniformity confidence is a very important performance measure in stream environment, and in this article we propose the uniformity confidence-based KSample (UC-KSample in short) to increase the uniformity confidence of KSample in the stream environment of large sensor data.
In order to improve the uniformity confidence of KSample, we first analyze the reason why the uniformity confidence decreases in KSample. According to the analysis, the low uniformity confidence happens for two reasons: (1) a limited range of data streams that can be sampled and (2) no change of the previously sampled data. In this article, we refer to this problem as initial uniformity confidence degradation or simply initial degradation. In addition, since we cannot use all the data as a population, the uniformity confidence continuously decreases as the sample size increases. In contrast to the initial degradation, we refer to this problem as continuous uniformity confidence degradation or simply continuous degradation. We next explain each problem in detail and present its efficient solution.
First, the initial degradation occurs because of two properties: sample range limitation and past sample invariance. The sample range limitation arises because the range of data streams that can be selected for a slot is limited. The past sample invariance arises because the elements already stored in the slot are sent to the secondary storage and cannot be changed. To solve these problems, in UC-KSample, we first alleviate the sample range limitation property by including the already sampled data in the next sample extraction range and eventually increase the number of samples that can be generated. We also alleviate the past sample invariance property by allowing that even an already selected sample can be changed, thereby increasing the number of samples that can be extracted as a result. Since the uniformity confidence is the ratio of “number of all possible sample cases that can be statistically generated” to “number of sample cases that can be generated by a specific algorithm,” we can improve it by increasing the number of samples that can be generated.
Next, the continuous degradation occurs because of the sampling range increase in which the range of streams to be sampled becomes greater than the range of streams that can actually be considered. To solve this problem, we present the concept of UC-window in UC-KSample and explain how to determine the size of UC-window to guarantee a certain uniformity confidence. That is, we determine and manage the window to divide the data stream in consideration of the uniformity confidence. More precisely, when we perform sampling, we ensure that the sampling algorithm has the uniformity confidence always higher than the user-specified threshold by starting a new window before the uniformity confidence becomes lower than the threshold.
Experimental results show that, compared to the existing KSample, the proposed UC-KSample significantly improves the uniformity confidence and provides high sampling accuracy. Specifically, when we fix the user-given threshold to
The contributions of this article can be summarized as follows. First, we propose a UC-KSample algorithm that combines the uniformity confidence, an important measure in the stream environment of continuous sensor data, with KSample. Second, through thorough analysis of uniformity confidence in KSample, we derive its uniformity confidence degradation problems and present corresponding solutions to alleviate those problems. Third, we present the concept of UC-window that keeps the uniformity confidence always higher than the user-specified threshold, and we also present a formal method of calculating its size. Fourth, through extensive experiments, we show that the proposed UC-KSample maintains high accuracy while providing higher uniformity confidence than the existing KSample. Uniformity confidence is an important indicator of the reliability of the sampling algorithm for the stream environment, where we handle a huge volume of continuous streaming data. Thus, improving the uniformity confidence is a very important research topic in evaluating stream sampling algorithms. To our best knowledge, this is the first attempt to apply the uniformity confidence to KSample, and UC-KSample is an excellent approach that increases the uniformity confidence while maintaining the advantages of KSample, which has high similarity to the population by dynamically sampling over a fixed sampling ratio.
The rest of the article is organized as follows. Section “Related work” describes the related work on sampling algorithms used in stream environments. Section “Background” provides an overview of uniformity confidence and KSample. Section “Uniformity confidence analysis of KSample” analyzes the uniformity confidence of KSample. Section “UC-KSample” explains in detail the concept and operation procedure of UC-KSample proposed in this article. Section “Experimental evaluation” presents the results of experimental evaluation, and finally section “Conclusion” concludes the article.
Related work
Sampling techniques used in the stream environments are classified into (1) fixed sampling size and (2) fixed sampling ratio methods according to how to specify the sample amount. 11 The fixed sampling size method fixes the sample size regardless of the stream amount, and the fixed sampling ratio method fixes the sampling rate by changing the sample size according to the stream amount. The typical algorithms for the fixed sampling size are Reservoir, 12 priority, 13 and stratified 8 sampling techniques; those for the fixed sampling ratio are KSample, 10 Naive UC-KSample, 14 systematic, 15 and hash 16 sampling techniques.
Reservoir sampling 12 is a sampling method that applies random sampling to the stream environment. When the data stream inflows infinitely, it samples a fixed number of elements, and the probability that each element is included in the sample is equal to (1/stream length). It is commonly used in many areas because its implementation is simple and has random sampling features.
Priority sampling 13 assigns a weight to each element of the data stream and samples an element having a high weight. That is, a data element having high occurrence has high probability to be sampled, and a data element having low occurrence has low probability to be sampled. In general, priority sampling is known to provide high reliability of the sample by showing the similar probability distribution between the sample and the population.
Stratified sampling 8 divides an input population into non-overlapping layers and extracts samples from each layer. Since each layer has different properties, this sampling method can reflect the characteristics of each layer as well as the characteristics of the entire population. Also, stratified sampling shows the higher accuracy than random sampling in many cases because it forms the entire sample by extracting sub-samples from each layer.
KSample
10
dynamically increases the sample size in the stream environment to keep the sampling rate constant for the input stream. It receives the sampling rate
Naive UC-KSample 14 is a recent algorithm that increases the uniformity confidence of KSample. In other words, it is a sampling method that improves the uniformity confidence of KSample by alleviating the sample range limitation and the past sample invariance while keeping the sampling rate constant for the input stream. However, it has a critical problem in that uniformity confidence continuously decreases over time. UC-KSample to be proposed in this article quite differs from Naive UC-KSample since it solves the continuous degradation problem above by introducing a uniformity confidence threshold and using the UC-window to satisfy the threshold.
Systematic sampling
15
selects the first element randomly and then samples every k-th element repeatedly. The sampling interval
Finally, hash sampling 16 uses a hash function to select samples. It first applies a hash function to each data element, then puts the element in the bucket corresponding to its hash value, and finally selects a specific bucket as a sample. Hash sampling shows good performance in complex data such as IP packet and log data. However, it has a difficulty in determining a good hash function for the given stream data.
Assuming that sensor data is infinitely generated in the stream environment, the fixed ratio approach at which the sample amount varies depending on the input stream amount is more effective than the fixed size approach. In this article, we focus on KSample among the fixed sampling ratio methods, which has the characteristics of random sampling for sensor stream data.
Background
Uniformity confidence
Uniformity confidence is an important measure of a sampling algorithm that represents how many sample cases are considered. It is based on the definition that a sample is said to be a uniform random sample if produced by a sampling algorithm in which all statistically possible samples of the same size are equally likely to be selected. 9 The uniformity confidence is calculated as a ratio of “number of all possible sample cases that can be statistically generated” and “number of sample cases that can be generated by a specific algorithm” as in equation (1)

For example, as shown in Figure 1(a), when we want to choose three out of 10 data items randomly, the uniformity confidence is

(a) Sampling and its (b) scheme when the uniformity confidence = 100%.

(a) Sampling and its (b) scheme when the uniformity confidence <100%.
In the batch environment where the population is fixed, we can maintain the uniformity confidence at 100% since we can perform sampling considering all data items. However, in a stream environment in which sensor data is generated in real time, the uniformity confidence is less than 100% because we can consider only the data temporarily stored in the memory at present rather than all the data due to the real-time processing and the limited memory problem. Al-Kateb et al.8,9 proposed a sampling method to keep the uniformity confidence above the lower limit when the sample size changes in the stream environment. They also proposed an efficient way of maintaining the uniformity confidence above the lower limit for join queries in the stream environment. 17 Ting 18 proposed a sampling technique that satisfies the constraint conditions such as memory and sample amount and uses the uniformity confidence as a measure for evaluating the sampling algorithm. The uniformity confidence is a measure of how much data the sampling algorithm considers in the limited memory space.8,9 This means that the uniformity confidence shows the reliability of samples when all data cannot be taken into consideration, especially in a continuous stream environment. Thus, the uniformity confidence itself is an indicator of the performance of the stream sampling algorithm, and supporting it at a high level is an important research issue. Therefore, when all the data, such as the stream environment, cannot be sampled, how much data the sampling algorithm considers to improve the uniformity confidence is an important performance factor.
KSample
KSample is a random sampling method that dynamically increases the sample size in the stream environment so as to keep the sampling ratio for the input stream constant.
10
KSample gets the sampling rate
Figure 3 shows the operation procedure of KSample, and its detailed explanation is as follows:
Stream input. The data source inputs a data stream to be sampled.
Sample size and sampling ratio verification. When a data stream is input, KSample checks whether the current sample size is
Slot creation. It creates one slot that is a single element memory space added to the sample.
Sampling. KSample performs sampling on the current slot. Specifically, if the probability that a data stream element is selected in the slot is greater than or equal to a random value, it inserts the corresponding element into the slot.
Secondary storage. It stores the sample element in the previous slot created before the current slot into the secondary storage.

Operation procedure of KSample.
Figure 4 shows the KSample algorithm. KSample receives the sampling ratio

KSample algorithm. 10
Example 1
Figure 5 shows the operation procedure of KSample when the sampling ratio is
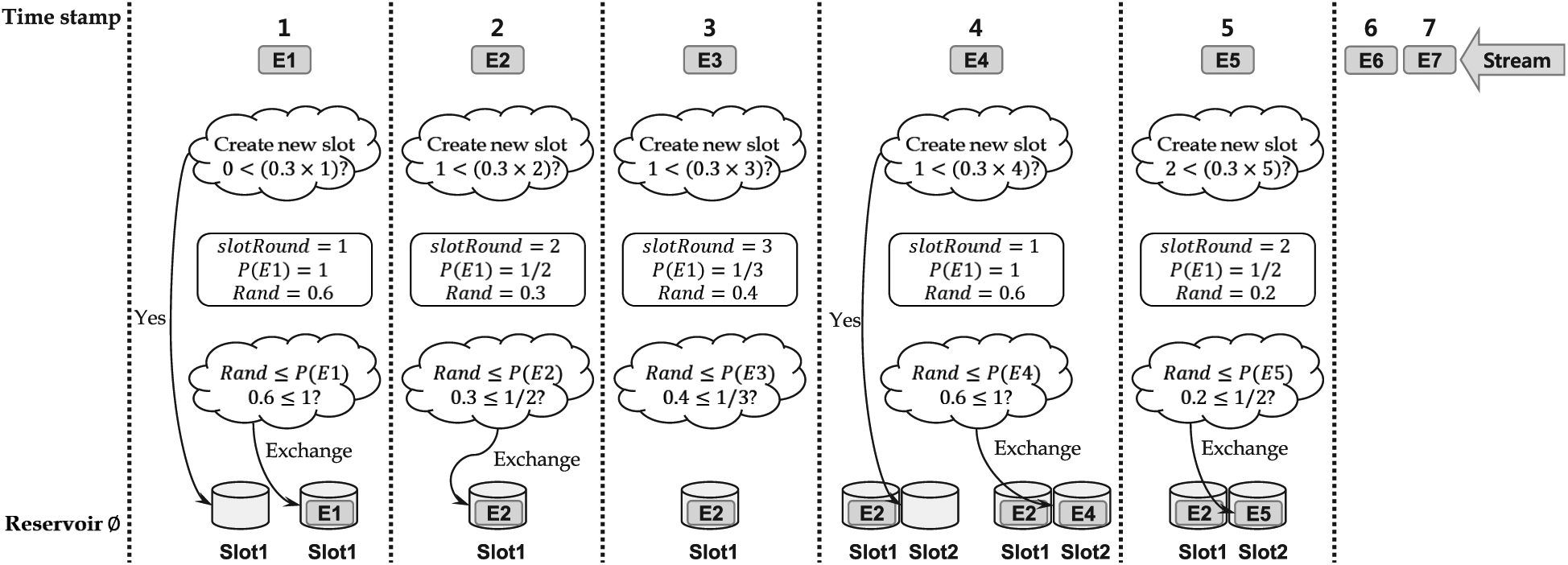
A sampling example of the operation procedure in KSample when
KSample has the advantages that it does not need to predefine the sample size according to the fixed sampling ratio principle and uses the memory efficiently due to no change of the previously sampled elements. However, we note here that the memory efficiency, which is an advantage of KSample, causes the large degradation of uniformity confidence. That is, since the data sampled in the previous slot already move to the secondary storage and is excluded from the sampling range of the next slot, the number of sample cases decreases and the uniformity confidence also decreases. Therefore, in this article, we propose UC-KSample which improves the uniformity confidence while preserving KSample’s advantages, which are the memory efficiency and the fixed sampling ratio.
Uniformity confidence analysis of KSample
For sampling in the real-time stream environment, we can consider only the data stored in the current memory rather than all the data due to a memory limitation problem. Like this, we cannot include all the data in the sampling range, so we need an objective measure for evaluating the sampling performance. The uniformity confidence used in this article is one of the major criteria for evaluating the sampling performance, and improving the uniformity confidence is an important research issue.
As described earlier, KSample is a useful sampling algorithm for stream environments because it increases the sample size dynamically so as to maintain the fixed sampling ratio. However, KSample causes a memory loss problem that cannot consider all data streams when sampling. Such memory loss causes a serious problem where uniformity confidence is very low and continuously decreases.
Figure 6 shows the uniformity confidence degradation problem of KSample in detail. The figure illustrates a graph comparing the uniformity confidence of Reservoir sampling with that of KSample

Comparison of uniformity confidence between KSample and Reservoir sampling.
In this article, we first analyze the initial and continuous degradation problems of uniformity confidence in KSample. We next derive three reasons of sample range limitation, past sample invariance, and sample range increase, which cause these degradations. We also present sample range extension, past sample change, and use of UC-window, as the requirements for resolving those reasons, respectively. We then propose UC-KSample, which improves the uniformity confidence of KSample by reflecting these three requirements, in the next section.
UC-KSample
In this section, we analyze the causes of uniformity confidence degradation in KSample and propose requirements to solve those problems. We then propose UC-KSample, which maintains high uniformity confidence of KSample, and explain its working procedure in detail using examples.
Analysis of problem causes
As mentioned earlier, KSample has two problems causing the uniformity confidence degradation. First, the initial degradation of KSample is due to two causes. The first cause comes from the limited range of data streams that can be selected for a particular slot is limited. KSample dynamically increments the sample size by one if the sample size is less than
Example 2
Figure 7 shows an operation procedure of KSample when the sampling ratio
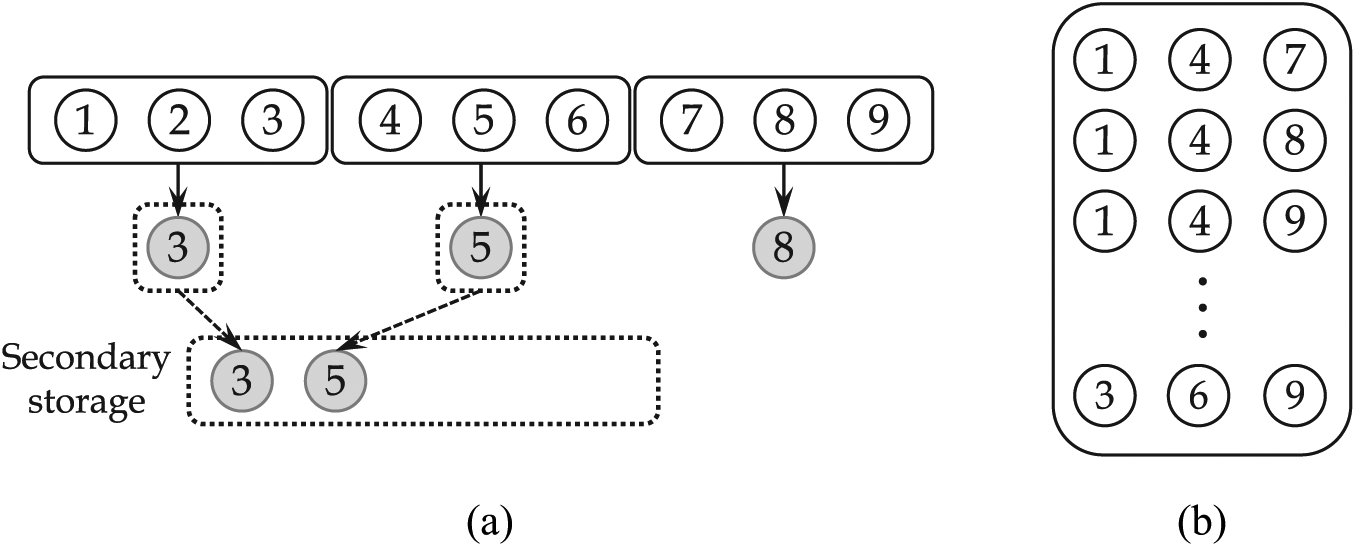
(a) Operation procedure of KSample for
As shown in Example 2, the uniformity confidence, which was 100% for the sample size of 1, sharply decreases for the sample size of 2 or more at the beginning of sampling. This initial degradation is due to the sample range limitation.
The second cause of the initial degradation is that the already sampled data moves to the secondary storage and does not change. Stream elements included in the sampling range of the slot compete to be selected as samples in that slot. However, when the range of the data stream for a current slot is over and a new slot is created, the already selected data moves to the secondary storage and does not change as shown in Figure 7(a). In this way, KSample cannot change the previously sampled data, and it reduces the number of sample cases to be considered. In particular, KSample decreases rapidly in the number of sample cases at the beginning of sampling, and the uniformity confidence decreases rapidly. In this article, we describe the two causes of the initial degradation presented above in detail as follows:
Sample range limitation. The range of stream elements for a specific sample slot is limited, and thus, the uniformity confidence decreases.
Past sample invariance. After completing the sampling for previous slots, the already selected samples do not change, and thus, the uniformity confidence decreases.
Second, we discuss the continuous degradation problem of KSample. The continuous degradation occurs because the increased number of sample cases in KSample is smaller than that of statistically possible sample cases. More specifically, as the input stream increases, the population increases as well, but due to memory loss and sample range limitation, KSample cannot use all the input stream as the sample extraction range. Thus, the ratio of the number of sample cases by KSample to the number of statistically possible sample cases continuously decreases over time.
Example 3
Figure 8 shows the operation procedure of KSample and the result of uniformity confidence calculation at the sampling ratio

Operation procedure and uniformity confidence calculation at
In this article, we describe the cause of continuous uniformity confidence degradation as follows:
Sampling range increase. Since the increase in the number of sample cases in KSample is smaller than that of statistically possible sample cases, the relative ratio of these two cases gradually decreases.
The analysis results so far are summarized as follows. First, the initial degradation of KSample incurs by the sample range limitation and the past sample invariance. Second, the continuous degradation incurs by the sample range increase. In the following subsection, we define requirements to solve these two degradation problems.
Requirements for UC-KSample
First, we refer to the requirement for the sample range limitation, which is a cause of the initial degradation, as the sample range extension. The sample range extension is to extend the range of stream data that can be extracted into a particular sample slot to the already sampled elements. As the population range considered in the sampling increases, the number of sample cases also increases, so the uniformity confidence eventually increases. Figure 9 shows the operation procedure of KSample and UC-KSample when the sampling ratio
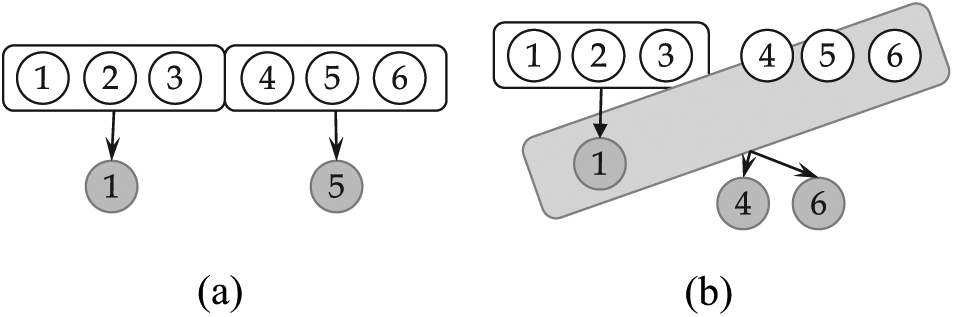
Operation procedure of (a) KSample and (b) UC-KSample for
Second, we call the requirement for solving the past sample invariance the past sample change. The past sample change makes it possible to change even the already sampled data. Allowing the replacement of already sampled data with other stream data increases the number of extractable sample cases, and thus the past sample change can eventually improve the uniformity confidence. As shown in Figure 9(a), after creating the second slot, KSample moves the element ① already selected in the first slot to the secondary storage and does not change it. On the other hand, UC-KSample does not move ① to the secondary storage but allows it to remain in main memory until certain requirements meet, and thus, it can include ① into the next sampling population.
Third, we use the UC-window as the requirement for solving the sampling range increase which causes the continuous degradation. (If we ignore the user-specified threshold, that is, set
Lemma 1
Given the sampling ratio

In equation (2),
Proof
UC-KSample works as shown in Figure 10 when the sample size increases by one. When the input stream size up to date is
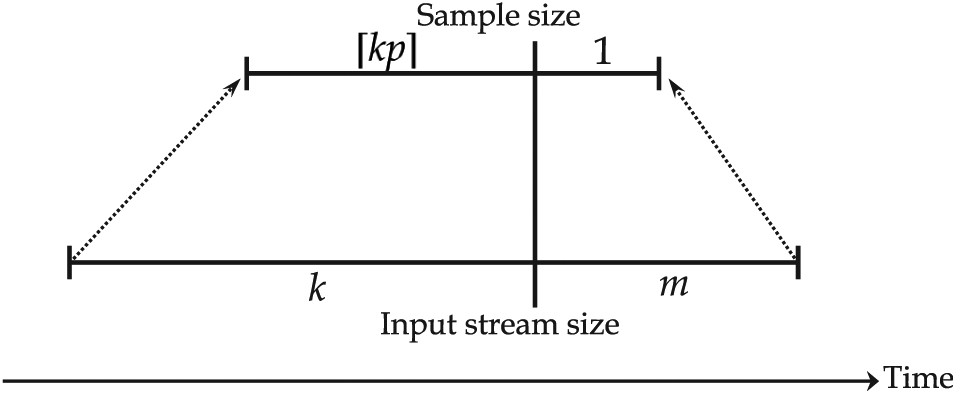
Working procedure of UC-KSample when the sample size increases by one.
Example 4
Figure 11 shows the operation procedure of UC-KSample when the sampling ratio

Operation procedure of UC-KSample when
Table 1 summarizes the two problems of KSample, their causes, and the requirements of UC-KSample for resolving those problems.
Problems and their causes in KSample and corresponding requirements for UC-KSample.

UC-KSample algorithm
We now present the algorithm and operation procedure of UC-KSample and give an intuitive example. Figure 12 shows the operation steps of UC-KSample, and the detailed explanation of each step is as follows:
Window size computation. We calculate the UC-window size that always satisfies the user-specified threshold
Stream input. The data source inputs a data stream to be sampled.
Comparison of window size and stream length. We compare the window size with the stream length that has occurred to date. If the window
Secondary storage. We store the samples generated in the current window to the secondary storage.
Window creation. We create a new window to maintain the uniformity confidence above the given threshold.
Sample size and sampling ratio verification. When a data stream is input, we check whether the current sample size is
Slot creation. We increment the sample size by creating a new slot, which is a single element memory space added to the sample.
Sampling. We perform sampling on the current slot. Specifically, if the probability that a data stream element selected in the slot

Operation procedure of UC-KSample.
Compared with KSample’s operation procedure in Figure 3, we can see that (1) window size computation, (3) comparison of window size and stream length, and (5) window creation are added to UC-KSample for use of UC-window.
Figure 13 shows the proposed algorithm of UC-KSample. The inputs are the sampling ratio

UC-KSample algorithm.
Example 5
Figure 14 shows the operation procedure of UC-KSample when the sampling ratio
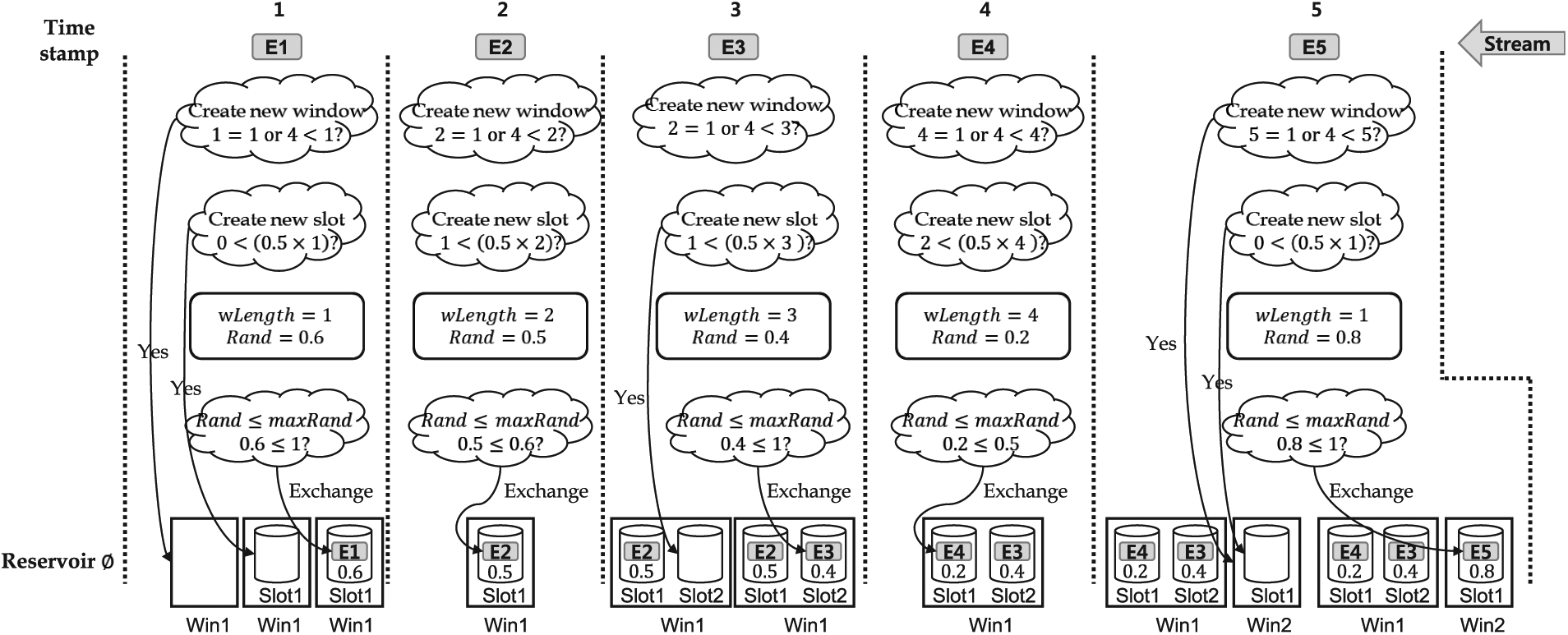
A sampling example of the operation procedure in UC-KSample when
Experimental evaluation
Experimental environment and data
We perform the experimental evaluation of KSample, Naive UC-KSample (UC-KSample with infinite window size), and UC-KSample. In the first experiment, we compare the uniformity confidence of UC-KSample with the other two algorithms by varying the sampling ratio and the user-specified threshold. In the second experiment, we evaluate the sampling accuracy instead of the uniformity confidence for different sampling ratios and thresholds. In the third and fourth experiments, we measure the secondary storage usage and execution time, respectively, by varying the sampling ratio.
For the accuracy test, we use three data sets: Gaussian data, temperature sensor data from nuclear power plants (Nuclear data in short), and Twitter hash tag data (Tweet data in short). Table 2 describes the three datasets used in the experiment. In Table 2, Gaussian data is used in various studies8,21 as the main experimental data for the stream environment. We use the Gaussian data generator that produces data items one by one according to the given mean and standard deviation and adds those items in real time as the input stream. The hardware platform used for the accuracy experiment is an HP workstation equipped with Intel i7 3.60 GHz CPU, 8.0GB RAM, and the software platform is the Ubuntu 16.04 LTS operating system.
Three datasets used in the experiment.

In a stream environment, the order of data input affects the sampling result. 5 However, this is a problem with all sampling techniques, and random sampling may also show different results depending on the order. Both KSample and the proposed UC-KSample inherit the characteristics of random sampling, and thus, they also show different sampling results by different input orders. However, if there is a large amount of input data, there is no significant difference between the data input order and the probability distribution of the sampling results. Thus, we do not consider the input order in the experimental results.
Experimental results on uniformity confidence
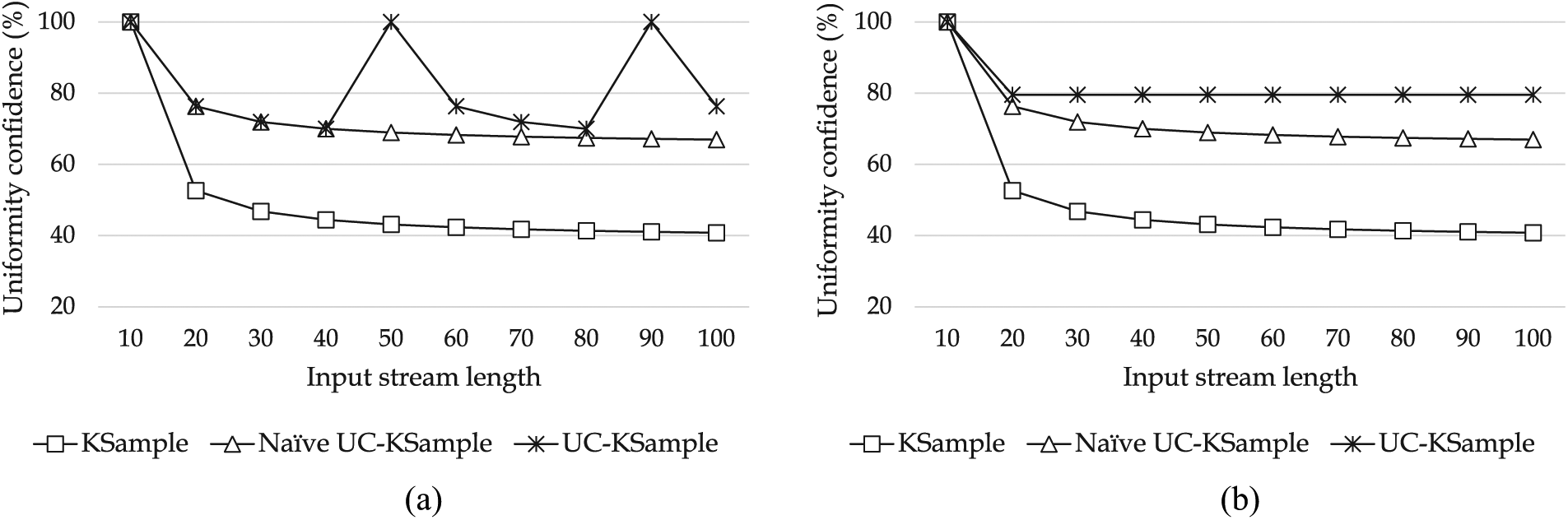
Here, we measure and compare uniformity confidence of KSample, Naive UC-KSample, and UC-KSample with different sampling ratio

Uniformity confidence comparison when
Figure 16 shows the results when we use the same

Uniformity confidence comparison when
Figure 17 shows the results when we keep
Uniformity confidence comparison when
Figure 18 shows the relative results for various user-specified thresholds and sampling ratios. In Figure 18(a), we fix

Relative comparison of uniformity confidence by varying the user-specified threshold and the sampling ratio: (a) relative results for
Experimental results on sampling accuracy
We now evaluate the sampling accuracy of the three algorithms. The accuracy, which is a comparative measure of this experiment, means the similarity between the population and the sample. Because Gaussian data and Nuclear data are numerical data following a normal distribution, we use the z-statistics
22
to measure the similarity. On the other hand, we can regard Tweet data as text documents, so we use the cosine similarity23,24 to evaluate the frequencies of hash tags. For each experimental case, we perform sampling
z-statistics results on Gaussian data.

Bolded terms emphasize the z-statistics closest to 0.
Tables 4 and 5 show the z-statistics of Nuclear data and the cosine similarity of Tweet data, respectively. In both experiments, we change
z-statistics results on Nuclear data.

Cosine similarity results on Tweet data.

Experimental results on secondary storage and execution time
Here we measure and compare the secondary storage space required in three algorithms. Table 6 shows the secondary storage space required in KSample, UC-KSample, and Naive UC-KSample, respectively, for Gaussian data. In the experiment, we use
Secondary storage required in KSample, Naive UC-KSample, and UC-KSample (KB, Gaussian data).

Now we measure and compare the execution times of three algorithms. Figure 19 shows the execution times of KSample, UC-KSample, and Naive UC-KSample for Gaussian data. In the experiment, we set the sampling rate
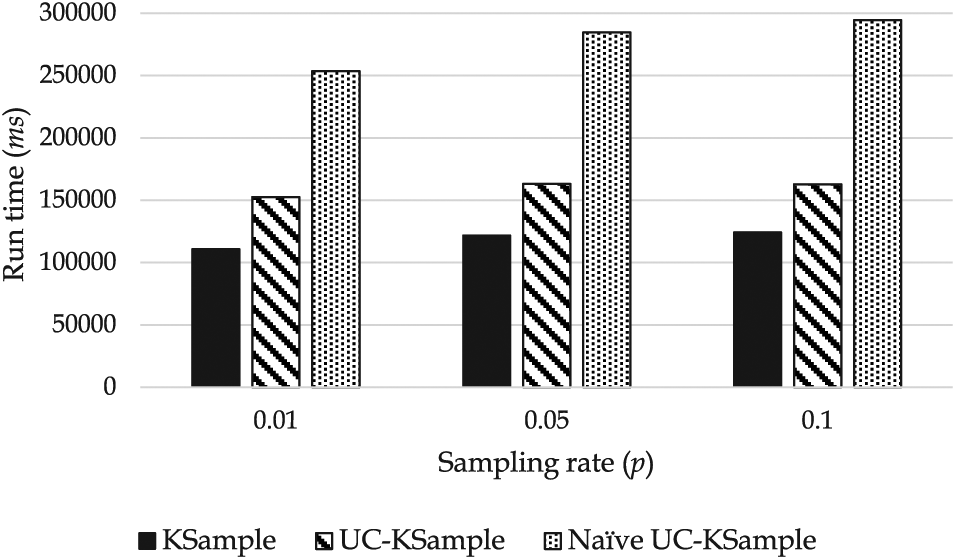
Comparison of execution times of KSample, Naive UC-KSample, and UC-KSample (Gaussian data).
Conclusion
In this article, we proposed the UC-KSample algorithm that improved the uniformity confidence of KSample in the stream environment of sensor data. We first derived two problems of initial degradation and continuous degradation of uniformity confidence in KSample. We then defined the properties causing the initial degradation as sample range limitation and past sample invariance, and the property incurring the continuous degradation as sampling range increase. Next, we presented sample range extension, past sample change, and use of UC-window as the requirements that alleviated these problems, and proposed UC-KSample that applied these requirements to KSample. Experimental results showed that, compared with KSample, UC-KSample increased the uniformity confidence about
Footnotes
Handling Editor: Suat Ozdemir
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by Institute for Information & communications Technology Promotion (IITP) grant funded by the Korea government (MSIT) (No. 2016-0-00179, Development of an Intelligent Sampling and Filtering Techniques for Purifying Data Streams) and the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2017R1A2B4008991).