
Abstract
Effective feature selection determines the efficiency and accuracy of a learning process, which is essential in human activity recognition. In existing works, for simplification purposes, feature selection algorithms are mostly based on the assumption of feature independence. However, in some scenarios, the optimization method based on this independence hypothesis results in poor recognition performance. This article proposes a correlation-based binary particle swarm optimization method for feature selection in human activity recognition. In the proposed algorithm, the particle swarm optimization algorithm is no longer used as a black box. Meanwhile, correlation coefficients among the features are added to binary particle swarm optimization as a feature correlation factor to determine the position of particles, so that the feature with more information is more likely to be selected. The k-nearest neighbor classifier is then used as the fitness function in the particle swarm optimization to evaluate the performance of the feature subset, that is, feature combination with the highest k-nearest neighbor classifier recognition rate would be picked as the eigenvector. Experimental results show that the proposed method can work well with six classifiers, namely, J48, random forest, k-nearest neighbor, multilayer perceptron, naïve Bayesian, and support vector machine, and the new algorithm can improve the classification accuracy in the OPPORTUNITY Activity Recognition dataset.
Keywords
Introduction
With the rapid development of ultra-low-power sensor technology, sensor-based applications could facilitate our daily life in various aspects. 1 Compared with vision-based activity recognition, the sensor-based one could better embody the essence of activities. Moreover, thanks to sensors’ small volume, high sensitivity, and simple apparatus characteristics, sensor-based activity recognition can preserve users’ privacy and acquire data unobtrusively, making it widely applicable in healthcare and elderly care. Therefore, research on sensor-based activity recognition has been attracting growing attention in a number of disciplines and application domains.2–4
Although some works have been done on sensor-based activity in recent years, there are significant problems yet to be solved. 5 In particular, when attempting to recognize human activity with better accuracy, the model could get more complicated as more features are extracted, resulting in curse of dimensionality. By eliminating the irrelevant or redundant ones to reduce the feature number, running time of feature selection could be significantly reduced, while model precision can be improved. 6 Feature selection refers to the selection of a subset with less redundant features and better classification results, that is, to construct a new feature vector with fewer features for activity characterization. As such, the high-dimensional feature turns into a low-dimensional one, enabling efficient reduction of computational complexity.
Common activity features (include time, frequency, and time–frequency domains) could only reflect a behavior from one aspect. Simply combing these features cannot improve the recognition accuracy and would increase the redundancy and weaken the feature expression instead. Feature selection not only enhances the expressive power of the feature category, but also greatly reduces the feature dimension, so as to improve the timeliness of the activity recognition.
To simplify the problem and reduce the runtime, most existing works on feature selection assume that each feature is independent of each other. However, in some scenarios, the optimization method based on the independence hypothesis degrades the recognition performance. For example, a feature may be irrelevant to the target when considered alone, but it may be very relevant to the target if it is considered together with the other features. Different feature combinations have different contributions to the classification results. However, due to correlation among features, the optimal feature subset is typically not a simple combination of multiple individual ones. Therefore, it is necessary to felicitously analyze the correlation between features. In this article, we take the correlation among features into consideration and propose a correlation-based binary particle swarm optimization (BPSO) method for feature selection in human activity recognition.
First, rather than using particle swarm optimization (PSO) as a black box, we attach the correlation among features to the BPSO and deem it as a feature correlation factor to determine the position of particle, so that the feature with a larger amount of data information is more likely to be selected, thereby enhancing the performance of feature selection.
Second, the k-nearest neighbor (KNN) classifier is used as the fitness function in the PSO to evaluate the performance of the feature subset, that is, the feature combination with the highest KNN classifier recognition rate would be picked as the eigenvector. This approach not only reduces the classifier computational complexity, but also improves the timeliness and accuracy of activity recognition.
Finally, extensive experiments are conducted to evaluate the proposed approach. The results show that the proposed feature selection algorithm outperforms the traditional ones and could improve the recognition rate considerably.
Related works
Feature selection is not only the key problem in pattern recognition, but also one of the important issues in sensor-based activity recognition field. Appropriate feature set has important influence on the accuracy of recognition. In general, an activity could be described with better specificity if more categories of features are extracted. However, with the increase of new features, eigenvector dimension extracted by sample data is growing, leading to a rapid increase in time consumption and computational complexity. Therefore, it is necessary to select a feature set that contains the least number of feature dimensions and contributes to higher recognition accuracy. Feature selection can eliminate irrelevant or redundant features, thus improving the accuracy and reducing the computational complexity of the model.
According to whether the feature subset evaluation criteria are related to the classification algorithm, feature selection can be divided into three categories: filter based, wrapper based, and embedded approach based.7–9 The filter-based methods separate the feature selection process from the classification verification process, so that the feature selection process is independent of the classifier. In addition, the evaluation criteria do not depend on the specific classifier, but rely on the attribute information of the data feature itself only. Therefore, the methods using this approach are typically fast but they need a threshold as the stopping criterion for feature selection. Several filter-based methods have been proposed in the literature including information gain, 10 gain ratio, 11 term variance, 12 Gini index, 13 Laplacian score, 14 Fisher score, 15 minimal-redundancy-maximal-relevance, 16 random subspace method, 17 relevance-redundancy feature selection, 18 unsupervised feature selection method based on ant colony optimization (UFSACO), 19 relevance–redundancy feature selection based on ant colony optimization (RRFSACO), 20 graph clustering with node centrality for feature selection method (GCNC), 21 and graph clustering based ant colony optimization feature selection method (GCACO). 22
Wrapper-based methods combine feature selection with the design of the classifier and evaluate the feature subsets on the basis of the accuracy of classification. Examples of wrapper-based methods include sequential backward selection, sequential forward selection, 23 ant colony optimization, 24 PSO, 25 genetic algorithm (GA),26,27 random mutation hill-climbing,28,29 simulated annealing, 30 and artificial bee colony.31,32 Although these approaches could generally achieve a better result compared to the filter-based approach, they require more computational resources in order to select the best feature subset.
The combination of filter- and wrapper-based approaches produces the embedded approach–based method. Embedded approach–based methods seek to subsume feature selection as part of the model building process and are associated with a specific learning model. First, the filter-based approach is used to eliminate the irrelevant features and noise features, so as to reduce the number of features to be selected. On the basis of that, the wrapper-based approach is applied to optimize the feature set. The embedded approach–based method integrates the high efficiency of the filter model and the high accuracy of the wrapper model, therefore achieving a better feature subset.33–35
Considering feature selection into the human activity recognition chain can improve performance than the one achieved when the entire feature set is used. 36 S Chernbumroong et al. 37 proposed a feature selection for multi-sensor activity recognition based on maximum relevancy maximum complementary. This method is different from the traditional ones using correlation and redundancy as the selection criterion and takes into account the complementarity among features, thereby improving the recognition rate of multi-sensor activity. H Fang et al. 38 integrated the back-propagation neural network algorithm with the principle of distance maximization between classes for feature selection. N Oukrich et al. 39 used multilayer perception and back-propagation algorithm to train the neural network, and selected the features in line with the minimum redundancy maximum correlation criterion to recognize activity behavior. Moreover, J Suto et al. 40 compared wrapper feature selection with the filter-based method, and their experimental results showed that the former one outperformed the latter one in terms of activity recognition. MT Uddin and MA Uddiny 41 proposed a guided random forest-based feature selection algorithm and leveraged the activity dataset to train the random forest to distinguish the importance between different features. Furthermore, multi-attribute fusion was used in Wang and Huo 42 to jointly incorporate the mutual information, interclass difference information, intra-class fluctuation information, and computational complexity. In order to select important discriminating features to recognize the human activities, the features were selected based on spatiotemporal orientation energy and template matching, and the relevant features were identified by gradient boosting and random forest. 43 S González et al. 44 first analyzed the information correlation coefficient and then adopted the wrapper method for feature selection. UM Nunes et al. 45 presented a novel framework using max-min features and key poses with differential evolution random forest classifier, which had no thresholds to tune. In addition, X Xian et al. 46 proposed a modified method with linear discriminant analysis (LDA) based on GA, and their testing results showed that the modified method can effectively raise the recognition accuracy.
In existing works on activity recognition, feature selection algorithms are mostly based on the assumption of feature independence. The independence hypothesis simplifies the model to a certain extent and reduces the selection time, but results in poor recognition results in some scenarios due to interdependence among features. For instance, if a feature is considered separately, it may not be related to the target object, but it may be very relevant to the target if it is considered together with other features.
Correlation-based BPSO method for feature selection
BPSO
PSO is a meta-heuristic search algorithm proposed by Drs Eberhart and Kennedy in 1995. The algorithm originated from the behavior of bird predation, which is simple and easy to implement, and is the most widely used swarm intelligence optimization algorithm.47,48 The basic idea behind PSO is to find the optimal solution through mutual cooperation and information sharing among individuals in a swarm. Inspired by the regularity of the birds’ cluster activities, it is actually a simplified model on the basis of swarm intelligence. When observing the activity of animal groups, the PSO changes the motion direction of the whole group from disorder to order in the feasible solution space, according to information sharing between individuals. For illustration, consider a group of birds (particle swarms) randomly searching for food in a region (a solution of the problem), with only one objective (optimal solution). All birds do not know the explicit position of the food at first but are aware of the distance between themselves (the current optimal solution of the individual) and food (the fitness of the solution). So the most intuitive way to find the target food is to search over the surrounding area of the nearest bird (the optimal solution of the group). In particular, each bird in the flock, based on the optimal position of the current flock and the best position it has flown over, constantly adjusts its current position and velocity to search for food.
More specially, Kennedy and Eberhart 49 proposed BPSO to solve the discrete optimization problem in 1997. For BPSO, the velocity vector of a particle is no longer the change rate of the particle position, but the probability of change for that particular particle position. Depending on the velocity, the value of the particle is set to be 1 or 0. The solution processes in the m-dimensional space of the BPSO are as follows:
1. Randomly generate n m-dimensional particles, with the position
2. Use the fitness function
3. Determine whether the convergence conditions are met: if met, go to step (5); otherwise, go to the next step.
4. Each particle tracks
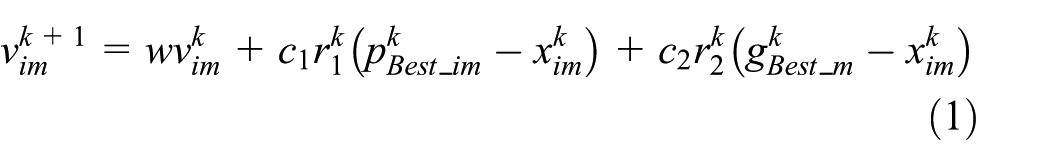
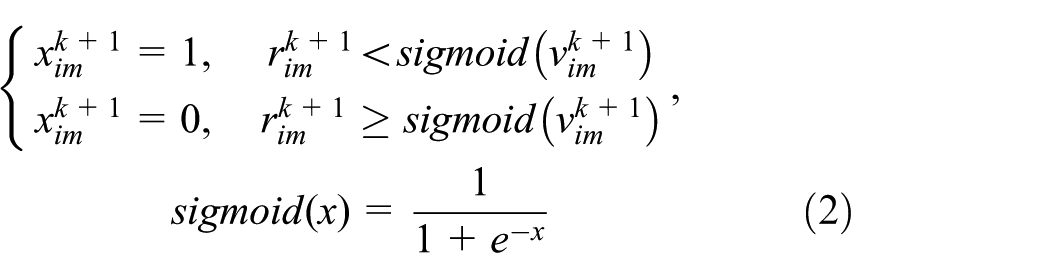
where
5. After the update is completed, go to step (2).
6. End.
Feature selection algorithm
PSO algorithm is easy to understand and simple to implement, and can solve many optimization problems. Therefore, studies on PSO for feature selection have concerned experts and scholars from both academia and industry. Although PSO has good optimization performance, it still has a lot of room for improvement when it comes to specific optimization problems. Most existing feature selection algorithms based on PSO ignore the particularity of feature selection and only take advantage of the search ability of particle swarm. However, if the differences between fitness functions are neglected, the existing feature selection by PSO is almost identical to other optimization problems.
The traditional feature selection typically assumes that the feature is independent of each other. However, there exists the correlation between features, and the optimal subset is typically not a simple combination of multiple individual optimal features, thus necessitating the analysis of the correlation between features. Moreover, the studies on feature selection mostly ignore the particularity of feature selection, but simply use the search ability of the PSO algorithm. At this time, PSO is only deemed as a black box. 50 Based on the above considerations, this article focuses on the combination of feature optimization and PSO, and proposes a feature correlation–based method to improve the search efficiency of PSO. This method increases the probability of feature with more information being selected and effectively selects features with larger discriminative power between classes, so as to reduce high computational cost and improve poorer performance of classification algorithms caused by redundant features. It also improves the timeliness and accuracy of activity recognition. The location update strategy adopted by traditional BPSO algorithm lacks the consideration of correlation between features, which makes it unsuitable for feature optimization problems. In this article, a new location update strategy for feature selection is designed to improve the optimization ability of BPSO. Intuitively, in each component of the position vector, the new position update strategy takes overall consideration of the particle’s current velocity, current position, the best position experienced by each individual, the optimal location of the population, and the relevance between features to be selected. As such, the feature with a larger amount of data would be selected with higher probability, resulting in a considerable improvement in optimization performance. Next, we will elaborate our proposed feature selection method–based BPSO with consideration of feature correlation in human activity recognition.
Given a p-dimensional feature set
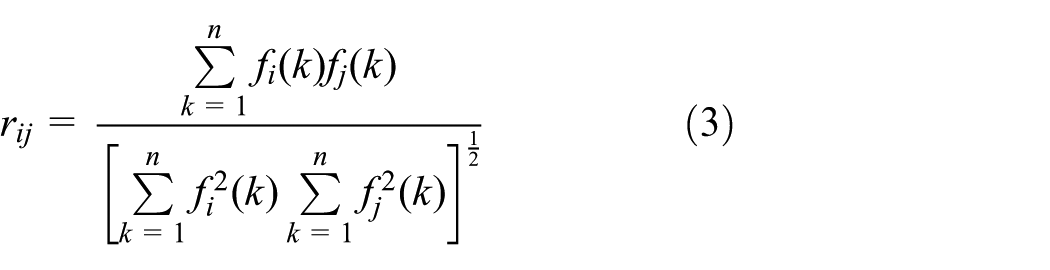
From the Cauchy–Schwartz inequality, it follows that the absolute value of the correlation coefficient is not greater than 1. A larger

where

which could be utilized to obtain the similarity measure of all the features

Considering the similarity between features (i.e. redundancy),

Typically,

where
The traditional PSO mainly utilizes real-number encoding to solve the continuous optimization problem; nevertheless, most selection problems are only with discrete data, thus constraining the PSO to some extent. In view of the particularity of feature selection, binary encoding is adopted, which encodes each dimension feature by binary numbers.
Meanwhile, to enable a higher recognition rate for the selected feature subset, we utilize wrapper feature selection. In other words, the fitness function of the PSO is a certain classification algorithm. KNN classification algorithm is simple and easy to implement, and supports incremental learning. In this study, the KNN classifier is chosen as the fitness function in the PSO to evaluate the performance of a feature subset. Then the feature set with the highest recognition rate of KNN classifier is selected as the final feature vector.
The pseudocode is shown in Figure 1, which starts with the initialization of each particle in the population. Then the correlation coefficients between features and the contribution of each feature in all feature sets are calculated to obtain the optimal initial value of the individual and the population, as defined by lines 6 and 7. The search process will stop and output the optimal position of the population, if the process comes to a stopping condition; otherwise, it will execute circularly. Two stopping conditions are defined—either when the error reaches the preset requirement or when the number of iterations exceeds the maximum allowable number of iterations. Lines 8–20 define the detailed cyclic process to get the optimal feature subset, which contains updating the particles’ velocity and position, calculating the fitness value of the particle using KNN classifier, and updating the historical best position of the particle and the optimal position of the population. The optimal feature subset will be selected after finishing this cyclic process.

Pseudocode of the proposed feature selection algorithm.
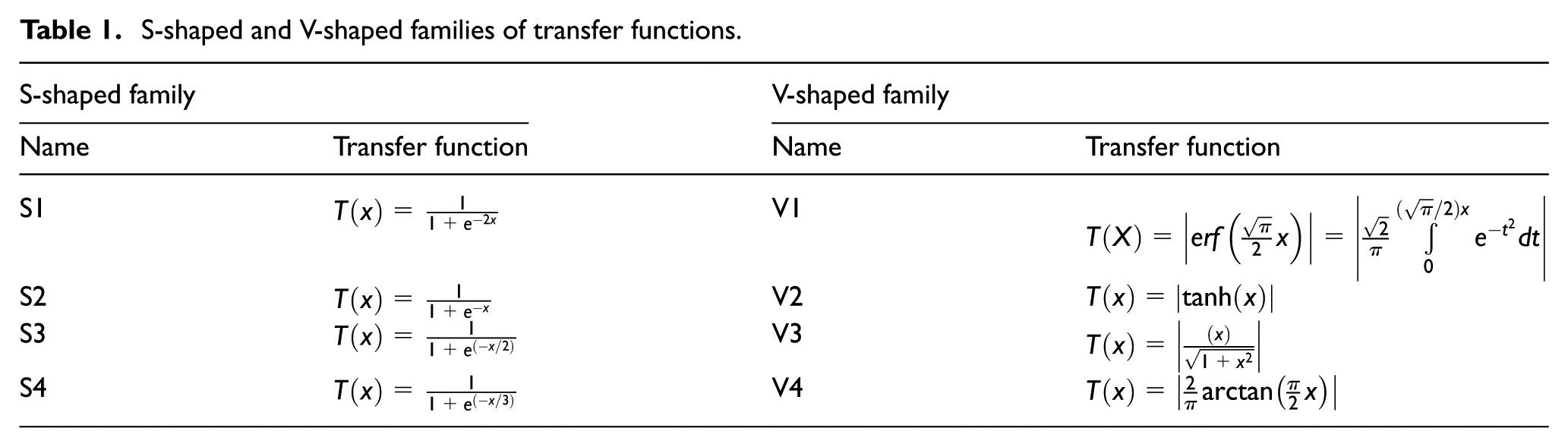
PSO is an optimization method and has good local search ability. Therefore, it is a hot research topic to use PSO to solve the problem of feature selection. There are a number of publications that have reviewed the work done so far in this area; for example, the BPSO is used to select effective text features in text data and extract effective physiological signal to classify the emotional state, and in addition it is also widely used in face recognition. So the proposed approach can be easily extended to different problems of feature selection. The main part of this algorithm is a transfer function which is for mapping a continuous search space to a discrete search space. In the study of Mirjalili and Lewis, 51 the sigmoid function in equation (8) has eight alternatives, including four S-shaped functions and four V-shaped functions, as shown in Table 1. Therefore, in this experiment, the eight transformation functions are used for feature optimization, and the results are compared.
S-shaped and V-shaped families of transfer functions.
Experimental results and discussion
Here, we show the effectiveness of the proposed method with the experimental results, where the OPPORTUNITY Activity Recognition dataset52,53 is employed. In particular, the acceleration sensor data of positions 1, 2, and 3 in the dataset are utilized to analyze four basic activities (i.e. standing, walking, sitting, and lying), as illustrated in Figure 2. The total number of raw data is 358,987, while that of the preprocessed data turns out to be 290,680, with a detailed volume list (as shown in Table 2) for each specific activity.
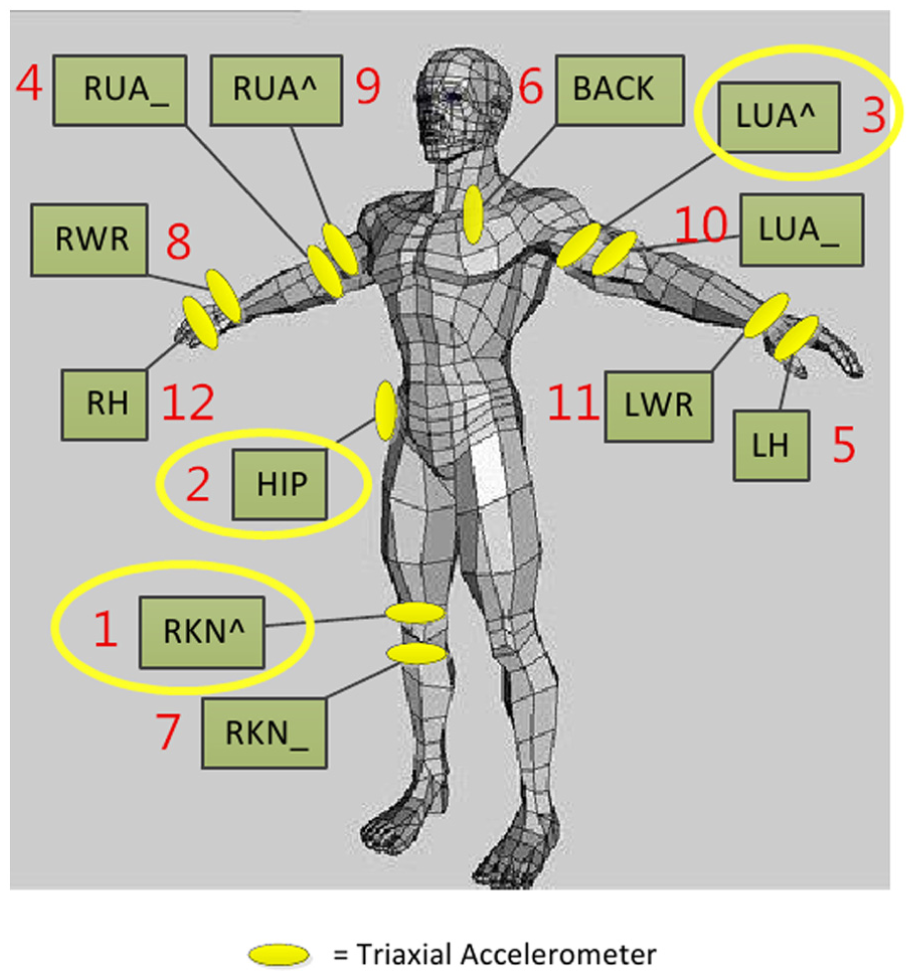
Sensor deployment of the OPPORTUNITY dataset.
The number of activity samples.

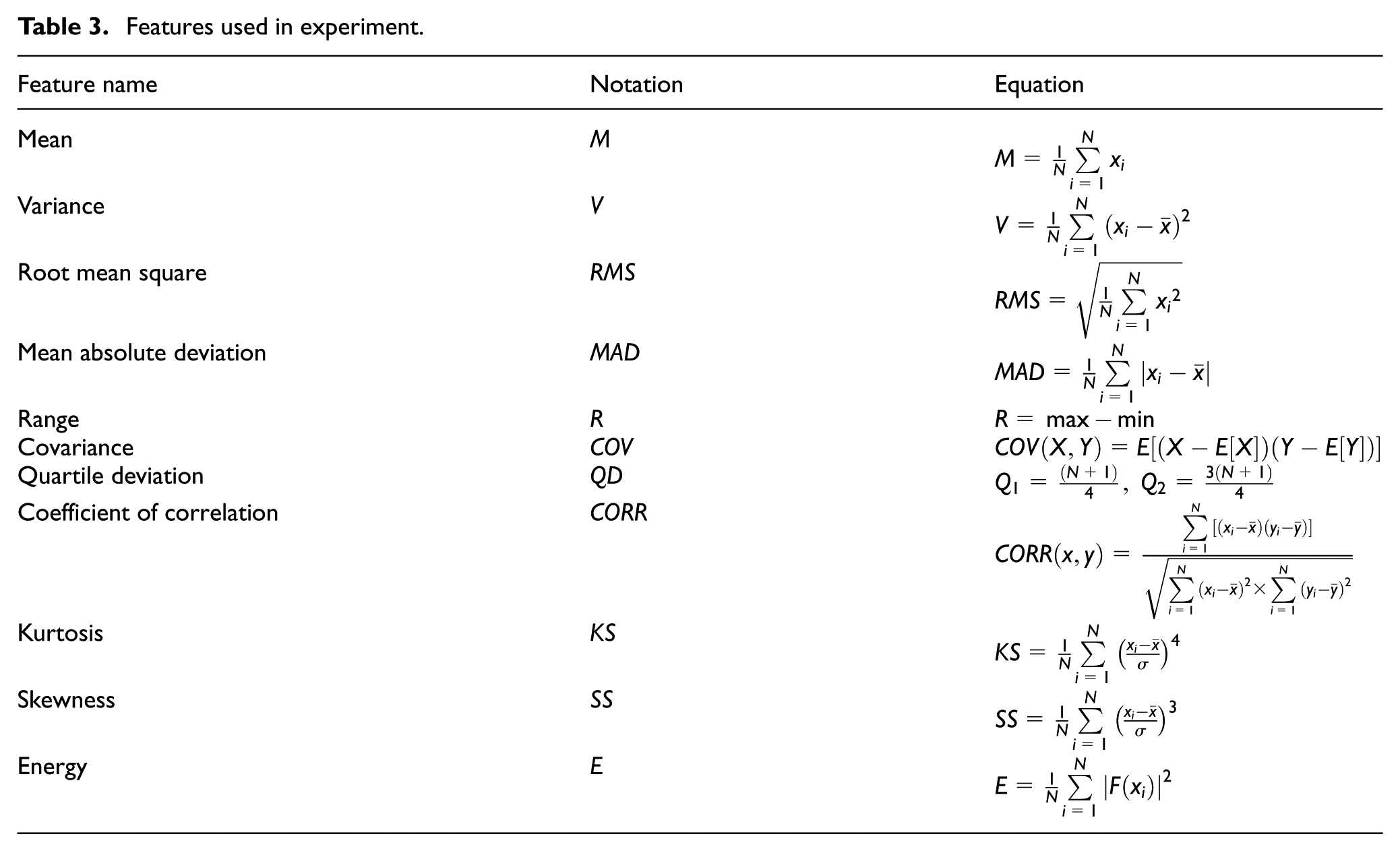
In the experiment, the BPSO iterates 500 times. The number of initial particles is 30 and the particle dimension is identical to the feature dimension. Majority of the approaches used window size in the range of 0.1–10 s, with an overlapping either absent or limited to 50% between consecutive windows.54,55 Banos et al. 56 proved that short windows normally resulted in better recognition performance, and the interval of 1–2 s would exhibit the best trade-off between recognition speed and accuracy from a global perspective. Therefore, the window size is set to be 0.5 (32 pieces of data in a window), 1 (64 pieces of data in a window), and 2 s (128 pieces of data in a window) for data partitioning and feature extraction, respectively. Meanwhile, a total of 11 features, that is, mean, variance, root mean square, mean absolute deviation, range, covariance, quartile deviation, coefficient of correlation, kurtosis, skewness, and energy, are utilized for selection, as shown in Table 3.
Features used in experiment.
Taking into account two factors, that is, sensors in different positions and different axes in the same sensor, the selection experiment can be categorized into two schemes: (1) considering only the influence of sensors’ positions on feature selection results, excluding the possible effect of different sensor axes, with a 33-dimensional feature set, and (2) involving only the effect of each feature in the same sensor on feature selection, without considering the influence of different axes of sensor and the different axes of the same sensor. Also, feature selection for sensor data is with three positions, that is, RKN, HIP, and LUA, respectively, and the feature set for each position is 10-dimensional (correlation coefficient is not taken into account). For each scheme, the experiment is further divided into two steps. First of all, pairwise combinations of all four behaviors form six types of activity groups, that is, sitting–lying, walking–lying, standing–walking, standing–lying, walking–sitting, and standing–sitting. By feature selection experiments, we can select the feature subsets which can be utilized to effectively distinguish among these activity groups and then analyze the optimal distinguishing feature sets of pairwise behaviors in each group (the experiment shows that the size of the window is 32 s and the feature dimension is 33, and the size of the other windows and the feature dimensions are similar to those of the group). Then, the four behaviors are assembled into an activity group for feature selection, and features that could effectively distinguish among all four activities are selected.
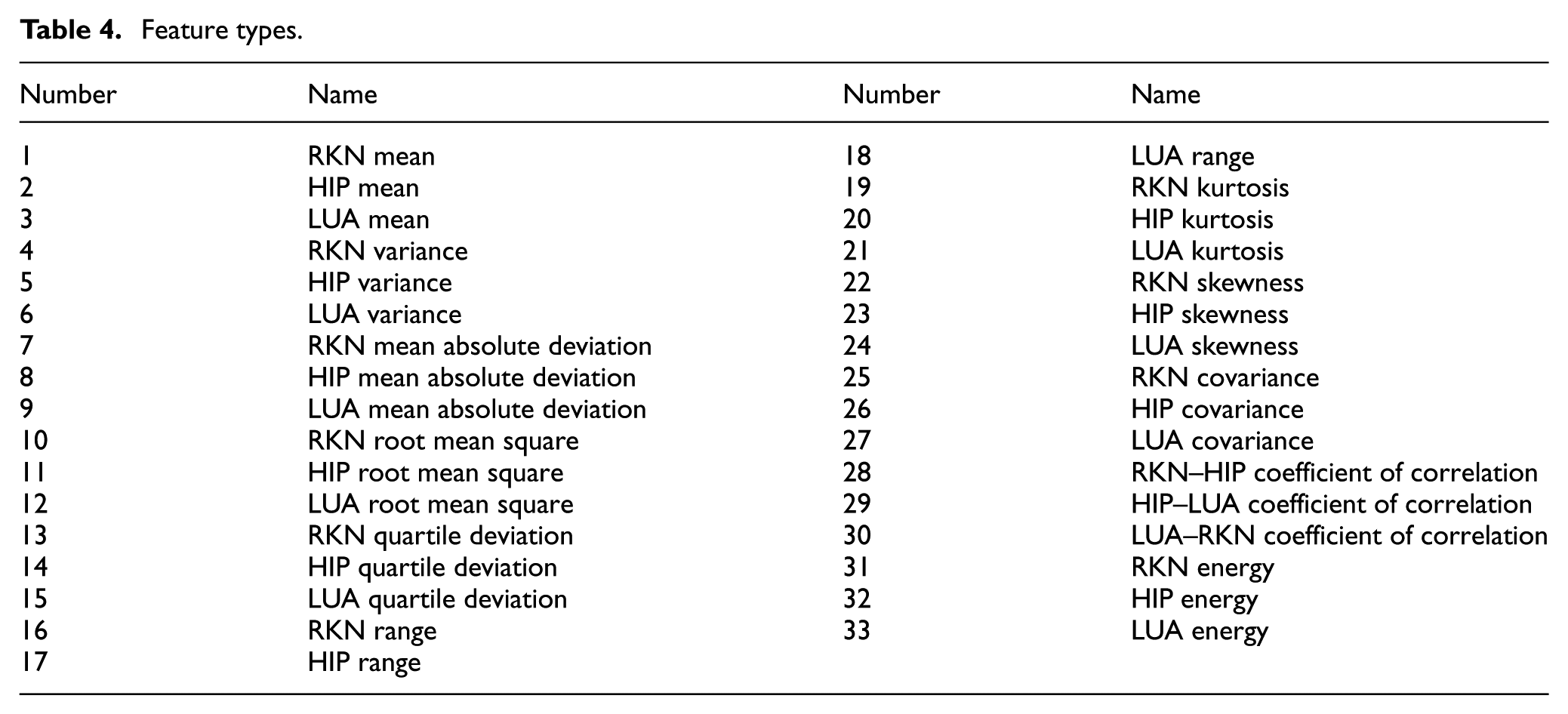
The 33 types of features are listed in Table 4. For the case with a window size of 0.5 s, the number of feature samples is set to be 18,162 and scheme 1 is conducted. The experimental results of four activities in pairwise combinations are shown in Tables 5–10 and Figure 3, and those of the four behaviors as a behavior group are presented in Table 11 and Figure 4.
Feature types.
Recognition rate and selected feature subset in the case of sitting–lying.

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
Recognition rate and selected feature subset in the case of walking–lying.
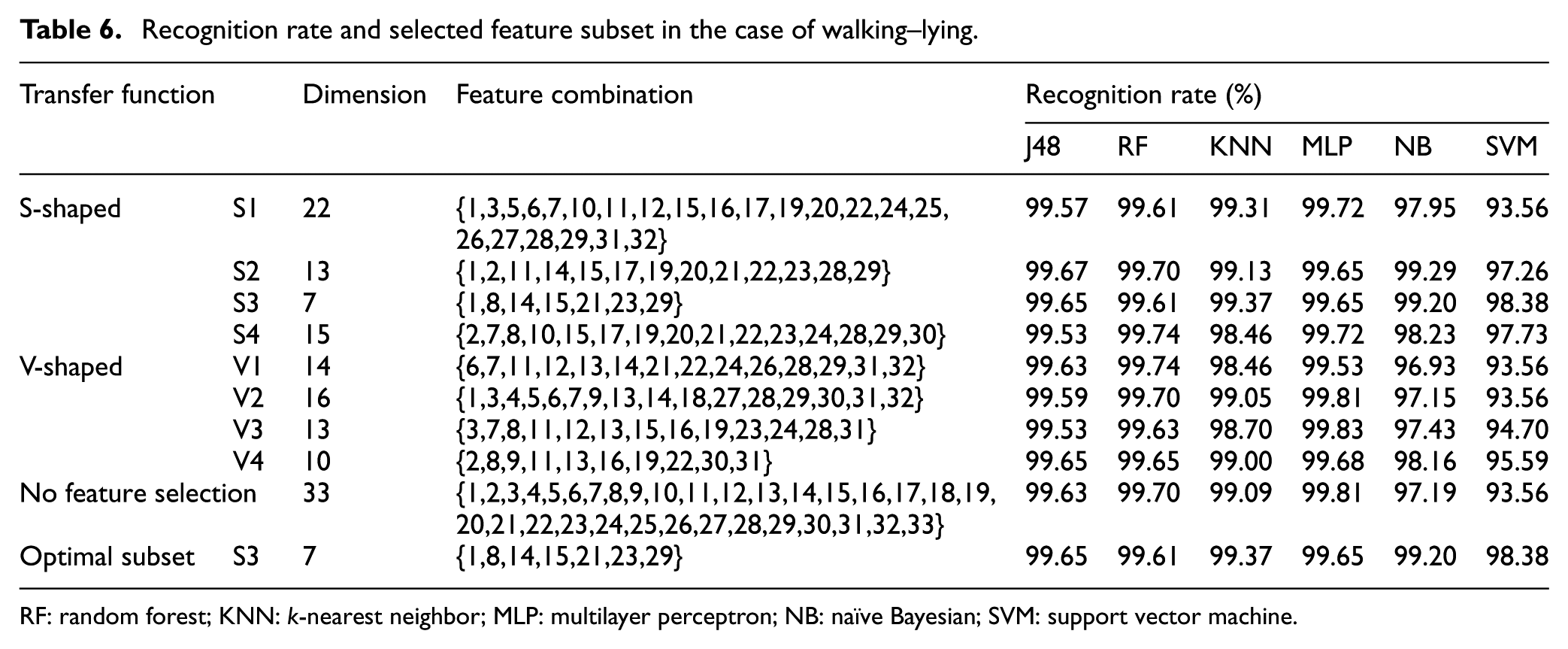
RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
Recognition rate and selected feature subset in the case of standing–walking.

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
Recognition rate and selected feature subset in the case of standing–lying.

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
Recognition rate and selected feature subset in the case of walking–sitting.
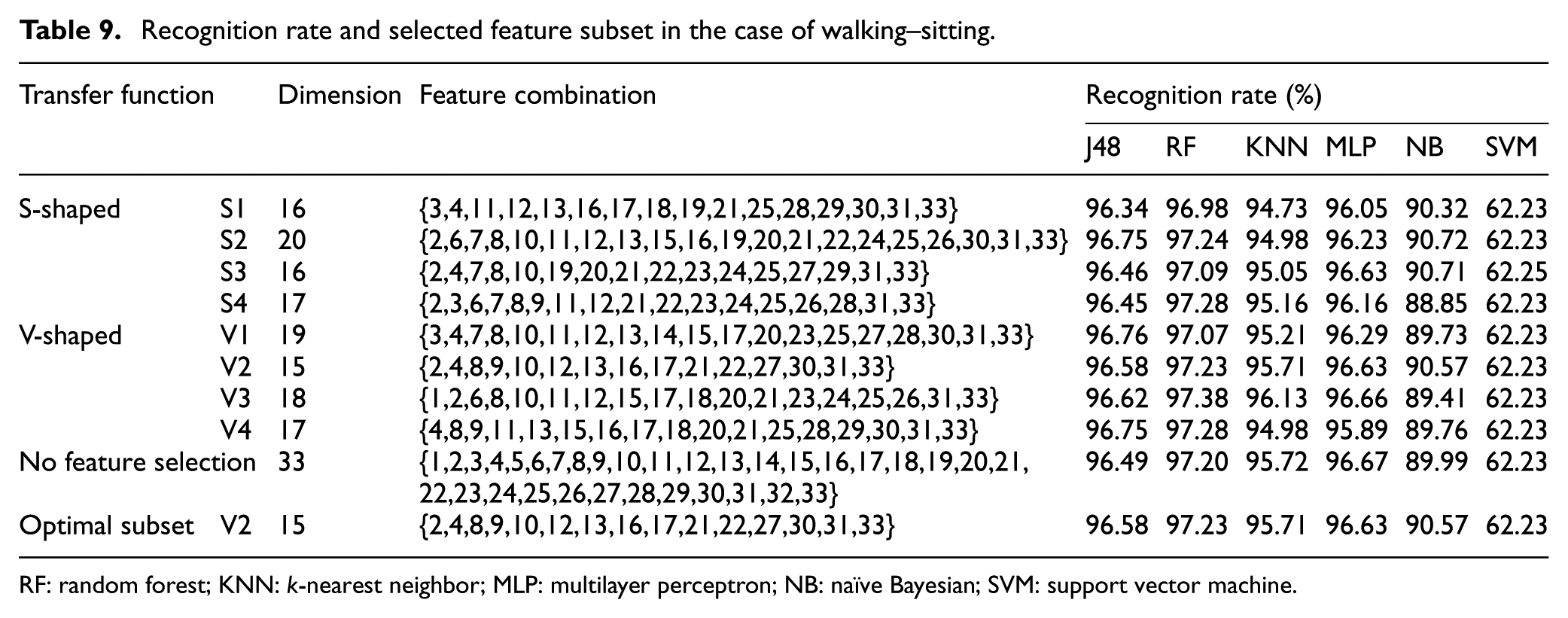
RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
Recognition rate and selected feature subset in the case of standing–sitting.

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.

Recognition rate comparison of full feature and optimal feature subset for six activity groups: (a) sitting–lying, (b) walking–lying, (c) standing–walking, (d) standing–lying, (e) walking–sitting, and (f) standing–sitting, with a window size of 0.5 s and scheme 1 being conducted.
Recognition rate of optimal feature subset with six classifiers in the case of six groups.

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.

Comparison of recognition rates in the case of all activities (window size is 0.5 s, scheme 1).
From the experimental results of the pairwise combinations (as shown in Table 11), it follows that for all six combinations of activities the feature selection proposed in this article can identically select the feature combination with lower dimension and higher recognition rate. Among all six classification algorithms, that is, J48, random forest (RF), KNN, multilayer perceptron (MLP), naïve Bayesian (NB), and support vector machine (SVM), the SVM and NB classifiers combined with our proposed method demonstrate the best recognition effect. It could not only greatly reduce the feature dimension, but also improve the recognition rate. Meanwhile, J48 and RF are suboptimal, while KNN and MLP recognition produce the worst performance. In terms of the overall recognition effect, the recognition rates of the RF and MLP classifiers are the highest, which are 99.74% and 99.83%, respectively. In addition, as compared to J48 and KNN, NB and SVM show lower recognition rates. It should be noted that the sensor data of RKN an LUA contribute significantly to distinguishing between sitting–lying, walking–sitting, and standing–sitting. For distinguishing between walking and lying, the contributions from the sensor data of HIP and LUA are greater. Moreover, the sensor data of RKN, HIP, and LUA are efficient for distinguishing between standing and walking. For the distinction between standing and lying, RKN and HIP contribute more.
It can be seen from Table 11 that the recognition rate of walking–lying is the highest among all six action combinations, which reaches 99.65% when using J48 and MLP classifiers. It should be noted that the distinction degree of lying is higher than those of the other three actions. Walking–sitting and standing–sitting have medium recognition rates, which shows that the sitting action is with moderate distinction. The activity with the lowest recognition rate is standing–walking, while the highest recognition rate of the six classifiers reaches 88.39%, indicating that the distinction between standing and walking is relatively low. It could be concluded that J48, RF, and MLP have the best recognition effect, while NB and SVM are of inferior effect and KNN is of medium effect.
The window size is 0.5 s and the number of feature samples is 18,162. The results of experiment carried out according to scheme 1 are shown in Table 12 and Figure 4, while Table 13 shows the results of scheme 2. Features 1–10 represent the mean, variance, mean absolute deviation, root mean square, interquartile range, range, kurtosis, skewness, covariance, and energy at each position, respectively.
Recognition rate and selected feature subset in the case of all activities (window size is 0.5 s, scheme 1).

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
Recognition rate and selected feature subset in the case of all activities (window size is 0.5 s, scheme 2).
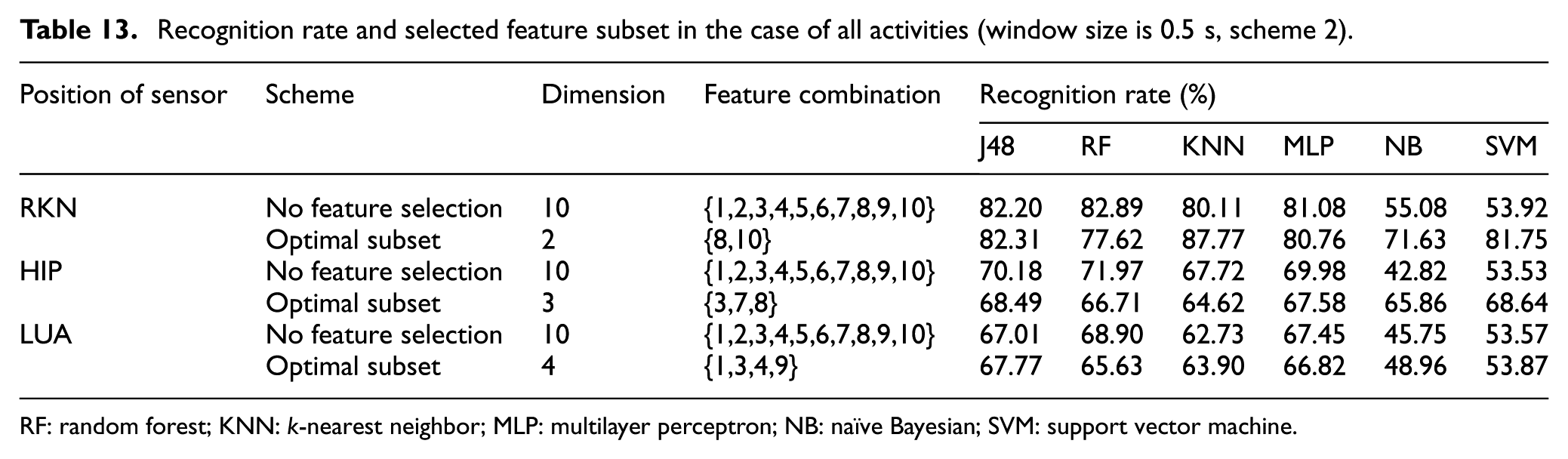
RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
As can be seen from Table 13, the recognition effect of RKN is the best, followed by HIP, and that of LUA is worse. For all six classifiers, the recognition rates of J48, RF, and MLP are higher, KNN shows a medium recognition rate, while NB and SVM demonstrate the worst performance. The feature selection proposed in this article can effectively reduce the feature dimension, optimize the feature that contributes the most to the classification performance, and reduce the computational complexity as well as improve the recognition rate.
For the window size of 1 s, the total number of feature samples is 9078. The experimental results are shown in Table 14 and Figure 5 when the experiment was carried out according to scheme 1, and the experimental results of scheme 2 are shown in Table 15.
Recognition rate and selected feature subset under the condition of all activities (window size is 1 s, scheme 1).

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.

Comparison of recognition rates under the condition of all activities (window size is 1 s, scheme 1).
Recognition rate and selected feature subset under the condition of all activities (window size is 1 s, scheme 2).
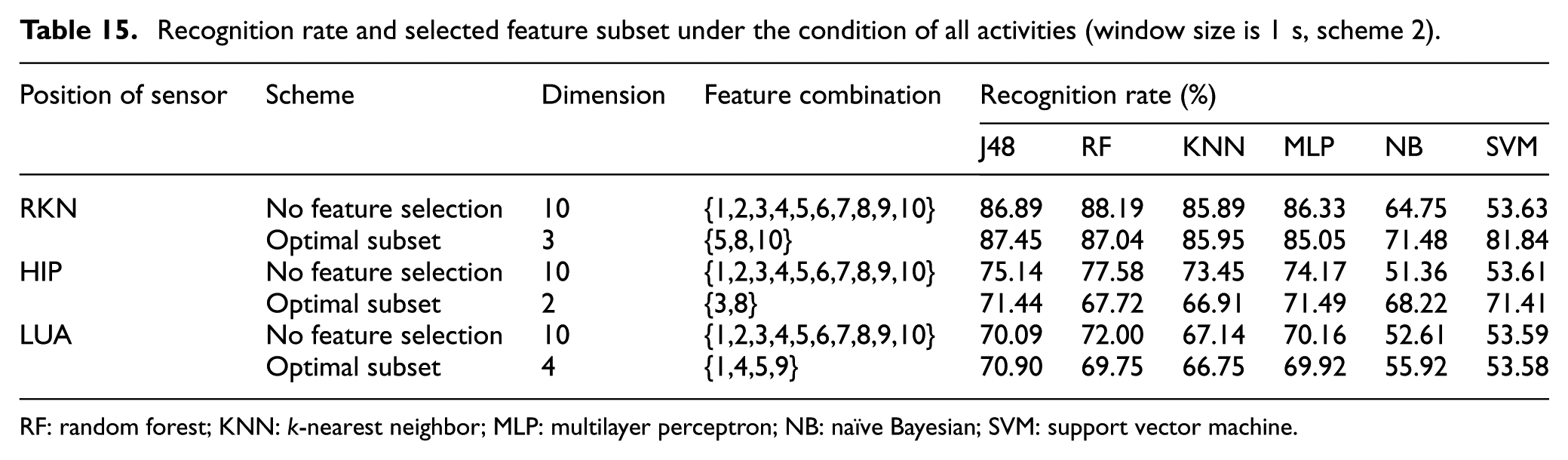
RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
For the window size of 2 s, the total number of feature samples is 4536. The experimental results are shown in Table 16 and Figure 6 when the experiment was carried out according to scheme 1, and the experimental results of scheme 2 are shown in Table 17.
Recognition rate and selected feature subset under the condition of all activities (window size is 2 s, scheme 1).
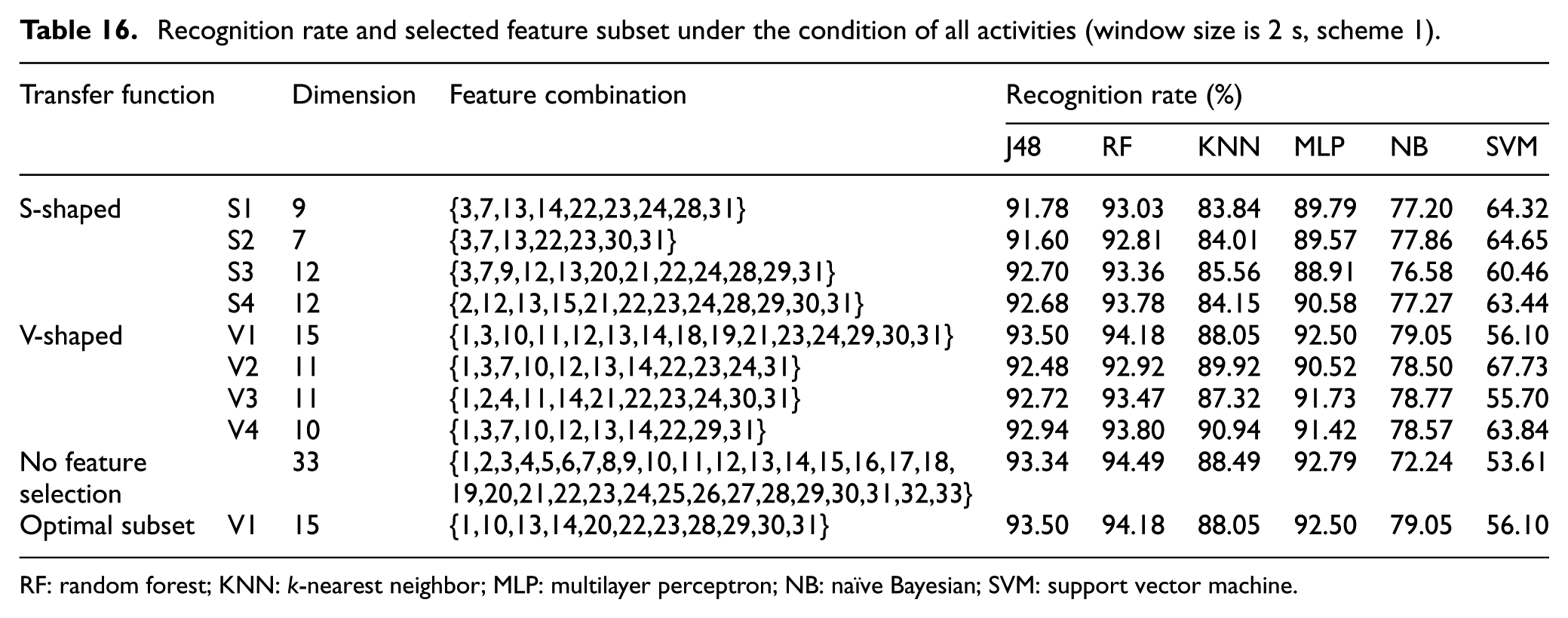
RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.

Comparison of recognition rates under the condition of all activities (window size is 2 s, scheme 1).
Recognition rate and selected feature subset under the condition of all activities (window size is 2 s, scheme 2).

RF: random forest; KNN: k-nearest neighbor; MLP: multilayer perceptron; NB: naïve Bayesian; SVM: support vector machine.
From Tables 12–17 and Figures 4–6, regardless of the size of the window, it follows that for each window size our proposed feature selection can effectively improve the recognition rate and reduce the computational complexity. Meanwhile, the recognition effect becomes better with the increase of window size. For a window size of 2 s, the recognition rate of RF can reach 94.49%. This is because the amount of data in each window increases with an increase of the window size. As such, the number of activity features embedded in the window also grows, leading to a higher recognition rate. In the cases with different window sizes, the recognition effect of sensors in the RKN position is the best and the most stable, followed by the HIP position, while the sensors placed in the LUA position show the worst effect. For the six classifiers, the recognition rates of J48, RF, and MLP are relatively high, KNN is of medium rate, while NB and SVM show the worst performance.
For the case with a window size of 2 s, the total number of feature samples is 4536 and the selection experiment is conducted with scheme 1. In the case of S-shaped and V-shaped conversion functions, the number of each dimension feature data belonging to the optimal feature subset is counted, as shown in Figure 7. It can be seen from Figure 7 that the number of the 3rd, 13th, 22nd, 23rd, 24th, and 31st dimensions of the optimal feature subsets is the largest, but the final optimal feature subsets {1,3,10,11,12,13,14,18,19,21,23,24, 29,30,31} do not incorporate all of these higher-frequency features (that is, the optimal feature subset is not a simple combination of features with high frequency). The optimal feature subset does not necessarily include features with high frequency, since the feature subset selected by features of high frequency only may not have the best classification effect. On the contrary, features with lower frequency are also likely to generate stronger classification effect through the interaction of features, such as the 18th and 19th dimensions.

Number of each feature in the case of S-shaped and V-shaped transfer functions.
For the case with a window size of 2 s, the total number of feature samples is 4536 and the selection experiment is conducted in scheme 2. Figure 8 illustrates the convergence curves in the case of S-shaped and V-shaped transfer functions of three different position data, with four activities treated as a group. As can be seen from the figure, the eight types of transfer functions converge rapidly under the three position conditions, which shows that the preferred method in this article can select the optimal subset of features that meet the requirements in a relatively short time and, to a certain extent, improves the real-time activity recognition system.

Convergence curves under the condition of S-shaped and V-shaped transfer functions: (a) RKN, (b) HIP, and (c) LUA.
Conclusion
In this article, the feature selection problem in activity recognition is discussed first and then the BPSO is introduced briefly. Based on the criteria of classification accuracy, a correlation-based BPSO method for feature selection in human activity recognition is proposed. In the proposed algorithm, the correlation coefficients between the features are added to the BPSO as a feature correlation factor to determine the positions of particles. This method takes into account the particularity of the feature optimization problem and no longer uses the PSO algorithm as a black box. It makes the feature with more information more likely to be selected and improves the performance of the feature selection method based on PSO. The KNN classifier is then used as the fitness function in PSO to evaluate the performance of the feature subset, and the feature combination with the highest KNN classifier recognition rate could be picked as the eigenvector. Finally, a large number of experiments were carried out for the proposed method. The results show that the proposed method can effectively improve the accuracy of activity recognition.
As we showed in this article, the proposed algorithm has a significant impact on activity recognition accuracy and should be taken into account. Considering the promising results obtained in this pilot study, we intend to work on novel feature selection methods based on BPSO while better dealing with data diversities. Another point that deserves to be further assessed is the optimization of runtime performance as it plays an important role in improving the recognition efficiency.
Footnotes
Acknowledgements
The authors are grateful for the anonymous reviewers who have made constructive comments.
Handling Editor: Daniel Gutierrez-Reina
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Plan (No. 2017YFB1402103), Natural Science Foundation of China (No. 61172018, 61771387), Scientific Research Program of Shaanxi Province (2016KTZDNY01-06), Project of Xi’an Social Science Planning Foundation (No. 16J133), CERNET Innovation Project (No. NGII20150707, NGII20160704), and Xi’an BeiLin Science Research Plan (No. GX1626, GX1623).