
Abstract
Recognition of human activities is getting into the limelight among researchers in the field of pervasive computing, ambient intelligence, robotic, and monitoring such as assistive living, elderly care, and health care. Many platforms, models, and algorithms have been developed and implemented to recognize the human activities. However, existing approaches suffer from low-activity accuracy and high time complexity. Therefore, we proposed probabilistic log-Viterbi algorithm on second-order hidden Markov model that facilitates our algorithm by reducing the time complexity with increased accuracy. Second-order hidden Markov model is efficient relevance between previous two activities, current activity, and current observation that incorporate more information into recognition procedure. The log-Viterbi algorithm converts the products of a large number of probabilities into additions and finds the most likely activity from observation sequence under given model. Therefore, this approach maximizes the probability of activity recognition with improved accuracy and reduced time complexity. We compared our proposed algorithm among other famous probabilistic models such as Naïve Bayes, condition random field, hidden Markov model, and hidden semi-Markov model using three datasets in the smart home environment. The recognition possibility of our proposed method is significantly better in accuracy and time complexity than early proposed method. Moreover, this improved algorithm for activity recognition is much effective for almost all the dynamic environments such as assistive living, elderly care, healthcare applications, and home automation.
Keywords
Introduction
People adopt independent lifestyles and emphasize the quality of their life. They wish to have easygoing and assisted living. Thus, the system with the intelligent ability to provide various services in accordance with user’s preference should be developed. But, in order to provide intelligent services, the system needs to understand and recognize human activity and behavior first.1,2 The objective of proposed work is to predict and recognize user activities in a smart home environment more conveniently and accurately with less complexity. If we able to create an accurate and fastest activity recognition method, the smart home can provide the appropriate service in accordance with user desires. The activity of human represents the functional status of the person. Human perform numerous activities from morning to night like brushing, toileting, eating, watching TV, listening music, cooking, sleeping, going outside, medication, and so on. The activity recognition in the real world is challenging due to diversity and complexity of user activities which affect the accuracy of recognition precisely. Many researchers have proposed many ideas and works but the accuracy and complexity still remain below the target in activity recognition evolution.
The human activity recognition has broad application areas such as elderly care, 3 remote health 4 monitoring emergencies such as natural disasters, robotics, 5 comfort applications in smart homes, and energy-efficient urban spaces. Among all these, activity recognition in the smart home has gained its popularity. The number of existing study has focused on recognizing resident’s activities based on sensory data in the smart home. 6 The activity recognition systems use several types of sensors, microphones, video cameras, RFID readers, wearable sensors, and embedded sensors with appliances to determine the state of the physical world. We mainly focused on using the external sensor rather than the inertial (wearable) sensor. These days a smartphone is also getting popularity as the sensing tools for monitoring purposes of individuals activity. Audio and video-based activity recognition are sophisticated to use because it requires processing of multidimensional data and may raise user’s privacy issue.7–9
Human activity recognition system needs access to sensors, computational process, and inferring mechanism to recognize the activity. 10 The accuracy and computational complexity are the main parameters mostly considered for sustainable recognition of human activity. Inter-activity and intra-activity variations influence the accuracy and complexity. Likewise, errors in sensors, execution of activities, limited training data may impact the performance of recognition methods. Different types of machine learning approaches and probabilities reasoning algorithms have been proposed for accurate recognition. Conditional random field, 11 Bayesian network,12,13 hidden Markov model (HMM), 14 hidden semi-Markov model (HSMM), 15 adaptive HMM 16 techniques are probabilistic in nature and have been widely used for detecting the spatiotemporal aspects of the data. However, recognition accuracy is just satisfactory not better that actually have to be. And computational complexity is also very high for large dataset. This method of recognition is the data-driven approach. The data-driven approach has two discriminative and generative root approaches. Discriminative approaches are computationally efficient and good in prediction but this may suffer from overfitting. Generative approaches are flexible to uncertainty in the data but they required a large amount of data for recognition and prediction. Many researchers used either of one, but some 17 used both approaches. In this article, we present the log-Viterbi (LoV) algorithm applied on second-order HMM for recognition of activities in the smart home. The second-order HMM is an extension to the first-order HMM which contains additional information about previous activity that leads to better accuracy results. Second-order HMM relies on one observation in a current state and the transition probability function based on two previous states. Increment in order of second-order HMM may lead to the computational complexity but use of logarithm function into the Viterbi algorithm eventually confront complexity problem.
The LoV algorithm is the dynamic programming algorithm used to find the most likely sequence of hidden states by converting the products of a large number of probabilities into additions from observation sequence. Therefore, the complexity to process the product value is reduced which ultimately speed up the system.
So for to our knowledge, the LoV algorithm applied into the second-order HMM makes our approaches noble from other existing one. We have evaluated the performance of activity recognition with regard to our proposed method using three fully annotated real-world datasets generated by Kyoto and Van Kasteren and hence, compared among other probabilistic approaches: Naïve Bayes (NB), conditional random field (CRF), HMM, and HSMM activity recognition algorithm.
The remainder of the paper is organized as follows: related works of the activity recognition are in section “Related work.” Section “The proposed method” illustrates the proposed activity recognition method. The algorithm for the whole process is described in section “The proposed method.” Section “Evaluation and results” describes the experimental results and evaluation. The time complexity is covered in section “Time complexity” followed by conclusion in section “Conclusion.”
Related work
From late 90s to till date, human activity recognition is one of the interesting topics for many researchers worldwide. However, development of improving an accurate technique has some serious issues to meet the real-world condition. The realistic data collection, unobtrusive, portable, and inexpensive data acquisition system development, the design of extraction and reasoning algorithm, flexibility to support new and multi-users are the major challenges faced during activity recognition. 18
The smart home project such as the Center for Advanced Studies in Adaptive Systems (CASAS) 19 at Washington State University (WSU), Aware Home Research Initiative (AHRI) 20 at Georgia Institute of Technology, Tim Van Kasteren, 21 PlaceLab Massachusetts Institute of Technology (MIT) 22 monitor resident’s activities, upgrading comfort by installing heterogeneous sensors but its efficiency depends only on the large number of sensor inputs and processing time. In a smart home, sensors play a vital role in observing and understanding human daily activities. Basically, the external sensors (pressure, light, heat, etc.) and wearable (accelerometer, ECG, etc.) sensors have been used for human activities recognition (cooking, sleeping, walking, running, etc.) in smart homes. 23 Kasteren et al. used temporal probabilistic models (NB, HMM, CRF) to recognize the activities from the sensor data by dividing data into time-slices in constant length which may not be well suited for all activities. Tapia et al. 1 used NB to learn different length time-slices for different activities during training data. Long-range dependencies between the observations within activity segments can be modeled by integrating sequential pattern mining, used to characterize the time spans during an activity execution, with the HSMM for the activity recognition. Video-based depth image compensation with colored markers and joint trajectory on HMM was implemented 5 and analyzed with high accuracy but complexity remains high due to image processing.
For the recognition of activity the label of activity class according to highest probability of sequences of the sensor technology is used in the NB classifier. 24 Dynamic bayesian network (DBN) is tested to recognize activities by rebuilding the already learned models to use differences in activities for an incremental learning approach. Support vector mechanism (SVM)25–27 applied for classification of activities, considers redundancy of activities during feature selection process. Multilayer perceptrons25,28 and decision tree 29 are used in activity classification. The combination of pattern clustering method such as K-pattern clustering algorithm an activity decision algorithm; an artificial neural network (ANN) featuring IoT on smart home environment 30 showed some good accuracy but due to two-step process and that of IoT complexity, runtime may increase. Equally, decision tree algorithm also affords some better feasibility for more interpretability. For the big structured dataset, the neural network techniques such as deep learning 31 and deep belief network are also widely used. Again restricted Boltzmann machine (RBM) 32 and conditional restricted Boltzmann machine (CRBM) 33 have been presented as probabilistic modeling tools. The discriminative models like condition random fields (CRFs) 34 use independence assumption in which we learn the model parameters by optimizing conditional likelihood rather than joint likelihood. However, CRF is computationally uncontrollable and repeatedly depend on approximation techniques. Analysis of resident’s behavior in the smart home is done using the activity recognition. Audio 35 –video36,37 activity recognition is most suitable for healthcare and monitoring. However, the audio-visual method has privacy, complex, and pervasive issue. 38
Deep neural network can only facilitate limited temporal modeling by executing into a fixed size sliding window of activity frame. Convolutional neural network (CNN); a broadly applied deep neural network, has the ability to extract features and can learn multiple layers of features but it is bit slower and complicated. Long–short term memory is recurrent neural networks with memory called cell to model the long range temporal dependencies in time series problems 39 using the multimodal wearable sensor. In this work, we use probabilistic LoV algorithm applied on second-order HMM to overcome the time complexity of existing algorithm. Eventually, it also addresses the accuracy issue.
The proposed method
The system architecture used in the activity recognition is shown in Figure 1. Although figure describes the overall system architecture of activity recognition, our main focus is on the development of reliable algorithm using second-order HMM. Hence, we proposed the LoV algorithm.

Block diagram of activity recognition.
Raw data are taken from the sensors. The feature is extracted from the sensor data. Leave one-day cross concept is considered for the evaluation, on which a single day data are used for testing. Meanwhile, 50% of the data are used as the training data while the remaining 50% for test data. LoV algorithm produces optimal path sequence of activity from given model. And finally, the desired activity is recognized.
Second-order HMM
Normal HMM explains hidden state

State transition of second-order HMM.
Unlike the transition probability distribution
The initial state distribution

where P(i) is the probability of being i as the initial state.
2.The transition probability distribution of k given i and j

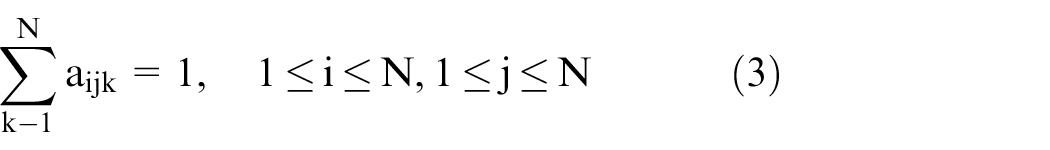
where N is the number of states in the model and yt is the hidden state at time t.
3.The observation distribution, also known as emission probability distribution and determined by

where
Second-order HMM finds a hidden state sequence which maximizes a joint probability

The parameters that maximize this joint probability are found by simply counting the number of occurrence of transitions, observations, and states. But the second-order HMM parameters need to be adjusted to overcome the evaluation, decoding, and learning problems. New forward and backward functions are defined to address the evaluation problem in which probability of observation given in the model


The log is applied to the given function
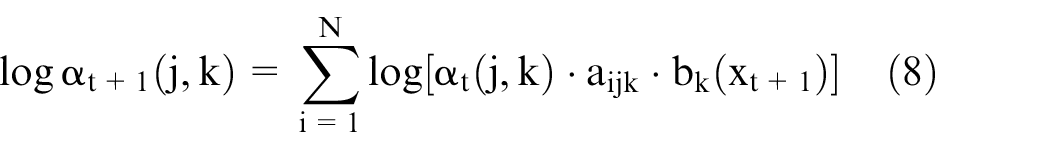

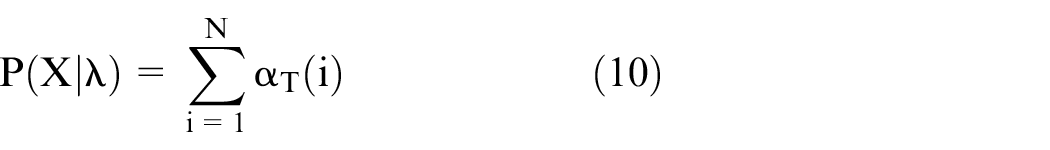
Likewise, the backward algorithm

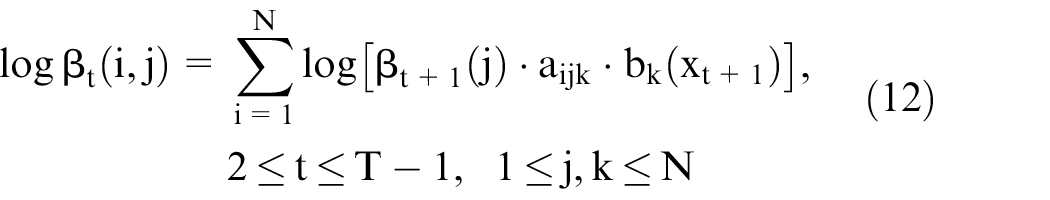
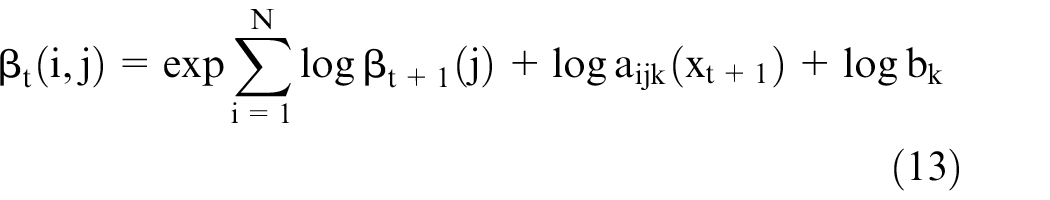
Proposed LoV algorithm
The problem of decoding can be addressed using the Viterbi algorithm. However, time complexity seems to be increased. Therefore, LoV algorithm is on the count. On given model and observation sequence

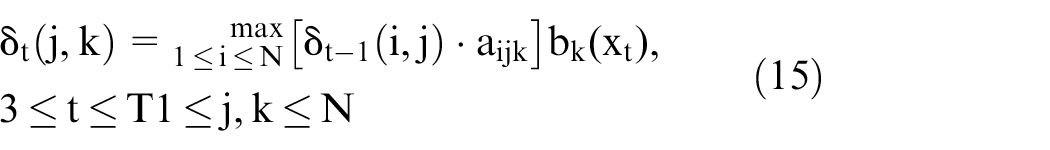
Log of




We also keep track of the most likely previous state for each possible state that we end up in probable path

And we terminate by computing the most probable final state

We can then compute the most probable sequence of states using backtracking or traceback approach.

Maximum likelihood estimation
The Baum–Welch algorithm is used 37 to compute the learning or likelihood of training observation of the model. In second-order HMM, the forward-backward algorithm determines the expected number of state transitions and emissions based on a current model in Baum–Welch-based algorithm. These parameters will be used to re-estimate the model parameters using estimation formula for each iteration. This interaction continues until a convergence to stationary point occurs. The probability of being in state Yj at time t and Yk at t + 1 given the model λ, then from definition of forward-backward algorithm is given as
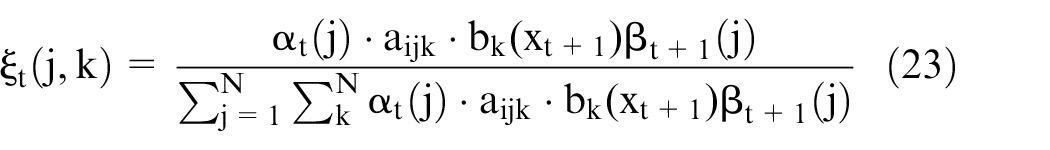
The probability of being in state Xj at time t, given the observation sequence Yj and the model λ is
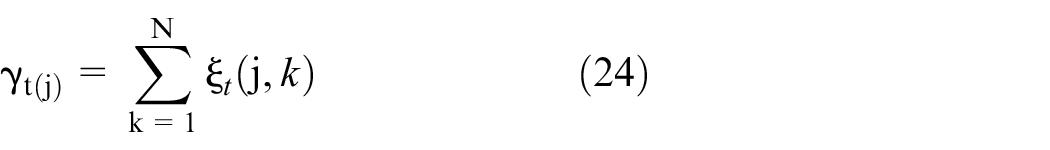
The maximum likelihood of model parameter can be re-estimate as




Evaluation and results
In our experiments, the state is considered to be the activity and observation data are the sensor data. We evaluate the proposed recognition model using three publicly available real-world datasets. The results of our approach are compared with NB, HMM, CRF, and HSMM. Furthermore, we put in front the activity level performance analysis through the confusion matrices. Leave one-day cross concept is considered for evaluation in which a single day data are used for testing, while the remaining for training. The process is repeated for all days and an average is calculated. The parameter taken for evaluation is F-score and accuracy. Finally, the time complexity is calculated as per experimental processing.

Evaluation terminology
We define evaluation terminologies as precision, recall, F-score, and accuracy. F-score is the harmonic mean of precision and recall. These terminologies are measures using true positive (TP), false positive (FP), and false negative (FN) through confusion matrix




N denotes the number of states. The F-score and accuracy values near to 1 highlight the best performance of proposed method otherwise indicates downfall of performance.
Datasets
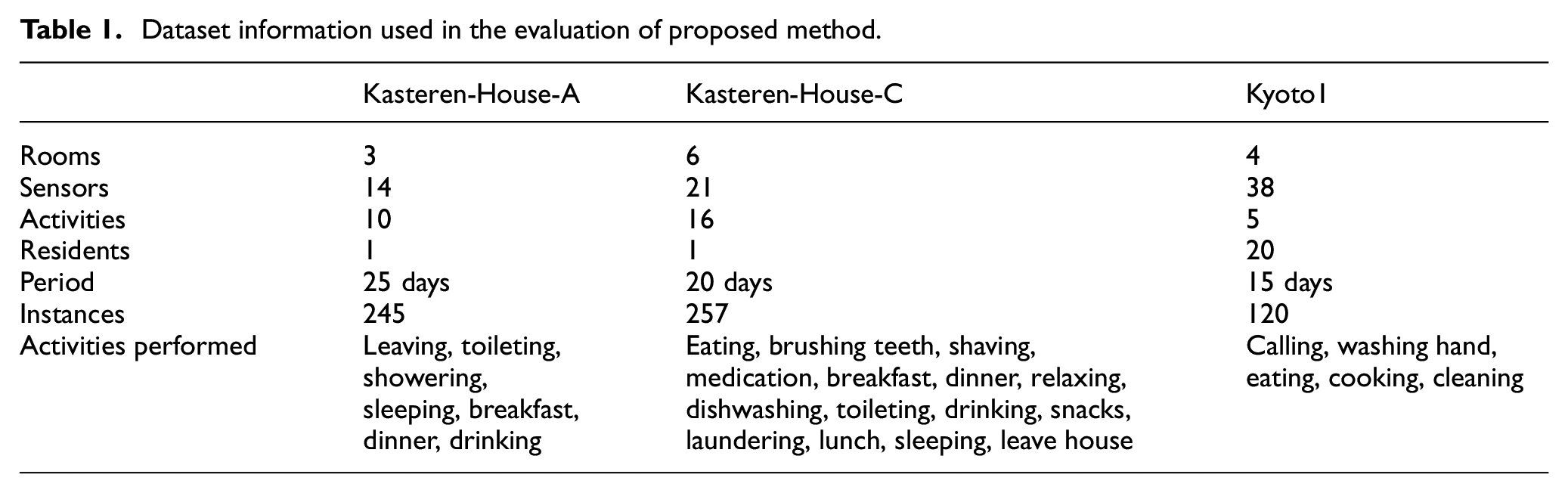
Many smart home datasets are publicly available; among them, the Kasteren datasets and WSU CASAS are very famous datasets for evaluation of any smart home projects for activity recognition. Overview of Kasteren datasets and WSU CASAS is shown in Table 1. Kasteren datasets contain three smart homes datasets (Kasteren-House-A, Kasteren-House-B, and Kasteren-House-C), but we chose only two of them. Kyoto1 is one of the many WSU CASAS datasets we selected. The Kasteren dataset is collected from performance performed by one resident. However, WSU CASAS comprises of multiple residents, which means WSU CASAS datasets provide high inter-subject variations.
Dataset information used in the evaluation of proposed method.
Activity recognition analysis
Table 2 presents confusion matrix of Kasteren-House-A activities. The proposed method recognizes activities with an average accuracy of more than 85%. Breakfast and dinner activities have 13% of their instances shared among each other because they are being performed at the same location (kitchen). Likewise, toileting and showering share 12% of instances as they share the same location (restroom). Drinking generates most of the confusion with other activity as drinking can be done while taking breakfast, dinner, leaving activities concurrently. Sleeping activity has highest accuracy of 91.3% as none other activity is done while sleeping. Table 3 shows confusion matrix of activities in Kasteren-House-C dataset. All the activities have been recognized with higher accuracy. Some of the activities like dinner have 79% activity instance recognition accuracy. It has 5%, 5.5%, 1.5%, 0.5% and 4.2% error activities recognized as eating, breakfast, dishwashing, lunch, and other, respectively. 85% of shaving activity is recognized correctly but 5%, 7.2%, 4.6%, and 5.1% activity is confused with brushing teeth, toileting, doing laundry, and other.
Confusion matrix for Kasteren-House-A.

Confusion matrix for Kasteren-House-C.

There occurred a confusion between different activities it is because of sharing same location and platform, for example, any eating activity like lunch, dinner, and breakfast, commonly occurs in the kitchen. Also share common sensor like gas sensor, heat sensor, and so on. The Kasteren-House-C has large confusion activities; therefore, F-score and accuracy are lower than Kasteren-House-A and Kyoto1. Other similar activities such as drinking, eating, lunch, snack exhibit a similar trend of sharing error and making confusion among each other. Kyoto1 dataset confusion matrix is shown in Table 4 whose recognition accuracy is more compared to other two datasets. Calling activity has 95% correctly recognized but still 6.5% of eating error activity because the call can be taken while doing both activities at the same time. Washing hand has 96%, while 3.7% and 2% of the cooking and cleaning confusion since washing hand can be done next or in between cleaning and cooking. The cooking activity is recognized 94% correctly but still creates confusion with 3%, 1.6%, 4.1%, and 1% of calling, washing hand, eating, and cleaning, respectively. The overall accuracy of the proposed method on Kyoto1 has 94.3% to recognize all of the activities. In eating activity, 89.4% instances are correctly identified, while 4%, 2% of instances are erroneously identified as wash hands, calling and 2.3% for cooking. Although accuracy is high, to find actual recognition distribution, a large number of the dataset could be needed. Kasteren and CASAS data have the least number of dataset and instances, therefore, actual distribution is easy to find out. On analysis, our proposed method to the available dataset proves to be more reliable and effective than other methods.
Confusion matrix for Kyoto1.

Activity recognition comparison
Performance evaluation of the Kasteren-House-A dataset on our proposed method is shown in Table 5. Activities like breakfast, dinner, and drinking again like toileting and showering are performed in the same location that means location sensor is shared in that location. Thus, there appeared less inter-class variation. Precision, recall, F-score, and accuracy in Kasteren-House-A are obtained as 84.21%, 83.47%, 0.84%, and 85.47% respectively, from our proposed method. The resultant values are satisfactory than the existing approaches NB, CRF, and HMM, which means location sensor is shared in that location. The resultant values are satisfactory than the existing approaches NB, CRF, HMM, and HSMM. In Kasteren-House-C precision, recall F-score and accuracy of the proposed method are 80.58%, 78.46%, 0.79%, and 78.46%, respectively. The precision, recall, F-score, and accuracy of Kasteren-House-C is less than that of inter-class variation but these values are high enough compare with other approaches. Table 3 shows the confusion matrix of the Kasteren-House-C. Kyoto1 is the CASAS datasets which have high intra-class and inter-subject variations and activity class is discriminative. Kyoto1 shows the excellent performance of our proposed method securing F-score of 0.94 and accuracy of 94.28%. The precision and recall of Kyoto1 are 94.33% and 94.28%, respectively, and remain higher on our proposed method compare to other four approaches. All the activity recognition comparison with other is clearly shown in Table 5.
Performance evaluation of smart home dataset with proposed method.

NB: Naïve Bayes; CRF: conditional random field; HMM: hidden Markov model; HSMM: hidden semi-Markov model.
Activity level performance comparison
The activity level performance of proposed method is compared with existing method NB. HMM, CRF, and HSMM are given in Figure 3. We measured the F-score of each activity on different datasets Kasteren-House-A, Kasteren-House-C, and Kyoto1 individually. Individual activity performance also shows better accuracy. Kasteren-House-A shown in Figure 3(a) has the accuracy of 85.65%, while Kasteren-House-C has 80.87% of accuracy as displayed in Figure 3(c) and Kyoto1 achieve an accuracy of about 95.67% as in Figure 3(b). We can still earn high accuracy but imbalance in the dataset, where the activities are done more frequently. The used dataset also has problem of overlapping with a minimum number of activity instances and sharing of a different sensor. However, the F-score solves this kind of drawbacks to produce reliable dataset. The proposed method has highest F-score of 0.84, 0.79, and 0.94 in Kasteren-House-A, Kasteren-House-C, and Kyoto1, respectively, compare to existing methods. This shows that our method can also be least affected by the problem of intra-class and inter-class instances.

The F-score comparison of the proposed method with the existing approaches in the activity level performance: (a) Kasteren-House-A, (b) Kyoto 1, and (c) Kasteren-House-C.
Time complexity
Time complexity appears on calculating the joint probability of hidden state sequences with observed series of activity. The regular time complexity of HMM is N2L for N states and NN state transition probabilities, 2N output probabilities of an output sequence of length L. The proposed method has the time complexity of (LN2 log N) which means the time complexity is reduced by log N. The effectiveness of the reduced time complexity is shown in Figure 4.
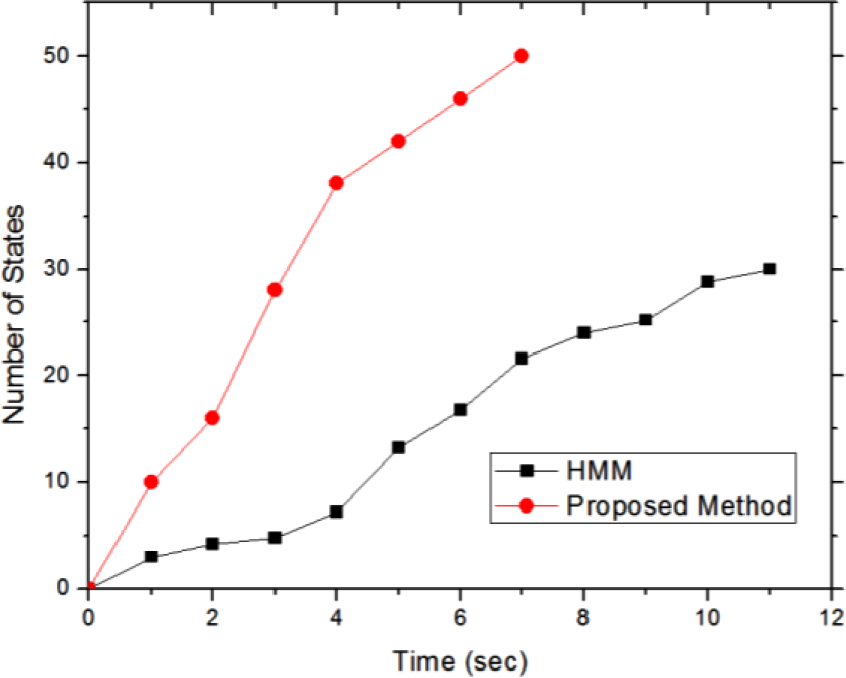
The time complexity comparison of proposed method with the HMM.
Conclusion
We have presented LoV algorithm using second-order HMM to recognize human activities in the smart home. Proposed method takes two previous activities and the current activity observation for recognition. Three real datasets are used to evaluate the recognition performance of the proposed method with other recognition methods. The proposed method shows F-score of 0.84, 0.79, and 0.94 in Kasteren-House-A, Kasteren-House-C, and Kyoto1, respectively, compare to other existing methods. In addition, it reduced time complexity by log N as compared to others. Therefore, accuracy and time complexity of recognition are better than other approaches. In future, we can increase the accuracy much more applying machine learning schemes for learning model parameters.
Footnotes
Acknowledgements
The work reported in this article was conducted during the sabbatical year of Kwangwoon University in 2016.
Handling Editor: Francesco Longo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.