
Abstract
Encryption is one of the best methods to safeguard the security and privacy of an image. However, looking through encrypted data is difficult. A number of techniques for searching encrypted data have been devised. However, certain security solutions may not be used in smart devices in IoT-cloud because such solutions are not lightweight. In this article, we present a lightweight scheme that can enable a content-based search through encrypted images. In particular, images are represented using local features. We develop and validate a secure scheme for measuring the Euclidean distance between two feature vectors. In addition, we use a hashing method, namely, locality-sensitive hashing, to devise the searchable index. The use of an locality-sensitive hashing index increases the proficiency and effectiveness of a system, thereby allowing the retrieval of only relevant images with a minimum number of distance evaluations. Refining vector techniques are used to refine relevant results efficiently and securely. Our index construction process ensures that stored data and trapdoors are kept private. Our system also efficiently supports multi-user authentication by avoiding the expensive traditional method, which enables data owners to define who can search for a specific image. Compared with other similarity-based encryption methods predicated upon searchability, the option presented in this study offers superior search speed and storage efficiency.
Keywords
Introduction
The need to conduct searches within extensive datasets using smart mobile devices has become increasingly vital in a number of different disciplines. 1 Practical applications that require this process include medical diagnosis, criminal identification, and Internet retail and advertising. In the case of third- and fourth-generation smart devices, users can connect rapidly to the Internet and easily relay, send, and acquire images while simultaneously collecting a number of images from various sources. However, the management and retention of these images make significant demands in terms of storage, its associated costs, and computing power. 1 Such facilities may be unavailable to all smartphone users, particularly those who use lightweight smart devices such as the iPhone.1,2
With the significant advances in cloud computing technologies, several companies, including Apple, Google, Microsoft, and Amazon, have adopted cloud computing technology to support users of smart devices with services such as mass storage and large-scale data management at an efficient cost.1,3 Despite the technical and economic benefits of cloud computing technology, transferring particularly vulnerable or important images to insecure cloud servers (CSs) presents difficulties in safeguarding the private images of users. 1 To prevent unsolicited access attempts, users generally encrypt such images prior to outsourcing them on a cloud. 1 However, this process presents a barrier when traditional encryption services are used and when searching for and through encrypted images. 1 In addition, despite the increasing computing power of smart devices, they are currently still unable to achieve the capacity of personal computers. 1
In recent years, a number of searchable encryption (SE) methodologies, which facilitate the selective retrieval of encrypted documents by means of keyword searches, have been developed.4–12 In such systems, a user has to send a secured keyword to look for specific encrypted text documents. Other modern informational retrieval systems have also introduced original technologies. For example, Google Goggles permits clients to send an image as a query and then search through the images in the database, where images with a comparable visual content are identified. 1 Original technological processes similar to this approach are referred to as content-based image retrieval (CBIR). Consequently, the development of an SE scheme that can manage image-based searches proficiently and precisely is necessary.
Most image matching (IM) approaches define an image representation and a distance metric that reduce the amount of data stored per image and the time cost of database search. Feature vectors (descriptors) of each image in the database are extracted and stored. During the matching, the descriptors of the query image are compared against their counterparts in the database to determine the most relevant image. However, keeping descriptors in their clear text may reveal information on some objects in the image. Thus, such descriptors should be encrypted in such a way that their distances are preserved without decryption.
In particular, attention has recently shifted to issues concerning privacy in the context of searching groups of encrypted images.1,13–18 These issues primarily focus on global features and are critically not lightweight. 1 Consequently, global feature-based CBIR techniques are unsuitable for smart portable applications and other instances where available computing power is comparatively low. 1 To our knowledge, the only local feature-based CBIR available thus far is the approach described in Abduljabbar et al. 1 and Xia et al. 19 In contrast with global feature approaches, local feature-based CBIR achieves enhanced accuracy in terms of retrieval but requires comparatively complex metrics related to distance, for example, earth mover’s distance (EMD). 1
Accordingly, a lightweight IM and retrieval scheme is required for applications that use IoT-cloud. Furthermore, preserving the privacy of images is among the most important of all security services provided by security applications and security systems. 20 Nevertheless, interest and the provision of security services are not imminent in smart mobile devices communicating in the IoT-cloud environment.
In summary, protecting the privacy of images during the matching process is necessary in some cases. The following example illustrates the importance of image security in the IoT-cloud real-time application. Imagine a security agency that has outsourced a number of sensitive images related to a potential terrorist suspect to CSs in accordance with its policy of fully utilizing the benefits of cloud technology. The security agency’s agents may wish to check whether images related to the suspect can be found in the databases of the CSs. In particular, such agents may use mostly restricted devices (smart devices) during the course of their work to remain mobile while attempting to identify and apprehend the suspect. For security reasons, however, neither the agency nor its agents want to reveal the images they hold and their queries to unauthorized entities, unless authorized agents need to access this information. One way to identify such a need is to detect similarities between the query of the agents (in the form of a bio-image) and the cloud database. When the need for matching is verified, the CS can send only similar images. In the process of identifying similar images, the security agency and its agents should not disclose the query image and the identity of the database. They should allow the latter to learn only of the existence of any commonality between images. Hence, the success of the security agency is depend on the efficiency and precision of the IM process.
To the best our knowledge, a lightweight and efficient scheme is yet to be developed for searching images over encrypted large-scale datasets through IoT-cloud with privacy-preserving when compared with other popular secure image search methodologies on powerful devices (laptops).
The contributions of this article are as follows. First, we shall address the question of how to search for and retrieve similar images between smart device users and CSs in a manner that preserves privacy without losing image confidentiality through lightweight multi-user authentication. 1 Second, distance metric techniques are designed to evaluate the plaintext data. In our method, we propose an efficient secure distance metric to achieve similarity comparison between encrypted vectors in the CS without revealing sensitive information. Third, our scheme will adopt local speeded-up robust feature (SURF)-based CBIR, which has the benefits of being lightweight, using the Euclidean distance, a well-known metric for scoring matching images and speeding up the search process. In addition, locality-sensitive hashing (LSH) is applied to achieve high search index efficiency and reducing storage requirements. The primary benefit of indexing in this approach is the accomplishment of similarity queries using as few distance evaluations as possible, in contrast with the alternative sequence-predicted searching of the entire index. Fourth, a simple solution for achieving secure matching shall be adopted using a trusted third party (TTP). For example, if Bob sends images (Bob’s collection) to the TTP and Alice sends a query I to the TTP, then the TTP shall subsequently assess the query and inform Alice whether the images she sought are located in Bob’s collection and are similar. In real-world scenarios, the identification of a totally trustworthy third party is a particular challenge, and our work does not require the involvement of a third party. Fifth, our proposed scheme manages the problem of similar image searching to achieve flexible searching. Finally, our scheme marks a considerable step toward the practical deployment of data hosting that preserves privacy in an IoT-cloud environment. 1
The remainder of this article is structured as follows. Section “Related works” presents a review of relevant literature. Section “Scheme overview” explicates the research problem and security exigencies. Section “Proposed scheme” describes the proposed scheme, while section “Scheme details” presents the scheme in detail and considers its preliminary concerns. Section “System evaluation” provides an analysis of security and presents the results of performance tests and investigations in relation to our scheme. Finally, section “Conclusion” makes recommendations for further research and draws the findings of our work with a summary and conclusion.
Related works
A number of authors have proposed different SE solutions based on text-based searches within the cloud environment. These processes imply that searching for encrypted data involves retrieving encrypted data in the form of text documents, where the owner of the data is allowed to outsource his or her data in a different server, and thus, provide it with the means to selectively recover a document through the use of a keyword-based search; consequently, data do not require decryption through searching.4–12 This process, which is based on searches for a single unique keyword, was initially suggested by Song et al. 4 However, this method does not facilitate similarity searching, although the search performed is characterized by precision. To enhance search efficiency and avoid scanning the whole document to search for a keyword, such as that in Song et al. 4 and Boneh et al., 5 the authors of Wang et al. 6 designed SE schemes based on various index constructions. Subsequently, SE schemes that use only a single keyword have been extended, such that these schemes can now work with multiple and conjunctive keywords.7–9 Through the aforementioned methods, these schemes have become more precise and flexible. However, such schemes may be unable to determine and recover typing errors within the data, which are common in real-life applications. To address this issue, several SE schemes that support fuzzy keyword searches have been suggested to manage any misspellings encountered within the search process.10–12
Although SE schemes that use keywords exhibit a number of interesting features, they remain unsuitable for use in secure image searches over decrypted datasets. Furthermore, they are limited to extant keyword sets, and keyword searching demands precise text descriptions of content that has already been made available. By contrast, no predefined search scope for use within a content-based image search is currently available.
Furthermore, the application of image-based searching has been undertaken within the context of encrypted image databases. The extraction of visual words from images, and the subsequent construction of indexes based on these visual words, was suggested by Lu et al., 13 who utilized a series of cryptographic approaches, such as order-preserving encryption (OPE), to achieve this objective. 21 Moreover, randomized hash functions are used to increase privacy protection and rank-ordered capability. Undoubtedly, large amounts of data can be leaked to an untrusted server via OPE, which may result in successful attacks. In addition, this scheme is applicable only to bag-of-features (BOF) image search, which exhibits an inferior search precision of up to 20% compared with the image search algorithms based on Fisher’s vector.7,22,23 By contrast, the empirical test results show that the scheme proposed in our work does not leak any data to untrusted servers.
Through the use of homomorphic encryption, other researchers have proposed an alternative secure BOF technique based on an image search scheme that applies superior security. 15 However, the efficiency of this scheme is significantly reduced as observed when Lu et al. 15 is compared with Lu et al. 13 A privacy-preserving image search engine scheme, along with the use of homomorphic encryption, was proposed by Abduljabbar et al. 1 and Hsu et al. 14 Although this scheme achieved high accuracy in recognizing images, it was two to four orders of magnitude more expensive than other schemes and demanded the regular involvement of the user throughout the searching process. 1
Other works have described the use of image feature protection in the areas of bit plane randomization, random projection, and randomized unary encoding.1,16 Features subjected to encryption using bit plane randomization and randomized unary encoding can be used to calculate Hamming distance within the encryption domain. 1 Meanwhile, features subjected to encryption using random projection can be used to calculate L1 distance within the encryption domain. Cheng et al. 17 developed a CBIR system that applied bit plane randomization and random projection similar to that adopted in Lu et al. 16 Ferreira et al. 18 suggested an image encryption approach that would be compatible with privacy-preserving image retrieval that encrypts colors by means of a deterministic algorithm that supports the retrieval of images that is contingent upon content. 1 In this instance, the details of texture are encrypted with a probabilistic algorithm to enhance security. The searchable index may then be developed using the details of the encrypted colors.
The aforementioned privacy-preserving CBIR methods are primarily predicated upon global feature-based techniques that are not lightweight, 1 and consequently, are incompatible with devices with comparatively low computational power such as smart devices. Compared with global feature-based CBIR, local feature-based CBIR characteristically acquires more accurate results. 1 However, locally based options require complex distance metrics, such as those that involve EMD. 1 We believe that the only currently available technique that supports local feature-based CBIR is the one proposed by Abduljabbar et al. 1 and Xia et al. 19 These authors essentially posited a CBIR scheme that maintains privacy and facilitates the outsourcing of an image database and CBIR service to the cloud by the data owner without disclosing the images stored in the database to the CS. 1 Scale-invariant feature transform (SIFT) and clustering algorithms are used to determine features that represent images, whereas EMD applied an evaluation process that assessed the similarity of images. Xia et al. 19 asserted that this approach is notable for its efficiency. 1 However, SIFT, clustering algorithms, and EMD are costly in terms of processing speed, and yet, they exhibit minimal efficiency in this respect. 1 This issue is further discussed in section “System evaluation.”
In this article, we present a practically achievable methodology where CBIR cloud outsourcing via IoT may be accomplished while maintaining privacy. The methodology is compatible with devices with low computing power such as smart devices. In addition, we use CBIR that is contingent on local feature SURF with appealing lightweight aspects through the use of the Euclidean distance, which is a well-known metric for scoring matching images. 1 In practical terms, this metric is based on secure matrix multiplication and randomization to protect the confidentiality of descriptors and to evaluate the similarity of images. 1 We use this method because of its efficiency and because it does not require massive encryption operations. LSH is also applied to enhance searching efficiency. This article reports the results of the empirical research using actual collections of images to establish the veracity of the claims made in our scheme.
Scheme overview
Notations
DB and DV: large-scale image database and dictionary of feature vectors, respectively 1
kdata: secret key used in encrypting and decrypting images
SDV and C: secure dictionary of the feature vectors and ciphertext, respectively, of a large-scale image database
BID and Bcon: bucket identifier and bucket content, respectively
QSV: refining vector of query image
Problem definition
Assume that the data owner DO (Bob) possesses a large-scale database
The CS is prevented from acquiring useful information regarding the outsourced data due to its encryption. However, this does not include DO, which is allowed to leak.
1
The encrypted data index should facilitate a search through it within an acceptable period before returning items that are most similar to those requested by the user.
1
To search a remotely stored image database DB with an image query

Proposed scheme.
Security definition
To facilitate the achievement of practical solutions, all presented SE scheme definitions allow the revelation of certain important information to the adversary server. 1 Such information includes access patterns (relevant images’ identifiers) and searching patterns (i.e. the extent to which queries have been repeated). 1 Our proposed scheme enhances security by not allowing the CS to acquire the access pattern. We present the required enhanced security features that should characterize our proposed SE scheme as follows: 1
Image security: The proposed encryption scheme should not leak any data that pertain to the stored images, except for their numbers and image
Trapdoor security: Without learning the secret key, the CS should be unable to generate a valid trapdoor. 1
Index security: The secure index should not leak any data regarding its contents. 1
Access pattern: The association between the search index and its corresponding image identifiers should remain unknown to the CS. 1
Our scheme uses a symmetric key SE to scale efficiency for large datasets. The “honest-but-curious” server is focused upon by the proposed scheme to maintain the majority of existing SE schemes. 1 On the basis of this assumption, the CS is operating honestly and the designed protocol specification is adhered to correctly. 1 Nevertheless, the server shall remain “curious” when inferring and assessing message-flow collected throughout the protocol, such that additional information can be acquired and retained. 1
Proposed scheme
In this section, we describe the design framework of our privacy-preserving CBIR scheme. A collection of seven polynomial-time algorithms constitutes the index-based SE schemes, that is,

Technical details of the proposed method.
The various notations function as follows in the configuration stage:
The various notations function as follows in the secure image retrieval stage:
The index-based
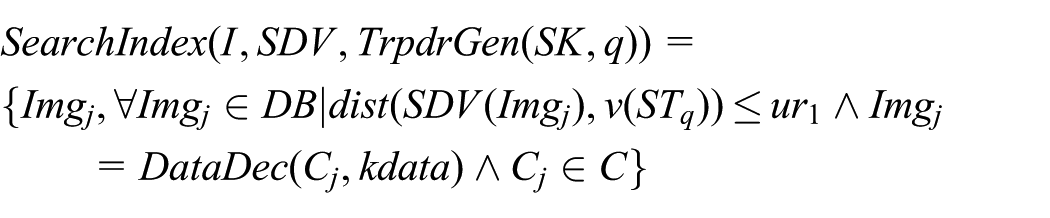
Scheme details
In this section, we explain the details of the proposed lightweight privacy-preserving CBIR scheme. 1 We will improve our scheme building in section “Multi-user authentication” to further provide a fine-grained multi-user authentication property for searching an image.
Configuration stage
The scheme is initiated by the data owner (DO) when calling
Generation of vector features
Before the feature indexing process is described, the method used to accomplish image collection feature vector extraction is summarized in this section.
In our scheme, we utilize the local feature SURF algorithm,24,25 which is a novel scale and rotation-invariant detector and descriptor.
1
SURF approximates, or even outperforms, the previously proposed patented SIFT algorithm1,26,27 with respect to repeatability, distinctiveness, and robustness, but it can be computed and compared much faster. In general, SURF extracts the feature vectors of the provided image as follows. First, SURF selects several interest points at distinctive locations in the image, such as corners, blobs, and T-junctions. These points are selected in such a way that enables the detector to find the same physical interest points under different viewing conditions. Subsequently, the neighborhood of each interest point is represented by a feature vector. This descriptor has to be distinctive and robust to noise, detection displacements, and geometric and photometric deformations. The descriptor vectors are matched among different images. Matching is based on the distance between vectors, for example, Euclidean distance or cosine similarity. Formally, given the images

SURF interest points in two images.
Feature indexing
The data owner then runs the algorithm
Building the LSH index
As an efficient algorithm for near-neighbor search within high-dimensional spaces,27,28 the core concept of LSH is to “hash” items more than once in a manner that ensures that more similar items will have a greater chance of being hashed together and placed in the same bucket compared with dissimilar items.
1
To achieve this objective, LSH utilizes a series of hash functions to map items into a number of buckets, and thus, the chance of similar items sharing a single bucket is high.
1
Assume the real d-dimensional point metric spatial value
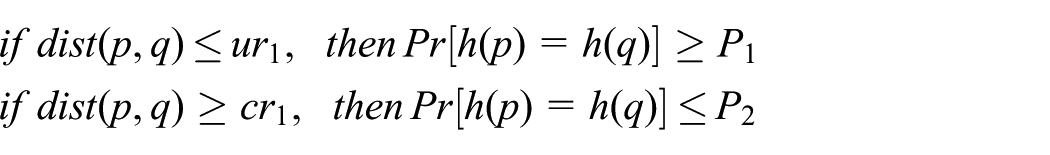
Interestingly, LSH can be utilized in a similarity search assuming

where <.> is the dot product,
In addition, the hash family
Furthermore,

and

In this case, the number of indexed points is

LSH index protection
The number of buckets and the contents of each bucket are revealed to the CS through the LSH index.
1
Such leakages may be potentially utilized by the CS to construct the whole image by inference. Therefore, the encryption of the LSH index should be completed before it is transferred to the CS.
1
In such situation, only the
Bucket identifier protection:
Bucket content protection:
Hash table protection:
Dictionary encryption
In addition to the secure index, the dictionary DV of the feature vectors is outsourced to prune the candidate list. Notably, the additional bytes of the stored data do not present a significant problem due to the low cost of storage that characterizes CSs.
1
Nevertheless, the transfer of feature vectors in plaintext format to a CS can disclose private information.
1
The best approach to ensure data security is through encryption, although the traditional schemes used for this purpose are unable to provide the means to assess the distance function over the data to be encrypted.
1
To resolve this issue, we utilize the secure Euclidean distance to calculate the distances between the stored dictionary vectors and the query without knowing the contents of the dictionary or the query.
1
This approach enables the execution of the relevant Euclidean distance function with regard to all the encrypted vectors without necessitating decryption.
1
Furthermore, an illustrative example is presented as follows.
1
Assume that

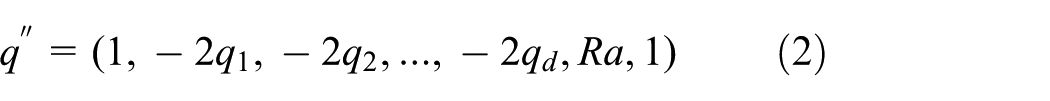
All these points are then encrypted; thus


The exact distance between the encrypted vectors is explained by Theorem 1.
Proof of Theorem 1
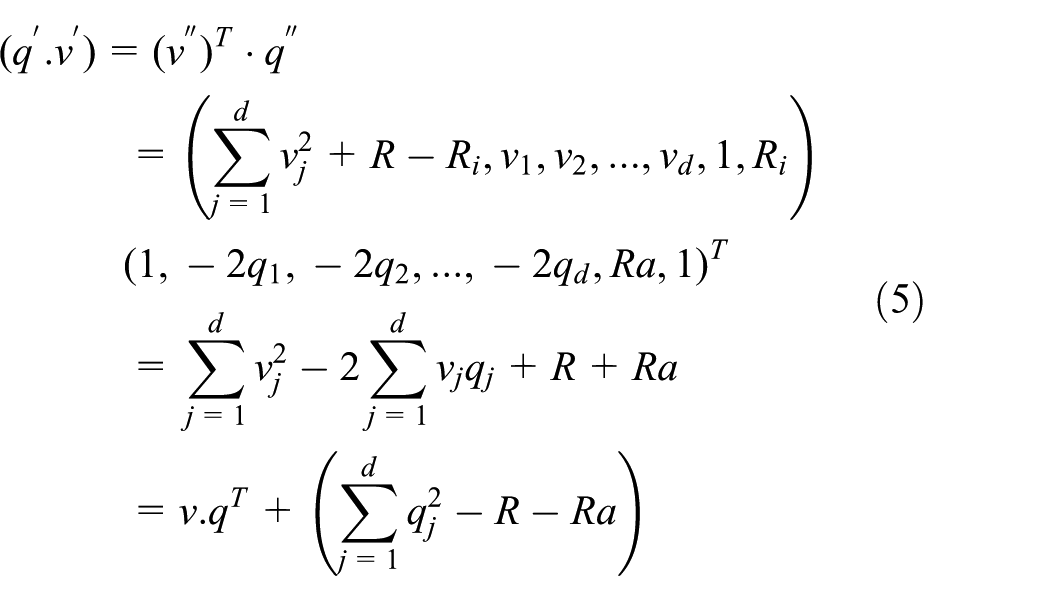
Therefore, the Euclidean distance will be equivalent to
Database encryption
The algorithm

Encryption results obtained using AES on the image “Lena.” The original image is on the left, whereas the encrypted image is on the right.
Secure retrieval stage
After outsourcing the secured
Secure search and retrieval
Trapdoor
Image decryption
After receiving the set of top-t encrypted images, the algorithm
Multi-user authentication
In this section, we enhance our scheme construction to efficiently support multi-user authentication. The
Upon receiving a search request from a user, the
Discussion
Security measures that are common in the majority of computing scenarios are unsuitable for smart IoT-cloud-mediated devices. The lightweight approach to image search and acquisition posited in our work is suitable for CS secure image applications where directly dishonest behavior is not a feature, but curiosity may be an issue. The lightweight approach described in this article involves secure index construction and image search that are compatible with smart devices that operate within the IoT-cloud. Query submission is also characterized by security. This approach represents a new means by which images may be securely transmitted in the IoT-cloud scenario. The benefits of lightweight encrypted image search include compatibility with smart portable devices that characteristically lack high-level computing power. The method posited here can prevent queries and image database contents from becoming known to the CS, as described in the security considerations in the previous subsection of this article, namely, those concerning LSH index protection, dictionary encryption, database encryption, and search and retrieval. Of equal relevance in this respect are issues considered in the following subsection of this article, namely, those concerning security analysis. On the basis of these conditions, the lightweight approach is asserted to have the potential to address security needs related to communication between smart devices and the CS, as well as secure image acquisition.
System evaluation
Security analysis
Our scheme posits that the encrypted database, secure searchable index, encrypted query, and encrypted dictionary will not disclose information to the CS. The assertion that the image database will be rendered secure through
Security of dictionary
The feature vectors that pertain to the dictionary are similarly secured through the randomization and permutation protocols described in section “Building the LSH index.”
1
To quantify the amount of information that is leaked to the CS from a secure dictionary

where

and

where
Search unlinkability
In our designed method, each search query
Experimental evaluation
This subsection describes the experiments used to assess and evaluate our proposed scheme. The symbols used in this subsection are explained in Table 1. We report the experimental results of the proposed scheme on a real-image database that contains 1000 images from the Corel dataset,
32
all of which are in a colored format. Image sizes are either
Symbols used in the experiments.

Efficiency
LSH index
In this subsection, the efficiency of the LSH index is analyzed to identify the means to improve search speed. The LSH index and the linear scan index are comparatively appraised using a brute force approach to discern the closest similarities in image queries. 1 Figure 5 illustrates that the index posited in this work achieves superior speed compared with that achieved by the scan index. As shown in Figure 5, the time consumed in searching the LSH index is short, even when the number of queries increases. 1 On one hand, LSH uses various hash functions to assign images to the appropriate buckets. Through this action, the likelihood that similar images will be assigned to the same bucket is enhanced. 1 On the other hand, our experiments evaluate the approximate distance of the candidate list, which has been found to be considerably smaller than the overall number of stored images.

Linear scan and LSH index.
Index generation
We extract SURF local features to represent images.
1
This extraction process is conceptualized as the process that precedes the creation of the index. Index creation will then be primarily consisted of LSH calculation.
1
Feature extraction is a considerably slower process than index construction.
1
These speeds are of particular relevance to data owners; however, they are one-time functions that take place prior to the outsourcing of data and are, therefore, affordable for the data owner.
1
Apart from analyzing the aspect of speed, the need for index storage capacity is considered.
1
This requirement has also been determined as not being unacceptably onerous for the CS. Time consumption issues that concerned feature extraction and index construction, as well as the index storage capacity issue, are presented in Table 2. In this respect, comparisons are drawn with the data recorded in Xia et al.
19
The required index storage capacity exhibited in Table 2 compares the results obtained from the method proposed in our work and those achieved in Xia et al.
19
Compared with the performance in Shafagh et al.,
20
the method posited in our scheme reduces the required storage capacity. This result can be attributed to the LSH index, which is built based on feature vectors.
1
In addition, our work uses the SURF method, which produces fewer local features24,25 compared with the SIFT method used in Abduljabbar et al.
1
and Xia et al.
19
The storage cost of our indexes represents the
Indexing performance.
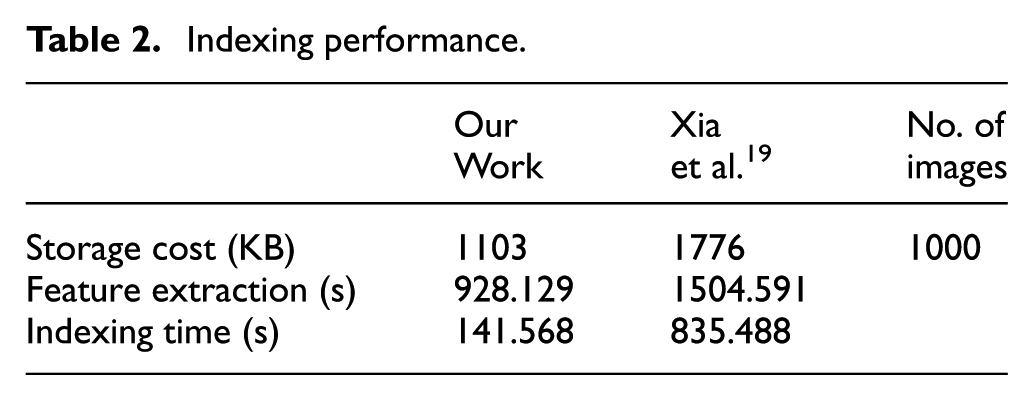
Table 2 illustrates the superiority of our work in terms of index construction time compared with that in Xia et al. 19 In the scheme described in Xia et al., 19 SIFT extraction and clustering precede index creation. Thereafter, the index is created using methods that involve the creation of a signature and the computation of the centroid and hash elements. In our scheme, SURF feature extraction precedes index creation. 1 Then, LSH generally consumes the time used in our scheme to construct its searching index. 1 Our scheme exhibits superior index construction time compared with that in Xia et al. 19 because it does not use time-consuming clustering and signature creation processes. 1 In addition, the need for centroid computation is precluded. Clustering becomes unnecessary because the time taken to complete the search index is extremely short, such that it is negligible when increasing query numbers, as shown in Figure 5.
Trapdoor construction
This subsection examines the performance of the trapdoor creation process in our scheme. Particular attention is given to the time required to create the trapdoor and the involved data traffic cost. For each query, trapdoor construction time consists of feature extraction,
Our scheme generates the trapdoor as two vectors: the vector of buckets (keyword set) and the refining vector
Time of search operation
When queries are submitted to the scheme presented in this work, CS speed includes the time taken to accomplish index searching (Figure 5) to generate the candidate list and the time cost of the approach based on the secure Euclidean distance.
1
This approach facilitates the efficient calculation of the Euclidean distance with respect to all the encrypted vectors without requiring decryption.
1
In particular, the CS calculates the Euclidean distance between the refining vector
As shown in Table 3, the CS in our scheme takes less time to process queries than that in Abduljabbar et al. 1 and Xia et al. 19 In particular, the secure Euclidean distance metric is significantly faster than the EMD distance metric used in Abduljabbar et al. 1 and Xia et al. 19 Unlike the EMD method, our distance metric method does not require excessive time-consuming operations (equation (5)). 1 Evidently, the distance metric operation is of greater significance compared with index searching. 1 This operation takes over 95% of the total time consumed in the query process, whereas the remaining time percentage, which is low and semi-stable, is dedicated to searching the index (Figure 5). 1 EMD has the disadvantage of producing time complexity that is proportional to image group cardinality. This disadvantage will be impractical in view of the number of images typically handled in the considered scenarios. On the user side, speed is partly determined by the time taken to generate the trapdoor. 1 Table 3 shows how the proposed scheme performs significantly better in terms of query user generation time than the scheme in Abduljabbar et al. 1 and Xia et al. 19 For our scheme and that presented in Xia et al., 19 the same settings were used to create the secure LSH index for trapdoor generation. 1
Times processing per trapdoor query.

Retrieval evaluation
Precision
Precision–recall curves are utilized to evaluate retrieval performance. In our scheme, the precision and recall of the image query q are defined as

where

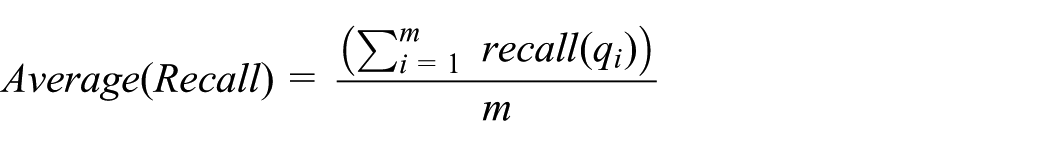
After a query has been issued, the retired images are ranked according to their distance. Subsequently, the images with top

Evaluation of image retrieval.
Effectiveness
In testing the retrieval of similar images, the effectiveness of our proposed scheme is appraised with respect to its efficacy in retrieving the most similar images to the trapdoor queries. Figure 7 presents samples of our results. The first column shows the provided image trapdoor queries. The remaining columns show the returned images arranged according to their similarity to the corresponding query. As shown in the figure, our scheme typically retrieves images that are in the same category as the query image.

Selected results of retrieved images.
Protection against adversaries
To protect stored images from adversaries, a user applies the trapdoor algorithm

Effect of private key on secured image matching.
Impact of the LSH index parameters
In this subsection, we assess the performance efficacy of the proposed index. The impacts of the LSH index parameters (
Number of hash functions
The impact of altering the value of

Effect of
Number of hash tables
The effects of adjustments on L are illustrated in Figure 10. As predicted, indexing time increases as the value of

Effect of
LSH distribution
The impact of the value of

LSH bucket distribution.
Conclusion
In this article, we intended to resolve the issue of supporting proficient CBIR for smart devices in IoT-cloud computing systems using encrypted data. 1 In addition, we designed a lightweight multi-user authentication property to allow the users of authorized smart devices to flexibly search for each image without influencing the searchable index tree. In this context, the preservation of privacy when outsourcing data are crucial and must be achieved without reducing functionality. 1 LSH, which is a commonly used process, is applied to achieve expedient similarity searches in high-dimensional spaces related to plain data. 1 The LSH secured index scheme is propounded by our scheme in producing a more efficacious search time in the context of encrypted data. 1 We designed a simple cryptographic primitive to protect the feature vectors and their corresponding indexes while enabling the CS to measure the similarity of the encrypted vectors without the need for a third party. 1 The similarity search is separated into two stages in our scheme. 1 First, a secure trapdoor is used to establish a candidate list. 1 Then, the candidate list is refined using a vector designed for such purpose, which also identifies the images with the most similarity. 1 The results of the security analysis and experiments demonstrate the superior security and efficiency of our proposed scheme.
The research described in this article will be continued. In the future, we will have opportunities to focus on questions regarding the ranking of images that are searched for within an encrypted image scenario. Among the proposed research opportunities, the most productive is likely to involve the extraction of features on the CS to reduce demands placed on smart device users and DOs. The initialization of the bag-of-words approach to generate visual words from feature vectors also has potential. The inverted index 33 or min hash 34 data structures may be used to develop expedient visual feature search techniques.
Footnotes
Acknowledgements
This article is an extended version of our paper entitled “Privacy-preserving image retrieval in IoT-cloud” that is published in the 15th IEEE International Conference on Trust, Security and Privacy in Computing and Communications (IEEE TrustCom’16), Tianjin, China, 23–26 August 2016.
Handling Editor: Geng Yang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Natural Science Foundation of Hubei Province under grant no. 2016CFB541 and the Applied Basic Research Program of Wuhan Science and Technology Bureau under grant no. 2016010101010003.