
Abstract
Traffic prediction in smart cities is an essential way for intelligent transportation system. The objective of this article is designing and implementing a traffic prediction scheme which can forecast the traffic flow with high efficiency and accuracy in Hong Kong. One problem in traffic prediction is how to balance the importance of historical traffic data and real-time traffic data. To make use of the real-time data as well as the history records, our ideas are combining data-driven approaches with model-driven approaches. First, the limitations of two baseline approaches auto-regressive integrated moving average and periodical moving average model are discussed. Second, artificial neural network is applied in the hybrid prediction model to balance between the two models. The training of neural network enables the artificial neural network to weight between real-time traffic data and traffic patterns revealed by historical traffic data. Furthermore, an emergency strategy using the Bayesian network is added to the prediction scheme to handle with the traffic accident or other emergent situation. The emergency prediction strategy on unexpected traffic situation considers the traffic condition of nearby links to predict the speed change on the link. Finally, experimental results of short-term and long-term predictions demonstrate the efficiency and accuracy of the proposed scheme.
Introduction
Nowadays, the large number of vehicles has caused a serious traffic congestion problem in modern city and deeply affects our daily life. Traffic congestion results in low throughput, excess delays, less safety insurance, and so on. The growing number of vehicles on streets increased the air pollution that emits greenhouse gases such as carbon dioxide. Furthermore, idling vehicles caused by traffic jams will waste more fuel and produce more pollution. With the rapid development of transportation systems, traffic has become a vital part of human life; its vulnerability significantly influenced the quality of life such as Hong Kong. All these situations remind us the importance of traffic management, with which to optimize the traffic stream and public traffic choices of citizens in smart cities.
One way to solve this problem is making smarter going-out strategy. To diminish the influence of bad traffic condition, the way of monitoring and analysis of traffic state needs to be more effective. Traffic prediction provides tools for improved road traffic management by allowing the reduction of delays, incidents and other unexpected events. 1
The objective of this article is designing and implementing a traffic prediction scheme which can forecast the traffic flow with high efficiency and accuracy in Hong Kong. Not only to simply demonstrate the primary data showing basic traffic status, but also make one more step on analysis of further data. To make use of the real-time data as well as the history records, our ideas are combining data-driven algorithms with model-driven approaches. In this article, its ideology to use the big data is focus on prediction of traffic stream, modeling with the large amount of traffic information and implementing the model in further forecast on real-time situation.
The traffic prediction received considerations from different fields, because of its essentialness in traffic engineering and its theoretical difficulties. 2 Quantities of the literatures are about the short-term prediction models. Two main approaches of road traffic prediction are model-driven (e.g. auto-regressive integrated moving average (ARIMA) model) and data-driven (e.g. periodical moving average (PMA) model).3–5 Different approaches provide traffic managers with varying but valuable information, forming different prediction models.
In this article, a hybrid prediction scheme is introduced to avoid the limitations of two baseline approaches ARIMA and PMA. Artificial neural network (ANN) is applied in the hybrid prediction model to balance between these two models. The training of neural network enables the ANN to weight between real-time traffic data and traffic patterns revealed by historical traffic data. Furthermore, an emergency strategy is added to the prediction scheme to handle with the traffic accident or other emergent situation using Bayesian network (BN). It is an important attempt in developing smart cities with the efforts of this new hybrid scheme working on forecasting the traffic conditions.
The related works are discussed in section “Related works.” Then, the problem definition and system model are introduced in section “Baseline models and their limitations.” In section “Hybrid prediction scheme,” we analyze limitations of different baseline prediction models. In section “Prediction with emergency strategy,” we give a detailed view of the hybrid prediction model and emergency strategy. The simulation parameters and results compared to the proposed scheme are showed in section “Simulation and results.” Finally, section “Conclusion” concludes this article and points the future work direction.
Related works
Past decades, machine learning, statistics, and deep learning methods have been demonstrated in traffic prediction simulations. Important ideas are auto-regression, 6 neural networks, 7 BN, 8 and some pre-processing techniques like smoothing.9,10 Works in Liu et al. 11 and Miller and Gupta 12 show the approaches for using traffic datasets to predict traffic congestion, which provides information for drivers to avoid areas with heavy traffic. These prediction results can be benefit to many parts of the civil life, and even to government on traffic policies managing. Other applications about traffic such as traffic light control algorithms 13 and online traffic prediction 14 are also serving for this reason.
Spatiotemporal prediction takes both time and space into consideration when doing prediction, forecasting the traffic as a whole network. A stacked auto-encoders (SAE) 15 model is a way to apply deep learning on traffic prediction. Pre-processing technology, such as singular spectrum analysis (SSA), 16 is also important part in traffic prediction which can help have a deeper understanding on this field.
One typical usage of auto-regression idea is ARIMA, 17 which is widely applied in researches to predict the short-term traffic conditions. The model integrates the moving average parts with auto-regressive computation steps. Box–Jenkins methodology offers main steps for applying ARIMA models in forecasting.
Neural networks contain many different ideas such as ANN18,19 and fuzzy neural networks (fuzzy NNs).20,21 Neural networks are a computational model which imitates the behavior of biological brain. The model comprises a large amount of artificial neural units, connected with many others to formulate the way of information commute in biological neural networks. Since the neural networks in computer science may confuse the idea with biological ones, it is often called ANN. Neural network is widely used in prediction of traffic. Its multiple hidden layer editions are important basics of deep learning technology. Hidden layers give traffic prediction ability to handle with complicate traffic situations. Researchers implement different kinds of ANNs in predictions, not only in forecasting the traffic conditions, but also in varieties of fields which require more enhanced prediction models to achieve better results.
BN is popular nowadays in many ways. It enables prediction of traffic to consider multiple inputs of data when forecasting, in which the speed information of nearby related links lead to important approach for prediction. Its application can vary in many formations.8,22 Inputs in BN sometimes may show less relativity than that of neural network. This specific characteristic offers BN more possibilities in the usage of combining different factors in prediction.
It is apparently revealed by researchers that no single model is good enough in every traffic situation. Researchers try to combine the predictions of different models to get better performance in forecasting. Those works show that prediction results of such hybrid models (HMs) yield higher prediction accuracy than that of single models,23,24 providing evidences to the conclusion. Zhang’ work 25 shows that neither the ARIMA model nor neural network models alone can predict time series in best way. None is adequate because the ARIMA model is not useful in nonlinear relationships and NN is not efficient in handling multiple traffic patterns.
One problem in traffic prediction is how to balance the importance of historical traffic data and real-time traffic data. We all understand that traffic situations are varying over time, making the traffic status dynamic in changing. However, there are also traffic patterns which give information of traffic trends based on historical data. In Pan et al. 18 it is shown that combination of models that selects prediction results in real time between an ARIMA model and a historical average model (HAM) generates better prediction accuracy, because of their different performances on short-term and long-term prediction. It is also considered in this article.
Baseline models and their limitations
In this section, first, we describe traffic prediction problem. ARIMA and PMA are two individual sub-models comprising the baseline approaches in our hybrid prediction scheme. We will introduce them in this part and then we will discuss the limitations of these two baselines to show why our hybrid prediction model is needed to enhance the prediction performance. The speed information data were collected in 5-min periods. They were aggregated into 30 min periods in some cases of the simulation.
Problem definition
There are a set of links referring to different road segments comprising n speed detectors, which is one-one mapped to link IDs. At certain time interval t, each detector provides the speed information v[t] (in our data, the interval is 5 min on Salisbury Road, Kowloon, Hong Kong). So we can describe the speed forecasting problem as follows:
Definition
There are a set of speed information observed by the detectors,
Baseline models
ARIMA
The basic model is ARIMA(p, q), given the time series data

Sometimes it can be simply described as

where B is the backward shift operator, which means
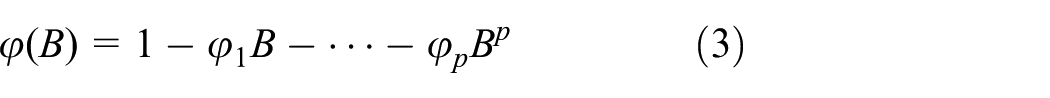
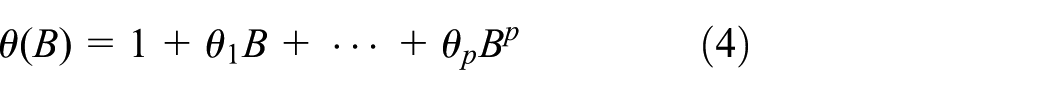
Using the B operator, we can describe the differencing as (1 – B). The ARIMA(p, d, q), with polynomial factorization is given by

where d denotes the order of differencing.
In 70s last century, Box et al. 26 developed a practical approach to generate the ARIMA models, which is widely used now. This approach makes ARIMA a popular and fundamental way to do the time series forecasting and analysis. The Box–Jenkins methodology describes three iterative steps for the forecasting. First, judge the time series to be whether stationary or not. A suitable degree d of differencing will be applied when the data are not stationary to transform the series. Second, ranks p and q are determined by checking the autocorrelation function (ACF) and partial autocorrelation function (PACF) of the transformed time series. Finally, with the chosen p, d, q, the AR and MA terms are estimated using different evaluation models.
PMA model
Through a rigorous research on real-world traffic data, we can find out the traffic pattern where the historical traffic situation usually shows a periodical correlation between temporally traffic data. The most significant rules the historical data seems to follow bring to us the influence of daily and weekly period. For instance, the traffic status of a certain link on Friday afternoon 5:30 pm can be estimated based on the average of previous speed information at the same time of Friday. This periodical influence gives us idea to introduce the PMA model, which uses the average of previous speed information on the same time of the same location to make the prediction on future traffic condition
The PMA can be described as

where
Performances limitations of baselines models
When doing the forecasting, both ARIMA model and PMA models can give a good prediction result. However, here we are going to explain the limitations of both baseline approaches, with the research on real-world traffic data. The cases provide various view angles for both models, showing their advantages and disadvantages in different situations.
Cases of prediction horizon
In this case study, a comparison between ARIMA and PMA is carried out on different prediction horizon (PH); the accuracy of both models will be compared to show the effect of PH. Note that the interval of PH is set to 5 min, which means
The presumption is that ARIMA relies more on recent traffic data, which may have a better performance on short-term forecasting. The differencing of time series data would become useless when the data range is too large to remain any stationary characters. On the other side, PMA uses historical traffic data to follow the traffic pattern, the accuracy of which may not show any tremendous change when the PH varies in a small range.
In Figure 1, mean absolute percentage error is used to judge the accuracy of prediction, which is computed as follows

where

Performance on different prediction horizons.
From the figure, we can find out that ARIMA yields better short-term forecasting than that of PMA, especially when the horizon satisfying
Limitation 1
The prediction accuracy of ARIMA has a descent trends when the PH increases, which is a sign that ARIMA is not suitable for long-term prediction. However, PMA would not be influenced by the PH, but is not able to yield a relatively high accuracy in short-term prediction, which is important part in traffic forecasting.
Cases of rush hour boundaries
In this case study, rush hour boundaries are specifically chosen to examine the prediction accuracy of both models. The particularity of this time range is that real-time traffic forecasting may have some latency in prediction when facing to the rush hour boundaries.
The presumption is that, ARIMA, though thought to be have better performance in short-term prediction, may show a latency when forecasting the speed near the rush hour boundary, which is because the speed change at the boundaries is sudden and unexpected, and no trends before it happens can indicate the change. However, as the historical traffic data reveal the pattern and periodical rules of traffic condition, PMA may have a better prediction accuracy. What makes PMA have more advantages is that time series data can hardly show stationary characteristics when a sudden change happens.
In this simulation, the PH is fixed to 30 min. The simulation results are depicted in Figure 2, from which we can find out that in the beginning of morning rush hour boundary, the PMA model’s prediction result catch up with change of real-world traffic data, while the ARIMA shows apparent latency in forecasting result. Similarly, at the ending of the rush hour, ARIMA predicts the speed with a latency as well, when the PMA successfully forecast the after-congestion speed. Therefore, PMA yields better prediction performance at the rush hour boundaries.

Performance on rush hour boundaries.
The limitation is concluded as follows.
Limitation 2
ARIMA has a latency when making traffic prediction on rush hour boundaries. However, PMA shows higher efficiency and accuracy when forecasting at this special time range.
Hybrid prediction scheme
As we discussed before, ARIMA and PMA models are limited in different traffic situations. In this section, we propose hybrid prediction scheme based on a novel hybrid model (HM) that combines the advantages in these two prediction models. The HM dynamically adjusts between the prediction results of both models and makes the final prediction to be more flexible. After the hybrid system model is introduced, we shall give two algorithms respectively for training ANN in HM and traffic flow prediction.
The HM
Figure 3 shows the architecture of our HM, using prediction results of ARIMA and PMA, balanced by ANN to achieve the best prediction performance, with combination of real-time data and historical data. The emergency strategy for accidents in nowadays traffic is discussed as well, in next section.

Architecture of hybrid prediction scheme.
When forecasting with ARIMA, real-time traffic data are utilized; the time series

As a contrast, historical traffic data with certain day in a week and time in a day are considered in prediction using PMA model. Time series

Moreover, PH and the time when the forecasting needs to be applied also influence the prediction performance of different prediction models. In our hybrid scheme, these factors are all considered to achieve higher prediction accuracy. After adding the current time t and PH h to the inputs layer of ANN, both factors are considered when forecasting the traffic status.
As a result, the learning process of ANN is just the process of considering the influence of these factors by weighting the parameters in gradient descent. A set of historical traffic data are used as training data set to train the parameters of ANN, which help learn the traffic pattern.
ANN
We have discussed about the limitations of ARIMA and PMA models in last section, the main factors affecting the prediction accuracy of both models are PH and the status whether the prediction happens on rush hour boundaries. To some degree, we can conclude that ARIMA provides better performance based on real-time traffic data while PMA does more works on historical traffic data.
In our hybrid prediction model, we are trying to use ANN to help balance the weight of real-time data and historical data when our prediction model forecasts the traffic flow.
As shown in Figure 4, the ANN model maps the four inputs to the output speed as prediction result. Considering the three-layer neural network, the number of input layer is determined by the dimensionality of our data, which is 4. Where the inputs

The ANN architecture in out hybrid scheme.
Here, h and t are key inputs in this ANN prediction model. As we discussed before, the performance on different PHs shows limitation of ARIMA and PMA. However, these two prediction models could yield excellent results when considering appropriate PH, which makes h an important factor affecting the prediction accuracy. Meanwhile, the performance on rush hour boundaries shows the importance of the prediction time. ANN is a significant part in this hybrid prediction model, since it balances the influence of prediction time and horizon.
We need to decide the activation function and the size of hidden layer to build the ANN, which will be discussed in next chapter in detail. Then, the most important step before we predict the traffic flow is to train the ANN model. The following algorithm depicts the works in training the ANN in our hybrid prediction model.
In Algorithm 1, at first, we initialize the ANN parameters with random seeds. Note that the dimension of parameters is decided by the dimension of input layer, hidden layer, and output layer, which is shown in the algorithm. In the first for circulation, we forecast the traffic condition using both ARIMA and PMA models, with different horizon h. The results of first for, prediction results of both models, are sent to the second for circulation as the inputs of our neural network model, together with current time and horizon. The ANN model is trained comparing the prediction results of neural network with the real-world traffic data. Loss function is calculated and backpropagation algorithm is applied to learn the parameters. Trained model is returned at the end of Algorithm 1.

In Algorithm 2, ARIMA and PMA models are used to predict and generate the first step prediction results. Then, the results, as well as the current time, PHs, are regarded as the inputs of the second step forecasting to produce the final results of our HM. Loss or accuracy is calculated after the prediction for a judgment on this prediction model. The robustness of this model will be discussed compared to the baseline approaches and some widely used prediction models in section “Simulation and results.”

Prediction with emergency strategy
The hybrid scheme combines the ARIMA and PMA models to break the limits of them, therefore yields better prediction performance on forecasting the traffic condition in different time ranges. However, there may be accidents in nowadays traffic, especially when the number of cars on roads becomes larger and larger. The accident, in some way, causes unexpected speed change in traffic, which cannot be predicted by the historical traffic pattern or recent traffic speed information. Here we introduce the emergency strategy (ES) of our scheme, which considers the traffic condition of nearby links to predict the sudden speed change on the link we are discussing.
The emergency strategy is based on BN in Figure 5. In our BN model, the most important edges are the edges from the neighbor links to the link which we carried out our prediction model on. There are links directly points to the road, and links the road points to, which will be considered in different situations. What makes the model different from the HM is that when a link nearby the simulation road happens an accident, the speed of vehicles on this road may not show any change until the influence of nearby links eventually come into effect. The emergency strategy here is to avoid the latency when forecasting the traffic condition, trying to react before undetectable influence of accident finally show up its strength.

Bayesian network in our hybrid model.
We suppose the speed at time
After adding the BN model, the prediction steps become to be like Algorithm 3.

In Algorithm 3, there is a check step before the prediction of hybrid ARIMA. If the current speed of neighbor links shows abnormal features, the emergency strategy would be called; as a result, the BN model will be applied to forecast the traffic status instead of our hybrid ARIMA model.
Simulation and results
Study area
The traffic data set used in this simulation experiment contains speed information collected from 10 February 2017 to 15 March 2017 on Salisbury Road, Kowloon, Hong Kong, China. The speed information was collected in 5-min periods. They were aggregated into 30-min periods in some cases of the simulation.
Fitness measurements
Two approaches are used in this simulation for measurements of the fitness. The mean absolute percent error (MAPE) is calculated as

The root mean square error (RMSE) is calculated as
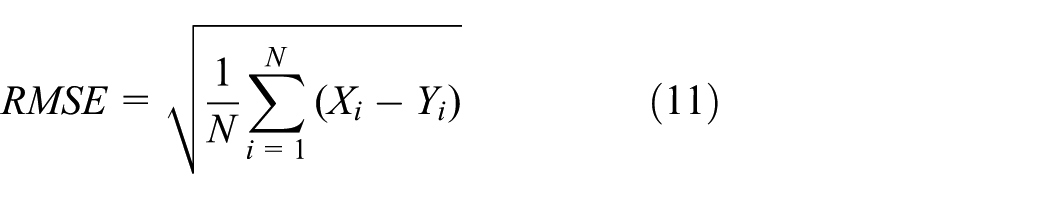
where
Selection of models and parameters
In this way, we settle the parameters of NNs both for the baseline and for our HM to ensure the best prediction performance. The baseline approaches include ARIMA, PMA model, neural network (NN), and BN. We mentioned before in section “Related works,” that there is a similar model 18 selecting dynamically between ARIMA and HAM to achieve better performance in prediction. However, we do not choose it as the baseline approach because the selection method of that model is simply selecting the one with lower error measurement, which means we can know the comparison results by comparing our model with ARIMA and PMA. All of the approaches above are concerned in our hybrid traffic prediction scheme (HM), though in different kinds of usage, not only for forecasting the traffic.
ARIMA
In this simulation, ARIMA is implemented following the steps of Box and Jenkins methodology. Since the original traffic data are nonstationary, first, we differencing d times the data into stationary time series. Then, we have to check the ACF and PACF of time series to determine the value of p and q. The
Different ARIMA models’ performance.

The p-value of ARIMA(1, 1, 1) is so high, indicating that coefficient
PMA
The parameters of PMA depend on the date and time of prediction we need to apply. When settling down the day and time of prediction, PMA can use them as d and t in calculations.
NN and hidden layer size
The number of neurons in input layer and output layer has been fixed in our hybrid prediction model. However, we still have to determine the input and output layer of NN for baseline approach. Moreover, the number of neurons in hidden layer for both NN needs to be decided. For the baseline NN, the input layer includes 10 nodes, with the inputs
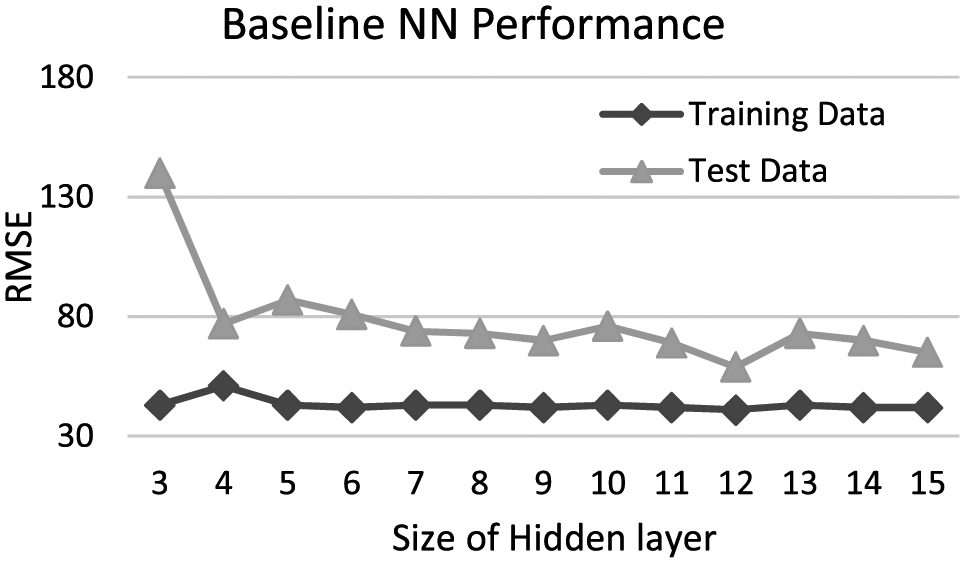
Performance of baseline NN with different hidden layer sizes.
Since the NN model is trained to fit the training data, the RMSE of training data is low and stable. From Figure 6, we can find out that the baseline NN with 12 hidden neurons yields best performance.
Furtherly, to determine the number of hidden neurons in NN of our hybrid prediction model, another training of NN is applied. Since the NN in our model has an input layer of four neurons, the size of hidden layer is chosen from a large range from 3 to 20. From Figure 7, we can note that NN in out HM yields best performance when the hidden layer with size of 18.

Performance of NN in hybrid model with different hidden layer sizes.
BN
We have to decide the joint probability distribution of a BN. For both BNs, for baseline and HM, we adopt the Gaussian distribution for mathematical convenience and natural orders.
Comparison of results
In this section, we carried out the simulation experiments with the data from 10 February to 10 March as the training set. While the data from 10 March to 15 March serve as the testing set.
Short-term prediction
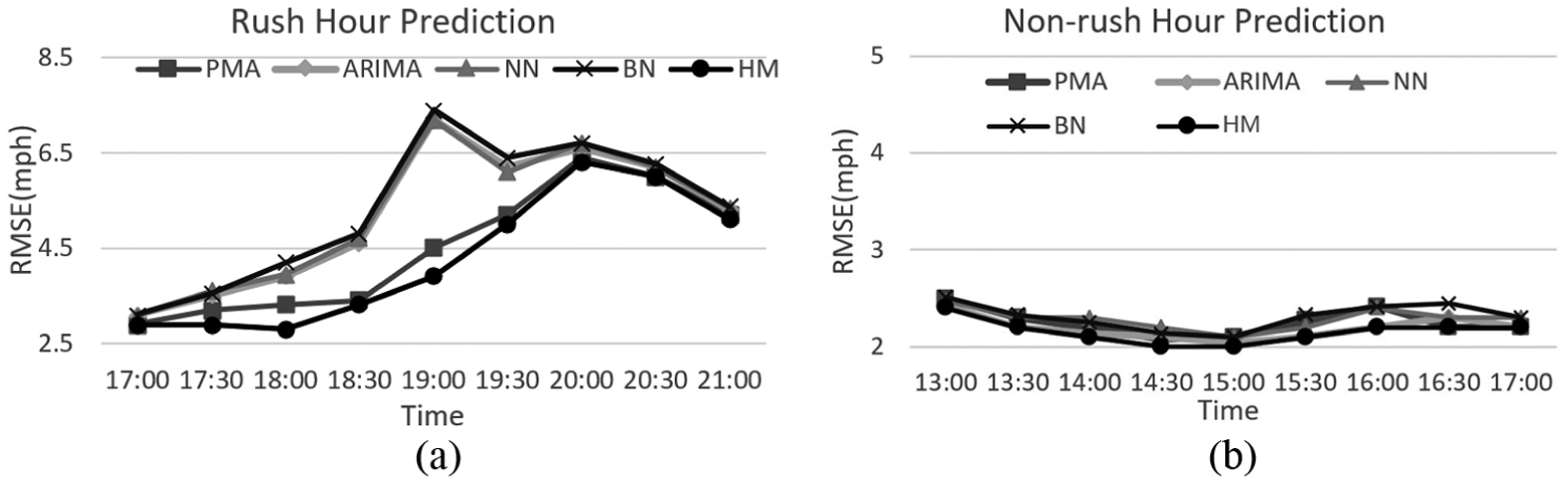
In short-term prediction experiment, PH is set to be

Short-term prediction performance: (a) rush hour performance and (b) non-rush hour performance.

Performance at the boundary of rush hour: (a) actual traffic around rush hours and (b) prediction accuracy at the boundary.
We can figure out that the prediction accuracy of all approaches shows a better result during the non-rush hours and PMA yields worse results than others. The hybrid prediction of us shows little advantages over the baseline approaches in the short-term prediction simulations. However, when forecasting the traffic situation at the boundaries of rush hours, our hybrid model shows significant better performance.
Figure 9(b) depicts the prediction accuracy changes at the boundary of rush hour. It is clear that the baseline approaches cannot predict the speed at the boundary of rush hour with an acceptable performance except the PMA model, which forecasts the traffic more based on traffic pattern revealed by historical traffic data.
Considering both experiments in the short-term prediction, most of the baseline approaches can well handle traffic prediction both in rush hour and non-rush hour while they show weakness in forecasting traffic condition at the boundary of rush hour. PMA model yields acceptable prediction accuracy at the boundary, but it is not effective enough for normal situation short-term predictions. In general, the hybrid prediction model of us shows a comprehensive outstanding performance in both normal traffic situation and in the boundaries of rush hour in short-term prediction.
Long-term prediction
In the long-term prediction simulation experiments, PH is set to be
From Figure 10, we can still note the information that the prediction accuracy of all approaches is higher than that of non-rush hour. However, the baseline approaches show different patterns regarding to the performance of prediction in rush hours. PMA leads the baseline approaches with the forecasting accuracy at long-term prediction in rush hours, close to our HM. The hybrid prediction model of us in long-term prediction yields remarkably better performance than the competitors.
Long-term prediction performance: (a) rush hour performance and (b) non-rush hour performance.
From the short-term and long-term prediction simulation experiments, we can find out that our hybrid prediction model combines the usage of real-time data and traffic patterns from historical data, as a result it handles all kinds of traffic situation with outstanding forecasting performance.
Comparison of prediction time
Since the proposed HM has more branches and procedures in prediction, it is important to consider computational complexity as a factor in traffic forecasting. As a result, in Figure 11, we calculate the average prediction time each approach cost in both short-term prediction and long-term prediction. The results do not include the training time of ANN and HM because the training process only need to be carried out once before the prediction, which can be done in preparation instead of costing more time in forecasting. It is shown in Figure 11 that PMA spend least time in prediction because it is the simplest one in all the approaches. ANN and HM take more time than ARIMA but less than BN. Except for PMA, all the approaches have the similar time complexity. In fact, while improving performance in both normal traffic and rush hour situations, the proposed model will not yield the result in an apparently longer time.

Prediction time of five different approaches.
Conclusion
In this article, we propose a hybrid traffic prediction scheme that forecasts the traffic with combination of different prediction models using traffic data collected from real-world spatiotemporal detectors. We point out the problem that single prediction models are not efficient enough to handle all kinds of traffic situations. Traditional prediction models fail to predict the traffic condition during boundaries of rush hours and in the case of emergency incidents. Our proposed HM significantly improves the forecasting performance at such situations by associating the usage of real-time traffic data and traffic patterns from historical traffic data. It also relies on our emergency strategy which uses BN to check the speed information of nearby road to be aware of incidents in advance. Moreover, the HM reveals the traffic patterns in short-term and long-term predictions.
There are some works we plan to do in the future: To consider the influence of spatial correlations of detectors, so the traffic information can be dealt with as a whole network. And to apply data pre-processing in the prediction model, in order to take advantage of smoothing techniques to yields better prediction performance.
Footnotes
Handling Editor: Aitor Almeida
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.