
Abstract
To provide guidance to and integrate directly with the information technology side implementation to achieve coherent data, information, and knowledge coordination and robust value-oriented adaptability for maximization of business profitability, we propose to leverage the ideology of service economics to achieve bidirectional computational bridging between business planning and technical implementation of ubiquitous services/XaaS in the application program interface economy for promoting the macro-service market, especially in global value chains. Enlightened by value-driven design, we propose a systemic formalization from value calculation to design quality measurement which binds the technical modification and variation on design artifacts with business value strategy through a framework of managed quality properties in a wireless sensor network–based service system creation process. In the process of building a service system, we use data, information, and knowledge flow to abstract various data, information, and knowledge manipulation and usage scenarios. We propose to improve system reliability and robustness by managing data and information reuse, redundancy as well as structure.
Introduction
Boehm and Sullivan 1 have proposed that various designs are motivated uniformly by creating value added for maximizing the profit of stakeholders. They have endeavored on guaranteeing the profit/interest 2 from strategic economic reasoning down to specific development processes which specify modeling activities and evaluation criteria. This integration fills the top–down gap between business planning and IT implementation. 3 Three different phenomena, data, information, and knowledge, are relevant in business process modeling. Despite of many shortfalls in the state-of-the-art practice and research which hinder the completing of this top–down seamless bridging of business area and IT area, a practical bottom–up corresponding bridging from IT side to the business side is mostly missing as a necessary feedback channel for a responsive refinement mechanism between business planning and IT implementation which will provide effective and efficient guidance for data, information, and knowledge interplay 4 in terms of enhanced data sharing, information exchanging, and knowledge creation between business and technical domains to maximize the general profitability of all stakeholders. Data are not specified for stakeholder or machine. Data are the collection of discrete elements and concepts. Information is specified for specific stakeholder and machine. Information is conveyed through conceptual mapping and combination of data and is used for interaction. Knowledge is used to reason and predict unknown resources. The strategic business planning to ubiquitous services 5 implementation especially in the application program interface (API) 6 economy trend is highly supportive to new development mode such as DevOps. 7 Recently, G Wiederhold 8 has proposed to motivate IT professionals to actively participate in filling the gap of data, information, and knowledge imbalance between economists and the IT toward coherent management from business planning to IT implementation.
Currently, service economy, 9 especially software-as-a-service economics, 10 has been proposed for promoting the macro-service market, especially in global value chains, which is becoming more dependent on effective and efficient service construction on various “as a Service (aaS)” 11 and effective service delivery/brokerage. 12 Web service is vulnerable to stochastic failures because of changes in Internet environment, which will seriously affect the reliability of business-critical applications. 13 Thus, there is a need to deliver reliable web application with attributes that cover the correctness and reliability. 14 To get the most value added from the efficiency improvement and strategic investment practice on the service economy with improved economic outcomes, it is necessary to construct a seamless data, information, and knowledge flow circle which goes through stages of economic planning and design details to guarantee the refinement of business consideration as decision-making, design activities or resource allocations, and model evaluation in terms of data, information, and knowledge elements collaboratively. 15 Retrospectively, a counter-direction feedback path in terms of data, information, and knowledge interplay is also expected to aid the measure of the performance and quality of the ongoing design process for further control planning and improvement toward value maximization. However, from software economics area, 16 few direct support can be found to construct this bidirectional data, information, and knowledge flow and control flow following the value-driven ideology. 17 In our previous work, 18 we specified Knowledge Graph in a progressive manner as four basic forms including Data Graph, Information Graph, Knowledge Graph, and Wisdom Graph and provided answers for 5W (“Who/when/where, what, how, why”) questions. 19 Traditional methods toward quality-of-service prediction suffer from a series of defects such as failing to handle data sparsity.20,21 Empirical knowledge and statistical models22–24 are effective for project management related to software quality properties but not linked directly between quality properties and specific design activities. The complexity of the interleaving of scopes of quality properties 25 constitutes a challenge for comprehensive synthesis and analysis. Some existing works26,27 have devoted to bridge the business society and the computer science society on the service development evaluation. Conceptually, in this work, enlightened by existing semantics clarification,28,29 we proposed that knowledge is rules based on information for dealing/predicting situations with incomplete information, and information is evaluation on observed data ontologically.
As a response to Wiederhold’s proposal, we proposed a systemic formalization from the value calculation to design quality measurement which binds the modification and change on implementation artifacts with the business strategy through a framework of manageable quality properties in a service design process under an investment perspective. This work differs from most existing works which are human experience–centric and focus largely either on service pricing30–32 from the IT side or on cost 33 and benefits from the economics side,34,35 but neither covers both sides simultaneously while conveying the created value added. We model the whole system design process from data, information, and knowledge introduction perspectives as stages of data sharing, information transfer, and knowledge creation 36 and control in a data, information, and knowledge lifecycle. Thereafter, we refine corresponding data, information, and knowledge processing stages as atomic data, information, and knowledge processing activities and states and relate these activities/states with their effects on system quality properties which eventually map to business values in computational manner. The evaluation on the adaptability and controllability of intermediate models and modeling activities in a development process is aided with a deviation measure centering core concepts of under design (UD) and over design (OD) 37 which represent the direction and distance of observable design degradation referring to an ideal model or best experience in a data, information, and knowledge lifecycle. Based on this bundling mechanism between design activities/states and corresponding evaluations, we proposed to use data, information, and knowledge flow to drive manipulation between business strategical planning and technical implementation for wireless sensor network system construction. Sensor nodes consist of sensing, data processing, and communication components and leverage the idea of wireless sensor networks based on collaborative effort of a large number of nodes.
The rest of the article is structured as follows. Section “Modeling of stakeholders’ expectation and their deviation” presents a modeling method of expectation and its deviation. Section “Revelation UD/OD through data, information, and knowledge manipulation and usage” elaborates the revelation of UD/OD through data, information, and knowledge manipulation and usage. Section “Decompose and synthesis toward service development economics” illustrates the decomposition and synthesis toward service development economics. Finally, section “Conclusion and future work” concludes the article while providing directions for future research.
Modeling of stakeholders’ expectation and their deviation
The meta model of the whole modeling process
Software development appears to be a process of setting up a computational environment and model of reality using concepts such as variable functions, storages, operations, data types, pipes, and channels. However, from the requirement layer and ontological layer, the description in terms of fact, data, knowledge, and wisdom is more general for sharing understanding on the efficiency and effectiveness of a process concerning completeness, consistency, and reliability. 38 Ontologically, the coherent process from business planning to IT implementation consists basic conceptual activities of data observation/collection, information transferring from sender to receiver (could be human or machine), and knowledge creation. These basic activities comprise superficial semantics in requirement specification transferred to design artifacts accumulatively. During this accumulation, there are value added generation and business value balancing among stakeholders. It is possible to model the process of implementing business strategies with IT techniques following the value-driven ideology in terms of the interplaying among data, information, and knowledge coherently and abstractly. This meta-level coherence can function as guidance for revealing the incompleteness and gaps of modeling and implementation activities in a model-driven process. The guidance consists a semantically pragmatic 39 measurement of artifacts and activities on data sharing, information lifecycle and knowledge creation. Yin et al.20,21 have proposed a non-intrusive approach named CloudScout that is capable of automatically discovering dependent service components through analysis of correlation among service components based on time-series information from system monitoring logs. To ease the distinguishing among basic concerns such as expectations of stakeholders, we create a meta process to abstract transferring of data, information, and knowledge at the requirement side top–down from business planning to service composition, model artifacts reflecting the expectation of stakeholders being implemented gradually. Every design activity either conforms the expected effect or deviates from the ideal effect. We build a deviation measure mechanism to monitor and measure the deviation for respective control purposes.
Transformation from artifact-activity view to data, information, knowledge-activity view
In a custom software development collaboration network, the cooperation between participants is achieved through the exchange of various artifacts. Moreover, development process constitutes by participants’ work of converting one artifact into another or a groups of new artifacts. During this process, the following situations on data, information, and knowledge may happen:
Data, information, and knowledge indicated by original artifact are kept effective in resulting artifacts.
Data, information, and knowledge are missing in resulting artifacts.
Extra data, information, and knowledge which are not contained in original artifacts are introduced in resulting artifacts.
The usage of data, information, and knowledge is closely related to the topic of using data, information, and knowledge to solve problems. We identify that following facts influence the general value of the exchange process of data, information, and knowledge in artifacts during an activity of data, information, and knowledge usage:
In the source data, information, and knowledge:
Where to seek data, information, and knowledge resource to realize specific functionality. What data, information, and knowledge are truly useful. Measure the cost of accessing relevant data, information, and knowledge.
In a design activity:
Inconsistency of data, information, and knowledge between source and target of the activity. Completeness of data, information, and knowledge between source and target of the activity. Misunderstandings of the target of activity (time requirement, cost requirement, etc.). Reusability of data, information, and knowledge. Efficiency of data, information, and knowledge introduction/organization. Effectiveness of data, information, and knowledge usage.
Software and service development lifecycle specifies participants’ interaction with each other. In the view of data, information, and knowledge transformation, each stakeholder/participant accepts specified form of data, information, and knowledge in the source and produces specified type of target data, information, and knowledge. In this scenario, we identify the following properties:
Stakeholders’ capabilities of processing information types may vary.
Introducing information that a stakeholder cannot understand may cause added costs or human resources.
A stakeholder may produce information that cannot be effectively processed/transformed.
We build up a model of user’s capability of data, information, and knowledge processing as follows: user’s capability of processing information is denoted by a matrix
Core concepts preparation
Core concepts of UD and OD 37 can aid the identification of the direction of the deviation of manipulation on data, information, and knowledge and represent the extent of the deviation. UD and OD provide shared semantics between business planning and IT implementation among stakeholders and are defined from the knowledge introduction perspective as follows.
OD refers to the state concerning design activities or design artifacts that the evaluated comprehensive value of the design product or product family or intermediate design model excesses what is expected for its whole investment by stakeholders either from short run measurement or from a long run one. The produced extra quality or functionality such as more robust or complicated will cost extra resources including: project time, human effort, efficiency, effectiveness, consistency, clearness, and deviation from optimized goals, with less comprehensive value gaining efficiency for the whole project usually. OD will leave less variability/constraint space 40 for further change or more content of data, information, and knowledge than expected from a cost efficient and effective criteria. OD can be partially a result of introducing subjective data, information, and knowledge by stakeholders, especially designers, which deviates from correctness, consistency, completeness, effectiveness, and efficiency. OD can also be caused by introducing/organizing objective data, information, and knowledge in improper temporal order.
UD is the design activity and planning side consequences that the evaluated value of the design product or product family or intermediate design model or protocol or mechanism in a certain design stage/state is less than what is expected for its whole project investment by some or all stakeholders either from short run measurement or from a long run measurement. UD could partially be a result of missing data, information, and knowledge unconsciously during data, information, and knowledge introduction or sharing or transferring phases. UD can also influence the correctness, completeness, effectiveness, and efficiency of a design process.
UD and OD are labeled as the negation of each other and expanded on the contrary directions. The actual design (AD) of a project is denoted as (AD) which represents the specific implementation of a project. Reasons of the occurrence of UD and OD can be understood in data sharing, information communication, and knowledge creation process through the concretion of modeling of the expectation from stakeholder sides.
Hypothesis on the expected time and cost HCos
We make hypothesis on the expected time and cost for a development process. For a given project goal G which can be materialized as the efficient composition and effective performance in terms of interplaying among data, information, and knowledge, there is an objective period of time T, a fixed amount of human effort H, and a fixed amount of resources R (storage, network, etc.) to accomplish the data sharing, information communication, and knowledge creation. These instances of T and H match to a proper design process plan P. We define that a service system development process is composed of a series of activities. These activities will be performed according to a necessary execution sequence. In the development process, we will find that results of sequential implementation and parallel implementation of some activities are equivalent, but costs of parallel implementation are much lower. For the actual development process that is not ideal, there will be information flow redundancy and useless situation. We identify them and calculate the corresponding price and make corrections. By proper here, it means that the cost and investment CosInv is minimized while reaching the optimized value maximization on stakeholders’ sides

We take the context information of how long and how much human resources are used to accomplish a set of functionalities and qualities into consideration. Through the comparison between the actually used time, resource, and effort with the expected time, resource, and effort, we can label the excess of the expected period and effort in HCos as either OD or UD. The UD and OD can be further expressed in terms of the amount of data, information, and knowledge.
Illustration of flows of data, information, and knowledge
An organization can only have the right data available at the right place and at the right time only when it organizes the collection of useful data and analyzes this data and distributes its results promptly and accurately. Figure 1 abstracts various data, information, and knowledge manipulation and usage scenarios with data, information, and knowledge flows in an intelligent traffic service system construction process. Problem solved by intelligent traffic is how to integrate information obtained from multiple platforms. The analysis after data mining can find potential factors of traffic so as to provide users with better services. With the development of web service, amount of web service providers completing the same function will increase and the service itself is also dynamic. The service system changes resources and services according to stakeholders’ demand and application situation as well as its characteristics. Through model-driven and dynamic mapping, the adaptive dynamic evolution or the fast dynamic resource and service reconstruction are carried out to maintain the best running performance of the service system. A participant is responsible for a series of activities. Various data, information, and knowledge are clustered into different categories according to their similar “utilities.” For an information flow of ideal design (ID), information that shares the same category should be merged and replaced by the most representative information which has the lowest cost and human resource and maximal utilization. We make the hypothesis on user’s preferences: stakeholders’ maximum satisfaction is reached through ideal data, information, and knowledge flows. For simplicity of expressing, here, we also ignore the payloads of data, information, and knowledge transformation.

Abstraction of service development data, information, and knowledge flows.
Revelation UD/OD through data, information, and knowledge manipulation and usage
UD and OD are inefficient phenomena in the development of a software. In this section, we propose to reveal and resolve UD and OD in terms of data, information, and knowledge reuse/redundancy, flow control, loss, and error.
Data, information, and knowledge reuse/redundancy
UD can come from the situation that some development activities are not planned efficiently and the resulting product is not as effective as expected in terms of general value within the available effort/resource limits. From the data sharing, information communication, and knowledge creation perspective, there are some redundancy cases which produced and collected the same data, information, and knowledge repeatedly and unnecessarily. This situation will cost more time and waste more resource. As shown in Figure 2, from the start location to the destination, three different nodes can provide three paths. Traffic flow indicates the road congestion. As for stakeholders, path 3 is the best choice whose time might be the least although not is guaranteed to be the nearest path. Thus, the other two paths that are not selected by stakeholder are redundant. This situation of UD can be remedied with optimization through enhanced and deepened integration41,42 of the static data, information, and knowledge reuse strategy and the dynamic data, information, and knowledge transferring strategy which will coordinate the process of reproduction, transfer, and reuse based on a trade-off of the gains versus loss of respective processes. Taking information as an example of data sharing, information communication, and knowledge creation, we formalized the scenario of UD in this situation covering the ideal criterion, UD identification, measure, and remedy strategy as follows.

Information redundancy in path selection.
The basic concepts of state, data, event, activity, and information are defined here

The information communication and data sharing are defined subsequently

For an ideal usage model of data, information, and knowledge concerning reuse, the usage occurrence for a piece of data, information, and knowledge will be maximized while minimizing the repeated creation of it. Based on the ideal model, we formulate the identification of UD from reuse concern and propose the calculation of UD

A given project goal is denoted as

Data, information, and knowledge flow control
UD can come from the situation that some design and development activities are not arranged efficiently or effectively. From the data, information, knowledge and value transferring perspective, data, information, and knowledge flow need to be well planned to avoid inefficient situations such as the sequential transferring which allows parallel mode or vice versa. Improper data, information, and knowledge control will cause information delay for modeling activities. Then, the time span will exceed expected time in the ideal process of P and results in UD. Inefficient information flow will increase the pressure on resource side including storage and bandwidth. The identification and measure of UD in this situation are formulated as follows

There are various situations where flow control can be optimized. For example, if the execution of an activity a is independent from previous activities which we represented as the input of a which consists no output of previous activities, then the start time of activity a (represented with
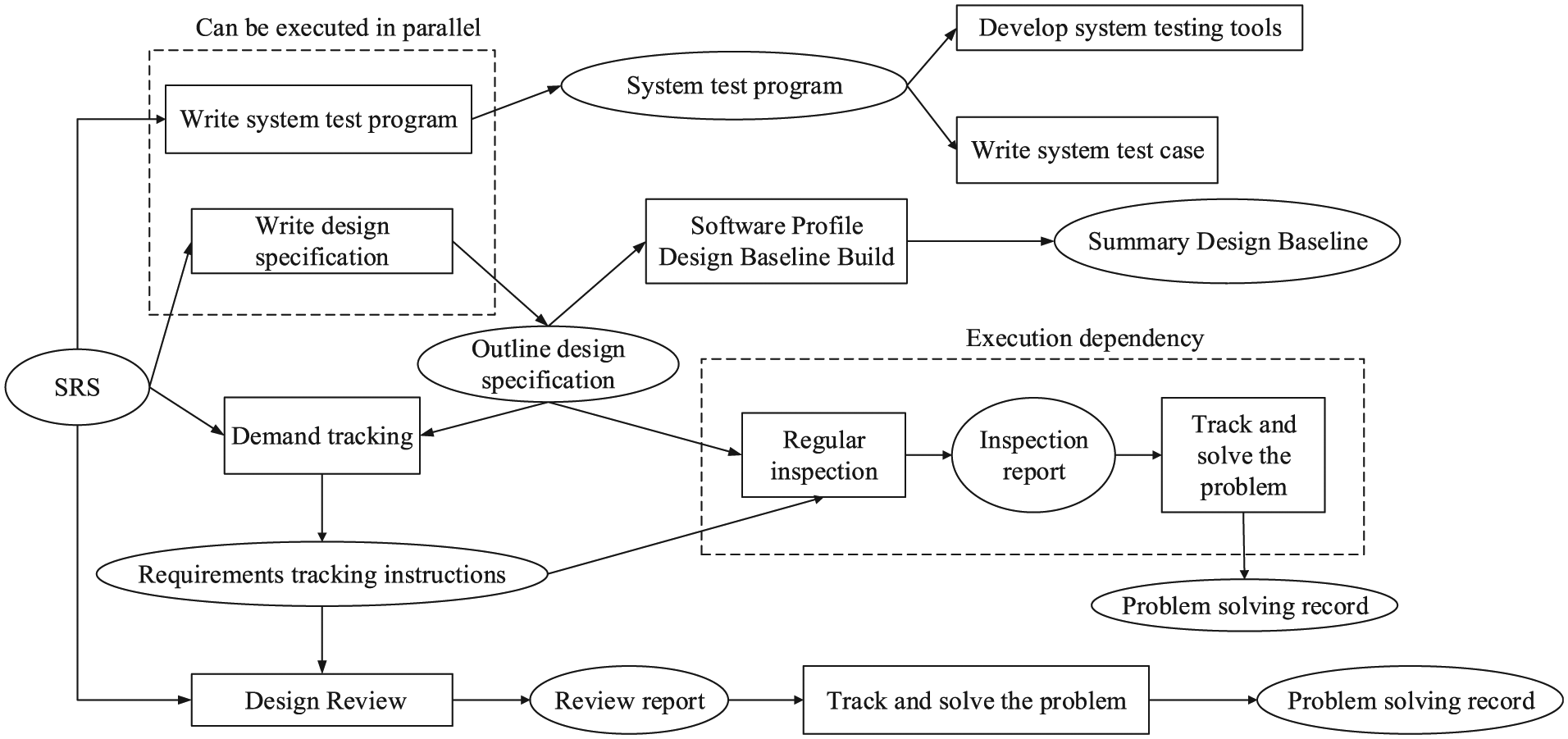
Low-efficiency information flow between activities of software summary design.

Data, information, and knowledge loss
Improper design can come from the situation that some data, information, and knowledge are lost during the transferring process from stakeholders’ side toward the implemented artifacts or a transformation process. When data are chosen as the target of transferring by stakeholders, data becomes information conceptually. Knowledge originates in utilizing data and information in incomplete sense to predict future situations or decide for unknown background. Taking information missing as the example, the lost information can be classified as follows.
Content information CTInfo
Direct content data/information refers to the usage of data/information as answering to questions of “Which,”“When,”“Where,” and “What.” Increasing content data/information will reduce information gaps among existing model construct and lead to the increase in the volume of the data/information of target models in the form of either the amount of entities or relationships directly connecting entities.
Constraint information CSInfo
Constraint information refers to information which is used to produce answers to questions of “How.” In practice, these kinds of information are used to construct activities to provide answer questions of “How,”“What,”“Which,”“When,” and “Where.” Constraint information does not directly comprise the target model through directly transferring or transformation, but could logically be used to categorize on existing data, information, and knowledge in terms of negative logical connectives of exclusion functionality. The accumulation of the constraint information on target models could decrease the amount of entities and relationships directly when constructing a system. Constraint information can be implemented with rules or hidden in machine learning mechanisms. Constraint information influences also the effectiveness of a system’s performance.
The current intelligent environment system mainly focuses on the use of context-aware and multi-channel information acquisition technology to achieve pervasive computing applications. But these systems are relatively fixed application processes, both difficult to meet different needs of users and lacking flexible service on demand expansion. The service environment based on service composition technology is attracting attention. Service composition can meet the dynamic and complex business needs on demand and solve the “changing according to demand” problem in application system. Service composition has become a new paradigm of distributed software development. Combined services can broaden the scope of business services and enhance the value of resources and business services. We take intelligent traffic as an example illustrating the flow of data and information in its design framework as Figure 4 shows. Each node of a single sensor collects the road conditions and vehicle-related data and then data will be updated to the background monitor computer after being integrated and optimized. The collected data and information obtained after analyzing data can answer the questions guided by interrogative words including “when / where / which,” and “what.” Vehicle can dynamically adjust the travel speed according to the information from the environmental feedback. If an incident is perceived, the vehicle can make reasonable decision to assist the driving. Intelligent traffic is a comprehensive use of information processing and computer technology to improve the real-time integrated transport management system. After clarifying information, stakeholders are able to get constraint information or knowledge to help them make decisions. Knowledge/constraint information is capable to answer “how” questions. Intelligent traffic is now widely used and it combines integration of things, cloud computing, large data, wireless sensor, and other advanced technologies together. It is an intelligent travel system making people, car, and road more coordinated and public transport services more humane.

Flow of data, information, and knowledge in intelligent traffic.
Losing these two types of information will lead to different design deficiencies.
Loss of CTInfo
Losing CTInfo cannot be evaluated as a success in terms of finishing the project earlier cause the accomplishment is incomplete compared to ideal P. Losing certain data/information can also lead to the impossibility to accomplish the project. In absence of the validation of the completeness of the system, it is impossible to identify the deficiency as either UD or OD. The loss of CTInfo will result in an information set with less information than expected. We identify this lack of modeling as UD

Loss of CSInfo
Since constraint information usually is introduced to reduce the freedom of the expansion or the coverage of existing models/artifacts, the accumulation of the CSInfo on the target models will decrease the amount of entities and relationships directly constructing the entities. The loss of CSInfo will result in OD of the final system. The measure of the degree of losing CSInfo is difficult to be implemented as the ratio of the amount of CSInfo which answers to “How” questions in actual situation versus the amount of CSInfo in ideal situation is uncertain since the amount of related entities and relationships are influenced by many possible forms of combinations and intermediate expressions

Data, information, and knowledge error (referring to true/false vs yes/no)
We propose that if data, information and knowledge doesn’t confirm to objective justification which usually refers to the real world or logic reasoning directly or indirectly is false in comparison to true. In addition, if consistent knowledge content confirms to the knowledge owner’s subjective expectation, the knowledge is justified as correct in contrast to wrong. Sometimes false information or information generated from the wrong knowledge might be introduced without notice or unconsciously. 43 Observation literally might not be wrong by itself but explanation in the brain of human could turn the observed true data into data not confirm to the reality. We call all data, information, and knowledge on the false and negative sides as wrong or error. Theoretically, error information might be any information which does not match the expected information. Here, we distinguish the situation of error information from the situation that after information loss subsequent information is introduced but not matching the expected information. Here, the error information does not include imprecise information which can be specified more proper as data/information loss. Therefore, we limit the error information as information which is negative/contrary to the expected information. The information error does not provide easy semantics for direct identification as UD or OD without context information. Sometimes error information will switch the evaluation results in terms of UD and OD. Currently, we do not focus on error information processing besides excluding it from targeted information categories

Useless data, information, and knowledge
We restrict some data, information, and knowledge as useless since they will contribute to neither the positive construction of the necessary intermediate model or target model nor the negative construction which is demonstrated by the implementation of error data, information, and knowledge. However, the introduction of useless data, information, and knowledge still incur extra effort, resource, and time cost. A special case of useless data, information, and knowledge is that useful data, information, and knowledge are unnecessarily but repeatedly created, introduced, and stored. The useless information introduction is considered as UD

Useless data, information, and knowledge are modeled as data, information, and knowledge that are generated during participants’ activities but being useful for none consequent activities. Figure 5 shows the existence of useless information represented by a red dashed box. Content in black box represents execution of activities and content in black oval box represents information production. The out degree of information product specification should only be 1 as information requirements tracking record has no effect on the final activity. Each activity is equipped with an execution time which is not shown in Figure 5.
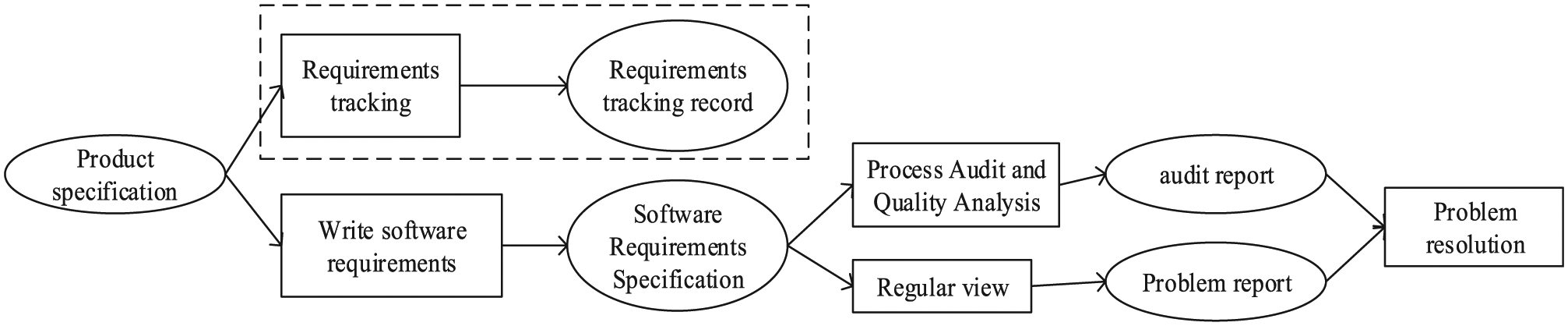
Activity diagram of generating useless data, information, and knowledge.
Improper unknown data, information, and knowledge processing
The processing of unknown data, information, and knowledge deals with the absence of data, information, and knowledge as necessary or complete during both the information introduction and model evolution stages. Improper unknown information processing will drive the design process away from the ideal process and bring extra cost to fix it. We limit the investigation here from the data, information, and knowledge lifecycle perspective of information transfer modes between known data/information and unknown data/information. Therefore, this division avoids the overlapping on the other phases of the data/information lifecycle such as the unknown information transfer which is intertwined with the constraint information processing. If we restrict the unknown information expression with the closed-world assumption (CWA), 44 unknown information will be justified within a set of undecided possibilities/choices which need to be objectively determined with further data, information, and knowledge introduction or subjectively decided by stakeholders. The objectively information processing is expected to keep the incompleteness of current data, information, and knowledge before processing and after processing consistently

Unexpected processing can be classified as the following two modes. The first mode denotes the information transferring mistakes of losing the decision of known data, information, and knowledge which fails into the scope of content data, information, and knowledge loss. The result of content loss will result in that there is not enough determinant data, information, and knowledge. Thereafter, there are usually several undecided possibilities which still indicate freedom of variability. The second mode denotes the situation that unknown data, information, and knowledge which contain several choices is taken as the sole choice or the scope of choices is subjectively/unconsciously minimized. This process can be a result of constraint data, information, and knowledge of other choices being missing. Then, the content which should be excluded is retained in the result system. Figure 6 shows the whole picture of the revelation of the UD and OD from the perspective of data, information, and knowledge lifecycle


UD and OD from a data, information, and knowledge lifecycle perspective.
In Petri net modeling, known and unknown data, information, and knowledge can be modeled as tags of places. An illustrative transformation/transfer activity is bundled between data, information, and knowledge that is represented by
Known data, information, and knowledge that are considered as
Unknown data, information, and knowledge
Unknown to known data, information, and knowledge: mapping human subjective imagination content to
Known to unknown data, information, and knowledge:
Beside unexpected transfer/transformation of data, information, and knowledge from unknown to known, knowledge could also play a proper role of predicting unknown data, information, and knowledge from incomplete data/information which is different from the erroneous transferring.
Decompose and synthesis toward service development economics
To measure and control the development and design processes of a service system, we propose to model the ultimate economics goal as for maximizing the general value added of the final system in the whole business process. We model this goal implemented through an AD in comparison to an ID in a business scenario as follows

This scenario takes into consideration of factors including the client/market scale of the final system, the efficiency of the design process, and the correctness of design result. We propose to model the computation mechanism for the efficiency and correctness of the design from the data sharing, information communication, and knowledge creation perspective to compliment the value calculation. We propose to model the correctness of the AD as follows. The rate of completeness indicates the percentage of expected data/information/knowledge which has been transferred. The rate of wrong data, information, and knowledge indicates the reliability of the accomplished data/information/knowledge transfer

We propose to model the efficiency of the AD as composing both structural efficiency and dynamic efficiency. Structural efficiency depicts the difference between the most efficient structure experience/knowledge and the actual structure in terms of reuse accomplishment, redundant data, information, and knowledge management, and data, information, and knowledge organization. The quality of data, information, and knowledge organization represents the conformance of the topological deployment of the data, information, and knowledge among classes, attributes, and operations, with the optimized experience/knowledge/patterns. The quality of organization will influences not only the possibility of reuse but also the length of communication paths, maintenance, and security

The dynamic efficiency depicts the data/information/knowledge usage for a specific data/information/knowledge structure set will be influenced by the mechanism of component/class communication, data/information/knowledge flow, and control flow. Although the policies and restriction in real situation will influence the enforcement of the system, we exclude them as outer factors which are not usually determined by developers

We assign values to some quantifiable parameters to the development process to calculate the value added in ID and AD, respectively. Through Table 1, we see that the AD can be divided into two kinds of situations that are UD and OD. When the cost and investment that stakeholders have to pay becomes greater but they do not get the same amount required services as in ideal situation, we define that this as UD. When the cost and investment that stakeholders have to pay is greater but the amount of service is more than what is needed in the ideal situation, we define that as OD. Both are deviated from the ID, and our approach proves that the software development process can be quantifiable. By interfering with and adjusting some relevant parameters which are shown in Table 2 such as rate (WrongInfoDataKnow), we can correct these deviations to make the software development process much closer to the ID while minimizing the cost and investment and reaching the optimized value added maximization on stakeholders’ sides.
Deviation of CosInv(P(t,h,r)) and ValueAdded between ID and AD.

ID: ideal design; AD: actual design; UD: under design; OD: over design.
Detail parameters influencing completeness and efficiency.

ID: ideal design; AD: actual design; UD: under design; OD: over design.
Conclusion and future work
Toward coping with the challenge of existing few value-oriented or value-driven data, information, and knowledge lifecycle evaluation approaches for bidirectional evaluation and control on the efficiency and effectiveness of the design activities between detailed design activities/content and business modeling, we proposed a conceptual systemic value calculation model centering this challenge in terms of the coherent basic data, information, and knowledge interplaying underneath the gap from business planning to IT implementation. From the ontological formalization on basic constructs of system design and evaluation, we expected to lay a foundation for further computational constructs crossing good economical knowledge and design experiences toward a win-win service mashup environment with increased value added for all stakeholders so that stakeholders can spend least cost but get the relatively optional services. Capability Maturity Model Integration (CMMI) concentrates on the management from the point of view of the refinement but fails to form a closed loop from the top of the commercial design to achieve the details. Currently, some qualities such as reliability and precision are not explicitly proposed in the calculation due to the difficulty that the meaning of these qualities lacks uniform definitions. However, we managed to consider these qualities in the calculation implicitly. For example, the precision of the transfer rate is represented in the correctness of the content transfer and the efficiency of the transfer process. Reliability of the system is partially reflected in the efficiency of the information structure and the management of the information reuse and information redundancy. Important factors which are too specific are not considered at this stage include the location, data format, transaction law, and policies which depend on the context of the specific service transaction scenarios. In the future, we will endeavor to implement the proposed approach for prototype system development to get feedback for further improvement. We will also explore deep learning approaches to incorporate some empirical data, information, and knowledge which are not explicit or difficult to be formulated as semantic rules or formulas in our existing work.
Footnotes
Handling Editor: Daniel Gutierrez-Reina
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (under grant nos 61363007, 61662021, and 61662019), the Natural Science Foundation of Hainan (under grand no. ZDYF2017128), and the National Key Technology Research and Development Program (under grant no. 2015BAH17F02).