
Abstract
A neighbor knowledge-based broadcast scheme is proposed to reduce the latency for wireless ad hoc networks, yet keeping the overhead at a reasonably low level and fulfilling the reliability. In the scheme, few Hello messages are interchanged to collect one-hop neighbor information. The collected information is used to calculate the neighbor density, the ratio, and the number of one-hop uncovered neighbors, upon which the rebroadcast probability and delay are adjusted adaptively. The way that the rebroadcast probability and delay are defined in neighbor knowledge-based broadcast scheme reduces the transmission overhead and restrains the traffic aggregation effectively. Next, a velocity-based data distribution mechanism is proposed and extended to neighbor knowledge-based broadcast scheme to further reduce the latency, forming neighbor knowledge and velocity-based broadcast scheme. It is stipulated that few higher-velocity nodes are employed with bigger probability to rebroadcast the incoming message. The performance of the schemes is evaluated by the simulation under diverse network configurations. The results show that they outperform the existing broadcast schemes in overhead and especially in average end-to-end delay. Compared with flooding, they reduce the overhead by 88.4% and the average end-to-end delay by 88.9% at most.
Keywords
Introduction
Broadcasting is a communication primitive in wireless ad hoc networks. It is essential to resolve many issues such as route discovery, route maintenance for unicast or multicast and emergency or warning message dissemination in disaster, battlefield, and VANET scenario. In some harsh conditions, an efficient broadcast mechanism is vital and may be the only possible way to disseminate crucial information. 1 Because radio signals are likely to overlap with each other in a same geographical area, a straightforward broadcasting by flooding is usually very costly and will result in serious redundancy, contention, and collisions, to which is referred as the broadcast storm problem. 2 Thus, during the past decades, broadcasting has attracted much attention of the research groups. Many kinds of broadcast schemes were proposed to minimize the number of transmissions while attempting to ensure a high reliability and a low latency.
Besides blind flooding,3,4 a basic classification of broadcast schemes divides them into two main categories: probabilistic broadcast scheme and deterministic broadcast scheme.1,5,6 The probabilistic broadcast scheme includes probability-based schemes,2,7–11 counter-based schemes,12–16 distance-based schemes,17–23 and location-based schemes.24–27
Probabilistic schemes do not need any information from the whole network and need not maintain a global distributing topology, but, rather, start of building a network with each broadcast domain. In probabilistic schemes, all nodes are allowed to participate in the broadcast process and forward the received broadcast message with some probability. Therefore, the traffic load would not aggregate on a part of nodes. Furthermore, the interest in probabilistic broadcasting schemes is due to their inherent low transmission overhead, low processing complexity, low delay, and high tolerance to frequent and rapid topological changes. Balancing these benefits, though, is the disadvantage of inability to guarantee full network coverage and, still, the presence of some redundant transmissions.
Deterministic broadcast scheme includes tree-based scheme,28–31 connected dominating set (CDS), and neighbor elimination-based scheme.32–41 Tree-based schemes construct a routing tree on which broadcast messages are forwarded. In tree-based scheme broadcast redundancy minimization scheduling (BRMS),
31
a set of forwarding nodes are found first to minimize the number of broadcast transmissions. Then, the scheme constructs a forest of sub-trees based on the relationship between each forwarding node and its corresponding receivers. Finally, a broadcast tree is constructed by connecting all sub-trees with a minimum number of connectors. CDS and neighbor elimination-based schemes maintain state on the neighborhood of each node, via “Hello” packets. Upon the collected neighbor information, each node decides its role (forward node or non-forward node) in a specific broadcasting. For example, in local broadcast algorithms (LBA)
38
proposed by Majid Khabbazian, every broadcasting node selects at most one of its neighbors to rebroadcast the received message. A node has to rebroadcast the received message if it is selected to do. Other nodes that are not selected have to decide whether to rebroadcast upon a self-pruning condition called the coverage condition. To evaluate the coverage condition, every node u maintains a list
First, we proposed a neighbor knowledge-based broadcast (NKB) scheme for wireless ad hoc networks. In NKB scheme, few Hello messages are interchanged between one-hop neighbors to collect the neighbor information. The rebroadcast probability and the rebroadcast delay on each node are adjusted adaptively according to the obtained neighbor knowledge including the neighbor density, the ratio, and the number of one-hop uncovered neighbors. Second, a velocity-based data distribution mechanism is proposed and extended to NKB scheme to reduce the latency further, forming neighbor knowledge and velocity-based broadcast (NKVB) scheme. In NKVB scheme, few higher-velocity nodes are employed with bigger probability to forward the broadcast message, which makes NKVB different from NKB scheme, and they do accelerate the data transmission.
The rest of the article is organized as follows. Section “Related work” presents a brief review of broadcast schemes. Section “NKB scheme” presents NKB scheme. The velocity-based data distribution mechanism and NKVB scheme are presented in section “NKVB scheme.” Performance evaluation of NKB and NKVB schemes by simulations in the context of wireless ad hoc networks is presented in section “Performance evaluation.” Finally, section “Conclusion” concludes the article.
Related work
Probabilistic broadcast schemes only need to maintain rough local topology knowledge, which makes it more insensitive to node mobility than deterministic broadcast schemes. Probability-based schemes2,8 use some basic understanding of the network topology to assign a constant forwarding probability to each node to rebroadcast. The fixed probability schemes do not need to collect the beacon information, including density, speed, and energy, and so on, upon which the optimal rebroadcast probability is calculated in the adaptive probability schemes. 1 GOSSIP1(p) 8 is a pure gossip scheme with the fixed rebroadcast probability. When a node first receives a route request, with probability p, it broadcasts the request to its neighbors and with probability 1 – p, it discards the request. If the node receives the same route request again, it is discarded. The fixed probability schemes cost less control overhead. But the constant rebroadcast probability makes the schemes function not so well in dynamic and asymmetrical network environment. In reliable gossip-based broadcast protocol (RGB) 7 and velocity and neighbor density-based broadcast scheme (VDNB), 11 the dynamic rebroadcast probability is calculated upon the immediate number of neighbors of the node. Compared with the fixed probability schemes, they are more suitable for wireless ad hoc networks.
In dynamic counter-based broadcasting scheme (DCB), 15 the number of neighbors is used to determine whether the node is located within dense, medium distribution or sparse regions and assign Cmin, Cmid, and Cmax thresholds, respectively. Each node needs to wait for a random assessment delay. Within the delay, the number of copies of the message received by a node is compared with Cmin, Cmid, and Cmax, and then the corresponding one of four different rebroadcast probabilities is assigned to the node. In Humoud et al., 13 only two thresholds, unlike in Yassein et al., 15 are used to evaluate the node distribution and the rebroadcast probability is rougher. In Tseng et al., 12 the decision to forward the broadcast message is determined by the function C(n) where n is the number of neighbors of the forwarding node.
In distance-based broadcast scheme, 17 whether a message is rebroadcasted or not is up to the relative distance between the mobile node and the previous sender. When a node receives a broadcast message from a neighbor node for the first time, its dmin is initialized with the distance between them and the count is initialized with 1. If dmin < D (where D is the distance threshold pre-defined), the node stops rebroadcasting. Else, the node waits for a random number of slots, during the waiting period, every time a copy of the broadcast message is received, dmin and D are reassigned correspondingly. If dmin < D, the node stops rebroadcasting. Else, if the waiting time is expired, the node rebroadcasts the received message. In distance and cooperation based broadcast (DCBB), 23 four neighbor nodes at most are determined to forward broadcast packets based on the number of neighbors and the distance between neighbors. The limited number of relay nodes is helpful to reduce the redundancy of the scheme. DCBB is applicable to densely distributed network environment.
In location-based broadcast schemes,26,27 the rebroadcast probability of a node is in positive correlation with its additional coverage ratio. In order to figure out an accurate additional coverage ratio, the rebroadcast delay is set without exception on each node to collect enough neighbor coverage information. In scalable broadcast algorithm (SBA), 26 three node-stamping broadcast algorithms, named basic stamping, advanced stamping, and hybrid stamping, are proposed. Each node in advanced stamping algorithm collects its one-hop neighbor information. IDs of each forwarding node and its neighbors are appended to stamp in advanced stamping scheme. When node r receives a broadcast message m for the first time, it uses the stamp of m to check whether all its neighbors N(r) are already covered. If so, the rebroadcast is stopped; otherwise, node r appends id(r) and id(N(r)) to the stamp and schedules for rebroadcasting. Hybrid stamping utilizes two-hop neighbor information for pruning. With hybrid stamping, each node further checks whether some of its neighbors can also be reached by other nodes in the stamp. When node r receives a new message m, it checks whether its neighbors N(r) are all contained in the stamp of m first. For each neighbor n not contained in the stamp, node r then tries to check whether a neighbor p in N(n) is in the stamp. If node p has a higher priority than node r, node r can assume node n will be covered by broadcasting from node p or node with an even higher priority. If all uncovered neighbors in N(r) will be covered by node with higher priority, the rebroadcast is stopped by node r; otherwise, node r appends id(r) and id(N(r)) to the stamp and schedules for rebroadcasting.
In neighbor coverage-based probabilistic rebroadcast (NCPR), 27 the proportion of the common neighbors between node ni and its upstream node s uniquely determines the rebroadcast delay Td(ni) of node ni, and the rebroadcast delay of node ni is defined as follows

where MaxDelay is a small constant delay; N(s) and N(ni) are the neighbor sets of node s and ni, respectively. |.| is the number of elements in a set. In NCPR, another parameter, the connectivity factor, is defined to provide the node density adaptation. The connectivity factor Fc(ni) and the additional coverage ratio Ra(ni) of node ni are defined as follows
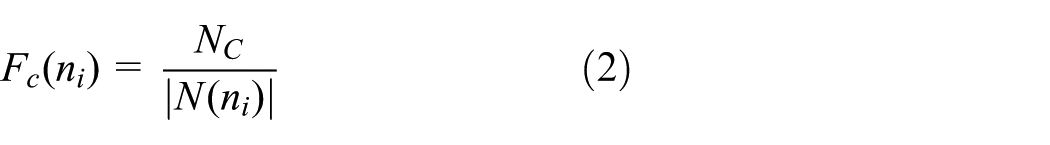

where Nc = 5.1774 log n, and n is the number of nodes in the network. |U(ni)| is the number of uncovered neighbors of node ni. By combining the additional coverage ratio and the connectivity factor, the rebroadcast probability of node ni is calculated as follows

The proposed rebroadcast delay is one of main contributions of NCPR. It determines the rebroadcast order, and then the more accurate additional coverage ratio is obtained. 27 We found that, in NCPR, more neighbors a node has, more likely it is to rebroadcast the message in less time. Namely, the way that the rebroadcast delay and the rebroadcast probability are calculated is inclined to incur the traffic aggregation.
In NKB scheme, we focus on defining the rebroadcast delay and the rebroadcast probability more reasonably to balance the traffic load, reduce the collisions and lower the end-to-end delay, which improved the reliability and the scalability of the scheme. For adaptability purpose in mobile environment, for example in disaster and battlefield scenario, few higher-velocity nodes are employed with bigger probability to rebroadcast the message in enhanced NKVB scheme, which lowers the delay further.
NKB scheme
In NKB scheme, the rebroadcast probability is adjusted adaptively at each node according to its neighbor knowledge. The neighbor knowledge includes the ratio of uncovered neighbors, the number of uncovered neighbor, and the neighbor density. The neighbor knowledge is obtained at each node by exchanging Hello message. In order to sufficiently pursue lower average end-to-end delay, exploit more accurate uncovered neighbors set, and avoid channel collisions, a proper rebroadcast delay is set at each node.
For research purpose, the network can be represented by an undirected graph
Collection of neighbor information
Hello message is used to collect a node’s one-hop neighbor information in NKB scheme. To reduce the overhead of Hello message, piggybacking is used. Moreover, piggybacking of the Hello message by broadcast packet could make the neighbor information fresher. Only when the time elapsed from the last broadcasting packet is greater than a Hello Interval, the node needs to send a separate Hello message.
In NKB, Hello message of node ni includes the following:
N(ni): a neighbor list of node ni;
M(ni): an ID list of broadcast messages received;
flag_leaf: if node ni is a leaf node, flag leaf is set to 1. Otherwise, this field is excluded from Hello message.
Definitions
leaf node: A leaf node has only one neighbor; it is a special kind of node who locates at the boundary.
secondary leaf node: It is a kind of node who is the neighbor of a leaf node.
Uncovered neighbors set
When node ni receives a fresh broadcast message from the upstream node ns, their common neighbors receive it too because of the broadcast nature of radio communication, as shown in Figure 1. Upon both node ns’s neighbor list and its own neighbor list collected by the Hello message, node ni can figure out who are their common neighbors and deduce its uncovered neighbors set. If node ni has more neighbors uncovered by the broadcast message, it is reasonable for node ni to rebroadcast the message with a bigger probability. The uncovered neighbors set U(ni) of node ni is defined as follows

where N(ni) and N(ns) are the neighbor sets of node ni and ns, respectively.
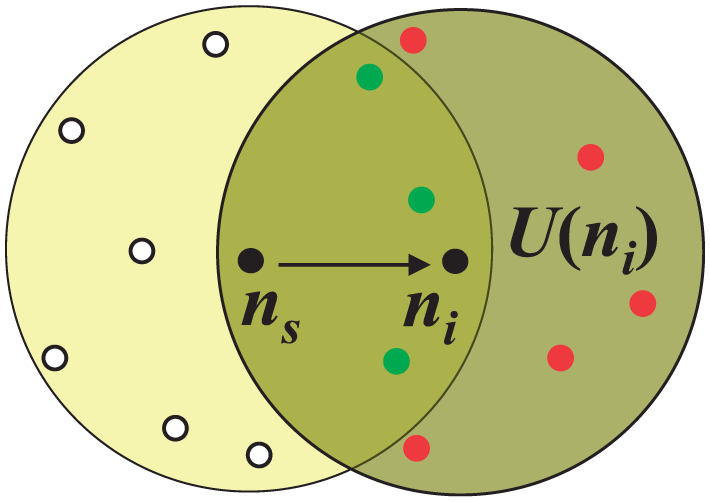
Neighbor set and uncovered neighbors set.
In NKB scheme, each node sets a rebroadcast delay (defined in section “Rebroadcast delay”) when it receives a fresh broadcast message, to exploit its accurate uncovered neighbors set. When node ni receives a duplicate message during the rebroadcast delay, for example from its neighbor node nj, node ni should update its uncovered neighbors setU(ni) according to formula (6). The uncovered neighbors set U(ni) is being updated until the rebroadcast delay expires

Rebroadcast probability based on neighbor knowledge
In proposed broadcast scheme, the neighbor knowledge, including the ratio of uncovered neighbors, the number of uncovered neighbors, and the neighbor density, is used to calculate the rebroadcast probability at each node.
Ratio of uncovered neighbors
As soon as the rebroadcast delay expires, node ni will calculate the ratio of uncovered neighbors Ru(ni) as follows

where |.| is the number of elements in a set and
If node ni has a big ratio of uncovered neighbors, it is reasonable for ni to rebroadcast the received message with a big probability to cover more fresh nodes. On the contrary, if node ni has a small ratio of uncovered neighbors, the smallest possible rebroadcast probability should be adopted by ni to reduce redundancy and collisions without hurting the packet delivery ratio.
Density factor and absolute number of uncovered neighbor factor
We assume that node nh and ni are neighbors of the upstream node ns and receive the same broadcast message from node ns. If they have the same ratio of uncovered neighbors but the different numbers of uncovered neighbors, it is reasonable for the node with more uncovered neighbors to rebroadcast the message with a bigger probability. Even when a node has a small ratio of uncovered neighbors, but a big absolute number of uncovered neighbors, it is worth rebroadcasting the message with a big probability.
Besides the number of uncovered neighbors, the neighbor density also affects the rebroadcast probability. When node ni is in a denser area, a smaller rebroadcast probability adopted avails to reduce the redundancy and the collisions. However, a bigger rebroadcast probability should be adopted to keep a higher packet delivery ratio in a sparser area.
Xue and Kumar 42 concluded that if each node connects to more than 5.1774 logN of its neighbors, then the probability of the network being connected is approaching 1 as N increases, where N is the number of nodes in the network. We use 5.1774 logN, denoted by Nc, as a reference value to evaluate the absolute number of uncovered neighbors and the neighbor density. The density factor d(ni) and the absolute number of uncovered neighbor factor Fu(ni) are defined as follows
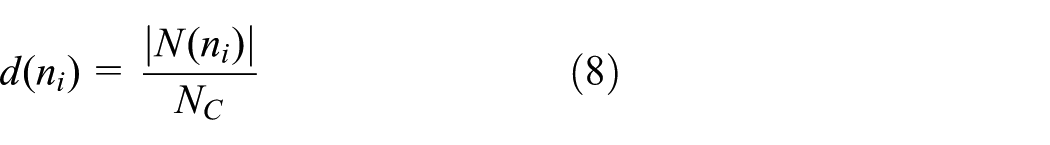

Rebroadcast probability based on neighbor knowledge
Combining the ratio of uncovered neighbors, the absolute number of uncovered neighbor factor, and the density factor, we have node ni’s rebroadcast probability pk(ni) based on its neighbor knowledge

where β and (1 – β) are the influence coefficients of Ru(ni) and Fu(ni), respectively. If pk(ni) is greater than 1, we set pk(ni) to 1. The value of β is related to node density and node distribution. In even and dense network, a big value of β assigned benefits reducing the collisions and the delay, and upgrading the reliability. A small value of (1 – β) is helpful to improve the packet delivery ratio in sparse area. A number of experiments, which are not emphases mentioned here, were done to prove it. And as a result, the empirical value of β is set to 0.8 in the following simulation in section “Performance evaluation.”
But, if node ni is an uncovered secondary leaf node, whose leaf node is nj as shown in Figure 2, it should rebroadcast the message with probability 1 for node nj. In addition, nj should give up the rebroadcast as a last node on the forwarding path. Finally, we have the rebroadcast probability pk(ni) as follows


Leaf node and secondary leaf node.
Rebroadcast delay
The definition of the rebroadcast delay is critical for the scheme to achieve optimal performance. The common neighbor ratio of node ns and node ni, denoted by Rc(nsi), and the absolute number of uncovered neighbors influence the rebroadcast delay in a different way. Rc(nsi) is defined as follows

where
The rebroadcast delay ratio Rd(ni) and the rebroadcast delay Td(ni) are defined as follows
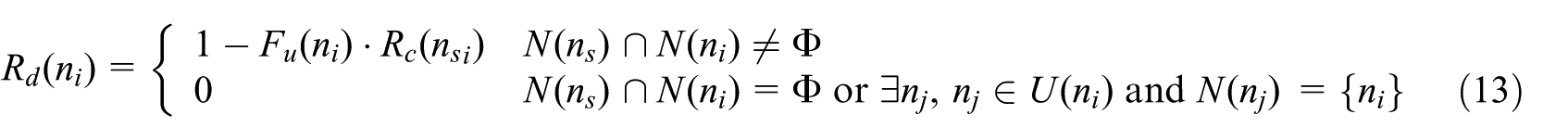

where Δ is a small constant delay. When there is no common neighbor between node ni and ns or ni is a secondary leaf node, Rd(ni) and Td(ni) are set to 0. If Rd(ni) is smaller than 0, we set Rd(ni) to 0.
Next, the details that the rebroadcast delay is defined are explained. Suppose node ni receives a fresh broadcast message from its upstream node ns, their common neighbors receive the message too.
If node ni has more uncovered neighbors, namely a bigger Fu(ni), it should rebroadcast the received message with a smaller rebroadcast delay to make the message cover more fresh nodes as soon as possible. In this condition, the smaller delay is helpful to accelerate the message propagation and reduce the average end-to-end delay.
If N(ns) ∩ N(ni) = Φ, namely there is no common neighbor between node ns and node ni, node ni rebroadcasts the message without delay (Td(ni) = 0) will not incur the collision. If
If bigger the common neighbor ratio of node ns and ni is, shorter the rebroadcast delay of node ni should be. Suppose node ni and node nj are neighbors of the upstream node ns. If the common neighbor ratio of node ns and node ni is bigger than the common neighbor ratio of node ns and node nj (
The first two points are obviously reasonable. We present the proof for the rationality of the third point in the following.
Proof

Note that
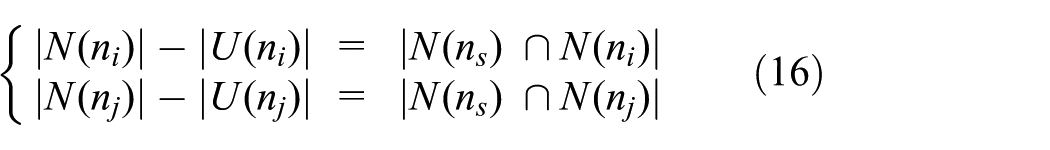
If Rc(nsi) > Rc(nsj), then

Formula (18) can be derived from formulas (16) and (17).

Formula (19) can be derived from formulas (15) and (18).
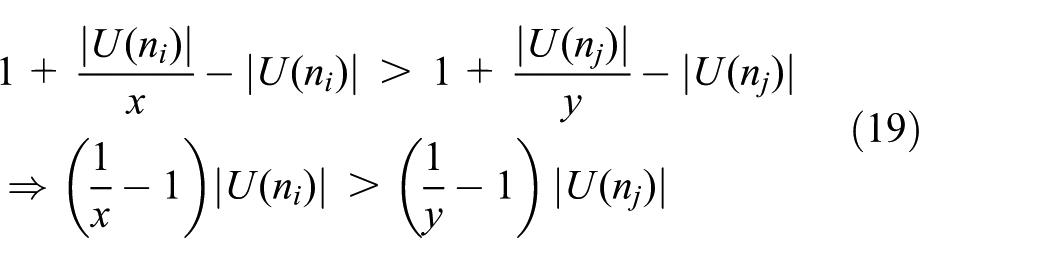

Combining formulas (19) and (20), we draw the conclusion as follows

NKB algorithm description
In NKB algorithm, the rebroadcast probability of node ni is determined by its neighbor knowledge. The formal description of NKB scheme is shown in the following.
The algorithm consists of three phases. In the first phase, U(ni) is initialized. If U(ni) = Φ, node ni refuses to rebroadcast the received message, else, Td(ni) is calculated. Next, if U(ni) ≠ Φ, U(ni) is being updated before Td(ni) expires. Finally, when Td(ni) expires and U(ni) ≠ Φ, pk(ni) is calculated and the message is rebroadcasted with probability pk(ni).
NKVB scheme
Several studies 43 draw the conclusion that the mobility increases the capacity of networks. However, it still is a big challenge for most of existing broadcast schemes to minimize the harm of node mobility. This section proposes a velocity-based data distribution mechanism. It stipulates that few higher-velocity nodes should be selected to rebroadcast the message with a big probability without delay to accelerate the data propagation. The mechanism is extended to NKB scheme to reduce average end-to-end delay further, forming NKVB scheme.

Velocity-based data distribution mechanism
Suppose node ni has ki neighbors, denoted by

The arithmetic mean of these neighbors’ velocities


The velocity-based data distribution mechanism stipulates strictly that node ni is allowed to rebroadcast the received message with the probability pv(ni) only if vi is bigger than

The overhead incurred by these employed high-velocity nodes is very limited. Assume that the node velocity obeys uniform distribution between vmin and vmax, the percentage PU of the nodes who take part in computing the rebroadcast probability is 0.21 calculated by formula (27)


Similarly, suppose the node velocity obeys normal distribution N(α, σ2), the percentage PN of the nodes who take part in computing the rebroadcast probability is 0.1587 calculated by formula (29)
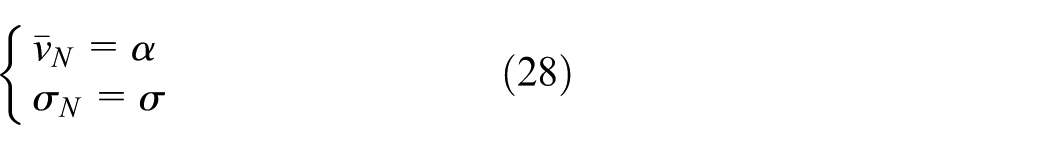
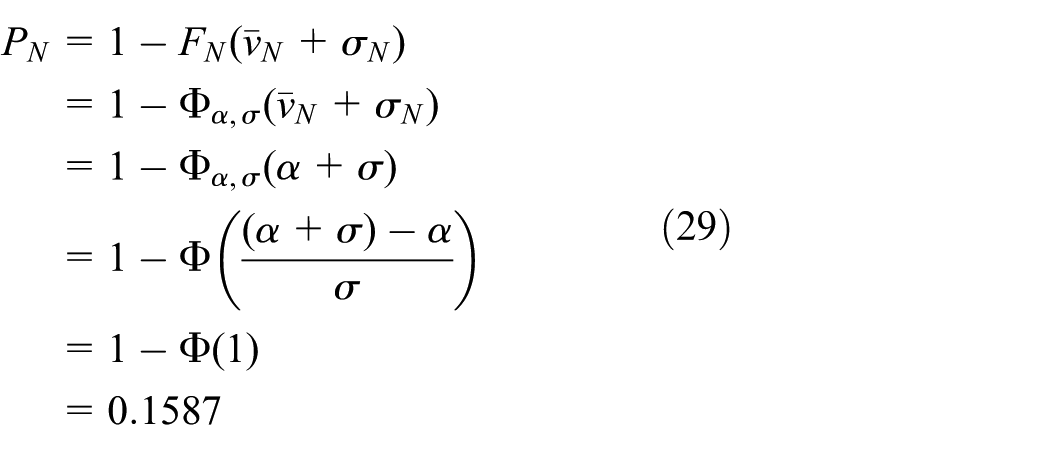
Note that ultimately, only few of nodes, who take part in computing the rebroadcast probability, are really employed to rebroadcast the message, so the proposed velocity-based data distribution mechanism incurs little overhead. It is also reconfirmed by the simulation result in section “Performance evaluation.”
NKVB algorithm description
In order to collect the neighbor nodes’ velocity, a new field vi, the velocity of node ni, needs to be added to Hello message. In NKVB algorithm, the rebroadcast probability of node ni is determined by both its velocity and its neighbor knowledge. The formal description of the NKVB algorithm is shown in the following.
The algorithm consists of three phases. In the first phase, U(ni) is initialized. If U(ni) ≠ Φ and
Performance evaluation
In this section, NKB and NKVB schemes are compared with flooding, 4 Gossip1(p), 8 DCB, 15 NCPR, 27 and LBA, 38 by simulation way using the NS-2(v2.35) 44 simulator. The IEEE 802.11 MAC with distributed coordination function (DCF) is used as the MAC protocol. The mobility model is based on the random waypoint model (RWM) in a square of size 1000 × 1000 m2. In the simulation of our schemes, the empirical value of β is set to 0.8. The rebroadcast probability p of Gossip1(p) is set to 0.65. The detailed simulation parameters are listed in Table 1.
Simulation parameters.

DCF: distributed coordination function.
We have used the following performance metrics for comparison purposes:
Normalized broadcast overhead: normalized broadcast overhead indicates the normalized transmissions of the broadcast operation per node. It defines the ratio of the total transmissions, including the broadcast packets and extra control packets to the broadcast packets per node. It is measured by bytes per broadcast byte per node.
Average end-to-end delay: the average delay of successfully delivered broadcast packets from source to destinations.
Packet delivery ratio: the percentage of nodes received the broadcast message.
The simulation is divided to three parts, and in each part, we evaluate the impact of one of the following factors on the performance of broadcast schemes. In the simulation results, each data point represents the average of 40 trials of experiments. The confidence level is 95%, and the confidence interval is shown as a vertical bar in the figures:
Mobility velocity. The max mobility velocity of nodes is modulated in range of 0–25 m/s to evaluate how the node mobility affects the performance of the schemes. In this part, the number of nodes and the number of CBR connections are set fixedly to 200 and 50, respectively.
Number of nodes. The number of nodes is modulated in range of 50–300 in a fixed square to evaluate how the node density affects the performance of the schemes. In this part, the max mobility velocity of nodes and the number of CBR connections are set fixedly to 15 m/s and 20, respectively.
Number of CBR connections. The number of randomly chosen CBR connections is modulated in range of 10–60 with a fixed packet rate to evaluate how the traffic load affects the performance of the schemes. In this part, the max mobility velocity of nodes and the number of nodes are set fixedly to 15 m/s and 200, respectively.

Effects of node mobility
Figure 3 shows that flooding and Gossip1(0.65) are deserved a high normalized broadcast overhead. The result is driven comprehensively by the high node density and their big rebroadcast probabilities. But their overhead curves are almost flat due to the fixed rebroadcast probabilities which are not affected by the node mobility. The normalized broadcast overhead of the other schemes increases proportional to the node mobility, namely, the node mobility has a negative impact on the reduction of overhead. It is because the node mobility directly brings about more control packets to repair the hurt communication link and to maintain the changed network topology. Furthermore, the topological variation may incur some collisions followed by the retransmissions. In some schemes, the node mobility as well gives rise to the imprecise neighbor information collected and the unnecessary rebroadcasts. As shown in Figure 3, when the mobility velocity is bigger than 15 m/s, there is a significant increase in the normalized broadcast overhead, especially for LBA and NCPR schemes.

Mobility velocity versus normalized broadcast overhead.
In LBA scheme, a node refuses to rebroadcast the received message only if it learned that all of its neighbors have been covered. In fact, it is almost impossible for each node to acquire the intact neighbor coverage knowledge in mobile environment. Then, many superfluous rebroadcasts are executed, leading to some incidental collisions and retransmissions. Therefore, in LBA scheme, the redundant broadcast is the main composition of the normalized broadcast overhead. In mobile environment, DCB scheme tends to define a rough threshold and count a wrong number of reduplicative packets received, which leads inevitably to the redundant rebroadcasts and collisions. Compared with LBA and DCB schemes, the normalized broadcast overhead of NKB, NKVB, and NCPR schemes is affected more mildly by the node mobility since their rebroadcast probabilities do not rely on the precise neighbor knowledge. Compared with Gossip1(0.65) and flooding, NKVB scheme saves 57.5%–84.9% overhead and 65.4%–88.4% overhead, respectively, as shown in Figure 3. Compared with NCPR scheme, NKVB scheme saves 16.2%–26.9% overhead.
Figure 4 shows how the node mobility affects the average end-to-end delay. Both Gossip1(0.65) and flooding keep a stable and higher average end-to-end delay. For the other schemes, as elaborated in Figure 3, the topological change incurs more collisions and retransmissions. Definitely, it leads to higher latency. The incomplete topology knowledge exceedingly amplifies the rebroadcast probability in LBA scheme, and then many redundant messages are rebroadcasted, which leads to a mass of channel competitions and collisions. Definitely, LBA deserves the worst average end-to-end delay among all schemes, especially when the nodes are moving at high velocity.

Mobility velocity versus average end-to-end delay.
In DCB scheme, the average end-to-end delay increases with the node mobility due to the incremental redundant rebroadcasts and collisions incurred by the inaccurate threshold and count of reduplicative packets. The rest of three schemes only need to maintain relatively rough topology knowledge, so, the node mobility has less influence on their average end-to-end delay than that of LBA and DCB. Both NKB and NKVB schemes outperform NCPR scheme far in average end-to-end delay, as shown in Figure 4, thanks to their reasonable rebroadcast delay and probability. Compared with Gossip1(0.65) and flooding, NKVB scheme reduces 53.4%–58.3% delay and 60.3%–63.6% delay, respectively. Compared with NCPR scheme, NKVB scheme reduces 25.2%–42.3% delay. And, there is an apparent difference that the first half of the curve of NKVB scheme shows a downward trend, which thanks to a part of higher-velocity nodes hired to rebroadcast the messages. These nodes do accelerate the propagation of messages.
As shown in Figure 5, the node mobility almost has no impact on the packet delivery ratio of flooding. Flooding always keeps its reliability at a high level, even when nodes are at high velocity. But the packet delivery ratio of the other schemes is affected in a negative way. The inherent deterministic broadcast mechanism makes LBA scheme obtain the best packet delivery ratio when the node mobility velocity keeps lower than 5 m/s and also makes it failed in high-velocity scenario. For DCB scheme, the changing of the topology reduces the accuracy of the threshold significantly, leading to the serious declining in the packet delivery ratio. The packet delivery ratio of NCPR, NKB, and NKVB schemes is influenced gently by the node mobility, because their rebroadcast does not rely on the accurate neighbor knowledge. Compared with the other three schemes, except for in low velocity scenario, NKB and NKVB scheme obtain a better packet delivery ratio in most scenarios. The simulation result above confirms that probabilistic broadcast schemes are more insensitive to node mobility than deterministic broadcast schemes as mentioned before, since they only need to maintain rough local topology knowledge.

Mobility velocity versus packet delivery ratio.
Effects of node density
How the node density affects the running of the broadcast schemes is illustrated in this section. As shown in Figure 6, at the very start, the normalized broadcast overhead of all schemes decreases with the increasing number of nodes. It is because the network connectivity is being enhanced by the joined nodes, and then every rebroadcast becomes more efficient to cover more fresh nodes. However, the continued increasing nodes inevitably bring about the collisions followed by retransmissions, which leads to the increasing normalized broadcast overhead afterward. When the number of nodes exceeds 200, the overhead curves of flooding, LBA, and NCPR start a noticeable uptrend. The overhead curves of NKB and NKVB schemes are relatively flat for their self-adjusted rebroadcast probability upon the network density. Compared with Gossip1(0.65) and flooding, NKB and NKVB schemes save 49.2%–67.5% overhead and 59.8%–75.8% overhead, respectively, as shown in Figure 6. Compared with NCPR scheme, NKB and NKVB schemes save 6.6%–41.4% overhead.

Number of nodes versus normalized broadcast overhead.
Different from the other schemes, the normalized broadcast overhead of DCB scheme almost decreases with the increasing number of nodes all the time. Because the value of threshold Cmax taken by DCB is not big enough in dense scenario, so the messages are rebroadcasted with smaller probability, reducing the collisions and the retransmissions. Accordingly, its average end-to-end delay also decreases with the increasing number of nodes as shown in Figure 7. Unfortunately, the inaccurate threshold Cmax also leads directly to the lower packet delivery ratio, as shown in Figure 8.

Number of nodes versus average end-to-end delay.
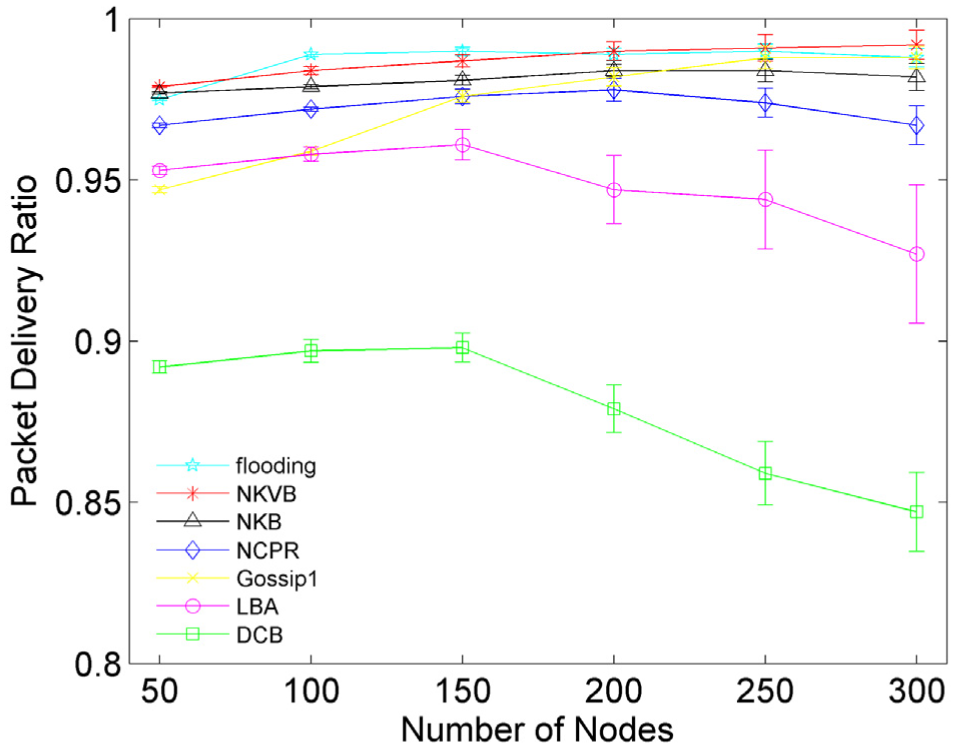
Number of nodes versus packet delivery ratio.
Figures 7 and 8 show how the node density acts on the average end-to-end delay and the packet delivery ratio. As mentioned before, the overhead decreases with the increasing nodes in sparse network environment. The increasing nodes make the rebroadcast more efficient, namely, lower delay and higher delivery ratio. In dense network environment, on the contrary, the increasing nodes incur more collisions and more retransmissions, increasing the end-to-end delay and deteriorating the delivery ratio. The increasing node density has a more serious and negative impact on the delay of flooding, compared with the other schemes, as shown in Figure 7. But flooding still keeps a stable and high packet delivery ratio. In NCPR, NKB, and NKVB schemes, the node density is taken into consideration when defining the rebroadcast probability and the rebroadcast delay, so the changing node density has less negative impact on their delay and delivery ratio. In NKB and NKVB schemes, some special nodes such as leaf node deserve a special treat in the process of broadcasting. Their rebroadcast parameters are defined more thoughtfully to deal with the node density than the other schemes do, which makes both schemes more reliable and efficient in complicated network environment. As shown in Figures 6–8, NKB and NKVB schemes outperform the other schemes especially in average end-to-end delay by 88.9% at most.
Effects of traffic load
How the traffic load affects the running of the broadcast schemes is illustrated in this section. As shown in Figure 9, without exception, the normalized broadcast overhead of all schemes increases with the growing traffic load, since more traffic load leads to more contentions and collisions. The high rebroadcast probability adopted by flooding and Gossip1(0.65) brings about a serious congestion, and the heavy traffic load aggravates the congestion further. LBA scheme rebroadcasts a great many redundant messages, so its overhead experiences a noticeable increase as shown in Figure 9. For DCB scheme, the main of the overhead originates from the retransmission.
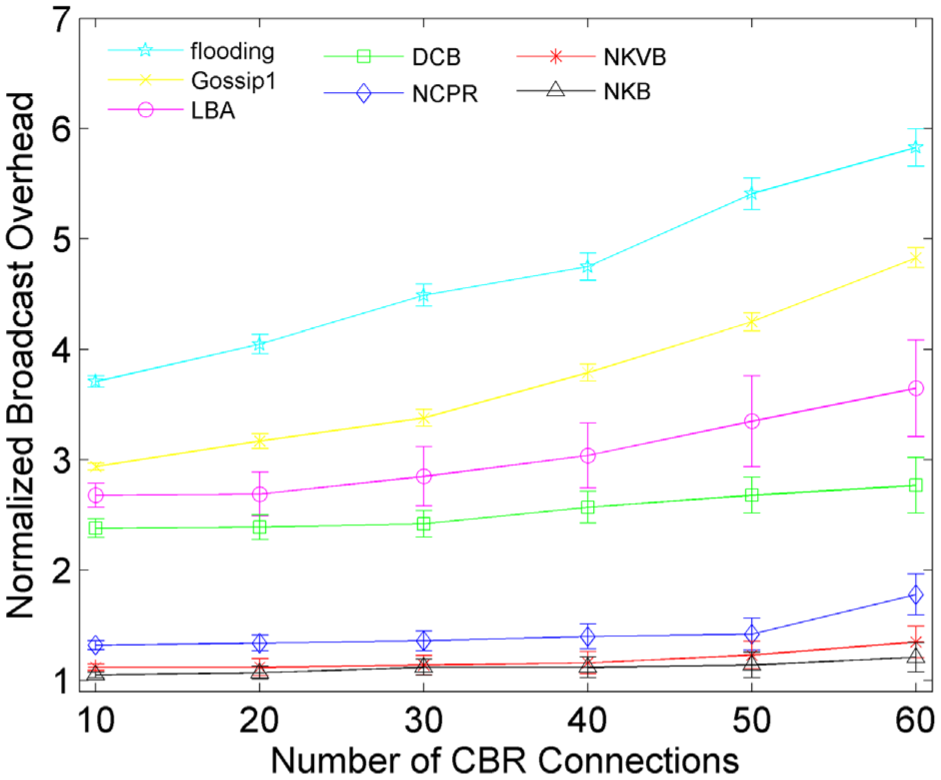
Number of CBR connections versus normalized broadcast overhead.
In NCPR scheme, the rebroadcast delay of a node is inversely proportional to the common neighbors between the upstream node and itself. Generally, it means that the nodes with more neighbors will rebroadcast the message more possibly after a smaller rebroadcast delay. Then, these nodes will forward more packets in less time than the other nodes around. Namely, the way that the rebroadcast delay and the rebroadcast probability are defined is inclined to incur the traffic aggregation. The situation becomes worse as the traffic load increases. As shown in Figure 9, there is a remarkable overhead fluctuation arising when CBR connections of NCPR scheme rise from 50 to 60. At the same time, there is a remarkable increasing of the average end-to-end delay and an obvious decreasing of the packet delivery ratio as shown in Figures 10 and 11, respectively.

Number of CBR connections versus average end-to-end delay.

Number of CBR connections versus packet delivery ratio.
Besides the ratio of uncovered neighbors and the neighbor density, the absolute number of uncovered neighbors is taken in consideration to calculate the rebroadcast delay and the rebroadcast probability in NKB and NKVB scheme. It makes the traffic load distribution relatively uniform and more reasonable. The contentions and collisions are restrained effectively. Therefore, the traffic load has less effect on NKB and NKVB scheme than that on the other schemes. Compared with flooding, the propose schemes save 79.2% overhead and reduce 79.1% delay at most, as shown in Figures 9 and 10.
Conclusion
We proposed NKB and NKVB schemes for wireless ad hoc networks. In both schemes, the neighbor density and coverage information are collected by Hello message to calculate the rebroadcast parameters in near real-time at each node. To reduce the overhead of Hello message and upgrade the validity of neighbor knowledge, piggybacking is used. One-hop neighbor information collected keeps the control overhead at a low level. The flexible calculation of the rebroadcast probability and delay guarantees a low average end-to-end delay as well as a high packet delivery ratio in complicated mobile environment. Moreover, the way we defined the rebroadcast delay and the rebroadcast probability is beneficial to balance the traffic load and improve the scalability of the schemes. In order to reduce the latency further, few higher-velocity nodes are employed to rebroadcast the received message in NKVB scheme. It makes NKVB scheme more adaptable to mobile environment. The simulation results show that the proposed schemes outperform the existing broadcast schemes in both reliability and overhead, especially in latency.
Footnotes
Handling Editor: Daniel Gutierrez-Reina
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by National Natural Science Foundation (NNSF) of China (61300198 and 61070092), and by Guangdong Natural Science Foundation (2015A030308017) and Guangdong Science and Technology Key Project (2015B010131009).