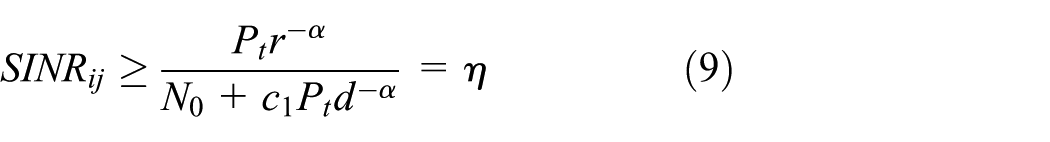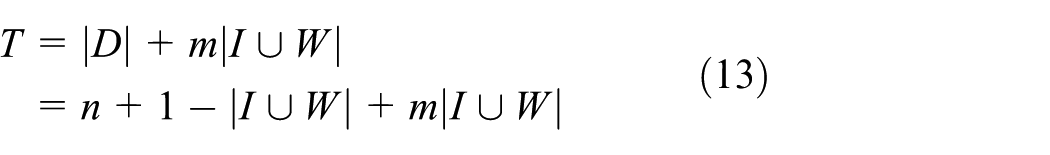We consider a joint routing and scheduling scheme for data collection in wireless sensor networks leveraging compressive sensing under the protocol interference model. We propose the construction of a connected dominating set as a network backbone for efficient routing. A hybrid compressive sensing technique, which combines conventional and compressive data gathering schemes, is used to aggregate data over the backbone. Pipelined scheduling is developed for fast aggregation of compressed data over the backbone. We set the communication range of sensor nodes to an appropriate value to control the size of the backbone and demonstrate that the proposed scheme can achieve order-optimal latency for data gathering. We extend the proposed scheme to the physical interference model and show that comparable latency is achievable under physical interference model. In addition, the proposed scheme is shown to be energy-efficient, in that it can achieve order-optimal energy consumption given that the sensor data sparsity is of constant order. Simulation results show the effectiveness of the proposed scheme in terms of latency and energy consumption.
Wireless sensor networks (WSNs) consist of low-cost and energy-constrained sensors that acquire and transmit environmental and contextual information to a data sink. WSNs are a key element in the emerging Internet of Things technology.1 Timely transmission of sensed data to the sink is important, particularly for applications such as emergency/catastrophe monitoring systems or mission-critical networks, which require low or strictly bounded latency for data collection. In this article, we consider a joint routing and scheduling scheme for data collection with compressive sensing (CS), which achieves order-optimal latency. The CS technique was originally proposed in the signal-processing literature; however, it has recently been applied to efficient data collection. The idea behind CS is to reliably recover a high-dimensional signal, that is, the original data vector, from a significantly smaller number of measurements.2 Surprisingly, exact recovery is possible with linear and non-adaptive measurements, which enables efficient sensing for data acquisition.2–5
Efficient collection of sparse data under the CS framework has attracted considerable attention. For example, Luo et al.6 proposed compressive data gathering (CDG) to collect data in WSNs using CS. In CDG, the sink collects linear combinations of sensed data rather than collecting all data samples individually. Once a sufficient number of linear combinations is collected, the sink can recover the original sparse data vector by solving an l1-based convex optimization problem.2 The main advantage of CDG is that it reduces sensor-node energy consumption and evenly distributes loads across the network. However, Luo et al.7 showed that applying CS naively, for example, CDG, may not improve performance because in CDG, nodes that are distant from the sink, for example, leaf nodes, may transmit more data (for times) than those in the conventional data gathering scheme (for one time for leaf nodes). Luo et al. proposed a hybrid CS scheme that encodes data only at overloaded nodes, for example, nodes close to the sink, unlike CDG, in which encoding is performed at each sensor. They demonstrated that the hybrid CS scheme can further improve throughput. Under the CDG framework, Ebrahimi and Assi8 considered not only energy consumption but also latency of data gathering. They formulated a joint optimization problem to collect data at the sink with both minimal latency and fewer transmissions. In addition, they proved that the problem was non-deterministic polynomial-time (NP)-hard. They also proposed a two-approximation method, which decomposes the problem into forwarding tree construction and link-scheduling subproblems. However, their scheme used the original CDG without modification. In contrast, the proposed scheme utilizes the hybrid CS scheme and considers both latency and energy aspects of data collection. Zheng et al.9 studied the capacity and delay of CS-based techniques for data gathering in WSNs under the CDG framework. They also considered the protocol interference model (PrIM).9,10 For a single sink case, they proposed a data gathering scheme that can achieve capacity and latency, where is the number of sensors in the network, is the capacity of each link, and is the sparsity of the data vector. However, a limitation of capacity-achieving schemes, such as the study of Zheng et al.,9 is that the schemes are typically built for regular-shaped networks, such as square networks. These schemes rely on a certain geometric structure of the network and node locations. However, practical WSNs may be deployed in an area with a highly irregular shape and node density. In contrast, we employ a graph-theoretic approach for joint routing and scheduling based on techniques proposed by Wan et al.11 This enables implementation of the proposed routing and scheduling scheme for networks of arbitrary shapes and topologies.
Recently, the energy efficiency of CS-based data gathering has been studied for WSNs. Karakus et al.12 compared the energy performance of CS-based schemes to conventional schemes under an energy dissipation model that considers the energy consumption of data acquisition, processing, and communication. Their measurement study using MICA motes demonstrated that network lifetime can be increased by applying CS to WSN data gathering. Under the CDG framework, Zhao et al.13 observed that determining the sparsity of raw data in WSNs may not be straightforward due to the randomness of sensor distribution. They proposed an energy-efficient treelet-based clustered compressive data aggregation (T-CCDA) scheme that jointly considers the sparsification basis and data aggregation routing. In T-CCDA, a treelet transform is adopted to determine the sparsity from the raw data, and a clustered routing algorithm is proposed to further facilitate energy-saving. Liu et al.14 proposed a nonuniform random projection-based estimation algorithm for compressive data collection using a power-law decaying data model under the CDG framework. Their scheme required fewer compressed measurements and allowed a simple routing strategy without excessive computation and overhead. They proved that their algorithm could achieve the optimal estimation error bound. Zhao et al.13 and Liu et al.14 both used CDG without modification, that is, each node in the data collection path must compress data. However, we construct a backbone for routing and aggregate the data over the backbone using the hybrid CS technique. This reduces the total number of transmissions in the network, which leads to further energy-savings because the backbone tends to be relatively small. Xu et al.15 observed that hybrid CS utilizes only a small fraction of sensors due to inefficient network configurations. They proposed hierarchical data aggregation using compressive sensing (HDACS) based on an energy model that captures both processor and radio energy consumption. The idea behind HDACS is to optimize data transmissions by setting multiple compression thresholds adaptively based on cluster sizes at different levels of the data aggregation tree. However, latency is not considered in their scheme.
In this article, we propose a CS-based data collection scheme for low latency and energy consumption. The proposed scheme exploits the graph-theoretic structure of the underlying network, which we refer to as the connected dominating set (CDS). We construct a network backbone for efficient routing using the CDS and develop a joint routing and scheduling scheme. We leverage the hybrid CS technique such that raw data from non-backbone nodes are aggregated to the backbone. Then, linearly combined data are routed and scheduled over the backbone in a pipelined manner. Since the proposed scheme is based on a network graph, it differs from previous schemes based on particular network geometry, for example, square networks,9 as follows. (1) The proposed scheme can be implemented on networks of arbitrary shapes and topologies; thus, it is more general than schemes designed for square networks. (2) The proposed scheme leverages a network graph induced from the spatial node distribution; thus, it can construct a smaller backbone compared to those based on square networks. Simulation results show that the proposed approach leads to less latency and energy consumption.
To demonstrate the efficiency of the proposed scheme theoretically, we analyze its performance on a random planar network. The scheme achieves latency given by with high probability, which improves the result obtained by Zheng et al.9 Moreover, this latency is order-optimal (given by ) provided that , which is commonly assumed for sparsity in the CS literature. We extend the proposed scheme to the physical interference model (PhIM), in which all receivers must satisfy a predetermined signal-to-interference-plus-noise ratio (SINR) requirement. We demonstrate that the proposed scheme is also energy-efficient, by showing that the total number of transmissions in the network is small. It is proved that our scheme consumes at most times the minimum energy, implying that it is order-optimal if . We perform a simulation to evaluate the energy performance of the proposed scheme and show that it outperforms the existing methods. In particular, the proposed scheme shows superior performance relative to energy consumption even when grows faster than .
The contributions of this article can be summarized as follows:
A graph-based algorithm is developed under PrIM and can be applied to networks of arbitrary shapes and topologies, unlike many conventional schemes that assume a specific network geometry, for example, square networks.9
The proposed scheme achieves order-optimal latency for data collection under PrIM.
We extend our scheme to PhIM10 and show that comparable latency is achievable.
The proposed scheme is shown to achieve order-optimal energy consumption if data sparsity is . Simulation results show that the proposed scheme has good energy performance even when data sparsity grows faster than .
The remainder of this article is organized as follows. We introduce the system model in section “System model.” In section “Proposed scheme,” we describe the proposed data collection scheme. Analysis of the proposed scheme for a random square network is presented in section “Latency analysis.” Section “PhIM” extends our scheme to a PhIM. Energy consumption is discussed in section “Energy consumption.” Simulation results are provided in section “Simulations,” and conclusions and suggestions for future work are presented in section “Conclusion and future work.”
System model
Here, we briefly introduce the CS technique, where the following linear model is considered
where is the measurement vector, is the original data vector, and is referred to as the sensing matrix. A vector is considered k-sparse in a basis if , and the number of nonzero entries in does not exceed . In CS, the sensing matrix is typically a random matrix. Note that a Gaussian random matrix is widely used, that is, each entry of is drawn i.i.d. from the Gaussian distribution . It is known that if and , a k-sparse vector can be recovered with high probability via linear programming.2,16 In this article, we assume that the original data vector can be reliably recovered if a sufficient number of measurements are gathered at the sink. We focus on the efficient collection of a given number of measurements from the sensors.
Here, we consider a network with sensors deployed in an area where is the sink node. Sensor acquires a reading denoted by . The collection of sensor readings, that is, , is referred to as the data vector. We assume that all nodes in the network share a common wireless channel. We denote the Euclidian distance between node and as . We consider a time-slotted system wherein time slots are of equal duration and assume that a node can transmit a unit-size packet during each time slot. In this article, PrIM is considered as follows. We assume a common range for node transmissions. Node can successfully transmit data to if (1) and (2) for concurrent transmitters , where is a constant. In PrIM, any two transmitters that are at least distant from each other, where , can transmit data simultaneously. We construct a communication graph induced by PrIM where , and an edge exists if .
Next, we briefly describe how to apply CS to data collection. In CS, the linear model is considered, where is the measurement vector, is the original data vector, and is the sensing matrix. A signal is said to be k-sparse in basis if , and the number of nonzero entries in does not exceed . Assume is a Gaussian random matrix, that is, each entry of is drawn i.i.d. according to the Gaussian distribution . If and , can be recovered from linear combinations where denotes the element of with high probability via linear programming.2
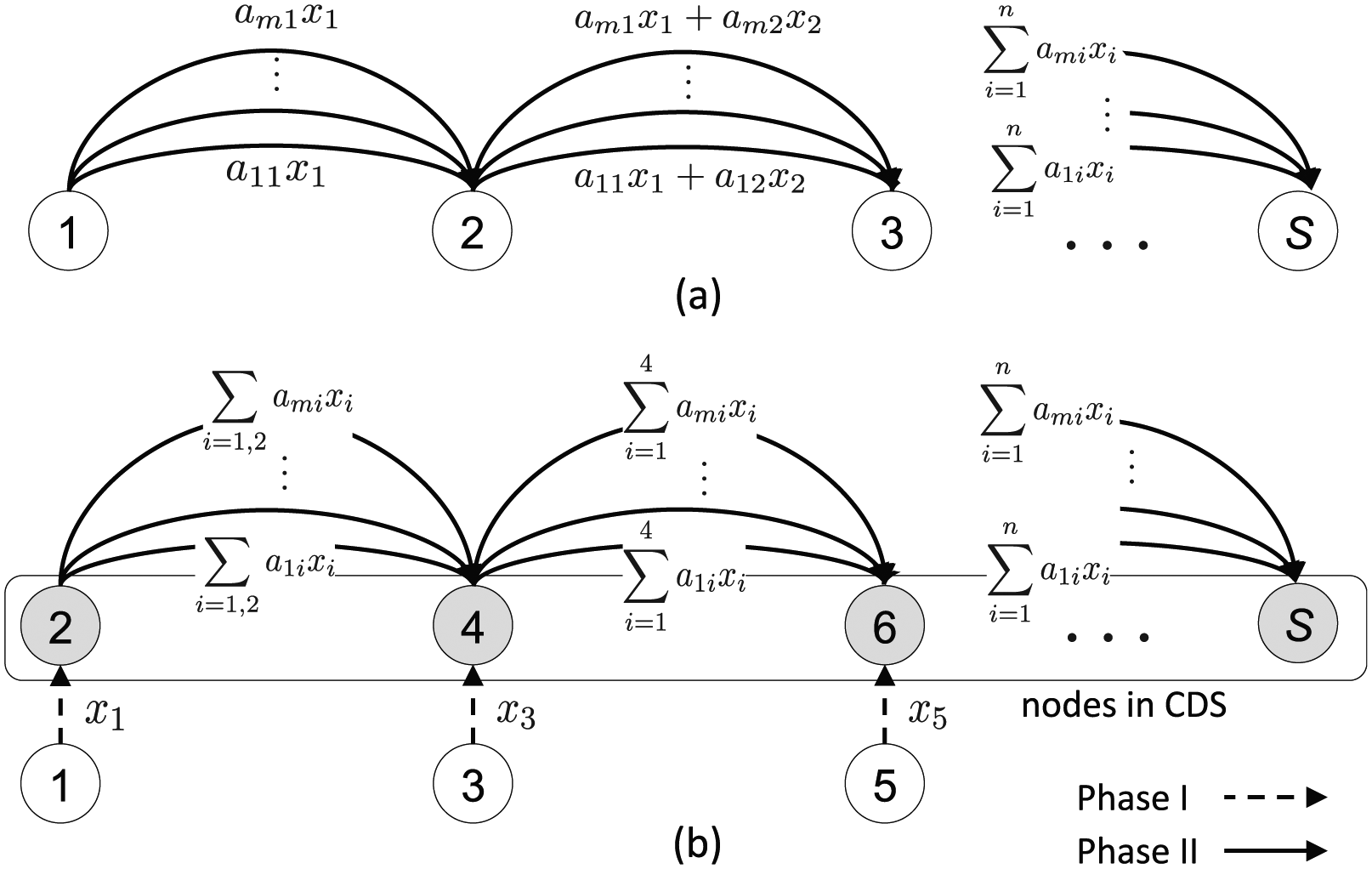
Figure 1(a) shows CDG, in which each node combines its data linearly with the data received from the node at the previous hop. The number of transmissions at any link is ; thus, CDG only requires a few transmissions per link and balances the load across the network.
Comparison of: (a) CDG and (b) proposed scheme for linear networks. Shaded nodes belong to CDS.
Proposed scheme
In the proposed scheme, we first construct a backbone that consists of nodes with a large transport gain, that is, the backbone enables efficient routing to the sink in a relatively small number of hops. Next, we schedule data collection in two phases. In Phase I, non-backbone nodes transmit raw data to the backbone. In Phase II, backbone nodes transmit linearly combined data toward the sink in a pipelined manner. Thus, the pipelined data aggregation takes place only among the backbone nodes, which can substantially reduce latency. An outline of the proposed scheme is shown in Figure 1.
Our scheduling method is inspired by hybrid CS proposed by Luo et al.;7 however, the key differences are (1) backbone construction leveraging CDS, (2) pipelined scheduling over the backbone, and (3) the backbone is constructed based on a graph-theoretic framework; thus, the algorithm can be applied to networks of arbitrary shape and topology, whereas Luo et al.7 outlined a scheme for square networks.
Routing
Here, we consider routing in the proposed scheme. First, we present some definitions.
Definition 1
A subset is a dominating set of if each node in is adjacent to some node in . is a CDS if the subgraph induced by is connected.
Definition 2
A subset is an independent set (IS) of if no two nodes in are adjacent.
Definition 3
An IS is a maximal independent set (MIS) of if is not an IS for any .
Definition 4
The radius of , denoted by , is given by , where denotes the distance of the shortest path between and sink node .
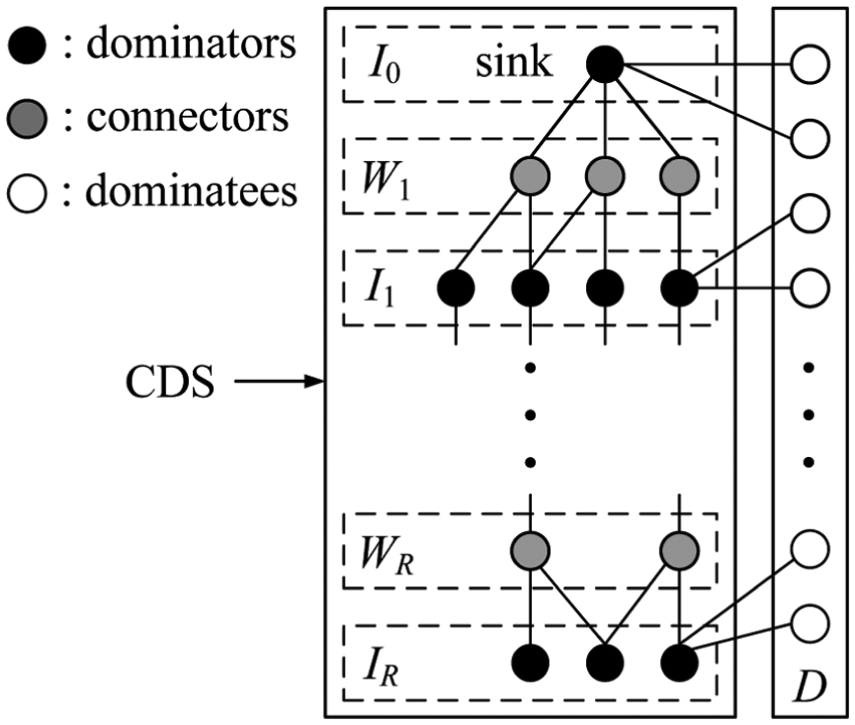
We adopt a widely used method proposed by Wan et al.11 to construct the CDS as follows. Given , we first find an MIS in which nodes are referred to as dominators. Then, we divide into the following levels. Let be the graph induced by where an edge between two dominators exists if and only if they share a common neighbor in . The radius of is denoted . Level consists of dominators of depth in . Next, we connect two adjacent levels and as proposed by Wan et al.11 Suppose is the set of nodes that connect and . The nodes in are called connectors. CDS is given by . Based on the distance to the sink, the increasing order of levels in CDS is given by . Finally, the set of non-CDS nodes is denoted by . We refer to non-CDS nodes as the dominatees. Figure 2 shows an example of the routing scheme.
Proposed routing scheme.
The routing procedure is completed by designating the next-hop nodes for CDS and non-CDS nodes as follows:
CDS nodes. Each node in CDS randomly selects a neighbor that belongs to the lower level as its receiving node. Specifically, a node in (resp. ) selects a neighbor in (resp. ) as its receiving node.
Non-CDS nodes. Dominatee selects the closest dominator as its receiving node, denoted by .
Scheduling
The scheduling procedure is divided into two phases (Algorithm 1).
Algorithm 1 Data Collection Scheduling
1: Input, 2: Phase I: schedule transmissions between and . 3: Construct a graph where an edge exists if . 4: Color nodes in such that any two adjacent nodes have different colors. Let be the total number of colors and be the color of dominatee . 5: fordo 6: Each dominatee with transmits its raw data to at the ith time slot. 7: end for 8: Phase II: schedule transmissions among the nodes in CDS. 9: :=(starting time of level Ij’s transmission during the ith round). 10: :=(starting time of level Wj’s transmission during the ith round). 11: /* Phase II starts at time slot */ 12: for do 13: fortodo 14: . 15: . 16: end for 17: . 18: . 19: end for
In Phase I, we schedule the transmissions between dominatees and dominators. First, we construct the graph (Algorithm 1, line 3) and then color each node in such that no two adjacent nodes are the same color. Note that the Euclidian distance between and is greater than if . Thus, and can transmit data concurrently. Each dominatee transmits the raw data to its receiving node. Thus, one transmission is sufficient for each dominatee to complete the data collection.
In Phase II, we adopt the CDG scheme to collect linear combinations of raw data. Specifically, the sink collects measurement during the ith round. Each node in CDS transmits the linear combination of its data and those from its receiving nodes during each round. Note that a dominator may have the raw data of its corresponding dominatees, which are collected in Phase I. During each round, we schedule the transmissions of CDS nodes using sequential aggregation scheduling (SAS)11 for . SAS assigns time slots to and time slots to , where . We also pipeline the transmissions between adjacent rounds based on levels. For example, can transmit at the round concurrently with at the ith round because the distance between the nodes in and is at least .
Latency analysis
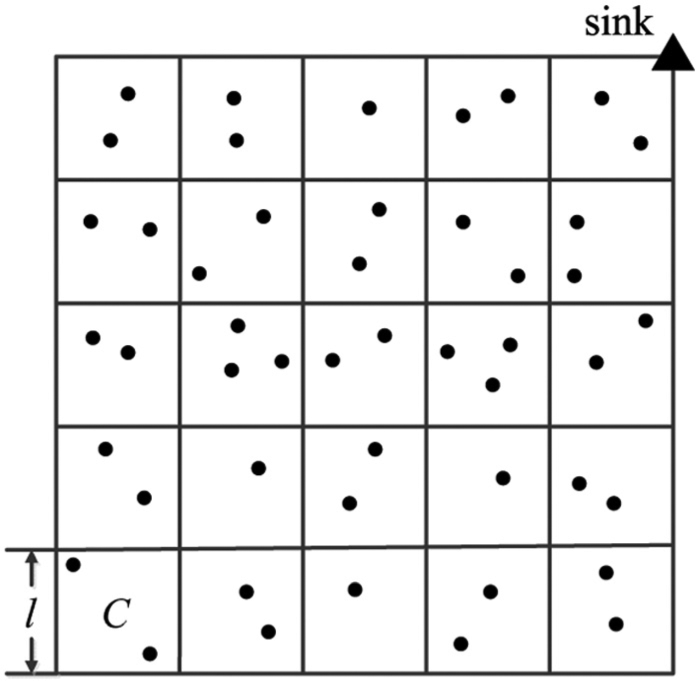
In this section, we analyze the latency performance of the proposed scheme. Although our scheme can be applied to networks of arbitrary shape and topology, it is difficult to analyze performance on arbitrary networks. Instead, for performance analysis, we consider a random planar network. Suppose sensors are deployed uniformly at random over a unit square where the sink is located at the top right corner (Figure 3). We demonstrate that the proposed scheme achieves order-optimal latency under this model. Throughout this section, we assume that , which ensures network connectivity.17
Partitions of the unit square network.
Lemma 1
For a large , the latency of any scheme under PrIM is at least with high probability.
Proof 1
We divide the network into square cells of size , where . Let be the cell located at the bottom left corner, that is, cell is farthest from the sink. Clearly, the overall latency of data collection is bounded below the worst latency experienced by a node in .
Let be the number of nodes in . Here, , where denotes binomial distribution. From Chebyshev’s inequality, for some , we have
From equation (2), for a large , the number of nodes in is with high probability, which can be expressed as
where
Thus, equation (3) implies that the variation in centered at in equation (2), which is given by , is ; thus, is with high probability. Moreover, any two nodes in cannot transmit data simultaneously because their distance is less than . Thus, it takes at least time slots to complete the transmissions in because all nodes in must transmit data at least once.
Now consider node , which is the last node to transmit in . Here, it must have waited for time slots. In addition, the packet generated by must be relayed to the sink. However, for any packet generated within , it takes at least time slots to reach the sink. Thus, the total latency experienced by is at least . The lemma is proved by “minimizing” with respect to or by letting , which yields latency of .
Lemma 2
Suppose . For a large , the maximum degree of nodes in is at most with high probability.
Proof 2
Consider a dominatee . The number of nodes in where is the disk rooted at and with radius is denoted . Here, . From Chebyshev’s inequality, for some
where equation (4) follows from the assumption that . This implies that for a large , the maximum degree of nodes in is at most with high probability.
Now, we are ready to prove our main theorem.
Theorem 1
Let . For a large , our scheme achieves latency with high probability. Thus, if , is given by , which is order-optimal.
Proof 3
Let us first consider the latency of Phase I. Brooks18 showed that colors are sufficient to color nodes in , where is the maximum degree of nodes in , such that no two adjacent nodes receive the same color. Thus, from Lemma 2, the latency of Phase I is at most time slots.
Next, we compute the latency of Phase II. Consider two dominators and . We observe that holds, which implies that the radius of is given by . In Phase II, the latency of each round is .11 We pipeline the transmissions between adjacent rounds for rounds; thus, the latency of Phase II is from Lemma 2. Therefore, the overall latency is given by
which reduces to if . This completes the proof.
Finally, note that the optimal transmission radius is sufficient for network connectivity because it exceeds the critical transmission range,17 that is, .
PhIM
We extend the proposed scheme to PhIM. We assume that each node transmits data at a common transmit power denoted by . Under PhIM, receiver can successfully receive data from a transmitter if and only if the SINR in satisfies
where is a constant, is ambient noise, is the path loss constant, and is the set of concurrent transmitters with .
The proposed scheme under PhIM is as follows. We use a protocol similar to that used in PrIM such that the transmitter and receiver must be within distance and two nodes can transmit data concurrently only if their distance is greater than for some . Note that is adjusted as a function of . Here, the question is that for a given , can we determine and such that the SINR requirement (equation (5)) is satisfied at every receiver?
Lemma 3
There exist constants such that any receiver under the proposed scheme satisfies the SINR requirement (equation (5)) with and .
Proof 4
Let . In Figure 4, the distance between any two transmitters is . Consider a transmitter which is transmitting data to the receiver . Suppose is the set of concurrent transmitters. We group all transmitters in into the following layers. The transmitters that are away from are grouped into the first layer, and transmitters that are away from the transmitters in the lth layer are grouped into the layer. Here, there are at most transmitters in the lth layer. Furthermore, the distance between any transmitter in the lth layer and receiver is at least . The interference at receiver satisfies
where inequality (6) comes from , inequality (7) comes from , and equation (8) holds since the Riemann zeta function converges for any . Consequently, SINR in the receiver satisfies
for and in the theorem, where the existence of constant to meet condition can be shown as follows. The condition on is given by
Side length of each equilateral hexagon is .
Thus, if , we can choose arbitrarily from the range to satisfy (equation (10)). If , can be any constant greater than 1.
With parameters and given by Lemma 3, the performance of the proposed scheme under PhIM is similar to that under PrIM. Thus, from Theorem 1, the following holds for .
Theorem 2
Latency is achievable with high probability under PhIM.
Energy consumption
In this subsection, we show that our scheme is energy-efficient; specifically, we demonstrate that the total energy consumption in the network is order-optimal under some assumptions regarding data sparsity. We first explain our model relative to energy consumption. We adopt a commonly used model for energy consumption in wireless networks.19 Here, we assume that there exists transmit and receive power (TX and RX, respectively) consumed in the radio communication of a packet between two nodes. Let and denote TX and RX power per bit, respectively. When a node receives a packet, the modem drives the radio frequency chain, which is the dominant part of the total power consumption. The measurement results show that such power is static, that is, it is approximately constant per bit. Thus, we assume is constant. In contrast, must be set sufficiently high to overcome path loss and thus, may depend on inter-node distances. We assume a perfect sleep schedule for power saving, that is, when a node does not transmit or receive, it immediately switches to sleep mode, in which power consumption is assumed to be negligible. Recall that the time spent in transmitting one data packet is assumed to be fixed. Thus, the energy consumed by transmitting and receiving a single packet is given by . Here, let denote the total number of transmissions in the network. The total amount of energy consumption is then given by .
In this section, we scale the network size differently than that of the previous section. Franceschetti et al.20 proposed two types of limiting regimes in their study into the capacity of wireless networks, referred to as dense and extended networks. In both models, it is assumed that nodes are uniformly distributed over the network. In the dense network model, the network area is fixed and the number of nodes tends to infinity. In the extended network model, the area of the network tends to infinity while maintaining a fixed node density. In this case, the network area is given by a square of size . The network considered in the previous section is the dense network model, whereas in this section, we consider the extended network model. The reason we consider extended networks is that in dense networks, will vanish as ; thus, only constant will dominate the total energy consumption. Therefore, the TX power plays no role in dense networks, and the energy performance depends only on static power . In contrast, the extended network model allows us to study the combined effects of routing strategies and power control on energy performance, as we will see in the sequel.
Here, we consider PhIM and assume that the Tx power is sufficient to cover the nodes in the transmission range to satisfy the SINR requirement in (equation (5)), for example, see the study of Zhao and Tong19 for a similar energy model.
Theorem 3
For extended networks, the total amount of energy consumption given by
is almost surely achievable under the proposed scheme.
Proof 5
Consider the proposed scheme under the PhIM presented in section “PhIM.” First, we compute the number of transmissions under the proposed scheme. In Phase I, each dominatee transmits its raw data to the closest dominator. Thus, the number of transmissions during Phase I is given by . In Phase II, each node in CDS transmits data times. As a result, the number of transmissions for Phase II is given by . Next, we bind the size of CDS using the following lemma by Oler.21
Lemma 4
Suppose a compact convex region contains non-overlapping disks of diameter 1. Then, the total number of disks is no more than
where and are the area and perimeter of region , respectively.
According to Lemma 4, the number of non-overlapping disks of diameter in a unit square is upper bounded by . Since is an MIS, we obtain
Here, we introduce the following lemma by Wan et al.11
Lemma 5
Each dominator in is adjacent to at most connectors in , that is, and . Each connector in is adjacent to at most dominators in , that is, .
According to Lemma 5, we have
where the last inequality follows from (equation (11)), and is a constant. Finally, the total number of transmissions in our scheme is given by
Finally, to ensure connectivity, we must set , where is the side length of the square network.19 Since we have , we set . Thus, the total energy consumption is , which, from equation (16), is almost surely .
Note that in the proof of Theorem 3, it is implied that . However, in practice, the TX power cannot increase without a bound. Instead, we can interpret the result as showing how the TX power scales with a growing network size. A similar argument was made by Zhao and Tong19 on (unbounded) scaling laws associated with TX power.
Next, we consider the lower bound on the achievable energy consumption.
Lemma 6
The total amount of energy consumption is at least under any scheme.
Proof 6
We observe that the TX power must be at least on the order of . This is because the TX power must compensate for the path loss such that the SINR requirement (equation (5)) is satisfied. Furthermore, the number of transmissions for any scheme is at least because each node must transmit data at least once. Thus, the total energy consumption for any scheme is at least . As shown in the proof of Theorem 3, we must have for network connectivity. Therefore, we have .
From Theorem 3 and Lemma 6, we conclude that our scheme consumes at most times the amount of energy consumption compared to the optimal scheme. As a result, our scheme is order-optimal if the data sparsity is of constant order, that is, .
Corollary
If , the proposed scheme achieves order-optimal energy consumption.
Simulations
In this section, we numerically evaluate the performance of the proposed scheme. Specifically, we compare the latency of the proposed scheme to the capacity-achieving scheme proposed by Zheng et al.9 We assume that sensor nodes are uniformly and randomly deployed over a unit square area. The sink is located at the top right corner. In the scheme by Zheng et al.,9 the unit square area is divided into cells, the side length is set to , and the communication range is set to . Note that data collection by Zheng et al.9 consists of three phases. In the first phase, each cell chooses a node as the cell head. Then, each cell head collects the raw data from the rest of the nodes in the same cell. In the second phase, the packets sent by cell heads are linearly combined and relayed along the column cells to the uppermost row cells, similar to CDG. In the third phase, packets in the uppermost row cells are relayed along the row cells to the sink using the CDG method.
We first evaluate the latency performance of the proposed scheme. In a recent study,22 the authors proposed a tree-based computation protocol that uses the hybrid CS method. Similar to the scheme proposed by Zheng et al.,9 the tree-based computation protocol divides the unit square into cells of side length , where cells in the vertical direction form a bin. The bottom cell in each bin randomly selects a node as the bin head. Their tree-based computation protocol consists of two protocols: intra-bin and inter-bin protocols. In the intra-bin protocol, all nodes in a bin transmit raw data to the bin head along the shortest path. In the inter-bin protocol, each bin head collects linearly combined data from its child bin head. The authors showed that the tree-based computation protocol can achieve latency ; however, this is higher than our result, that is, .
Figure 5 compares the latency of the proposed scheme to the scheme proposed by Zheng et al.9 and the tree-based computation protocol for varying . In Figure 5, we set , that is, the interference range is times the communication range. Here, the sparsity of the original data vector is ; thus, the number of required measurements is . In our scheme, we set the communication range as according to the optimal scaling law. We observe that for a fixed value of , the latency of the proposed scheme is less than that of Zheng’s scheme and the tree-based computation protocol. This result agrees with our latency analysis, that is, according to Theorem 1, the latency of the proposed scheme increases in the order of . However, the latency of Zheng’s scheme and the tree-based computation protocol increases in the order of and , respectively.
Comparison of latency versus number of nodes when .
Figure 6 compares the latency of the proposed scheme for different communication range values. In Figure 6, sparsity . Here, we consider three schemes, that is, (Scheme A); (the proposed scheme); (Scheme B). In Scheme A, is set according to the critical connectivity. We observe that the latencies of the proposed scheme, Scheme A, and Scheme B are on the order of , , and , respectively. Thus, the case for the optimal scaling law outperforms other suboptimal choices for .
Comparison of latency for different communication ranges.
Next, we test our scheme for the case where sparsity scales faster than . Note that real sensory data may have such sparsity, and we consider the data measured in the CitySee23 system, which monitors the CO2 level of urban areas. Wu et al.24 showed that data from the CitySee system are approximately 0.1n-sparse in the discrete cosine transform or discrete wavelet transformation basis. Figure 7 compares the latency of the proposed scheme with Zheng’s scheme and the tree-based computation protocol for . The latency increases at a different rate in compared to Figure 6, which is due to the different scaling of sparsity. However, for any fixed , the proposed scheme achieves lower latency than Zheng’s scheme and the tree-based computation protocol.
Comparison of latency versus number of nodes for .
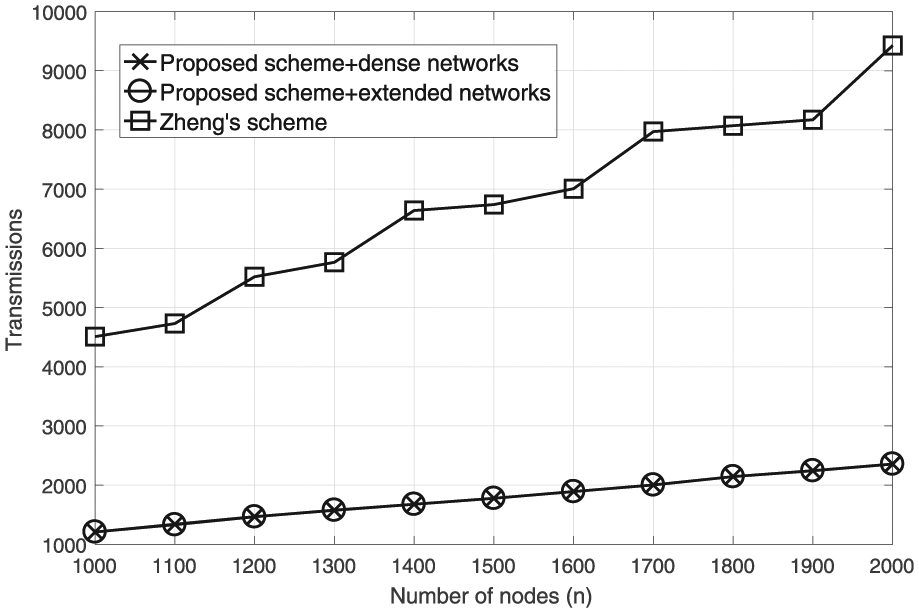
Next, we compare the total number of transmissions in the network, which is related to energy consumption and traffic loads in the network. We compare the proposed scheme to Zheng’s scheme.9Figure 8 compares the number of transmissions against . In Figure 8, we set the sparsity of constant order; we let . In addition, we set the communication range and for the dense and extended network models, respectively. In this simulation, dense and extended networks are defined as follows. In dense networks, the network area is fixed, and the number of nodes is increased. In extended networks, node density is fixed, and the network area is increased. For Zheng’s scheme, we use the dense network model.9 Here, the number of transmissions of our scheme under the dense and extended network models is approximately equal because for a fixed number of nodes, the network topology is similar even under different scaling methods. Furthermore, we observe that the number of transmissions under our scheme is significantly smaller than that under Zheng’s scheme because in Zheng’s scheme, the heads in the cells construct the network backbone. Non-backbone nodes send raw data to heads, and the cell heads then relay data to the sink following the CDG method. Thus, the size of the backbone is exactly the number of cells in the network. However, in the proposed scheme, the backbone size is considerably smaller because our scheme finds the CDS from the network graph, which changes with node distribution. Thus, it is likely that our scheme will construct a small backbone adapted to the given network topology. However, the topology of the backbone is fixed in Zheng’s scheme; thus, it cannot adapt routing to a changing topology. This clearly shows the advantage of our graph-theoretic approach compared to that based on a network area with specific geometry. Alternatively, by applying an inequality similar to equation (12) to dense networks, the CDS size (backbone) is under our scheme, whereas that for Zheng’s scheme, it is . In other words, our backbone size is asymptotically no larger than that of Zheng’s scheme.
Comparison of number of transmissions with varying .
Figure 9 compares the total energy consumption of the proposed scheme and Zheng’s scheme. In Figure 9, we set path loss constant , ambient noise power , SINR threshold , constant , and RX . Under the dense network model, the energy consumption of our scheme is less than that of Zheng’s scheme because the total number of transmissions of the proposed scheme is less than that of Zheng’s scheme. Moreover, the energy consumption under the extended network is considerably greater than that under the dense network because the communication range under the extended network model is greater than that under the dense network model by a factor of . Another observation is that the rate of increase in energy consumption is small for large under the dense network model because as tends to infinity, TX power vanishes; thus, the RX power dominates energy consumption.
Comparison of energy consumption with varying .
In the previous sections, we claimed the order-optimality of energy consumption when . In this section, we numerically evaluate energy performance when sparsity is not . Figure 10 compares the total energy consumption of the proposed scheme and Zheng’s scheme with sparsity . The other parameters are the same as those in Figure 9. Similar to Figure 9, the energy consumption of our scheme is significantly less than that of Zheng’s scheme under the dense network model. Furthermore, under the dense network model, the gap between our scheme and Zheng’s scheme in Figure 10 is even greater than that shown in Figure 9, which implies that the proposed scheme performs better with greater sparsity. This can be explained as follows. For fixed , sparsity in Figure 10 is greater than that in Figure 9. Greater sparsity implies a greater number of measurements because . Let and denote the backbone size of our scheme and Zheng’s scheme, respectively. The total number of transmissions over the backbone is approximately (resp. ) for our scheme (resp. Zheng’s scheme). Thus, the difference in the number of transmissions is approximately . Previously, we argued that the backbone size in our scheme is smaller than that of Zheng’s; thus, the gap in the number of transmissions increases with increasing , which can be observed by comparing Figures 9 and 10. In conclusion, when sparsity grows faster than , the proposed scheme is likely to perform even better due to the construction of efficient backbone networks.
Comparison of energy consumption with sparsity .
Conclusion and future work
In this article, we have proposed a joint routing and scheduling scheme for data collection that leverages hybrid CS. The proposed scheme is based on a graph-theoretical framework; thus, it is applicable to networks of arbitrary shape and topology. We constructed a CDS that serves as a network backbone and aggregated linearly combined data over the CDS in a pipelined manner. By properly setting the transmission range and backbone size, we demonstrated that the proposed scheme achieves order-optimal latency and low-energy consumption. Simulation results show that our scheme outperforms existing schemes in finite-size networks. In the future, we plan to integrate our protocol with practical packet reception methods based on PhIM. The packet-level PhIM (or packet reception ratio (PRR) versus SINR (SINR-PRR)) models the packet error rate as a function of SINR; thus, the SINR threshold in equation (5) determines the target PRR. However, there may exist significant variations in the measured SINR in large-scale WSNs. To address this issue, we may apply techniques based on the spatiotemporal diversity of traffic25 or regression-based modeling26 to our protocol to address fluctuations in the actual SINR and reduce measurement overhead.
Footnotes
Acknowledgements
The authors would like to thank anonymous reviewers for their valuable comments and suggestions.
Handling Editor: Giacomo Oliveri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT & Future Planning (MSIP) of the Republic of Korea, No. NRF-2016R1A2B1014934; Institute for Information & Communications Technology Promotion (IITP) grant funded by the MSIP (No. B0126-17-1046, Research of Network Virtualization Platform and Service for SDN 2.0 Realization); National Nature Science Foundation of China (NSFC) No. 61701441.
References
1.
GubbiJBuyyaRMarusicSet al. Internet of Things (IoT): a vision, architectural elements, and future directions. Future Gener Comp Sy2013; 29(7): 1645–1660.
2.
CandèsEJWakinMB. An introduction to compressive sampling. IEEE Signal Proc Mag2008; 25(2): 21–30.
3.
CandèsEJRombergJTaoT. Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE T Inform Theory2006; 52(2): 489–509.
4.
DonohoD. Compressed sensing. IEEE T Inform Theory IEEE2006; 52(4): 1289–1306.
5.
CandèsERombergJ. Sparsity and incoherence in compressive sampling. Inverse Probl2007; 23: 969–985.
6.
LuoCWuFSunJet al. Compressive data gathering for large-scale wireless sensor networks. In: Proceedings of the 15th annual international conference on mobile computing and networking, Beijing, China, 20–25 September 2009, pp.145–156. New York: ACM.
7.
LuoJXiangLRosenbergC. Does compressed sensing improve the throughput of wireless sensor networks? In: Proceedings of the IEEE international conference on communications, Cape Town, South Africa, 23–27 May 2010. New York: IEEE.
8.
EbrahimiDAssiC. On the interaction between scheduling and compressive data gathering in wireless sensor networks. IEEE T Wirel Commun2016; 15(4): 2845–2858.
9.
ZhengHXiaoSWangXet al. Capacity and delay analysis for data gathering with compressive sensing in wireless sensor networks. IEEE T Wirel Commun2013; 12(2): 917–927.
10.
GuptaPKumarP. The capacity of wireless networks. IEEE T Inform Theory2000; 46(2): 388–404.
11.
WanPHuangSWangLet al. Minimum-latency aggregation scheduling in multihop wireless networks. In: Proceedings of the tenth ACM international symposium on mobile ad hoc networking and computing, New Orleans, LA, 18–21 May 2009, pp.185–194. New York: ACM.
12.
KarakusCGurbuzATavliB. Analysis of energy efficiency of compressive sensing in wireless sensor networks. IEEE Sensors J2013; 13(5): 1999–2008.
13.
ZhaoCZhangWYangYet al. Treelet-based clustered compressive data aggregation for wireless sensor networks. IEEE T Veh Technol2015; 64(9): 4257–4267.
14.
LiuXYZhuYKongLet al. CDC: compressive data collection for wireless sensor networks. IEEE T Parall Distr2015; 26(8): 2188–2197.
15.
XuXAnsariRKhokharAet al. Hierarchical data aggregation using compressive sensing (HDACS) in WSNs. ACM Trans Sens Netw2015; 11(3): 45.
16.
EldarYKutyniokG. Compressed Sensing: theory and applications. Cambridge: Cambridge University Press, 2012.
17.
GuptaPKumarPR. Critical power for asymptotic connectivity in wireless networks. In: McEneaneyWMYinGGZhangQ (eds) Stochastic Analysis, Control, Optimization and Applications: a volume in honor of W. H. Fleming. Boston, MA: Birkhauser, 1998, pp.547–566.
18.
BrooksRL. On colouring the nodes of a network. Math Proc Cambridge1941; 37: 194–197.
19.
ZhaoQTongL. Energy efficiency of large-scale wireless networks: proactive versus reactive networking. IEEE J Sel Area Comm2005; 23(5): 1100–1112.
20.
FranceschettiMDousseOTseDNCet al. Closing the gap in the capacity of wireless networks via percolation theory. IEEE T Inform Theory2007; 53(3): 1009–1018.
21.
OlerN. An inequality in the geometry of numbers. Acta Math1961; 105(1): 19–48.
22.
ZhengHGuoWFengXet al. Design and analysis of in-network computation protocols with compressive sensing in wireless sensor networks. IEEE Access2017; 5: 11015–11029.
WuXXiongYYangPet al. Sparsest random scheduling for compressive data gathering in wireless sensor networks. IEEE T Wirel Commun2014; 13(10): 5867–5877.
25.
LiuSXingGZhangHet al. Passive interference measurement in wireless sensor networks. In: Proceedings of the 18th IEEE International Conference on Network Protocols (ICNP), Kyoto, Japan, 5–8 October 2010, pp.52–61. New York: IEEE.
26.
ChangXHuangJLiuSet al. Accuracy-aware interference modeling and measurement in wireless sensor networks. IEEE T Mobile Comput2016; 15(2): 278–291.