
Abstract
Within the emerging fog network, mobile devices along with local sensors and actuators dynamically form an ad hoc network. As mobile ad hoc networks frequently merge and split in such mobile fog network scenarios, the node addresses must be changed too. This implies that a session may be broken if one of the peers is assigned a new IP address. To overcome this problem, this article proposes a novel structured late-binding address that makes use of node contexts to determine the logical destination group carried in the packet header. The idea is to hide internal mobile ad hoc network details (e.g. addresses) from external sources. The mobile ad hoc network advertises only its own ID and the list of internal contexts. When an external sender transmits a packet to a remote mobile ad hoc network, it must choose first the combination of contexts (i.e. qualifications) that an internal node must present to get the packet. This gives rise to a new data delivery paradigm called polycast. Namely, the physical identities of the destination(s) are determined only when the packet reaches the target mobile ad hoc network. Consequently, the number of destinations can vary from zero (no match) to unicast and multicast depending on the set of contexts. Say, the destinations and routing mode (e.g. unicast, multicast, or broadcast) are determined by the contexts. Simulation models are used to evaluate the scheme and to determine sensitivity to network variables.
Keywords
Introduction
As sensors and acutators are being deployed to everywhere in our physical environment, the importance of a network edge increases. Sensor networks are connected to the edge and play significant roles of data generators, controllers for physical systems, and in-network computing platforms. Pervasive deployment of sensors and actuators has also lead to the emergence of new applications at the edge, requiring to process data in real time and to understand local contexts. This brings a new research area of fog computing that moves down portions of computing capability of a cloud to the network edge (i.e. fog), forming a local computing environment. The local computing becomes more complicated as mobile devices such as smartphones and vehicles are frequently connected/disconnected to the network edge. Such mobile devices along with local sensors and actuators at the fog form an ad hoc network and complete a common task in a collaborative manner. That is, a mobile ad hoc network (MANET) is created within the fog, and we name it a mobile fog network. Unlike the existing MANET, member nodes in the fog are of dissimilar types in many aspects and handle a variety of local contexts.
Most MANET studies have considered homogeneous network conditions—all nodes have the same radio and run the same protocol. Real-world scenarios in the emerging mobile fog network do not always follow this assumption, however. For instance, in civilian and tactical applications, multiple teams are deployed, often featuring different wireless technologies. A typical example is the emergency rescue scenario where police, firefighters, and medical crew form a MANET coalition on-the-fly from different communication assets. To achieve the interoperability among multiple heterogeneous MANETs, the research community has investigated multi-MANET systems (MMSs). Without modifying existing intra-MANET network protocols, the MMS 1 features dynamically elected gateways that supervise inter-MANET communication. In static condition (i.e. low mobility), MMS performs reliable packet delivery over MANETs. However, when MANETs move, critical challenges are raised by changes in node addresses.
In an MMS, MANETs frequently merge and split because of mobility. Conventional IP-based address formats cannot cope with these dynamic changes. For example, after splitting, addresses must be re-assigned and routing tables must be updated. This process involves long delay and enormous overhead. Dynamic address changes also cause identifier ownership problems. 2 That is, a node should be identified using a unique address, but in MMS the address changes so frequent that it fails to represent the node identity consistently. The ownership problem affects inter-MANET routing as well as other communication solutions. For instance, conventional encryption cannot be used because a sender cannot distinguish destinations. Therefore, the existing IP-based address system is not proper to dynamic multi-MANET environments.
To solve the problem, this article proposes a novel node addressing system, structured late-binding address (SLA). Instead of establishing a route using target destinations IP address, with the SLA system, a source node defines a “logical” destination group by combining the set of node contexts (e.g. attribute and semantic). Since the SLA does not designate a specific node as a destination, the number of destinations can vary from zero (if none qualifies) to several depending on the set of contexts. Say, the destinations and routing mode (e.g. unicast, multicast, or broadcast) can be dynamically changed based on contexts and network formation and condition with the SLA. Thus, we define this dynamic transmission model as polycast.
The contributions of this article are two-fold. First, we introduce a new node addressing system, SLA, that does not require address re-assignment after merging/splitting MANETs since SLA represents nodes using their attributes and contexts instead of numerical IP address. Next, we define a new delivery paradigm called polycast. Polycast is a polymorphic data delivery model that delivers packets based on node context, not node address. Polycast is executed using SLA. It dynamically determines a routing mode based on the defined contexts and the network conditions. We evaluate the proposed system via simulation study.
The rest of the article is organized as follows. Section “Related work” reviews existing inter-MANET routing protocols and their limitations. It also reviews research works on an information-centric networking. Section “SLA” describes the SLA scheme and the polycast model. In section “Evaluation,” the proposed system is evaluated with simulation results. Finally, we conclude the article in section “Conclusion.”
Related work
Inter-MANET routing protocol
Over a past few years, several multi-MANET routing protocols have been proposed3–5 to solve the interoperability problem among heterogeneous MANETs. This section reviews three common features of existing protocols.
First, inter-MANET protocols do not modify existing intra-MANET routing mechanisms. Say, intra- and inter-MANET routings do not depend on each other and they run separately. In other words, inter-MANET protocols are able to run on any MANET routing protocols. For instance, in Figure 1, when node a1 transmits data to a2, that is, intra-MANET, they use Ad hoc On-Demand Distance Vector (AODV) without the help from inter-MANET protocols.

An intra and inter-MANET routing scenario with two heterogeneous MANETs. They are inter-connected via gateways running multiple wireless technologies and protocols.
Next, for data transmission over MANET boundaries, gateways, special types of nodes, are required. Assigned either statically or dynamically, gateways play the same role of border gateways in the Internet. We note that a gateway election problem is an active research area in the MMS. 6 Gateways run multiple protocols and wireless technologies simultaneously so that two gateways belonging to different MANETs can transmit data if they are within the radio range. Two gateways per each MANET are assigned in Figure 1; they are A1, A2, B1, and B2. When node a1 transmits data to b2, it first delivers data to A1. Then, data are forwarded to b2 via B1 that is adjacent to A1.
Finally, a proactive routing mechanism is employed for the inter-MANET networking. Gateways in the same MANET periodically monitor the network topology and member changes, and such information is advertised to all gateways in the network periodically. Upon receiving topology/member change information, a gateway updates own routing table for inter-MANET routing. When a node c1 joins MANET B, two gateways, B1 and B2, detect the event. Then, B1 advertises this updates to A1, which also shares new topology information with A2 later. In this way, routing tables keep the newest inter-MANET routing information, and packets are forwarded through multiple MANETs to reach the final destination.
Challenge in node addressing
Existing inter-MANET protocols provide the fundamental mechanisms to bridge heterogeneous MANETs in MMS, but other challenges, such as node addressing, are rarely explored.
Figure 2 illustrates that MANET B in Figure 1 splits into two MANETs B′ and B″. After the split, each MANET must determine own network number and re-assign nodes’ addresses. But these two processes in a distributed MMS are not trivial. An arbitrary assignment of network and node addresses may cause an address duplicate problem: two networks or nodes have the same address. For instance, two IP addresses in Figure 2 represent the identities assigned to b1 and b2 before the split. After the partition, they could have the same IP address because it is randomly chosen. This violates the uniqueness requirement of a node identity. To avoid the address duplicate problem, a new MANET may consult with all other MANETs in the network when determining the network number and assigning the addresses. However, this would come with a huge overhead in terms of latency and traffic. To date, no efficient solution for the address re-assignment has been proposed.
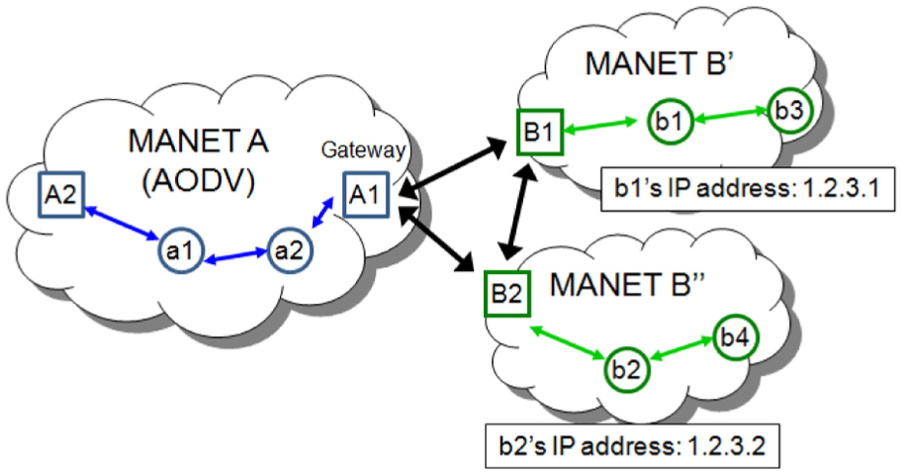
MANET B splits into two MANETs B′ and B″. Three gateways, A1, B1, and B2, inter-connect three heterogeneous MANETs. Two IP addresses represent the identities assigned to b1 and b2 before splitting.
In addition, the identifier ownership problem occurs because the re-assignment process works in a stateless manner. For instance, suppose that node b2 in MANET B″ is assigned a new IP address “5.6.7.2” after the split in Figure 2. The gateway B2 would advertise the new address to all other MANETs including MANET A. But any node in A does not recognize that two IP addresses, that is, “5.6.7.2,” and “1.2.3.2,” represent the same node, b2. This violates the consistency requirement of the node identity. The inconsistency can degrade data delivery performance severely. Suppose that node a1 in MANET A transmits data to node b2 in Figure 1 (i.e. inter-MANET transmission before the split). When a1 tries to retransmit data to b2 at “1.2.3.2” after the partition (Figure 2), it would fail to make a connection. a1 may not even find b2 because it does not learn that a new address “5.6.7.2” is assigned to b2. To overcome this problem, gateway B2 may advertise the new address with its own assignment history, which, however, would cause an enormous overhead.
Information-centric networking
As discussed, the conventional IP address system does not cope with network dynamics in wireless multi-MANET environments. As an alternate, we consider the information-centric networking (ICN) paradigm that routes and processes packets based on destination content. Since ICN does not rely on the IP-based identity of a node for data routing, it can also resolve the addressing problem in MMS. We review some previous studies that are on the track of the paradigm and discuss their limitations.
Over the years, several information-based routing schemes have been proposed. For instance, content-based routing 7 and data-centric routing 8 transmit user data based on application-layer context in wireless sensor network (WSN). In the distributed hash table (DHT)-based peer-to-peer routing schemes,9,10 a node finds and accesses content based on its name and its corresponding unique hash value in the network. Besides, service-oriented network sockets 11 and service-driven routing 12 schemes implement service-oriented architecture (SOA) in wireless ad hoc environments.
Although proposed schemes provide good solutions for their specific applications, they cannot be applied to wireless MMS for three reasons. First, they provide an overlay routing. They still require using conventional IP address–based routing schemes to deliver data. As discussed, however, the IP-based addressing system is not proper for the MMS. Second, existing schemes rarely handle node mobility. In WSN, data-centric routing 8 assumes that a sink node is already aware of the existence of stationary sensor nodes in the target area and only checks the changes in sensor measurement. However, it does not work if nodes move out of the target area. Finally, they only support a publish/subscribe model. The model works well in such network environment where the node identity is consistent. But in MMS, the relationship between the publisher and the subscriber tends to break due to node mobility and thus identities change frequently.
Recent researches in the ICN area investigate named data networking (NDN), which primarily differs from schemes discussed above in that it runs at the networking layer.13,14 NDN views a network as a dynamic storage of information and provides end-to-end communications in terms of named contents instead of traditional IP-style addressing that combines node’s identity and location.15,16 TRIAD 17 uses content name that is user-friendly, structured, and location-independent names. For content discovery, TRIAD transmits a request to the next hop, continuing until a copy of the data is found and its location is returned to the client. Then data delivery occurs. Routing on Flat Labels (ROFL) 18 employs semantic-free flat labels and creates a circular namespace, such as DHT, for routing like Chord. 19 Receivers put in a trigger, data identifier, and their address into the DHT. The trigger is delivered to the node which has the requested identifier and data. Data-Oriented (and beyond) Network Architecture (DONA) 20 uses flat, self-certifying names. Generated content is published and registered with a tree of trusted resolution handlers (RHs) that provide a forwarding table–recorded next hop information of content. Thus, RHs must be updated whenever location of content changes.
Research in the NDN tries to replace the existing IP-based addressing system with a content-oriented data delivery system.21,22 However, NDN is not proper for the MMS because NDN purely runs on the network layer. The NDN schemes assume that most nodes in a network are capable of handling the NDN messages, and thus hardly support backward compatibility with the existing address system. As reviewed, however, one of the main goals of the inter-MANET networking design in MMS does not change the intra-MANET routing systems. Since most intra-MANET routing protocols utilize the IP-based address, it is not trivial to apply NDN to MMS directly.
To solve the addressing problem in MMS, Lee et al. 4 proposed attribute-based addressing. The address of the MANET is defined by attributes belonging to the MANET, and a gateway runs a role of Name Server. Similarly, Ford 23 proposed a semantic routing framework that leverages semantic technologies to facilitate routing messages. Instead of IP-prefixed form, the destination address is specified using metadata describing some common properties of the target destination node. To date, both attribute-based addressing and semantic routing schemes are only sketched conceptually, and their design and implementation still remain to be further examined. We propose a new addressing system that is on the same track of this philosophy in section “SLA.”
Structured Late-Binding Address
This section presents the proposed SLA and illustrates its operation in MMS.
Structured address
Context
In a MANET, each node maintains its own set of contexts, and any subset can identify the node. In addition, an arbitrary combination of contexts can represent more than one node if the nodes’ contexts satisfy the combination. Such context information is broadly categorized as follows:
Network/node name is a unique identifier of an entity. It could be a name in a text or IP-based address.
Node attribute is a feature that describes a node. It may represent the role of the node in a MANET, types of resources owned, current location, and valid time window.
Application semantic indicates application data and constraints of application engines. Examples include metadata for the application content and required maximum screen resolution.
Network specification denotes required network condition (i.e. quality of service) or own network status for advertisement. Link statistics and the number of neighboring nodes fall into this type of context.
System parameter explains the hardware specification of a device. This includes the battery level, processing power, and description of sensors if attached.
Addressing
When a node transmits data packets, it specifies the destination as a combination of contexts. The text-based representation of destination influences the existing packet header and its delivery. We expect that SLA will eventually replace the address fields, such as source and destination addresses, in the packet header. With the contexts above, SLA represents the source and the destination node in the following format:
SLA = {FROM Source [WITH Indicator]
TO Destination [WHERE Descriptor]
}
In SLA, the FROM and WITH clauses describe the source, whereas the TO and WHERE clauses specify the destination. “Source” in the FROM clause denotes the identity of the source node such as the node name, ID, or the network name which the node belongs to. “Indicator” in the WITH clause describes the contexts of the source node which include the current node location, application and network-level requirements, or a simple description of the content. The contexts are expressed in the form of monotone Boolean formula given the information listed above. The same rule applies to the destination node within the TO and WHERE clauses. Below is an example form of SLA, in particular the TO and WHERE clauses.
TO ((f1 AND f2) OR (f3 AND f4))
WHERE ((f5 AND f6) OR (f7 AND f8))
Note that fi represents a context, and the clauses are constructed in a disjunctive form. Once a node receives the data packet, it compares own contexts with both the TO and WHERE clauses specified in SLA. If matched, the node processes the packet.
One advantage of SLA is that it supports a general framework for data dissemination in a distributed network environment. SLA can work either on top of existing routing protocols or on the network layer as another form of NDN. Section “Information-centric networking” shows adaptation of SLA to one of the existing inter-MANET protocol with an example. SLA can also implement both a push service, such as publish/subscribe, and a pull service. Furthermore, the SLA-based framework introduces a new data delivery model beyond existing unicast, multicast, and broadcast. We name it polycast.
Polycast
Central to the concept of polycast are the flexible addressing format and the late-binding behavior. The behavior of packet delivery, that is, unicast, multicast, or broadcast, is determined dynamically as the packet reaches the destination MANET. This dynamic packet delivery mode decision is named Polycast.
A source node S in Figure 3 initially determines group D as a destination by specifying “Destination” and “Descriptor” in SLA, and then transmits a data packet toward the destination MANET B. Note that S does not clarify the physical identities of destination node(s) at this moment—it only defines logical boundary of destination by defining a set of node contexts. This implies that the number of actual nodes in D, ND, is unknown. Instead, the set of physical nodes in D that receive the packet is determined by an in-network process while the packet travels. As such, polycast behaves exactly the same as unicast if a specific node ID or name is specified in “Destination” or ND = 1. If

An example of polycast operation. The sender S transmits a packet with logical destination group D. The addressing binding in the network determines two destination nodes, b1 and b3.
Polycast differs from proactive routing and normal multicasting as the destination node in polycast has never subscribed the service or joined the multicast group. To be precise, polycast is a proactive service without prior subscription. Therefore, it is possible that there is no receiver node in the destination MANET, that is, ND = 0. This is a critical violation in terms of efficient network resource usage (and it will be evaluated in the evaluation section). Nevertheless, the polymorphic behavior copes well with node mobility. As a node moves around, it changes its position and connection (e.g. MANET) dynamically. In this scenario, it would be hard to identify the node with a unique IP address consisting of a network and a host address. When a node joins a new MANET or its MANET is merged/split (so that the network address changes), its IP address must be re-assigned. However, polycast can deliver data to the node successfully because it uses what the node has—the node contexts that rarely change.
Operation of late binding in a multi-MANET system
The three properties of inter-MANET network protocols, discussed in section “Related work,” define an MMS environment where SLA is running as follows: a conventional IP-based addressing scheme is used for intra-MANET routing, inter-MANET communication exploits polycast, and gateways perform the address binding between SLA and IP-based address. This section describes the operation of polycast in the MMS.
Suppose an emergency, first responder scenario where police and medical crew MANETs form an MMS as shown in Figure 4. Each node maintains a set of contexts including its own name. For instance, node b2 in MANET B has four contexts: one name and three attributes, {node b2; ambulance; medicine M; location X}. The gateway B1 continuously collects the attributes of all nodes belonging to MANET B. When a new node joins the MANET, the corresponding attributes are registered to B1. B1 maintains all the attributes in the form of the Bloom filter (BF) 24 in the routing table, such as BF[b1, b2, b3, ambulance, …]. The BF is the OR operation of the hashes of the attributes so that it does not increase the size of the routing table. B1 advertises its own routing table to other gateways in the neighbor MANETs, that is, A1 in Figure 4. B1 also maintains a table that maps an attribute to a list of nodes and vice versa. When node a1 transmits data to MANET B, it specifies destination D by constructing a Boolean formula for the TO and WHERE clauses.
FROM (MANET A AND a1)
WITH (police car)
TO (MANET B)
WHERE (amb. AND loc. X) OR (doc. AND med. N)

An example scenario of the MMS: police and medical crew collaborate for emergency and rescue mission.
Node a1 delivers a data packet to its gateway A1, and then it is forwarded to B1 based on A1’s routing policy. B1 performs the address binding with four inputs from the WHERE clause, “ambulance,”“location X,”“doctor,” and “medicine N,” and determines the physical identity of the destination node (b2 in this case). B1 then initiates the intra-MANET routing, Destination-Sequenced Distance-Vector Routing (DSDV), to transmit the data packet to node b2. When b2 tries to reply back to the sender, it simply sends a packet back to a1 in MANET A without constructing the WHERE clause.
For the operation of late binding, a gateway performs the following functions. (1) It manages contexts (or attributes) inside a MANET. It periodically collects contexts from internal nodes and maintains a context table. When nodes join or leave the MANET, it contacts the nodes to (de)register appropriate contexts. (2) The gateway also communicates with other gateways representing neighboring MANETs. It advertises its own context table so that neighbors are allowed to fetch data from the MANET. Upon receiving a data request message, the gateway runs an address translation; it finds a list of nodes that store requested data and forwards the message to the nodes found.
Throughout the operation, the gateway maintains two types of tables. A context table stores all the contexts managed in the MANET, and a mapping table is used to find (map) a list of matched nodes given a data request message. The size of the tables fundamentally grows as the number of nodes inside the MANET and the number of contexts increase. As noted previously, a data structure of BF and a hash table can be recruited to implement the tables, which enable to minimize the memory usage in the gateway. Using the hash table can also reduce the computation overhead when the gateway performs the mapping function. In a general scenario, a gateway is expected to run on top of a mobile system having more computing resources than a conventional smartphone. Say, an ambulance in the previous example will take the gateway role, and its MANET may include less than 100 internal nodes. Assuming that the ambulance is equipped with a laptop-equivalent system running the gateway, overhead for computation and memory usage could be in controllable level. If we take the same assumption, communication overhead in the gateway could be moderate. We note that issues on communications among internal nodes such as AODV and DSDV shown in Figure 4 are out of scope.
Security concern
The core of the proposed system is to use node contexts instead of the node address. This property allows us to practice a more advanced data protection scheme—information-centric encryption. That is, a sender encrypts data using user contexts, not node identity like in the conventional public key infrastructure (PKI). For instance, in Figure 4, node a1 makes use of what it knows: “MANET B,”“ambulance,”“location X,”“doctor,” and “medicine N.” a1 encrypts
To implement the concept, we consider ciphertext-policy attribute-based encryption (CP-ABE)25–27 that encrypts data using nodes’ attributes defined within the MANET context. CP-ABE realizes the secret sharing scheme 28 using node attributes. More specifically, each node is assigned a set of shares (attributes), and data are encrypted by the sender using a public key that reflects that set of shares. If the node has the proper credentials—for example, it has a private key that covers enough number of shares—it can recover the secret and decrypt data. To make each share secret, CP-ABE exploits bilinear map-based pairing-based cryptography (PBC). It also allows the creation of an access policy tree, representing a Boolean formula defining the combination of shares in the ciphertext. When the node’s set of shares satisfies the tree, it is authorized to access the data. To make each tree secret, CP-ABE exploits polynomial interpolation techniques that guarantee information theoretic security. To prevent collusion attacks (i.e. two or more users combining partial trees to access data they are not authorized to see), the authority ties all the shares that belong to one user with a random number unique to that user.
Evaluation
Preliminary
With the existing system, a node is bound to an IP address that is ever-changing due to network mobility. This gives rise to consistency and uniqueness problems (as discussed in section “Challenge in node addressing”). Our approach is to hide details (nodes’ addresses) of a MANET from external nodes. The MANET advertises only own ID and the list of internal node contexts When an external node has a packet to transmit to the MANET, it chooses the combination of contexts that the intended receiver must satisfy. However, the number of internal nodes that satisfy this combination is unknown to the sender. If the sender makes an ill-informed choice, namely, it overspecifies the qualifications of the receivers, there might be no node to receive the packet in the destination MANET, that is, zero hit ratio. For example, the sender may request an ambulance with a doctor who speaks Korean. The first attempt may fail. In the second attempt, a request for a doctor on board who speaks English or Chinese will be satisfied. The zero hit can also be caused by node defections from a MANET that have not yet been registered, or by false BF positives. Either effects can be controlled in the protocol design (at the cost of increasing update frequency and BF size, respectively). In this article, we assume that the two latter contributions have been minimized by proper choice of parameter and focus here on the first contribution to the zero hit ratio, namely, the mismatch between the context requested by the sender and the actual attributes of the receivers. In our evaluation, we examine the impact of various systems parameters on the zero hit ratio and thus on the ability of SLA to deliver the data. These results are of practical importance in that the sender, upon learning about the attribute distribution in the receiving team (say paramedics), can calibrate its request so as to get a success in as few trials as possible. Time is of essence in emergency operations, and a prior knowledge of the chances of success is important. Lee et al. 29 discuss interesting scenarios in vehicular fogs where some of our results had been reproduced.
To investigate the data delivery performance of SLA and polycast, we carefully look into the number of attributes (k) used to specify the destination group D in SLA (we use two terms “attribute” and “context” interchangeably from this point as we focus on the WHERE clause in SLA). For intuitive representation, we suppose that the WHERE clause in the general form of SLA (see section “SLA”) is a conjunction of literals. This implies that a node must satisfy all the attributes in SLA to receive data packets. In a general sense, as k increases, the number of qualified destination nodes ND decreases, because only those nodes that have k attributes can receive the packet. ND reaches the maximum when k = 1, whereas its minimum (zero hit ratio or ND = 0) relies on conditions in the destination MANET such as total number of nodes (N), average number of attributes per node (C), and total number of attributes available in the MANET (M). They affect ND together once k is chosen by a sender, and we show their impact via modeling and simulation results.
Simulation
To evaluate data delivery performance, we implement polycast on QualNet and run simulations with the MMS scenario in Figure 4. We assume that an existing inter-MANET routing protocol 4 supports basic functionalities for network maintenance, for example, a media access control (MAC) and physical layer communication, network connectivity due to mobility, and gateway selection. Thus, our implementation focuses on node address and data delivery. In general terms, there are N nodes and M attributes in the destination MANET R (e.g. medical team in the first responder’s example). Each node has C attributes. Initially, we assume that each attribute is equally likely selected from M attributes—homogeneous case. See Appendix 1 for the data delivery model for the homogeneous case. We release this assumption later. The sender S (say, a1 in the police patrol MANET) constructs SLA that specifies the logical destination group D by selecting k out of M attributes. When a node in R is reached that satisfies all the k attributes in SLA, it can receive the packet; the number of actual destination nodes (ND) increases by 1. Table 1 summarizes the variables.
Symbol and notations.

MANET: mobile ad hoc network; SLA: structured late-binding address.
The number of attributes used in communication parties
We, at the first experiment, examine the impact of “the number of attributes in both a sender and potential receivers” on the hit ratio; that is, the impacts of C and k on ND. In the setting, C varies from 10 to 50 and the number of k varies from 1 to 40, while N and M are fixed to 200 and 50, respectively. Figure 5 shows the results. As k grows, ND declines exponentially. With C = 30 (the square mark), ND begins at around 120 when k = 1. When k increases to 5 and 10, ND sharply decreases down to 23 and 2, respectively. Finally, ND becomes less than 1 when
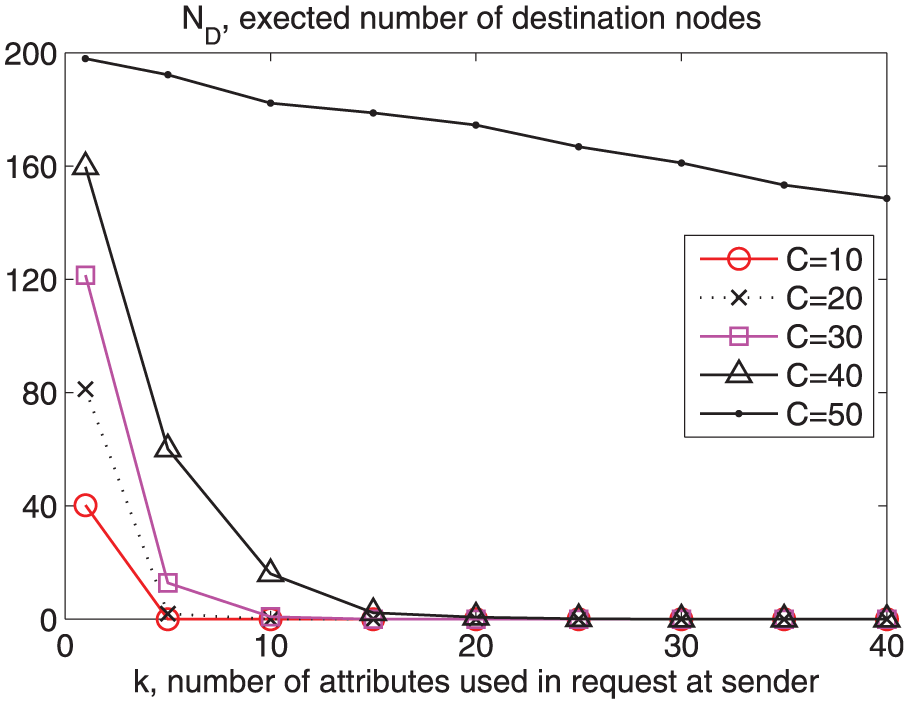
Values of C and k affect ND. The target MANET R has 200 nodes (N = 200) and 50 attributes (M = 50).
Uneven numbers of attributes on individual nodes in R
The previous experiment assumes that all the nodes in R maintain the same number of attributes. In practice, however, some nodes may have more attributes (say, group X), whereas some other nodes have few attributes (say, group Y). For instance, powerful and active nodes might have more contents and be equipped with more functional peripherals. To realize such a heterogeneous case, we consider that the number of attributes that nodes in R have follows the normal distribution with mean = C and variance = σ. A high σ value means that nodes in R have very different numbers of attributes.
Having considered the distribution of C, we repeat the first experiment with the same configuration but with σ = 10. Figure 6 shows the experimental results. Compared with the curves in Figure 5, the number of destination nodes clearly increases with more realistic user and attribute configurations. ND reaches 2, 6, 34, 82, and 147 with C = 10, 20, 30, 40, and 50 when k = 5, where ND is increased by 40 on average. In particular, the curve with C = 40 (the triangle mark) benefits noticeably. Even with k = 25, ND shows above 40, representing that the sender’s data are delivered to more than 20% of nodes in the receiving MANET. These results are reassuring and confirm the value of using SLA and polycast in realistic attribute distributions. As C decreases, the uneven property affects data delivery performance more critically. When k = 10, ND shows 1.8 and 12.1 with C = 20 and 30, respectively. Note that the same configurations show 0 in the previous result. This implies that even when sender S tries to find special nodes by increasing the number of attributes in SLA, it is expected to have destinations in the target MANET.

Distribution of C affects ND. C follows normal distribution with σ = 10 (N = 200 and M = 50).
To evaluate the impact of the uneven property in detail, we conduct an experiment with varying values of σ. We note that the C value also changes while N = 200 and k = 10 are fixed. Figure 7 draws the result curves confirming that as C increases, ND grows. It also demonstrates that ND grows with increasing σ values. As σ increases, there are more nodes in group X which are highly likely to belong to D. This stability makes the curve of σ = 20 less exponential than other curves. One interesting observation is that all the curves converge when C = 44. This is the case when nodes have 88% of attributes (44 of 50) on average. After this point, the curves are totally inversed. When C = 50, most nodes have around 50 attributes (i.e. in group X) with σ = 1, which results in high value of ND. On the other hand, with σ = 20, there are still noticeable numbers of nodes in group Y that cannot belong to D.

The σ values (variance of C) affect ND.
Considering popularity of contents (attributes)
The next experiment takes into account popularity of attributes that the target MANET R has; that is, some attributes are more popular than others so that more nodes in R might have them. This implies that attributes are ranked according to their popularity, and a node is more likely to select highly ranked attributes. To realize the concept, we take the Zipf’s law that has been studied in web objects: The web-page access rate follows Zipf-like distribution, generally considered as representative of its ranked popularity. 30 In the distribution, the access probability of the ith most popular item is represented

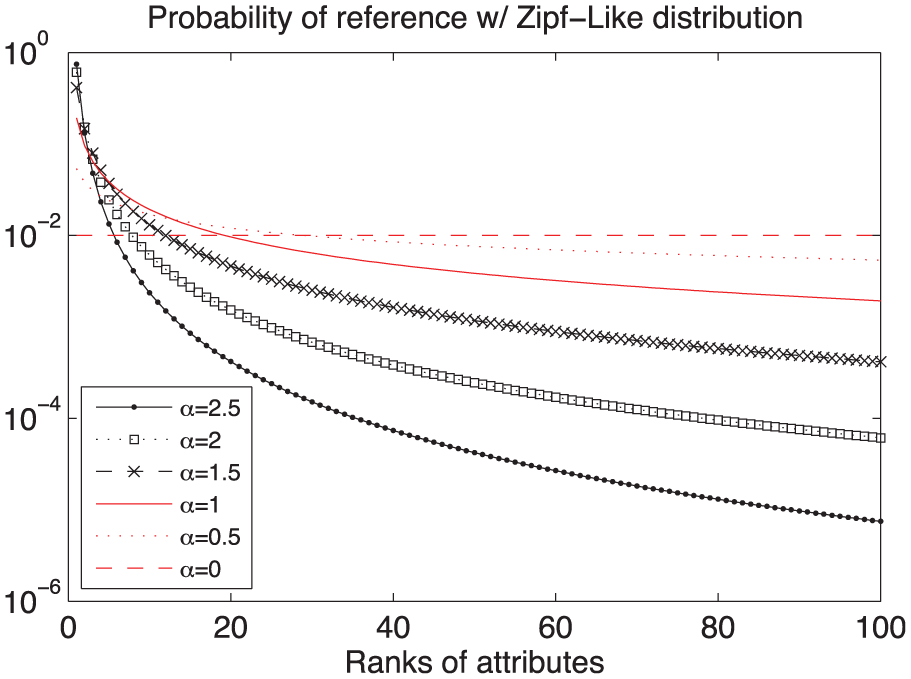
Reference of 100 attributes with Zipf-like distribution.
To investigate the impact of attribute popularity on the hit ratio, we sketch a scenario where M attributes are ranked, and sender S and the nodes in R select k and C attributes with the Zipf-like distribution. The experiment fixes

Attribute popularity affects ND. N = 200 and M = 50.
Total number of attributes available in R
Under a realistic configuration, that is, taking into account the distribution of C and attribute popularity, we examine how the total number of attributes available in the target MANET R affects data delivery performance. In the last experiment, we fix
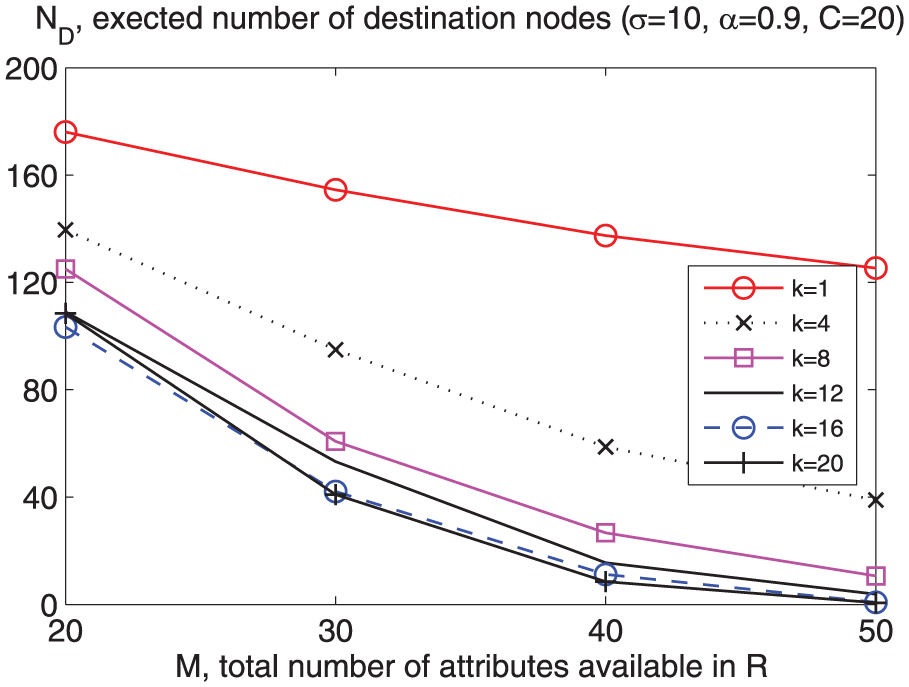
Impact of M and k on ND. C follows normal distribution w/
Conclusion
This article has presented a node address scheme (SLA) and a new data delivery paradigm (polycast) for content and context-based delivery in multiple MANETs’ environment. SLA makes use of node contexts to determine a logical destination group that satisfies the sender specifications. Thereafter, the network determines the physical identities of the destination nodes when the packet reaches the target MANET. Since the proposed system does not use a node address for inter-MANET communication, it is not affected by network merge/split dynamics, thus proving to be more robust than conventional IP routing. We examine the polymorphic behavior of the proposed context-based delivery system via simulations and discuss the impact of various parameters such as user contexts and network configuration on the success of date delivery, that is, on the ability to find one or more qualified receivers. Our future research includes enhancement of polycast’s communication efficiency and information-centric encryption.
Footnotes
Appendix 1
Academic Editor: Francesco Longo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by the NRF of Korea funded by the Ministry of Science, ICT & Future Planning (2016R1C1B1016084), and by the International Collaborative Energy Technology R&D Program of the KETEP granted financial resource from the Ministry of Trade, Industry & Energy, Republic of Korea (201685 30050030).