
Abstract
Internet of Things networks together with the data that flow between networked smart devices are growing at unprecedented rates. Often brokers, or intermediaries nodes, combined with the publish/subscribe communication model represent one of the most used strategies to enable Internet of Things applications. At scalability viewpoint, cloud computing and its main feature named resource elasticity appear as an alternative to solve the use of over-provisioned clusters, which normally present a fixed number of resources. However, we perceive that today the elasticity and Pub/Sub duet presents several limitations, mainly related to application rewrite, single cloud elasticity limited to one level and false-positive resource reorganization actions. Aiming at bypassing the aforesaid problems, this article proposes Brokel, a multi-level elasticity model for Pub/Sub brokers. Users, things, and applications use Brokel as a centralized messaging service broker, but in the back-end the middleware provides better performance and cost (used resources × performance) on message delivery using virtual machine (VM) replication. Our scientific contribution regards the multi-level, orchestrator, and broker, and the addition of a geolocation domain name system service to define the most suitable entry point in the Pub/Sub architecture. Different execution scenarios and metrics were employed to evaluate a Brokel prototype using VMs that encapsulate the functionalities of Mosquitto and RabbitMQ brokers. The obtained results were encouraging in terms of application time, message throughput, and cost (application time × resource usage) when comparing elastic and non-elastic executions.
Keywords
Introduction
The Internet of Things (IoT) is considered the next evolution in the era of computing after the Internet.1,2 In the IoT paradigm, many objects around us will be connected in networks and will communicate with each other without any assistance or human intervention. IoT devices implement different types of services for applications related to smart health, smart farming, smart city, among others. Normally, these services use a middleware layer that can act as a messaging service, receiving information, storing, and processing it, in addition to making automatic decisions based on the environment status and historical data. 3 Often, brokers or intermediate nodes (also named in some cases as superpeers) are used in this layer to enable communication among applications and things in a publish/subscribe (Pub/Sub) fashion. 4 Pub/Sub is a communication paradigm for asynchronous data dissemination among services and users. 5 In many Pub/Sub systems, clients are able to register subscriptions in a particular broker. In turn, brokers receive post messages from publishers and perform the filtering according to the subscriptions.6,7
As an indirect communication pattern, 8 where publishers and subscribers sometimes do not have knowledge of each other, Pub/Sub is useful to implement several IoT scenarios and applications. A smart object is responsible for generating events based on the collected information, which can be used not only by other things or high-level applications, but also further processed by other modules (e.g. an event-processing unit). 4 For instance, we can model a Pub/Sub system when collecting patients vital data via a network of sensors connected to medical devices, so delivering the data to a medical center for storage and processing and guaranteeing ubiquitous access to medical data in the electronic healthcare record (EHR) format. Figure 1(a) depicts a standard Pub/Sub deployment with a single broker. However, this organization suffers from the traditional problem related to centralized systems, that is, scalability. In other words, this deployment sometimes cannot provide quality-of-service (QoS) when enlarging the network clients, because of the larger amount of data in the system, the larger infrastructure requirements to store, process, and present it efficiently at real-time.

Pub/Sub deployment approaches: (a) centralized, (b) P2P-like distributed style, and (c) Brokel proposal.
Figure 1(b) illustrates a possibility to explore scalability using a Peer-to-Peer (P2P) network of brokers. This organization could be assembled using a cluster or grid infrastructure. Traditionally, both cluster and grids have a fixed number of resources that must be maintained in terms of infrastructure configuration, scheduling (where tools such as PBS (http://www.pbspro.org), OAR (http://oar.imag.fr), and open grid scheduler (http://gridscheduler.sourceforge.net) are usually employed for resource reservation and job scheduling), and energy consumption. The resource requirements of IoT Pub/Sub applications will inevitably fluctuate over time. 9 Thus, parallel machines such as clusters and grids may lead to either under-provisioning or over-provisioning situations, incurring in performance and cost penalties, in addition to do not addressing the growing demand of IoT systems. 10 IoT platforms should provide facilities to adapt (i.e. dynamically reconfigure) the resources allocated according to the perceived changes to the environment.
Cloud Computing can provide the virtual infrastructure to support the IoT paradigm by integrating monitoring, storage, analytical tools, visualization platforms, and client access.8,10,11 Unlike clusters and grids, cloud providers offer features to hide all the complexity and functionalities necessary to implement an IoT ecosystem. 12 Among the main features, it is possible to emphasize the elasticity which allows users to change the cloud capacity at any time dynamically. 13 Through the on-demand and pay-as-you-go provisioning principle, the interest in elasticity is related to the benefits it can deliver: better performance, improved resource utilization, and reduced costs. In this way, we can allocate a small number of resources at application launching time, so this number is moldable at runtime without user interference.
Although several principles have been studied for cloud computing elasticity and IoT systems, we have not seen such principles for engineering IoT Pub/Sub systems on top of cloud resource reorganization. Our review of the state-of-the-art in the aforementioned topics revealed five gaps: (1) obligation to change the application source code or to develop additional scripts to transform a non-elastic application in an elastic one;1–3,14 (2) use of proprietary software components, not available to buy or download;2,3 (3) system scalability, but only for a particular set of Pub/Sub middlewares;1–3,14 (4) virtual machine (VM) thrashing, so launching elasticity actions on sporadic peaks prematurely;1–3,14 and (5) single-level elasticity support.11,15–17 Exploring (5), we perceive that cloud elasticity is widely explored on Web systems, where a unique entry point acts as load balancer and elasticity manager. But, a research question arises: what happens whether the own entry point becomes overloaded?
Aiming at filling these gaps, we are proposing in this article a model named Brokel, a multi-level elasticity model for Pub/Sub brokers. Thus, users, things, and applications employ Brokel as a centralized messaging service broker, which is responsible for providing better performance and cost (used resources × performance) on message delivery using cloud elasticity. Figure 1(c) presents the main ideas of our proposal, which includes two main levels: orchestrator and broker. Particularly, the orchestrator is a component in charge of managing the distribution of client requests among the brokers. The term orchestrator is commonly used to define a component with administration functions, as presented in Hurtle (http://hurtle.it/), Open Baton, 18 LiveCloud, 19 and Roboconf. 20 The multi-level keyword is explored in two elasticity levels, orchestrator and broker, and through the addition of a geolocation domain name system (DNS) service to define the most suitable entry point in the Pub/Sub architecture. The broker level is responsible for processing and handling messages, while orchestrator level performs load balancing and elasticity among brokers. The scientific contribution of Brokel relies on offering a peak-aware agnostic elastic Pub/Sub model, which can be implemented in any Pub/Sub system in the market, including RabbitMQ (https://www.rabbitmq.com) and Mosquitto (https://mosquitto.org). The peak-aware feature enables Brokel to avoid false-positive VM allocations, avoiding scaling in or out operations when only a load peak is observed.
In the next sections, we present more details about Brokel. First, we introduce related work and then describe Brokel in detail, including its architecture and elasticity decision making. Second, we present the evaluation methodology in terms of client application, test scenarios, and observed metrics. Finally, we present experiment results and final considerations. In particular, in the last part of the article, we emphasize again the scientific contribution of the work also detailing several challenges that we can address in the future.
Related work
This section presents some initiatives that guided us on developing Brokel. Here, we are handling Pub/Sub systems and how they address scalability.
Running in cloud environments, E-STREAMHuB covers a mechanism for automatically expanding and reducing resources for Pub/Sub services with content-based filtering. 21 The E-STREAMHuB system is an extension of STREAMHuB, 17 a scalable but static Pub/Sub engine. Subscribe messages are sent via unicast to a selected operator, while publish messages are transmitted through broadcast to all operators. E-STREAMHuB introduces data parallelism on Pub/Sub systems, enabling the processing of several publish messages in parallel to registered signatures. However, if the number of publish messages grows quickly, all the solution will be overloaded since all messages are sent to all operations for matching purposes. Elastic Queue Service (EQS) 15 is a message queuing architecture classified as topic-based Pub/Sub, designed to allow elastic scalability, performance, and high availability. Its project concerns the deployment of a Cloud Computing infrastructure using Infrastructure as a Service (IaaS). The EQS elasticity is obtained by migrating topics between processing nodes. If the migration is not enough, the model can instantiate new replicas to meet the growing demand. Migration of threads between nodes can lead to cost and potential service disruption.
Blue Dove 22 seeks to deploy attribute-based Pub/Sub services in public cloud environments. Available nodes are divided into regions, which one with its attributes. Subscribe and publish messages are sent to the servers that manage a particular region. Its architecture has two layers. The first concerns Dispatchers Servers, which plays the role of front-end, so directing publishers and subscribers to nodes that manage a given region. The second works as system back-end, processing received messages and forwarding to subscribers when necessary. Its approach only provides attribute-based filtering in addition to not allowing extraction of contents from subscribe messages on the server side. Blue Dove partially supports elasticity, allowing only scaling out operations without supporting any kind of resource release in under-utilization cases. In Wang and Ma, 23 the authors present a content-based, scalable, and elastic Pub/Sub service called general scalable and elastic content-based Pub/Sub service (GSEC). GSEC proposes a framework with two layers, which uses a hybrid space partitioning technique to achieve a high throughput rate, dividing subscriptions into multiple clusters through a hierarchical way. In addition, a helpers-based content distribution technique is proposed to achieve high upload bandwidth, in which servers act as providers and coordinators to fully exploit the system’s upload capability.
X Ma et al. 5 focus on a hierarchical architecture of servers to provide low latency in event matching of attribute-based Pub/Sub systems. Their solution divides all servers in two specific layers that define their function. Servers in the first layer act as load balancing applying a hash strategy to define to which broker send a request. The brokers act in the second layer processing client requests matching events to subscriptions. In addition, a component named PDetection is in charge of monitoring the requests’ waiting time in the broker layer and performs elasticity actions comparing it with defined thresholds. After an elastic action, PDetection performs all reconfigurations in brokers and load balancers to adjust to the new configurations.
Elastic computing framework (ECF) 24 presents an architecture in which programmability of front-end machines is drawn upon to dynamically divide data processing tasks into (1) those that see all of the data but perform simple operations on it; (2) those that see a transformed subset of the data and extract deep insights from it. This results in lifting pressure on network that links the front-end to the back-end and achieves capability adaptive deployment of IoT solutions. In Bellavista and Zanni, 25 the authors propose a distributed architecture combining machine-to-machine industry-mature protocols (i.e. Message Queue Telemetry Transport (MQTT) and Constrained Application Protocol (CoAP)) to enhance scalability of gateways for efficient IoT–cloud integration. In addition, the article presents how they have applied the approach in a practical experience of efficiently and effectively extending the implementation of open-source gateway that is available in the industry-oriented Kura framework for IoT. This architecture is used by Bellavista and Zanni 26 to propose a scalability solution for IoT gateways via MQTT–CoAP integration. The authors use the hierarchical structure of MQTT to enable an easy way to manage messages. Using CoAP, the solution provides a CoapTreeHandler responsible of dealing with changes in the hierarchy. Through this strategy, it is possible to add or remove entities without needing topics reconfiguration.
Table 1 presents a comparison among the aforementioned research initiatives. We perceive that some academic researches are focusing on providing cloud elasticity toward Pub/Sub systems. However, this combination is an open challenge when it comes to elasticity support for middlewares. Alternatives have to deal with some limitations related to either difficulty to adapt the application to take advantage from elasticity or middleware implementation restrictions. A common strategy present in the literature to transform a non-elastic application in an elastic one requires changes in the application source code or development of additional scripts.5,15,21–23,26 It makes the adoption of resource reorganization of cloud-based Pub/Sub applications more difficult, since developers/administrators must have a deep knowledge about both system environment and application code. Moreover, we perceive that elasticity is mainly addressed by solutions employing threshold-based reactive techniques, combining horizontal and replication techniques.5,15,21–23 Such strategy requires user experience in configuring specific parameters and deploying cloud resources. However, the use of load threshold to guide resource reorganization can cause the problem of VM thrashing, where sporadic peaks exceeding one of the thresholds can result in an undesired elasticity action, being interpreted as a false-positive action. Finally, the main limitation of the state-of-the-art today refers to the elasticity support, which is offered only in a single level.5,16,24,27–29 What happens when users have an additional broker and need to inform or rewrite their own applications to deal with this new broker? Or yet, how can users know the best broker to receive the client (publisher or subscriber) requests in order to reduce communication latency in this interaction?
Related work comparison in front of seven relevant Pub/Sub features.

VM: virtual machine.
Brokel proposal
Brokel is a multi-level cloud elasticity model for Pub/Sub Brokers. The model also includes Orchestrator replicas, which are responsible for load balancing clients’ requests between the active Broker instances. Brokel offers a two-level elasticity approach providing elasticity for Brokers and Orchestrators. In this section, we present Brokel, including its architecture, application model, and elasticity mechanism. In the next subsections, we discuss details about the model. Therefore, in the first place, we present the design decisions. Also, we describe details about the architecture and model components. Finally, we discuss the application model and the elasticity decisions.
Design decisions
Brokel provides reactive and horizontal elasticity transparently for users, things and applications in both Broker and Orchestrator levels. We adopted horizontal elasticity by applying VM replication since vertical elasticity is limited by the resources available in a particular physical node. In addition, the majority of operating systems do not allow the addition of resources at runtime without a system reboot.30,31 To develop Brokel, we adopted the following design decisions:
Users do not need to configure the elasticity mechanism; however, they can input elasticity thresholds;
Developers do not need to rewrite their source code to take advantage from elastic resources;
The model is agnostic at the Pub/Sub system viewpoint, since the code of Brokers is encapsulated in VM templates;
The Broker provides authentication to the actors who connect to it;
The cloud architecture considers homogeneous resources, that is, each VM has the same hardware configuration;
Resource provisioning is accomplished through a threshold-based reactive, horizontal, and automatic elasticity mechanism with VM replication;
The elasticity runs in two levels: Broker replication and Orchestrator replication.
Architecture
Brokel operates at the PaaS (Platform as a Service) level of a cloud, acting as a middleware that transforms non-elastic Pub/Sub applications in elastic ones. Figure 2 depicts the main ideas of Brokel, highlighting the communication path for information exchange. The model focuses on enabling Pub/Sub Brokers to take advantage from cloud elasticity without needing source code modifications. In this way, Brokel provides elasticity by allocating and consolidating VMs with replicas of application services. Additionally, the Orchestrator plays an important role in the architecture since it is in charge of balancing clients’ requests among Brokers. At the user’s viewpoint, the Orchestrator acts as a web server processing clients’ requests as a Broker itself. The user does not need to change its application to connect to an Orchestrator since it dispatches the requests to a Broker. Furthermore, aiming at providing a multi-level elasticity model, Brokel also provides elasticity for Orchestrators. The model maintains a DNS server allowing clients to query an appropriate Broker. Thus, the server returns a single address for a particular Orchestrator, so then acting as a load balancer for the Orchestrator level.

Brokel ideas representing how client requests are distributed among the Orchestrators and Brokers.
To illustrate Brokel architecture, Figure 3 presents its three main components, each one running in a particular VM: (1) Broker, (2) Orchestrator, and (3) Elasticity Manager. The Broker is in charge of processing clients’ requests. Each Broker VM runs a particular message broker system, which is managed by the Pub/Sub provider. Brokel is generic enough to cover all message broker systems. In turn, the Orchestrator is in charge of routing clients’ requests to the active Brokers transparently. Acting as a wrapper, the Orchestrator forwards requests to a suitable Broker and, if applicable, receives the Broker delivery and forwards it to clients. Moreover, elasticity is provided by the Elasticity Manager in both Broker and Orchestrator levels. This component performs all activities related to cloud resources and communication topology reorganizations. Additionally, it also provides the DNS service providing load balance among the Orchestrator VMs.
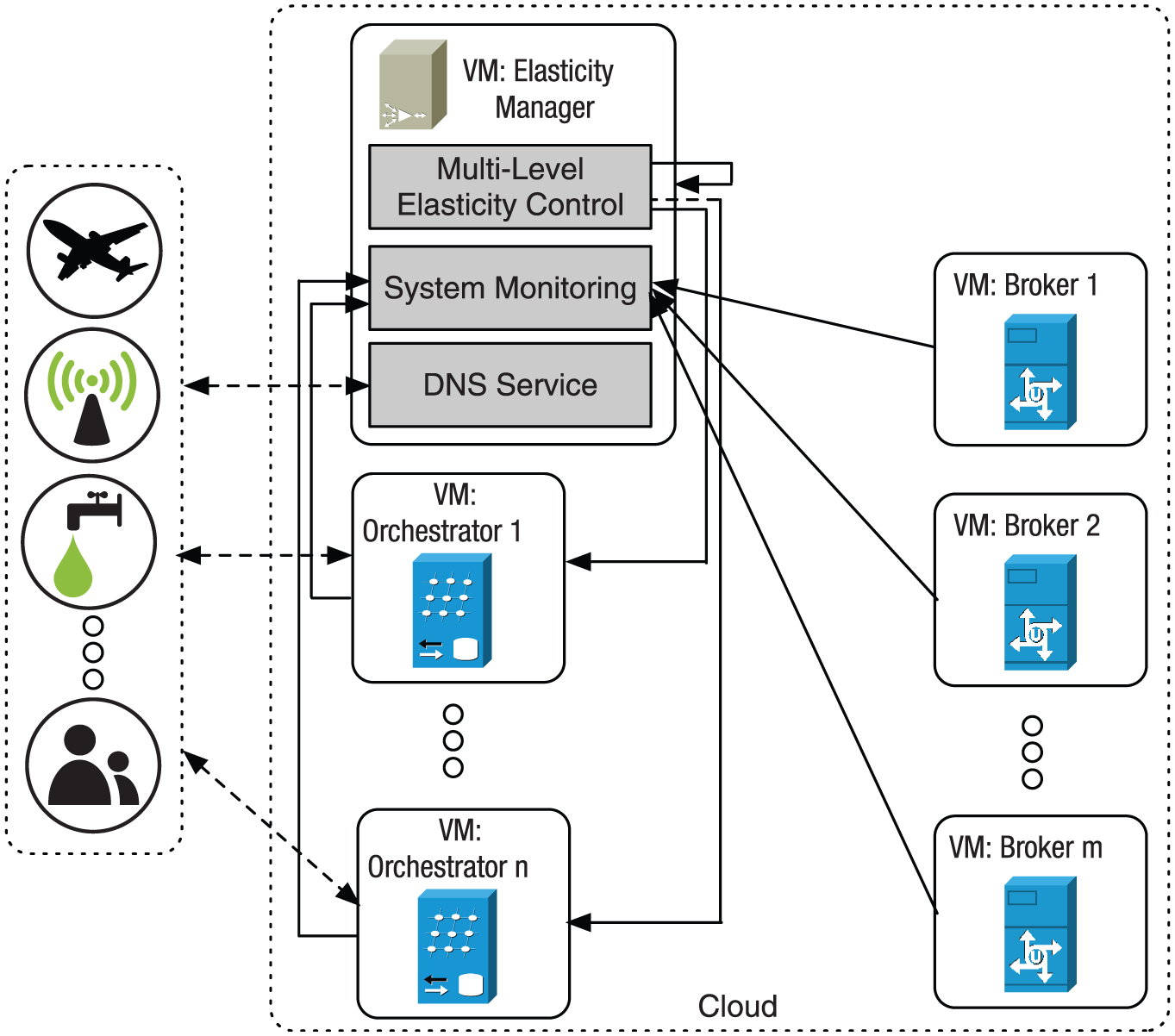
The Brokel architecture. While the number of Broker VMs is m, the number of Orchestrator VMs is identified by n. The number of VMs running in the cloud is v, which can be computed by
Brokel levels
In the Broker level, the system operates as a traditional Pub/Sub system, which means that the provider does not need to change its system behavior. A Broker receives requests from both clients and Orchestrator processes not needing to be aware if the request came from an Orchestrator or a client itself. In this context, for subscribe requests, it just updates its distribution list. On the other hand, for publish requests, the Broker generates a client distribution list and sends the message to these clients. At the Orchestrator level, a particular Orchestrator forwards clients’ requests to Brokers in different ways depending on the type of the request. In particular, the Orchestrator processes send requests and receive data from Brokers as clients. When receiving a publish request, an Orchestrator forwards the message applying a round robin strategy to select one of the active Brokers. We selected this algorithm due to the simplicity and efficiency for load balancing between servers. Nevertheless, when handling a subscribe request, the Orchestrator connects to all Brokers individually and sends the message to them. This strategy is pertinent to guarantee that all Brokers have its subscriber lists updated. Additionally, it enables an one to n communication topology that is not supported by default in a transmission control protocol (TCP) implementation.
Brokel Elasticity Manager
Brokel Manager is in charge not only of DNS services, but also of managing all operations related to resources monitoring and elasticity actions. Therefore, the Manager takes account of the processing load on VMs as input data to elasticity decision making. The Manager executes all cloud reconfigurations by sending requests to the Cloud Front-End, which is in charge to execute all operations related to the cloud environment by receiving requests through the cloud provider application programming interface (API). The Manager observes the cloud resources central processing unit (CPU) occupation levels in constant periods of time evaluating the need of elasticity. To illustrate its functioning, Figure 4 shows the main monitoring phases that the Brokel Manager executes. At each monitoring observation, the Manager collects data from the available resources and evaluates it afterward for elasticity decision making. When scale out operations take place, the new resources require some time to be actually available for the application. This happens due to the process of transferring the VM image to a physical node and bootstrap overhead of the VM operational system. The Brokel Manager is aware of this process delivering the new resources only after they are online in fact. Thus, after starting the allocation process, the Manager continues its execution flow and at the beginning of each monitoring observation, it checks the new resources are online.
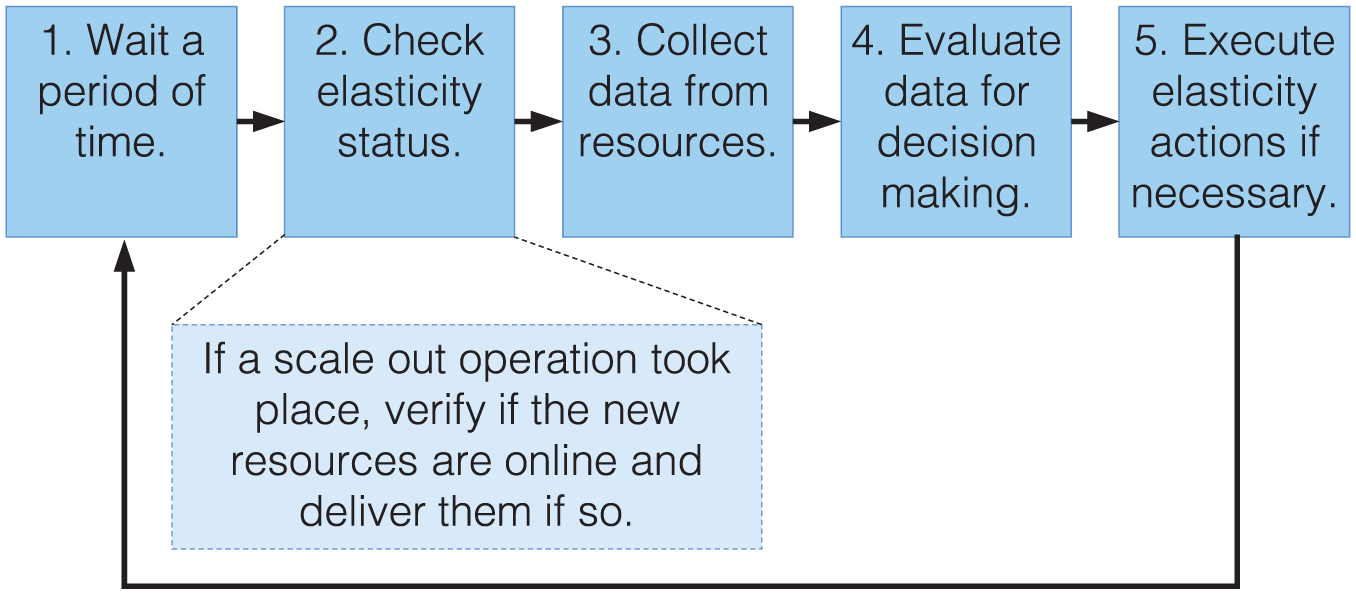
Brokel Manager computation phases.
In particular, after performing an elasticity action, the Manager needs to reorganize the communication topology. To clarify this process, Algorithms 1 and 2 present pseudo-codes with the main operations the Manager does in each cloud elasticity moment. Algorithm 1 presents the pseudo-code when a scaling out operation takes place. When adding a new Broker VM (line 4), the Elasticity Manager configures this new Broker with the current subscribers list (line 5). Specifically, line 8 of the algorithm represents the operation where the Elasticity Manager reconfigures all active Orchestrator processes including a Broker in its lists. In case of adding a new Orchestrator (line 12), the Elasticity Manager configures the list of Brokers in this new Orchestrator (line 13) and updates the DNS service (line 14). However, instead of connecting with external VMs, when updating the DNS the Manager only needs to reconfigure its own DNS service.


When removing either a Broker or an Orchestrator, the Manager must ensure that the target VM is neither receiving nor processing clients’ requests before performing the scale in operation. Thus, the Manager executes a collection of operations to guarantee it. Algorithm 2 presents the pseudo-code when a scaling in operation takes place showing these operations. When removing a Broker VM, the Manager executes four steps. First, it configures all Orchestrators to not send requests to the Broker that will be removed (line 6). Second, it waits until the target Broker be idle and not processing client requests (line 9). This step is important to guarantee that clients’ requests will not be lost. In the next step, the Manager removes the Broker VM from the cloud (line 12). Finally, it notifies all Orchestrators to remove completely the Broker from its lists (line 13). In case of removing an Orchestrator, the Manager performs similar operations. First, it removes the Orchestrator from the DNS service (line 15) in order to guarantee that new client request will not be processed by this particular Orchestrator. Following, as when removing a Broker, the Manager waits until the Orchestrator finishes clients’ requests (line 16). Thus, only after that, it removes the Orchestrator VM from the cloud (line 19).
Application model
Brokel offers a two-level elasticity approach for both Brokers and Orchestrators. Thus, many Brokers and Orchestrator are available to process clients’ requests. Consequently, the flow of these requests is different depending on its type (publish or subscribe). Therefore, Figure 5 shows the request processing flowchart when a client request arrives. First, a client requests an Orchestrator to the DNS service that selects one of the active Orchestrator replicas employing a load balance algorithm. Next, the client sends the message to the Orchestrator which analyzes it to discover the request type. Depending on this type, the Orchestrator acts in two different ways. If the message is a subscribe request, the Orchestrator stores this information and forwards the request to all active Brokers. The process of store information by Orchestrator is important in situations where Brokel elasticity mechanism includes new Brokers. All new Broker needs to be updated of all subscriptions before it can operate properly. On the other hand, if the message is a publish request, Orchestrator applies the load balance algorithm to select the most suitable Broker to forward the message. This strategy is pertinent to avoid that two different Brokers process the same client request. Also, it increases the model processing capacity.

Message processing flowchart.
In the last phase of the flowchart, the message arrives to a Broker. Then, the Broker analyzes its type and, if the message is a subscribe request, the Broker just stores this information in its table and the flow ends. However, if the message is a publish request, the Broker engine generates the client distribution list and sends it to the Orchestrator. Finally, the Orchestrator sends the message to all clients and the flow ends.
Elasticity decisions
When considering the task of monitoring resources, cloud platforms typically use metrics from the operating system to determine the node workload. In this context, CPU load in percentage refers to the most used metric particularly pertinent for CPU scavating applications.29,32,33 Thus, Brokel Manager monitors CPU load of each VM periodically and computes the load for each level. If resource reorganization is necessary, the Manager proceeds elasticity actions using the cloud API. When completing elasticity verification and action tasks, the Brokel Manager ends a monitoring observation and waits for the next monitoring cycle.
One role of the Manager is to generate the system load (l) in order to minimize the effect of disturbances or noises on the behavior of the target level. Thus, we are working with time-series and simple exponential smoothing (SES),
34
also referred as weighted moving average
35
—technique over the CPU load metric of each VM. Equation (1) presents


Evaluation methodology
In this section, we present methodological aspects related to the Brokel evaluation, starting from the application. Next, we discuss both infrastructure and evaluation scenarios. Finally, we show the metrics used to evaluate the experiments in the proposed scenarios.
Application prototype
To evaluate Brokel, we designed two different applications: (1) a Publisher application to produce and send messages to our platform and (2) a Subscriber application to receive these messages. The Publisher receives an input file containing a list of messages to produce for a specific topic. In addition, each line of the file contains three parameters: (1) target topic, (2) data field 1, and (3) data field 2. To represent how Publisher works, Algorithm 3 shows it as a loop processing each line of the file separately. Basically, each line of the file results in an operation of publication of a message. On the other hand, the Subscriber receives the same file, processing it differently. The application reads each line of the file, retrieves the target topic, and sends a subscribe request to the server. To illustrate this process, Algorithm 4 shows the Subscriber functioning. Regarding optimizations, a topic receives a subscription only once.


To simulate data input to our model, we used a data set 36 with over 21 million records. Each record describes the precise location of one of the 316 taxis of Rome with the following structure: taxi identification, location, timestamp (date/time). The Publisher application uses the identification field as a topic and the location and timestamp as the message body. The data represent all data gathered between 1 February 2104 and 2 March 2014.
Elasticity manager prototype and cloud infrastructure
We implemented a Brokel prototype for private clouds using OpenNebula (https://opennebula.org/) version 4.12.1. The Brokel Elasticity Manager was coded in Java and it uses the Java-based OpenNebula API for both monitoring and elasticity activities. Two image templates for the VMs were provided: one for the Orchestrators and another for the Brokers. The grain of an elasticity action is always a single VM, so we have an increase or decrease of 1 Orchestrator or Broker at every resource reorganization. Moreover, as presented in Sladescu and Fekete, 14 we used the interval of 15 s to configure the Brokel Manager periodic monitoring activity, which is associated with the OpenNebula lowest bound index for periodical VM monitoring.
Considering the cloud infrastructure, our cloud is composed by 11 (1 Front-End and 10 nodes) homogeneous 2.9 GHz dual core nodes, each one with 4 GB of RAM memory, and an interconnection network of 100 Mbps. These nodes are configured with the Operational System Ubuntu Server 14.04 LTS. Besides, we configured in the cloud Front-End the shared data area to store application files and VM images. Finally, our DNS was deployed using the BIND (https://www.isc.org/downloads/bind/) DNS server version 9.9.5.
Evaluation scenarios
To evaluate our solution, we designed a set of scenarios with different configurations. We are considering strategies which support either single or multi-level elasticity. In addition, we are also evaluating the performance of our application prototype as a basis of comparison among the different scenarios. Particularly, we are basing this strategy on the work of Barazzutti et al., 21 which first evaluated an application without elasticity support as a baseline. Thus, aiming at analyzing the impact of different configurations in the application performance, we defined three scenarios: (s1) running the application with the lowest number of VMs and disabling the elasticity feature, (s2) running the application starting with the lowest number of VMs and enabling elasticity in the Broker level, and (s3) running the application starting with the lower number of VMs as possible and enabling the multi-level elasticity. For all executions in these scenarios, the application started with one single VM per stage. In scenario s1, the goal is to obtain the results from the execution of the application without considering elasticity. In this scenario, the results represent traditional approaches, in which the application runs with the same amount of resources in the entire execution. On the other hand, in scenario s2, we aim to evaluate our model as a single-level elasticity solution. So, in this scenario, we reorganized resources only in the Broker level. Finally, in scenario s3, we intent to evaluate our model enabling elasticity in both Broker and Orchestrator levels. This is the scenario that characterizes our model as a multi-level elasticity solution.
Regarding scenario s2, we used two Broker environments to model three subscenarios: (s2.1) VM replicas running Mosquitto Broker, (s2.2) VM replicas running RabbitMQ Broker, and (s2.3) 50% of VM replicas running Mosquitto Broker and 50% of VM replicas running RabbitMQ Broker. Furthermore, in these subscenarios, we first executed the application setting the cloud service level agreement (SLA) to allow a maximum of 6 VMs in the cloud. Later on, we run again the application in these scenarios setting the cloud SLA to allow a maximum of 10 VMs. Concerning elasticity parameters, 70% and 90% were used for the upper threshold (
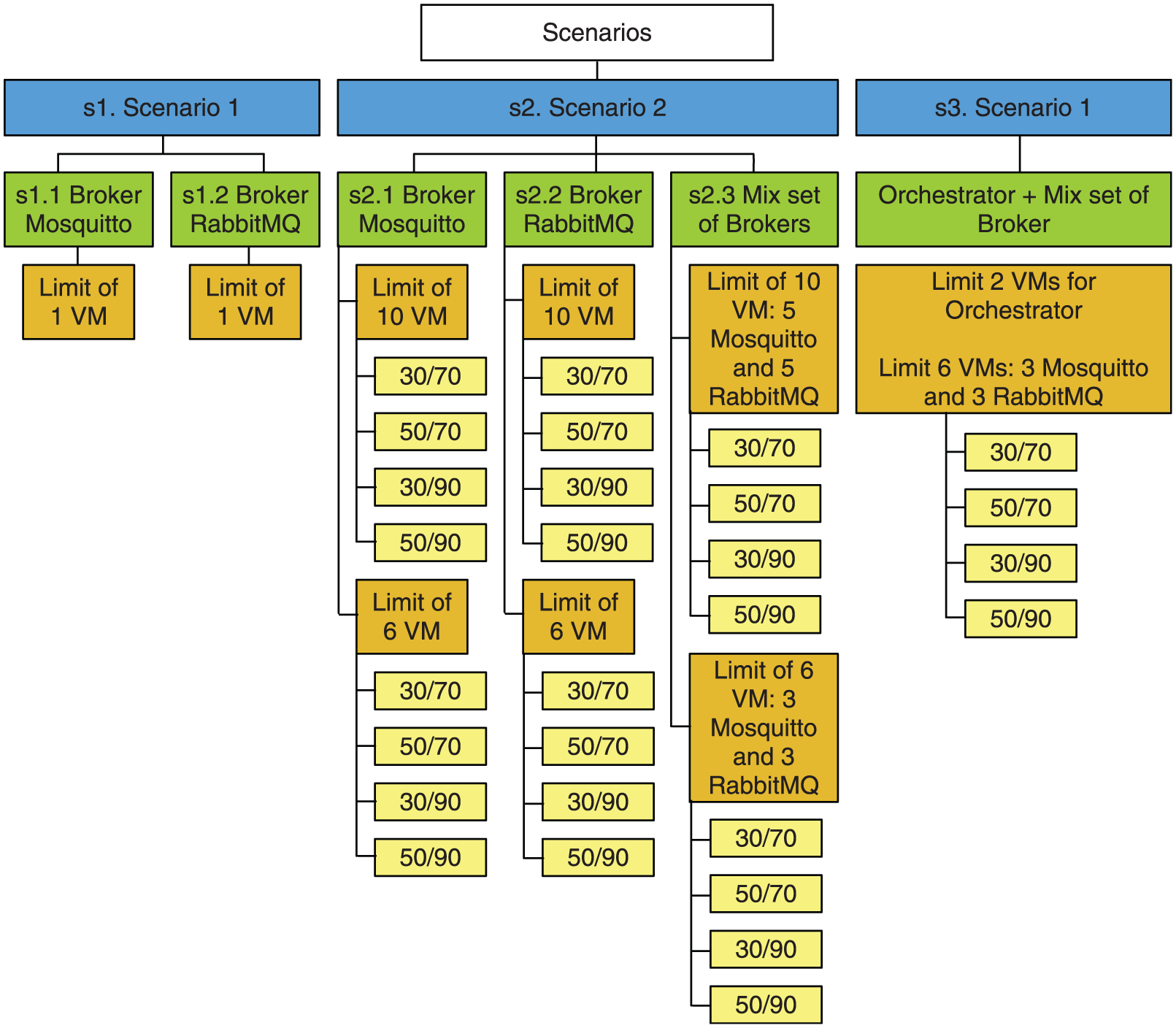
Evaluation scenarios: without elasticity in s1 and with elasticity in s2 and s3.
To generate input load for scenarios s1 and s2, we instantiated 20 publisher processes and divided among them the first 400,000 records of our data set. In addition, we also instantiated 20 subscriber processes to receive these data. In scenario s3, as the elasticity multi-level is enable, we doubled the input data to generate a higher throughput and, consequently, increase the load. In this way, we instantiated in scenario s3 40 publisher processes and divided among them the first 800,000 records of our data set. Furthermore, we also instantiated 40 subscriber processes to receive these data.
Evaluation metrics
Focusing on analyzing performance and resource consumption, our evaluation analyzes the aforementionecenarios against four metrics: time,


Results
This section presents the results, which were organized in five subsections for better exploring each perspective of cloud elasticity applied to Pub/Sub systems.
Application time
Figure 7 illustrates the time spent on handling the workload on each environment configuration. The y-axis refers to the type of Broker used and the replica boundary, while the x-axis corresponds to the time measured in seconds in which a bar refers to a threshold setting. In particular, the first value is the lower threshold (

Application execution time of all scenarios and configurations.
The percentage of reduction in execution time using Brokel is shown in Figure 8. In this figure, we present a comparison of Mosquitto with 6 VMs and 10 VMs against the deployment using a single VM. Moreover, the same was conducted for the RabbitMQ broker. We can perceive that Brokel reduced the time required for handling the workload in environments running the Mosquitto broker by up to 76.6%. The advantage was even greater when running with RabbitMQ, reaching 81.2% of time reduction. In general, the best result obtained using elasticity was with Mosquitto (10 VMs) when using

Percentage of reduction in execution time.
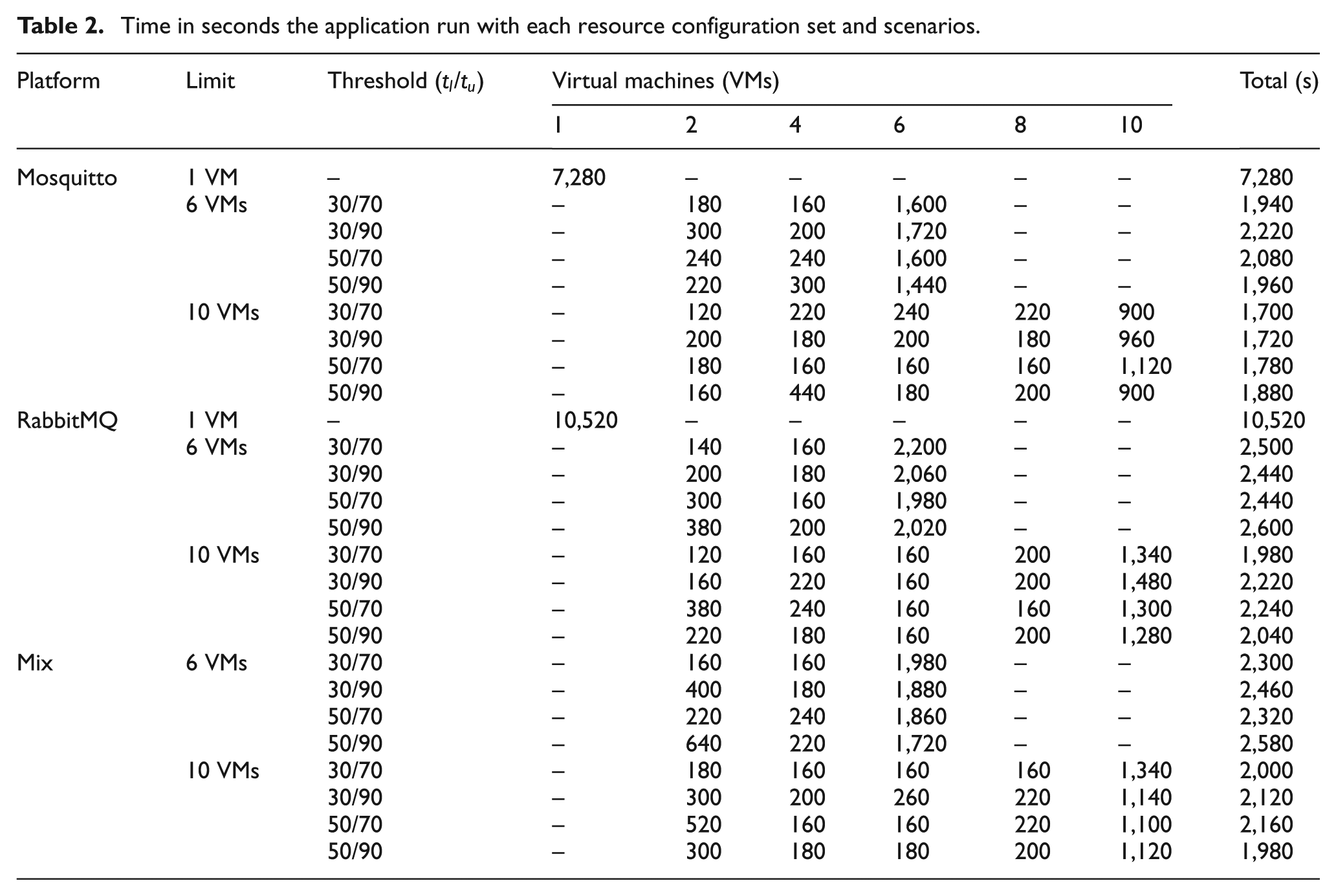
Resource allocation
Table 2 shows the utilization time of the virtual resources on each environment configuration. For example, the Mosquitto environment with a limit of 10 VMs using
Time in seconds the application run with each resource configuration set and scenarios.

Profile of VM configuration along the application execution in each scenario and configuration.
Figure 10 depicts the state of the thresholds at each monitoring point. The y-axis refers to the type of Broker, the allowed replica limit, and thresholds used in the experiments. The x-axis corresponds to the number of collections performed and each stacked bar of the graph means the state of the thresholds. Mosquito obtained 39 readings above

Load status in all monitoring observations.
Throughput analysis
Figure 11 illustrates the rate of messages per second handled at each environment setting. The y-axis refers to the type of broker used and the allowed replica limits. The x-axis corresponds to the number of messages per second (Mps) and each bar of the graph means a threshold setting used. It is important to highlight that the messages have the same size for all executions.

Messages per second handled by the application.
Mosquitto (1 VM) obtained the best result when considering the concurrents inside scenario s1 (without elasticity), reaching a rate of 54.95 Mps. RabbitMQ (1 VM) environment achieved a performance of 38.02 Mps, then 30.8% lower than the previous one. Using the limit of six replicas of VMs, the best result was obtained by Mosquitto (6 VMs) environment using
In particular, with the replica creation limit set to 10 VMs, 235.29 Mps were treated in the Mosquitto (10 VMs) environment using
Cost and efficiency
In Table 3, we present the results regarding the cost of each execution. The cost computation corresponds to the total number of resources used during the execution of the experiment. Thus, the idea is to minimize the cost. Figure 12 depicts the information presented in Table 3. Here, the y-axis refers to the type of broker used and the allowed replica limit. In its turn, the x-axis corresponds to the cost value where each bar of the graph represents a threshold setting used.
Cost results of all evaluation scenarios.

VM: virtual machine.

Total cost to execute the application in all scenarios.
The best result associated with the cost was obtained by the Mosquitto (6 VMs) environment with
Efficiency results of all evaluation scenarios.

VM: virtual machine.
Multi-level resource allocation
The main objective of scenario s3 is to evaluate the elastic performance in the Orchestrator layer. To accomplish this, two replicas of Orchestrator VMs were used, as well as three Mosquitto Broker replicas and other three broker replicas for RabbitMQ. Table 5 shows the utilization time of the virtual resources in each environment configuration. For example, the broker setup with a limit of 6 VMs using
Time the application run with each resource configuration set in the multi-level scenario.


Profile of resource allocation in scenario s3.
Figure 14 shows a graph of CPU utilization in the Orchestrator viewpoint when running scenario s3 with 30% and 70% for thresholds. Here, the blue line represents the total CPU allocated at the time of data collecting, while the red line refers to the CPU usage. Figure 15 presents the same information as Figure 14, but referring to scenario s3 with 50% and 70% for thresholds. These two figures were selected to demonstrate the impact that thresholds setting can cause to the environment with elasticity.

Resource utilization and allocation in scenario s3 with thresholds
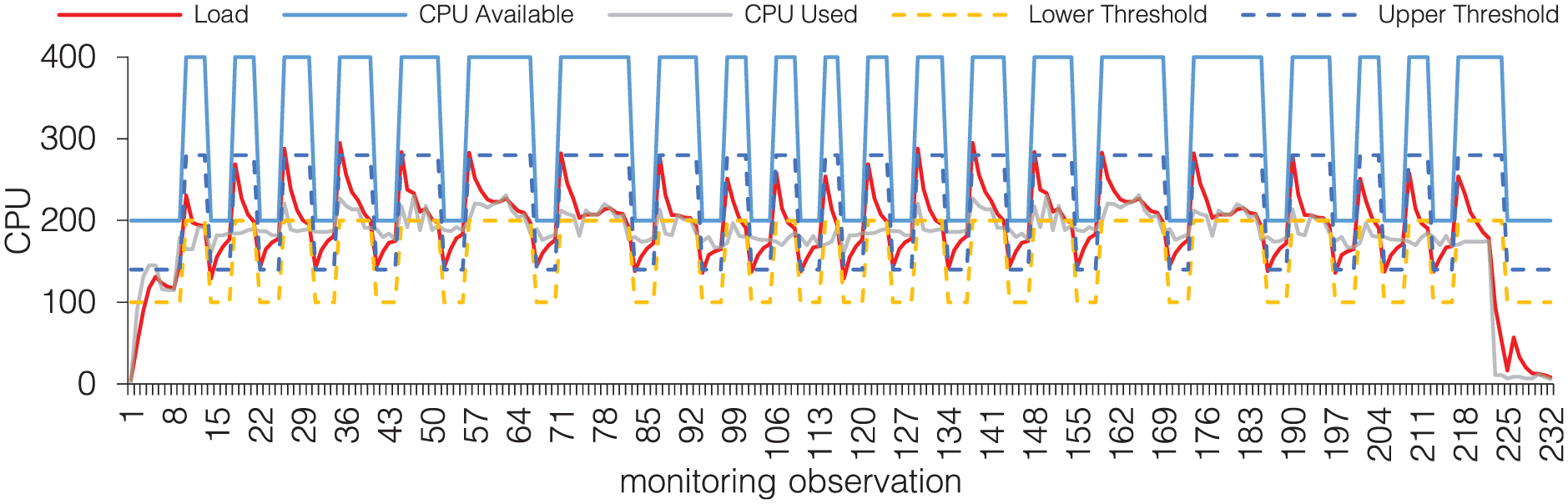
Resource utilization and allocation in scenario s3 with thresholds
In the experiment represented by Figure 15, the second Orchestrator replica is instantiated around observation 13. This action is performed because the total processing of the environment exceeds the value of
Conclusion
This article presented Brokel, a multi-level elasticity model for Pub/Sub brokers, so enabling a performance-driven communication bus that integrates applications, things, and users. Our idea is to address the growing IoT demand in an effortless way at clients viewpoint, enabling them to perceive an acceptable performance level when using the Pub/Sub system regardless of load and time of day. We introduced two elasticity levels: Broker and Orchestrator, in which the latter acts as a load balancing wrapper without needing to change the existing Pub/Sub applications. Cloud elasticity is also offered as an agnostic service to brokers, that is, we only need to create VM templates for each target broker, allowing Brokel to work with any Pub/Sub broker (such as RabbitMQ, Mosquitto). Our scientific contribution relies on providing horizontal elasticity at both Orchestrator and Broker levels, adding the possibility of using a geolocation DNS service to define the most suitable entry point (Orchestrator) to the messaging system. Another Brokel feature that we did not observe in Pub/Sub state-of-the-art refers to the Aging method on evaluating the load of both aforesaid levels, then avoiding VM thrashing on elasticity actions.
To the best of our knowledge, there is no solution that proposes cloud elasticity in Broker and Orchestrator levels. Thus, we compared our solution with different configurations and non-elastic scenarios. Our results are encouraging and serve as proof of concept for the use of elasticity in Pub/Sub systems. We evaluated Brokel by developing a prototype and a client application, testing both against different scenarios, brokers, and metrics. Comparing elastic and non-elastic environments, we highlight performance gains of 76.6% and 81.2% when using Mosquitto and RabbitMQ brokers, respectively. At messages per second (Mps) viewpoint, we also get throughput benefits: from 54.95 to 235.29 Mps for Mosquitto and from 38.02 to 202.02 Mps for RabbitMQ. When exploiting the resource metric perspective, the best result was obtained when averaging 5.24 VMs per second during the execution, with lower threshold of 50% and upper threshold of 90%. These threshold values are in charge of postponing resource allocation, since new resources will only be instantiated after crossing 90% of system load. On the other hand, the worst results in the resource perspective happened when using 30% and 70% for the lower and upper thresholds, revealing a value of 8.51 VMs. In the elasticity scope, it is pertinent to observe that execution time and resource allocation are inversely proportional metrics.
Future research includes the evaluation of Broker on real environments. We are studying the possibility to assess it in post office agencies. Furthermore, future studies include additional evaluation of research strategies employing our solution. Additionally, we intend to improve network performance investigating event notification strategies as proposed in Scalable Internet Event Notification Architectures (SIENA) (http://www.inf.usi.ch/carzaniga/siena/).6,7 Although presenting encouraging results, the current version of Brokel uses reactive elasticity where lower and upper thresholds must be informed beforehand. Thus, we plan to explore proactive elasticity in order to drive elasticity actions in advance, therefore delivering the resources before entering in an over- or under-provisioning state.
Footnotes
Academic Editor: Sang-Woon Jeon
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the following Brazilian agencies: CNPq, FAPERGS, and CAPES. The work was also partially supported by Finep, with resources from Funttel, grant no. 01.14.0231.00, under the Radiocommunication Reference Center (Centro de Referência em Radiocomunicações (CRR)) project of the Inatel, Brazil.