
Abstract
K-means plays an important role in different fields of data mining. However, k-means often becomes sensitive due to its random seeds selecting. Motivated by this, this article proposes an optimized k-means clustering method, named k*-means, along with three optimization principles. First, we propose a hierarchical optimization principle initialized by k* seeds (
Introduction
Clustering is to partition the data into different clusters with respect to similarity measures and is one of the most important tasks in data analysis, such as pattern discovery, pattern recognition, data summary, and image processing. 1 These fields now include many branches, namely partition-based methods, model-based methods, 2 hierarchical methods, 3 density-based methods,4–6 graph-based methods, grid-base methods, 7 and clustering ensemble methods. 8 Partition-based method is the simplest and most important part of cluster analysis, and many algorithms are raised to facilitate its process such as k-means, 9 k-means++, 10 and k-medoids. 11
K-means is a skillful and classic method in clustering. Given a dataset


Due to it is simple yet effective, k-means becomes a widely used clustering algorithm across different disciplines over the past 50 years.12–15 However, k-means has an obvious limitation that it is sensitive to the initial seeds selecting. Random initial centers always lead to k-means trapped in the local optimum easily. A frequent observation that k-means usually merges small adjacent clusters into a larger one or divides a large cluster into several small partitions to let

Example of clusters begins with a bad initialization.
Many work attempts to resolve the sensitivity of initialization for k-means.1,16 Arthur and Vassilvitskii
17
propose a probability-based seeds selecting method called k-means++. The probability of point
Moreover, k-means suffers from the high computational complexity for processing high-volume datasets. Hence, there is another class of methods that attempt to improve the performance of k-means. To accelerate k-means, Hamerly 19 leverages the distance bounds and triangle inequality to avoid the redundant distance calculation. On the other hand, parallel solutions are also developed to further improve the performance of k-means. In Bahmani et al., 10 they propose a scalable k-means++ to accelerate the initialization process in parallel on Hadoop platform. The parallel computational model reduces the number of passes over large datasets.
In this article, we propose k*-means algorithm, a novel hierarchical clustering, to improve both effectiveness and efficiency of k-means. In k*-means, we first start k-means with
While this work is based on a conference article, 20 the scope of the proposed work has been significantly extended.
In this article, we now integrate these three optimized principles into a framework (section “Framework”). The framework helps us to better understand k*-means algorithm in a holistic approach.
We now add and elaborate the proof of the proposed principles and strategies. These materials include “top-n nearest cluster merging” (Lemma 1), “optimized update principle” (Lemma 2 and Lemma 3), and “cluster pruning strategy” (Lemma 4).
We give the pseudo-code of “top-n merging method” (Algorithm 2) and “optimized update method” (Algorithm 3) with further descriptions.
We extend the experimental evaluation focusing on the effectiveness (section “Effectiveness evaluation”) and efficiency (section “Efficiency evaluation”) of proposed k*-means compared with other existing methods. In addition, we also use five additional datasets to extend the experiments with theoretical analysis.
We now evaluate and discuss the contribution of three optimization principles on efficiency (section “Impact of optimization principles”). Experiments show that our proposed three optimizations reduce CPU time significantly.
We also discuss the value selection of the parameter
Related work
Initialization methods for k-means
Forgey
21
first partition the data into
As mentioned above, k-means++ is a probabilistic-based seeds selected method. The point that has been far away from the already selected seeds has a high chance to be chosen as a center. They claim the complexity of k-means++ reaches at
Su and Dy
23
propose two methods, PCA-Part and Var-Part, to solve the initializing problem. PCA-Part first regards all the data as one cluster, and then cuts it into two partitions by the hyperplane that passes through the cluster centroid and is orthogonal to the principle eigenvector of cluster covariance matrix. After that the method repeatedly selects the cluster that has the greatest
A recent study named MinMax k-means
18
is proposed to overcome the sensitivity of random initialization. MinMax k-means uses the objective of maximum
Another category of methods try to eliminate the dependence on initialization, such as global k-means 26 and kernel-based k-means. 27 Experimental results show that these methods achieve a better effectiveness than random initialization of k-means. However, these algorithms relieve the bad initialization at price of much more expensive computations.
Optimized variants of k-means on efficiency
Kanungo et al. 28 implement an efficient k-means method that first uses kd-tree to store instances and then adopts the index to prune or filter the candidate seeds to accelerate the procedure. Hung et al. 29 propose a Unit Block (UB)-based algorithm, which partitions the dataset into blocks and locates the centroids of the UBs. To improve the efficiency of k-means, they just examine the UBs that pass through the boundary of candidate clusters to compute the final converged centroids. Hamerly 19 uses distance bounds and the triangle inequality to accelerate k-means procedure. Another type of algorithm attempts to improve the efficiency of k-means from parallel perspective. Zhao et al. 30 propose a parallel k-means, named PKMeans, based on Hadoop platform. To accelerate the process of k-means++, Bahmani et al. 10 propose a MapReduce-based algorithm, which focuses on the initialization stage of k-means++ to fast obtain the probabilistic initial seeds in parallel by reducing the number of passes. However, these methods also suffer from the sensitivity of initialization issues.
The algorithm
In this section, we present our proposed k*-means method for optimizing both quality and efficiency of k-means. First, we depict overall framework of our k*-means. We next propose three optimization principles to further cut down the CPU cost. These principles include “top-n nearest clusters merging”, “optimized update principle”, and “cluster pruning strategy”.
Framework
Because k-means selects initial seeds randomly, it is difficult to avoid choosing noises or nearer points as the seeds. Figure 1 illustrates the situation happened where some close clusters are merged and a single cluster is divided due to a bad initialization. Especially when handle imbalanced or skewed dataset, the risk of random seeds selecting increases significantly.
Supposing cluster
However, some additional steps need to be implemented to decrease

Top-n nearest clusters merging
As shown in algorithm 1, we first obtain
Definition 1 (edge)
Given two clusters
By Definition 1, we only need to find top-n shortest edge to get top-n nearest clusters. The algorithm of top-n nearest clusters merging strategy, we call Top-n method, is given in algorithm 2. We first use an ascending list structure to store the edges associated with corresponding clusters. Then, the top-n shortest edges are selected and clusters associated with the edges are merged.

However, top-n merging does not always reduce
Proof
Suppose the top-n shortest edges involve
Consider the cases of reducing maximum number of clusters, the first case is that the
Although top-n merging method reduces the number of cluster, we still need to re-compute the feature values of merged clusters for next round optimizing. To save CPU computation, we use a method to get the feature values of merged cluster directly by utilizing the feature values of previous clusters. As shown in Figure 2, suppose clusters

An example of cluster merging: (a) before merging and (b) after merging.
Lemma 1
Given clusters


where
Proof
Without loss of generality, let
First, since

Then we get equations (5) and (6)


Note that
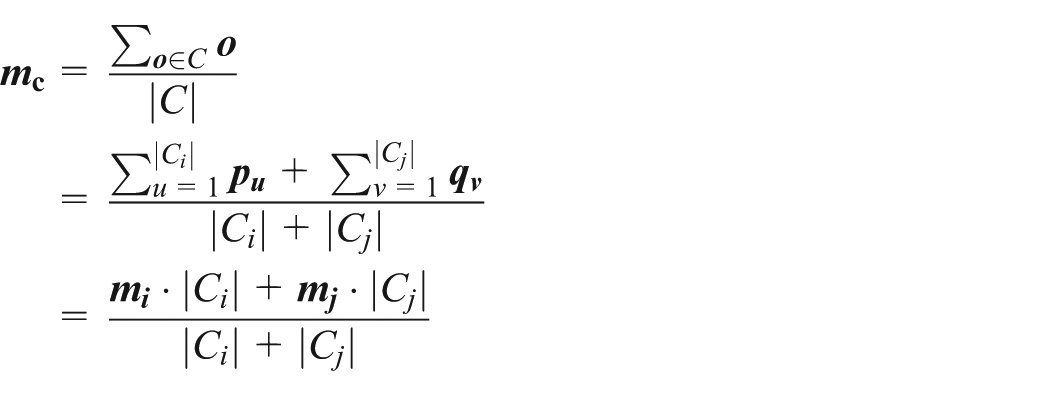
Second,

And then, we get equation (8) by equation (7)

By equations (5) and (6), we also get

Hence, we deduce equation (10) by equations (8) and (9)

Because all points in

By equations (5) and (6) we have

Substituting equation (12) into equation (12), we obtain equation (13)

Therefore, we have equation (4) by equations (10) and (13), and we are done.
Lemma 1 implies that the feature values of merged cluster can be computed directly according to those of previous sub-clusters. Therefore, our top-n nearest clusters merging exactly leverages the optimization strategy to reduce merging cost.
Optimized update principle
From extending experiments on UCI data (see details in section “Experimental setup and methodologies”), we observe that the number of moved points declines sharply during the k-means iteration processes. Figure 3 shows two samples over two real-world datasets. As k-means iteration goes on, the points in clusters trend toward stability; thus, the number of moved points also goes toward zero. In particular, the number of points moved across clusters is very low after the forth iteration. And only average 3% of points are adjusted from fifth iteration to end. Motivated by this observation, we propose an optimized update principle, which updates feature values in each iteration using the moved points instead of re-computation from all points.
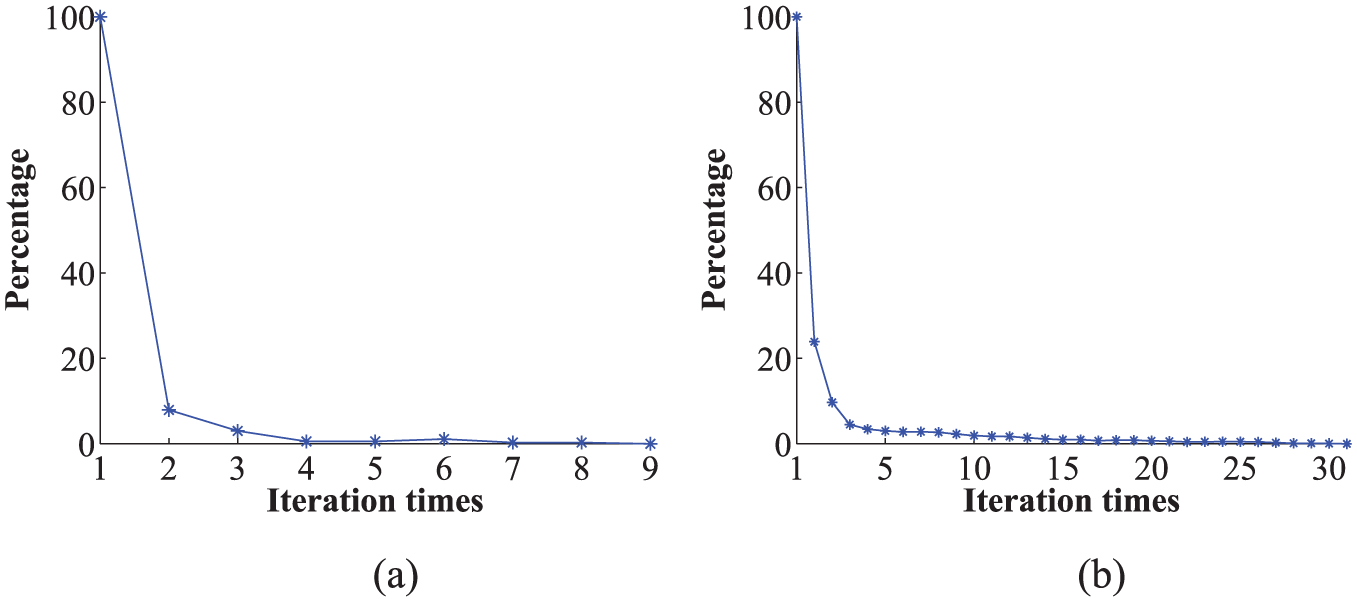
The number of moved points in k-means iterations: (a) dermatology and (b) optdigits.
To understand our optimized update principle, we first state Lemma 2 and Lemma 3.
Lemma 2
Given a cluster


Proof
Lemma 2 can be easily proved by Lemma 1. Consider

and

Lemma 3
Given a cluster


Proof
First, we show proof of equation (17).
Since

By equation (5), we can easily get

Next, we give proof of equation (18). Let

Because

Therefore, we have

According to equation (5), then we get

We further deduce that

by equation (17).
Because
Lemma 2 and Lemma 3 depict updating method of
Armed with Lemma 2 and Lemma 3, we propose the optimized update method to reduce computation costs, as shown in algorithm 3. In each iteration, we maintain the copies of feature values incrementally according to moved points. Optimized update method obviously saves much computation resource when the number of moved points is very low. However, at beginning iterations of k-means, specially, the first round k-means, moved points amount is relatively larger, and the optimized update method may cost more time than completed method. Therefore, we use a threshold

Cluster pruning strategy
To reduce the computational costs, we now introduce optimization principle, regarding to minimization of distance comparison, termed cluster pruning strategy.
In k-means iterations, each point needs to be examined if it is closer to its center than any other centers. Hence, each point has a larger searching space. For example, if there are
Next, we introduce our pruning optimization method for each point at cluster level based on definition 2 and Lemma 4.
Definition 2 (radius)
Given a cluster
Lemma 4
Given two clusters
Proof
Suppose there are two clusters,

Pruning distance between two clusters.
Now, we consider the farthest point in
If
Since

Therefore,
Lemma 4 guides our pruning rule for k*-means iteration. For each cluster
It is essential to show the usage of

k*-means algorithm
Next, we present our extending k*-means algorithm based on our proposed three optimization strategies. The detail pseudo-code of k*-means is shown in algorithm 4.
In k*-means, we also use the random initialization method to choose
Experiments
Experimental setup and methodologies
All algorithms are implemented by Java, and all experiments are performed on platform equipped with 2.4 GHz Intel Core i3 CPU, 4 GB memory, and Windows 7 operating system.
Datasets
We use 11 datasets including 4 synthetic datasets and 7 real-world datasets from the UCI Machine Learning Repository 31 to evaluate the effectiveness and efficiency of our k*-means. These datasets cover many fields such as spatial data, image, text, etc. As described in Table 1, D1–4 are generated by our data generator using mixture Gauss model for covering different situations, such as unbalanced clusters, clusters with arbitrary shapes.
Descriptions of synthetic and real-world datasets.

As shown in Figure 5(a), D1 includes 30 clusters that composed of 3851 points. In this dataset, each cluster contains less than 200 points with Gauss distribution and number of clusters is balanced. We denote the small dataset as Smalldata.

Demonstrations of four synthetic datasets: (a) D1, (b) D2, (c) D3, and (d) D4.
D2 (Figure 5(b)) includes five clusters with clear gaps; number of points in the dataset reaches at 18,000 but is unbalanced in each cluster. We name the unbalanced dataset Unbaldata.
D3 (Figure 5(c)) contains 41,065 points, which consists of 12 clusters. Clusters of the dataset are also unbalanced but with clear shape. This dataset is denoted as LargeUnbal.
The forth dataset shown in Figure 5(d) comprises massive data points of 120,000, including 50 clusters with arbitrary shapes. Moreover, there are no obvious gaps for some clusters, and the number of points in clusters also is unbalance. We denote the big dataset with arbitrary shape clusters as Bigdata.
Ecoli 31 is calculated from the amino acid sequences, which includes 8 classes that comprised of 336 proteins. The data has eight attributes (includes one label), and the number of classes is different, thus it is an unbalanced dataset.
Pendigits 31 is collected from 44 writers, which contains 10,992 instances that represented as constant length feature vectors in 16-dimensional space.
Optdigits 31 is optical recognition of handwritten digits by extracting normalized bitmaps of handwritten digits from a preprinted form. Each preprinted form is represented as an 8 × 8 matrix, where every element is an integer. The dataset includes 5620 instances in 64-dimensional space.
Dermatology 31 contains 366 patients with 34 attributes, which is partitioned into 6 types of erythemato-squamous disease. The dataset is also unbalanced.
Folio1 & Folio2 31 are leaves images taken from different plants in the farm of the University of Mauritius and nearby locations. We first extract the SIFT descriptors from these images, and then use the bag of 500 visual words to represent the data. Two subsets of the data were generated, Folio1 (300 leaves from 15 different types of plants, balanced) and Folio2 (300 leaves but from 20 different types of plants and unbalanced).
CNAE-9 31 contains 1080 documents of free text business descriptions of Brazilian companies. These documents are categorized into a subset of nine categories. Each document is represented as a vector, where the weight of each word is its frequency in the document.
Experimental methodologies
For effectiveness evaluation of our algorithm, we use three metrics of average


Therefore, NMI score ranges from 0 to 1.0, more higher value indicates more better quality of clustering.
As shown in equation (20), we need additional labeled class information for computing NMI score. But it is difficult to obtain data with annotations in many real-world applications. So, we also adopt another widely used metric SC, which describes both similarity among points in intra-cluster and differences among clusters without cluster labels. Let

The average SC of all points
For efficiency evaluation, we measure the common metrics of CPU consumption. All experiments are conducted 10 times on each dataset, and we take the average CPU time. Moreover, we discuss the selection of
Alternative algorithm
We compare our algorithm against k-means, k-means++, and MinMax k-means. We also apply k-means++ initialization method into our k*-means, named k*-means++ algorithm. That is, k*-means++ chooses
Effectiveness evaluation
First, we evaluate the clustering quality of k*-means on 11 datasets when
Clustering quality on NMI.

NMI: normalized mutual information.
Clustering quality on SC.
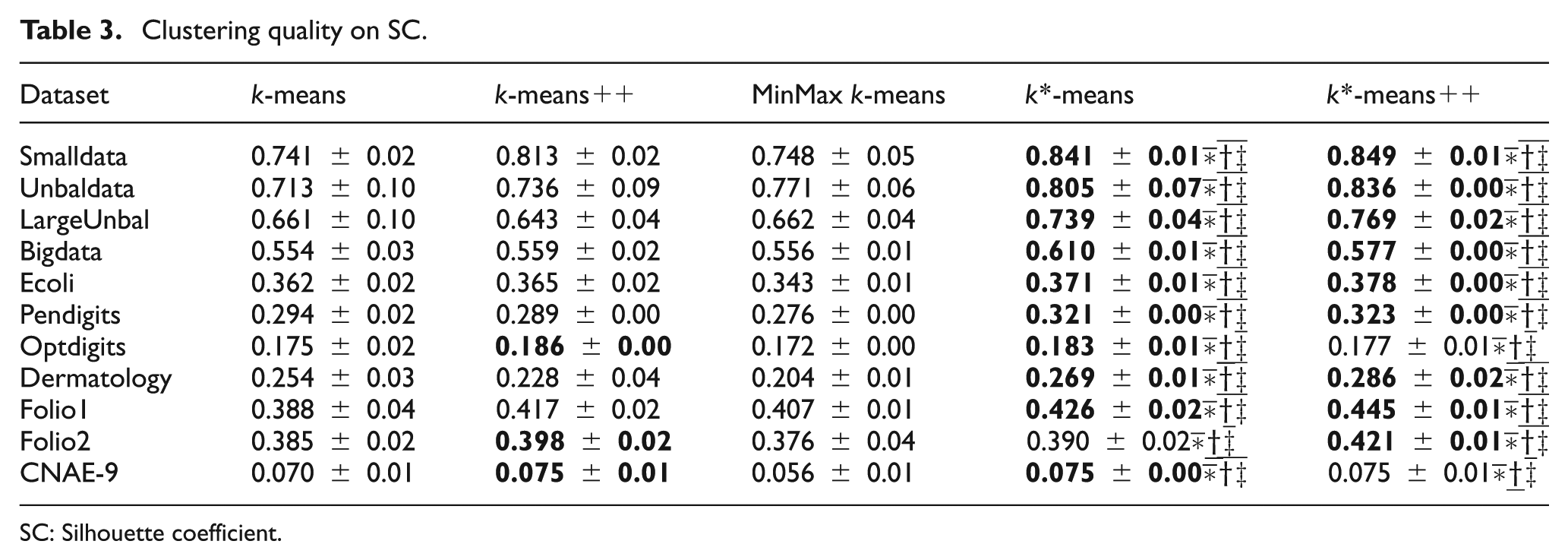
SC: Silhouette coefficient.
Clustering quality on SSE.

SSE: sum of squared error.
NMI
The results of NMI on 11 datasets are shown in Table 2, our k*-means is superior to k-means, k-means++, MinMax k-means on all datasets but pendigits. In particular, NMI scores on four synthetic data demonstrate that k*-means has better ability of handling various scenarios compared to other tree algorithms. Even on real-world datasets, k-means also achieves robustly higher NMI score. In particular, it is worth noting that k*-means also works better than the competitors on the high-dimensional text dataset CANE-9. This clearly displays that
For k-means++, its probability initialization process improves performance to a certain extend compared to randomly starting of k-means. MinMax k-means aims to get lower maximum
SC
As shown in Table 3, again, k*-means outperforms k-means, k-means++, and MinMax k-means in term of SC value. In particular, our algorithm exhibits better SC value than k-means and MinMax k-means on all datasets, and better than k-means++ on all datasets but Optdigits and Folio2 data. However, SC values of k*-means are very close to those of k-means++ on this two datasets. K*-means++ also improves clustering quality in 90% of tested cases. This is because careful selection of
SSE
Table 4 shows the
In summary, the above comprehensive experiments confirm the effectiveness of our proposed k*-means in attaining clusters of better quality. Furthermore, our k*-means integrated with k-means++ initialization robustly achieves best quality clusters in most real-world applications.
Efficiency evaluation
Comparison of efficiency with other algorithms
Next, we evaluate the efficiency of our k*-means compared against k-means, k-means++, and MinMax k-means on 10 datasets when

CPU time of algorithms on 10 datasets: (a) Group 1, (b) Group 2, (c) Group 3, and (d) Group 4.
Impact of optimization principles
We next analyze the contribution of three optimization principles (“top-n nearest clusters merging,”“optimized update principle,” and “cluster pruning strategy”) on efficiency using four datasets (two real and two synthetic datasets). In this experiment, we demote the k-means armed with “top-n nearest clusters merging” as top-n, armed with “optimized update principle,” and “top-n nearest clusters merging” as update + top-n and the completed version as k*-means, respectively. Figure 7 shows the CPU time of optimization principles by varying number of

CPU costs in different part of k*-means: (a) dataset dermatology, (b) dataset optdigits, (c) dataset smalldata, and (d) dataset bigdata.
Determining of parameters
and
We conduct experiments to explore the selection of
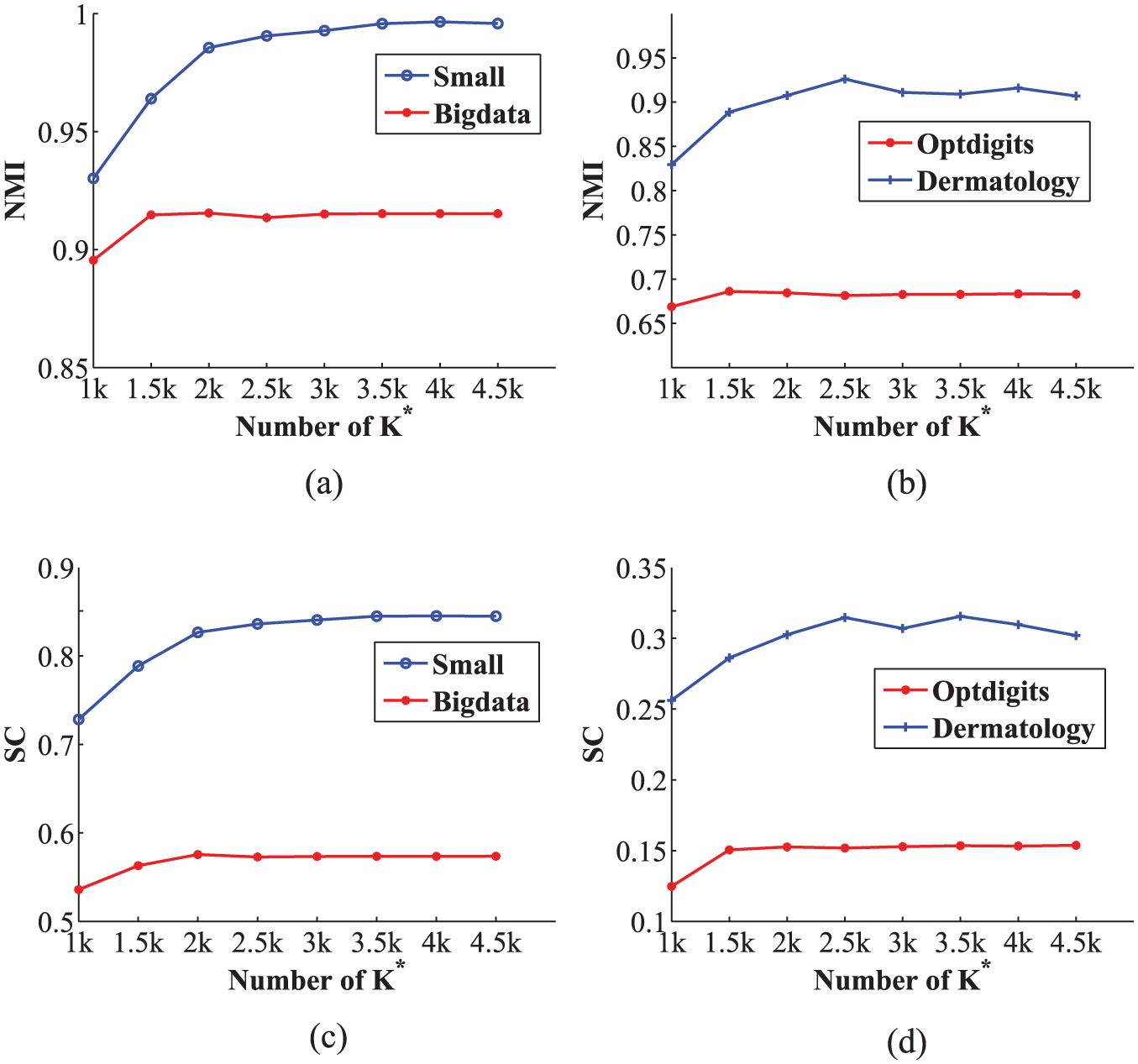
Impact of
Figure 9 shows the impact of

Impact of
Finally, we evaluate the effect of parameter
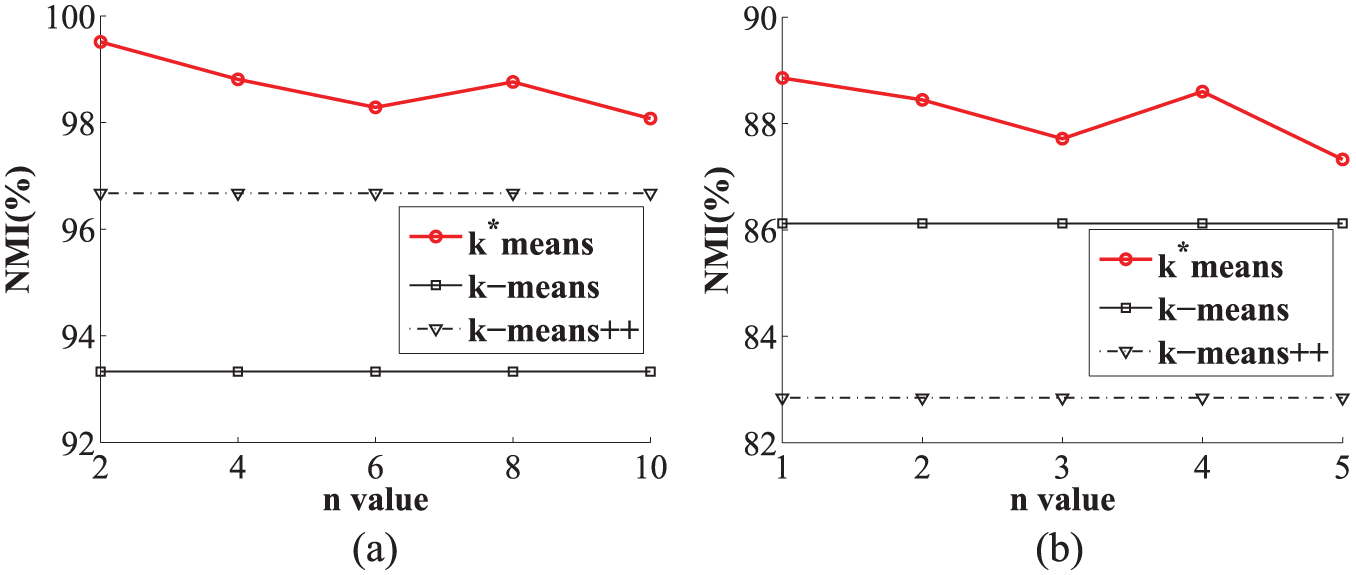
Impact of

Impact of
Conclusion
In this work, we propose a novel optimized hierarchical clustering method incorporated with three optimization principles, namely “top-n nearest clusters merging,”“optimized update principle,” and “cluster pruning strategy” to achieve both effective and efficient clustering robustly.
An interesting direction for future work is to leverage modern distributed multi-core cluster of machines for further improving the scalability of our algorithm.
Footnotes
Academic Editor: Zhipeng Cai
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is based on a conference “Proceedings of the IEEE international conferences on bigdata and cloud computing” and partially supported by the National Natural Science Foundation of China (nos 61403328, 61773331, 61572419, and 61502410), the Key Research & Development Project of Shandong Province (no. 2015GSF115009), and the Graduate Innovation Foundation of Yantai University (no. YDZD1712).