
Abstract
Online social networks are an important part of people’s life and also become the platform where spammers use suspicious accounts to spread malicious URLs. In order to detect suspicious accounts in online social networks, researchers make a lot of efforts. Most existing works mainly utilize machine learning based on features. However, once the spammers disguise the key features, the detection method will soon fail. Besides, such methods are unable to cope with the variable and unknown features. The works based on graph mainly use the location and social relationship of spammers, and they need to build a huge social graph, which leads to much computing cost. Thus, it is necessary to propose a lightweight algorithm which is hard to be evaded. In this article, we propose a lightweight algorithm GroupFound, which focuses on the structure of the local graph. As the bi-followers come from different social communities, we divide all accounts into different groups and compute the average number of accounts for these groups. We evaluate GroupFound on Sina Weibo dataset and find an appropriate threshold to identify suspicious accounts. Experimental results have demonstrated that our algorithm can accomplish a high detection rate of
Introduction
In recent years, online social networks (OSNs) such as Twitter, Facebook, Sina Weibo, and RenRen provide people with a platform that puts the relationships in the real world into the virtual world. While OSNs make peoples’ life various, it brings a lot of problems with network security. Spammers propagate a variety of attacks to other users through OSNs, such as phishing, drive-by download, malicious code injection, and hosting botnets. These malicious behaviors threaten the users’ security of information and property. In the first half of 2010, about 1.67% new Twitter accounts are closed due to malicious behaviors, suspicious behaviors, or other account abusing behavior. 1
Malicious URLs is one of the most commonly used methods that spammers implement malicious attacks. 2 Spammers usually share some interesting videos, stories, photographs, and information about discount, while these contents actually contain links to malicious websites. With the launching of short-link services in OSNs, spammers can take advantage of this short URL to hide the domain name of malicious website. Some works show that spammers can identify whether there are detection tools in the present network environment. These make it difficult to detect malicious URLs in OSNs. Since spammers mainly spread malicious URLs by spam accounts, we are just trying to detect spam accounts to curb the spreading of malicious URLs in OSNs, even make it disappear.
Spammers attempt to follow a lot of users and want to be followed back to increase their followers.2–4 The study demonstrates that a quite part of users will follow strangers who follow them in Sina Weibo. 5 There are some differences between the following strategies of normal users and spammers. For spammers, evidences are found that most spam accounts are programmed and run automatically, which is easy to achieve with low cost. For normal users, they can decide whether or not to follow according to their own judgment. Therefore, spammers cannot make sure who will follow them, and the followers of spam accounts often have no obvious relationships between each other.
In order to protect the users away from phishing attacks or URLs hiding in a malicious website, many researchers make a great effort for it. Currently, main research works are classified into three categories. In the first category, some studies aim to establish a detection model based on social network behaviors;6–10 they setup different behavior models through analyzing the different behavior characteristics of normal accounts and malicious accounts in OSNs. Then, according to whether other accounts matching with the model, whether the accounts are malicious or not is determined. However, spammers often deceive detection by reconstructing a new attack model through imitating the behavior of real users. In the second category, some studies use machine learning methods to discover features from malicious accounts, such as behaviors and content.11–17 They extract the features and train a classifier to identify whether the accounts are malicious or normal. However, once the spammers modify key features, this detection method can be obsolete easily. In the last one category, some researchers construct a graph according to the connection between the accounts, such as relationships among friends, attention and fans.18–23 They design a detection algorithm to detect malicious accounts through different positions of the normal account and malicious account in the social graph. However, the accuracy of the detection algorithm based on graph is relatively low, and different social networks have their own characteristics.
To spread malicious URLs widely, spammers try to follow a lot of users to attract them to follow. Currently, most methods usually use a bi-direction ratio to detect this feature. However, spam accounts can use different technologies to escape most of the existing methods, such as following a large number of accounts, which will follow their follower to balance the ratio. Normal users can determine whether to follow the malicious account according to their own judgment, so spammers cannot control the consistency of their own fans. In order to find a robust and lightweight detection method, we try to discover features that are difficult for spammers to rebuild and make detection confused. Thus, we propose an algorithm based on local graph to detect suspicious accounts in OSNs.
In this article, we propose a lightweight algorithm which focuses on the structure of local graph. First of all, we collect about 246,898 accounts from the Sina Weibo, which contain about 22,417 spammers. Then, we establish an undirected graph–based on the bi-follow relationships among accounts. Next, we design an algorithm called GroupFound. As the bi-followers come from different social communities, we divide all accounts into different groups and compute the average number of accounts per group. We evaluate GroupFound on Sina Weibo datasets and use receiver operating characteristics (ROC) curve and area under curve (AUC) value to verify its analyzed and validated. We find the appropriate threshold to identify suspicious accounts through ROC curve. The experimental result indicates that the accuracy rate of GroupFound is
We propose the GroupFound algorithm to detect suspicious accounts in OSNs. GroupFound uses the difference of location characteristics between normal and suspicious accounts on the graph to identify suspicious accounts. It is difficult to avoid by spammers.
GroupFound is a lightweight detection algorithm. Compared with the previous works, we focus on the structure of local graph. Therefore, we can detect a large number of accounts in a shorter time.
We use ROC curve and AUC value to prove the effectiveness of the algorithm, and find the best threshold to identify suspicious accounts according to the ROC curve.
The rest of the article is organized as follows. In section “Related work”, the related work is discussed. The experimental dataset and the method used to collect the dataset are described in section “Dataset collection and analysis”. In addition, motivation and observations are explained, and the proofs of the observations are also expounded in this part. Section “Algorithm” introduces the GroupFound algorithm. Experiments are conducted in section “Evaluation” to detect spam accounts in Sina Weibo and evaluate the result of experiments. Related methods are compared to evaluate the speed of the GroupFound algorithm. The conclusion is in section “Conclusion”.
Related work
Spammers usually implement attack with malicious URLs, which make many people and companies in trouble and often cause huge economic losses. For detecting the spammers in OSNs, many researchers and enterprise engineers make a lot of efforts. We plan to discuss these related works from three perspectives: models based on social-behavior, machine learning classifiers based on the social-features, and algorithms based on the social graph.
Social behavior–based models
The key of the detection methods based on the model is to select appropriate behavior characteristics to differentiate normal accounts and suspicious accounts. Then, they judge accounts by whether they match with the model. Le et al. proposed a novel scoring model for signature-based detection that uses static features to pre-filter potential malicious web pages. Their model can combine knowledge from various information sources of web pages very effectively in order to filter potential malicious web pages. 6 Viswanath et al. proposed using principal component analysis (PCA) to detect anomalous users’ behavior in OSNs. They experimentally validate that normal users’ behavior is limited to a low-dimensional subspace amenable to the PCA technique. 7 Jiang et al. presented a study of detecting suspicious following behaviors. They discovered that the zombie followers exhibit behaviors that are synchronized and abnormal. 8 Wang et al. built a practical system for detecting fake identities using server-side clickstream models. They develop a detection approach that groups similar user clickstreams into behavioral clusters, by partitioning a similarity graph that captures distances between clickstream sequences. 9 Cao et al. designed and implemented a malicious account detection system called SynchroTrap. They observed that malicious accounts usually perform loosely synchronized actions in a variety of social network contexts. 10
Social feature–based machine learning classifiers
This kind of detection scheme uses machine learning methods to train a classifier according to social behaviors, accounts, and content characteristics. Eshete et al. developed an approach that uses machine learning to detect whether a given URL is hosting an exploit kit. Central to their approach is the design of distinguishing features that are drawn from the analysis of attack-centric and self-defense behaviors of exploit kits. 11 Yang et al. made an empirical analysis of the evasion tactics utilized by Twitter spammers and then designed several new and robust features to detect Twitter spammers. They formalized the robustness of 24 detection features that are commonly utilized in the literature as well as their proposed ones. 12 Aggarwal et al. used Twitter specific features along with URL features to detect whether a tweet posted with a URL is phishing or not. They use machine learning classification techniques and detect phishing tweets. 13 Eshete et al. 14 presented a holistic and at the same time lightweight approach, called BINSPECT, that leverages a combination of static analysis and minimalistic emulation to apply supervised learning techniques in detecting malicious web pages pertinent to drive-by download, phishing, injection, and malware distribution by introducing new features that can effectively discriminate malicious and benign web pages. Almaatouq et al. 15 presented a unique look at spam accounts in OSNs through the lens of the behavioral characteristics and spammer techniques for reaching victims. Zheng et al. proposed a supervised machine learning–based solution for an effective spammer detection. The solution considers the users’ content and behavior features and apply them into support vector machine (SVM)-based algorithm for spammer classification. 16 Based on the spam policy of Twitter, novel content-based and graph-based features are proposed to facilitate spam detection by Wang. 17
Social graph–based algorithm
There are many graph structures in OSNs. In the graph, the normal accounts and suspicious accounts have different location characteristics. Yu et al. proposed decentralized algorithms SybilLimit to determine whether a suspect node is Sybil or not; it is an improved version of SybilGuard. It relies on the assumption that social networks are fast mixing and the attack edge is limited. SybilLimit uses random routes, in which each node uses a randomized routing table to choose the next hop. Compared to their previous SybilGuard that accepted
Compared with above methods, GroupFound is a lightweight algorithm. It does not need training data in advance. If an attacker wants to spread malicious information, he will need to establish a relationship with normal users. When normal accounts establish relationship in OSNs, they will make their own judgment. Normal users would not establish relationship with the accounts they are not interested in or with malicious behavior. If they suspect that an account is abnormal, they will not follow it back. Attackers are difficult to change their account’s structure of the graph. Unlike most of the existing detection methods based on the graph, we do not need to setup a huge graph. GroupFound focuses on the local structure of the graph, and it can detect one account each time. Sometimes, we just want to detect one node, and GroupFound does not need to build a complete social graph.
Dataset collection and analysis
Before introducing our dataset, there are some definitions for an account in Sina Weibo. The followings_count is defined to be the number of accounts that an account follows and the number of accounts that an account be followed is called followers_count. A very important relationship in our research is bi-follow, which established when between two accounts who follow each other. For an account, those accounts which have bi-follow with it called bi-followers.
Dataset
Our Sina Weibo dataset consists of 246,898 accounts, collected from January 2015, using the Sina Weibo public open platform API. For each account, we collect the users’ latest personal information, follow, Weibo content, label education, professional, location, system recommending, fans, and other data items. The data stored in JSON format.
To distinguish normal accounts from malicious accounts of the dataset, we use the Python scripts to mark each account. As shown in Figure 1, we input http://weibo.com/u and the ID of accounts in the browser address bar, like http://weibo.com/u1234567890 . When it is sure that a current account is a normal one, browser will redirect the visitor to the homepage of account, like http://weibo.com/u1234567890?is_all=1?is_all=1 . When it determines that an account is not a normal one, browser will simply redirect the visitor to http://weibo.com/ . All accounts are marked with this method. Finally, we identified 224,481 normal accounts and 22,417 spam accounts.

Mark data.
We began to conduct experiments on this dataset in June, 2016. During the experiment time, we visited the homepage of these accounts several times by crawling. Every time, we find the new officially suspended malicious accounts, we would suspend those accounts accordingly in our dataset. To date, it has been a long time since the last malicious account was officially suspended. So, we can conclude that Sina Weibo has closed all the spam accounts in it. Even if some spam accounts successfully escape the official spam detection mechanism, the number of them is so small that they will exert little influence on our experiments. Therefore, we decided to verify our experiments using the officially suspended accounts.
Due to the limitation of the official privacy policy, collecting data from OSNs is still a challenge to researchers. OSNs protect their API carefully, for example, Twitters API restrict methods depending on the type of requests. The limitation of crawling Twitter users basic information is 180 times every 15 min, but the users’ followers can only get 15 times every 15 min. We are trying to collect more data for our future research of OSNs by the official API as far as possible.
Motivation
To spread malicious URLs widely, spammers try to establish a relationship with a large number of normal accounts in a short time. Evidences are found that most spam accounts are programmed and run automatically. Different from spam accounts, the relationships that normal accounts establish with other accounts are usually related to the real life, such as friends, family members, and their favorite stars. Besides, spammers control spam accounts to follow other accounts; however, they cannot determine whether other accounts follow themselves or not. Therefore, the bi-followers of spam accounts usually come from different social communities. Figure 2(a) shows a typical graph structure of the spam node. As shown in the figure, there is no relationship between its neighbors. Some spammers can have a large number of fake accounts. They can make these fake accounts follow each other to construct communities that can be similar to the ones of the normal accounts. As shown in Figure 2(b), the gray nodes are fake ones. When these fake nodes form a group, the center of the graph structure will deviate toward this social group. The distance between other nodes and the center becomes larger.

Use fake accounts: (a) spam accounts and (b) spam accounts with fake accounts.
To deal with those problems, we use Hierarchical Clustering to get the clusters of an account. In the local social graph, we set each node as a cluster at first and merge two closest clusters every time. We use the error sum of squares (ESS) to compute the distance between two clusters and get an irrelevant distance in section “The details of GroupFound.” When the distance between two clusters is bigger than the irrelevant distance, we think that the two clusters have no relationship and the clustering process will terminate in advance. When the algorithm stops, we get the number of clusters and call it
Observations
In order to explain our algorithm, we present detailed statement of observations at first. Our algorithm is based on three observations, and we will prove them in our dataset.
Observation 1: spam accounts follow more accounts with an aim to widely propagate spam information
If an account never has followers, it will become an isolated point in the social graph and cannot propagate information to others in OSNs. In order to widely propagate spam information, spam account needs to become a part of social communities and establish social relationships with other accounts. Even if it is not a real or valuable account. Spammers cannot control other accounts to follow them, so they need to follow normal users as many as possible to increase their bi-followers. We analyzed 22,448 normal accounts and 22,417 spam accounts in the dataset. In Figure 2, the x-axis represents the followings-count of accounts, and the y-axis is the percentage of total accounts.
As we can see from Figure 3, the blue line is the distribution of followings-count of normal accounts. The purple line shows the distribution of followings-count of spam accounts. We can see from the blue line, as the followings-count increases, the percentage of total accounts grows rapidly. Differently, the curve of purple line is more smoothly. For further observation, we take a value from the x-axis which equals to 50. When x = 50, the corresponding value in the y-axis is 0.89804 for normal accounts. It means that 89.804% normal accounts’followings-count is less than 50. For spam accounts, the value in the y-axis is 0.057215. It means that there are only 5.7215% spam accounts’followings-count is less than 50. Obviously, to widely propagate spam information spammers follow more accounts.
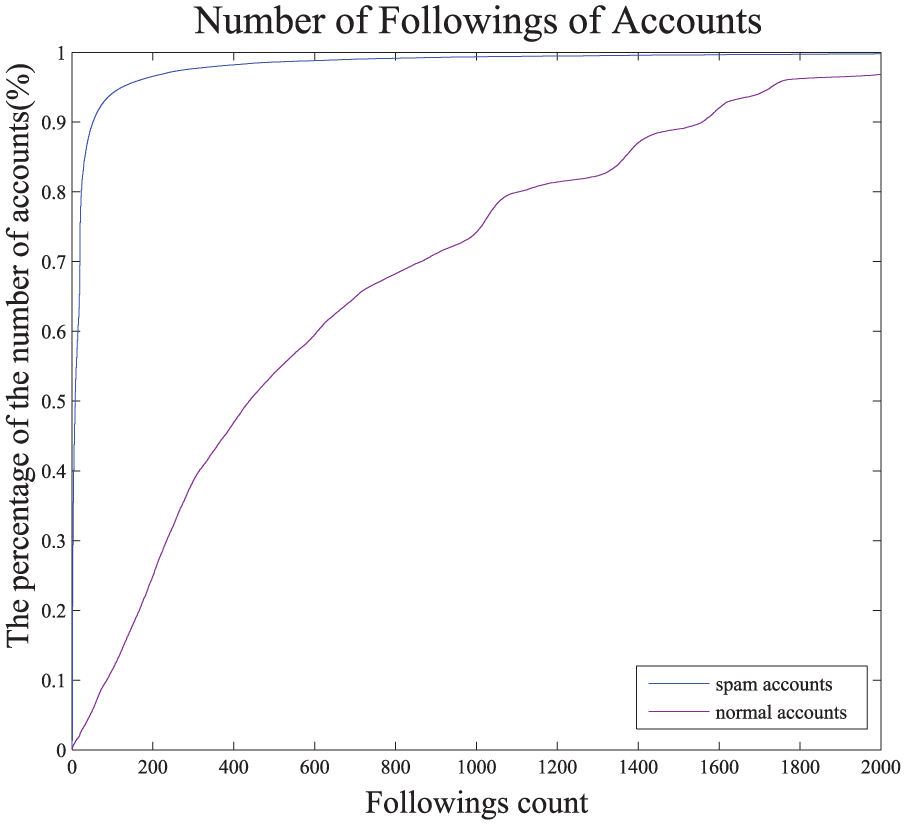
Number of followings of accounts.
Observation 2: spam accounts cannot control their followings to follow them
Normal accounts correspond to the people in the real world. When normal accounts establish relationship in OSNs, they will make their own judgment. Normal users would not follow accounts that they are not interested in or with malicious behavior. If they suspect that an account is abnormal, they will not follow it. If normal users are good at judgment, they would not be attacked easily by spammers. However, spam accounts follow a large number of normal accounts, and only few accounts follow them back. We can prove it by computing Bi-directional Links Ratio by the following formula
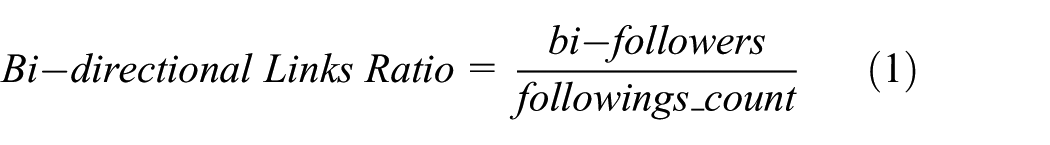
We choose about 5000 accounts both from normal accounts and spam accounts in Sina Weibo dataset randomly. After processing these accounts by formula (1), we get the Bi-directional Links Ratio of both normal accounts and spam accounts. In Figure 4, x-axis represents the account number, ranging from 1 to 5000 and y-axis represents the value of Bi-directional Links Ratio for each account. Figure 4(a) is the Bi-directional Links Ratio of normal accounts and Figure 4(b) shows spam accounts’Bi-directional Links Ratio. Observing these two figures, we can clearly find that the Bi-directional Links Ratios of normal accounts center around 0.5. However, the Bi-directional Links Ratios of spam accounts center around 0.3. It is oblivious that the average Bi-directional Links Ratio of normal accounts is larger than that of spam accounts. We can conclude that spam accounts follow a lot of accounts but few of these accounts follow them back, because spam accounts cannot control their followers to follow them.

Bi-directional links ratio of accounts: (a) normal accounts and (b) spam accounts.
Observation 3: the bi-followers of spam accounts usually come from different social communities
To propagate spam information widely, spam account need to follow a lot of normal accounts to attract these accounts to follow them. On one hand, spammers do not care who are their followings or if there are some relationships between them. On the other hand, spammers could not control their followings to follow them. Usually, spammers prefer to follow accounts coming from different social communities. If followings of spammers come from few social communities, it is difficult for them to draw more victims and spread spam information widely. Thus, the bi-followers of spam accounts usually come from different social communities, and there is little interaction between them. In order to prove it, we design an algorithm to detect the interaction strength among accounts’bi-followers based on local clustering coefficient.
Local clustering coefficient: we consider the data of OSNs can be abstracted as a graph (G), where nodes represent accounts and edges the relationships among them. In our study, we use the bi-follow as edge. Easily, when a node is being detected, we call it target-node and the bi-followers of it is neighbor-nodes. In G, the nodes always tend to establish a set of strict organization relationships and then form a community. The local clustering coefficient (LLC) of a node can reflect the degree of the closeness of the community. For a target-node, we use edges_num to represent the total edges among the neighbor-nodes of it and sum to represent the total nodes of it. Finally, LLC can be computed by following formulas:
Undirected graph

Directed graph

We use bi-follow relationship of a target-node (i.e. similar to the friend relationships in Facebook) to establish an undirected graph. Then, we calculate the LLC of each node (Figure 5). In the figure, the blue line is the LLC distribution of normal accounts and the purple line represents the spam accounts. As we can see, a quite number of spam accounts’LLC are 0. When the LLC of a target-node is 0, it means that there is no interaction among its neighbor-nodes. This also proves the third observation. Although the local clustering coefficient can measure the degree of closeness among the neighbor-nodes of a target-node, it cannot distinguish spam accounts from normal accounts clearly because that different target-nodes have different number of neighbor-nodes. In the rest of this article, we will introduce our algorithm GroupFound.

Local clustering coefficient of accounts.
Algorithm
In this section, we present some statement about our algorithm and then show details of it.
Problem statement
In order to detect the suspicious accounts in OSNs, we propose a lightweight algorithm GroupFound, which focuses on the structure of local graph. We use groups to represent the communities from which neighbor-nodes of a target-node come. For an account
The fundamental of algorithm
For an account

We use formula (4) to compute the similarity of every two nodes in

With the aim at getting groups of

In order to get the distance of



For



The details of GroupFound
In this part, we will describe the details of GroupFound. Our algorithm mainly contains three procedures. First, we get the two layers of neighbor-nodes of the target-node in Procedure 1. In the procedure, we set
Procedure 1.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
Then, in Procedure 2, we compute the similarity of every two nodes among the neighbor-nodes of a target-node by computing Jaccard index, which is a statistic used for comparing the similarity of two collections. After that, we get a similarity matrix, which will be used to calculate the groups of target-node.
Procedure 2.
1:
2:
3:
4:
5:
6:
7:
8:
9:
Finally, we use the similarity matrix
Procedure 3.
1:
2:
3:
4:
5:
6:
7:
8:
9: groups = clusters
10: Group_avg = nodes/groups
11:
The irrelevant distance
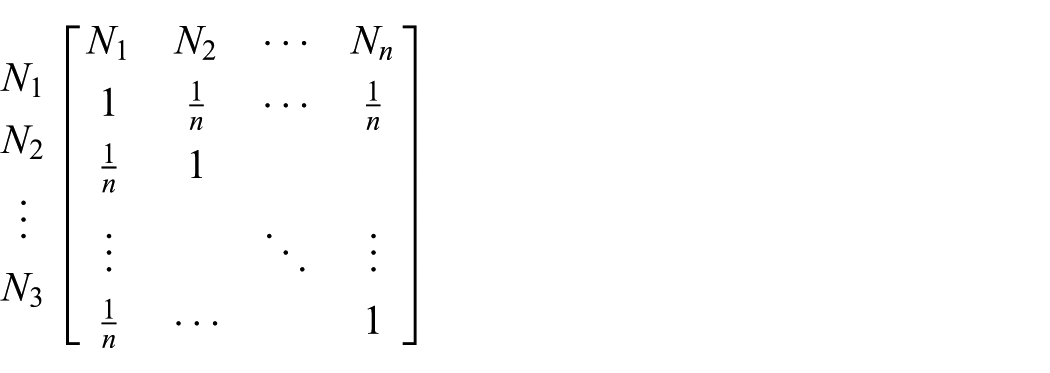



We use it as a unified metric. As we can see in Figure 6, which is a Hierarchical Clustering dendrogram, the x-axis represents the distance of clusters and y-axis is the order of nodes. The formation process of tree structure corresponds to the process of clustering. The GroupFound will stop when the distance

Hierarchical clustering dendrogram.
In order to detect suspicious accounts in OSNs, we propose a lightweight algorithm GroupFound, which focuses on the structure of local graph. We leverage the local location features of a node in bi-follow relationship graph to get the groups of target-node. We use Group_avg to represent the average number of nodes in each group. As the bi-followers of spam accounts usually come from different social communities, the Group_avg of spam accounts is very small. For each account, we will get one Group_avg. Through comparing the Group_avg of each account and threshold, we can identify the suspicious accounts. Above all, we can see that GroupFound can focus on detecting one node. To identify the suspicious account, we need to further experiment and find a threshold, which can clearly distinguish the normal accounts and the suspicious accounts.
Our algorithm is based on Hierarchical Clustering, which set
Difference between our algorithm and community detection technologies: most of the local community detection approaches work by starting with one (or more) seed node(s) and greedily adding neighboring nodes until a sufficiently strong community is found. 28 The group in our algorithm is different from that of the community, some groups of our algorithm have only one node. Especially, there are a large number of groups of spam modes formed by a single node. This division is meaningless to community detection, but our algorithm is making use of this kind of single-mode groups of spam modes (which reduces the average number of nodes for all groups) to detect suspicious nodes.
Different between our algorithm and graph clustering technologies: clustering methods based on graphs usually cluster normal nodes in one cluster according to the different characteristics of normal nodes and spam nodes and then other nodes which are not in the cluster are suspicious nodes. Sometimes, the above methods cluster normal nodes and suspicious nodes, respectively, by sampling the nodes in the two clusters, so that whether the other nodes in the cluster are suspicious can be determined. Our algorithm uses clustering to merge the two clusters whose distance is smaller than the irrelevant distance
Evaluation
In this section, we will evaluate our algorithm GroupFound. First, we introduce the confusion matrix, which will be used to evaluate the accuracy of our algorithm. Then, we run GroupFound on the Sina Weibo dataset. We get the
Confusion matrix
We use the confusion matrix to evaluate the accuracy of our algorithm. Each column of the matrix represents an instance’s prediction of the class and each row represents an actual instance of the class. As shown in Table 1, the confusion matrix shows the relationships among true positive rate (TPR), FPR, false negative rate (FNR), and true negative rate (TNR).
Confusion matrix.

TP: true positive; FN: false negative; FP: false positive; TN: true negative.
It is important to find a balance point between these metrics for achieving an effective detection system. Our algorithm aims to detect spammers in OSNs. It needs to identify more spammers as many as possible while reducing the misjudgment of normal accounts. Based on the considerations above, we can use formula (15) to calculate the accuracy of our algorithm
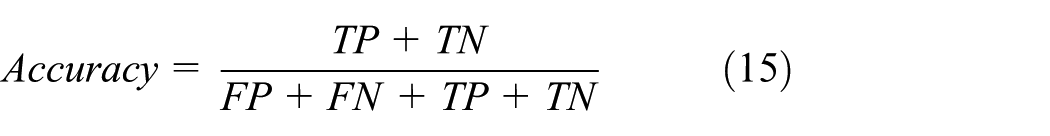
Experiment
Our evaluation environment is an IBM System X3100 M4. This server is populated with eight 3.30-GHz Intel Xeon CPU E3-1230 V2, 32 GB memory, a 3000.0-GB hard-disk and connected by a 1000-Mbit Ethernet.
Data preprocessing: before starting the experiment, we preprocessed the experimental data. In order to reduce the FPR of the algorithm, we cut out some accounts which have no bi-follow relationships with other accounts in the dataset. They are some isolated points in the social graph; therefore, they have no ability to spread malicious information to other accounts, we think these accounts are harmless. Through preprocessing, we find 9270 harmless accounts.
After data preprocessing, we run our algorithm on Sina Weibo dataset which contains 215,211 normal accounts and 22,417 spam accounts. We get the
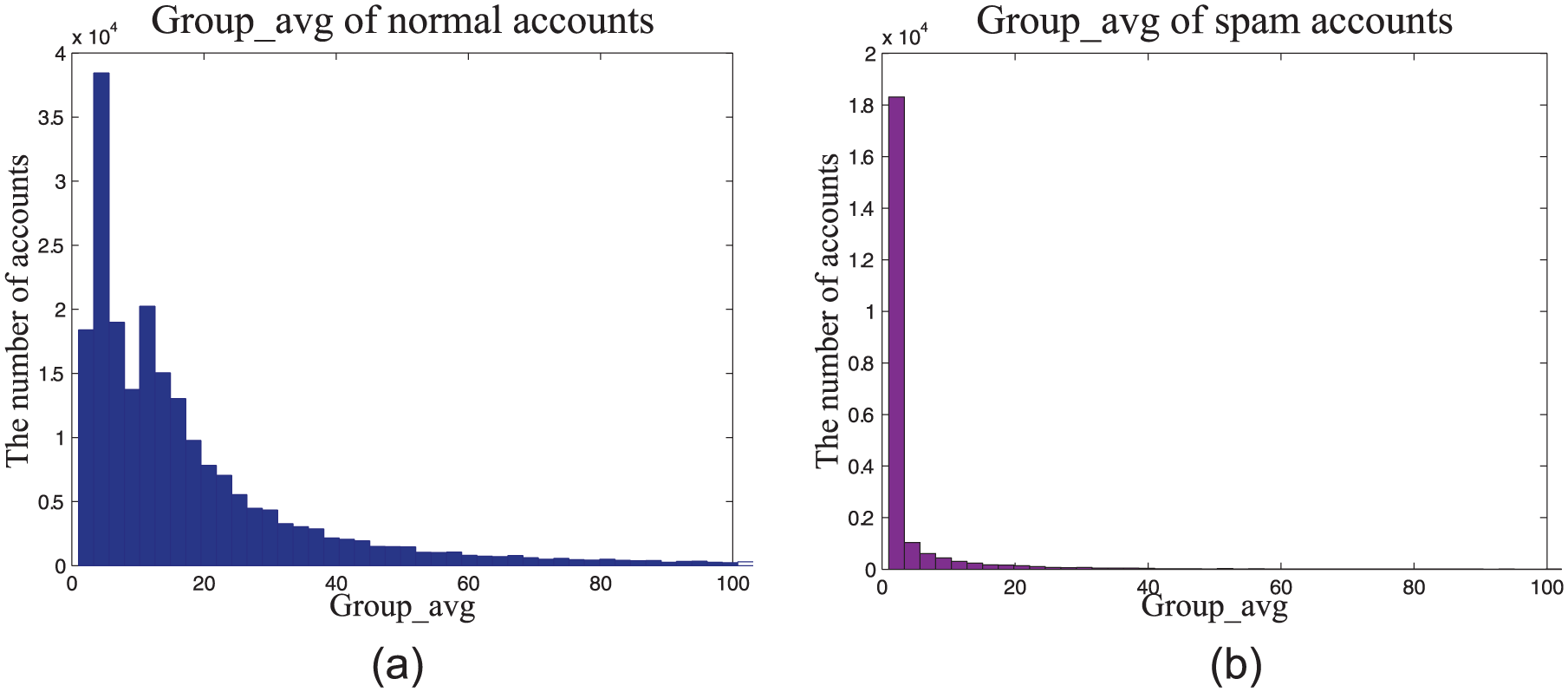
Group_avg of account: (a) normal accounts and (b) spam accounts.
ROC curve and AUC value
In order to determine the effectiveness of the algorithm, we further analyze the results of experiments. We can easily find that almost all of the accounts’

ROC curve of GroupFound.
The value of AUC
AUC is a probability value. When we select a positive sample and a negative sample randomly, the AUC is the probability that the positive sample is arranged before the negative sample. The larger AUC value is, the more possible to identify spammers is. For computing the AUC value, we divide the ROC curve into small rectangular and obtain the area using calculus.
We use the TPR value of the node, which is on the left side of the rectangle. Finally, the AUC value is smaller than the actual one slightly. After calculating, the AUC value of the ROC curve is 0.887003. It means if you select a spam account or a normal account randomly, the probability that the spam account ranks before the normal one is at least 0.887003 by our algorithm GroupFound. Therefore, our algorithm can distinguish spam accounts from normal accounts effectively.
Threshold
In ROC curve, we think that the point that closest to the upper left corner is the most appropriate to as the threshold. To obtain this point, we use the formula (16)

When threshold is
Performance
In this section, we will evaluate the performance of our algorithm with two aspects: the accuracy and the speed.
Accuracy
We use
Statistical data of evaluation on Sina Weibo.

Speed
In order to evaluate the running speed of our algorithm, we use GroupFound to detect 237,628 accounts. We record once when we detect every 5000 accounts. Finally, we get the distribution of the running time (RT) as shown in Table 3. As shown in Table 3, the first row represents the timestamp. Each timestamp corresponds to the time when every 5000 accounts were detected. The second row is the GroupFound’s actual RT. In the last row,
Running time of GroupFound.
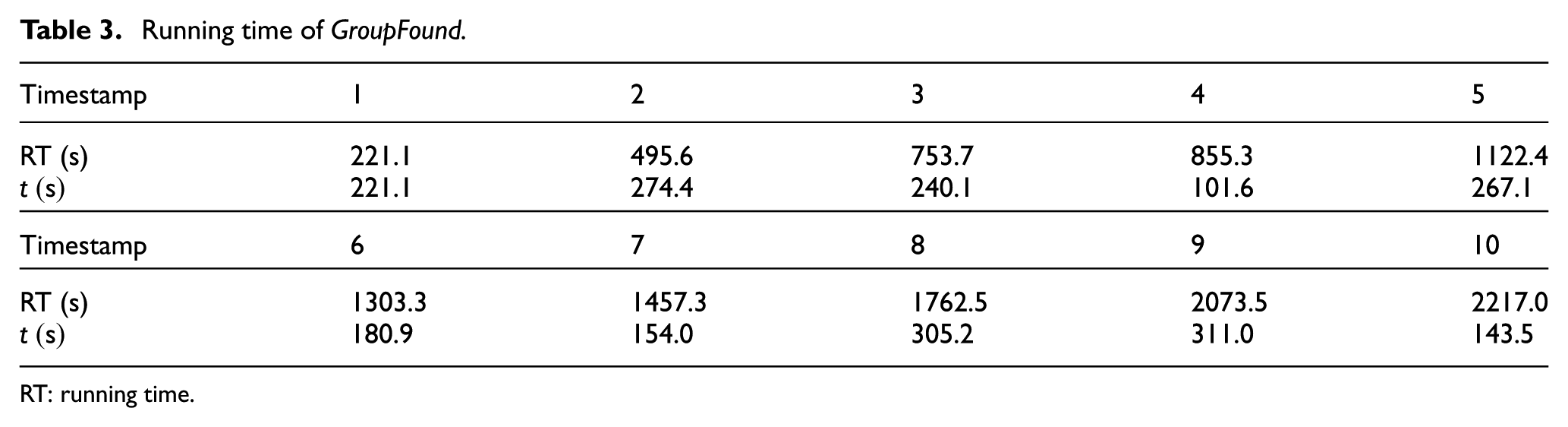
RT: running time.
Most of the existing detection methods based on machine learning to train a classifier according to social behaviors, accounts, and content characteristics. After training the classifier, it can detect suspicious accounts quickly. Compared with these methods, GroupFound is a lightweight algorithm, and it does not need training data in advance. Other works focus on social graph–based algorithm, the time complexity of GroupFound is higher than most of them. But unlike most of the existing detection methods based on the graph, we do not need to setup a huge graph. Sometimes, we just want to detect one node, and GroupFound has a better performance. The uniqueness of GroupFound is that it focuses on the local structure of the graph and can detect one account each time.
Analysis
First, we analyze the FPR of algorithm. Results of the experiment show that the
Comparison
In this section, we will compare GroupFound against other approaches in terms of its effectiveness in detecting suspicious accounts.
PageRank: 29 we implement the PageRank method and use it to detect suspicious nodes in social graph. Evidences are found that most spam accounts are programmed and run automatically. To propagate spam information widely, spam account needs to follow a lot of normal accounts to attract these accounts to follow them. Therefore, the out degree of spam account is very big and the in degree of spam account is very small. Eventually, each node gets a value of rank; the smaller the value, the more suspicious the node is.
SybilDefender:
19
it consists of three components: a Sybil identification algorithm, a Sybil community detection algorithm, and two supporting approaches to limiting the number of attack edges. According to the pseudo-code of SybilDefender, we implement one part of it: a Sybil identification algorithm, which has two phases. In the first phase, the algorithm takes the social graph
We run PageRank and SybilDefender on our dataset and show the ROC curve for each method. As shown in Figure 9, the black curve represents the ROC curve of GroupFound, the red one is SybilDefender’s ROC curve, and the green one is the ROC curve of PageRank. Then, we calculate the AUC value of each curve; the AUC value of the black, red, and green curves is 0.887003, 0.858296, and 0.829042, respectively. Compared with PageRank and SybilDefender, our algorithm can distinguish spam accounts from normal accounts more effectively. In order to compare with more existing studies, we still need to connect with other authors and ask for related sources. In addition, most graph-based algorithms only detect malicious nodes for some instant in a social network. As the node structure in a social graph will change over time, we need to keep crawling more data and consider the time factor to improve our algorithm in future research.

ROC curve.
Conclusion
OSNs become an important part of people’s life and also are the platform that spammers use suspicious accounts to spread malicious URLs. Most existing works mainly utilize machine learning method based on features. However, once the spammers disguise the key features, the detection method will be invalid. It also has no reliable performance in detecting suspicious accounts with unknown features. In this article, we propose a lightweight algorithm GroupFound, which focuses on the structure of local graph. As the bi-followers of an account come from different social communities, we divide all accounts into different groups and compute the average number of accounts of these groups. The experimental result indicates that the time cost of our algorithm is relatively low. For future work, we will continually improve the performance of our algorithm. Apart from this, we are sincere to communicate with other researchers working in this field.
Footnotes
Academic Editor: Michele Amoretti
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China under grant no. 61472162.