
Abstract
The cloud computing paradigm enables elastic resources to be scaled at run time satisfy customers’ demand. Cloud computing provisions on-demand service to users based on a pay-as-you-go manner. This novel paradigm enables cloud users or tenant users to afford computational resources in the form of virtual machines as utilities, just like electricity, instead of paying for and building computing infrastructures by their own. Performance usually specified through service level agreement performance commitment of clouds is one of key research challenges and draws great research interests. Thus, performance issues of cloud infrastructures have been receiving considerable interest by both researchers and practitioners as a prominent activity for improving cloud quality. This work develops an analytical approach to dynamic performance modeling and trend prediction of fault-prone Infrastructure-as-a-Service clouds. The proposed analytical approach is based on a time-series and stochastic-process-based model. It is capable of predicting the expected system responsiveness and request rejection rate under variable load intensities, fault frequencies, multiplexing abilities, and instantiation processing times. A comparative study between theoretical and measured performance results through a real-world campus cloud is carried out to prove the correctness and accuracy of the proposed prediction approach.
Introduction
Cloud computing, as an emerging technology, is featured by the ability of elastic provisioning of on-demand computing resources ranging from applications to storage over the Internet on a pay-per-use manner. Cloud computing brings in numerous benefits for companies and end customers. For example, end customers can invoke computational resources for almost all possible types of workload when resources are reachable. This erases the conventional need for IT (information technology) administrators to build, provision, and maintain resources. Moreover, companies can dynamically scale upward or downward to meet the fluctuations of varying demands. Therefore, investments into physical computing infrastructures, which are substituted by virtual environments connected to cloud data centers, are thus no longer necessary. In this way, computational resources are priced at a granular level, allowing customers to pay only for what they actually require and use. Through the provision of on-demand access to hardware/software/communication/storage components, clouds deliver services at multiple levels: Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS). IaaS clouds 1 provision customers or tenant users virtual machine (VM) instances as computational resources. These instances are created and executed in the owner data center. In contrast, PaaS and SaaS use the web to deliver platforms and applications that are managed by a third-party vendor and whose interface is accessed on the clients’ side. PaaS and SaaS are typically used by application developers, while IaaS is used by network architects. In other words, PaaS and SaaS provide a mechanism to develop applications, whereas IaaS provides only the infrastructure necessary to run the code developed by application developers.
Cloud users consistently concern about the quality of cloud service delivered. Thus, performance promised by cloud providers is crucial to the success of cloud service offered. A major performance metric frequently used is expected response delay. When running mission-critical web-facing applications in cloud environments, one of the major requirements is the expected response time, usually specified as the expected waiting interval between a request submission and its requested outcome returned. Specifically, this work considers expected instantiation response delay, that is, the expected waiting interval between a cloud request arrival and its corresponding VM instance created, as the metric of system responsiveness. Note that instantiation-creation-time differs from task execution time in that the latter is actually the sum of VM instantiation response delay and VM usage time. VM usage time can be application-dependent and vary from one request to another. Thus, task execution time of IaaS cloud is hard to model and predict. Moreover, the last thing cloud users want to see is the rejection of their requests. We therefore consider request rejection rate as another important performance metric, which directly determines users’ satisfaction. This rate is expressed by the probability that a submitted request receives no response or a negative response (cloud system being unable to instantiate its VM request). Note that the two performance metrics are determined by various system factors and parameters, for example, service rates, buffer scale, multiplexing ability, and fault rates. As will be shown later in this work, a successful VM instantiation on IaaS cloud has to go through several provisioning steps, each of which can be subject to unexpected faults. Fault-handling activities are thus inevitable and such activities could strongly affect the overall cloud performance. However, a careful investigation into related works (discussed in next section) suggests that, for model simplicity, most existing approaches assume reliable and fault-free cloud provisioning and thus have less difficulty in theoretical derivation of performance metrics. Although some recent performance/quality of service (QoS) models consider fault/fault-handling, they rely on measurement/test data to analyze cloud performance. Measurement-based approaches have limited value in optimization and bottleneck analysis. In contrast, comprehensive theoretical models capable of modeling unreliable cloud provisioning with accurate prediction of performance metrics are in high need.
Instead of assuming reliable cloud and fault-free cloud provisioning by most existing related studies, we introduce a performance modeling and trend prediction framework for runtime performance prediction of unreliable IaaS cloud with faulty VM instantiation. For this purpose, a stochastic-process and time-series-based approach is developed, and product-form results of multiple performance metrics are derived. To prove the effectiveness and accuracy of the proposed stochastic model, we employ runtime performance data from an actual campus cloud built on OpenStack and show that runtime experimental performance results closely converge to predictive ones.
Related works
Recently, performance estimation of cloud computing systems is attracting increasing attention. Various model-driven methods in this direction are developed for analytical performance prediction of cloud computing systems and cloud data centers. For example, Xiong and Chen 2 work on percentile of job execution times and response delays and present an M/M/1 queue model, that is, a single-server queue with Poisson arrival, for QoS prediction of cloud services. It assumes reliable and fault-free cloud provisioning to simplify the derivation of performance results. Our recent work in Xia et al. 3 and Li et al., 4 however, shows that faults exist at different levels of IaaS cloud and the overhead required to counter such faults intensively affects performance especially when cloud is heavily loaded. Wang et al. 5 introduce a comprehensive performance model by considering machine error and repair. They also obtain the theoretical distributional functions of cloud task execution durations. He et al. 6 consider a multivariate QoS model to analyze efficiency of VM-PM (physical machine) mapping strategies with reliable cloud provisioning. Bruneo and colleagues7,8 model the aging process of cloud PMs and derive performance results under different request load intensities. Our work differs in the ways below: (1) Bruneo and colleagues7,8 consider reliable provisioning but our work captures fault/fault-handling activities; (2) Bruneo and colleagues7,8 ignore waiting periods, which are actually non-negligible. Ghosh et al. 9 develop a scalable performance and energy prediction model for describing resource placement, dynamic speed scaling, and job failure. To reduce model complexity, their model decomposes the provisioning process into sub phases and obtains performance results of each phase separately. Finally, an integration method composes performance results of separate phases together. For simplicity and tractability, the interacting performance model is subject to accuracy loss because such separate phases of IaaS clouds actually have inter-dependence with each other. Our framework, instead, considers a monolithic provisioning control-flow model where all provisioning activities and phases co-decide final performance. Khazaei et al.10,11 develop a more refined work using the Continuous-time Markov chain, that is, CTMC model. They derive closed-form expressions of executing times and failure rate as the QoS metrics but use the fault-free assumption.
In comparison with the above-mentioned work, the contributions of this work are multifold: (1) instead of assuming reliable cloud provisioning, we consider a fault-prone one and propose a stochastic model to quantify cloud performance under variable fault frequencies, load intensities, multiplexing abilities, and instantiation processing distributions; (2) instead of using separate modeling approaches at the cost of accuracy loss, we consider that provisioning steps work simultaneously to determine the final performance and develop a monolithic performance model; (3) instead of static performance analysis and assumptions of Markovian processes (It is worth noting that although various works assume general distributions of performance results, these works are still limited. For analyzing the distributional functions of performance metrics, Hwang et al. 12 and Xia and colleagues13,14 consider the historical empirical distribution to be the theoretical distribution. By doing so, they consider the historical empirical distribution to be able to describing the future fluctuations of performance. A major limitation of doing so lies in that the historical empirical distribution merely employs the density of samples as their distributional probabilities but ignores its trend. As a case in point discussed in our earlier work, 15 a distribution of response delay with increasing occurrences of long delays with time clearly suggests a deteriorating performance which is caused by, for example, increasing failures of cloud components. However, its empirical distribution may be quantitatively identical to that of another response delay type with stable occurrences of long delays with time. Such limitation of using the historical empirical distribution could be well avoided using a time-series-based analysis instead.), we introduce a dynamic prediction approach (using the Autoregressive-Moving-Average-Model (ARMA) 16 series model) with special attention to the runtime trend of cloud performance in real-world environments; (4) based on real-world performance data, we compare the theoretical and empirical performance results to validate the correctness and accuracy of our proposed performance model.
The ARMA model
ARMA 16 models aim at modeling and predicting performance of computing, 17 communication, traffic control manufacturing system, and so on. It captures the dynamic feature of a time-varying distribution by employing an integration of an autoregressive (AR) type and a moving average (MA) type.
For a series

where
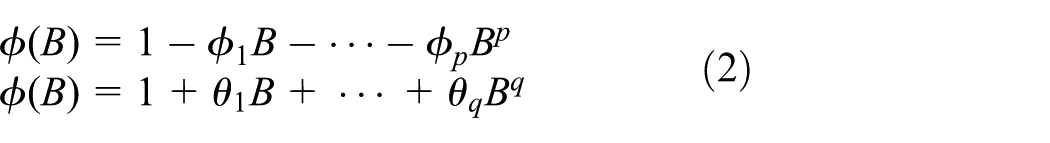
and

where
The Box–Jenkins method is highly effective in prediction of the future value of an established
The Box–Jenkins-based prediction is carried out through the following steps:
Series stationarity;
Model identification;
Optimization and selection;
Model diagnostic checking.
As discussed earlier, performance of IaaS cloud systems is mainly decided by instantiation processing time, request arrival rate, fault frequency, and the physical capacity, among which instantiation processing time is the most varying and fluctuating one. We can feed the historical instantiation processing time-series into the ARMA model and obtain the predicted future instantiation processing time (as shown in Figures 4–6), that is,
System view and its stochastic modeling
The IaaS cloud paradigm is featured by elastic provisioning of virtualized computing entities on the web. In a typical IaaS cloud, third-party providers own hardware, software, communication, storage, system maintenance, backup, resiliency planning, and other infrastructure entities for its customers. The capability of IaaS cloud provided to the consumer is to provision processing, storage, networks, and other fundamental computing resources where the consumer is able to deploy and run arbitrary software, which can include operating systems and applications. The consumer does not manage or control the underlying cloud physical infrastructure but has control over operating systems, storage, deployed applications, and possibly limited control of select networking components. IaaS cloud offers highly dynamic resources that can be invoked and used on-demand at run time. Such elasticity is well suited for highly fluctuating workload and unexpected increase in request intensity.
In a typical IaaS cloud architecture, a cloud management unit is responsible for admitting incoming requests. The request input flow can be usually captured by the input rate,
In OpenStack, the time-stamp of VM creation can be obtained in the INSTANCE-SPAWNED property. As suggested by Figure 1, the above process involves multiple phases and interactions. The last phase is the time required for the cloud management unit to create a VM, that is, instantiation processing time. In OpenStack, such time is denoted by the interval between INSTANCE-BUILDING and INSTANCE-SPAWNED. As mentioned earlier, instantiation processing time is highly sensitive to system load and network connectivity and thus strongly fluctuating with time. We thus employ its predicted value through the ARMA method as the input into the stochastic model presented in the next section.

Sequence chart of VM instantiation in OpenStack.
With the support of VM multiplexing
18
powered by modern multi-core/multi-threading technologies, more than one VM can be instantiated on a single PM. However, such number is usually bounded and we thus use
As shown in Figure 1, all the provisioning phases are subject to faults, and unsuccessful VM instantiation can thus be inevitable since internal or external communications are sometimes fault-prone. Such faults are usually caused by, for instance, temporary connection failure to remote database, communication congestion, inappropriate input/output sequence, gateway failure, database access failure, and unexpected user quit. The overhead required to counter such faults, for example, compensation/transactional rollback/ re-instantiation, can have intensive impact on system performance. This is especially evident when system is heavily loaded as discussed later in the section of case study.
Based on the above observations, the control-flow view of cloud provisioning on fault-prone IaaS cloud, in terms of a queuing network, is shown in Figure 2. This model erases implementation contents of cloud infrastructures while focusing on the control-flow contents adequate for stochastic modeling. Based on the stochastic control-flow model, the following section shows how closed-form expression of performance metrics can be derived and the theoretical effects of changing input loads (request load, fault load, and capacity load).
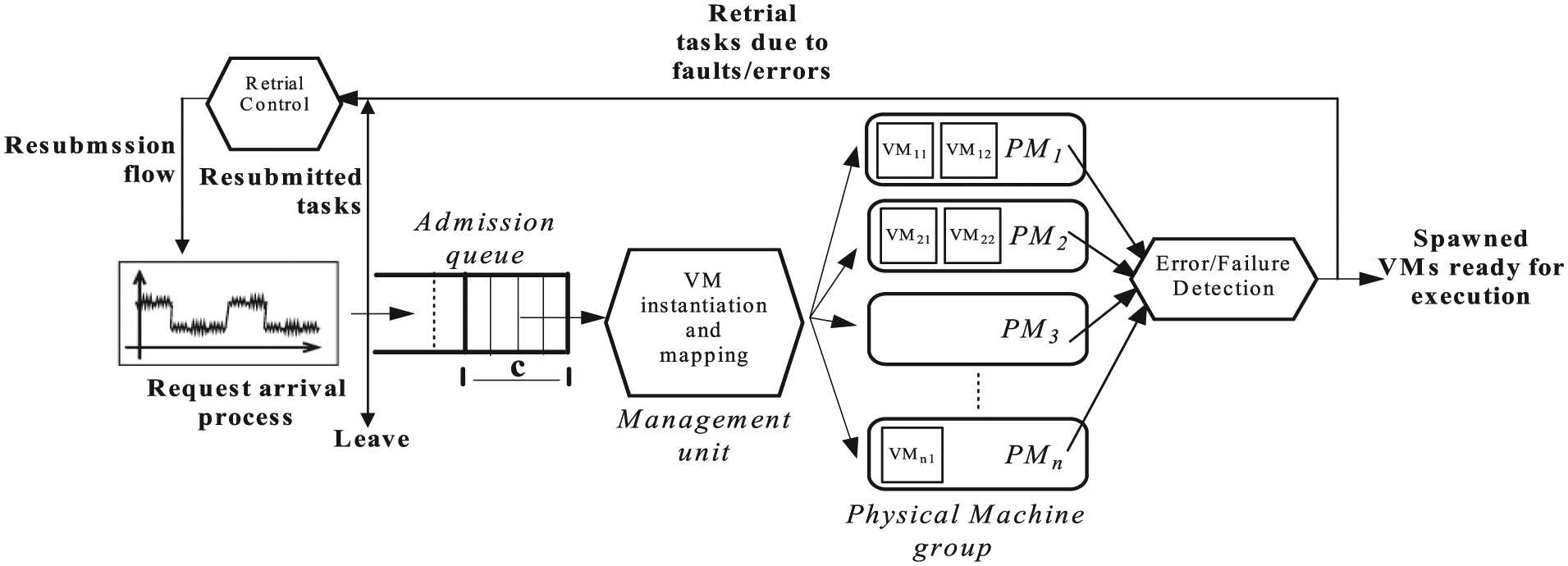
IaaS cloud provisioning control flow.
Performance prediction
We denote

where
It has been widely recognized that heavy-tailed distributions are well suited for modeling job processing and request handling activities in computer systems and networks. The Pareto distribution is often presented in terms of its survival function (or reliability function, or tail function), which gives the probability of seeing larger values than a given value. Thus, we employ it for the VM instantiation processing time. In particular, we choose the Pareto distribution where

where

Let
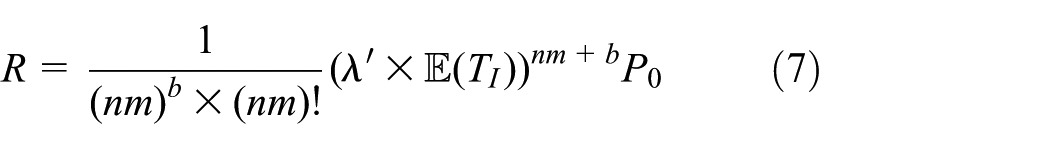
where

Let


By combining the results derived above, we have

Note that
The instantiation response delay,
Since the instantiation processing time,

In the following, we have to calculate the probability that a cloud request enters the retrial control unit,

As can been seen from Figure 2, a successfully instantiated request may experience several retrials before its final successful instantiation due to the capacity limit and instantiation faults. The expected number of retrials of a cloud request on condition that it is finally successfully instantiated,



Instantiation response delay can therefore asymptotically approach the sum of the time needed for retrials due to the capacity limit, the time needed for retrials due to faulty instantiations, and the time needed for the last successful trial

Case study and model validation
To prove the effectiveness of the prediction framework, we present a comparative study on a campus IaaS cloud. It is built following the IaaS architecture presented in Figure 2 and is developed by the XenServer and OpenStack toolkits. Figure 3 shows its physical architecture.

The architectural view of the campus cloud.
The cloud system bases itself on six Intel I450 servers (4-CPU Intel Xeon 5506/128G RAM/15TB storage but only 3-CPU/8G RAM/4TB storage is available for users), each of which serves as a PM. Each PM is capable of supporting eight VMs in parallel at most. The capacity of the waiting buffer for requests is 16 as specified in OpenStack. The fault rate is 0.13%–0.79% based on an experimental test conducted from 14:20 to 18:35 on 5 May 2016. In the test, the IaaS cloud continuously processes requests from students and tries to instantiate each request into a corresponding VM instance. Each VM is deployed on only one PM for data consistency and integrity. The test logfile covers time-stamps of each request’s arrival, departure, failure, and successful instantiation times in consecutive periods.
The request arrival rate and instantiation processing time fluctuate and we thus employ the ARMA model to predict their future values as the inputs of the stochastic performance model. As discussed earlier, we consider instantiation processing time as a fluctuating random variable and thus employ its predicted future value (illustrated in Figures 4–6 using the ARMA method),
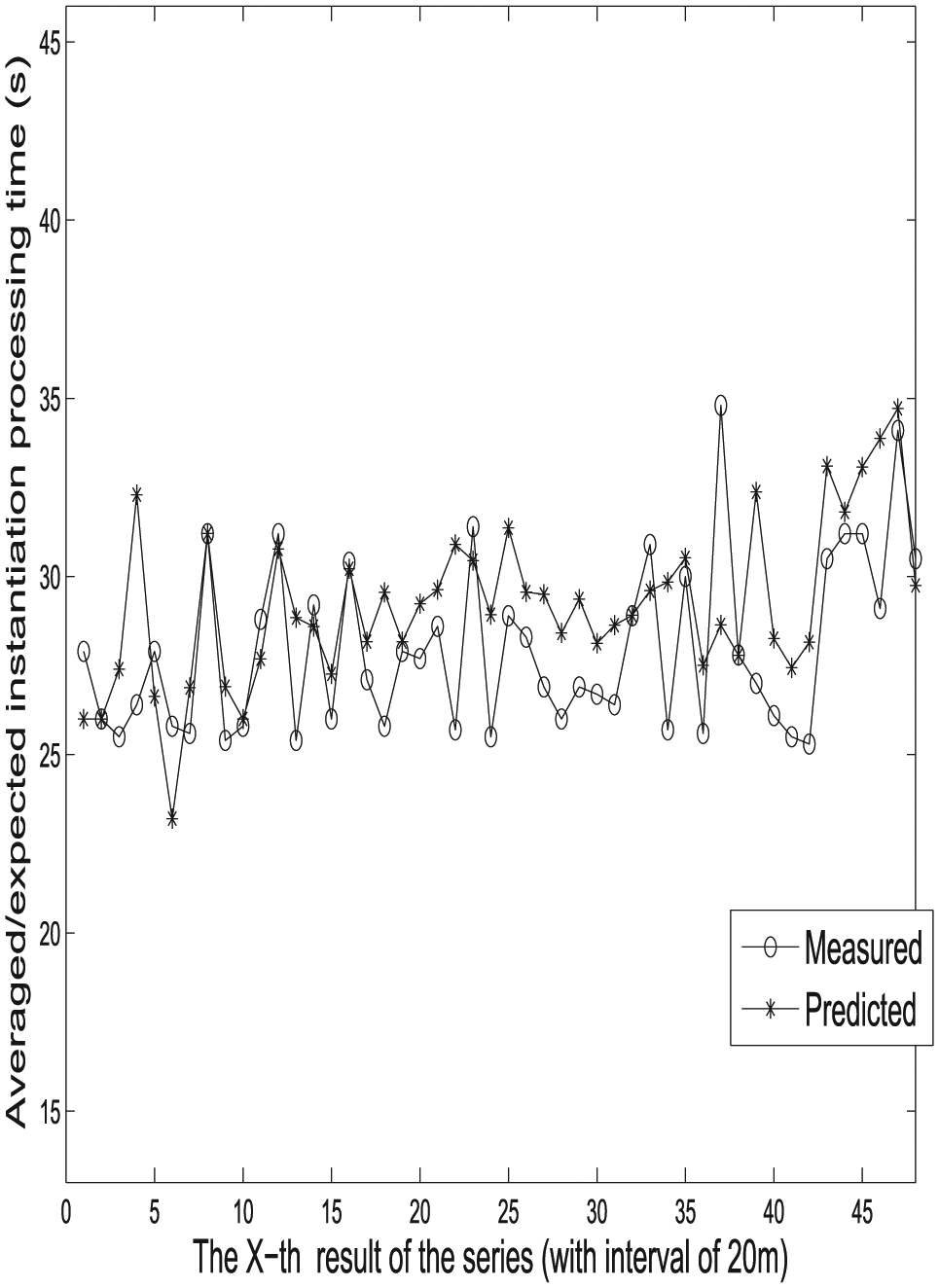
Predicted versus measured averaged instantiation time at high load.

Predicted versus measured averaged instantiation time at medium load.

Predicted versus measured averaged instantiation time at low load.
Measured performance results and their corresponding predicted ones are compared in Figures 7–12. As suggested, our proposed prediction approach achieves satisfactory trend-curve-fitting, and predicted performance results show good convergence to measured ones. Note that measured results show more fluctuations than predicted ones due to the fact that the ARMA method tries to converge to the overall trend with least squares regression and find the values of the parameters which minimize the error term. Individual fluctuations are thus less captured. However, as can be seen that the overall long-term trends of experimental results are well followed by predicted ones.

Predicted versus measured expected response delays at high load.
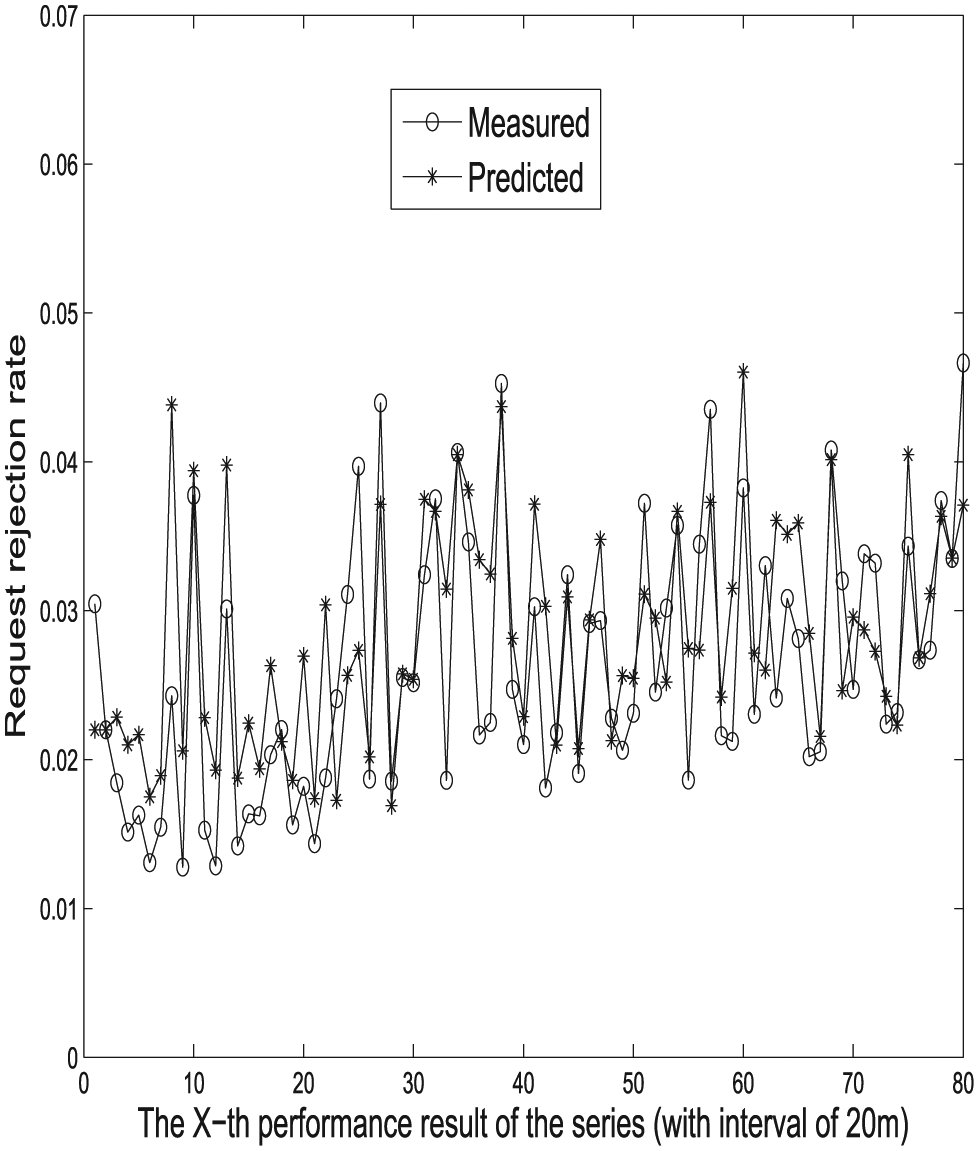
Predicted versus measured request rejection rates at high load.
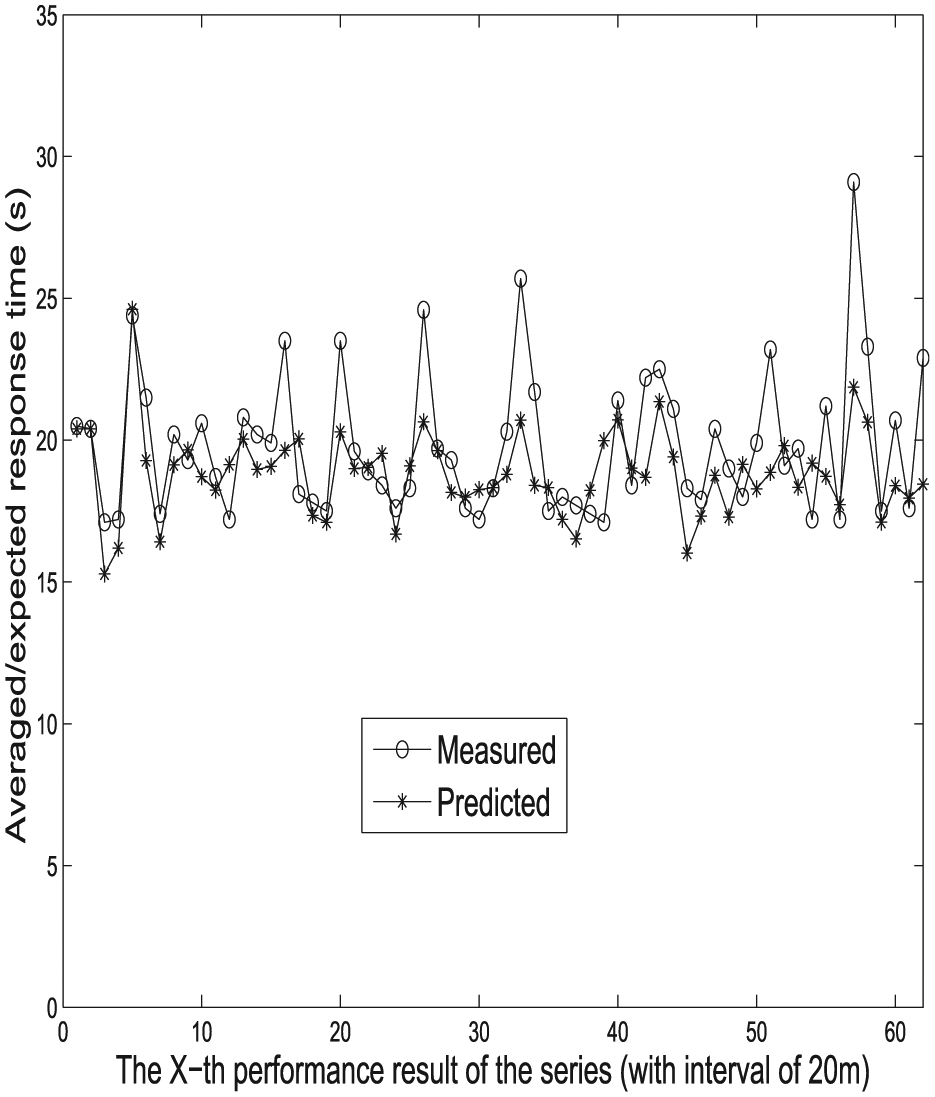
Predicted versus measured expected response delays at medium load.
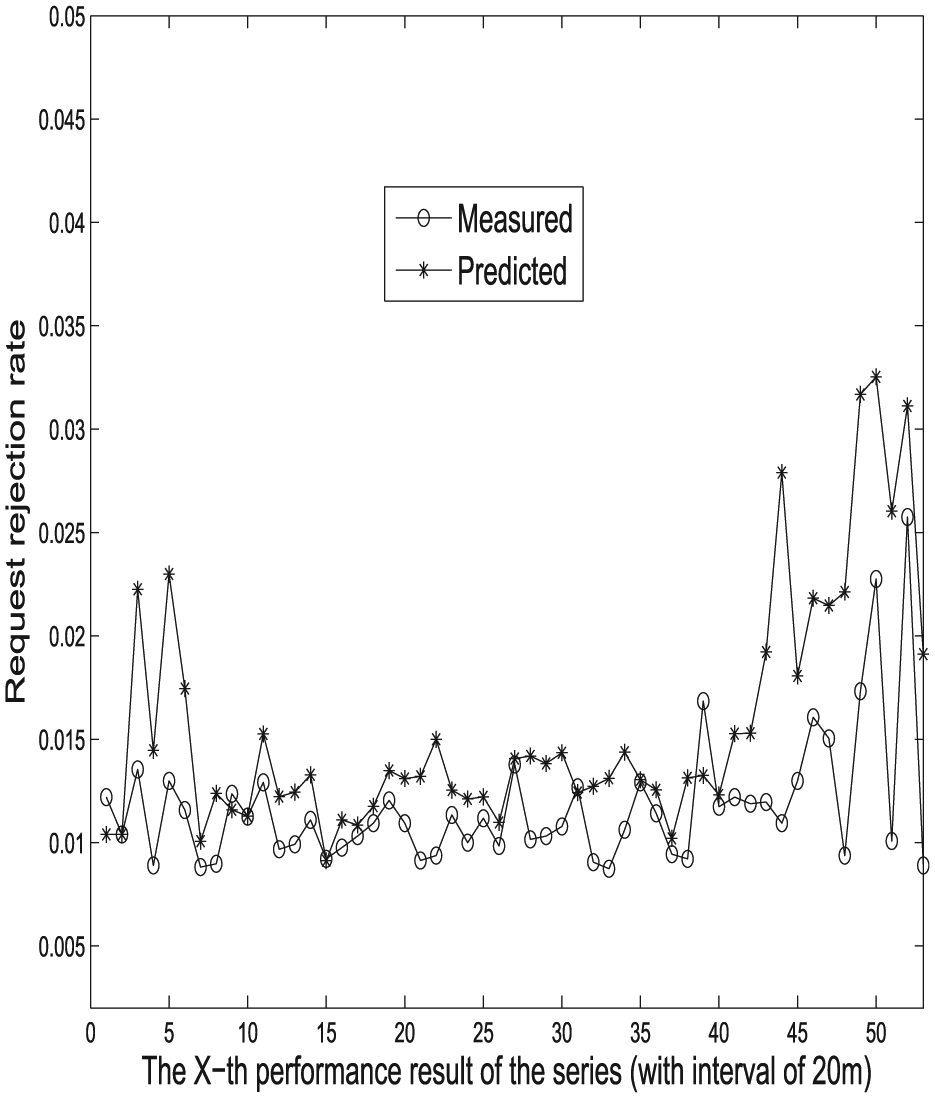
Predicted versus measured request rejection rates at medium load.

Predicted versus measured expected response delays at low load.

Predicted versus measured request rejection rates at low load.
Conclusion and further studies
In this work, we propose a comprehensive performance estimation and trend prediction approach for fault-prone IaaS clouds with request rejection and resubmission. Based on a stochastic queuing model and a ARMA time-series, our approach is capable of predicting request responsiveness and request rejection rate under variable system conditions. For the model validation purpose, in the case study based on a real-world campus cloud, we compare predicted and measured performance results and show their satisfactory convergence.
We intend to work on the following topics as our future research: (1) more, for example, throughput, mobility, and consolidation overhead should be considered; (2) Petri nets19–22 can be used as an alternative model formalism to facilitate structural reduction techniques and reduce computational complexity; (3) dynamic VM-PM-mapping strategies should be considered and modeled instead of static ones assumed in this article where PMs are equally likely to host incoming VM instances. According to a dynamic mapping strategy, the cloud management unit decides the mapping plan based on the utilization and working status of each PM at run time. However, theoretical performance estimation and derivation of response delay distribution of dynamic-mapping-based IaaS cloud can be very difficult.23,24
Footnotes
Academic Editor: Sang-Woon Jeon
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the NSFC under Grant No. 61472051, the Fundamental Research Funds for the Central Universities under Project Nos 106112014CDJZR185503 and CDJZR12180012, the Science Foundation of Chongqing under Nos cstc2014jcyjA40010 and cstc2014jcyjA90027, Chongqing Social Undertakings and Livelihood Security Science and Technology Innovation Project Special Program No. cstc2016shmszx90002, China Postdoctoral Science Foundation No. 2015M570770, Chongqing Postdoctoral Science special Foundation No. Xm2015078, and Universities’ Sci-tech Achievements Transformation Project of Chongqing No. KJZH17104.