
Abstract
The research of localization technology based on received signal strength and machine learning has recently attracted a lot of attentions, since with the help of enough labeled training data this technology is able to achieve high positioning accuracy. However, it is an expensive job to collect enough labeled training data in the broad outdoor space. In order to reduce the cost of building and maintaining training database, semi-supervised extreme learning machine is applied to solve the cellular network localization in this article. However, the performance of this algorithm is sensitive to the values of the hyper parameters. Without any systematic guidance, the optimal hyper parameters can only be selected by experienced workers through trial and error. To address this problem, we propose a novel algorithm by combining particle swarm optimization and semi-supervised extreme learning machine to automatically select the optimal hyper parameters of semi-supervised extreme learning machine in this article. The experiments demonstrate that applying particle swarm optimization in our optimization framework makes the hyper parameters of semi-supervised extreme learning machine algorithm self-adaptive in different conditions. Moreover, the proposed method is more stable than the general semi-supervised extreme learning machine and outperforms other compared methods.
Keywords
Introduction
The highly developed cellular network with worldwide range signal and the popularity of the smartphone make the localization technology based on cellular network become an important outdoor localization technology. When the Global Positioning System (GPS) is unavailable, the smartphone has no choice but relying on the cellular network to obtain the location information. Meanwhile, acquiring the accurate location information is a prerequisite of many Internet of Things (IoT) applications, whose development makes more and more devices be connected to cellular network. Therefore, the situation presented above motivates us to improve the positioning accuracy in the environment of cellular network.
Traditional localization technologies, such as time of arrival (TOA), time difference of arrival (TDOA), and angle of arrival (AOA), are geometrical distance based. Compared with these technologies, the technology based on received signal strength (RSS) and machine learning is more suitable for the non-line-of-sight (NLOS) environment. 1 It is a challenging task indeed because the labeled RSS data with location information for training are artificially collected by moving devices in target area. But the collecting process in outdoor space is time-consuming. In contrast to the acquisition of labeled data, the unlabeled RSS data without location information is easier to be collected. We can extract RSS data from the measurement report (MR) uploaded by mobile at the target area.
Since the existing semi-supervised learning algorithms can make use of the unlabeled data to reduce the demand of labeled data, some semi-supervised learning algorithms have been proposed to solve the indoor localization for WIFI network, such as the label propagation algorithm (LP algorithm), which is applied in Liu et al. 2 and Sadiq and Valaee. 3 However, LP algorithm is inefficient, since in online positioning phase, the LP algorithm estimates the location by labeling the new coming RSS through the LP process, involving the whole dataset. Lin et al. 4 applied spectral decomposition of Laplacian matrix to labeling the unlabeled data through aligning the labeled data in the eigenvectors space. Then, they used the entire labeled dataset to train the supervised learning algorithm for localization.
In order to address the ill-posed problem, Tikhonov
5
put forward a regularization method. The basic idea of this method is to introduce regularization function with the prior knowledge about the solution. So that we can obtain a stable solution by solving a well-posed problem, which is proximate problem of the original ill problem. In essence, many machine learning problems are ill-posed problems. From 1990s, the development trend of classical regularization technique is making the solution of function
To overcome the ill-posedness of semi-supervised learning problems, Belkin and Niyogi6–8 extended the basic Tikhonov regularization framework by introducing manifold regularizer and called it manifold regularization framework. Through the manifold regularizer, this framework approximating the manifold structure by the graph is built from the labeled and unlabeled data. The famous semi-supervised learning algorithms like Laplacian support vector machine (Lap-SVM)6,7,9 and the semi-supervised extreme learning machine (SS-ELM) 10 are built on this framework.
Liu et al. 11 have proposed an algorithm called SELM for indoor localization based on the theory of extreme learning machine (ELM)12,13 and manifold regularization,6,7 which inherits the property of ELM, so that it can utilize the unlabeled data to improve the localization accuracy with fast training speed. However, the SELM does not control the complexity of the classifier. Another improved version algorithm, which is called SS-ELM, is proposed by Huang et al. 10 based on manifold regularization. Different from SELM, the Tikhonov regularization constraint is added to the object function of SS-ELM, thus the complexity of the classifier can be controlled. Moreover, SS-ELM can weigh the labeled samples in order to handle the imbalanced classification problem. Iosifidis et al. 14 put forward a discriminant extreme learning machine (DELM) from the discriminant analysis perspective. Based on DELM, they proposed semi-supervised discriminant extreme learning machine (SDELM) in the same paper.
Although ELM is much faster than the traditional gradient-based learning neural network, the random determination of the input weights and hidden biases makes the ELM need more hidden units, which may result in ill-posed. 15 To obtain a more compact network with better generalization ability, most evolutionary-based ELM research is focused on optimizing the input weights and hidden biases, such as E-ELM, which is proposed by Zhu et al. 16 In the framework of E-ELM, the input weights and hidden bias of ELM are optimized by differential evolution (DE), according to the root mean square error (RMSE) and norm of output weight. Later, Cao et al. 17 put forward an improved version of E-ELM named Sa-ELM by replacing the standard DE with self-adaptive DE, whose trial vector generation strategies and their associated control parameters are self-adapted. In the same way, PSO algorithm has been applied to the optimization of ELM such as PSO-ELM in Xu and Shu 15 and IPSO-ELM in Han et al. 18
Through the experiment, we find out that the lack of labeled training data makes the ill-posedness prominent in semi-supervised learning. Thus, the prior knowledge of regularizer is more important than the input weights and hidden bias selection. That is why the performance of SS-ELM is sensitive to the values of the hyper parameters in the case of lack of labeled data. Thus, the hyper parameters of SS-ELM are varied in different situation. The number of the labeled training data usually leads to different optimal hyper parameters. Without any systematic guidance, the optimized hyper parameters can be only determined by experienced worker through trial and error.
In this article, we treat this parameter selection problem as a parameter optimization problem. We are going to present the hybrid of particle swarm and semi-supervised extreme learning machine, for convenience we call it PSO-SSELM. The practice has proved that the stochastic search algorithm particle swarm optimization (PSO) is an efficiency algorithm that can reach the global minima. 19 Compared to genetic algorithm, the PSO not only has no complicated evolution but also has less parameters to adjust. 20 Based on the above context, the contributions of this work are as follows:
By implementing the SS-ELM, we reduce the demand of labeled training data without lowering the localization precision level in the cellular network environment.
In the proposed PSO-SSELM algorithm, we use the PSO to optimize the hyper parameters of SS-ELM, so we obtain a hyper parameter self-adapting SS-ELM with optimal performance in different condition.
Considering the lack of labeled information in semi-supervised learning problem, PSO optimizes the hyper parameters according to both the loss on labeled data and the number of extreme values on the whole dataset (including labeled and unlabeled data) in the framework. This important feature of PSO-SSELM makes the SS-ELM obtain better performance.
Preliminaries
PSO
PSO is a population-based stochastic optimization technique, which is developed by Eberhart and Kennedy.21,22 The concept of particle swarm is inspired by social behavior of bird flocking or fish schooling. The PSO algorithm can be described as an automatically evolving system.
PSO works by randomly generating a batch of particles over the given search space and these particles move with a certain velocity to find the global optimal position after some iterations. In each iteration, every particle updates its velocity according to its momentum, the contribution of its best position
Velocity update


where the positive constant
Particle position update

Optimal position update


Another improved version of adaptive particle swarm optimization (APSO) is put forward by Shi and Eberhart. 23 This algorithm can be described by the following functions

where

where
SS-ELM
ELM belongs to the family of single hidden layer feed forward networks (SLFN). However, unlike traditional thinking that all the parameters in the feed forward networks need to be tuned, the training process of ELM only adjusts the output weight.12,13 For a given



where
Since we do not need to adjust the input weights

where † is the Moore–Penrose inverse of matrix. Although the Moore–Penrose inverse guarantees the existence and uniqueness of solution, it cannot guarantee the stability of the solution because the unavoidable noise data and undersampling cause the difference between observation value
Therefore, in order to use the unlabeled data to improve the stability of ELM in the case of lack of labeled training data, Huang et al. 10 put forward a semi-supervised learning extreme learning machine (SS-ELM) using the manifold framework


where the first term in the object function is the empirical loss on the labeled training data, and the second term and third term are Tikhonov regularizer and manifold regularizer, and

where
To obtain the optimal solution of
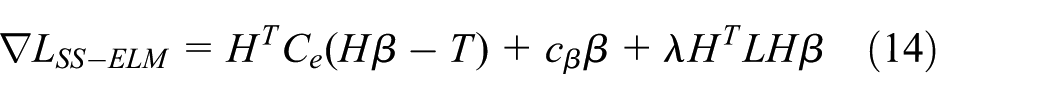
By setting the function to 0, we get the optimal solution

If the number of the labeled training data is less than the number of hidden units in SS-ELM, which means the rows are more than the columns in matrix

where
Hybrid PSO and SS-ELM for localization
The hyper parameters
We do not usually have access to the true marginal distribution, just to data points sampled from it. Therefore, regularization with respect only to the sampled manifold will lead to an ill classifier.
There are some situations that the manifold assumption holds in less degree, thus smaller impact of manifold regularizer in the objective function of classifier will produce a better solution.
That means being able to trade off these two regularizers are important in practice. However, there is not any theoretical instruction guiding us to select optimal hyper parameters, so that we can trade off the manifold regularizer and Tikhonov regularizer. Since it is difficult for us to summarize the complex parameter adjustment method into a theory, we solve this problem from the parameter optimization perspective.
Before we can optimize the hyper parameters
For the first problem, we use the real number encoding method by equations:
As we mentioned in the second section, the fitness function
Based on the analysis above we can solve the second problem, our fitness function based on both the label prediction error and the number of extreme values. In fact by introducing the number of extreme values into the fitness function, PSO is able to utilize the unlabeled data to select proper hyper parameters. So that we can broaden the criteria information, which PSO use to select proper hyper parameters. Therefore, for regression model, the fitness function is expressed as

where

where

where
If we denote the training output of SS-ELM as

According to fitness functions (17) and (18), the contribution of RMSE and F1 of labeled data will increase along with the increase in the proportion of labeled training data. That means when we have enough labeled data, PSO will mainly depend on the labeled information in the optimization phase. Because compared with the unlabeled data, the information from labeled data is more accurate. Somewhat this strategy makes the model self-adaptive.
Finally, we summarize the procedure of our proposed method as follows:
Step 1. Randomly initialize the input weighs
Step 2. Randomly generate a batch of particles. Then, denote the initial position of particle with index
Step 3. Compute the fitness for each particle according to the functions (17) or (18).
Step 4. Update the variable according to functions (1)–(5).
Step 5. If the global optimal fitness has met convergence condition, then stop the iterations and obtain the optimal hyper parameters, otherwise continue the iterations from Step 3.
Experiment
Experimental setup
To our knowledge, there is not any appropriate public cellular network benchmark dataset for the RSS-based localization research. So the simulated data are used in our experiments. In order to obtain the RSS data, the radio propagation environment in urban area is simulated based on the real three-dimensional (3D) map and the Base Station distribution of city Guangzhou by Volcano URBAN model (Volcano propagation model: www.siradel.com/software/connectivity/volcano-software/), which is one of the 3D tray tracing propagation models 24 that is integrated in a commercial radio planning software Atoll version 3.1. Figure 1 gives the rendering of this simulation. The simulation resolution is set as 5 m in Atoll, therefore we can obtain a sample for each 5 m.

Simulation output based on the Volcano model.
Table 1 shows the format of RSS sample, where the first 35 columns are the RSS-simulated values for each base stations and the last 2 columns represent the real-world coordinate, the longitude and latitude coordinates (in meters with UTM from WGS84). To evaluate the performance of the algorithm, the localization area should be defined, in this article we consider a localization area of
The format of simulated data.

Performance measurement
The performance measurements are different according to the ways we estimate the location of terminals:
1. Location region recognition. This is usually applied by dividing the localization area into several subregions, the locations of terminals are estimated by recognizing the subregions, where the terminals belong to. Usually, the classification algorithm is used to recognize the regions. Therefore, the True Positive (TP), False Positive (FP), True Negative (TN), and False Negative (FN) are employed to obtain performance metrics such as accuracy (AC), precision (P), and recall (R) for one experiment
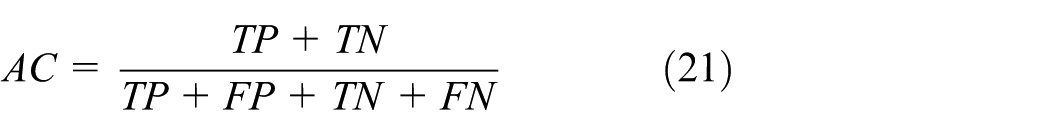


Through the evaluation for one single experiment, we can obtain macro metrics for multiple experiments



2. Coordinate prediction. Rather than recognizing subregions, we estimate the coordinate of terminal directly while applying this method. Usually, regression model is used to predict the coordinate of terminal. Therefore, we evaluate the performance of algorithms by measuring the error distance (ED) between the estimation location and the real location

To evaluate the stability of the algorithm we need the metrics



Since SS-ELM can be applied in classification and regression, in order to demonstrate the strengthness of the proposed method from different perspectives, we evaluate the proposed method in both ways. Thus, we also divide the
To evaluate the performances, the cross-validation technique is applied in the experiments. In a typical k-fold cross-validation, the samples are randomly split into K subsets equally. Then, the subsets are divided into two sets, the test set with only one subset and the training set with the reset (k − 1) subsets. The k-fold cross-validation process can be described as Algorithm 1.

Performance comparison
After the division of training set and testing set, we further divide the training data into two groups, one group with labels, the rest are unlabeled. Our experimental configurations are as follows: (1) operating system: Linux 3.19.0-25-generic, (2) CPU: Xeon E5-2640V2@ 2.0 GHZ, (3) memory: 32 GB, and (4) software: Python2.7 and MATLAB R2015b for Lap-SVM.
The experiments are run in two groups. In the first group of experiments, localization problem is treated as a regression task. The proposed PSO-SSELM is compared with ELM, SS-ELM, PSO-ELM, E-ELM, and support vector regression (SVR). Except for SVR, whose program is provided scikit-learn 0.18,
25
we developed the python program of all these algorithms according to the source code of ELM and SS-ELM from the homepage of its author (Source code of ELM and SS-ELM: www.ntu.edu.sg/home/egbhuang/elm_codes.html). The default parameters of SVR in scikit-learn 0.18 are used in our experiments. The number of hidden units in all the neural networks are 150. The hyper parameters of SS-ELM are set as constant values:
Table 2 gives the experiments result of the first group. The experimental variable in this group is the number of labeled sample and the best performance for metrics in each experiment are the bold values in the table. As observed from this table, the semi-supervised learning algorithm (PSO-SSELM, SS-ELM) outperforms the supervised learning algorithm (ELM, PSO-ELM, E-ELM, SVR), when the number of labeled data is less than 50. When the number of labeled data is more than 50, they reach the same level. Notice that the proposed PSO-SSELM gets the lowest error distance in five of six experiments. Moreover, in these six experiments, the SVR and the proposed PSO-SSELM achieve the much fewer extreme values than other compared algorithms. On the contrary, E-ELM and PSO-ELM produce more extreme values than other compared algorithms in these six experiments, because in both E-ELM and PSO-ELM, the input weights and hidden bias are optimized only according to the limited labeled data. However, by introducing the number of extreme value into fitness function in training, PSO is able to utilize both labeled data and unlabeled data to select optimal hyper parameters, which are more efficient in improving the stability of SS-ELM. Through this mechanism, the hyper parameters of SS-ELM are self-adaptive as what we demonstrate in Table 3. That is why the proposed PSO-SSELM can obtain optimal SS-ELM with fewer extreme values.
The performance comparison of coordinate prediction.

The optimal hyper parameters of PSO-SSELM for each experiment.

In the second group of experiments, the localization problem is treated as a classification task. In this group of experiments, the compared methods are several semi-supervised classification algorithms, including LP, 25 Lap-SVM, 9 SS-ELM, and SDELM. The default parameters in the library are used for the LP and Lap-SVM. The parameters of SS-ELM and PSO-SSELM are the same with what we declared in the first group of experiments. The fitness function of PSO-SSELM is function (18).
Table 4 reports the macro precision (%), macro recall (%), and macro accuracy (%) with the best performance represented by the bold value for the 10-fold validation. Among these six experiments, the proposed method achieves best precision in four experiments, and best recall and best accuracy in three and four experiments, respectively. Based on this result we can infer that, the performance of the proposed algorithm is better than the other graph-based algorithms (SS-ELM, SDELM, Lap-SVM, LP) in the comparison experiments. The potential reason is that the hyper parameters of SS-ELM in the proposed algorithm are self-adaptive, which result in optimal performance of SS-ELM in difference conditions. While the other compared methods with non-adaptive parameters, they do not achieve their best performance in some certain condition. For example, LP may not converge to global optimal solution with the default parameters.
The performance comparison of regions recognition.

Through the two groups of experiment above, we can summarize that the proposed method makes the hyper parameters of SS-ELM self-adaptive, by integrating PSO and SS-ELM. Therefore, SS-ELM can achieve optimal performance under different conditions. By comparing the optimization of strategy proposed PSO-SSELM with the optimization strategies of E-ELM and PSO-ELM, we can infer that the most appropriate way to improve the performance of ELM family in the case of lack of labeled data is to give reasonable hyper parameters. Because in the training phase of extreme learning family, the output weights are determined by the inverse. The inverse is likely to produce the extreme values, which cause huge error. We solve this problem by utilizing both labeled and unlabeled data in the fitness function of PSO, so that the proposed method gains comprehensive information for optimal hyper parameters selection, which improves the stability and provides better accuracy for SS-ELM.
Analysis of fitness functions
In Figure 2(a) and (b), we plot the regression fitness in training according to function (17) and the RMSE of the SS-ELM in the testing, under the condition that the number of labeled training data is 70. In these two figures,

(a) Regression fitness surface and (b) root mean square error surface.
In the same way, we plot the classification fitness according to function (18) in training and the average classification accuracy (%) of the SS-ELM in testing, under the condition that the number of labeled training data is 300. As observed from Figure 3(a), the z axis is the opposite number of the average classification accuracy. In Figure 3(a), the optimal values are obtained in the region where

(a) Classification fitness surface and (b) average classification accuracy surface.
Analysis of optimization methods
In order to explore the performance difference between PSO and other parameter selection algorithms, we replace the PSO in the framework of PSO-SSELM with other heuristic evolutionary algorithms such as genetic algorithm (GA), 26 DE algorithm, 27 and the brute-force grid search algorithm (GS). 28 For convenience, we denote them as GA-SSELM, DE-SSELM, and GS-SSELM in the following. We run these algorithms in the same machine and software and time the training phase of each algorithm. Figure 4 gives the performance comparison, while Table 5 gives the average training time consumption.

Comparison of (a) average error in coordinate prediction and (b) macro accuracy in regions recognition.
Comparison of average training time with different parameters selection method.

As observed from Figure 4 and Table 5, PSO-SSELM, DE-SSELM, GA-SSELM, and GS-SSELM reach the same performance level, since all these parameter selection algorithms are in the same optimization strategies, which are the fitness functions (17) and (18). Although we declare the same level here, it does not mean strictly equal, there are some differences among them. But the differences are usually within 1 m or 1%, which is small enough to ignore in the outdoor localization.
For training time consumption, the brute-force grid search takes much longer training time compared to other three heuristic algorithms. Among the heuristic evolutionary algorithms, GA-SSELM takes longer time than PSO-SSELM and DE-SSELM for training, while the PSO and DE are in the same level. This is because PSO and DE usually converge earlier than GA. Again we declare same level here, but this does not mean strictly equal, considering both PSO and DE are heuristic searching algorithms with randomness, we cannot guarantee the convergence rate is not affected by this stochastic factor and other experiment factors, therefore the training time difference within 2% can be ignored. Based on the above analysis, we can conclude that the chosen PSO and DE are the reasonable parameter selection tools.
Conclusion
The outdoor localization based on RSS with the cellular network usually need to collect labeled training data. By implementing the SS-ELM, we can reduce the demand of labeled training data without lowering the precision level. But the calibration of hyper parameters in SS-ELM is another labor-consuming job. To address this problem, in this article, we introduce a PSO and SS-ELM hybrid algorithm to optimize the hyper parameters automatically, so that SS-ELM can achieve optimal performance under difference conditions.
The experiments demonstrate that by importing a large amount of unlabeled training data in training phase, the PSO-SSELM gains comprehensive information for optimal hyper parameters selection, which improves the stability and provides better accuracy for SS-ELM.
We replace PSO with other parameter selection algorithms to explore the performance differences between PSO and others. Through the experiment, we find out that the performances of all the parameter selection algorithms are in the same level, the PSO even performs better in some cases. Moreover, PSO and DE take shortest training time among all the compared algorithms.
The necessary iteration in the training phase of PSO-SSELM takes a longer training time SS-ELM. However, considering the overall localization performance and the labor-saving calibration, we think that the idea in this article is worthy of referencing for outdoor localization.
The research of PSO-SSELM remains in the progress of overcoming its shortcomings. First, we use the artificial data in the validation, and we plan to deploy PSO-SSELM in the real environment in the future research. Second, although PSO-SSELM outperforms the other methods for outdoor location estimation, the accuracy is still in need to be improved. We would take the parameters of Laplacian matrix into the optimization phase.
Footnotes
Acknowledgements
The authors are grateful for the constructive advice on the revision of the manuscript from the anonymous reviewers.
Academic Editor: Stefano Savazzi
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work described in this paper was funded by the Engineering and Technology Research Center of Guangdong Province for Logistics Supply Chain and Internet of Things (Project No. GDDST[2016]176); the 3th strategic rising industry program of Guangdong Province (Project no. 2012556003); International Cooperation Special Program for platform (Project no. 2012J510018); the key lab of cloud computing and big data in Guangzhou (Project no. SITGZ[2013]268-6); Engineering & Technology Research Center of Guangdong Province for Big Data Intelligent Processing (Project no. GDDST[2013]1513-1-11); IoT home wireless router system and RFID (Project no. GDEID2012IS054); and the Promotion of the industrialization of Family Information Platform (Project no. 2013B090200055).