
Abstract
In mobile ad hoc networks, topology changes very frequently due to node’s mobility. Frequent change in topology increases traffic signaling that may arise energy and scalability issue. Cluster-based routing is the energy-efficient technique in mobile ad hoc networks to address the scalability issue and to minimize control messages. In this article, honey bee algorithm is used for dividing the mobile ad hoc network nodes into different clusters. The bees work to gather in groups to perform their activities. The proposed honey bee algorithm–based clustering forms clusters in an efficient manner with fewer resources such as energy and bandwidth utilization. A node is selected as cluster head based on node degree, neighbor’s behavior, mobility direction, mobility speed, and remaining energy. Due to the efficient nature of bees and maximum parameter’s consideration, the proposed technique inspired from the foraging behavior of honey bees gives efficient and stable cluster formation. The control message overhead is also avoided. The work is validated mathematically, and simulation has been performed for different scenarios. Simulation results are compared with existing clustering schemes. The simulation results show that the honey bee algorithm–based clustering technique used for clustering outperforms the existing schemes under consideration.
Introduction
MANET (mobile ad hoc network) 1 also known as the packet radio network is the group of nodes that share information with each other even in the absence of a fixed communications infrastructure. It consists of mobile nodes that move around freely and cooperate in relaying packets on behalf of one another. MANET can be deployed in a variety of engineering applications such as emergency rescue, law enforcement, battlefield communications, and disaster relief. A MANET can be divided into a hierarchical architecture by organizing nodes into clusters, 2 similar to the IP (Internet Protocol) subnetwork concept on the Internet. The information about the links and nodes is aggregated within each cluster. The whole cluster can therefore be seen as a single node (logical) at the cluster level. The network layer then communicates with these logical nodes (clusters) to manage the network. The control overhead of the network is reduced with the help of clustering. Optimal cluster head (CH) selection is a non-deterministic polynomial-time hard (NP-hard) problem. 3
The design and development of clustering protocol that route data to their destination in an efficient manner with few resources are required. The significance of the clustering issue can be stated in two ways. First, clustering can be used for effective network management. Usually, a MANET consists of more than hundreds of mobile nodes. In flat network infrastructure, 4 unnecessary information is produced. When the size of the network is very large, the flat network infrastructure saturates the network and encounters the scalability problem. In contrast to wired networks, scalability is more challenging in MANETs due to node’s mobility. Thus, effective network management is very essential. So far, the most competent method to manage MANET is clustering. 5 Second, clustering serves as the base for numerous other key problems in MANETs, for example, topology control, 6 backbone construction, 7 intrusion detection, 8 and routing. 9 All the above issues are solved based on a well-structured clustered network.
The main objective of a clustering algorithm 2 is to discover a reasonable set of clusters interconnected with each other covering the complete set of mobile and static nodes in a MANET. At any moment, one node can only be the member of one cluster. It is not necessary that each cluster has a CH. However, as the election of CHs brings the benefit of easy network management, the majority of the previous research works focus on clustering where CHs are elected. The clusters should be formed and maintained in such a way that the cost in terms of resources, such as battery power and bandwidth utilization, should decrease. The cost should be decreased during cluster formation and maintenance. If not, the clustering will become more expensive than flat routing. To form balanced clusters with low cost, different optimization techniques 10 such as particle swarm optimization and genetic algorithm (GA) have been applied. In this article, a honey bee algorithm 11 inspired from the foraging behavior of honey bees is applied to form balanced clustering. The CHs are selected based on remaining energy, node mobility, mobility direction, relative mobility, node degree, and neighbor mobility. According to our knowledge, it is the first study that considers all the above metrics during the CH selection process. Considering these metric results, some interesting features of a cluster-based MANET are cluster stability, low energy consumption, topology control, and effective network management.
In the proposed method, nodes are known as food sources. A node (a food source) with more nectar (nectar is calculated as node degree, mobility, energy remained, etc.) is the CH. The scout bees handle new food sources (exploration and selection of CH nodes). The onlooker bees wait for the dance floor to observe food sources with more nectar (which satisfy more parameters). Once the CHs are selected, the employed bees are responsible to collect nectar (data) from CHs. The collected data are then sent to other nodes based on the requirements. The parameters are regularly checked, and once the node has nectar less than its neighbor, the role is assigned to other nodes based on the objective function. Larger nectar value means the node satisfies more parameters.
The rest of the article is organized as follows: section “Related work” discusses the existing work, section “Proposed honey bee algorithm–based clustering” describes the basic honey bee algorithm and how the honey bee algorithm is used for clustering, section “Experiment evaluation” presents the performance evaluation of the proposed technique and experimental results, and section “Conclusion and future work” presents the conclusions and future work.
Related work
Many researchers worked on how to increase the network lifetime. One emerging technique to increase the network lifetime is load balancing.
Load balancing
The lifetime of the network can be increased by distributing the load equally among all nodes. In the work by Subathra et al., 12 a token passing mechanism for group communication is used along with minor CH. In this scheme, principal CH is elected based on node’s mobility and its degree of connectivity, while the minor CH is also selected to help the principle CH for carrying some unimportant activities. The objective of this work is to simplify the token monitoring scheme and CH play the role of the monitor with the help of the secondary CH. The limitations of this work include the following: it fails to work if the mobility model is random, relative mobility is not considered during cluster formation, the remaining energy of a node to become a CH is not considered, and a node with different mobility direction than its neighbors may become the CH.
The CHs are selected using independence set and density in the work by Su et al. 13 Independence sets discovery algorithm works in a distributed fashion for the election of CHs. The independence set is formed, and the nodes that are the subset of node ID’s can participate in the CH election process. In this way, the load is balanced among sensor nodes in the network.
Game theory is used for a cluster-based routing in the work by Chatterjee et al. 14 The cost-per-hop for intermediate nodes can be determined using Dutch and procurement auction schemes. The claim is the flexibility in managing trust and less computation and communication are needed. Thus, message overhead is also decreased. The CH is elected based on its trustworthiness. The Markov chain is used for analysis. The objective of this research is to ensure the cooperation of nodes using incentive and punishment mechanism. The limitations are the geographic location is used to form clusters that may result non-optimized clusters, node degree is ignored, and mobility of nodes is not mentioned.
Weighted and multimedia conference–based clustering
Nath et al. 15 present a survey of weighted clustering algorithms, the cluster formation as well as the CH selection, and its limitations are discussed. They tried to stabilize the CH; the decrease in the total required time and the overhead of transmission are also up to a minimal level. Changes in topology are automatically adopted.
Ganeshan et al. 16 proposed a solution for multimedia support in MANETs. Clusters are formed at the application level. The CH’s election is done based on the capability of nodes it has. The objective of this scheme is to solve the scalability issue and large size routing information. This scheme is proposed for multimedia-based conferencing. The limitations of this scheme are as follows: it is not applicable in general MANET scenarios like military operation, rescue management, and so on, mobility is an important feature of MANET which is not considered in this scheme, and node remaining power is also ignored during cluster formation.
Quality of service multicast clustering
In a MANET, the design of a multicast scheme is employed with the clustering mechanism in the work by Su et al., 17 which exploits unidirectional links. The performance of multicasting using unidirectional links can be improved if these links are detected and utilized. A protocol called Quality of Service multicast routing protocol (QMRP) for MANET is presented by Li and Li. 18 The information maintenance at the global level is not required in this protocol; however, the local multicast routing information on other clusters is maintained. It supports multi-quality of service (QoS) constraints, and any node is allowed to leave or join the network anytime. The objective of this work is to generate QoS routes in mobile environments with certain QoS constraints. It provides fast convergence and provides guarantee for multiple QoS constraints. The limitations are as follows: it fails to work when topology changes very frequently, hard QoS is not guaranteed in this work, and nodes with low energy may be elected as CH.
Trust-based model and other techniques
In the work by Wang et al., 19 the trust is used for cluster formation to improve the scalability and searching efficiency of MANETs. The Bayesian analysis is used for trust’s evaluation, and clusters are formed with partial knowledge. The FASTRoute protocol is proposed by Xia and Yeo, 20 in which the networks with low group mobility and faster node mobility are divided into clusters. Node starts its operations after joining the cluster immediately, and thus, delay generated by the CH election is eliminated. The authors claim that its delivery ratio and scalability are high, while control overhead is very low. A single path for routing data is established when the nodes in the network want to communicate packets to the destination in adhoc on-demand distance vector. 21 The main drawback of this protocol is it drops the packets when a route fails to transmit the packets.
Swarm intelligence and clustering optimization
In a cluster-based MANET, Sinha et al. 22 use agents for routing. The nodes are considered as vertices of the graph, and the dominating set technique is used in a distributed manner. The remaining battery power, stability, and connectivity are the parameters used for CH election. The objective of this work is to elect most stable, reliable, and high-power node as CH, and ant colony optimization is used to find routes from the source to destination. The limitations of this work are as follows: stable nodes are suitable candidates for CH and may not work when the majority of nodes are mobile; the protocol may not perform well if some nodes move in a different direction with slow speed; optimal clusters may not be generated as node degree and relative mobility are not considered.
In bee ad hoc, 23 scout and forager bees are used for routing in a MANET. The responsibility of the scout bee is to search for the routes from the source node to the destination node. The bee ad hoc uses broadcast to send the scout bees. The scout bee has a long life in the network as compared to other bees. The forager handles transmitting the packet from the transport layer to the receiver. The life and latency foragers are responsible to collect information about the battery power and latency of the network. In Bee-MANET, 24 the scout bees handle searching. The scout bees are randomly broadcasted in a different direction. The scout bee is deployed only when there is a need for food. The scout bee acquired the routing information from the nectar area. In this way, the shortest path is selected. Bee-MANET is a type of reactive protocol.
Selected clustering schemes
Finally, the clustering schemes considered for simulation and comparison in this article are as follows.
Dynamic genetic algorithms for dynamic and balanced clustering in mobile ad hoc networks (DGAC)
The cluster-based load balancing problem is formulated to the dynamic optimization problem in this article. 25 The GA is used to form the balanced clusters in MANETs. An individual represents the members of a cluster. The fitness is calculated on the basis of load balancing metric. To help the population to cope with the changes in topology and suggest closely related high quality solutions, numerous dynamics handling methods are presented. A series of dynamic GAs are developed to solve dynamic optimization problems used to solve the load balancing problem in MANET. The limitations of this work are as follows: (1) The authors discuss many schemes to address the dynamic load balancing problem, but how these schemes will be applied to dynamic load balancing problem is not clear. (2) The algorithm mentioned in the article is very generic. (3) The article only considers the node degree for CH election, which may not perform well in many scenarios. (4) If the nodes with high mobility are elected as CHs, then it will result poor than flat routing structure. (5) CHs are elected only if the topology changes. CH’s battery will drain quickly if the topology changes are low.
Energy-efficient clustering in MANETs using multi-objective particle swarm optimization
The working mechanism of the algorithm is as follows: first, the CH neighbors are identified, and their energy and transmission range are also calculated. 26 The objectives of current and previous solutions are compared and a cluster headset with high objective value is chosen. The proposed approach is flexible in the sense that it provides multiple solutions. The user selects a solution according to the network requirements. Objective values can be adjusted dynamically. The limitations of this article are as follows: (1) the node degree is not considered while electing CHs. (2) Node having no neighbor while having good transmission power may also be elected as CH. And if this is the case, then it just wastes the energy on cluster formation. (3) It may not be possible to calculate the energy consumption in advance. (4) It may be more optimized if we also consider the neighbor quality. (5) The important parameters, node speed, and mobility model are not considered in the simulation.
Clustering in MANETs through neighborhood stability-based mobility prediction (MobHiD)
In MobHiD, the clusters are formed based on the mobility of mobile host (MH) neighbors. 27 The neighborhood mobility can be estimated easily with context aware modeling. A node is elected as CH if the mobility patterns in comparison to its neighbors are same. The node with low mobility is the best candidate. The mobility model assumed is regular pattern mobility. The regular mobility pattern is considered for long time stable clustering. For the existing host mobility, information theoretic techniques are used to gain the future node’s mobility estimation which permits online learning of the reliable probabilistic model. The limitations of this mechanism are as follows: (1) the algorithm may fail to work if the mobility model is random. It may have more clustering overhead with random mobility. (2) In some scenarios, future mobility of MHs may not be predicted. (3) The quality of neighbor (for how long it will be a neighbor) is not considered in this model. (4) Re-clustering is initiated locally if a topology change occurs; it is not possible in the same scenarios that the same nodes always form a cluster.
The schemes and their limitations discussed above motivate that a method is required to form clusters in an efficient way based on multiple parameters. Different optimization techniques such as ant colony optimization, GA, and the honey bee algorithm can be used to handle the clustering problem in MANET. Each technique has its own strengths and limitations. In this work, the honey bee algorithm is used to handle the clustering problem. The next section guides the basic mechanism of the honey bee algorithm.
Honey bee algorithm
The honey bees start flying for the purpose of foraging in many different directions. The journey may be a short distance or may fly for longer distances. The honey bees collect pollen or nectar from different sources like flowers. If the food source contains more nectar, more bees will visit that site for their task to collect more nectar. 11
The scout bee starts the process of foraging by randomly searching the patch in a colony. The scout has no prior knowledge of food sources. The scout is a type of bee that searches for food sources and gives direction to worker bees about the food sources. 11
The colony declares a portion of its population as a scout bee for exploration during the harvesting season. 11 The bee evaluates different patch qualities based on the amount of sugar or nectar in the patch. 28 The bee performs a type of dance known as the “waggle dance.” The amount of nectar and the direction of the food source are then calculated. The direction of food is guessed based on the bee dance in that particular direction. The speed of dance shows the amount of nectar in the food source. Slow dance demonstrates that the food source contains less nectar and vice versa. This dance is very important for communication between the colony members. 28 Through this way, the worker bees are sent to different food sources for nectar collection without any map, guide, or any other instruction.
The worker bees wait on the dance floor for the waggle dance of scout bees. The worker bees start their journey based on the type of dance seen on the dance floor. If the dance is fast, more worker bees are sent to that food source for nectar collection. Similarly, the colony gathers more nectar in an efficient manner. The next waggle dance is very essential for the scout after returning to the hive. 28 If there is still enough pollen in the food source, the dance is advertised, and the worker bees are sent to the food source. The honey bee algorithm has been extensively used in the literature for clustering in data mining. In these schemes, the honey bee algorithm is applied to static data. In the proposed scheme, the nodes are divided into clusters that are mobile.
The limitations of previous work are summarized as follows: in the works by Subathra et al., 12 Su et al., 17 and Li and Li, 18 the remaining energy of a node during cluster formation is ignored. Many authors12,14,16,22–24,27 did not consider mobility, the mobility direction, and relative mobility. Node degree is an important parameter in a cluster-based routing and is not considered by Chatterjee et al., 14 and Sinha et al. 22 Irrespective of node mobility, the neighbor quality which is described in section “Proposed honey bee algorithm–based clustering” is not considered in many studies.11–23 In our proposed scheme, multi-objective function is optimized using the parameters such as node degree, node remaining power, relative mobility (speed and direction), and neighbor quality.
Proposed honey bee algorithm–based clustering
Honey bee algorithm is a multi-objective optimization technique inspired from the foraging behavior of honey bees. It can be applied to many optimization problems such as the traveling salesman problem, longest common subsequence, and matrix chain multiplication. In our proposed scheme, the honey bee algorithm is used to divide the network into clusters. We consider different parameters during cluster formation, such as node mobility, node degree, node remaining energy, and neighbor quality. Our proposed scheme starts with deploying bees in the search space. In HBAC (honey bee algorithm–based clustering), the bees are categorized into three different groups; these are scout bees, onlooker bees, and employed bees. The scout bees handle exploring the new food sources better than the old one. The onlooker bee waits on the dance floor for the waggle dance of the employed bees. The onlooker bee selects the food source based on the type of dance which employed bee performs. The type of dance shows the direction of food as well as the amount of nectar in that position. The employed bees are the worker bees that perform the nectar collection. In this work, the foraging behavior of honey bees (HBAC) is used to select the CHs. Clusters are formed based on the selected CHs. The role of CH is assigned to other nodes which have more nectar than old one. The CH nodes are re-elected after all members in a cluster sent their data via a time division multiple access (TDMA) schedule. The proposed HBAC algorithm works in two phases. The first one is the cluster setup, and the second is cluster maintenance and communication phase.
Cluster setup
In this phase, the bee colony is divided into three sets; the first 10% of the population is known as scout bees. The second 45% is employed bees, while the remaining 45% is tagged as onlooker bees. The scout bees represent total clusters in the network. The nodes in the network are divided into clusters using HBAC algorithm. The working mechanism of setup phase is stated in Algorithm 1.

In this way, onlooker bees are equal in number to employ bees. The algorithm begins with generating investigational (trail) points (called initial CHs) in the search space (network), from where the honey bees start foraging. The initial CHs are selected randomly and their fitness is evaluated. The fitness of a CH depends on the amount of nectar. The CH having more nectar is a good candidate for the CH role as compared to those having less nectar. The amount of nectar in a node depends on several parameters.
To calculate the amount of nectar in a node
Node energy (
)
In this parameter, the node having maximum power is designated as a strong candidate for CH. Similarly, the node having medium power is known as an optimum node. The node having a minimum power is known as a weak node.
Neighbor quality (
)
The neighbor with one hop distance is considered a good neighbor. The neighbor two hops away is considered the intermediate neighbor and neighbors far away are considered a bad neighbor.
Node degree (
)
The nodes having a degree more than 10% are considered excellent. A node having a degree between 5% and 10% is considered a good node. The node with a less degree is known as a bad node.
Node mobility (
)
The node with relative mobility is known as recommended. Similarly, the node with different mobility but the same direction is known as partially recommended. The nodes with different mobility and different direction are marked as not recommended for CH. In this way, the amount of nectar in a node xi can be calculated by

where
Food sources are computed (optimized) in such a way that the Euclidian distance of each food location to other food locations should be approximately the same. Here, the problem of grouping



In the above equation,

where the number of nodes in the
After the initialization process is completed, the search procedure of the scout, onlooker, and employed bees is repeated to produce a new population of the CHs (solutions). The memory of the employed bees which stores CHs (solutions) should be updated depending upon the local or visual information and the results of the tests performed via equation (6) (used to calculate the nectar amount) for the quality of the new CHs (novel solutions). Here, when the amount of available nectar calculated for novel CH is superior as compared to the previous (stored in the memory of the bee), the bee memorizes the new nectar amount and forget the previous (will be replaced). If not, the location of the earlier CH is maintained in her memory without any modification. The employed bees share the quantity of nectar of different CHs and their directions with other bees on the dancing floor through various dancing patterns when they return to the hive after completing the search process. When an onlooker bee watches the dance of bees that are dancing on the dance floor, she analyzes the nectar amount by observing the type of dance that employed bees perform. The next CH is selected based on their probability associated with the nectar quantity.

where
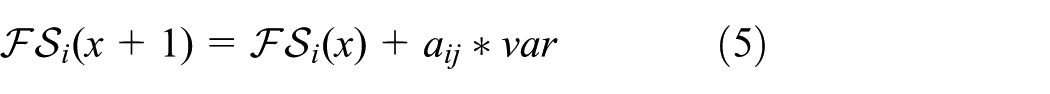
In equation (5),
Employed bees check the quantity of nectar in candidate positions. The new location is memorized and forgets the existing position stored in her memory (modify the position array in their memory) subject to the fitness of the candidate’s position. Candidate position is qualitative if the nectar quantity in it is higher than the previous one. The probable elucidation to the clustering problem is the location of the nectar positions and the amount of nectar (its fitness) represent its quality associated with the possible solution and can be calculated by the equation

The cost function to be minimized is represented by the equation

The next step after producing each candidate food location
The search process is designed in such a way that both the exploration and the exploitation of honey bees can be carried out jointly. In this article, the exploitation process of the search space can be carried out with employed bees and onlooker bees and exploration is the duty of scout bees. The greedy selection process adopted in this article and the neighborhood search which the onlooker bees and the employed bees perform have a great effect on local search performance. Similarly, the global search performance of the proposed mechanism depends heavily on the behavior of onlookers and employed bees for the construction of neighbor solution and a random search process performed by scout bees. In this approach, each food source having more nectar amount is declared as a cluster and a node is selected as a CH for some period called round (which is to be discussed in the next section).
Cluster maintenance and communication
Once the clusters are formed in cluster setup phase, the next step is to maintain clusters if any change in mobility and energy depletion of a node occurs. The data communication occurs when needed. The clusters can be easily maintained if the nodes and their neighbors are defined. The neighbors of a node

where
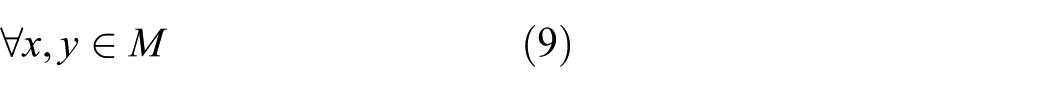
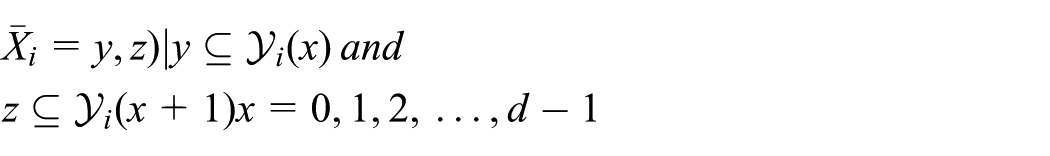
All the links in the cluster can be expressed by the set
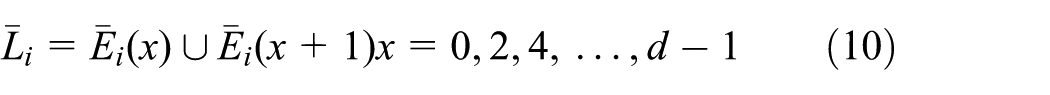
A node is within the range of node i, if it belongs to the set of nodes that are d hops away from the node i and is represented by the set
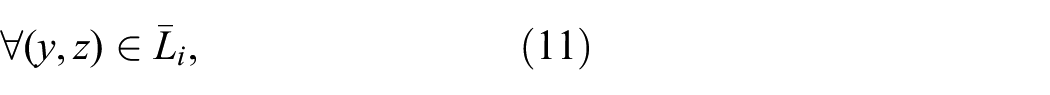

In the second round, the bee just performs foraging within
The set


The CH nodes after each round are changed to distribute equally the load among all the nodes in the MANET, and the energy of a single node will not be depleted soon. In this way, all the nodes in the network will survive for an equal time, and the network will function efficiently. In the next section, the experimental results and analytical reasoning are discussed.
Experiment evaluation
Many simulation experiments have been performed in EstiNet 8.1 to analyze the performance of the HBAC cluster formation scheme. The mobile nodes (50–100) are deployed randomly and uniformly within a square area of size 1000 m × 1000 m. Each node moves in a speed change from 1 to 80 km/h. Medium access control protocol CSMA/CA (Carrier Sense Multiple Access/Collision Avoidance) with IEEE 802.11 is used during the simulation. The propagation model used is two-ray ground. The channel capacity used for communication between mobile nodes is 2 MB/s. Each node in the network has built-in omnidirectional antenna. The propagation range of each antenna varies from 100 to 200 m. The size of the data packet is 512 bytes. Each node is assumed to have stored and forward queuing station and have information about its neighbor’s mobility. The traffic is generated through CBR (Continuous Bit Rate) traffic sources. The traffic generation rate is 20 p/s (packet per second). The simulation is run for 20 min. The results of simulation experiments are averaged over 100 different runs. The penalty and reward parameters in our proposed work are set to 0.1.
The performance of our proposed scheme is compared with DGAC (dynamic genetic algorithms for the dynamic load balanced clustering problem in MANETs 25 ), EMPSO (energy-efficient clustering in a mobile ad hoc network using multi-objective particle swarm optimization 26 ), and MobHiD (a neighborhood stability-based mobility prediction algorithm for clustering the MANETs 27 ). The metrics used in simulation for comparison of our proposed scheme with above algorithms are described below.
Cluster lifetime. The time interval a node is selected for the CH role in a cluster is defined as the cluster lifetime. The stability of a cluster can be measured by the cluster duration. The cluster lifetime decreases when the relative mobility of neighbor nodes is different. The resistance of clustering scheme in contrast to network dynamics can be represented with this metric.
Number of clusters. The number of partitions after executing the clustering algorithm in a network is known as the number of clusters. The number of clusters has a strong effect on the cluster size. Increasing the number of nodes in a cluster (cluster size increase) raises the issues like latency, channel access scheduling, energy consumption, complexity, contention, and so on.
Re-affiliation rate. The frequency a mobile node changes its CH per unit time is known as re-affiliation rate. The ordinary nodes join the nearest CH. The node re-affiliation with another CH takes place when the current CH quits its role or it cannot be connected to its CH any more. The cluster lifetime is inversely proportional to the re-affiliation rate.
Control overhead. The number of message exchanges during the cluster formation process is control overhead. The number of control messages sent per second is used to measure this metric.
Number of clusters
In this section, experiments are conducted to evaluate the number of clusters when the number of nodes is increased from 50 to 500. The number of nodes is increased with 50 increment step. The nodes in the network are free to move in any direction with the random waypoint mobility model. The simulation area is of size 1000 m × 1000 m. The mobile nodes move on speed 70 km/h at maximum. The transmission range of each mobile node is set to 100 m. The results in the form of a graph are shown in Figure 1. The curves show the average number of clusters (or CHs) against the network size (i.e. the total nodes in the network). The graph clearly shows that the number of clusters increases as the number of nodes increases in all algorithms. Matching the curves shown in Figure 1, we notice that MobHiD has the poorest performance, and the number of clusters formed by EMPSO is slightly reduced than that of MobHiD. As discussed in the literature section of this article, these algorithms do not give importance to reduce the number of clusters in the network. The results show that HBAC algorithm outperforms other clustering schemes under consideration.
Average number of clusters versus network size (trx range 100 m).
The performance of DGAC is better after HBAC. The same experiments are repeated for the radio transmission range of 200 m and the results obtained are shown in Figure 2. As shown in the graph, the number of clusters decreases significantly with high transmission range. This shows that a CH can cover a larger area and a large number of nodes when the transmission range is high. In this way, the larger networks can be covered by a small number of CHs and thus the size of the backbone network will be reduced. Comparing the graphs shown in Figure 2, we find that the score given in Figure 2 for the clustering schemes remains unchanged here and the proposed method outperforms the others and MobHiD forms the maximum number of clusters.

Average number of clusters versus network size (trx range 200 m).
Cluster lifetime
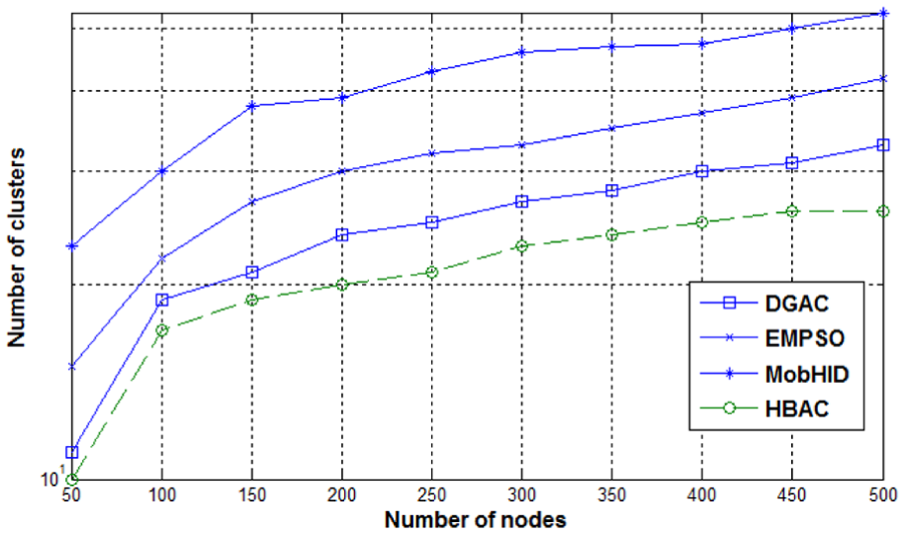
The impact of node speed on cluster lifetime is studied in this metric. The lifetime of the cluster will be decreased when the node’s mobility is high. The simulation experiment conducted in this section assumes 50 mobile nodes with a transmission range 200 m. Node speed varies from 1 to 80 km/h. The average lifetime of the cluster is measured in seconds. The results obtained during simulation are presented in Figure 3. In terms of cluster stability, the proposed cluster formation scheme is more superior over the others as shown in the curves depicted in Figure 3. The constant mobility characteristics are assumed in some papers cited in section “Related work.” In these algorithms, the long-term mobility behavior of network nodes cannot be predicted pragmatically. In HBAC, the member nodes stay linked to the CH for a long time. This is due to the reason that the relative mobility of mobile nodes is considered, before the cluster headset selection and a node with high stability is the best candidate to become a CH.
Node speed versus cluster duration (trx range 200 m).
By comparing the curves displayed in Figure 3, we find that MobHiD gaps far after HBAC, and DGAC is graded below MobHiD. EMPSO outperforms DGAC and so it is ranked worse than MobHiD. Consequently, the clusters formed by DGAC have the lowermost stability against the node speed. The reason behind it is DGAC does not consider the node mobility metric of the node during the cluster formation process. As shown in Figure 4, we increased the transmission range to 300 m and keep other things same (as in Figure 3) and presented the obtained results to evaluate the effects of the radio transmission range on the cluster lifetime. The results demonstrate that the cluster lifetime is significantly increased when we increase the transmission range. The CH neighbors stay within the neighborhood for a longer time when we increase the radio transmission range of the CH and this prolongs the lifetime of the cluster.

Node speed versus cluster duration (trx range 300 m).
Re-affiliation rate
A series of simulation experiments are conducted and the results are presented in this section to evaluate the impact of the radio transmission range and node mobility speed on the re-affiliation rate. The number of times a mobile node leaves its CH and joins a new CH per unit time is known as re-affiliation rate.
A mobile node re-affiliates to a new cluster if the current CH leaves its role or the node cannot stay connected to its CH any longer. The increase in the re-affiliation rate is probable with high-speed mobile nodes due to the fact that mobile nodes leave their clusters more rapidly as the node speed increases. In these experiments, the mobility model assumed is the random waypoint, the number of mobile nodes deployed in 1000 m × 1000 m simulation area is 50, and the transmission range of each mobile node is 200 m.
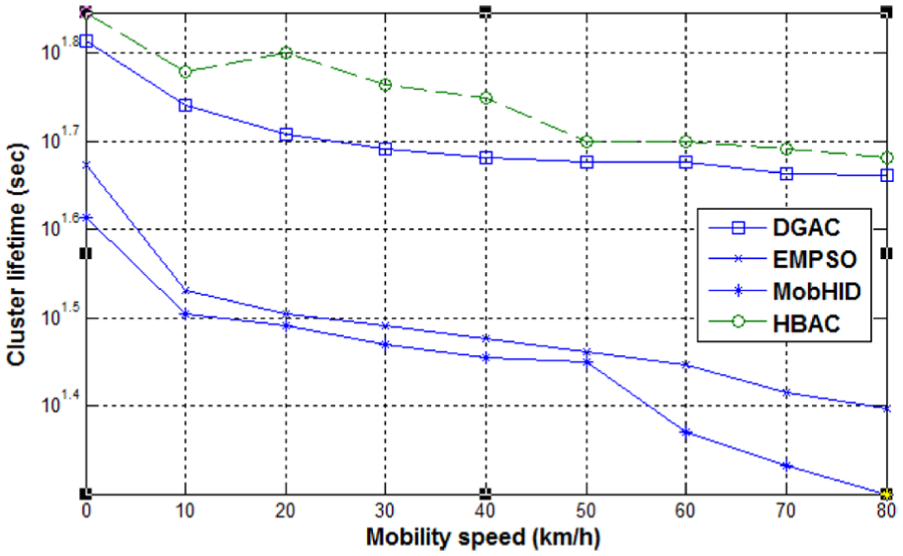
The node speed changes from 1 to 80 km/h to measure the average re-affiliation rate. In Figure 5, the average re-affiliation rate with different node speeds is presented. As shown in curves, the re-affiliation rate increases with high mobility in all schemes. The HBAC has the lowest re-affiliation rate among all other schemes as shown in the graph. The results obtained for cluster lifetime also indicate that our algorithm could perform well. The reason behind this improvement is that, in our algorithm, the CHs are selected based on relative mobility and some other important metrics. Hence, the lifetime of the CH increases and the member nodes leave the current cluster at a very low rate. The MobHiD has also lowered the re-affiliation rate after HBAC as the CHs in MobHiD are also selected based on relative mobility. So, MobHiD is best among existing algorithms and the probability of re-affiliation decreases as the node that stay connected to its neighbors for a long time is selected as CH. DGAC has the maximum re-affiliation rate among all other schemes. The relative mobility was not taken into account during the CH selection in DGAC. Hence, non-stable clusters are formed. We also study the impact of radio transmission range on re-affiliation rate and the results are presented in Figure 6. The transmission range is enlarged from 100 to 400 m with increment step 50 and the mobile node speed assumed is 40 km/h. The curves in Figure 6 show that the re-affiliation rate of all schemes is high when the transmission range is low and it decreases when the transmission range becomes high. The CHs with a high transmission range have the highest connectivity, and the re-affiliation rate becomes low because the node rarely finds to join another CH. The graph in Figure 6 shows that HBAC outperforms existing algorithms in terms of the re-affiliation rate for all radio transmission ranges. The CH selection is based on multiple metrics, including relative mobility, and thus forms stable clusters.

Re-affiliation rate with different speeds.
Re-affiliation rate versus radio transmission range.
Control message overhead
The number of messages transmitted per second during the cluster formation process is known as control overhead. The clustering algorithm requires a number of message exchanges to form clusters in MANETs. In this section, the results of the experiments conducted for observing the message exchanges during cluster formation are presented. The results obtained are compared with DGAC, MobHiD, and EMPSO.
In this group of simulation tests, 50 mobile nodes are deployed randomly inside the simulation area of size 1000 m × 1000 m. The nodes move with the random waypoint mobility model. Initially, the transmission range of mobile nodes is set to 200 m. The node speed increases from 10 to 80 km/h with a step 10. The same experiments are repeated for the higher transmission range, that is, 300 m. The results obtained during simulation are shown in Figures 7 and 8. The worst algorithm compared to others in terms of control overhead is MobHiD as shown in the graphs. It can be seen from the results obtained during simulation that in all schemes, the control message overhead increases as the node mobility increases. The control overhead decreases when we increase the radio transmission range at the cost of more energy consumption. The re-affiliation rate of node decreases and cluster lifetime increases when we increase the transmission range. Therefore, in our algorithm, the remaining energy of nodes is considered during CH selection. The curves depicted in Figures 7 and 8 show that HBAC and MobHiD have the lowest and highest control message overhead, respectively. The outperformance of HBAC is stated as follows. The HBAC has the lowest re-affiliation rate and maximum cluster life as compared to other schemes. Thus, the HBAC has the lowest re-clustering rate and forms the most stable clusters. The decrease in the re-clustering rate reduces the control message overhead rate.
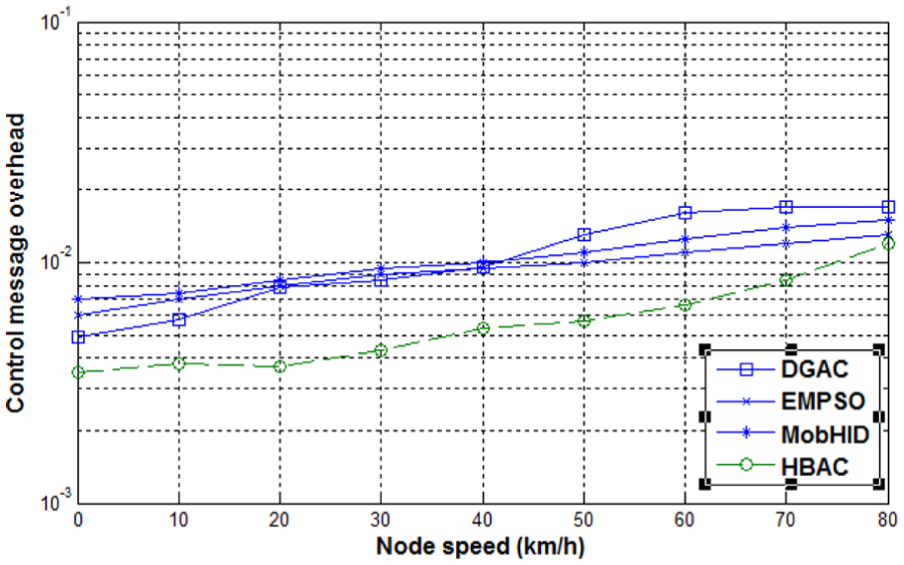
Node speed versus control overhead (trx range 200 m).

Node speed versus control overhead (trx range 300 m).
Computational overhead
In this test (Figure 9), we calculated the total number of statements per second with increasing number of nodes and for several values of communication ranges when the maximum node speed is at 50 km/h. Once more with greater values of communication range, neighborhood congurations are getting lengthier and therefore neighborhood associations are taking slower to execute. Similar outcome is also detected when the number of nodes is increasing subsequently and neighborhoods may contain a vast number of nodes. Moreover, when the number of nodes is increasing, re-clustering events are more often. Consequently, the number of nodes moving on the territory is a monotonically increasing function of the number of statements executed per second.

Number of nodes versus number of instructions with a transmission range 100 m.
Conclusion and future work
In this article, honey bee algorithm is used for optimal cluster formation and routing data to the destination. The foraging behavior of honey bee is used to form the clusters in an efficient manner. Simulation has been performed for different scenarios like different mobility models, different node movement speeds, and a different size network. HBAC gives the maximum throughput when the mobility model is either random waypoint or group mobility. Similarly, the HBAC has better performance results when we scale the network. The walking mobility of 1 m/s, running mobility of 5 m/s, and vehicle mobility of 10 m/s are used for simulation. The HBAC has very good results when the speed of the nodes is high. Similarly, the average end to end delay is also compared with other protocols. The HBAC has good results. The protocols used for comparison are DGAC, 25 EMPSO, 26 and MobHiD. 27 The proposed protocol has a maximum throughput as compared to these three protocols.
In the future, the foraging behavior of honey bee will be applied to the vehicular ad hoc network. This study gives a strong indication that it is also suitable for vehicular networks because the results show that in high-speed networks, the honey bee algorithm outperforms as compared to existing schemes.
Footnotes
Academic Editor: Sergio Toral
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.