
Abstract
Integration of industrial control network and normal office network makes Ethernet to be widely used in industrial control. The improvement of industrial Ethernet service quality has become a hot research topic because the traditional Ethernet does not optimize the performance for industrial use. The main ideas related to research results are improving the link layer protocols or the scheduling algorithms. The method of improving scheduling algorithm is more suitable for integration of industrial and office network because it does not need to modify the link layer protocol, and it can easily realize the compatibility between office network and industrial network. The size-based scheduling proves to be effective for improving the forwarding performance of small packets (such as industrial packets). One of the newest research results of size-based scheduling is least attained recent service. Least attained recent service optimizes the queuing algorithm by applying historical accumulation factor and decay cycle factor. Least attained recent service improves the forwarding performance of small data flows significantly in data link access. But the application of the two factors in least attained recent service also results in the problem of high memory occupancy rate and unstable performance. We analyzed the cause of least attained recent service problems and designed a classification-based size-based scheduling algorithm according to the quality-of-service requirements of office and industrial networks integration. The tests prove that classification-based size-based scheduling algorithm, which can keep basic characteristics of size-based scheduling algorithm, reduce the memory consumption, and provide more stable forwarding performance than traditional least attained recent service, is an effective algorithm that can provide quality of service in the industrial network and office network integration applications.
Introduction
Demand of information integration between industrial control network and normal office network (industry 4.0 or Internet of things) makes industrial information technology become more and more open. Many traditional information technologies are applied in industrial control system. Ethernet, which has the advantages of high bandwidth and flexible networking, has become the most widely used technology in office network. These advantages of Ethernet received attention from the field of industrial control, and many enterprises and scholars tried to apply Ethernet to industrial control network. 1 The application of Ethernet technology in industrial control network will make it easier to achieve office network and industrial network integration and adapt to the needs of the development of the future.
Ethernet has some inherent features that are not fit to be used in industrial control network, such as using free competition method to allocate the bandwidth, using the IP in network layer, and no connection. These features make it difficult for Ethernet to provide good quality of service (QoS) for industrial use. Many scholars tried to improve Ethernet and enable it to meet the needs of the industrial use. Major methods to improve the performance of industrial Ethernet are to improve the protocol or the scheduling algorithm. Most of the protocol improvement researches mainly aimed at modifying the link layer protocol.2,3 This approach can effectively overcome the shortcomings of the traditional Ethernet, but may also cause compatibility problems in integrating with office network. Scheduling algorithm improvement research focuses on packet queuing or request response queuing optimization, not related to a specific protocol. So, this method does not cause incompatible problems. Therefore, the scheduling algorithm improvement is more suitable for network optimization in office network and industrial control network integration.
There has been some research about using scheduling algorithms to improve network performance, such as custom queuing (CQ) and weighted fair queuing (WFQ). But these algorithms usually take fixed strategies, resulting in poor dynamic adaptability. Many research works take adaptive and effective data transmission as the research goal.4,5 In recent years, the size-based scheduling algorithm has been a hotspot of research on scheduling algorithm optimization. The goal of size-based scheduling algorithm is to provide fair service opportunity for all jobs 6 (such as network data flows). This characteristic makes size-based scheduling helpful for improving the forwarding performance of small data flows, and data flows in the industrial control network are always short. It means that the industrial control data can get better QoS in the network which runs size-based algorithm. In addition, the objective function of the size-based scheduling algorithm also makes it have good dynamic adaptability. As with other scheduling algorithms, the size-based scheduling algorithm has no limit on which protocol layer to run. But according to the requirements of industrial network information integration, the most suitable operating protocol layer is the network layer. That is, using the size-based scheduling algorithm to optimize the router’s packet waiting queue scheduling. Therefore, the router running the size-based scheduling algorithm in the real application will be between the office network and the control network, responsible for data transfer between the two networks. Routers will use “fair forwarding” feature of the size-based scheduling algorithm to provide QoS guarantee for the data transmission between the two networks.
After a study, it was found that the size-based scheduling has the faults of high memory occupancy rate and high algorithm complexity. These problems also have bad influence on the stability of the forwarding performance, or even reduce the forwarding performance. These problems make the application of size-based scheduling algorithms mostly limited to end systems or access-level networks. If these problems are overcome, the size-based scheduling algorithm will be well applied in the industrial network information integration and other multi-service networks. Aiming at these problems, this article proposes an improved size-based scheduling algorithm based on data packet classification to make such algorithms can be applied in the convergence layer or higher level networks and to provide better network service for industrial network.
The main contributions of this article are as follows: (1) the least attained recent service (LARS) algorithm is studied in detail, and the existing problems of the LARS algorithm and the reasons for these problems are clarified; (2) the classification-based size-based scheduling (CBSBS) algorithm is designed, which is combined with the LARS and packet classification, and the performance of the CBSBS is analyzed; and (3) the performance of CBSBS is tested from multiple perspectives and show that the improved size-based scheduling algorithm can be used in the convergence layer or above networks to improve the packet forwarding performance.
This article consists of six parts. Section “Introduction” gives the brief introduction. Section “Related works” introduces related research works about industrial Ethernet and packet scheduling algorithm. Section “Principle and problems of LARS algorithm” analyzes the algorithm principle of LARS and its existing problems. Section “CBSBS” introduces CBSBS algorithm and the analysis. Section “The test results and analysis” briefs the performance testing and comparison of the routers running first-in first-out (FIFO), LARS, and CBSBS under the same data conditions and the analysis of the test results. Section “Conclusion and future work” presents the conclusions and future research work.
Related works
Research on protocols
Ethernet has 40 years of development history, and its performance has been rapidly improved. The transmission bandwidth has exceeded the level of gigabit per second, and the switched Ethernet technology also solved the uncertainty problem caused by the carrier-sense multiple access with collision detection (CSMA/CD). The application of Ethernet in industrial control field has become a hot research topic in recent years. The representative research results include time-triggered Ethernet (TTE), EtherCAT, and Powerlink.
TTE is an open network protocol. In order to solve the uncertainty problem caused by the traditional event-triggered Ethernet, TTE uses the time-trigger policy to allocate network resources. H Kopetz 7 designed TTE protocol specification, including the message format, operating rules, and data frame structure. Because stations transmit data according to the preassigned time slice, the transmission delay time in TTE can be guaranteed. 8 But, however, bandwidth utilization ratio of TTE is low because of the limitation of time slice.
EtherCAT is a kind of technology that applies Ethernet in industrial control network. 9 Because the EtherCAT adopts special coding technology to carry several stations’ data in one data frame,10,11 the EtherCAT network does not need to send data to each station separately. G Prytz 12 made a performance analysis of EtherCAT and PROFINET IRT. The result shows that the EtherCAT can offer better performance than PROFINET IRT. As EtherCAT cannot use standard Ethernet equipment to build a network, it cannot integrate industrial network with the office network directly.
Powerlink is another technology aiming at industrial control application. 13 Similar to EtherCAT, Powerlink is designed for industrial control bus applications. Powerlink is very different from EtherCAT. Each Powerlink station has its own data frames, which make Powerlink’s data frame shorter, and the efficiency is slightly lower than that of EtherCAT. Powerlink adopts open protocols and standard Ethernet media access control (MAC) layer, and it makes Powerlink more compatible with standard Ethernet technology. 14 This feature also shows that core of the Powerlink is the optimization of the scheduling algorithm indeed, and its being compatible with office Ethernet has a direct relationship with this feature.
In addition, some scholars take attempts to modify switches application specific integrated circuit (ASIC) in order to improve some certain data flows’ transmission speed and flow-control mechanisms to improve the real-time performance of Ethernet. 15
To sum up, the method of improving the protocol can effectively higher Ethernet’s real-time performance, but also leads to incompatibility between improved network and standard Ethernet. The method of improving the scheduling algorithm can keep current protocols in each layer, and it will not lead to compatibility problems. The method of improving the scheduling algorithm is in favor of the integration of industrial network and office network.
Research on scheduling algorithm
The new generation of industrial technology and multi-service network, such as industry 4.0 16 or wireless sensor network (WSN), ask for deeper information integration and higher performance. The development trend puts forward new requirements for the dynamic extensible performance and service quality assurance performance. Therefore, optimizing the network performance by improving the scheduling algorithm has become an important part of the research in related fields. Reasonable data scheduling algorithms can not only enhance performance but also reduce resource overhead, therefore improving the reliability of the system. 17 Traditional static packet queue scheduling policies, such as CQ and WFQ, will be difficult to meet the requirements, so many research results are about dynamic scheduling algorithms. AM Elnaka 18 improved transmission performance on heterogeneous networks by introducing a fair and delay adaptive scheduler (FDAS) to bridge the gap and balance between fairness and delay requirements of incoming traffic flows and achieved fairness in allocating and distributing transmission bandwidth among contending flows. Y Liu and colleagues17,19 studied the multicast problem in device-to-device (D2D) and opportunistic networks and developed a distributed online algorithm based on the optimal stopping strategy, and the communication costs are effectively reduced. These research results show that scheduling algorithm optimization is an important and feasible means to optimize network performance.
Size-based scheduling algorithm has been a research hotspot in dynamic packet queue scheduling algorithm in recent years. Size-based scheduling is a kind of priority scheduling algorithm based on the size of the data. The algorithm has been used for network performance optimization since 2000. The representative algorithms include shortest remaining processing time (SRPT), least attained service (LAS), and LARS. The goal of size-based scheduling is to provide fair transmitting opportunities for all network data flows. It makes size-based scheduling helpful for improving the forwarding performance of small packets, while packet lengths in industrial network are always shorter than those in office network.
M Harchol-Balter et al. 20 used SRPT to reduce the reaction delay time of Web server successfully. IA Rai 21 tried to use LAS to improve the performance of short transmission control protocol (TCP) flows and designed a special dropping policy, and the test result showed that the transmission time and loss rate of short TCP packets were reduced significantly. Ferrero and Urvoy-Keller 22 improved the fairness of data flow transmission in wireless local area network (WLAN) using LAS.
A Sivaraman designed the push-in first-out (PIFO) architecture. A variety of scheduling algorithms (included the size-based scheduling) were built into Ethernet switch without changing the hardware. The PIFO can provide line-rate forwarding under certain hardware conditions. 23
Except for network performance optimization, the size-based scheduling algorithm has been used for system performance optimization. M Dell Amico studied the size-based scheduling algorithm in application of job scheduling in computer system. They analyzed the amount uncertainty problem of size-based scheduling algorithm and designed the practical size–based scheduler (PSBS) on the basis of fair sojourn protocol (FSP). The experiment shows that the performance of PSBS has improved significantly than FSP. 24
Mario Pastorelli applied the size-based scheduling algorithm to Hadoop and designed the Hadoop fair sojourn protocol (HFSP) scheduling algorithm. The tests showed that the system running HFSP reduced the average response time significantly, and the algorithm showed good robustness performance. 25
One of the newest research results in size-based scheduling is LARS. The LARS is a network forwarding scheduling algorithm which is derived from LAS, 26 and it improves the LAS “service hunger” faults and makes forwarding resource allocation more reasonable. These improvements make LARS more suitable for QoS in industrial and office integration network environment than other size-based scheduling algorithms. M Heusse et al. 27 improved the data transmitting performance of a wireless access point (AP) by LARS. The test results show that LARS can schedule more fairly than LAS and self-clocked fair queuing (SCFQ) scheduler.
But LARS still has some significant shortcomings. LARS’ queuing priority is determined by the decay value of a data flow, which is a historical accumulative value, 28 and the forwarding node (switch or router) has to allocate a lot of resources to store and calculate each data flow’s decay value because the number of data flows is always great in real network. A great number of decay values take up a lot of memory and reduce data processing efficiency and the forwarding performance as well. J Chen et al. 29 constructed a scheduler using early flow discard (EFD) to solve the problem of high memory occupancy rate of LARS algorithm and improved the service quality by controlling the corresponding time of each data flow. Therefore, a key to improving LARS algorithm is to find a method that can reduce the computing complexity while keeping the advantages of LARS.
Principle and problems of LARS algorithm
Basic principle of LARS algorithm
LARS scheduling algorithm counts each data flow’s forwarding volume (attained service) and uses it as a data packet on priority judging basis in the waiting queue. Its formula is

LARS uses the forwarding volume of a data flow as the priority criteria. The greater the forwarding volume is the lower the queuing priority is. This is the main reason why LARS is suitable to improve the QoS of small data flows in the multi-service network. LARS features and its comparison with FIFO are shown in Figure 1.

Features difference between (a) FIFO, (b) LAS, and (c) LARS.
Problem analysis of LARS
It is clear from above that LARS is a priority queue algorithm based on services statistics, and it is greatly different from traditional algorithm such as FIFO and WFQ. Traditional algorithm usually uses fixed queuing rules, while LARS algorithm’s queuing rule has been constantly adjusted. This feature means LARS may consume more computing resources and bring some problems. The more complex the network environment is, the more serious the problems are. So, the existing research seldom applied the size-based scheduling algorithm to the backbone links.
Too large memory consumption problem
The dynamic queue priority judging of LARS algorithm is based on a certain data flow’s decay value, which is a historical accumulation value. It means that the transmitting nodes (such as routers) have to record each data flow’s decay value. Distinguishing packets from different data flow needs to pick data packet source address, source port, destination address, and destination port for identification, and it will take up a lot of memory. The more complex the network is, the greater the memory consumption is.
Additional time delay problem caused by decay value processing
The corresponding decay values need to be found and dealt with before a packet is inserted into the queue. The excessive memory occupation of the decay value table will lower the value extraction efficiency and longer the data transmission time.
Abnormal delay time jitter rate is higher
A detail need to be mentioned is that a data flow whose decay value is not recorded will have the highest priority because its decay value is deemed to be zero. A new data flow’s long packet can get the highest queuing priority, which means that the forwarding port will be occupied for a long time, and other data packets forwarding time will be extended. The more complex the network is, the higher the possibility of this situation is. This situation goes against the QoS of delay-sensitive data flows.
CBSBS
The analysis above shows that the biggest difficulty of implementing the LARS algorithm is the complexity of the decay value processing and the queuing algorithm. Reducing the record number of LARS decay value can reduce the memory cost and raise the processing efficiency.
Reducing the decay value table means that the LARS algorithm will not involve all the data flows, and doing so does not mean that the performance of LARS will be changed. The main reason is that most data flows such as the normal hypertext transfer protocol (HTTP), file transfer protocol (FTP) data flows, and peer-to-peer (P2P) download data flows are not so sensitive to delay time. When these data are no longer involved in the computing process, LARS computing cost will be dropped significantly. The improved algorithm is CBSBS.
Packet classification
According to the different requirements on the time delay performance, data packets can be divided into three classes:
Class A. Low time–sensitive data flows (such as HTTP and FTP).
Class B. Delay-sensitive data flows (such as packets from WSN sensor).
Class C. Sequential-sensitive data flows (such as control signal packets).
Class A data flows have a high tolerance for delay time, which means these packets do not need to participate in CBSBS, and they can be put into the low-priority queue (FIFO queue) directly without calculating the decay values.
The other two kinds of data flows need to be processed by CBSBS. Packets of Class B data flows are put into CBSBS queue after being calculated their decay values. Class B and Class C data will take LARS algorithm for scheduling policy. Class C data flows need to be assigned the highest priority because the control information plays an important role in the industrial network, so decay values of these kinds of packets will not be calculated (their values keep zero) to make sure they will get the highest queuing priority. The process is shown in Figure 2.
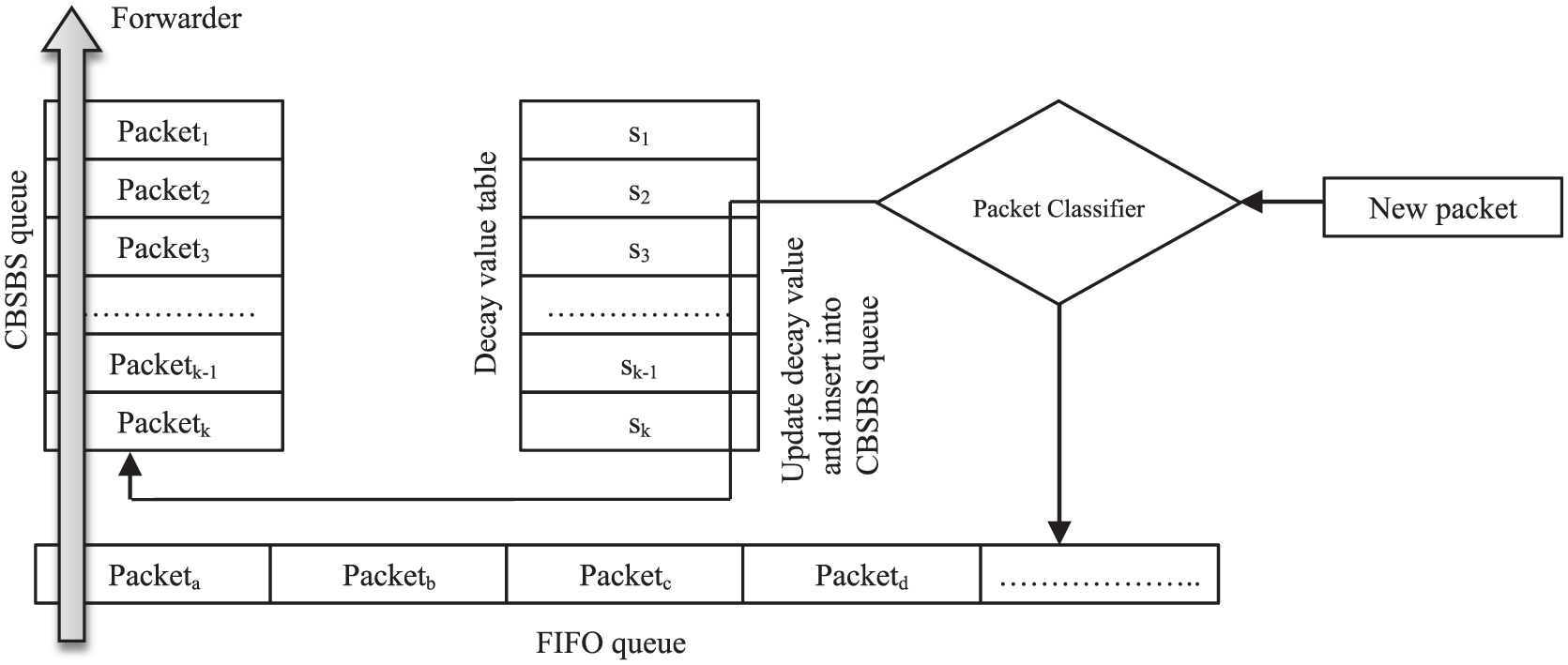
Running framework of CBSBS.
The framework consists of classifiers, FIFO queue (low-priority queue), CBSBS queue, and forwarder. The main function of the classifier is to classify the packets and put the Class A packets into the low-priority queue and put the other two types of data into the CBSBS queue. The function of the FIFO is very simple; it uses the FIFO strategy to forward the data packets to the forwarder. The CBSBS queue needs to manage the decay value table that records the decay values of all data flows, and the packets are queued by priority based on the decay of the data flow. The forwarder is responsible for forwarding the packets. It will first attempt to forward the packets in CBSBS queue. If the CBSBS queue is empty, it attempts to forward the packets in the FIFO queue. Therefore, the performance-sensitive packets will get better forwarding performance.
Operation process of CBSBS
Processing procedure and features
When receiving a new data packet, the forwarding node (router) will put it into the packet classifier to make sure which class the packet belongs to. Packets belonging to Class A are usually much bigger than those belonging to Class B and C, so distinguishing the packet classification according to the size of the data packet is a simple and effective method. This article takes the method of setting a packet length threshold value in the classifier for the preliminary filtering. The low-priority data packets (longer than the threshold) can be filtered out and sent to the low-priority queue (FIFO queue). The other data packets (shorter than the threshold) will be treated as Class B or C data flow and put into CBSBS queue.
As mentioned above, this article takes the policy of not calculating decay values for Class C packets. These packets will be put to the head of the CBSBS queue directly if there is no other Class C packet in the queue. Data volume of Class B and C is always few in total data flows, and the low-priority queue will not have “service hunger” problem.
CBSBS pseudocode description
CBSBS algorithm is mainly composed of three main parts. The three parts are data classification, the decay value extraction and update, and scheduling and forwarding.
Data classification
The data classification’s function is to classify the data packets according to the threshold and put the packets into different queues according to the classification results. The pseudocode is as follows.

Decay value extraction and update
The main function of this part is to extract and update the corresponding decay value of the data flow. The pseudocode is as follows.

Scheduling and forwarding
This is the core part of CBSBS. Its first function is to insert the packet into the waiting queue by the priority (decay value). Its second function is to pick and forward packets according to the CBSBS rules. The pseudocode is as follows.

Performance analysis in FIFO, traditional LARS, and CBSBS
Delay time in FIFO and LARS
In FIFO scheduling algorithm, the delay time mainly depends on the speed of data generation, router’s processing capacity, and the size of the current packet. The delay time in FIFO is as shown in formula (2)

LARS uses the decay values as the queuing priority; therefore, the processing delay time is multiplication of the processing delay time and a data volume ratio. In addition, case of the port being occupied by a packet will also increase the delay time. Therefore, the time of LARS is as shown in formula (3)
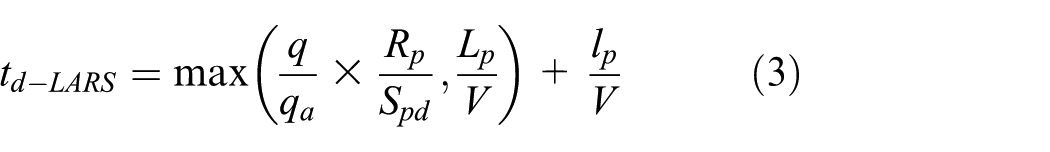
LARS uses u and t to calculate the decay value. The expectation value of decay value is proportional to the amount of data, so the formulas use data volume to replace the decay value.
Delay time in CBSBS
In CBSBS, Class A forwarding delay will increase due to the data packet classification, and the increasing volume depends on the data amount of Class B and Class C. The delay time of Class A is as shown in formula (4)

The delay time of Class B is commonly smaller than that of traditional LARS. This is because the

where
Decay value of Class C value is constantly zero, and similar data packets take the FIFO queue rules, so the time delay of Class C is as shown in formula (6). The forwarding performance in CBSBS will be significantly higher than that in traditional LARS because of the low Class C data volume ratio

where
Although CBSBS did not completely solve the unstable performance problem caused by forwarding port contention. But situation of a long Class A packet taking up the forwarding port is greatly reduced in CBSBS because the classification makes the Class A long packets cannot get high queuing priority. So, the forwarding performance stability of CBSBS is much better than that of LARS.
The test results and analysis
Network topology
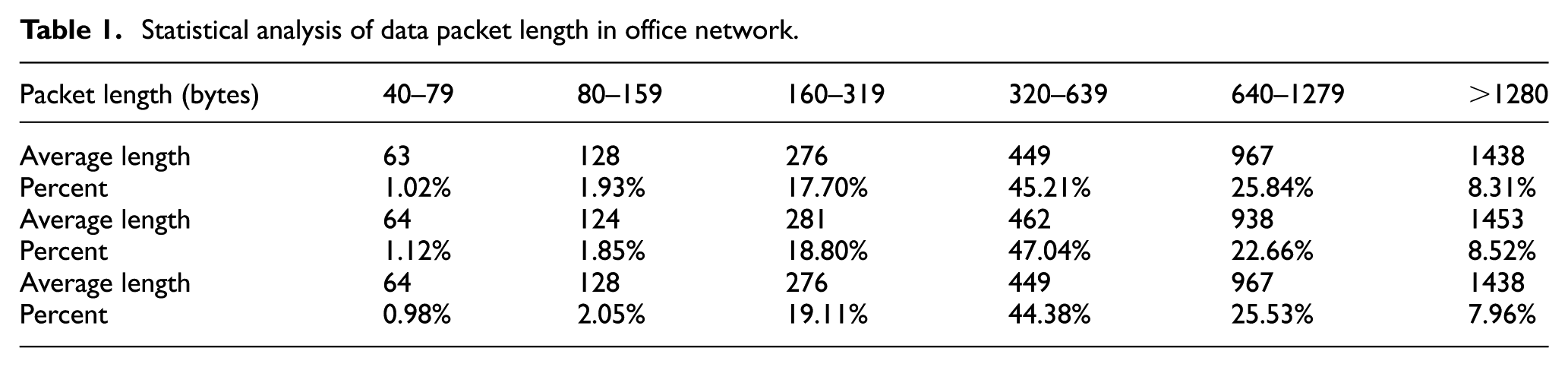
Test simulation network topology is shown in Figure 3. The three routers run FIFO, traditional LARS, and CBSBS scheduling algorithm. Three kinds of data generators on the left side of the router are used to generate three kinds of data packets. Three identical copies of the data from the source code will be generated and sent to the three routers. The three destination networks on the right side of the routers are exactly the same. Time of each packet entering and leaving the router will be recorded accurately. The main purpose of doing this is to let the routers running different algorithms be able to perform comparative tests under the same condition. Table 1 shows the statistics of the packet characteristics captured in three different backbone links of a real office network. The office network data generation strategy during the testing process is based on Table 1.
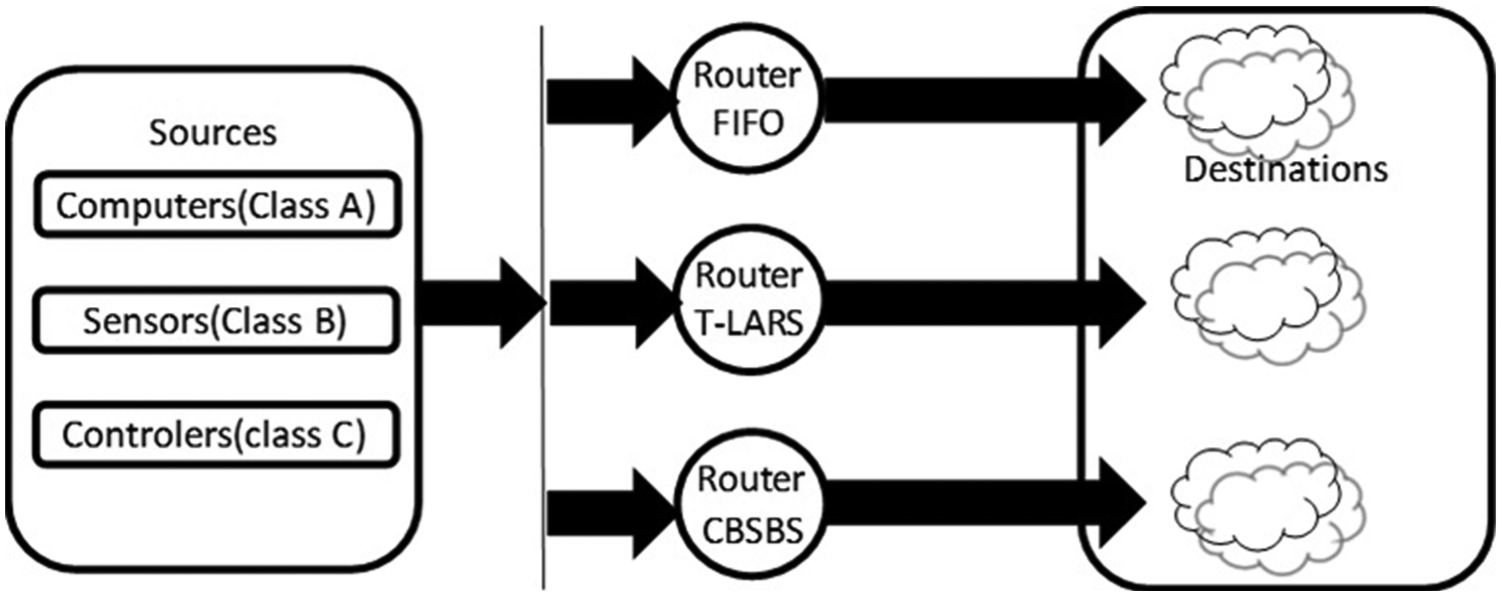
Topology of the test network.
Statistical analysis of data packet length in office network.
Factor
and
As is shown in formula (1), changing
Results and analysis
Forwarding performance test results and analysis of Class A packets
Figure 4 shows the performance comparison of Class A data flows in condition of small data load. The abscissa is the serial number for the data packet, ordinate of a packet forwarding time delay value. In order to improve the figure’s readability, this article makes a sample of the original data source.

Class A data flow delay time statistics of CBSBS, traditional LARS, and FIFO in condition of small amount of data.
Under these conditions, Class A forwarding performance of CBSBS is similar to that of FIFO. Figure 4 also shows that the delay time jitter of traditional LARS is slightly larger than those of the other two scheduling algorithms. The variance of FIFO and CBSBS are both 17.2, while the variance of T-LARS reached 19.9. The main reason is that in condition of large number of data flows, the probability of long packets obtaining the highest priority increases.
Figure 5 shows the test results in case of data volume three times greater than that in Figure 4. It needs to be mentioned that because injection speed is higher than the router forwarding ability and the routers did not adopt congestion control, the delay time showed a trend of increasing gradually.

Class A data flow delay time statistics of CBSBS, traditional LARS, and FIFO in condition of large amount of data.
Under this condition, CBSBS and FIFO still have similar forwarding performance. The performance fluctuations of traditional LARS increase significantly, despite its average delay time is shorter than FIFO’s.
The results show that CBSBS can keep the forwarding performance of Class A packets while improving the performance of the other two types of packets. Although Class A packets are not sensitive to time delay performance, there is no doubt that such performance is good for the QoS of the network. Therefore, performance of CBSBS is superior to that of the traditional LARS.
Forwarding performance test results and analysis of Class B packets
Figure 6 shows the forwarding performance of Class B data under the condition that the amount of data in the network is low. In order to ensure the readability, Figure 6 takes a similar sampling process as in Figure 4.

Class B data flow delay time statistics of CBSBS, traditional LARS, and FIFO in condition of small amount of data.
According to test results in Figure 6, performance of CBSBS is superior to that of traditional LARS and FIFO because the small data flows will always get higher forwarding priority in CBSBS. In most cases, the performance of traditional LARS is slightly better than that of the FIFO. But at some point, traditional LARS forwarding delay time may have a bigger jitter. At this time, the variance of CBSBS is 11.3, and the variance of FIFO and T-LARS are 15.8 and 16.9, respectively. The main cause of the jitter is that the traditional LARS involved all data flows, and the possibility of send port being occupied by a big packet increases greatly.
Figure 7 shows the test results in case of data volume three times greater than that in Figure 6. The test results show that the CBSBS obtained better forwarding performance than the other two scheduling algorithms with its optimized queuing policy in condition of large amount of injected data.
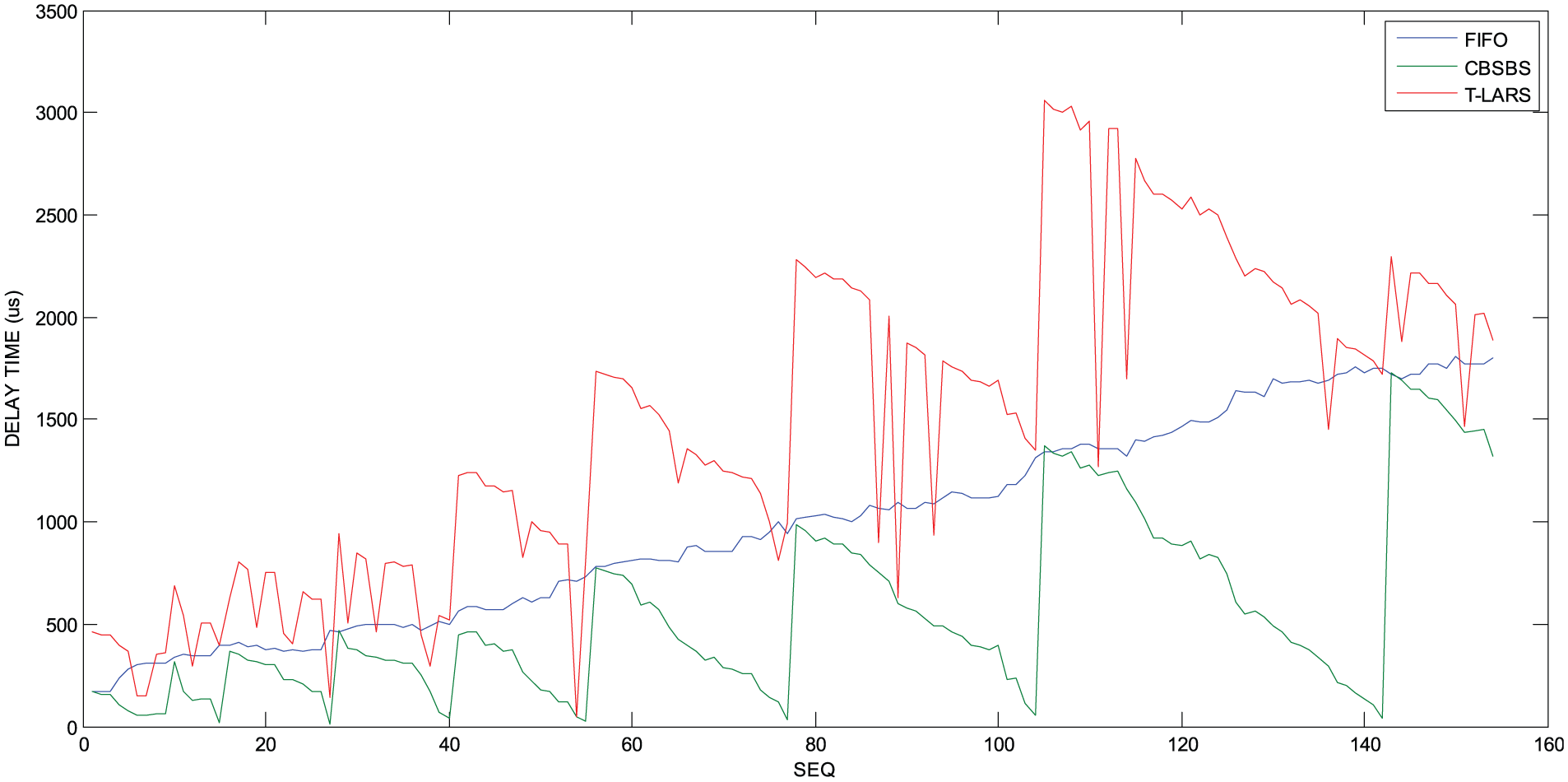
Class B data flow delay time statistics of CBSBS, traditional LARS, and FIFO in condition of large amount of data.
Forwarding performance test results and analysis of Class C packets
The result in Figures 8 and 9 is similar to that of Class B forwarding test in Figures 6 and 7. The Class C packet can always get better forwarding performance in CBSBS than in other two scheduling algorithms. In the result data of Figure 8, the variance of CBSBS is 8.2, and the variance of FIFO and T-LARS are 17.0 and 15.4, respectively. The result shows that the delay time jitter is reduced significantly in CBSBS than in traditional LARS. The results in Figure 9 also demonstrate that CBSBS has better stability than traditional LARS.
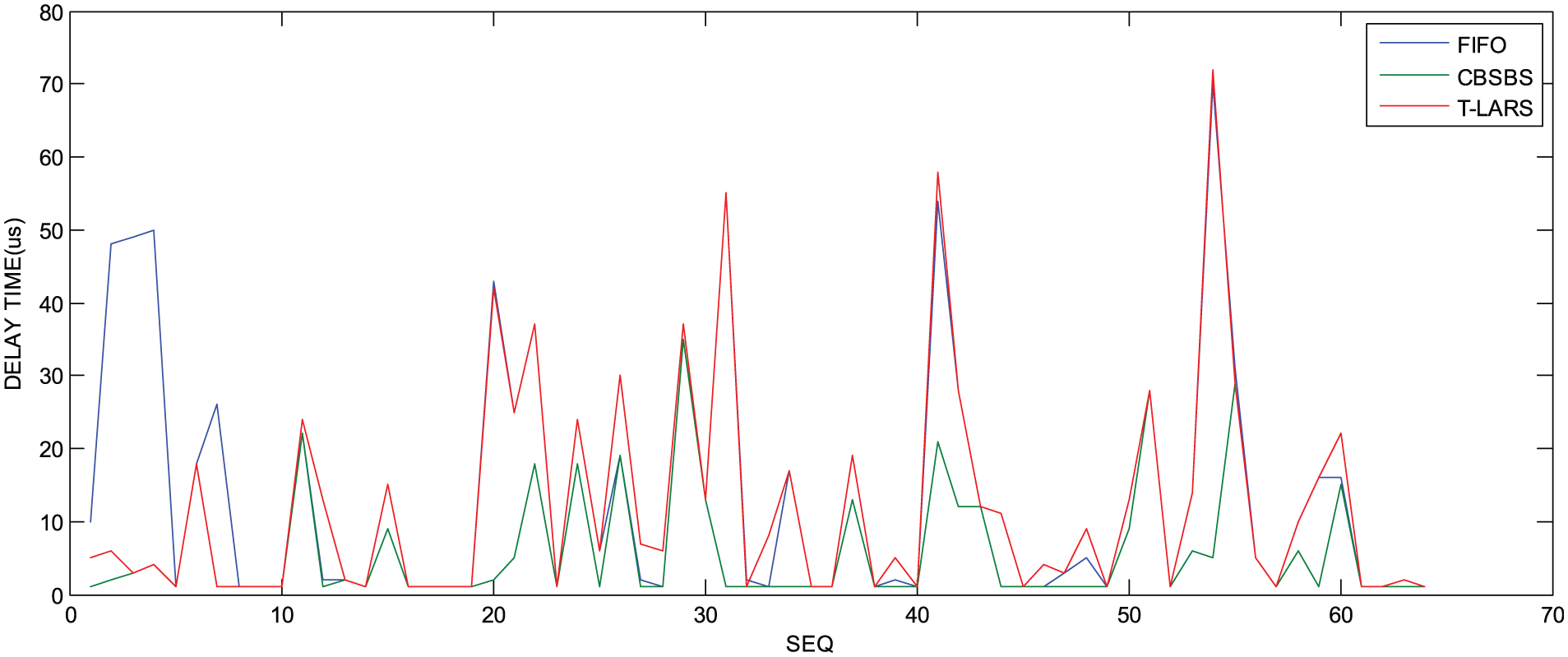
Class C data flow delay time statistics of CBSBS, traditional LARS, and FIFO in condition of small amount of data.

Class C data flow delay time statistics of CBSBS, traditional LARS, and FIFO in condition of large amount of data.
Test results in Figures 7 and 9 also show that excessive resource costs of LARS will significantly reduce the forwarding performance in the complex network environment if the router’s performance is limited. The performance of the traditional LARS is even worse than FIFO, and CBSBS solved the problems very well.
The size of the decay value table
Figure 10 shows the comparison of size of decay value table of CBSBS and traditional LARS. The results show that the size of CBSBS value table size can be maintained in a small range, while the size of traditional LARS value table is expanding rapidly. The traditional LARS needs to record all the data flows’ decay values; the longer the router works, the bigger the amount of data flows is. Thus, the decay value table of traditional LARS will become bigger and bigger. While CBSBS only involves part of the data flows, its memory usage is controllable.

Number of decay values.
Deploy CBSBS in the network
Deploying CBSBS in the network can be flexible. Just make sure that CBSBS can cover all the backbone links that carry key applications. In the industrial network and office network integration environment, deployment of CBSBS can be shown in Figure 11. The left side of the firewall is the industrial network, and this part of the network can be considered to have set the performance optimization strategy. The right side of router A is the office network. The firewall and router A are responsible for the connection and security between the two networks. In order to ensure that CBSBS can serve the key applications, the firewall and all the backbone routers (such as router B and router C) in office network at the right side need to run CBSBS.
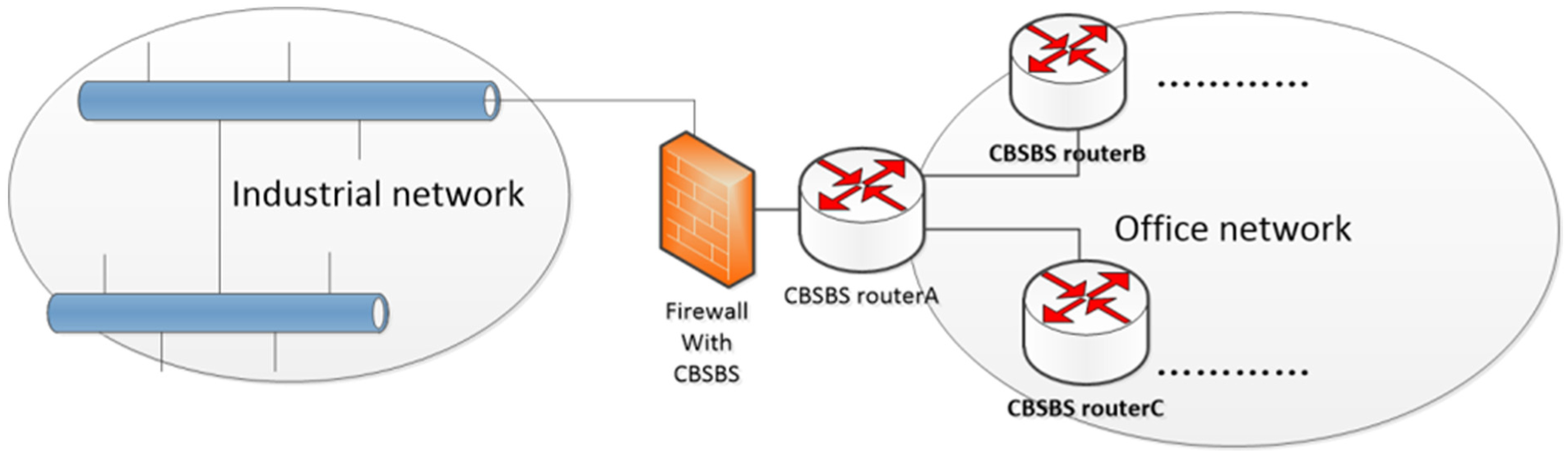
Deploy CBSBS in the industrial network.
Conclusion and future work
CBSBS can effectively improve the forwarding performance of small data flows. CBSBS can provide better performance for packets Class B and C than traditional LARS, and those packets can get through the router in shorter time. The traditional LARS shows the high abnormal delay time jitter rate problem in condition of large amount of data. The rate is much lowered by CBSBS, which means that the delay time is more controllable in CBSBS. Decay value table of CBSBS is smaller than that of traditional LARS. The reduced decay value table can lower the memory usage and improve the processing efficiency. At the same time, CBSBS algorithm makes the forwarding delay time of Class A data flows more stable and does not increase the average delay time significantly. The test result also shows that the traditional LARS’ performance is not good in the router because of the complexity of the data flow types, and the classification of CBSBS can solve the problem very well. In addition, CBSBS’ multi-level queues can make the forwarding device prioritize low-priority data in the event of congestion, which makes the data transmission of key applications in the network more reliable. This improvement makes the size-based scheduling algorithm, except can be used in the access link, can be used in backbone links, such as the integration of industrial and office network.
The CBSBS still shows some problems in the test results. There is still delay time jitter during the transmission which is unfavorable for the performance of industrial network. According to the analysis in section “Operation process of CBSBS,” the main reason of the problem is the conflict in the sending port. The conflict is associated with the allocation of the port sending resource and also with the priority rules of the CBSBS. In addition, the existing size-based scheduling algorithm can optimize the transmission performance of small data flows and performance of some delay-sensitive big data flows (such as voice over Internet protocol (VOIP) packets) will be adversely affected. The main reason for this problem is that CBSBS, like LARS, only uses the attained service as the scheduling priority calculation basis. This approach makes it difficult to objectively reflect the different requirements for network performance of different types of data flows. This problem will reduce the adaptive performance of size-based scheduling algorithm. In addition, CBSBS does not solve the defect of size-based scheduling algorithm amplifying the distributed denial-of-service (DDoS) attacks which has limited the use of size-based scheduling. We will continue the research to solve these problems in the future.
Footnotes
Acknowledgements
The authors thank Wang BingShu, professor of North China Electric Power University, for his academic and constructive advice in the process of composing this paper. The authors appreciate their colleagues who helped them in the process of testing.
Academic Editor: Hongyi Wu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper was funded by the Natural Science Foundation of Hebei Province (grant no. F2016502104), the Science and Technology Project of Baoding City (grant no. 15ZG042), the Hebei Province Key Development Discipline of Computer Application in Hebei Finance University, and the Application Technology Research and Development Center of Intelligent Finance in Hebei Finance University.