
Abstract
Short-term traffic flow forecasting is a difficult yet important problem in intelligent transportation systems. Complex spatiotemporal interactions between the target road segment and other road segments can provide important information for the accurate forecasting. Meanwhile, spatiotemporal variable selection and traffic flow prediction should be solved in a unified framework such that they can benefit from each other. In this article, we propose a novel sparse hybrid genetic algorithm by introducing sparsity constraint and real encoding scheme into genetic algorithm in order to optimize short-term traffic flow prediction model based on least squares support vector regression. This method can integrate spatiotemporal variable selection, parameter selection as well as traffic flow prediction in a unified framework, indicating that the “goodness,” that is, contribution, of selected spatiotemporal variables and optimized parameters directly depends on the final traffic flow prediction accuracy. The real-world traffic flow data are collected from 24 observation sites located around the intersection of Interstate 205 and Interstate 84 in Portland, OR, USA. The experimental results show that the proposed sparse hybrid genetic algorithm-least square support vector regression prediction model can produce better performance but with much fewer spatiotemporal variables in comparison with other related models.
Keywords
Introduction
Intelligent transportation system (ITS) 1 which incorporates information and communication technology into traffic infrastructure and vehicles, has been applied to extenuate the traffic pressure, reduce fuel consumption, and improve environment quality in large cities. As an indispensable part of ITS, short-term traffic flow forecasting, defined to be predicting traffic flows at a target road site in the next time interval (usually in the range of 5–30 min), can be applied to traffic signal control, congestion alleviation, route guidance, adaptive ramp metering, and so on. For example, with the aid of reliable forecasting data, traffic managers are able to early realize the potential danger in unstable traffic condition and adopt necessary measures to ensure normal traffic operation. For travelers, they can receive the real time and dynamically estimated results about future traffic condition and make a decision on departure time or adjust travel routes before jam formation. Thus, short-term traffic forecasting has become an interesting topic and attracts more and more interests of researchers because of the significant role and wide range of applications in ITS. Nowadays, some traffic flow forecasting systems have been deployed in some ITS, 2 such as the Sydney Coordinated Adaptive Traffic System and parallel-transportation management systems.
Generally speaking, traffic flow forecasting can be regarded as a learning problem. A forecasting model is first constructed by learning the underlying variation patterns from the given historical traffic flow data and then used to forecast future situations based on real-time traffic variables. A traffic flow forecasting model generating estimation which is very consistent with actual traffic flow data is more preferable and valuable in real-world applications. Over the past decade, various traffic flow forecasting methods have been proposed. 3 Accurate and reliable traffic flow forecasting, however, is still a challenging issue because traffic system is a highly nonlinear, time-variant, stochastic, and complex system. 4
Some investigations in the literatures treat historical traffic flow for the target site as a time series process. They employ time series analysis theory to model the temporal variation of traffic flow and forecast the future trends. Some typical models include Kalman state space filtering models,5–7 autoregressive integrated moving averaging (ARIMA), 8 seasonal ARIMA (SARIMA),9,10 k-nearest neighbor, 11 ridge regression, 12 and so on. These methods mainly characterize the temporal correlation of traffic flow at a specific location and perform well when the traffic variations are relatively stable. However, traffic flow forecasting is essentially a complex, nonlinear problem 13 since the traffic flows at different locations may interact with each other. For instance, traffic flow at the target site will be intensively influenced by its adjacent sites, especially upstream traffic. Moreover, traffic flows from distant but correlated sites also have impact on the target site to a certain extent. 14 As a result, merely utilizing the limited information about the target site may be insufficient for high accurate traffic flow prediction under unstable traffic conditions and complex road settings. 3
Recently, constructing forecasting models that can incorporate information of more road locations or even the whole traffic network is increasingly drawing the attention from many researchers. Hobeika and Kim 15 used current traffic, historical average, and upstream traffic to perform short-term traffic flow prediction. Sun et al. 13 took into account the historical data from both current and upstream adjacent road segments in the Bayesian network framework. Min and Wynter 16 predicted traffic flow by considering the spatial characteristics of a road network, including the distance and the average speed of the upstream road segments. Xu et al. 17 first applied multivariate adaptive regression splines (MARS) model 18 to identify most predictive variables which are then used to construct prediction model. Kamarianakis et al. 19 divided the traffic flow into homogeneous regimes and applied l1-norm penalized regression 20 in each regime to perform estimation and model selection simultaneously. Gao et al. 21 applied graphical Lasso (least absolute shrinkage and selection operator) 22 to select the most informative variables for traffic flow prediction. These methods exploit both temporal and spatial information among multiple road sites in terms of the variation of traffic flow, thus usually leading to better performance. However, the models are relatively complex and include many parameters which are difficult to adjust.
Because the rapid process change underlying traffic flow is too complicated to be captured by a single linear statistical model, various advanced machine learning methods, such as artificial neural network (ANN) and support vector machine (SVM), have been used to learn inherent regularity from historical traffic data for traffic flow forecasting. ANN is widely used in traffic flow forecasting, especially deep learning23–25 because it is able to approximate any complex function without prior knowledge of the problem. Although ANN is a powerful nonlinear modeling tool, it has some limitations, such as the difficulty to interpret the involved black-box operations, the determination of suitable network structure including the number of hidden layers and neurons.
As a competing method, SVM 26 introduced by Vapnik and colleagues is another important machine learning method which has achieved great success in many real-world applications, including drug discovery, 27 robust regression, 28 pattern classification, 29 time series prediction, 30 and so on. In comparison with ANN, SVM has several remarkable advantages. First, it is based on structural risk minimization (SRM) principle 31 which strikes a balance between traditional empirical risk and model complexity. Second, it can be used to solve nonlinear problems by kernel trick which means the input space is first mapped into a much higher (or even infinite) dimensional feature space wherein a linear SVM model is constructed. Third, SVM boils down to a quadratic programming (QP) problem 32 which is convex and has globally optimal solution. The original SVM was developed to solve pattern classification problems. With the ε insensitive loss function introduced by Vapnik, SVM can be extended to solve nonlinear regression problems, namely, support vector regression (SVR). Furthermore, least squares SVR (LSSVR) 33 and its kernel version simplify traditional SVR by changing ε insensitive loss function into least squares loss function. In such a way, the solution of LSSVR can be found by solving a linear system of equations instead of complex QP problem, without sacrificing generalization performance. SVR and LSSVR are broadly exploited in traffic flow forecasting.34–37
Although LSSVR can well model the inherent nonlinear relationship between historical data and future data, it has two main limitations. The first one is parameter optimization problem. The forecasting performance of LSSVR varies broadly with different combination of kernel width parameter
Some works have focused on the parameter selection problem of LSSVR/SVR in traffic flow prediction. For example, Hong et al. 34 presented a short-term traffic flow forecasting model which uses continuous ant colony optimization (ACO) algorithm to adjust parameters in SVR. Zhang et al. 35 applied genetic algorithm (GA) to optimize the parameters in SVR for ship traffic flow prediction. Cong et al. 36 developed an LSSVR-based traffic flow forecasting model in which the fruit fly optimization algorithm (FOA) is applied to determine two parameters. Instead of FOA algorithm, Yusof et al. 37 used firefly algorithm (FA) to optimize the parameters of LSSVR. Overall, these works attempt to use different intelligent optimization algorithms, such as GA, 35 ACO, 34 to automatically determine suitable parameters for LSSVR/SVR.
However, the application of intelligent optimization algorithm for variable selection in the case of traffic flow forecasting is rare. Actually, variable selection is of great importance in constructing model for forecasting traffic flow data because the number of variables is generally much large, especially when simultaneously taking into account temporal and spatial information of the whole road network. For example, given a road network containing 24 sites and four time lags (i.e. four historical time points), the number of spatiotemporal variables involved in LSSVR reaches 120. Considering the topological structure of road network, the spatiotemporal variables collected at different time intervals and locations are actually closely related, thus making many variables highly correlated with each other or irrelevant with the traffic flow at the target site. It indicates that not all of these spatiotemporal variables are predictive or informative in terms of traffic flow forecasting at target site.19,21 Directly fitting an LSSVR model to the traffic data including much redundant and/or noisy information will dramatically increase the complexity of forecasting model. Consequently, it may lead to overfitting and thus influence the effectiveness of model. In addition, lacking of variable selection ability also makes the resulting forecasting model difficult to interpret in the sense that it is hard to identify which spatiotemporal variables really contribute to the traffic flow prediction for the target site.
Motivated by the above discussions, in this article, we propose a novel traffic flow forecasting model by simultaneously dealing with the parameter selection and variable selection problems of LSSVR. A sparse hybrid genetic algorithm (SHGA) is developed to achieve this goal. Specifically, we first propose a hybrid encoding scheme of the chromosome, which can encode candidate parameters and variable subset, respectively, using real numbers and binary numbers. A sparsity constraint is further imposed on the binary encoding in order to restrict the number of variables involved in LSSVR. An elaborately designed crossover and mutation strategies finely tuned for the above hybrid encoding scheme is presented to implement the evolution of population. In such a way, it is possible to find sparse optimal solution for general optimization problems. We apply the SHGA to optimize traffic flow forecasting model based on LSSVR and present the whole flowchart. In such a way, we can not only determine the suitable combination of kernel width parameter
The rest of this article is organized as follows. Section “Preliminaries” describes the preliminaries, including the definition of short-term traffic flow forecasting problem and an overview of LSSVR. Section “Model description” presents the proposed joint spatiotemporal variable and parameter selection method. Section “Experiments and analysis” presents the road network traffic data, extensive experiments, and detailed results analysis. Finally, we draw some conclusions in section “Conclusion.”
Preliminaries
Problem definition
Consider a road network consisting of
Given a set of historical and current readings
Least squares SVR
Given a set of training samples denoted as

where


where

where
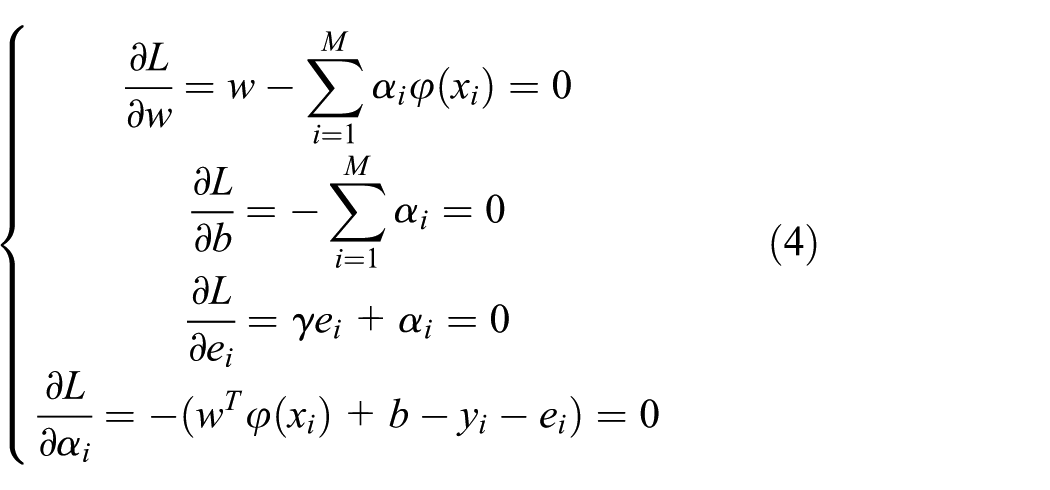
By simplifying the above equations, we can get the following linear system of equations

where

Kernel function plays an important role especially when solving nonlinear problems based on LSSVR model. In this article, we use Gaussian kernel as follows

where
As can be seen, on one hand, the performance of LSSVR performance depends on the combination of its some vital parameters such as the trade-off parameter
On the other hand, as can be seen from Gaussian kernel (7), all variables in
Model description
Genetic algorithm
GA 39 is a heuristic search algorithm aiming to solve the optimization problem. It was originally developed from some phenomena in evolutionary biology, including genetics, mutation, natural selection, and hybridization. This method is very flexible and attractive, especially suitable for optimization problems without explicit objective function and/or difficult to solve using traditional numeric algorithms, for example, gradient descent.
To solve an optimization problem, GA first generates a population with an abstract representation of many candidate solutions. Traditionally, a solution can be represented in the form of chromosome (or called chromosome) which comprises multiple genes. The commonly used representation method is binary encoding, that is, 0 and 1 although some other representation methods are also available, such as real encoding. 40 Evolution begins with the population with completely random chromosomes. All chromosomes in the current population are evaluated by a predefined fitness function and then a certain number of superior chromosomes are preserved according to their fitness values and some selection strategy. Favorable chromosomes have more chance to be selected while unfavorable chromosomes are less likely to survive. Afterwards, crossover and mutation operations are applied on those preserved chromosomes in order to generate offspring in a new population. By doing so, the population as a whole can evolve toward better solutions. After many iterations, the chromosomes with favorable fitness will dominate the population and yield solutions which are good enough for the optimization problem.
Sparse hybrid GA with LSSVR
In this section, we propose a sparse hybrid GA which can implement simultaneous spatiotemporal variable and parameter selection automatically in LSSVR for effective traffic flow forecasting. The details of this method are explained as follows.
Chromosome representation
The first step when applying GA is to represent each candidate solution by a chromosome in population. To achieve joint spatiotemporal variable and parameter selection for traffic flow forecasting, we design a chromosome representation by combining real encoding and binary encoding in a unified scheme. This chromosome representation method is illustrated in Figure 1 where each element in chromosome

An illustration of chromosome representation.
Furthermore, in order to restrict the number of spatiotemporal variables fed into LSSVR model, we require the binary encoding genes across all chromosomes in the population that have the same number of “1,” which is usually very small in comparison with the total number of variables. This imposed sparsity can guarantee very few spatiotemporal variables which really contribute to forecasting the traffic flow at the target site can be well selected. To sum up, this chromosome representation method has two interesting characteristics. One is that it is made up of both parameter genes and variable genes which use different encoding schemes. The other is that the number of variable genes marked as “1” is restricted in order to control the sparsity of variable selection.
Fitness function
Fitness function is regarded as an important component in GA, responsible for estimating the quality of each chromosome in current population. In this work, the root mean squared error (RMSE), which is widely used to evaluate the performance of traffic flow forecasting models, acts as the fitness function. Thus, smaller fitness value indicates better chromosome. Specifically, given a validation data set

where
Selection, crossover, and mutation
Some chromosomes need to be selected from the current population to be parents. According to Darwin’s evolution theory, the superior ones should survive and create new offspring. In this work, half of the current population are kept following rank selection principle 39 which can guarantee that all the chromosomes have a chance to be selected.
These selected chromosomes are randomly matched to form parent pairs and then the crossover operator is conducted so as to generate child chromosomes. Suppose the probability of crossover is
For real encoding, the parameter genes in child chromosomes can be expressed by the linear combination of the corresponding parent chromosomes as follows

where
For the binary encoded variable genes, we attempt to keep the number of “1” in the chromosome unchanged after crossover operation so as to keep the imposed sparsity consistent across all newly generated chromosomes. Therefore, we propose a multi-point crossover operator for variable genes. Specifically, define two index sets as

where

An illustration of chromosome crossover operator.
Similarly, we need to construct different mutation strategies for different types of genes. In this study, for real encoded parameter genes, we randomly replaced the original value with a new value in the range of
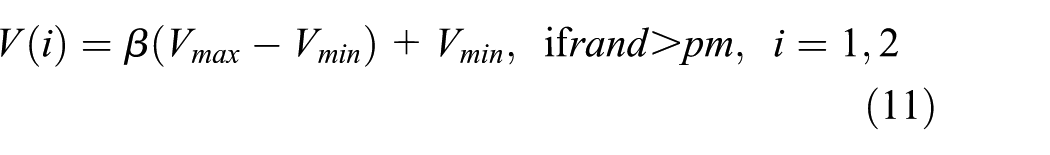
where β is a random number distributed in [0,1] and
For binary encoded variable genes, a “1” at arbitrary location is replaced with “0.” Meanwhile, a “0” at arbitrary location is replaced with “1.” In such a way, we can not only keep the number of variable genes with value “1” (and also “0”) constant, but also achieve the goal to enrich the diversity for population.
Framework
The flowchart of our proposed SHGA-LSSVR method for short-term traffic flow forecasting is shown in Figure 3. An explanation is described as follows:
Step 1. Collect traffic flow data from real-world road network equipped with loop detectors, which are partitioned into training, validation, and testing data.
Step 2. Perform normalization on the data to have zero mean and standard deviation.
Step 3. Initialize GA population by randomly generating binary encoded genes and real encoded genes.
Step 4. Construct multiple LSSVR models, based on training data and chromosomes in population, and then evaluate fitness of each model on validation data.
Step 5. If GA does not converge, go to Step 6, otherwise go to Step 7.
Step 6. Execute selection, crossover, and mutation operations based on current population to generate updated population, then go to Step 4.
Step 7. Pick up optimal chromosomes and identify the selected variables and optimal parameters.
Step 8. Construct the final LSSVR model based on variable subset and optimal parameters.
Step 9. Apply LSSVR on the testing data to generate forecasting results.

Flowchart of SHGA-LSSVR for traffic flow forecasting.
Experiments and analysis
Data description
In this article, we use the traffic flow data collected by loop detectors installed at 24 observation sites. These sites are located around the intersection of Interstate 205 (I205) and Interstate 84 (I84) in Portland, OR, USA. The data can be downloaded from the website (http://portal.its.pdx.edu/). The locations of these 24 sites and their numbers are labeled on the sub-area map of Portland shown in Figure 4. Overall, 18 sites locate on the I84 and 6 sites locate on the I205. Each site is denoted by a solid circle with different colors. Black indicates the traffic flow from west to east and green represents the opposite direction. Similarly, red indicates the traffic flow from north to south and purple represents the opposite direction. We use the 15 min aggregation data whose unit is vehicles per 15 min (veh/15 min). Therefore, there are totally 96 sample points for each site and every day. We collect traffic flow data of 10 weekdays (from 18 September to 1 October 2015) of each site and discard the data belonging to holidays and weekends because the traffic states on weekends and holidays vary differently from the weekdays. Furthermore, in order to train various models, choose their parameters and evaluate the prediction performance of models, we split the whole data set into three parts. The first eight weekdays of 18–29 September (by removing weekends and holidays) are grouped as the training set, the data set of 30 September is regarded as the validation set and the data set of 1 October is treated as the test set. In our experiments, we chose six sites (3, 10, 12, 19, 21, and 24) as the target sites that we want to forecast. These target sites are intentionally labeled with yellow in Figure 4 for clear illustration of their distribution in the road network.
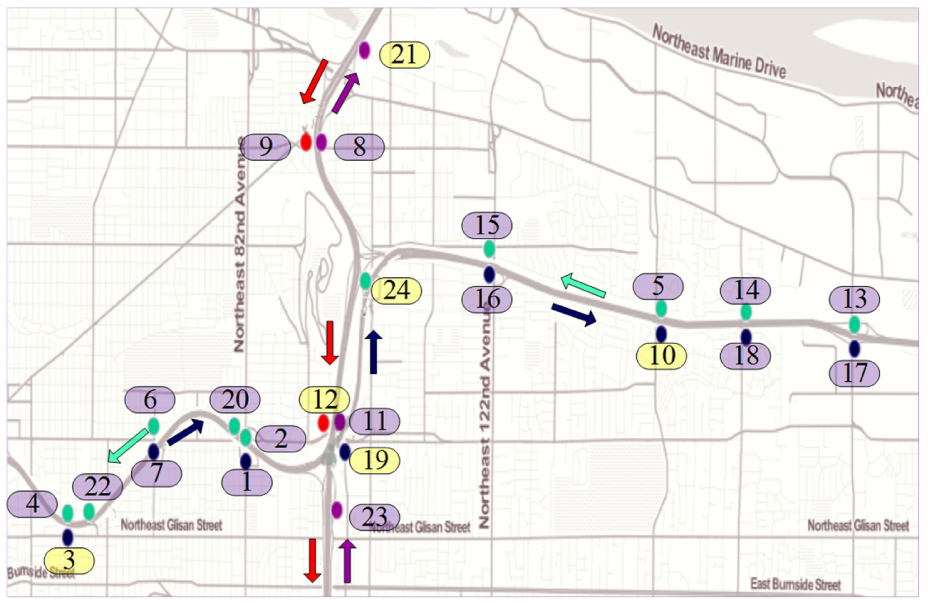
The selected sub-area road network of Portland, OR, USA.
Due to the malfunction of some detectors or transmission errors, there exist some missing values in the original traffic flow data. We count the ratio of missing values to total values and find that the missing rate (<1% for) is very small for these sites and time range. Since our model is not applicable in case of missing values, a simple temporal correlation based traffic flow imputation method is applied to complete these missing values.
Configuration
In order to evaluate the effectiveness of the proposed SHGA-LSSVR method for short-term traffic flow forecasting, we conduct extensive experiments based on the above real-world traffic data set. We compare SHGA-LSSVR with three closely related methods, including Ridge regression, Lasso regression, 20 and the original LSSVR without variable selection. Ridge and Lasso share the same least squares loss function; however, they have different penalty terms. In particular, Ridge is penalized by the l2-norm of model parameters, while Lasso is penalized by the l1-norm of model parameters. Due to such subtle but important difference, Lasso can achieve variable selection as the proposed SHGA-LSSVR while Ridge cannot. In addition, it should be emphasized that Ridge and Lasso are both linear regression models. LSSVR with Gaussian kernel is also involved in our experiments because of its powerful nonlinear modeling ability as well as wide applications in time series forecasting. In this study, the parameters in all methods are selected based on grid search and prediction error on the validation traffic flow data. All methods are implemented in MATLAB environment on a PC with Intel(R) Core i7 3.5 GHz with 16 GB RAM. The SHGA-related parameters for the proposed model are shown in Table 1.
Parameters for SHGA.

SHGA: sparse hybrid genetic algorithm.
To compare the prediction performance of various forecasting methods, two widely used criteria, namely, RMSE and mean absolute percentage error (MAPE),
17
are adopted in this study. In addition, since Lasso and our SHGA-LSSVR both can select spatiotemporal variables, the number of selected variables is also recorded which indicates the prediction performance can be achieved with typically much fewer variables. Taking into account the influence of different time lags on prediction performance, we change the time lags from 1 to 5 and record the experimental results for each case. The correspondence between time lag and the total number of spatiotemporal variables is shown in Table 2. For example, when time lag equals 1, the traffic flow data collected at time
Correspondence between time lag and the number of spatiotemporal variables.

Prediction error analysis
First, we take site 21 as an example to analyze different methods. The prediction errors in terms of RMSE and MAPE criterion obtained by all the methods under different time lags are listed in Table 3. From these experimental results, some interesting observations can be summarized as follows.
RMSE of different prediction methods on site 21.

RMSE: root mean squared error; MAPE: mean absolute percentage error; SHGA: sparse hybrid genetic algorithm; LSSVR: least squares support vector regression.
Significance of bold values are the best results.
For Ridge and Lasso, which are two linear methods, we can see their performance is worse than two nonlinear methods, LSSVR and SHGA-LSSVR. This is because the variation of traffic flow is actually very complex and highly nonlinear, especially in the case of road network where many potential factors may influence the prediction at the target site. Ridge and Lasso are more suitable when the relationship between the input and the output is approximately linear. Comparing LSSVR and SHGA-LSSVR, we can see the latter achieves smaller prediction error than the former. We have performed paired t-test at 5% significance level for the null hypothesis that the performance achieved by our proposed SHGA-LSSVR and other methods is the same. The results are shown in Table 4. As we can see from the results, in most cases, the proposed method outperforms the other competitors significantly.
Significance test of the proposed SHGA-LSSVR to other methods.

RMSE: root mean squared error; MAPE: mean absolute percentage error; SHGA: sparse hybrid genetic algorithm; LSSVR: least squares support vector regression.
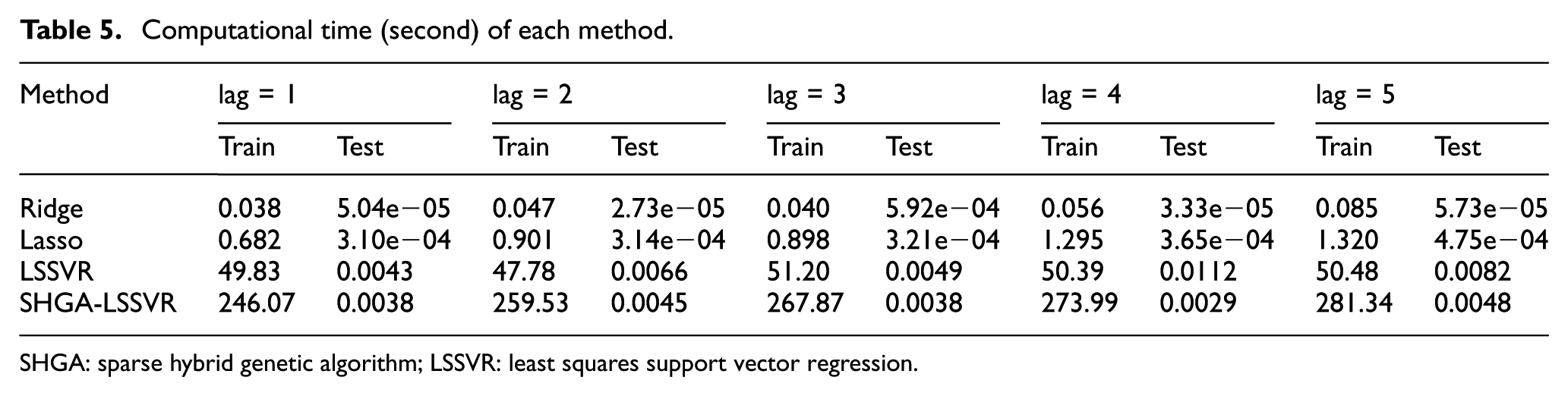
For the computational time and execution time, we have reported the experimental results in Table 5. As can be seen, in terms of computational time, the proposed SHGA-LSSVR is slower than LSSVR because variable selection and parameter optimization are performed using GA, which is time-consuming. On the other hand, in terms of execution time, we found that SHGA-LSSVR is actually faster than LSSVR. This is reasonable since test can be performed based on those selected variables instead of all variables. Note that model training can be performed offline and execution time is usually an important factor for practical application of algorithm. As a result, the proposed method not only has superior prediction accuracy, but also less execution time, in comparison with original SVMs
Computational time (second) of each method.
SHGA: sparse hybrid genetic algorithm; LSSVR: least squares support vector regression.
The number of spatiotemporal variables involved in each method is shown in Table 6. From the viewpoint of variable selection, Ridge and LSSVR are unable to select crucial variables, thus they use all available variables to construct the prediction model. In contrast, Lasso and the proposed SHGA-LSSVR can jointly choose a small number of variables from the whole set and construct the prediction method. However, as mentioned above, Lasso is a linear method, while SHGA-LSSVR is a nonlinear method. It enables SHGA-LSSVR to select fewer variables than Lasso and at the same time achieve better prediction performance because it can reveal the nonlinear relationship between those spatiotemporal variables.
Number of variables in different prediction models on site 21.

SHGA: sparse hybrid genetic algorithm; LSSVR: least squares support vector regression.
To intuitively illustrate the prediction results of different methods, we show the actual traffic flow, the predicted traffic flow, and the associated residual obtained by each method in Figure 5. From these results, we can observe that the proposed SHGA-LSSVR achieves smaller prediction error than the other competitors, indicating this method can better capture the traffic flow pattern.

Prediction results obtained by Ridge, Lasso, LSSVR, and SHGA-LSSVR.
For the other sites, that is, 24, 19, 3, 12, and 10, the experimental results including prediction RMSE, MAPE, and the number of spatiotemporal variables that are selected by SHGA are depicted in Figure 6. As we can observe, these results further verify that in most cases, the proposed SHGA-LSSVR outperforms all the other methods in terms of prediction error and at the same select fewer spatiotemporal variables.

Prediction results comparison of different methods. From top row to bottom row: sites 3, 12, 19, 24, and 10.
Interpretation of spatiotemporal variables
An advantage of the proposed SHGA-LSSVR is its interpretability which can provide some useful insights about the spatiotemporal relationship between the selected spatiotemporal variables and the target site in terms of traffic flow forecasting. When the SHGA optimization is finished, the variable subset with superior performance can be obtained, implying that the resulting variables from the sites located in the same road network, contribute to the target site. In terms of the site 21 with 4 time lags, the selected 14 spatiotemporal variables from the totally 120 variables are shown in Figure 7. Specifically, the center large circle in Figure 7 represents the target site 21 to be predicted. The surrounding small circles with different size and color represent 120 spatiotemporal variables associated with 24 sites in the road network. The size of each circle indicates the time lag, that is, the larger the circle, the smaller the lag. For instance, the biggest circle for each site denotes 0 time lag and the smallest circle indicates 4 time lags. The color is used to differentiate 24 sites. The straight lines connecting the surrounding small circles and the center large circle indicate that these spatiotemporal variables contribute to the traffic flow prediction at the target site. Accordingly, these selected sites are marked by bisque in Figure 8. From these results, we can observe some interesting findings.

Variable selection result for site 21 with 4 time lags.

Distribution of the sites (bisque) related to target site 21.
On the whole, 10 sites are related to the target site 21 besides itself, which are 5, 7, 8, 11, 13, 14, 18, 19, 23, and 24. Among them, sites 8, 11, and 23 contribute to the target site 21 as the role of direct upstream sites. These sites all belong to I205. In addition, sites 5, 7, 13, 14, 18, 19, and 24 which locate on I84 also influence the traffic flow at the target site because I205 and I84 actually intersect and their traffic flows may impact each other. We also observe that for site 21, only the traffic flow immediately prior to the prediction time is selected, thus implying the inclusion of historical data of the target site is unnecessary. This observation is well consistent with Yang et al. 14 In addition, many selected sites are not the nearest neighboring of the target site, reflecting that not only the adjacent sites but also the distant sites can have significant influence on the target site in the case of road network. This also coincides with the conclusion given in Yang et al. 14 Generally speaking, the relationship between these spatiotemporal variables is rather complex. Nevertheless, the proposed SHGA-LSSVR method can automatically select only 14 variables from all 120 variables and at the same time construct an accurate prediction model for traffic flow forecasting.
Conclusion
In this article, we propose a novel SHGA optimized LSSVR model for road network short-term traffic flow forecasting. This method can combine spatiotemporal variable selection, hyperparameters optimization, and traffic flow prediction in a unified framework, indicating that the “goodness,” that is, contribution, of selected spatiotemporal variables and optimized parameters directly depends on the final prediction performance. In such a way, the spatiotemporal correlations among all other road segments and the target site are fully excavated and the parameters in LSSVR are also optimized simultaneously so as to improve the prediction performance. We exploit the real-world traffic flow data to evaluate the prediction ability of our proposed model. The experimental results show that in comparison with other methods, the proposed SHGA-LSSVR model can achieve better prediction performance with much fewer spatiotemporal variables. In the current work, we adopted LSSVR as prediction model because it has been widely used and shown promising results. However, it should be noticed that besides LSSVR, neural network based prediction models, such as deep learning,23–25 have attracted much attention during the last few years. Comparing with LSSVR, deep learning is able to show better prediction accuracy given large number of samples. However, spatiotemporal variable selection has not been taken into account in current deep learning based prediction models. Therefore, the integration of the proposed SHGA with deep learning for further improvement of prediction is an interesting problem that we will investigate in the future work.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers for their constructive comments and suggestions.
Academic Editor: Michele Magno
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the National Natural Science Foundation of China (Grant Nos 61203244, U1564201, U1664258, 61601203, and 61403172), Fujian Provincial Key Laboratory of Information Processing and Intelligent Control (Minjiang University) (MJUKF201724), Key Research and Development Program of Jiangsu Province (BE2016149), Natural Science Foundation of Jiangsu Province (BK20140555), and the Talent Foundation of Jiangsu University, China (No. 14JDG066).