
Abstract
Accidental falls of elderly people are a major cause of fatal injuries, especially for those living alone. We present a novel vision–based fall detection approach that analyzes an extracted human body using described human postures. First, a human body extracted by a background subtraction technique is located by a minimum area-enclosing ellipse. Then, a normalized directional histogram is developed around the center of the ellipse to represent a human posture by multi-directional statistical analysis. After that, 12 static and 8 dynamic features are derived from the normalized directional histogram. These features are fed into a directed acyclic graph support vector machine to distinguish four closely related human postures (standing, crouching, lying, and sitting). A fall-like accident is detected by counting the occurrences of lying postures in a short temporal window. After conducting majority voting, a fall event is determined by immobility verification. From the experimental results, an overall accuracy of 97.1% is obtained for recognition of the four postures, and only 1.0% of postures are misclassified as lying postures. Our fall detection system achieves up to 95.2% fall detection accuracy on a public fall dataset.
Introduction
Falls and fall-related injuries are a major public health problem for aging populations all over the world. According to the statistics of the World Health Organization, 1 approximately 28%–35% of people aged 65 and over fall every year, and this rate increases to 32% or even 42% for those over 70 years old. This makes falls one of the five most common causes of death among elderly people.2–4 The medical expenses caused by the immense number of falls occurring every year have become a heavy burden for the population not only of China but also of other countries with the aging problem. It has already been proven that the medical consequences of a fall incident are highly dependent on the response and rescue time. However, commercial fall detection systems are mostly based on wearable sensors, which elderly people may forget to wear. It is not very convenient for them to carry these devices at all times. The main drawback of such devices is obvious. The demand for fall detection surveillance systems, which can automatically monitor and analyze abnormal behaviors of elderly people, has increased within the healthcare industry with the rapid growth of the population of the elderly. Thus, a highly accurate automatic fall detection system may become a significant part of the smart living environment for elderly people living alone.
More specifically, the monocular vision–based approach plays an irreplaceable role in fall detection. Monocular vision–based systems are very cheap and easy to set up. Moreover, many other activities besides fall incidents can be detected simultaneously with less intrusion. Each event lasts for a short period of time and contains different types of postures. During this short period, human postures change considerably with high velocity, especially in a fall incident. Due to this observation, a fall event can be detected by distinguishing these postures. Other actions, such as crouching, lying, and sitting, may have some postures similar to a fall incident, but they have entirely different semantic contents. Knowing only postures is not enough to distinguish these similar motions accurately; therefore, in our approach, we also consider the temporal information between postures.
This article proposes a novel posture–based framework for fall detection inspired by the observation that different motions have different characteristics reflected by postures. For distinguishing a fall incident from other daily activities, the majority voting strategy is utilized to combine several classified postures in a short temporal window. Our main contributions are summarized as follows:
The foreground human body extraction is reported in section “Human body extraction.” The human silhouette is refined and covered by a minimum area-enclosing ellipse, which is more compact than the traditional rectangular box for describing human posture.
To describe the postures of a fall incident, a normalized directional histogram (NDH) is developed from the covered silhouette by multi-directional statistical analysis. In light of the NDH, 12 static and 8 dynamic features are also derived for posture recognition.
To detect a fall incident, fall-related postures (standing, crouching, lying, and sitting) are classified by a directed acyclic graph support vector machine (DAGSVM). We accumulate the lying postures in a short temporal window to filter fall-like accidents. Once a fall accident is verified by immobility detection, the final decision is made.
The remainder of this article is organized as follows. Section “Related work” provides an overview of related works. In section “Human body extraction,” we briefly describe the extraction of the human body implemented with the help of a background model. Section “Human posture description” gives an elaborate explanation of the posture description, which includes the human body location, the NDH representation of postures, and the statistical characteristics of the NDH. Section “Fall event detection” explains the classifier of the fall detection, including the postures related to fall incidents, the directed acyclic graphic strategy of multi-class support vector machine (SVM) used for the four postures classification, and the fall event validation. In section “Experimental results,” several experiments are conducted to show that our algorithm works not only in the case of fall incident detection but also in detecting other complicated human postures. Some guidelines on fall detection are presented in section “Discussion.” Finally, section “Conclusion” contains the conclusion.
Related work
Current solutions to the fall detection problem can be roughly divided into two categories: non-computer vision–based methods and computer vision–based methods:5,6
Non-computer vision–based methods. There are many non-computer vision–based methods of fall detection, such as sensitive floor tiles, 7 simple sensors, 8 and wearable sensors.9–11 As falls cannot be detected at locations not equipped with specialized tiles, these tiles should be installed everywhere in the living room. These simple sensors merely provide some raw data and do not give sufficient information of a fallen person. The error rate of the method is also very high. The problem of wearable detectors is that the elderly may easily forget to wear them. Moreover, such a device is useless once the battery power is used up. Recently, to alleviate this problem, some researchers have proposed the use of acoustic and Doppler radar for fall detection.12,13 Moreover, there is a new trend toward the use of mobile fall detection systems.14,15 These systems also make it possible to prevent and anticipate many other health hazard situations apart from fall detection and notification.
Computer vision–based methods. Great progress has been made in computer vision and image processing techniques in recent decades, which has opened up new opportunities to improve fall detection systems. Image processing plays an indispensable role in fall detection systems because of its evident advantages. According to the principles of fall characteristics, they can be grouped into three categories: inactivity detection, moving human body shape change analysis (silhouette analysis), and 3D head motion analysis. 16 In the vision-based fall detection domain, Lee and Mihailidis 17 initially used the centroid, perimeter, and principal axis of the silhouette to describe a series of fall human postures and then identified required postures by a preset threshold value. Lee’s system was able to discriminate standing, stooped over, and lying down postures. Liu et al. 18 employed the ratio and differences of width and height of the bounding box of a human body silhouette to classify postures into three categories, namely standing postures, temporary postures, and lying down postures. The performance of their system was promising when the camera was placed sideways. A shape-matching technique, 19 such as shape context, Procrustes shape analysis, was proposed to match different postures. A fall event could be determined by analyzing the human shape deformation during a video sequence using a Gaussian mixture model. The occlusion problem was also partly solved. As for Auvinet et al., 20 to detect fall incidents of seniors, they utilized an occlusion-resistant method based on multi-camera networks, which reconstructs the three-dimensional shapes of people. Fall events were also determined by analyzing the volume distribution along the vertical axis. An alarm was triggered when there was an anomaly in the distribution during a predefined period. Increasing the number of cameras used, we can enhance the complexity of the final detection result. Yu et al. 21 applied the background subtraction technique to extract the foreground. The moving object was located in the image plane by an ellipse, the parameters of which were obtained by computing several spatial moments of the foreground image. In describing human postures, the ellipse fitting was more accurate than the rectangle box. A projection histogram along the axis of the ellipse (the local features) and the ratio between the major axis and the minor axis (the global feature) could evidently distinguish the postures of a fall incident. Olivieri et al. 22 presented a spatio-temporal motion representation, called motion vector flow instance (MVFI) template, which captured relevant velocity information by extracting the dense optical flow from a video sequence of human actions. As both the magnitude and direction of the velocity were fed into MVFI, falls could be distinguished from daily human motions with high accuracy and computational efficiency. Mirmahboub et al. 23 proposed the use of variations in the silhouette area obtained from only one camera. View-invariant features of the human body region were fed into a classifier of different events, mainly focused on the detection of fall accidents. Chua et al. 24 also proposed a new simple vision-based posture description technique that was based on human body shape variation analysis. Only three key points were used instead of the traditional ellipse and rectangle box. The fall was detected by analyzing the shape changes of the human silhouette through the centroids of three different regions of the foreground. The proposed three points of the human posture representation technique improved the fall detection rate without increasing the computational complexity. A novel posture representation approach, histogram of maximal optical flow projection (HMOFP), was presented in Li et al. 25 HMOFP mainly concerns the motion features of abnormal events, such as falling, running, and crouching, that occur in the crowded scenes. Curvature scale space (CSS) features and the bag-of-words (BOW) method 26 were combined to detect a fall in a depth video. An improved extreme learning machine (ELM) classifier was adopted to distinguish falls and non-falls. In a later work, 27 instead of representing an action as a bag of CSS words, the description of an action was provided using Fisher Vector (FV) encoding on the basis of CSS features. The Microsoft Kinect was also applied to fall detection; 28 a person’s vertical states in the depth images were characterized in the first stage, and then an ensemble of decision trees was used in the second stage to compute the confidence that a fall had preceded a ground event.
Our work is slightly different from the above-mentioned vision-based detection features used for fall detection. We present a novel vision–based approach for monitoring elderly people that is focused on detecting falls using different human postures. The representation of a human posture is based on the NDH. It not only considers the spatial information of a human posture but also concerns the motion information by analyzing the change rate of the NDH. Then, a multi-class SVM is used to classify postures into four types (standing, crouching, lying, and sitting) that are closely related to fall event detection, especially the lying postures. Figure 1 shows the flow chart of the proposed fall detection approach. Briefly speaking, the approach involves three main blocks. First, the human body is extracted from each frame using a background model. Second, the NDH is built as an information source to represent a human posture. Third, postures are classified by the DAGSVM. After all the postures are classified, the fall accident is verified by a majority voting strategy and immobility detection. In the following sections, we will describe the details of the three blocks.
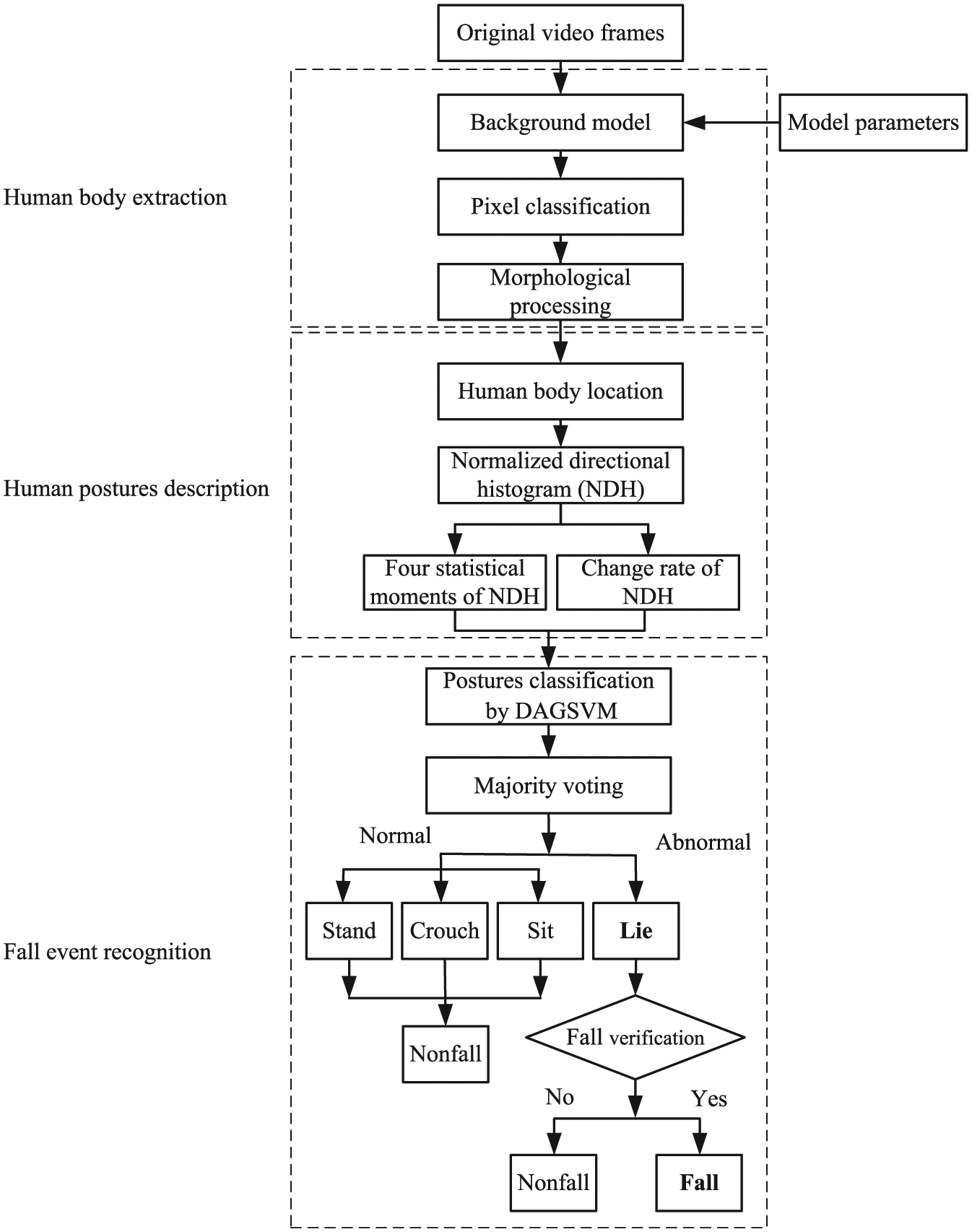
Flow chart of the proposed fall detection approach.
Human body extraction
Extracting a moving person from an image sequence is one of the most challenging tasks in the computer vision field. Human bodies are highly non-rigid objects with a high degree of variability in size and shape. When people walk toward or away from a video camera, both the shape and size of the human body change greatly. Sometimes, even the color and texture are affected significantly by the shadow or ambient light in a living room. The approach to human body extraction has to cope with such complex situations.
Our initial assumption is that there is only one moving object, the walker, in the video sequence. The camera and the background are always static. Under this assumption, the background model is obtained by computing several model parameters over a number of static background frames. We employ the color distortion model proposed by Horprasert et al., 29 which can be used to address the problem of slight illumination changes, such as shadows and highlights. The color distortion model is adopted to separate the brightness from the chromaticity component. Figure 2 shows the color distortion model in three-dimensional RGB color space.
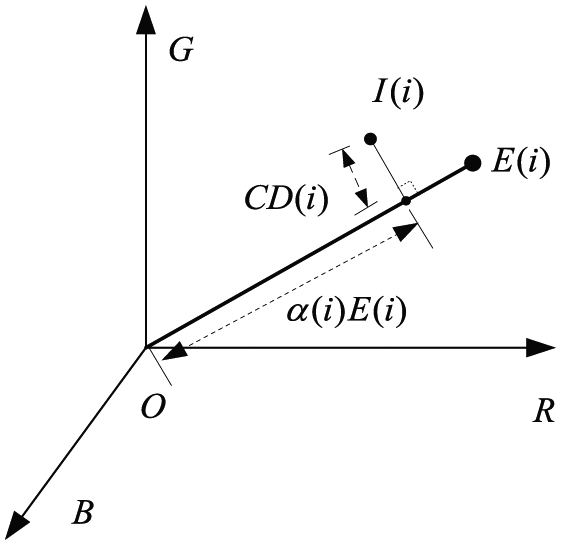
Color distortion model.
Considering a pixel i in the frame, let


There are three main steps in human body extraction. The first step is to construct a reference background image using the background model. Second, threshold selection determines the appropriate threshold values for pixel classification. The final step is to classify the pixels into the background mask, moving object mask, and shadow mask.
These three steps yield a binary foreground image. However, the foreground image may be corrupted by bad noise both inside and outside of the object. The noise can even create small holes in the object. Morphological operations are implemented to remove the noise. The crucial steps of human body extraction are demonstrated in Figure 3.

Human body extraction: (a) an original background image, (b) the current image with a human body, (c) the extracted human body in the foreground, including shadows and holes, and (d) the final extracted human object after the morphological operations.
Human posture description
To conduct a thorough analysis of human movement, the highly non-rigid moving human body should be identified within frames. For an object separated into several small blocks, since it moves rapidly on a similar background along with the human body, we gather all the extracted pixels together into a point set, and identification of the human body in the image plane can be carried out by optimizing the minimum area-enclosing ellipse of these points.
Human body location
Consider the equation of an ellipse in the image plane

where
which can be solved by the Khachiyan first-order algorithm in Kumar and Yildirim. 30 Equation (3) can be rewritten as

where the u terms are the components of the unit eigenvectors of the symmetric matrix, E, and



Region of interest.
Since the unit eigenvectors of a real symmetric matrix are orthogonal, let the direction of

This means that the matrix of unit eigenvectors for a symmetric

This allows the equation of the ellipse to be expressed in the

The reciprocal values of square roots of the eigenvalues for the two unit eigenvectors are the lengths of the semi-major and semi-minor axes of the ellipse. This is a rather important result for the representation of a human body.
NDH of human postures
An example of the ellipse of interest determined by the locating algorithm on the foreground image is given in Figure 5.

The divided region and normalized directional histogram: (a) the divided region of the human body and (b) the normalized directional histogram of the posture built according to the coding (numbers 1–8).
We set the center of the ellipse as the origin of the coordinate
Given a T-frame sequence of the foreground pixel’s position

where
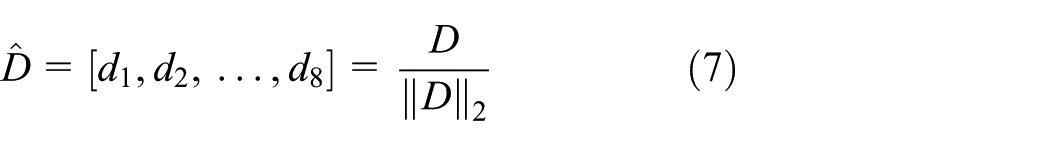
It can be used for a description of the human posture in the region covered by the ellipse. It is obvious that a human posture has a close relationship to the distribution of the components of
To give a better understanding of our method, we visualize the NDH of a human posture in Figure 5(b). We also illustrate other concerned NDHs of four closely related postures of a fall incident in Figure 6. Concerning the distribution of the components of
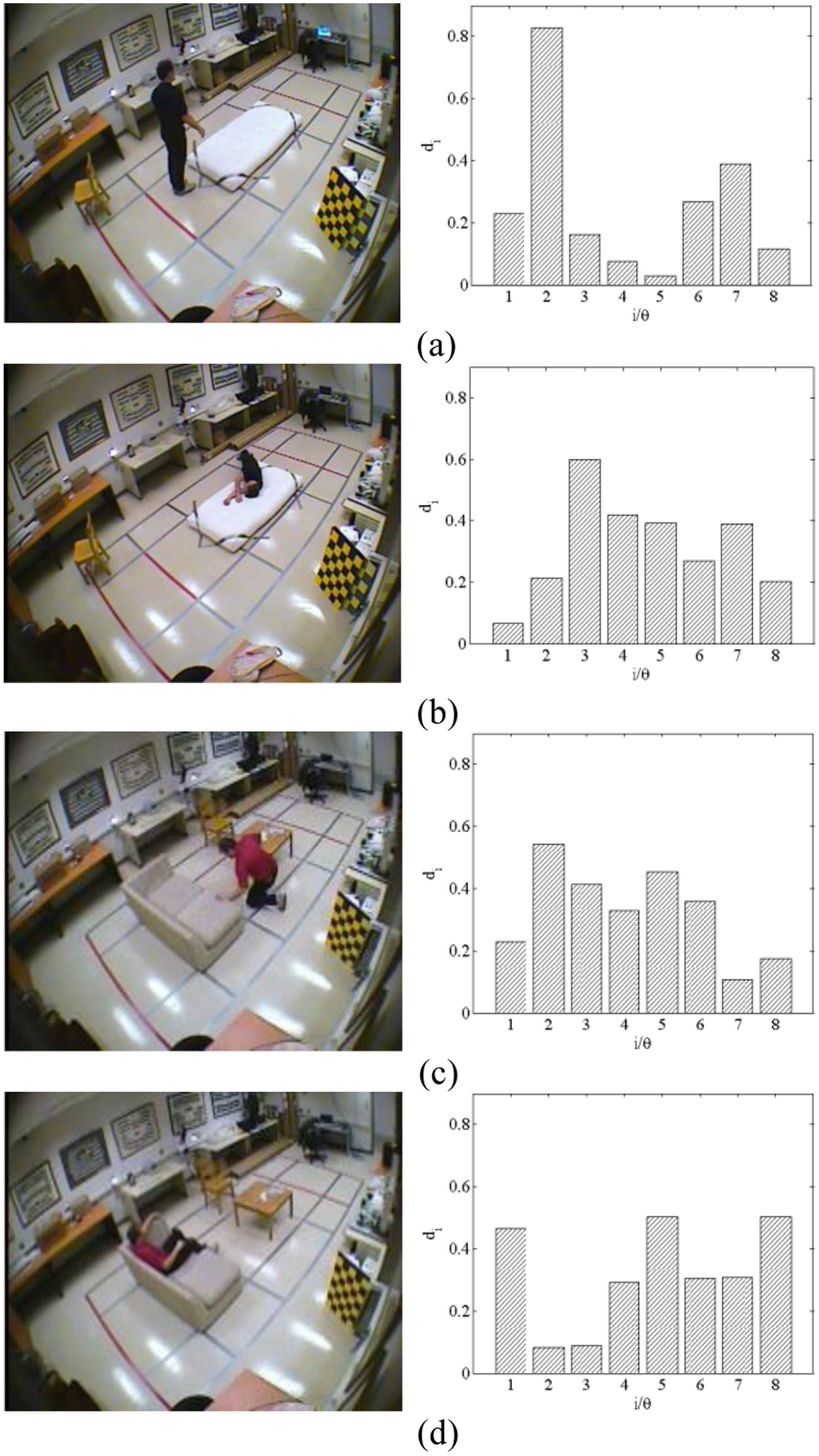
Normalized directional histograms of four postures: (a) standing, (b) lying, (c) crouching, and (d) sitting.
Statistical characteristics of NDHs
Obviously, the mean of NDH
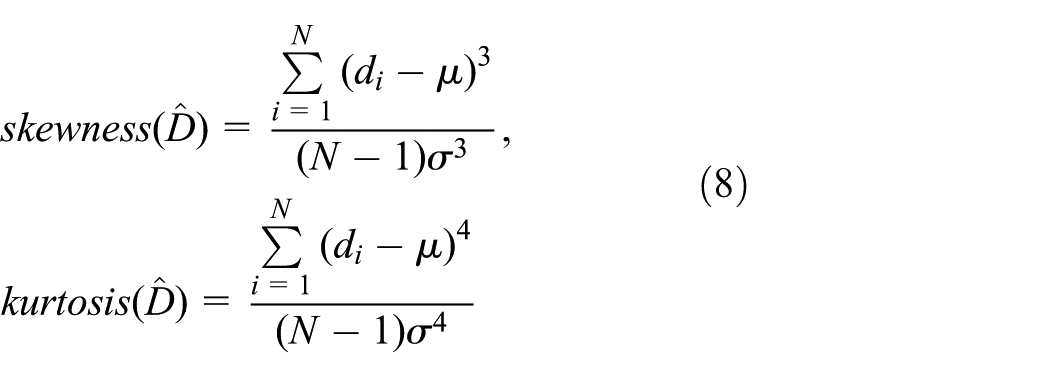
where
To evaluate four statistical moments of
The histograms of the mean

where

Histograms of four statistical features: (a) mean, (b) standard variance, (c) skewness, and (d) kurtosis.
Statistical hypothesis testing is conducted, and the null hypothesis
For only one instance, the feature mean
Table 1 gives the statistics
Significance test.

The NDH

Variations of the four statistical features for video sequences: (a) standing to lying, (b) standing to sitting, and (c) standing to crouching.
Due to these observations, eight change rates of the components of NDH

where
Fall event detection
At the beginning of this section, we discuss the posture characteristics of fall incidents, and then a tree structure classifier for separating lying postures from fall events is elaborated in detail.
The related postures of fall incidents
There are a variety of postures that occur during a fall incident. It is similar to a walking or standing posture in the pre-fall phase of a fall incident. In the following step, the fall speed gradually increases, and different body parts (such as the head and feet) have different velocities. Meanwhile, the body shape also has some distortions. During this period, the NDH
Moreover, considering the characteristics of a fall incident that are similar to those of crouching and sitting motions, we can observe several such traits, for example, the speed of the head is much faster than that of the feet, and the body shape has some distortions. However, what is peculiar about a fall incident is that the direction of the head’s motion is entirely different from the directions of sitting and crouching movements, and the distortion of body shape is much smaller. To increase the robustness and reduce the error rate of our fall detection system, we also introduce crouching and sitting postures into the experiment.
Posture recognition by DAGSVM
The fall-related postures are represented by a feature vector F, which can be attributed to one of the four categories (standing, crouching, lying, and sitting) by a classifier. SVM is a binary classifier that constructs an optimal hyperplane according to the minimum structural risk principle31,33 in the feature space or a transformed high-dimensional feature space, which can be used for classification, regression, or other tasks. Naturally, a good separation is achieved by the hyperplane that has the largest distance to the nearest training data point of any class (the so-called functional margin) since, in general, the larger the margin, the lower the generalization error of the classifier. It was originally designed for binary classification, so how to make it suitable for solving multi-class problems is still an open issue. Currently, there are two types of strategies for multi-class SVM. One is the construction of several binary classifiers and the combination of the classifiers by various rules, such as one-versus-all and one-versus-one strategies. The other is direct consideration of all of the multi-class data in one optimization formulation. However, because this method solves the multi-class SVM in only one step and the parameters of the SVM are too complicated to solve, a much larger optimization is required.
To take full advantage of the binary classifier SVM, the directed acyclic graph scheme is employed to combine several SVMs to solve multi-class classification problems. The adopted DAGSVM provides an excellent balance between generalization error and time efficiency at both training and computing time compared with other multi-class SVM schemes.34,35
Figure 9 shows the structure of the DAGSVM designed according to the related information of NDH
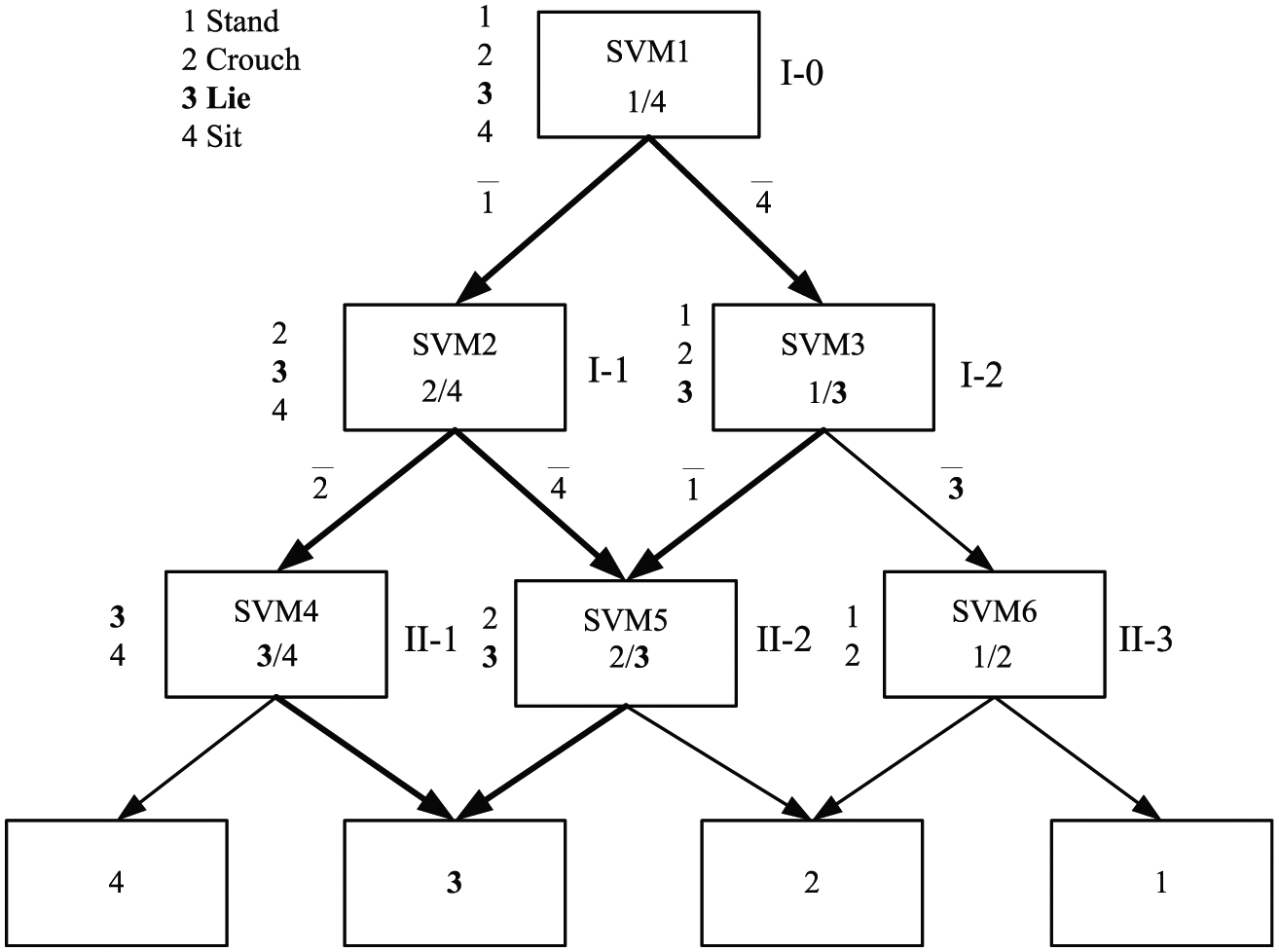
Classification structure of DAGSVM.
Overlap ratio of the histogram.

Fall incident detection by a majority voting strategy
A fall incident usually occurs in a short period of time. The typical duration of an event is approximately 0.4–0.8 s. That is approximately 10–20 frames. According to the characteristics of fall events, in most of the cases, a fall accident starts with a standing posture and ends with a lying posture. Meanwhile, there are a variety of other similar postures between the start and end postures. At the end of the fall accident, lying postures usually remain unchanged for some time because the fallen elderly person is lying immobile. As explained in the previous section, all the frames are classified into four different types of postures. Once the postures’ classes have been found, we filter this per-frame posture solution of the fall event detection by counting the occurrences of lying postures within a short temporal window. For this purpose, the majority voting strategy is adopted as shown in Figure 10.

An overview of the voting strategy for fall detection.
Having considered the typical duration of a fall event, we decided to set

A fall-like event can be determined by considering whether the indictor
Experimental results
In this section, we present the performance of our fall detection system. The experiments are carried out on a desktop with an Intel(R) Core(TM) i3-2120 CPU and 2.00 GB of RAM. We test it intensively on a public multiple-camera fall dataset. 32
This video dataset contains simulated falls and normal daily activities recorded in 24 realistic situations. In each scenario, an actor engages in many activities, such as falling, sitting on a sofa, walking. Every scenario is shot simultaneously with eight different cameras mounted around the room where the fall incident happens. All of the actions are performed by the same person with differently colored garments. Some of them include partial occlusion. We used all of the 736 samples of the dataset, which are shot from different viewpoints. Figure 11 illustrates the eight directions of a fallen person with its NDH. It can be seen as eight different lying postures of one person. Figure 6 shows the extracted human body and the NDH of the four typical postures. We should choose samples to train the classifier. Therefore, the dataset is split into two parts. The first part contains 80% of the samples (589). It was used for training, and the other samples were used for testing (148). The commonly used cross-validation technique was applied to evaluate the performance of the classification system. Three different types of evaluations are made. Then, we compare our system with other related fall detection methods using the same data.
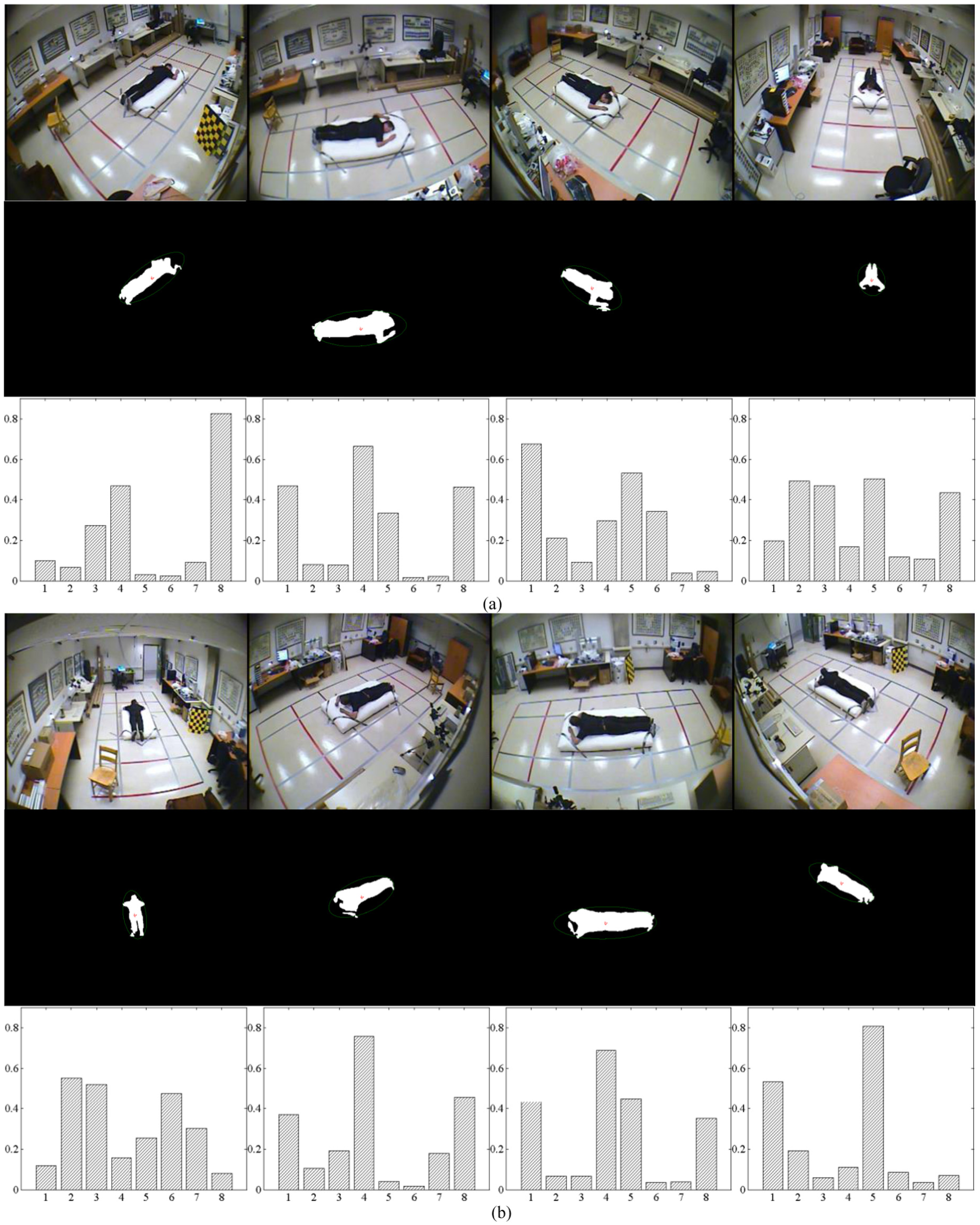
Eight postures of a fallen person: (a) directions 1–4 and (b) directions 5–8.
Posture classification results
Based on this dataset, we first apply the classification accuracy to evaluate the performance of the DAGSVM in fulfilling the task of posture classification. The first assessment is associated with different types of features used for human posture classification, which is summarized in Table 3. The classification results are compared by regarding the values of the global features, local features, and dynamic features alone and using a combination of these three types of features. The DAGSVM is employed for this purpose. From the table, we can see that the classification result is promising only regarding the global features (93.6%). It is much higher than the performance obtained within the local features (60.4%) and dynamic features (45.8%). However, the accuracy achieved with the combined features improves the overall classification rates significantly. According to the classification rate, a combined group of three types of features achieves the best performance, with a much better classification rate (97.1%) than that of one-type or two-type feature groups.
Comparison of different types of features.

The second estimation is of different feature extraction methods for human posture classification. The comparison of the proposed method and some other existing approaches conducted on the same data is shown in Table 4. We see that the accuracy values achieved by our method are higher than those of the three other compared techniques. Our approach yields more favorable results compared to those achieved by the complicated projection histograms. 21 The projection histograms are obtained by analyzing the projection on the major and minor axes of the ellipse. They only provide static information without the motion information of the human posture. The method of extracting features by analyzing the variations of the silhouette area 23 just utilizes the dynamic information of a person’s movements. The variations of the silhouette area are view-invariant. The approach is widely dependent on the background update strategy. The bounding box ratio method 18 is easy to implement only when the camera’s view direction is perpendicular to the moving person.
Comparison of different feature extraction methods.

In the third assessment, the performance of DAGSVM in distinguishing the falling posture from the other three postures is compared with the performances of two state-of-the-art classifiers: the ELM and multilayer perceptions neural network (MLPNN) 36 ). The results of the comparison are given in Table 5. To conduct a fair and representative comparison, the parameters of the compared classifier are tuned to be optimal using a tenfold cross-validation technique. DAGSVM achieves the best performance with a much better classification rate (97.1%) than that of MLPNN (only 92.9%) and that of ELM (only 74.7%). The overall classification rate of DAGSVM is 4.2% higher than the accuracy of MLPNN. The receiver operating characteristic curves of the three algorithms are shown in Figure 12. It can be found that the proposed DAGSVM outperforms both of the compared classifiers.
Comparison of three classifiers for the four postures.

ELM: extreme learning machine; MLPNN: multilayer perceptions neural network; DAGSVM: directed acyclic graphic support vector machine.

The receiver operating characteristic curves of the three classifiers.
It is not a reliable metric to estimate the performance of the classifiers only using classification accuracy for the four-posture classification since classification accuracy is mainly concerned with the percentage of correctly classified instances out of the total number of samples and neglects the rate of misclassified samples. The classification rate cannot accurately reflect the performance of the multi-class classifiers in the case of one class accuracy being very high while the other is very low. To adequately evaluate the effectiveness of classifiers, the confusion matrix, also known as the error matrix, is the best choice. A confusion matrix is a specific table that allows for visualization of the performance of a classifier on a set of test data for which true values are already known. Each column of the matrix represents the instances (postures) in a predicted class, while each row represents the instances in an actual class (or vice versa). All correct predicted instances are located in the diagonal of the table, so it is easy to inspect the table visually and find the errors, which are represented by the values outside the diagonal. It is easy to see whether the classifier confuses two classes (i.e. perceives the sample of one class as belonging to the other). Figure 13 shows the confusion matrixes of the classifiers conducted on the dataset. The differences among the diagonal entries of ELM are very significant, especially that between the first posture (standing) and the fourth posture (sitting). The accuracy of distinguishing standing postures can exceed 95.0%, while the classification rate of sitting postures is only 58.0%. Almost 23.0% of sitting postures are misclassified as crouching postures. The confusion matrix indicates that the ELM algorithm has some trouble distinguishing both falling postures and crouching postures, but it can make the distinction between standing postures and other types of postures pretty well. There are two reasons for this poor result of ELM. One reason concerns the feature distribution. The input features are suitable to distinguish standing postures. This reflects that the feature’s distribution of standing postures is obviously different from that of the other three postures (crouching, lying, and sitting). Furthermore, the feature’s distributions of crouching, lying, and sitting are very similar, especially lying and sitting. Thus, the accuracies of the two postures are not so satisfying. The other reason is the ELM classifier. There is only one single hidden layer in the extreme learning machine, which can simply be considered a linear system. The classification performance of ELM is highly dependent on the number of hidden nodes, although it has been proven that N hidden nodes can correctly learn N distinct observations. If the number of hidden nodes is equal to the number of distinct training samples, ELM can approximate these samples with zero error. In fact, in most cases, the number of hidden nodes is much less than the number of distinct training samples. However, considering our small-sized classification task, we only choose 24 hidden nodes, which is equal to the number of features. The four-posture classification rate of MLPNN is almost the same. However, it is not suitable for lying posture recognition since the accuracy is only 84.0%. There is still room for improvement in the accuracy of falling posture discrimination. DAGSVM has almost the same performance for the four postures. The discrimination accuracy of all posture types exceeds 95.0% and is higher than that of the compared algorithms. From the confusion matrix in Figure 13(c), we can see that all standing and crouching postures are not misclassified as lying postures. Only the sitting postures are misclassified. There are only 1.0% of postures misclassified as lying postures. The lying posture classification accuracy of our approach is approximately 96.0%. It is very beneficial for fall-like motion recognition. The rate of lying postures that are not correctly detected is acceptable at only 4% of the total number.
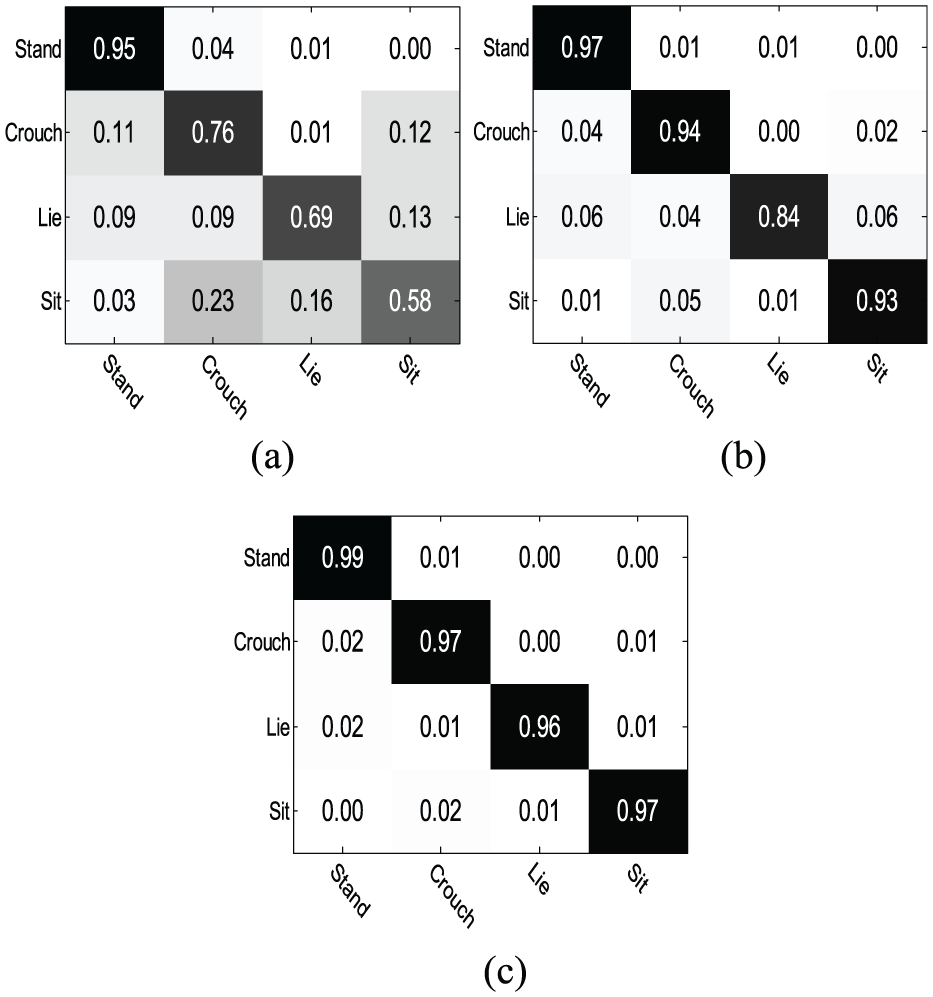
Confusion matrixes of the three classifiers: (a) extreme learning machine, (b) multilayer perceptions neural network, and (c) the directed acyclic graph support vector machine.
Fall detection results
Posture classification constitutes a critical step in our fall detection system. The labels of the postures in the temporal window are used to detect falls according to the majority vote strategy explained in the last section. If more than half of the labels in the temporal window indicate lying postures, it testifies that a fall-like incident has occurred. After the incident has occurred, we observe the characteristics of the fallen person, that is, the located minimum area-enclosing ellipse of the fallen person. If the person has been lying immobile on the ground for a while, the fall event is verified. To illustrate this, we show eight different cases of a fall incident in Figure 11. The monitored person falls on the floor, and a lying posture is detected on the ground. This lying posture is maintained for a while, so a fall event is verified. The system issues an alarm to call for the assistant.
To evaluate our fall detection system, we used this free-fall detection dataset as testing samples. The samples used in this subsection contain only one subject in each video sequence. A total of 148 instances were recorded, including 42 fall incidents and 106 non-fall activities. Table 6 depicts the samples and the detection results. The length of the temporal window T is considered in our approach. It may have significant effects on the overall performance. To investigate the effect of this parameter, we perform fall detection experiments on the public dataset with different parameter settings. Figure 14 shows the accuracies of various parameters of the temporal window T. It can be found that the accuracy of our system increases with the increase in length of the temporal window until
Evaluation of DAGSVM for fall posture recognition.


Accuracies of different temporal windows.
To demonstrate the effectiveness of our system, two state-of-the-art methods, namely shape variation 24 and projection histogram, 21 were implemented, and their results were compared with those of the proposed methods. To assess the performance of the three methods, the fall detection accuracy was calculated for each one. From Table 7, we can note that the proposed system of fall detection methods based on the posture classification outperforms the other two approaches. The fall detection accuracy of our method can exceed 95.2%, while the accuracies of the two compared methods were only 90.5% and 95.1%, respectively. This implies that the proposed method is more effective than the other two methods.
Comparison of different fall detection methods.

Discussion
The proposed fall detection system is based on the strategy of detecting the required posture through majority voting, compared to the traditional posture classification system, it has the following merits:
It is conveniently not as greatly affected by background noise in the environment as the methods based on acoustic sensors 12 and floor vibration sensors. 7 A reference background image was first constructed by our background model. Model parameters were used to classify the current image pixels into three categories: the background mask, moving object mask, and shadow mask. The thick noise around the object in the foreground image was removed by morphological operations.
Even if the training dataset is much larger and contains more types of actions of daily life, the well-trained DAGSVM tree structure classifier can still distinguish many types of postures that are used for fall detection. The classified postures are not only used for fall detection but can also be employed for the detection of particular types of fall events by analyzing the labels of postures in the filtered temporal window at the stage of majority voting, for example, slip-backward, trip-forward, and left/right lateral types. In prosthetics research, the adjustment of parts of a knee joint is often a tradeoff because of the different types of falls that may occur. Different types of falls can lead to different types of injuries. For the elderly, a slip may be likely to result in an injury more serious than a trip. It is more likely a lateral fall when the person loses his or her consciousness. Knowing the type of fall incident might be necessary for the fall assistant to choose the more appropriate response. It is also valuable for adjusting the treatment of monitored seniors and for preventing similar types of falls in the future.
Our posture-based approach is implemented at the frame level; there is no need to segment a video clip. Compared with the video clip-based method,26,27 our approach is computationally more efficient since it extracts classification features only from the foreground rather than from the entire video clip.
The proposed fall detection system yields favorable results compared to those reported in the literature. However, some problems still occur in our system. One core problem is that it is designed to monitor one person. In some special cases, such as the presence of many people or a large-sized pet along with the elderly in the monitored environment, it does not cope well with the situation. In this case, other object classification techniques should be applied to determine whether the extracted silhouette is a human body or that of a pet and whether this silhouette belongs to the monitored person.
Another problem is the occlusion of the living room of elderly people. The real room environment is sometimes much cluttered which causes occlusions and hampers the extraction of features. A severe occlusion will degrade the final performance of the fall detection system. Before the fall detection phase, the ground is determined initially. It may be helpful for partly solving the occlusion problem. However, if we use only one camera, it is impossible to address this problem completely. More than one camera can be used to make sure that the human body is visible in at least one camera’s view. We can find that the view of the occluded part of the human body may be obtained from the other installed cameras, making it much easier to accomplish the task of extraction of human body features. For instance, Auvinet 20 reconstructed the three-dimensional shape of people by multiple camera networks. Each three-dimensional position was independently reconstructed. Hence, the algorithm was able to address several occlusions.
As for the possibility of the background changing drastically, for example, a light being turned on or the sun suddenly illuminating the room, the background subtraction technique is very sensitive to such situations. This is another shortcoming of the posture-based approaches. To suit the varied environment, the system has to undergo a background update procedure and will recover to the normal performance after the procedure is finished. If a fall incident occurs during the period of the upgrade process, most of the fall detection systems based on the RGB video camera fail to detect it. This is an open issue with ongoing research. Fusing multiple sensors in a proper manner may serve as a satisfactory solution to this extreme situation.
Last but not least, although the risk for falls increases dramatically with age, falls are not an inevitable result of aging. There is evidence that falls of the elderly can be prevented with clear guidance for effective interventions. Practically, few old people are offered interventions to prevent falls. General practitioners (GPs) are usually relied on to manage the needs of our system. These GPs are invited to simulate types of fall prevention activities in the environment. Our fall detection system detects trials of these activities. Then, clinical guidelines, such as environmental modification, medication review, and exercise/rehabilitation, are provided according to these results. Furthermore, the development of care plans in fall prevention has been determined based on the resident characteristics. Through practical lifestyle adjustments, the number of falls among seniors can be substantially reduced.
Conclusion
In this article, we have proposed a novel vision–based fall detection approach characterized by the utilization of human postures. There are three main elements in our approach. First, the human body that was extracted from frames by the background model technique is located using a minimum area-enclosing ellipse. This ellipse represents an excellent tool for solving the problem of locating a separate human object. Second, human postures are described by the NDH constructed around the center of the ellipse. The method not only avoids the deviations of posture description caused by the fragmentariness of the extracted object but also eliminates the effects produced by different sizes of the same posture. We obtained classification features by pooling the spatial and dynamic information got from the NDH of a human silhouette. The 12 static features mainly reflect the spatial information, while the eight motion features express the dynamic information. The analysis of four statistical features out of the 20 lays a good foundation for feature unitization and multi-level classification of human postures. Third, we propose DAGSVM, which utilizes the directed acyclic graph strategy to combine several binary classification SVMs to sort human postures. It classifies the postures first into two categories (stand–lie, crouch–sit) and then into four categories, namely standing, crouching, sitting, and lying. An overall accuracy of 97.1% is obtained for the four-posture recognition. These classified postures are then filtered frame by frame in a short temporal window. A fall-like accident is detected by counting the occurrences of lying postures. After conducting the majority voting, the fall event is determined by immobility verification. From the experimental results, our fall detection system achieves up to 95.2% accuracy on a public fall dataset. It is worth noting that the accuracy of our system is greater than that of two other compared methods.
Despite all the advantages listed above, this study is still very limited since we did not use the records of real fall accidents for our research. In real settings, falls are relatively rare events compared to movements such as sitting down, crouching down, and walking. The occlusion and cluttered background problems still need to be solved in our system. In the future, a probable solution to these problems may be found using multiple types of sensors.
Footnotes
Academic Editor: Joel Rodrigues
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Department of Science and Technology in Hebei Province under the program “Smart Video Surveillance System for Community Integrating the Internet of Things” (No. 12213519D1).