
Abstract
As the developments of new techniques, mobile social networks have been built wildly. To obtain and spread information over mobile social networks efficiently, the influence maximization problem is to find a seed nodes set with limited size such that it can influence as many nodes as possible. Previous works ignore the dynamic influence phenomenon of diffusing information on mobile social networks. In this article, we propose a new model to express the procedure of diffusing information under the existence of dynamic influence. Theoretical analysis shows that the influence maximization problem under new model is non-deterministic polynomial-time hard, and efficient approximation algorithm is proposed. Experimental studies on real data sets show that the new model can process dynamic influence well in the diffusing information procedure, and the proposed algorithms can solve the influence maximization problem on new model efficiently.
Introduction
Recently, as the developments of techniques of communications and computing, modern smart phones have huge increase and rapid popularization in the whole world. According to the reports, until 2015, the size of mobile phone users in the world has reached 4.45 billion and 42.9% of them are using smart phones (about 2 billion). By the reports from China, the size of mobile smart phone users has reached 5 billion in 2014. In addition, as the emergence of more devices, such as tablet and smart watch, more and more smart mobile devices are popularized now. Because of the developments of embedded computing, sensing, and communicating techniques, the smart mobile devices have more and more powerful abilities and they are not only tools for communications any more. In many applications, they have performed to be powerful tools for mobile sensing, computing, and so on. For example, iPhone 6 has integrated at least eight types of sensors such as ALS (ambient light sensor), PS (proximity sensor), and GPS (Global Positioning System), and it takes a 2.6 GHz 64-bit processor, besides common modules for telecommunication, and it also has powerful WiFi and bluetooth devices.
As the size and power of smart mobile devices increase, more and more online social applications are being used in mobile environments, and the traditional social networks have evolved to be mobile social networks. The typical applications of mobile social networks include Facebook, Twitter, Google+, and Sina Weibo. According to the reports, until 2014, the number of month average users (MAU for short) of Facebook is about 1.3 billion, and in 2015, the MAU size for Sina Weibo has reached 212 million only in China. As more and more mobile applications are utilized, more and more natural mobile social networks are being created.
The emergence of mobile social networks changes the way of information diffusion and provides opportunities for viral marketing as shown in the work by Chen et al. 1 Different from traditional methods for marketing, viral marketing can utilize the “word-of-mouth” advantages of mobile social networks and diffuse advertising information more efficiently. It has attracted lots of research interests from both mobile and social computing areas. Influence maximization problem is one of the most popular topics in the area of mobile social network. It has been formally investigated by Kempe et al. 2 and obtained lots of attentions from many researchers.3–5 However, there are still important challenges not solved in real applications of influence maximization problem when facing more complex scenarios. One of them is that the influence ability between nodes in real world may usually dynamically change, which is also the motivation of this article, while most of current research efforts on influence maximization problem always assume that the influence ability is static.
For general social networks, they are at least composed of nodes and edges like general networks. Usually, each node represents one social actor (e.g. one person in physical world and one user of Facebook) and the edges represent the social interactions between social actors (e.g. two persons are friends and one user is following the other one on Facebook). When considering the influence maximization problem on mobile social networks, usually, the edges have special meanings related to influence (e.g. one user accepts the advice of another one). The most popular methods proposed by previous works are as follows. First, a model is built to describe the information diffusion procedure on mobile social networks; then, the algorithms for finding special seed set with maximized influence are designed. In classic models, whether user A will be influenced by user B depends on the influence probability between them. In detail, if B has accepted some advice and the influence probability between B and A is 0.9, A will accept the same advice with probability 0.9 in next step. The influence probability is a simple and clear method to describe the ability of influence between two nodes, and it is usually assumed to be a constant once if a special social network is considered. However, in mobile social networks, the influence probability may be dynamically changed.
Let us consider an example in real life to show the dynamic influence phenomenon during the process of diffusing information which has been also observed by only few previous works.6–8 Assume that there is one user A of Twitter, which can be treated to be a directed graph, before lunch A is browsing his following twitters. Using GPS or WiFi devices of A’s smart phone, the app of Twitter may know the location of A and push one advertisement about restaurant X nearby. After seeing that, A may have his lunch in X and post twitters to recommend X to his friends. Assume A has two friends B and C, B is also near from X but C is not. Then, B is more likely than C to view the advertisement and go for a taste, while A may have the same influence probabilities for both B and C on general information. Let us imagine and compare two similar scenarios. In the first case, A receives one posted tweet from his friend B; here, B is the original author of that tweet. In the second case, A still receives the tweet from B, and the difference is that B reposted that from C. Obviously, the influence probability from B to A in the first case should be higher than the one in the second case. In the two examples above, the influence probability is not static for two given nodes, and it can change during the procedure of information diffusion. As known by us, there are only few previous works considering such challenges and none of them considers the influence maximization problem under dynamic influence directly.
Actually, the examples above show two important sources of dynamic influence, locations and time delay. In a mobile social network, if two nodes have same or similar locations, the influence probability between them tends to become larger. If one information has long time delay or has been reposted several times by users sequentially, after receiving such information, the influence probability between two users tends to become smaller. Here, the location need not be a geographic position, and it can be any profile information of nodes which can enhance the social interactions between nodes. For example, when the nodes represent academic authors, the affiliation or research area information can be the “location.” The time need not be a real time either, and it can be any value about the information which can affect the interests for the information of nodes. For example, we can use the times that one user has received the same information to measure the “time.” Zhou et al. 6 considered only the “location” factor but not the “time” factor. Only few works focus on dynamic influence caused by those factors. Goyal et al. 7 and Leskovec et al. 8 have observed the dynamic influence cases caused by “time” factor. Leskovec et al. 8 summarized a series of interesting scenarios including the dynamic influence in social networks by experiments on real data sets. Goyal et al. 7 studied how to learn such dynamic influence efficiently. Neither of them directly focuses on the influence maximization problems under dynamic influence. Moreover, when considering dynamic influence, the algorithms designed for classical influence maximization problem are not able to be applied. This article studies the influence maximization problem under dynamic influence caused by the location and time factors.
In this article, we address the problem of diffusing information under dynamic influence in mobile social networks. Following the methods of previous works, we also use influence maximization problem to describe the procedure of diffusing information over mobile social networks. To overcome the challenge of dynamic influence, we modify the classic models to support describing the change in influence under considerations of location and time factors. To solve the influence maximization problem efficiently, we study its computational complexities and design efficient algorithms. The main contributions can be summarized as follows:
We identify the dynamic influence as new challenges of information diffusion on mobile social networks. To overcome them, we propose new information diffusion (ID) models to support dynamic influence and formulate the new influence maximization problem based on new model.
We show the hardness for influence maximization problem under dynamic influence. It is achieved by proving that classic influence maximization problems is a special case of the new problem.
We design efficient approximation algorithms for the new influence maximization problem. By showing the monotone and submodular properties of the new problem, a (1 − 1/e) approximation algorithm can be obtained.
More efficient approximation algorithms for the new influence maximization problem are designed. Also, several optimizing strategies are discussed.
The experimental results on real data sets show that the proposed method can solve the information diffusion problem with dynamic influence on mobile social networks.
The rest parts of the article are organized as follows. In section “Related work,” the related works are discussed. Then, some preliminaries and new definitions will be introduced in section “Notations and definitions.” In section “Approximation algorithm for IMD problem,” theoretical analysis and approximation algorithms for influence maximization problems are introduced. Also, an improved algorithm is given in section “Improving Algorithm G
Related work
The influence maximization is an important problem in the research area of online social networking, which has many applications such as viral marketing and computational advertising. It is first studied by Domingos and Richardson,9,10 and the formalized definitions and comprehensive theoretical analysis are given by Kempe et al. 2 The standard formal definition of influence maximization can be explained as follows: given the constraint that at most k nodes can be selected, the input is a graph which represents the “influence” relationships between nodes, the problem is to compute a set of k nodes such that the number of nodes influenced by the k nodes is maximum. Different models have been formally defined to simulate the information propagation processes with different characteristics, and the two most popular models are the independent cascade (IC for short) and linear threshold (LT for short) models. In the work by Kempe et al., 2 the influence maximization problems under both IC and LT models are shown to be NP-hard (non-deterministic polynomial-time hard) problems, and the problem of computing the exact influence of given nodes set is shown to be ♯ P-hard problem in the work by Chen et al. 1
Many research efforts have been made for the problem of finding the node set with maximum influence. Kempe proposed an algorithm for influence maximization based on greedy ideas which has constant approximation ratio (1 − 1/e). The time complexity of the greedy approximation algorithm of influence maximization is O(n2(m + n)), which is too high to be applied in large-scale social networks. To overcome the shortcomings of greedy-based algorithms, many researchers focus on the problem of influence maximization. By studying the submodularity characteristics of influence functions, Leskovec et al. 11 proposed CELF (cost-effective lazy-forward) algorithm. CELF can improve the performance of greedy-based algorithms for influence maximization by reducing the times of evaluations of influence set of given seed set; however, its performance on large-scale data is still not satisfying. Using the similar ideas, CELF++ is proposed to improve the performance of algorithms for solving influence maximization by Goyal et al. 12 In the work by Chen et al., 3 degree-discount algorithm is proposed to improve the performance of greedy-based influence maximization algorithms. By assuming all influence probabilities are same in IC models, Chen et al. 3 reduce the complexities of influence maximization problems and give better algorithms based on the new models. Utilizing the structural properties of communities in social networks, Chen et al. 13 proposed new algorithms by merging similar nodes and reduce the cost of computing influence set. Goyal et al. 14 proposed SIMPATH algorithm in LT model which improves the performance of greedy-based influence maximization algorithm in LT model. Jiang et al. 15 proposed simulated annealing-based influence maximization algorithms.
Kimura and Saito 16 proposed new models of information propagation based on the idea of finding shortest paths, which assume that the information is mainly transferred through shortest paths, and designed new heuristic algorithms for influence maximization problems. Using this model, Chen et al. 1 proposed heuristic algorithms based on maximum broadcast paths, which assume that the information propagated on the network is not transferred by shortest path but maximum broadcast paths. Based on the influence probabilities between users, for each single node, an influence tree is built by computing the maximum broadcast paths, which can be used to estimate the influence range of each user. By assigning threshold for each user, the influence tree can be controlled to ignore nodes which contribute little for the computation of influence set and reduce the size of nodes computed by the influence computation. Also, Chen et al. 1 proved the submodularity of influence functions defined based on maximum broadcast paths and designed approximation algorithms with 1 − 1/e approximation ratio. In the work by Han et al., 17 timeliness networks with opportunistic selection are investigated and the information maximization model is extended to those applications. In the work by Shi et al., 18 maximal time bound is considered to limit the abilities of diffusing information in social networks, and efficient algorithms for influence maximization problem for computing maximal time-bounded positive influence set are proposed. In the work by Chen et al., 13 similarities of nodes of communities in social networks are utilized to reduce the number of nodes involved in the influence computation. Kim et al. 19 proposed efficient influence maximization algorithms in parallel computing settings. Cai et al. 20 try to extend the information maximization models to the applications of crowd-sourced data-based social networks. Han et al. 21 consider the communities in social networks and study the influence maximization problem over such networks.
There are also many works which try to extend the classic influence maximization methods to other application settings. Li et al. 22 study the problem of influence maximization under location-based social networks. In those networks, one node can be influenced by the other node if and only if they are neighbors according to their location information, and Li et al. 22 focus on the problem of finding k users which can influence maximum users in the location-based social network. Tang et al. 23 identify the relation types during propagating the information and formally define the problem of influence maximization by considering different types of relationships between nodes. A key idea is that given certain information which needs to be propagated, the influence set of some node set can be computed more efficiently by reducing those edges belonging to some certain types. Chen et al. 24 study the problem of influence maximization under topic-aware applications. Cai et al. 25 use the idea of information diffusion to prevent sensitive information in social networks. More related work on applications in social networks can be found in the works of Han et al. 26 and Bi et al. 27 Although the problem of extending classic influence maximization methods has been studied by many research works as shown above, we are not aware of any efforts on influence maximization on dynamic setting.
Obviously, the influence models are usually defined based on several parameters which are utilized to describe the key properties in real applications. The parameter selection problem is essential to the influence maximization methods. Tang et al. 5 propose topic factor graph (TFG) models to determine different parameters between users and topics. Liu et al. 4 determine different influence parameters among users using probabilistic models to analyze the relationships of distributions between topics of users and influence relations of users. Weng et al. 28 utilize the latent Dirichlet allocation (LDA) models to describe the topic distributions of user topics and propose TwitterRank methods to determine the influence probabilities between users and topics.
Notations and definitions
In this section, classical information diffusing models are introduced first; then, to integrate the two challenge aspects of diffusing information on mobile social networks, new model is proposed by modifying the classical one. Finally, based on the new ID model, we give the new definition of influence maximization problem. In fact, the problem of influence maximization depends on the definition of diffusing models. For all diffusing models, the related influence maximization problems are based on the same idea, but they are different on the aspect of computational hardness.
Traditional ID models
In this article, information diffusion can be described as the propagating procedure of information over some network. A network is usually denoted by a graph G(V, E). Here, V is the node set where each node represents one person or entity and E is the edge set where each edge represents the relation (cooperation, friends, enemies, and so on) between two nodes. Each node is associated with active or inactive state. Intuitively, the active state means that the node has been affected. The active set of nodes may affect the nodes in inactive set, and the influence ratio can describe the strength of that affection. If some inactive node is affected by some active node so much that the inactive becomes active, such a process is called activation. Intuitively, for some node v, the more of the neighbors of v are activated, more likely v will be activated. After that, v will affect more nodes further. As such procedures repeat, more and more nodes will become active. The procedure of activation cannot be reversed: one node can transform from inactive state to active state, but not vice versa. To design proper theoretical model to describe information diffusion in real world, the key is to explain how the interactions between nodes work. Next, we introduce two popular ID models.
LT model
Given a network G(V,E), let N(v) be the set {u|(u,v) ∈ E}. For each (u,v) ∈ E, a threshold value buv is utilized to represent the degree of influence from u to v. For each node v, it is satisfied that
IC model
IC model is a probabilistic model. Instead of buv in LT model, this model uses puv to describe the probability that u can activate v in a single activation. The whole procedure of information diffusion under IC model can be described as follows. First, an initial node set S0 will be set to be active. Then, in the ith step, every node will try to activate their neighbors. In detail, for each node u∈Si − 1 and node v∈V\Si − 1, if (u,v) ∈E, v will be activated once with probability puv. If v indeed becomes active, it will be added to Si and not be further considered in current step. Repeat this procedure until that no new nodes are added. It should be noted that puv is only determined by u and v and is independent with other node pairs. In this model, each edge (u, v) will be considered only one time. Once it fails, this edge will never be considered. In the work by Kempe et al., 2 an extended model in which puv will be decreased as time goes by is considered.
New model for diffusing information
All previous models for information diffusion do not consider dynamic influence; this part will propose a new model integrating both “location” and “time” factors which are major sources of dynamic influence in mobile social network.
ID model for dynamic influence
In ID model, the mobile social network can be represented by a graph G = (V, E). Here, V is the node set and E is the directed edge set which represents the influence relationship between nodes in the network. Intuitively, if there is an edge (u, v) ∈ E, it says that v can be influenced by u. That is, if u has been influenced, v also may be influenced through the edge (u, v). We use a function
To integrate the dynamic influence caused by “location” factors, we use the function
To integrate the dynamic influence caused by “time” factors, we use the function
Therefore, in ID model, to describe the information diffusion on some mobile social network, we need one four-tuple 〈G, P, L, C〉 .
In ID model, given the network 〈G = (V, E), P, L, C〉 and seed node set A and a threshold 0 ≤ θ ≤ 1, the information diffusion process working in discrete time can be explained as follows. Here, we use t0, t1, … to represent the discrete times. Initially, at time t0, all nodes in A will become active and inserted into the set Z, and all other nodes will be initialized to be inactive. At time ti, all active nodes will try to activate their “new” neighbor nodes which are met first time at time ti. In detail, suppose node u is active and v is an inactive new met node of u, that is, u and v did not meet before ti. If luv ≥ θ, the node u will try to activate v in two steps. First, generate a random value x1 between 0 and 1. If x1 ≤ luv, the node v will be activated with probability
The idea of integrating dynamic influence into information diffusion procedure can be explained as follows. The function L measures the location similarity between two nodes. If they are similar, v will become active with probability higher than the original puv. It can be used to describe the case that one node tends to be influenced by the nodes “nearby.” The function C measures the decrease in influence caused by time delay. When considering the “time” factor, node v will try to be activated with probability lower than puv. In real applications, using this model needs choosing proper values for the parameters used which can be solved by sophisticated learning methods. The problem of choosing values for the parameters has beyond the scope of this article. Furthermore, we have the following observations.
Observation 1. Without function C, node v will be activated by u with probability luv + (1 − luv)puv which is larger than puv.
Observation 2. Without function L, node v will be activated by u with probability
Let us consider a real example of ID model shown in Figure 1.

ID model for mobile social network and its possible worlds: (a) original graph G, (b) possible world G1, (c) possible world G2, and (d) possible world G3.
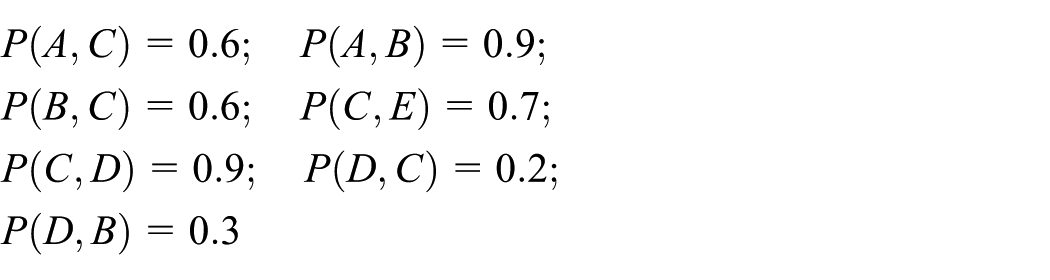
The definition of function L is as follows
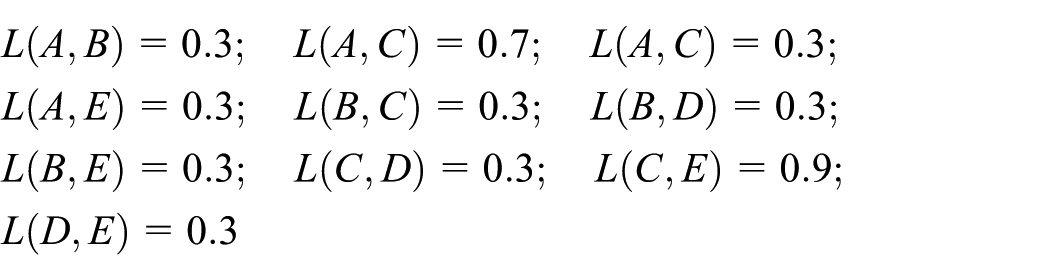
The definition of function C is as follows
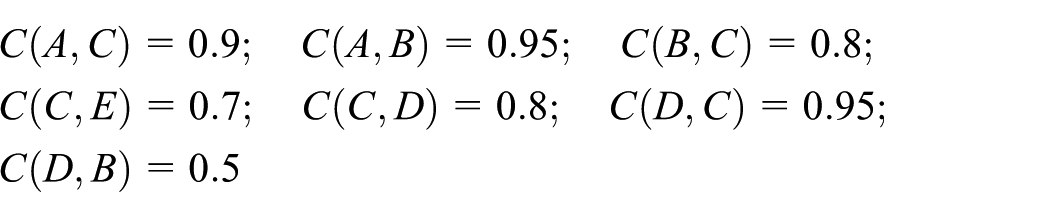
Given {A} as the seed node set and the threshold θ = 0.6, an example of information diffusion procedure is shown in Figure 2. In the first step t0, node A will be initialized to be active and no edges will be processed in this step. In the second step t1, two edges connected with A will be processed. For (A, C), since lAC = L(A, C) = 0.7 > θ = 0.6, node C will be tried to be activated in two steps. First, assume that the random value generated is 0.85. Because 0.85 > lAC = 0.7, C will be activated with probability
t 2- {(C, D) : pCD · cCD = 0.72}, {(C,E): lCE > θ, random value = 0.85 > lCE, cCE = 0.7}
t
3- {(D, C) : not processed},
t 4- {(B, C) : not processed}
t 5- {no edges left}

Information diffusion procedure on ID model.
In steps t3 and t4, the edges (D, C) and (B, C) are not processed because C has become active in t1. In t5, all edges have been processed and the procedure of diffusing information is finished. Finally, the nodes {A, B, C, D, E} are influenced by the seed set {A}.□
Influence maximization problem on ID model
Based on the observations of ID model above, it is easy to find that we can partition the result set Z to several disjoint subsets {Z0, Z1, …} according to the time when nodes in Z become active. Also, if we consider the procedure of information diffusion on ID model as a breadth-first traversal on directed graph G, {Zi} is obtained by partition Z using the depth of each node.
The object of general influence maximization problem is to maximize the node set influenced by the seed node set. Obviously, in ID model, information diffusion is a probabilistic process, in which node can become active during the procedure is uncertain. Therefore, we need to understand the procedure based on possible world semantics.
Let Ω be the set of all different possible worlds of given ID model. In fact, each possible world X ∈ Ω can be determined uniquely by giving assignments to all probabilistic variables in the information diffusion. For special G = (V, E), if we do not consider the seed node set, the number of possible worlds is 2|E|. For more, for given seed set A, let GA be the induced graph of G on node set A, EA be the set of edges in GA, and the number of all possible worlds should be
It should be noted that in ID model, two different processes may reach the same possible world. Therefore, the probabilities of each single process and possible world are different. Formally, given an information diffusion process M, let S be the set of edges processed during M, then the probability

Let

Therefore, by combining those probabilities, we have

Obviously, not all edges in G should be considered since there are some edges not visited during the information diffusion procedure because of the topology structures.□
Usually, we use the function σ(·) to represent the influence range of given seed node set. That is, given seed set A, σ(A) will be the nodes which become active after diffusing the information based on A. Observing the above procedure of information diffusion, for each single process, we have σ(A) = Z. However, the diffusion process is a probabilistic one, we need a definition based on possible world semantics.
It can be found that for each possible world Gi, its node size is just the node set which can be influenced by A.
In the following parts, we will use IMD (influence maximization under dynamic influence) to represent the influence maximization problem on ID model.
Approximation algorithm for IMD problem
In this section, first, the computational complexity of IMD problem is studied which indicates that it is intractable and should be solved by approximation or randomized ways. To design approximation algorithms for IMD problem, the ID model proposed above is simplified to reduce possible worlds of the model and integrate dynamic influence. Finally, an approximation algorithm is proposed and formal analysis shows that the approximation ratio can be efficiently bounded.
Hardness of solving IMD problem
Since the influence maximization problem on classic models is usually NP-hard and approximation and heuristic algorithms are often needed, we first consider the computational complexities of IMD problem.
For IMD problem, we can prove that they are NP-hard by making a direct reduction from the classical influence maximization problem on IC model in the work by Kempe et al. 2 Given a classical influence maximization instance I, by setting the parameter cuv = 1, luv = 0 for every (u, v) and θ = 0, it is easy to obtain the corresponding instance I′ of IMD problem. Furthermore, it can be easily verified that there are bijective maps between the solutions of I and I′. Therefore, IMD problem is NP-hard.
Simplifying the ID model
By Example 3, it is easy to find that the computation of possible world probability is tricky and it is hard to process in solving IMD problem. In this part, we propose a method to simplify ID model by integrating the L function with ID model.
Given an instance I = 〈G, P, L, C〉 of ID model, we can build another instance I′ = 〈G, P′, L′, C〉 as follows:
Let the threshold be θ.
For each edge (u, v) ∈ EG, if luv ≥ θ, let
For each edge (u, v) ∈ EG, if luv > θ, let
For each edge (u, v) ∈ EG, let l′(uv) = 0.
After such transformation, the new instance will only contain zero-value L function, in fact, we can delete the L function in I′.
While in I′, since L′ value is 0, for any edge (u, v), the value
Obviously, all edges in the possible world have same probabilities to be chosen. Therefore, each possible world in I and I′ has same probabilities. Finally, the distributions of possible worlds of I and I′ are same.
As shown above, the ID instance after transformation has zero-value L function; therefore, we can ignore the L function in the following discussions and only use 〈G, P, C〉 to represent the instance of ID model. For more, given any instance I = 〈G, P, L, C〉 and threshold θ, the transformation can be finished in polynomial time cost.
Efficient approximation algorithm
According to Theorem 1, it is almost impossible to solve IMD problem in polynomial time; therefore, in the following parts, our aim is to find efficient approximation algorithms with performance guarantee. As shown in the work by Kempe et al., 2 monotone and submodular properties allow us to develop greedy algorithms to achieve (1 − 1/e − ε) approximation ratio. Here, given function δ(·): 2 V →R, δ is called to be monotone iff δ(S1) ≤ δ(S2) for any S1 ⊆ S2, it is called to be submodular iff δ(S1⋃x) − δ(S1) ≥ δ (S2⋃x) − δ(S2) for any S1 ⊆ S2. Therefore, in the following parts, we will try to utilize such strategies to design efficient approximation algorithms for the influence maximization problems in this article.
We proposed an algorithm based on greedy idea which can produce approximation algorithms with ratio 1 − 1/e as shown by Fisher et al.
29
The algorithm is shown in Figure 3. The Algorithm G

Algorithm G
In the G
Finally, based on the observation that the main procedure of Algorithm 3 is to iterate among all nodes and the G
Analysis of Algorithm Greedy IMD
In this part, we will show that Algorithm G
First, we introduce another kind of view of the information diffusion on ID model. According to the results in the work by Kempe et al.,
2
an equivalent view of information diffusion process on IC model is as follows: each edge (u, v) of G is identified to be live independently with probability puv and blocked otherwise. Therefore, we can use different assignments of live and blocked states of the edges to represent different results of information diffusion on IC models. Moreover, Kempe et al.
2
have shown that they have same distributions. Here, we can also use the similar view of information diffusion process on ID model. For each edge (u, v) of G, (u, v) is identified to be live with probability
Second, we introduce a new representation for the influence function δIMD(·). According to the definition of δIMD, we have

where F(G, A) represents the size of influence node set of A on network G with fixed choices of P and C, and f(G, A, v) is 1 or 0 which represents whether node v is in the influence node set of A on G.
In equation (1), given network G, we use XG to represent the set of all different live-blocked assignments on EG and x to represent some special assignment of EG. Given x ∈ XG, we use Gx to represent the graph obtained from G by deleting blocked edges. It should be noted that, even for same x, the probabilities of the assignments of EG on different seed sets A are different. We use
In the following, we will show the monotone and submodular property of δIMD.
Naturally, it is hoped that


An example of
For another example, let us modify the original graph G into H as shown in Figure 4. Similarly, we have

Finally, we can obtain the result that
Since
Observing that those combinations of v and x such that g(G, x, A, v) = 0 have no contributions to the final result of δIMD(A), we can reform the representation of δIMD(·) as follows

Here, we use
The set
Based on the above observations and equation (4), δIMD(A) is monotone.
Using the similar idea of the proof of Theorem 2, let us consider equation (4), we will explain the proof based on the function
The first case is that u cannot be directed to v. That is, there are no paths from u to v in G. Obviously, the addition of u will not add the paths between seeds set and node v, and u will not increase the
The second case is that there are paths between u and v. It should be noted that the topology structure constructed by the information diffusion procedure is in fact a tree and the edges between trees are eliminated by the mechanism that every node can be activated at most once. Therefore, we can divide all kinds of paths into three types: the path started from S1, the path started from S2, and the path started from u. We use P1, P2, and Pu to denote them, respectively. The value of
By combining the above two results and equation (4), we have δIMD(S1⋃u) − δIMD(S1) ≥ δIMD(S2⋃u) − δIMD(S2).
Improving Algorithm Greedy IMD
In Algorithm G
Based on the idea above, propose improved version of

Algorithm for getting influence.
Experimental evaluation
Based on real data sets, we evaluate the performance of Algorithm G
Experiment setup
We ran our experiments on four real data sets, whose summary information is shown in Table 1. The digital bibliography & library project (DBLP) data set is a large network of research collaboration maintained by Michael Ley. In the network of DBLP, the nodes represent the authors of academic papers and there exist one edge between two nodes if and only if the two corresponding authors have collaborations. For DBLP, we use the coauthor relationships to compute the influence probability between two authors. Twitter is the network composed of twitters and the tweets posted by them, which is the most popular micro-blogging system in the world. In this network, the nodes represent the twitters and the edges represents the “following” relations between them. For Twitter, we use the repost actions to compute the influence probability. Epinions is a network built by who-trust-whom relations. In this network, nodes represent the users and the edges between them represent the trust relation. We use the metadata about trust relation to compute the influence probability. Wikivote is the data about voting administrator on Wiki. In this network, the nodes represent the wiki users and the edges represent the voting relation. We use the metadata about voting actions to compute the influence probability.
Statistics of real data sets.

Experimental results and analysis
We compare the algorithms proposed in this article on qualities of seed sets and running time costs based on the four real data sets.
We use different parameters of L and C to run the experiments. Here, given a constant c, the value of function C on each edge is generated randomly with following Poisson distribution. Similarly, L values are generated randomly for each pair of nodes. In the following parts, we use MID-A to represent the G
Effects of seed sets
The effect of given seed set can be evaluated by the influenced nodes size. On four data sets, we compare four algorithms with different parameters on seed node sets with different sizes. The results are shown in Figure 6. It can be observed that as the size of seed nodes set increases, the size of influenced nodes increases almost with linear speed. The result is expected since in a large enough network, all nodes tend to perform uniformly during the information diffusion. Also, it can be found that when increasing the value of L and C functions, the size of influenced nodes set gets larger. Actually, when L becomes larger, essentially it increases the probability of influence, thus the size of influenced set will get larger. When C becomes larger, it reduces the decreasing speed of time delay parameters and the size of influenced set will also gets larger. This is because that the two parameters are used to control the influence abilities of the set of seed nodes, which will be much clearer in the following experimental results.

Influence spread against seed set size on four data sets: (a) DBLP, (b) Epinions, (c) Wikivote, and (d) Twitter.
Effects of function L
The effect of function L is evaluated by the influenced nodes size. On four data sets, fixing the size of the seed nodes to be 20, we compare four algorithms with different L function values. The results are shown in Figure 7. It can be observed that as the value of L increases, the size of influenced nodes increases. When the L value increases, the increasing speed of influenced nodes set becomes slow. In fact, the effect of L values is to increase the original influence probability in a proper level; therefore, when the L value becomes much larger, the increasing speed of influence set size will get slow. Also, it can be found that for fixed L value, when we scale C from 0.2 to 0.8, the size of influenced nodes set gets larger.

Influence spread against value of L on four data sets when seeds set size is 20: (a) DBLP, (b) Epinions, (c) Wikivote, and (d) Twitter.
Effects of function C
The effect of function C is evaluated by the influenced nodes size. On four data sets, fixing the size of the seed nodes to be 20, we compare four algorithms with different C function values. The results are shown in Figure 8. It can be observed that the results are similar to the results of L function. It should be noted that when the value of C is relatively small, the increasing trend of size of influenced nodes set is more sharp than the results in L function. It depends on the working mechanism of L and C. L is used in linear way in the diffusing information procedure, while C is used in exponential way.

Influence spread against value of C on four data sets when seed set size is 20: (a) DBLP, (b) Epinions, (c) Wikivote, and (d) Twitter.
Running time
For two data sets, we ran the original greedy algorithm and improved greedy algorithm proposed in this article for different sizes of seeds set. The running time results are shown in Figure 9. It can be found that as the size of seeds set increases, the running time cost also increases; when seed node size becomes larger, the increasing speed of running time cost becomes slow. Also, we can find that the improved algorithms are three times in average faster than the original algorithms. This is because of the reduction in computation cost and optimizing strategies.

Running time against seed set size on two data sets: (a) DBLP and (b) Twitter.
Conclusion
In this article, based on the observations of information diffusion process on mobile social networks, the ID model for diffusing information under dynamic influence is proposed. By theoretical analysis, we determine the complexities of solving influence maximization on the new model and design efficient algorithms with approximation performance guarantee. By experiments over real data set, the performances of ID model and the algorithms proposed are verified. One possible further question is how to design more efficient algorithms for dynamic influence in social networks. Another question comes from the methods of modeling dynamic influence in this article. Obviously, our methods cannot cover all possibilities of dynamic influences, and we need to investigate more typical representations for dynamic influences and study how to design algorithms for the related influence maximization problem.
Footnotes
Academic Editor: Zhipeng Cai
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Basic Research Program (973 Program) of China via grant 2014CB340503, the National Natural Science Foundation of China (NSFC) via grant 61472107 and 61632011, the National Social Science Foundation of China via Grant 14CXW045, the Research Project for Humanities and Social Science of the Ministry of Education of China via grant 13YJC860013 and the Heilongjiang Social Science Foundation via grant 12D062.