
Abstract
Network virtualization technology allows the creation of virtual networks that reflect the requirements of various services and distribute resources of a physical network among virtual tenants. Recently, the virtualization of physical networks through software-defined networking technology has become a popular method. OpenVirteX is a software-defined networking-based network virtualization platform that can create multiple virtual and programmable networks on top of a single physical infrastructure and provide full isolation of each virtual tenant. However, some shortcomings persist in OpenVirteX, one of which is the lack of a mechanism to distribute physical network resources efficiently among the virtual tenants. In this article, we propose a novel quality-of-service management mechanism, based on the single rate three color marker proposed by the Internet Engineering Task Force. This mechanism employs two new token buckets, called global token buckets, which are used to collect idle tokens from each virtual network. Furthermore, a resource manager can redistribute the collected tokens among the virtual networks according to their weights. Finally, our work achieves a maximum improvement of approximately 1.6 times over the performances of previous mechanisms.
Keywords
Introduction
Modern computer networks have become extremely complex because many kinds of network equipments from routers and switches to middleboxes such as firewalls and load balancers are involved in the network. Accordingly, the management of an entire network has become a laborious and time-consuming work. For example, routers and switches run complex, distributed control software that is typically closed and proprietary so that network administrators configure these devices only through their proprietary configuration interfaces. Moreover, these configuration interfaces are not uniform and vary across equipment manufacturers. This complex and hand-operated management mode tremendously increases operational costs of running a network and is difficult to adapt to the increasing network scale. One of the ways to solve these issues is to make computer networks more programmable. 1 Software-defined networking (SDN) is an emerging architecture that is dynamic, manageable, cost-effective, and adaptable, making it ideal for the high-bandwidth dynamic nature of present-day applications. 2 The core concepts of SDN 3 can be summarized as follows: (1) SDN decouples the control plane from the data plane so that network elements can concentrate on handling the traffic and (2) SDN consolidates the control plane so that a single software control program controls the data plane of multiple network elements. Figure 1 illustrates the difference between a legacy network infrastructure and an SDN infrastructure. Namely, in the legacy network infrastructure, the plane responsible for packet forwarding (i.e. the data plane) and the plane responsible for routing (i.e. the control plane) are integrated into a single network element. In this infrastructure, because all of the functions are dependent on the real hardware, it is almost impossible for network administrators to change the behavior of the network core unless the network administrators alter the devices’ configuration manually. In contrast, the SDN infrastructure separates the control plane from all network elements and integrates them into a centralized server, which is called the controller. Furthermore, it provides a set of well-defined protocols and application programming interfaces (APIs) for the communication between the controller and the network elements, which allows administrators to customize the network through software applications running at the controller. This feature provides network administrators with a new method for controlling and managing the entire network more easily and it is not necessary to alter the devices’ configuration manually, which greatly reduces the costs of network management. At present, the typical and de facto standard protocol for communication between the controller and the SDN elements is OpenFlow. 4 OpenFlow was developed by Stanford University and initially used for research. Now, it has become an open standard that can be freely developed or implemented.

Legacy versus SDN: (a) legacy network infrastructure and (b) SDN infrastructure.
An outstanding feature of SDN is flexibility. To demonstrate the flexibility issues existing in the legacy network infrastructure, we consider the case of the quality of service (QoS). QoS allows routers to prioritize the forwarding of specific data packets according to their characteristics, scheduling demands, and so on, and this reduces data transfer delays resulting from network congestion. For instance, delay-sensitive voice and video traffic are usually designated with high-priority forwarding to ensure a good user experience. Traffic prioritization is typically decided based on the class of service (CoS) of an L2 frame or differentiated services code point (DSCP) of an L3 packet. These frames or packets must be determined prior to entering the core network. These demands seem arbitrary, because every node device must configure the same information and the administrators should configure all ports of every forwarding device manually. These processes are very time-consuming and easy to get wrong. Furthermore, other challenges exist in legacy networks. For example, we assume that two types of traffic coexist in a network, namely, internet small computer system interface (iSCSI) and voice. In general, the packet size of iSCSI traffic is usually full scale, while voice traffic is always composed of small packets. Voice traffic is sensitive to delay, while iSCSI traffic is not, but it requires more bandwidth. In legacy network infrastructures, there is almost no way to distinguish between them and select a suitable datapath to meet their specific demands.
In addition, bringing new services into today’s networks is becoming increasingly difficult due to the proprietary nature of existing hardware appliances, the cost of offering the space and energy for a variety of middleboxes, and the lack of skilled professionals to integrate and maintain these services. 5 Network function virtualization (NFV) was recently proposed to tackle these problems. NFV mainly implements various hardware-based network functions such as router and firewall, and network address translation (NAT) as software-based solutions and runs them in virtual machines on general-purpose platforms (e.g. x86 platform). NFV and SDN are always complimentary. For example, an SDN controller may be implemented as part of a service chain. This means that the centralized control and management applications (such as load balancing, monitoring, and traffic analysis) used in SDN can be realized, in part, as virtual network functions (VNFs), and hence benefit from NFV’s reliability and elasticity features. 6
Although SDN and NFV solve the flexibility problems, further issues remain. Currently, Internet-of-Things (IoT) and machine-to-machine (M2M) technologies facilitate the networking of almost all types of non-PC devices. Accordingly, the basic framework of modern networks has not significantly changed, and it has become ossified and difficult to adapt to diverse devices. These devices may include some low-power sensors with very limited computing and storage capacities, and the original network protocol stack probably cannot be applied to them. In addition, future network services will also have more stringent requirements, such as some services requiring closed networks that must be entirely separated from other services, or services requiring a certain amount of network resources to function normally. The most significant trend is massive data centralization, and the scale of servers in data centers is growing rapidly. Alongside, the increase in costs of these servers, the costs of hardware and managing large numbers of servers simultaneously are also increasing. Thus, it is unrealistic for each service to construct a proprietary network. Virtualization has emerged as a candidate to solve these problems. Virtualization refers to creating a logical entity through multiple physical entities, or creating multiple logical entities on a single physical entity. An entity may be a computing, storage, network, or application resource. Virtualization is the essence of isolation, which allows different businesses to remain isolated and unable to access one another. Figure 2 illustrates a case of network virtualization. In this case, two virtual networks (also called logical networks or tenants) are created on a single physical network. The two virtual networks are isolated, and neither can be accessed by the other. By allowing multiple heterogeneous network architectures to cohabit a shared physical substrate, network virtualization provides flexibility, promotes diversity, and promises security and increased manageability. 7 Now, intense discussions indicate that SDN is emerging as one of the most promising technologies for making networks programmable and virtualizable, 8 and some of the typical SDN-based network virtualization platforms proposed so far include FlowVisor, 9 OpenDaylight, 10 and OpenVirteX (OVX). 11 These network virtualization platforms can achieve the construction and isolation of virtual networks. However, some problems still exist. For example, each virtual tenant may have different objectives. Some virtual tenants are used for providing VoIP services and are always required to satisfy stringent jitter and delay constraints. In addition, some are used for safety-critical system applications, such as remote surgery, and are required to ensure their reliable availability. Furthermore, some virtual tenants are assigned considerable bandwidth but consume only a small amount, whereas some virtual tenants may suffer from insufficient bandwidth because of burst traffic during the same period, which can be described as the resource allocation problem. However, almost all types of network virtualization platforms provide only a best-effort service model to serve their virtual tenants. That is, they do not provide any guarantees that data will be delivered or that a user will be given a guaranteed QoS level or a certain priority. Obviously, this is not sufficient to satisfy most types of service demands.
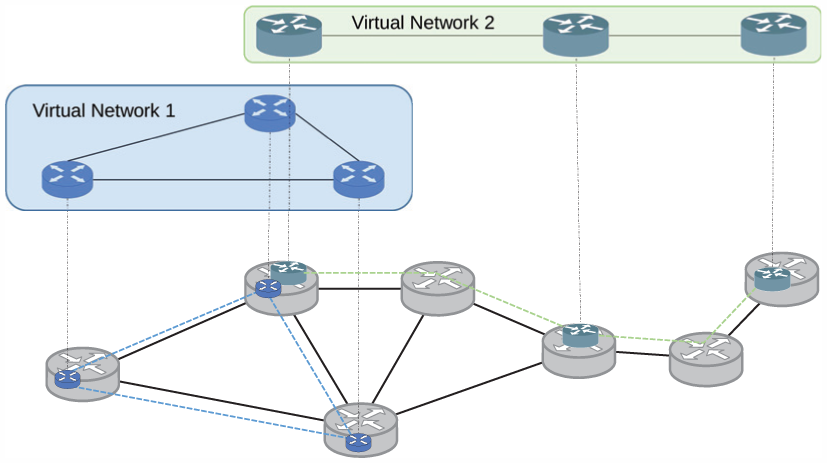
Network virtualization.
To solve issues regarding QoS, Internet Engineering Task Force (IETF) proposed two types of QoS model: IntServ 12 and DiffServ, 13 in 1994 and 1998, respectively. Here, the IntServ model is an integrated service model that can accommodate diverse QoS requirements, but it involves considerable equipment requirements, and the processing and storage capabilities of the device will encounter great pressure when network traffic becomes heavy. Thus, the scalability of the IntServ model is poor, and it is difficult to implement in core networks. In contrast, DiffServ overcomes the shortcomings of the IntServ model. DiffServ is a multiple-service model that can satisfy diverse QoS requirements. Unlike IntServ, it does not need to notify the network to reserve resources for each business, which makes it scalable and simple to implement.
In this article, to solve the resource allocation issues in network virtualization, we propose a traffic-aware QoS control mechanism for SDN-based virtualized networks. Through this work, physical network resources can be allocated and redistributed effectively among virtual networks according to how their traffic changes. Our work consists of two parts: a packet-marking mechanism working at the data plane and a management mechanism working at the control plane. Specifically, the data plane is implemented on the basis of open-source virtual-switch software, such as Open vSwitch (OVS). 14 Benefiting from NFV’s elasticity feature, our work can be seen as a virtual appliances that can be instantiated on demand without the installation of new equipment.
The remainder of this article is organized as follows. In section “Related works,” related studies regarding SDN, network virtualization, DiffServ, and autonomic networks are discussed. Section “System design” is mainly devoted to giving an account of the system design. Section “Implementation” is focused on the implementation details of our work. Experiments are presented in section “Experiments and performance evaluation,” and finally, the work is concluded in section “Conclusion.”
Related works
An SDN-enabled network can easily be sliced or virtualized into several parts for different purposes through programming. For instance, we can instantiate three virtual networks: one for research, one for business, and the other one for industry. Thus, SDN and network virtualization technology are widely employed for applications such as cloud data centers or big data analysis. Recently, several approaches based on SDN have been proposed for QoS management and network virtualization. In recent research, Egilmez et al. 15 proposed a novel OpenFlow controller design for multimedia delivery called OpenQoS. This mainly provides its APIs for the purpose of users performing route planning. Caraguay et al. 16 also focused on multimedia delivery in an SDN environment. They analyzed issues regarding best-effort-oriented IP networks and proposed a QoS routing algorithm for delivery such that multimedia streaming satisfied QoS service requirements. Both these approaches provide QoS only through packet routing, and no fine-grained QoS strategies are involved. Drutskoy et al. 17 proposed an SDN-based network virtualization framework, where SDN technology is used to offer a standard interface between controller applications and switch-forwarding tables.
Differentiated services (DiffServ) is a networking architecture that specifies a mechanism for classifying and managing network traffic and providing QoS on IP networks. For example, DiffServ can provide low latency to critical network traffic, such as voice or streaming media, while providing simple best-effort service to non-critical services, such as web traffic or file transfers. Usually, DiffServ uses DSCP 18 for the purpose of packet classification. As shown in Figure 3, DSCP is located at the 8-bit type-of-service (ToS) 19 field of the IP header and uses the left-most 6 bits. DiffServ relies on a mechanism to classify and mark packets as belonging to a specific class. This can be described by per-hop behaviors (PHBs), which define the packet-forwarding properties associated with a class of traffic. Different PHBs may be defined to offer, for example, low loss or low latency. DiffServ operates on the principle of traffic classification, where each data packet is placed into a limited number of traffic classes, rather than differentiating network traffic based on the requirements of an individual flow. Each router on the network is configured to differentiate traffic based on its class. Each traffic class can be managed differently, ensuring preferential treatment for high-priority traffic on the network. Usually, the complicated functions, such as packet classification and policing, are always performed at the edge of the network. That is, mark the packets to receive a particular type of PHB. And this can simplify the functionality of core routers such that core routers simply apply PHB treatment to packets based on the marking. Most networks use the commonly defined per-hop behaviors of default PHB (also called best effort or BE), expedited forwarding (EF), 20 and assured forwarding (AF). 21 Single rate three color marker (srTCM) 22 can be used as a component in a DiffServ traffic conditioner. srTCM meters a packet stream and marks its packets according to the three traffic parameters committed information rate (CIR), committed burst size (CBS), and excess burst size (EBS), as green, yellow, or red. A packet is marked as green if it does not exceed the CBS, yellow if it does exceed the CBS but not the EBS, and red otherwise. After the packets are marked, the forwarding devices can process packets according to their colors. For example, green packets can be forwarded immediately, yellow packets can be forwarded or dropped according to the link state, and red packets will be dropped directly.

Format of DSCP.
There are several early and recent research works on DiffServ. For example, to achieve guaranteed or fair-share rates in TCP (Transmission Control Protocol), Li et al. 23 present a traffic conditioner on the basis of srTCM called Rate Regulation via Early Adaptive Detection (READ), which uses the knowledge of TCP congestion control behavior to proactively regulate flow throughput in order to achieve the desired rate. However, in traditional network frameworks, this approach is difficult to implement in real network hardwares. Lee and Kim 24 proposed a QoS-aware hierarchical token bucket (QHTB) queuing discipline. This approach is similar to hierarchical token bucket (HTB), which is a queuing discipline provided by the Linux kernel. Rather than taking the approach that allows the extra bandwidth of a class to be borrowed by others, the root class controls the redistribution of unused bandwidth to the backlogged flows according to their required rates and the backlog status. Some issues also exist, for example, this approach considers only the fairness but ignores the precedence and importance of each traffic class when redistributing the unused bandwidth.
Currently, autonomic network management is a promising approach to reducing the cost and complexity of managing network infrastructures. It attempts to lead the human administrator out of the network control loop, leaving the management tasks to be performed by the network itself. 25 Bari et al. 26 noted that the concept of service-level agreements (SLA) has been utilized to establish QoS parameters, but most technologies in this area are both proprietary and inflexible. SDN can overcome these disadvantages, because it has the potential to make network management tasks flexible and scalable. Therefore, they presented a framework called PolicyCop, which is an open, flexible, and vendor-agnostic QoS policy-management framework, aiming toward OpenFlow-based SDN. Wendong et al. 27 proposed an autonomic QoS management mechanism in a software-defined network called AQSDN. This study demonstrates that various QoS features can be configured automatically through OpenFlow and OFconfig protocols.
Wang et al. 28 also proposed an SDN-based autonomic QoS model in 2015. This research mainly emphasized how to allocate network resources efficiently and intelligently among virtual networks. The authors noted that the network resources (e.g. bandwidth) allocated to each virtual network may not be used efficiently in terms of their traffic states. For example, some virtual networks may have significant idle bandwidth, because their loads are not heavy, while other virtual networks may not have sufficient bandwidth because of a traffic burst. Furthermore, packets from different services may have different weights. For example, the packets from real-time services should be forwarded prior to those from web services. Therefore, a modified srTCM and an algorithm called collaborative borrowing-based packet marking (CBBPM) have been proposed. In this research, the packets from each virtual network are classified into two classes, critical and non-critical. Then, a new token bucket is added to the marker, which is used for marking critical packets. Borrowing tokens from other virtual networks that have light loads is allowed when a virtual network does not have sufficient tokens to forward a critical packet. Thus, the idle resources of other virtual networks can be fully taken advantage of, and the performance of the holistic network can be enhanced. However, the borrowing mechanism used in the network virtualization environment has the disadvantage that it breaks the isolation of the virtual networks. For example, some virtual networks have light loads during a certain period, and their tokens may be borrowed by networks with heavy loads. However, no one can predict the traffic of the lending networks in the next period and guarantee that their packets will be forwarded smoothly. If a lending network suffers from a burst in current and its tokens were borrowed in the most recent period, then unfortunately its performance will decrease. This goes against the principle of isolation in virtual networks.
System design
Overview
To provide well-virtualized networks and overcome the shortcomings existing in past works, the main objectives and contribution of this work are as follows:
Simplicity and practicability. It should be possible to implement the functions of this work easily and simply, otherwise the proposed approach cannot be thought of as a practical solution. Fortunately, SDN could help us to achieve this objective since SDN centralizes all control planes into a single controller, which allows us to implement the functions as software running at the SDN controller.
Autonomic management. Network management is an extremely complicated task and this work is aimed at simplifying it. Thus, this approach should be able to remain fully aware of the traffic status of each virtual network and configure the networks automatically according to their traffic statuses.
Reasonable resource distribution. To achieve this, the status of each virtual network, such as traffic precedence, traffic burst duration, and resource requirement stipulated by SLA, should be fully considered when distributing the resources among virtual networks.
Isolation guarantee. Isolation is the most important principle of network virtualization. That is, the virtual networks should not be influenced by one another.
Figure 4 presents the architecture of an autonomic managed network.
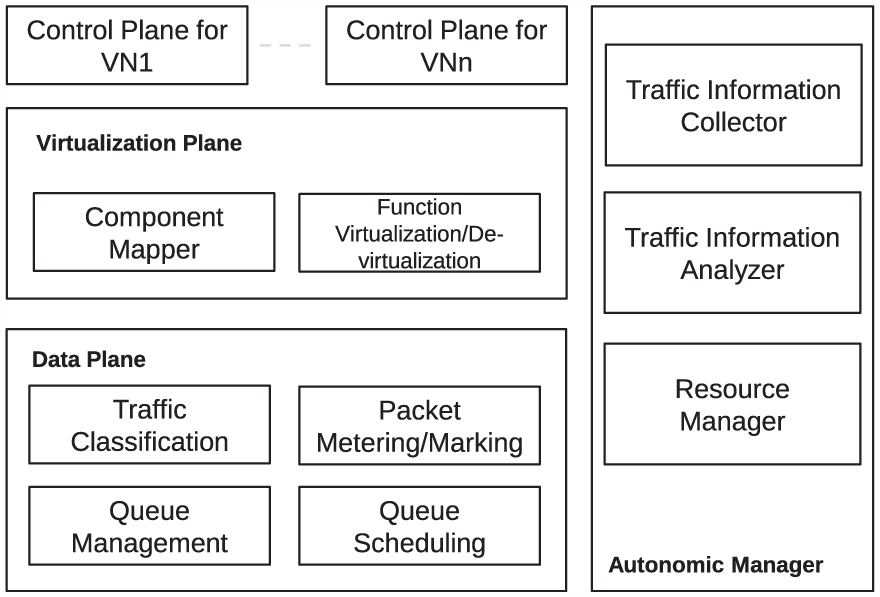
Architecture of autonomic managed network.
In this architecture, there is a virtualization plane between the control plane and the data plane, which provides the virtualization function for the control plane of each virtual network and is responsible for slicing the physical network according to the requirements of each virtual network and providing virtual network instances to the control planes. The autonomic manager is responsible for monitoring, collecting, and analyzing the traffic and resource usage of each virtual and physical network, and then redistributing the resources among all virtual networks through a resource manager. The virtual networks are not served equally, but classified into different service levels. This is achieved through the DiffServ approach. That is, the packets of each virtual network are marked as different colors in terms of the link status, and then the marked packets are inserted into the correlative queues with different precedence. Thus, we employ an extended srTCM, called srTCM with global token bucket (i.e. srTCM+GTB), to meter and mark packets from each virtual network.
srTCM+GTB
According to the description of srTCM, it has three parameters, CIR, CBS, and EBS, and two token buckets, the C bucket and the E bucket. A token is added to the C bucket every 1/CIR s. When the number of C tokens (denoted as
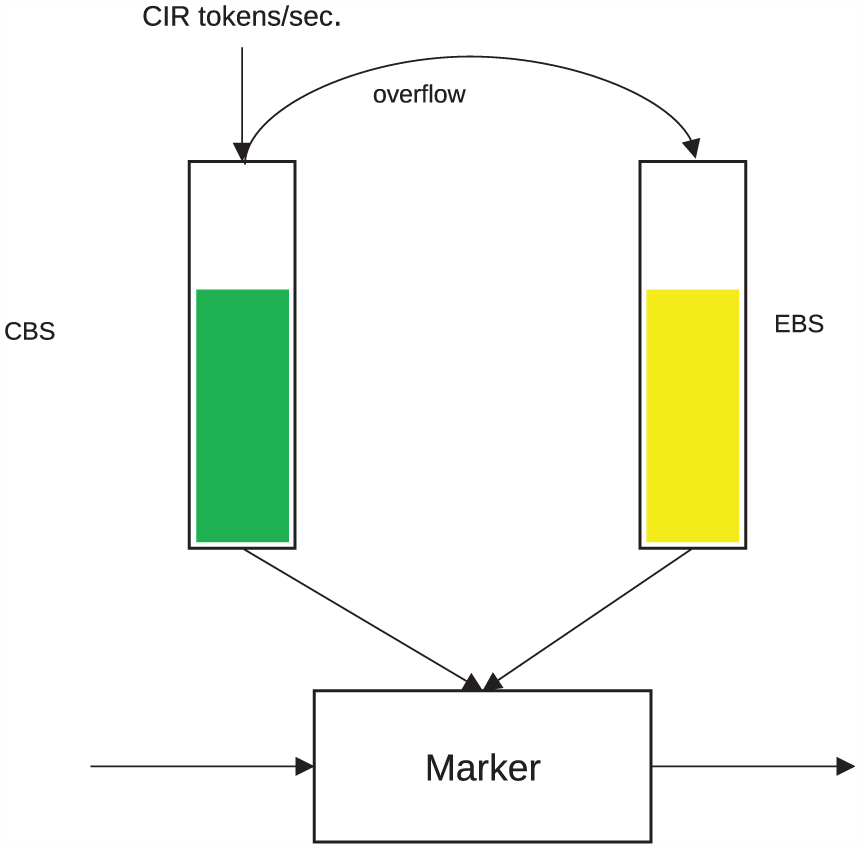
Token refill scenario of srTCM.
When a packet reaches the edge of the DiffServ domain, the srTCM first compares the packet length with the number of tokens in the C bucket (C tokens). If the number of C tokens is greater than or equal to the packet length, then the packet will be marked as green, and forwarded immediately. Then, the number of C tokens will be reduced by the packet length. If there are not enough C tokens, then the marker compares the packet length with the number of tokens in the E bucket (E tokens). If the number of E tokens is greater than or equal to the packet length, then the packet will be marked as yellow, and delayed. Then, the number of E tokens will be reduced by the packet length. Otherwise, the packet will be marked as red and dropped. In this situation, neither the C tokens nor E tokens will be reduced (Algorithm 1).

To distribute and utilize idle resources when some of the virtual networks have light traffic loads, we extend the srTCM and the marking algorithm. As shown in Figure 6, we added two extra buckets called the global C bucket and the global E bucket. These are the same as the private token buckets of each virtual network, but are not refilled automatically, and the depth of both is not fixed, but rather equal to the average depth of all buckets, that is




Token refill scenario of srTCM+GTB.
The global tokens come from overflowing buckets of each virtual network. That is, when both the C and E buckets of a virtual network are full, newly generated tokens will be added to a global bucket. Similar to private token buckets, the global tokens are added first to the global C bucket. If the global C bucket becomes full, the global tokens will be added to the global E bucket. If both global C and the global E buckets become full, the global tokens will be discarded (Figure 6; Algorithm 2). All virtual networks can acquire global tokens according to a probability assigned to them, when traffic bursts occur on them and there are not sufficient tokens in their private bucket to mark a packet. The acquisition probability for a global token will be discussed in the next section.

Resource manager
The resource manager is responsible for monitoring and analyzing the incoming data rate at the edge node of each virtual network, as well as the global token usage. Because global tokens are common resource, they should not be occupied by one or several virtual network instances. To prevent virtual networks from violating the CIR maliciously and generating burst traffic continuously, a punishment mechanism is required for the resource manager to prevent virtual networks from obtaining global tokens immoderately. Fernandes and Duarte
29
proposed a resource manager called maximum usage controller (MUC) and applied to allocate and monitor the total usage of common resources. MUC monitors bandwidth by observing the volume of bits transmitted on each physical output link. If a virtual router exceeds the allocated bandwidth in an output link, then it is punished by having its packets sent on that link dropped. Inspired by MUC, we also propose a punishment computing heuristic algorithm, to punish each virtual network and prevent them from consuming too many global resources. The algorithm pulls the data rate
If the average data rate of the incoming traffic exceeds the CIR and the percentage of remaining global tokens is lower than a set threshold

If the average data rate of the incoming traffic exceeds the CIR but the percentage of remaining global tokens is greater than the threshold

If the average data rate of the incoming traffic did not exceed the CIR, then the penalty of the virtual network will be decreased

Algorithm 3 illustrates the details of the procedure of penalty computing. After calculating the penalty, the virtualization platform sends an OpenFlow message containing the penalty to the datapath, and the datapath marks packets according to the corresponding penalty for each virtual network when using global tokens. Thus, the full packet-marking algorithm of srTCM+GTB is as shown in Algorithm 4.


Implementation
OpenFlow extensions
To support autonomic management, we extended the OpenFlow 1.0 protocol. 30 First, when a virtual network instance is created or removed, the corresponding marker should also be added or removed from the datapath. Second, the resource manager should collect the traffic statistics. Third, the calculated penalty should be conveyed to the datapath. Fourth, when a packet enters the network, it should be marked at the edge node. Thus, we added five OpenFlow extension messages and a marking action. Figure 7 illustrates the scenario of penalty updating.
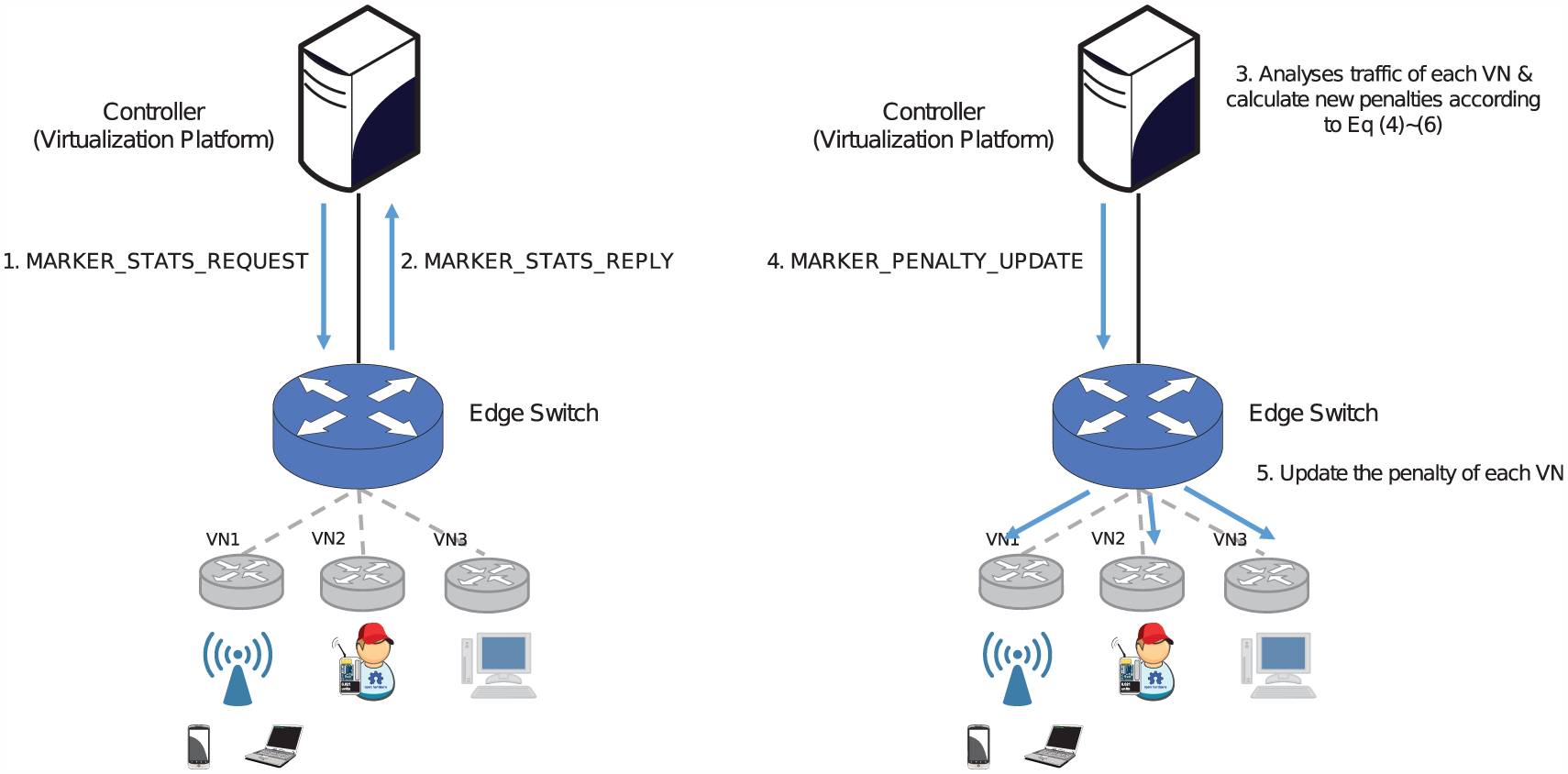
Scenario of penalty update.
Control plane
We use OVX as the virtualization platform. OVX is a network virtualization platform that is capable of spawning virtual networks with OpenFlow semantics. These virtual networks may have arbitrary topology and addressing schemes, configured as per tenant’s request. Requests are conveyed via API calls to OVX using a tool such as a network embedder.
31
The resource manager is implemented as a module of OVX. It pulls the statistical information for each marker and the global token bucket, by sending and receiving
Data plane
We implement the data plane on the basis of OVS. OVS is composed of two parts: vSwitch and datapath. vSwitch is the main process of OVS and runs as a daemon in the user space. It is mainly used for configuring the datapath and processing OpenFlow messages going in or out of SDN controllers. Datapath is a kernel module, running at the kernel space, which is used for processing packets. We implement the srTCM and global token bucket as a kernel module in the datapath. Every marker is assigned an ID, which is identical to the corresponding virtual network ID. The markers of each virtual network also record the traffic states (e.g. the total number of marked packets, and the number of packets marked as green, yellow, and red). Thus, the controller can obtain the statistical information regarding each virtual network by querying the corresponding marker and then calculating the penalty for them.
Experiments and performance evaluation
The physical topology is constructed by MiniNet.
32
Figure 8 illustrates the physical topology. Furthermore, four virtual networks are constructed on it. The four virtual networks are H1-ES1-CS1-CS2- ES2-H5, H2-ES1-CS1-CS2-ES2-H6, H3-ES1-CS1-CS2-ES2-H7, and H4-ES1-CS1-CS2-ES2-H8. We limit the bandwidth of the links ES1-CS1, CS1-CS2, and CS2-ES2 to 10 Mbit/s. The proposed srTCM+GTB runs at the edge switches (i.e. ES1 and ES2), which are used to meter and mark the incoming packets of each virtual network. At the core switches (i.e. CS1 and CS2), we employ weighted random early detection (WRED) as active queue management (Figure 9). WRED is an extension of random early detection (RED), which was proposed by Floyd and Jacobson,
33
where a single queue may have several different queue thresholds, and each queue threshold is associated to a particular traffic class. The queue can be configured using Traffic Control,
34
also called

Physical network topology.

Active queue management.
The traffic-related parameters for each virtual network are listed in Table 1. The virtual networks 1, 2, and 3 (VN1, VN2, and VN3) are mapped to the AF class, while virtual network 4 (VN4) is mapped to the best-effort (BE) class, which is used to generate background traffic. The weight of virtual networks 1, 2, and 3 are
Parameters of each virtual network.

CIR: committed information rate; CBS: committed burst size; EBS: excess burst size.
Isolation
In this experiment, we verified that our virtualization platform can isolate each virtual network from others. Isolation is a very important characteristic in network virtualization. That is, each virtual network should be isolated from the others, and the performance of one should not be affected by the others. In this experiment, we observed the throughput variation of each virtual network and compared the results with CBBPM. We made VN1, VN2, and VN3 generate traffic at 50% of their CIR for 120, 60, and 180 s, respectively. Figure 10 illustrates the results, and our work shows a better performance than CBBPM. Because
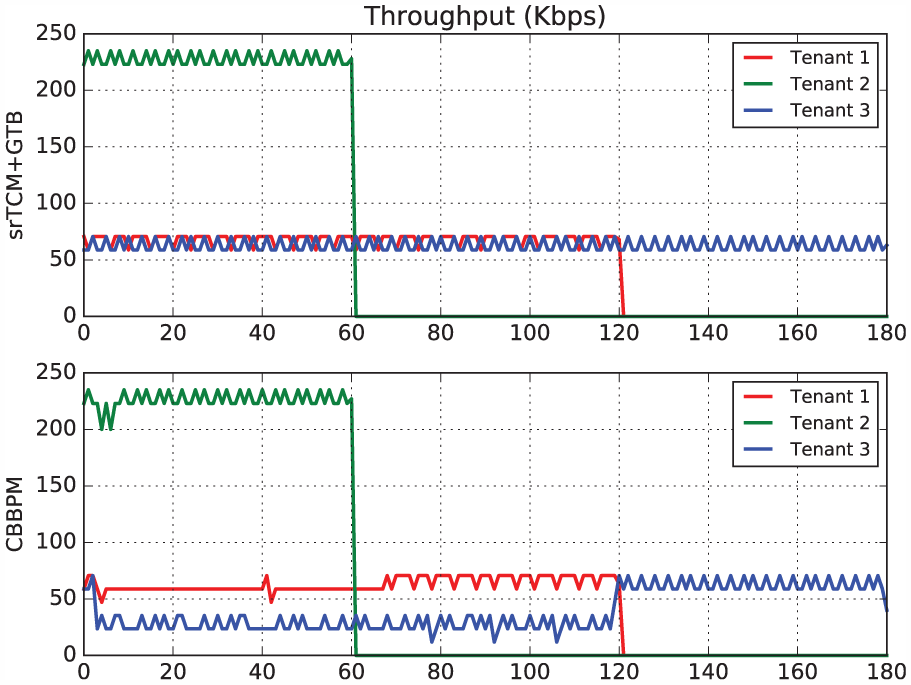
Isolation provisioning.
UDP performance
In this experiment, we evaluated the UDP performance, including the throughput and packet loss of each virtual network. Here, the traffic of VN1, VN2, and VN3 was generated randomly, and modeled with the Pareto distribution

Here,
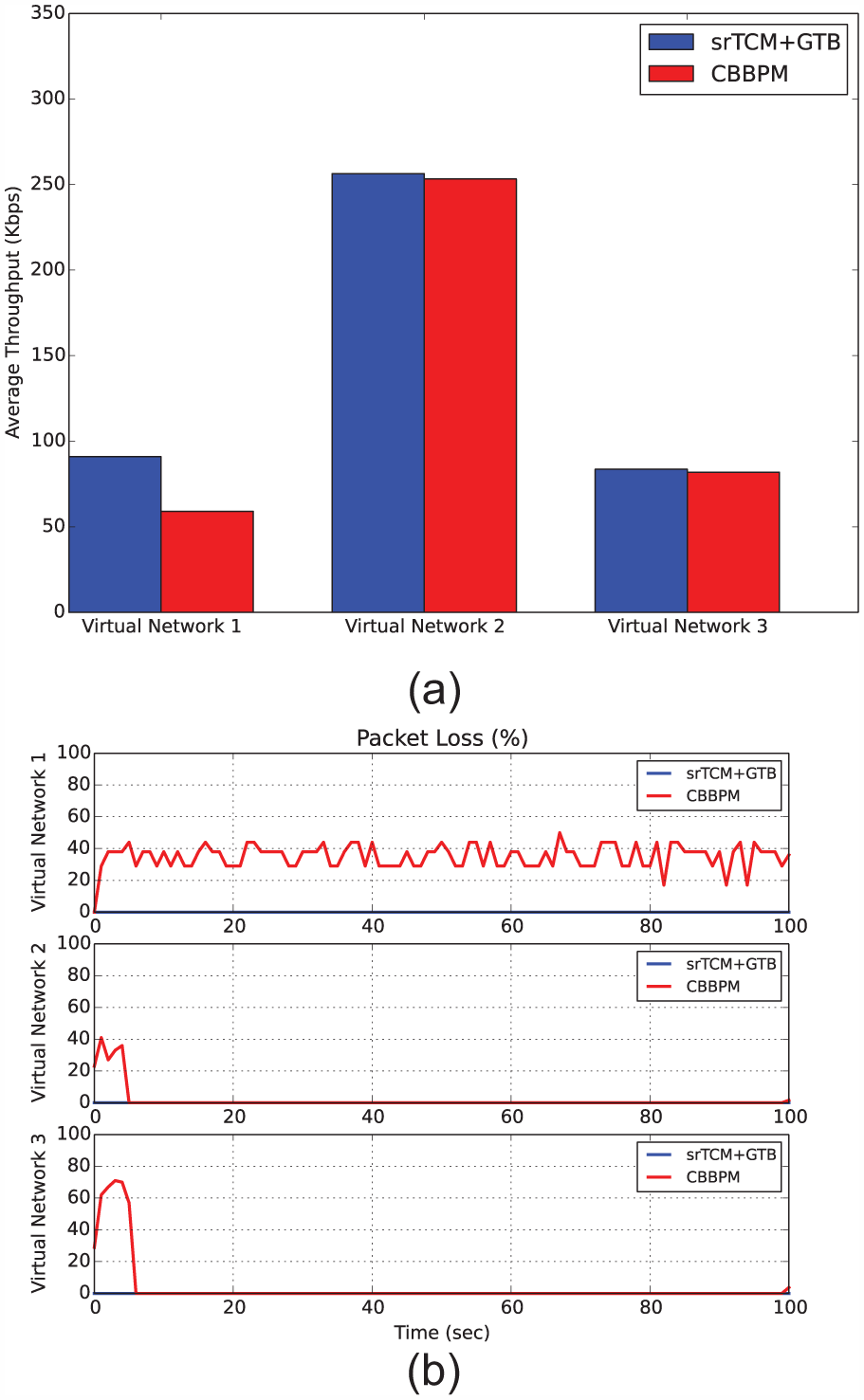
UDP performance of first set: (a) throughput and (b) packet loss.

UDP performance of second set: (a) throughput and (b) packet loss.
TCP performance
In this experiment, we evaluated the TCP throughput of each virtual network. Figure 13 presents the experiment results. Clearly, srTCM+GTB achieves a better performance than CBBPM. Compared with CBBPM, the TCP throughputs of the networks VN1, VN2, and VN3 increased by 160%, 36%, and 17%, respectively.
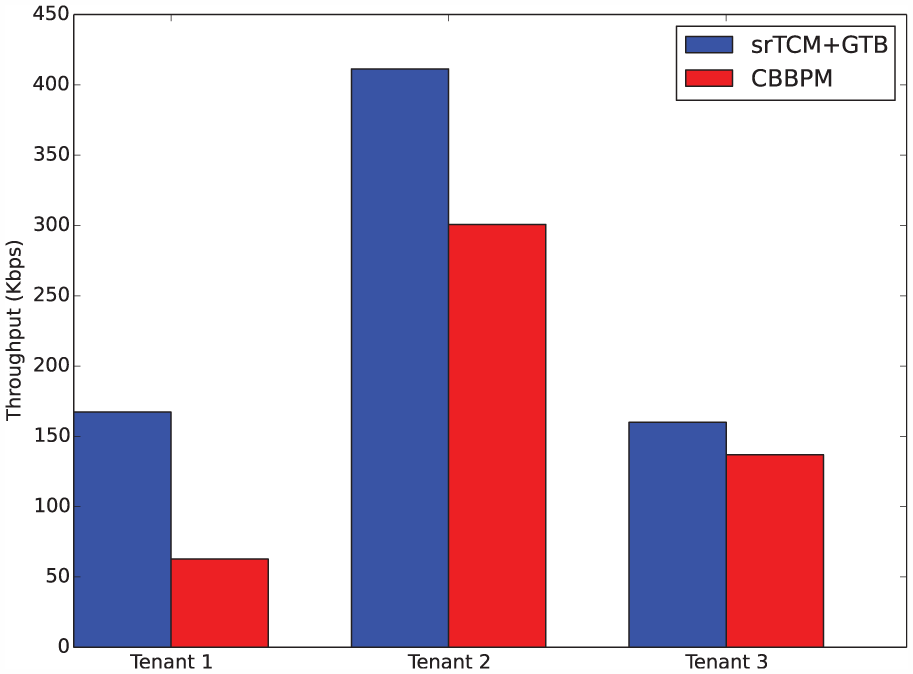
TCP throughput of each virtual network.
In CBBPM, not all virtual networks were able to even achieve their CIRs, because TCP requires the adjustment of the data arrival rate through adjusting a congestion window to avoid congestion. Furthermore, VN2s data rate achieved 65% of its CIR, and VN3s data rate exceeded its CIR, because VN2 and VN3 allow a large burst size. In such situations, VN1 can almost never borrow tokens from VN2 and VN3, even if it has a higher weight than VN2 and VN3. However, srTCM+GTB collects idle tokens from all virtual networks into a common space called the global token bucket and redistributes them to each virtual network according to their weights using a resource manager. Therefore, the issue mentioned above is not present in srTCM+GTB, and this illustrates that srTCM+GTB can utilize bandwidth more effectively.
Conclusion
In this article, we proposed a traffic-aware QoS control mechanism for SDN-based virtualized networks. This mechanism implements an extended srTCM, that is, srTCM+GTB. This acts first as a traffic meter to mark and meter the incoming packet flow of each virtual network and second as a resource manager to manage the global token bucket. This QoS control mechanism can redistribute the idle resources of the physical network according to the traffic states of each virtual network. Furthermore, we performed five experiments and compared the results with the existing mechanism called CBBPM. Our work shows that the performance of each VN was enhanced by our method, that is, the bandwidth of the physical links can be distributed among the VNs efficiently, and the isolation of each virtual network can also be guaranteed.
Footnotes
Academic Editor: Paul Mitchell
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Institute for Information & communications Technology Promotion(IITP) grant funded by the Korea Government (MSIP; no. B0126-16-1051, a Study on Hyper Connected Self-Organizing Network Infrastructure Technologies for IoT Service).