
Abstract
Information retrieval is applied widely to models and algorithms in wireless networks for cyber-physical systems. Query terms proximity has proved that it is a very useful information to improve the performance of information retrieval systems. Query terms proximity cannot retrieve documents independently, and it must be incorporated into original information retrieval models. This article proposes the concept of query term proximity embedding, which is a new method to incorporate query term proximity into original information retrieval models. Moreover, term-field-convolutions frequency framework, which is an implementation of query term proximity embedding, is proposed in this article, and experimental results show that this framework can improve the performance effectively compared with traditional proximity retrieval models.
Keywords
Introduction
There will be more and more data stored in cyber-physical systems than in Internet of computers. We must extract the necessary information we needed, so the technologies of information retrieval (IR) are more important than ever. 1 The main task of IR is that searching for the documents which users need based on their information needs. Therefore, the representation and organization of information items should make it easier to access information in which users are interested. 2 Generally, users should translate their information needs into queries which can be processed by a standard IR system. The logical views for the user’s information needs are all based on query terms in traditional IR models including vector space model, 3 probabilistic model,4–6 and language model,7–10 and most of IR models can be applied to wireless networks for cyber-physical systems. These traditional IR models use the occurrences of query terms in the documents to determine their weights for the user’s queries, and they all adopt term-independence assumption. That is, these models ignore the relations between query terms including proximity, semantic relations, collocations, and so forth.
Some researchers tackle this problem by incorporating Query Terms Proximity (QTP) into traditional IR models. These “incorporations” are usually based on the linear combinations of QTP scores and scores of traditional IR models.11–13 In this article, we call these proximity retrieval models QTP-attaching models, of which the scores are a linear or nonlinear combination of original scores of IR models and original QTP scores. QTP-attaching models are understood easily, and the working prototypes are developing-friendly. The research on QTP-attaching models has been very thorough. Using this mode of incorporations (basically all the linear combinations of them), there are some significant improvements in the proximity retrieval models over baseline models, and these show that QTP is a very intelligible, efficient, and useful measure to tackle the term-independence assumption in traditional IR models.
However, the shortcomings of QTP-attaching models are found in our recent research. First, there is not an appropriate theory to interpret the reason why it should be compliance with the related formulas in QTP-attaching models. Second, the score of traditional IR models and QTP score are separate. The score ranges of various traditional IR models and QTP-attaching models are different, and we must normalize these scores so that we can combine them in the same standard. Finally, in QTP-attaching models, the QTP measures are isolating values, so the choice of particular QTP measures is very important and sensitive for the performance of QTP-attaching models.
In this article, we propose QTP-embedding models to resolve these problems. At first, we propose a term-field-convolutions frequency framework to interpret the relations between query terms in a document with the relative concepts of physics and maths; then, in this framework, we propose a method to postprocess the correlation between two terms by their semantic similarity. Finally, we integrate these concepts into QTP-embedding models, which embed QTP into traditional IR models.
The rest of the article is organized as follows. We first introduce the main work of related researchers in section “Related work”. In section “QTP-assisting IR”, we outline the two types of QTP-assisting models: QTP-attaching and QTP-embedding. Then, we propose term-field-convolutions frequency framework as an implementation of QTP-embedding model in section “Term-field-convolutions frequency framework”. After that, we test our model with systematic experiments in section “Experiments”. Finally, we give conclusions and future research directions in section “Conclusion and future work”.
Related work
In this section, we will introduce important QTP-attaching models and some proximity retrieval models similar to QTP-embedding models proposed by other researchers.
QTP is a easy-understanding way to avoid the term-independence assumption in traditional IR models. It is very effectively compared with some complex methods based on deep theories. In some research works,14–16 QTP is not an independent method but a trick to resolve some detail problems. Metzler and Croft 14 propose a formal framework to model term dependencies through Markov random fields. They describe three types of term dependencies models: full independence, sequential dependence, and full dependence and then use their linear combination to rank documents. Beigbeder and Mercier 15 developed a model based on a fuzzy proximity degree of term occurrences. Petkova and Croft 16 propose a expert search model based on the dependencies between the named entities and terms which appear in document. They proposed a series of proximity kernels to describe these dependencies between the named entities and terms, for example, triangle kernel, Gaussian kernel, and step function.
However, in research works of Rasolofo and Savoy, 17 Tao and Zhai, 18 and Cummins and O’Riordan, 19 some standard QTP-attaching models have been proposed. In these models, original IR models have been regarded as the core, and the measures of QTP have been appended as the attachments. These QTP-attaching models focus on the QTP itself and discuss various types of proximity measures in detail. Rasolofo and Savoy 17 propose a combination of proximity measurements and Okapi probabilistic model. 20 On this basis, Tao and Zhai 18 propose a complete proximity retrieval model with five proximity measures. Cummins and O’Riordan 19 expanded Tao’s research and proposed a more integrated proximity retrieval model with 12 proximity measures.
The other researchers tried to make use of QTP by other ways. Robertson et al. 21 proposed a method for weighting term frequencies based on the importance of the document field in which they occur. Vechtomova and Karamuftuoglu 22 were inspired by Robertson’s idea and replaced original term frequency by pseudo-frequency (section “Pseudo-frequency” will introduce its definition). Vechtomova’s proximity model is indeed a preliminary QTP-embedding model, and the partial discussions in this article are based on this research.
We should further note that Vechtomova’s proximity model is not unique emphasis in her paper. She also proposed Lexical Bond combined with proximity in her paper. But there is no perceptible performance improvement (even opposite) of separate lexical bond in Vechtomova’s experiments, and the performance of combining model of proximity and lexical bond is very close to separate proximity model. In addition, the calculation of lexical bond is very large compared with proximity, and it is not worth according to its performance. Since lexical bond is based on natural sentences, we cannot use the information in the inverted table of index and must access the original document directly. Based on the above two reasons, we do not discuss lexical bond furthermore in this article.
QTP-assisting IR
QTP assisting
Query is a very summary, refined, and simple abstract of user’s information needs. Query terms in a query consisting of two or more terms are not independent absolutely. Term-independence assumption in traditional IR models is just a way to simplify problems. QTP is an effective and easy-understanding way to avoid this assumption. As an assisting strategy, QTP cannot retrieve information in IR systems independently, and it must be incorporated into a traditional IR models.

where D is a set of information resources (in most cases is text documents or multimedia documents), Q is a set of information needs of users, F is a framework to process information resources and information needs, and
Equation (1) gives a universal definition of all IR models. We can give a general definition of IR models which adopt the term-independence assumption.

where
Most of popular IR weighting functions, such as tfidf,
24
According to the definition of original IR model, we call the model QTP-assisting model, which revises the term-independence assumption of original IR model by QTP.
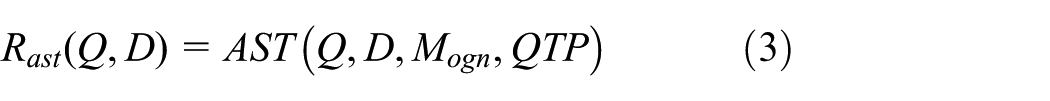
where
This definition of QTP-assisting model is relatively rough. In next two subsections, we will define two types of QTP-assisting models in detail.
QTP-attaching model
Original IR models do not consider the proximity between query terms, so we must add the proximity information into the weighting function of original IR models. The natural idea is that, we can regard the return value of a function based on original IR model score and original QTP score as the score of compound models. We call these models QTP-attaching models.
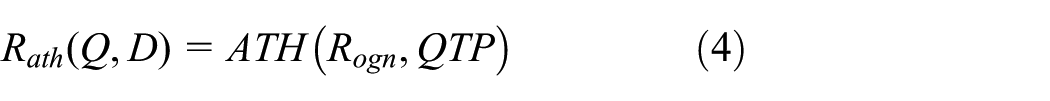
where
QTP-attaching model is a subset of QTP-assisting model, but their definitions are quite similar. The differences between the definitions of QTP-assisting model and QTP-attaching model are twofold. First, Definition 3 is an open definition. All information of IR systems is in its parameter list. On the contrary, only two parameters in Definition 4. Second, as proximity retrieval models, QTP-assisting model and QTP-attaching model are all based on original IR model, but in QTP-assisting model, original IR model is
The most common form of attaching strategy function ATH is linear combination

where
QTP-attaching model avoids term-independence assumption through a convenient way and it can improve the performance of original IR models effectively. However, there are still two problems in its applying. First, in QTP-attaching model, the scores of original IR models and QTP scores are isolated, so the tuning of their weights
QTP-embedding model
In this subsection, we propose QTP-embedding model to address the issue that some problems of QTP-attaching model mentioned in the previous subsection. As the name suggests, in QTP-embedding model, QTP measures are “embedded” in the original IR models:

where
We can see that QTP-embedding model maintains the main form of original IR model. Different from QTP-attaching model, QTP-embedding model makes use of QTP measures to preprocess its parameters. For an actual QTP-embedding model, there are two problems that need to be resolved: (1) Which parameters in original IR models can be QTP-embedded? (2) How to QTP-embed? That is, how to determine the embedding strategy functions?
For the first problem, only a part of parameters is appropriate to QTP-embed in spite of every parameter being QTP-embedded formally in equation (6). At first, QTP measures are statistics to describe the relations between query terms within documents and not within queries, so the QTP-embedding-friendly parameters should be relevant with the documents. Therefore, some parameters relative to the queries, such as the length of query |q| or the term frequency within query
For the second problem, we propose three constraints to restrict the choices of embedding strategy functions.
Constraint 1 means that embedding strategy function cannot affect the parameter characteristics of original IR model
There is a prerequisite in next two constraints: the higher the QTP measures of query terms, the closer the QTP. If original QTP measures do not satisfy this prerequisite (in fact most of original distance-based QTP measures are opposite), we can normalize them first.
Constraint 2 and Constraint 3 are symmetrical. These two constraints mean that embedding strategy function should play its due role, namely, improving the weight (
Constraint 1 is the basis, which tries to make the performance of QTP-embedding model not lower than homologous original IR model. Constraint 2 and Constraint 3 are the essences, which try to make the performance of QTP-embedding model higher than homologous original IR model. Note that these three constraints are only necessary conditions of actual embedding strategy functions.
Term-field-convolutions frequency framework
In this section, we introduce pseudo-frequency proposed by Vechtomova and Karamuftuoglu 22 first and then outline term-field-convolutions frequency framework as an actual implementation of QTP-embedding model.
Pseudo-frequency
As mentioned in section “QTP-embedding model”, only a few parameters are appropriate to QTP-embed. The term frequency within documents
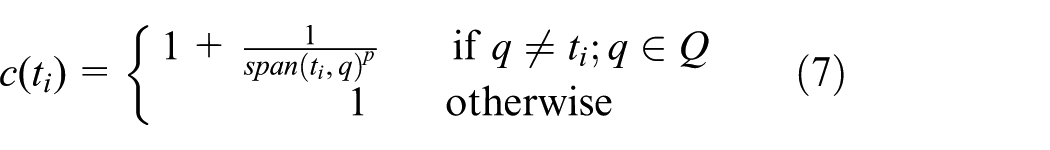

where
IR model based on pseudo-frequency is typical QTP-embedding model obviously, and the embedding strategy function from equations (7) and (8) meets the constraints mentioned in section “QTP-embedding model” (after QTP measure normalization). However, the function of pseudo-frequency is somewhat arbitrary. Although it is generally considered “the shorter distance, the higher correlation between term pairs’’, but it is difficult to determine the particular distance-correlation function. In the next subsection, we will discuss the problem furthermore.
Term-field-convolutions frequency
Every term within document has its context, and context is the language circumstance of terms in practical application. Context is a very useful resource in the research of IR and computational linguistics. We can draw an analogy between the context of terms and the electric field around electric charge or the magnetic field around magnetic charge, that is, there is an affected area around each term of documents and we can call them “Term Field.” Each term in document has its own term field.
Furthermore, we can draw an analogy between term frequency within document and magnetic flux or electric flux. Magnetic flux or electric flux is the integral of magnetic field strength and electric field strength, so “Term’s Flux”
Generally, the term field strength within document can be expressed by

where
In order to meet the definition of term flux, we require that the integral of term field for an instance must be 1, that is

where
So, the term frequency in document can be expressed by

where
In equation (11),
There are interactions between field and field, whether magnetic fields or electric fields. So, we consider that there are some interactions between term fields. For different instances of the same term, their term fields simply overlie each other. But for the instances of different term, there should be additional effects between them to avoid term-independence assumption.
Convolution is a very important concept in mathematics, physics, and in particular, communication science. It is defined as the integral of the product of the two functions after one is reversed and shifted. The convolution of function f and function g can be expressed by

In research of statistics, convolution is the promotion of weighted moving average. For this article, it is suitable to weigh the close-degree of two term fields. So, we choose the convolution of term fields to measure the interaction between term fields.
In addition, the interactions of term fields relate with not only their distance but also their semantic similarity. When their distance is a fixed value, the higher the semantic similarity of two terms, the lower the interaction between their term fields. If the semantic similarity of two terms is low, their substitutability is also low, so their proximity is valuable to evaluate the correlation between the document and the query. On the contrary, if the semantic similarity of two terms is high, their substitutability is also high, so their proximity is unnecessary even in highly relevant documents.
Based on the above discussions, we can define term fields interaction formally.
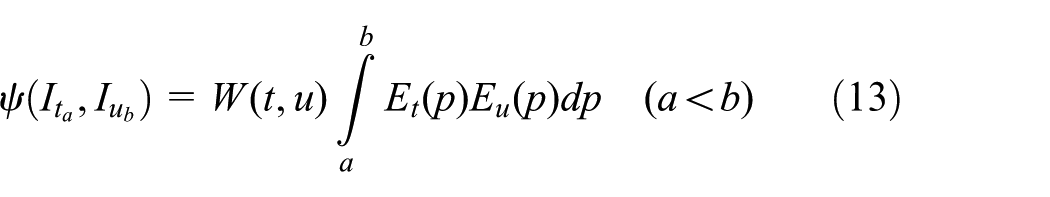
where
Note that
From Figure 1, we can see that the term field of “ electric”

Term fields interaction.
Similar with pseudo-frequency, the term-field-convolutions frequency is calculated as follows


where
Experiments
Experimental setup
We choose the traditional Okapi BM25 model
25
as the baseline of original IR models, and choose Tao and Zhai’s
18
model and Cummins and O’Riordan’s
19
model as the baseline of QTP-attaching models. The proximity function of Tao’s model tao and the best proximity function of Cummins’ model


The tuning constant
For calculating
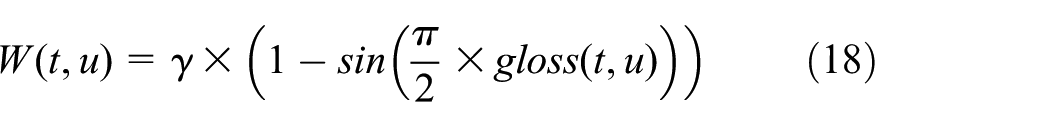
where
Term field strength function S in equation (9) should also be determined. We choose the Decaying Co-occurrence Model proposed by Gao et al. 29 as function S in the experiments
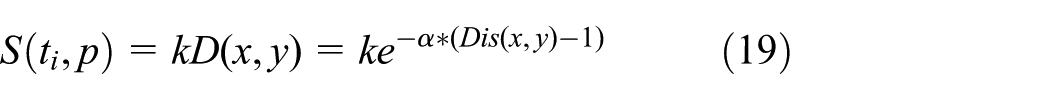
where
The test collection of this experiment is WT10g data set, a popular benchmark for the development and evaluation of IR systems. 30 It contains 1,697,027 documents and 9,147,236 distinct terms. Text REtrieval Conference (TREC) topics 451–500 correspond to this collection, so we make 50 queries from topics 451–500.
As shown in Table 1, we use eight models (
IR models in experiments.

IR: information retrieval.
Evaluation measures.

MAP, P10, P20, P100 and Bpref are very popular evaluation measures in IR. MAP is the mean of the precision scores obtained after each relevant document is retrieved. Bpref is a preference-based IR measure that considers whether relevant documents are ranked above irrelevant ones. There are generally 10 search results in one page in most of IR systems. So, P10 means the precision in page 1 (all users will see page 1); P20 means the precision in page 1 and page 2 (most users will click next page at least once). Moreover, there are 20 results in one page in some IR systems; P100 means the precision in pages 1–10 (most users will not see the pages after page 11).
Experimental results
The experimental results are shown in Table 3. Note that there is a strong correlation between the performance of term-field-convolutions frequency framework and the value of the decay rate
Experimental results.

Maximum values of all models to each measure are in bold.

Experimental results.
The conclusions of experimental results are threefold:
To term-field-convolutions frequency framework, the performance of
The performance of
The performance of QTP-attaching models
Discussions
In the experiments, term-field-convolutions frequency framework with the decay rate 0.8 achieves the best performance. The performance of
Overall, if we choose an appropriate decay rate, the performance of term-field-convolutions frequency framework is higher than all the baseline models. Even the decay rate is not appropriate enough, its performance is not lower than traditional QTP-attaching models obviously, in spite of the performance being lower than other QTP-embedding model
Tracing it to its cause, we consider that the “proximity” in term-field-convolutions frequency framework is a “higher order proximity.” Traditional “proximity” is the relationship between term and term, and term-field-convolutions is an indirect relationship between term field and term field. Two terms in a document not only relate each other directly but also relate each other through other terms between them. Term-field-convolutions frequency framework considers these information and other models ignore them simply.
In addition, the performance of
Equation (13) is in an integral form in order to be consistent with the form of the convolution (equation (12)). In fact, the convolution between term fields is discrete and the sentences are short in most of documents, so QTP-embedding model does not take too much computation time. Furthermore, some static data, such as the semantic similarity between terms, can be calculated in advance and stored into Hash table. In our experiments, there is no significant difference between QTP-attaching models and QTP-embedding models in computation time.
Conclusion and future work
In this article, we propose the concepts of QTP embedding and then propose term-field-convolutions frequency framework as an implementation of QTP-embedding. This framework draws an analogy between the context of terms and the electric field or the magnetic field and regard the term frequency as the flux of term field, then using the convolutions of term fields to consider the QTP. Theoretical analysis and experimental results show that the performance of term-field-convolutions frequency framework–based IR model is higher than baseline models including its original IR model, some QTP-attaching models, and previous QTP-embedding model.
Looking forward, possible improvements might be pursued. One of the most important requirements is more deep discussions of term field strength functions. Term field strength function used in this article is proposed in previous research, 29 which derived from experience, and it requires further theoretical analysis and expansions. It implies many new tasks to be done in the future.
Footnotes
Academic Editor: Wei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (No. 61202181, No. 61671371), China Postdoctoral Science Foundation (No. 2012M512006), and the Fundamental Research Funds for the Central Universities (No. xjj2013097).