
Abstract
Currently, a huge amount of visual data such as digital images and videos have been collected by visual sensor nodes, that is, camera nodes, and distributed on visual sensor networks. Among the visual data, there are a lot of near-duplicate images, which cause a serious waste of limited storage, computing, and transmission resources of visual sensor networks and a negative impact on users’ experience. Thus, near-duplicate image elimination is urgently demanded. This article proposes a fast and accurate near-duplicate elimination approach for visual sensor networks. First, a coarse-to-fine clustering method based on a combination of global feature and local feature is proposed to cluster near-duplicate images. Then in each near-duplicate group, we adopt PageRank algorithm to analyze the contextual relevance among images to select and reserve seed image and remove the others. The experimental results prove that the proposed approach achieves better performances in the aspects of both efficiency and accuracy compared with the state-of-the-art approaches.
Keywords
Introduction
With the rapid developments of sensor technology, wireless networking, and distributed computing, visual sensor networks (VSNs) have emerged as an important part of Internet of Things (IOT), which can support many visual applications such as security surveillance and environmental monitoring. 1 Generally, similar to the other networks researched in Ma et al., 2 VSNs contain a number of distributed visual sensor nodes, that is, camera nodes, which have appeared in many products such as mobile phones, drones, and robots. These visual sensor nodes are commonly used to collect, process, and transmit visual data including digital images and videos on VSNs.
However, as the number of camera nodes increases significantly, the amount of visual data increases explosively on VSNs, which can be managed by various cloud computing systems.3–12 Among the visual data, there are a lot of near-duplicate images, which are usually defined as the images derived from the same digital source by various copy attacks or the ones captured from the same scene by different cameras and/or different conditions.13–15 Two examples of near-duplicate images are shown in Figure 1. The existence of those near-duplicate images causes a serious waste of limited storage, computing, and transmission resources of VSNs, and it also leads to a low users’ experience since the users have to go through a large amount of near-duplicate images before finding the images that they are interested in. Therefore, near-duplicate image elimination has become an important issue of VSNs.

Two examples of near-duplicate images: (a) the original image and its near-duplicates generated by different copy attacks and (b) the original image and its near-duplicates captured by different conditions.
Since the simplified hardware structure is used in VSNs, the storage, computing, and transmission capabilities are generally limited, which makes the task of near-duplicate image elimination much more challenging. An ideal near-duplicate image elimination approach for VSNs is expected to have high efficiency while maintaining good accuracy. The existing approaches related to near-duplicate elimination are designed for traditional computer-based networks but not for VSNs, which require relatively low computation cost without a significant decrease in accuracy.
To meet the efficiency and accuracy requirements of VSNs, in this article, we propose a fast and accurate approach to efficiently and effectively eliminate near-duplicate images. It mainly consists of two key stages: near-duplicate clustering and seed image selection. The main contributions of our work are summarized as follows:
Near-duplicate clustering is the first and basic step of near-duplicate elimination. Considering both efficiency and accuracy, we propose a near-duplicate clustering scheme based on a combination of global and local features to obtain near-duplicate clusters in a coarse-to-fine manner. First, near-duplicate images are clustered based on global feature to obtain initial clusters, that is, near-duplicate image groups (NIGs). Then a clustering optimization based on local feature is employed with a proposed “nearest expansion” strategy to optimize the clustering results.
The seed image is expected to be the most representative image that has the highest relevance to the others in a NIG. 16 The existing seed selection methods usually choose the top-quality image of each NIG or the image nearest to the computed centroid of the group as seed image. However, those images are not the most representative images. By taking into account the contextual relevance among the images in each NIG, we propose a novel seed image selection method based on PageRank algorithm, which can accurately select the most representative images as seed images and remove the other redundant images to finish the near-duplicate elimination.
The remainder of this article is organized as follows. We review the related work of near-duplicate image elimination in section “Related work.” In section “The proposed near-duplicate elimination approach for VSNs,” the proposed near-duplicate image elimination approach is detailed. In section “Experiments,” the experimental results are presented and discussed. Finally, we draw the conclusion of the proposed approach in section “Conclusion.”
Related work
Due to the fact that near-duplicate elimination is quite related to near-duplicate detection and copy detection, in this section, we review not only the existing near-duplicate image elimination approaches but also the near-duplicate image detection and image copy detection approaches.
Different from steganography techniques researched in Xia et al.,17,18 which embed mark into digital source beforehand to indentify the copies, near-duplicate detection and copy detection focus on how to find the near-duplicates or copy versions of a given query (original) image. The existing near-duplicate detection and copy detection approaches can be roughly classified into two main categories: global feature–based approaches19–21 and local feature–based approaches.14,15,22–26 The global feature–based approaches extract single or several global features from the whole or nearly whole image region and then match those features between images to realize near-duplicate detection or copy detection. Typical global features include the feature based on discrete cosine transformation (DCT), 19 edge-based feature, 20 and color feature.21,27 Although the global features are efficient to compute and match, they are sensitive to some relatively serious changes and attacks such as the viewpoint changing, capture position changing, and cropping. Consequently, the global feature–based approaches cannot effectively detect the images after those changes and attacks. To address this issue, many local feature–based near-duplicate and copy detection approaches have been proposed.14,15,22–26 Different from global feature–based approaches, the local feature–based approaches extract hundreds of high-dimensional local features from each image, such as scale-invariant feature transform (SIFT), 28 principal component analysis (PCA)-SIFT, 26 and bag-of-visual-words (BOW).15,22–25 However, the matching of those high-dimensional local features between images is quite time-consuming. Thus, local feature matching of those approaches is generally accompanied by the construction of index structure to improve the detection efficiency. Locality sensitive hashing (LSH) 29 is one of the most popular index structures for local feature matching.
Most of the recent approaches focus on the studies of near-duplicate detection and copy detection. Only a few approaches introduce some techniques for near-duplicate image elimination. Generally, the existing near-duplicate elimination approaches consist of two key stages: near-duplicate clustering and seed image selection. First, images are clustered into a number of NIGs. Then in each NIG, only the seed image, that is, the most representative image that has the highest relevance to the others, 16 is selected and reserved and the other images are removed.
Chen et al. 30 proposed an image deduplication approach. In this approach, the near-duplicate images are clustered into a number of NIGs by the global feature matching. Then by evaluating image quality considering several factors including size, resolution, and clarity, the top-quality image of each NIG is selected as seed image. However, in this approach, the near-duplicate clustering based on global feature will miss the near-duplicates captured by different viewpoints and positions, due to the week robustness of global feature. Moreover, since top-quality images do not mean that they have the highest relevance to the others, this approach is not accurate enough to select seed images, causing some seed images to be falsely removed. Liu et al. 31 proposed an approach to filter the near-duplicates of geo-tagged photographs. In this approach, the geographic tags embedded in the photographs are used to cluster photographs into initial photograph groups. For seed photograph selection, it simply chooses the photograph nearest to the centroid of each group as seed photograph, where the centroid is computed by the mean values of visual features of all the photographs in the group. However, the near-duplicate clustering cannot be implemented when the images do not have geographic tags. Moreover, choosing the photograph nearest to the group centroid as seed image is not accurate enough. Yang et al. 32 proposed a junk image filtering approach to remove the duplicate images and the irrelevant images. It randomly chooses one image as seed image from each image group, which will result in low accuracy for junk image filtering.
In conclusion, most of the existing near-duplicate elimination approaches only use one type of simple feature, which results in low accuracy for near-duplicate clustering. Also, they ignore the contextual relevance among the images in NIGs, and thus the seed images cannot be accurately selected. Consequently, the near-duplicate images cannot be efficiently and effectively eliminated. More importantly, all of them are originally designed for traditional computer-based networks but not for VSNs, which requires relatively low computation cost without a significant decrease in accuracy for near-duplicate elimination.
Because the global features are more efficient while the local features have better robustness, by combining both their advantages, we propose a near-duplicate clustering scheme based on a combination of global and local features for VSNs to obtain near-duplicate clusters in a coarse-to-fine way. On the other hand, since the seed images are the most representative images that have the highest relevance to the others, the contextual relevance among images in NIG needs to be explored for seed image selection. Inspired by Xie et al. 33 and Jing and Baluja, 34 which use graph-based models to capture the contextual relevance among images for image ranking, we attempt to capture the relevance among images in such a way. Thus, in each NIG we use PageRank algorithm to capture the visual relevance among the images to select seed image to realize near-duplicate elimination.
The proposed near-duplicate elimination approach for VSNs
In this section, we introduce the proposed near-duplicate elimination approach for VSNs in detail. Figure 2 shows the framework of the proposed approach. Similar to the existing near-duplicate elimination approaches, our approach includes the following two major stages:
By combining global and local features, near-duplicate images are clustered in a coarse-to-fine way to obtain the NIGs. First, quantized global features of images are used to efficiently cluster near-duplicates to obtain initial NIGs. Then a clustering optimization based on local feature is employed with a proposed nearest expansion strategy to further optimize clustering results.
In each NIG, seed image is selected and reserved based on PageRank algorithm while the other images are removed. First, PageRank algorithm is used to capture contextual relevance among near-duplicate images in each NIG. Then the image that has the greatest share of the visual authorities after iterations on weight propagation is selected as the seed image of the group.

The framework of the proposed near-duplicate image elimination approach for VSNs.
Near-duplicate clustering
At this stage, we describe the near-duplicate image clustering method in detail. As mentioned above, global features have high efficiency but low robustness, while local features have good robustness but high computational complexity. To obtain high efficiency while maintaining good accuracy, we combine the advantages of both global features and local features to cluster near-duplicates in a coarse-to-fine way.
First, images are divided into a number of equal-sized blocks, and the mean gray value of each block is calculated to generate the global features, that is, hash codes. Then according to the hash bins which the hash codes belong to, the dataset images can be divided into different groups, that is, initial groups. To refine the clustering results, we also employ a nearest expansion strategy under the presumption that near-duplicate images are located not only in the same hash bin but also may in nearby hash bins. Thus, we also search for the near-duplicates in the nearest neighbors of each hash bin to improve the recall of near-duplicate clustering. To this end, we extract robust local features from the images in each group. Then to improve the efficiency of local feature matching, an inverted index is constructed and a similarity table (called SimTable) recording the similarities between images is created offline. Finally, by local feature–based matching, we search for near-duplicates in the nearest neighbors of each hash bin to obtain the final NIGs. After traversing all hash bins and searching in their nearest neighbors, all the final NIGs are generated.
Coarsely clustering based on global feature
First, we coarsely cluster images based on their global features. Global feature can reflect the global appearance of an image and has high efficiency to compute and match. As we know, most near-duplicate images usually have similar global content but some differences in local appearance. Therefore, after coarsely clustering based on global feature, it is likely that most near-duplicate images will be grouped together in the same group or be located in the nearby groups.
The extraction of global feature is detailed as follows. First, we divide an image I into 3 × 3 equal-sized blocks. Then, we calculate the mean gray value of each block to generate a vector g = (g1, g2,…, g9) by

where M × N is the resolution of the image, f(x,y) is the gray value of the pixel located in (x,y), and Ki is the ith image block. Next, vector g is quantified into a binary hash code h = (k1, k2,…, k9) by

where
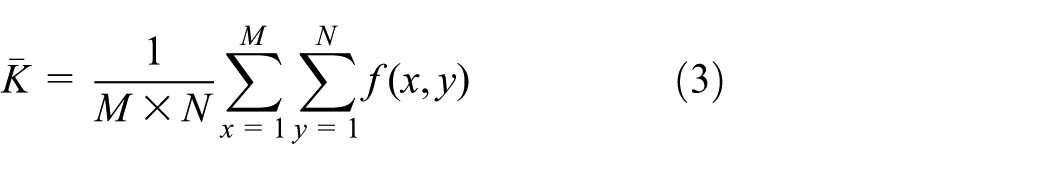
This procedure of coarsely clustering based on global feature is illustrated in Figure 3. However, although the global feature can be used to efficiently cluster the near-duplicates, the initial clustering results are not accurate enough and many near-duplicates that suffer relatively serious changes or attacks will be missed.

The procedure of coarsely clustering based on global feature.
Clustering optimization based on local feature
As mentioned above, only using simple global feature for clustering is not accurate enough to cluster all kinds of near-duplicate images. Compared with global features, local features are generally more robust and stable. 35 Thus, we use local feature to further optimize the initial clustering results. From Bay et al., 36 speed up robust feature (SURF) is one of the most popular local features, due to its relatively low dimensionality (64 dimensions) and high efficiency of extraction and matching. In this section, we adopt SURF to describe image local regions. Figure 4 illustrates an example of local feature matching results based on SURF after filtering the false matches. In this figure, each line represents a true matching.

An example of near-duplicate image matching based on SURF.
Although SURF has relatively high efficiency, hundreds of SURF features will be extracted from each image. If those SURFs are directly used for near-duplicate detection, it will lead to an intensive computational cost. To improve efficiency, it is necessary to construct an inverted index. For a SURF denoted as fi = (fi,1, fi,2,…, fi,n), where fi,j represents the jth dimension of the feature vector fi and n = 64. We quantify fi into a bit vector vi = (vi,1, vi,2,…, vi,n) by


where fi,mean is computed as follows

LSH 29 is a famous technique of building inverted index file for the matching of high-dimensional features. In the technique, each feature is indexed according to its hash value to build the inverted index file, and the feature and its image ID are recorded in each entry of inverted index file. During the feature matching, the hash values of a given query feature are looked up from the entries of the inverted index file, and then an additional comparison between the original features is implemented to further confirm whether two features are a match or not. Similar to LSH, we also index each SURF according to its vector to establish an inverted index structure, in which each entry records the ID of the image that the feature belongs to. Then we treat each entry as a visual word. If two SURF features fall into the same entry, they can be directly regarded as a match. From the above, it is clear that our method has some differences from the traditional LSH. Our method is much more efficient than LSH in the aspects of both space and time, because we do not need to store the original SURF features and compare them.
For two images Ii and Ij, suppose that the number of the visual words they shared is m, and mi and mj are the total number of features in Ii and Ij, respectively. Then the similarity Sij between image Ii and Ij is defined as
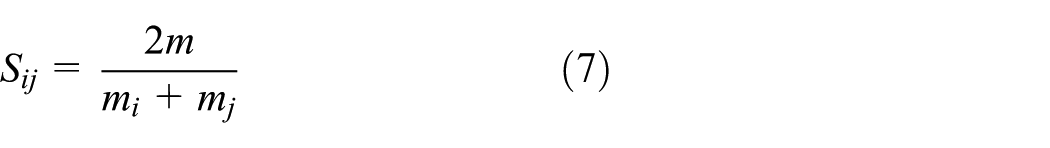
When checking two images with their visual words, we use a threshold
An example of the SimTable.

In the coarsely clustering stage, near-duplicate images may also be located in neighbor hash bins. To improve the clustering recall, using the constructed inverted index file and the SimTable, we propose a nearest expansion strategy based on local feature to optimize the initial cluster results. The “nearest neighbor” strategy is detailed as follows:
For a hash bin hi, in the proposed approach, its nearest neighbors are defined as those bins of which hash codes satisfy hj ⊕ hi ≤ 3, where j ≠ i and ⊕ means exclusive OR operation. Consequently, there will be in total

The algorithm of clustering optimization based on local feature.
Seed image selection
After the near-duplicate clustering, we implement seed image selection to reserve the most representative image and remove the other redundant images in each NIG. First, we use PageRank to analyze the contextual relevance among images based on their visual similarity. Then the image with the highest relevance value will be selected as the seed image to represent the group.
The seed image is selected as the most representative image of a NIG, which should have the highest relevance to the others. 16 Thus, in each NIG, we select seed image utilizing contextual relevance among the images, rather than only relying on the image quality or the centroid of the group. Therefore, we need a proper link analysis algorithm to deeply explore the contextual relevance among images in each NIG. As we know, Hyperlink-Induced Topic Search (HITS) is a query-dependent algorithm while PageRank is query-independent, and the seed image selection in each NIG is independent of any specified queries. Thus, we use PageRank to find the one with the highest relevance as the seed image, that is, to find most representative image of each NIG.
PageRank is a ranking algorithm that can identify the importance of a webpage, and it is the only standard of “Google” to measure the importance of a website. In this algorithm, the more popular website will receive more links from other websites. It treats each website as a node, and the link weight between every two nodes is the click rate that one will arrive from one website to another. Each node collects weights from others and distributes its weight to others. After several iterations, each node will have a convergent authority for ranking. Similarly, the idea of PageRank can be cited to vote the most relevant image as the seed image in a NIG. We treat each image as a node and establish links between every two images of the group. Then we use PageRank to iteratively update the authority of each node with link weight propagation. Since the link weight is based on the visual similarity, the image that has the highest visual authority after iteration will be regarded as the image that has the highest relevance to the others, and thus it will be reserved as the “seed image” to represent its group.
In our image seed selection method, the link weights between image nodes in a NIG are assigned into an asymmetric matrix a, where a[i, j] is the similarity from image Ij to image Ii (note that a[i, j] ≠ a[j, i] because the reference image is different). Inevitably, the aforementioned near-duplicate clustering method may lead to some false positives, and thus there will be some exceptional image nodes in NIGs. To avoid false elimination, we remove the exceptional image that has smallest similarity to the others beforehand. We iterate this process until the similarity between every two images is larger than the predefined threshold

Seed selection algorithm based on PageRank.
Experiments
To evaluate the performance of our approach, we conduct the experiments on an artificial near-duplicate image dataset. We also implement intensive experiments on a real-world image dataset, in which images are downloaded from web image search engine. In addition, we compare our approach with several state-of-the-art approaches in the aspects of both accuracy and efficiency.
Datasets
The details of the two datasets adopted in our experiments are given as follows:
CopyDays3K. 37 It is the INRIA Copydays dataset, which consists of 3000 near-duplicate images, including 150 original images and 2850 near-duplicates. There are 19 near-duplicates of each original image in average. These near-duplicates are generated via some typical copy attacks such as scaling, JPEG compression, rotation, caption adding, and their combinations. In this dataset, the ground truth of images in each NIG is the original image and the corresponding near-duplicates, and the ground truth of the representative image is the original image.
Web3K. This dataset contains 3000 images downloaded from the Internet. We search on the image search engine of Google by 10 random keywords, and then select the top 300 results for each keyword. As a result, there are 10 NIGs and 300 images for each NIG. It is necessary to note that all the images in this dataset are tagged by 10 volunteers, and the ground truth of images in each NIG and the corresponding representative images can be determined by their tagging results.
Reference works
In our experiments, we compare our approach with the following approaches:
Geo-tag. This is a framework of near-duplicate elimination based on the geo-tagged photographs. 31 The approach proposes a hybrid index structure to store the useful image information during the stage of offline, so that the online retrieval has less computational complexity. Moreover, some strategies are proposed to quickly skip some unnecessary computations. Then seed photograph selection is determined by the distance between each photograph and its group centroid.
FAIDA. This approach aims to eliminate redundant copies of duplicate images. 30 In this approach, duplicate image clustering is implemented using three global feature-based filters: perceptual hashing filter, gray block filter, and Haar wavelet filter. During the stage of duplicate elimination, a fuzzy logic reasoning system based on the image quality is adopted to determine whether each image needs to be reserved or removed.
K-way. This approach is devoted to filter junk images on the Internet. 32 Junk images in this approach refer to irrelevant images and duplicate images. For image clustering, web near-duplicate image clusters are indentified by integrating bilingual image search results of the same keyword-based query. Then the duplications are removed under a coarse-to-fine structure.
Evaluation criteria
We use precision, recall, and F1-measure to evaluate the performances of different approaches for near-duplicate image clustering. The accuracy of near-duplicate image elimination is evaluated by redundancy elimination accuracy, denoted as mRea. The total time cost is used to evaluate the efficiency of our approach. The definitions of precision, recall, F-measure, and mRea are given as follows:
1. Precision, recall, and F1-measure. In this section, we use precision, recall, and F1-measure to evaluate the performance of our clustering method. The mean precision mp and the mean recall mr in our article are defined as


where m is the number of detected near-duplicate image clusters; p(ci) and r(ci) are the precision and recall of cluster ci, which are defined by

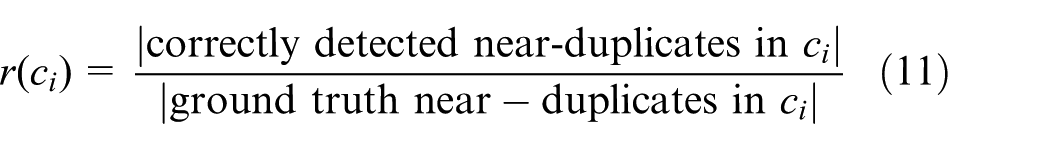
where |*| is the number of *. Then F-measure is defined by

where α is a constant. When α = 1, F-measure will change to the most common form: F1-measure, as

2. Redundancy elimination accuracy. The performance of our near-duplicate elimination method is evaluated by the mean redundancy elimination accuracy, denoted as mRea, which is defined by

where m is the number of detected near-duplicate image clusters; Rea(ci) is the redundancy elimination accuracy of cluster ci, and it is defined as

where r (from 1 to |ci|) represents the ranking results of cluster ci; gt(r) is a binary function. For example, the real representative image in cluster ci is ranked at r = 2, and thus gt(2) = 1 and gt(r) = 0, when r ≠ 2. Thus, when the real representative image is ranked at the top of NIG ci, Rea(ci) has the largest value.
Parameter evaluation
The similarity threshold

Effect of
Experimental results and analysis
We first evaluate and compare the effectiveness of our approach and the other three approaches for near-duplicate clustering. Then we evaluate and compare the accuracy of those approaches for redundancy elimination. In addition, we use total time cost and memory usage to evaluate and compare the efficiency of those approaches:
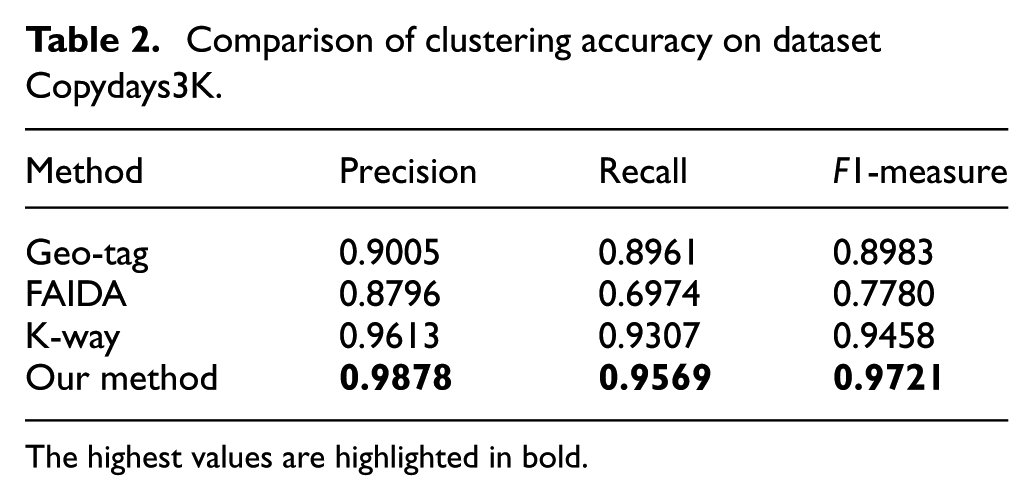
The effectiveness of near-duplicate clustering. We evaluate and compare the effectiveness of our clustering method and the three aforementioned methods. The precision, recall, and F1-measures of those methods on the two datasets are listed in Tables 2 and 3, respectively. From the two tables, it can be observed that our method outperforms the other three methods both on Copydays3K and Web3K. Moreover, it is clear that the results of all of those methods on Copydays3K are better than those on Web3K, because the real-world images usually suffer more serious changes and attacks.
The effectiveness of redundancy elimination accuracy. the results of those approaches for near-duplicate clustering are illustrated in Figure 8(a) and (b). From the two figures, we can observe that our clustering method has the highest redundancy elimination accuracy, and thus the final selected seed images will be most close to the ground truth of representative images. It is also clear that the mRea values of the latter three methods on Copydays3K are better than on Web3K. That is because artificial near-duplicate images are more regular than real-world near-duplicate images, and thus they are easier to be identified.
Time cost and memory usage. We use total time cost and memory usage to evaluate and compare the efficiency of our approach and the other three approaches. Figure 9 shows the comparison results of the total time costs on the two datasets. From the figure, we can observe that the K-way has the highest time cost because it directly adopts pairwise image matching based on local feature. The efficiency of our approach is slightly lower than that of FAIDA, because FAIDA is only based on global feature and thus it can achieve rapid near-duplicate identification. Moreover, the efficiency of our approach is higher than those of the other two approaches.
Comparison of clustering accuracy on dataset Copydays3K.
The highest values are highlighted in bold.
Comparison of clustering accuracy on dataset Web3K.

The highest values are highlighted in bold.

Comparison of the mean redundancy elimination accuracy: (a) mRea of Copydays3K and (b) mRea of Web3K.

Comparison of total time cost: (a) mRea of Copydays3K and (b) mRea of Web3K.
As memory usage is another significant factor of efficiency, we also compare the memory usages of different approaches. Table 4 shows the comparison results of memory usages of the four approaches. In this table, the memory usage of FAIDA is the lowest. Our approach is second to FAIDA and outperforms the other two approaches. Geo-tag has the highest memory usage, due to the extensive memory usage during the building of the hybrid index structure. Our approach has less memory usage than the other two approaches, mainly because we do not store the original global and local features in the index files. Memory usages of those approaches on the Web3K dataset are always higher than those on the CopyDays3K dataset, because NIGs in the former dataset contain more near-duplicates than the latter one.
Comparison of efficiency of memory usages.

Conclusion
In this article, we present a fast and accurate approach for near-duplicate image elimination for VSNs. At the stage of near-duplicate clustering, we combine the advantages of global feature and local feature to efficiently cluster the NIGs. Moreover, we adopt PageRank algorithm to select seed images. This PageRank algorithm can effectively capture contextual relevance between near-duplicate images based on their visual similarity, and thus the most representative image in each NIG will be accurately selected and reserved. The experiments conducted on artificial near-duplicate image dataset and real-world near-duplicate image dataset demonstrate that our approach can achieve desirable performance in the aspects of both efficiency and accuracy for VSNs.
Footnotes
Acknowledgements
The authors would like to thank Prof. Ching-Nung Yang from National Dong Hwa University for reviewing this article and giving some valuable advices.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by the National Natural Science Foundation of China under grant numbers 61602253, U1536206, 61232016, U1405254, 61373133, 61502242, and 61572258; in part, by the Jiangsu Basic Research Programs-Natural Science Foundation under grant numbers BK20150925 and BK20151530; in part, by the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD) fund; in part, by the Collaborative Innovation Center of Atmospheric Environment and Equipment Technology (CICAEET) fund; and, in part, by College Students Practice Innovation Training Program under grant number 201610300022, China.