
Abstract
The advertised quality of an Internet of things service is not always trustable due to the exaggerated quality propagation and dynamic network environment. Therefore, it is more trustable to evaluate the Internet of things service quality based on the historical execution records of service. However, an Internet of things service often has multiple historical records whose invocation time and location are different, which makes it necessary to weigh each historical record of an identical Internet of things service. Besides, for different candidate Internet of things services, their invocation frequencies are often varied, which may also affect the final service selection decision of target user. In view of the above two challenges, a novel service selection approach “Time–Location–Frequency”–aware Service Selection Approach is put forward in this article. In Time–Location–Frequency–aware Service Selection Approach, we first weigh each historical record of an Internet of things service, based on its service invocation time and location; afterward, we weigh each candidate Internet of things service based on its invocation frequency; finally, with the derived two kinds of weights, we evaluate each candidate Internet of things service and return the quality-optimal one to the target user. At last, through a set of experiments deployed on a real service quality data set WS-DREAM, we validate the feasibility of our proposal.
Keywords
Introduction
With the advent of Internet of things (IoT) age, an increasing number of IoT services are emerging on the web, many of which share the same or similar functionality. 1 Therefore, it becomes necessary to evaluate the IoT service quality and finally select the quality-optimal service and return it to the target user. However, due to the exaggerated quality propagation and dynamic network environment, the advertised service quality by IoT service providers is not always trusted. 2 In this situation, the historical records of IoT services generated from past service invocations and execution provide us a promising way to evaluate the real qualities of IoT services. 3
Many researchers have investigated the historical records–based IoT service evaluation and selection problem and put forward various suggestions and solutions.4–6 However, several shortcomings are still present in the previous research works. First, an IoT service often has multiple historical records whose context information (e.g. invocation time and invocation location) is different, which brings a necessity to weigh each historical record of an identical IoT service based on the service invocation time and location information. Besides, for different candidate IoT services, their invocation frequencies are often varied. For example, some popular IoT services are often frequently invoked, while other ones that are not famous are often invoked rarely. In this situation, the service invocation frequency also plays an important role in the final service selection decision of target user. While present research works seldom consider the potential effect of above three factors, that is, invocation time, invocation location, and invocation frequency, the accuracy of IoT service selection is decreased.
In view of the above two challenges, a novel service selection approach named “Time–Location–Frequency”–aware Service Selection Approach (TLF_SSA) is put forward in this article. More concretely, in TLF_SSA, we first weigh each historical record of an IoT service, based on the service invocation time and invocation location; afterward, we weigh each candidate IoT service based on its invocation frequency; finally, with the derived two kinds of weights, we evaluate the quality of each candidate IoT service and return the quality-optimal one to the target user.
The rest of article is structured as follows. In section “Formalization and motivation,” the historical records–based IoT service selection problem is specified formally, and afterward, the motivation of our article is demonstrated with an intuitive example. In section “TLF_SSA,” service selection approach named TLF_SSA is introduced in detail. In section “Experiments,” according to a real service quality data set WS-DREAM, a set of experiments are designed, deployed, and tested to validate the feasibility and advantages of our proposal. In section “Evaluation,” we introduce the related works and compare them with our proposal. Finally, in section “Conclusion,” we conclude the article and point out the possible improvement directions in the future.
Formalization and motivation
In this section, we first formalize the historical records–based IoT service selection problem, and afterward, we demonstrate the motivation of this article with an intuitive example.
Formalization
Generally, the historical records–based service selection problem could be formalized with a five-tuple P (Usertarget, IoT_SS, HR, Contexthist, Contexttarget), where
Usertarget denotes the target user who is ready to select a quality-optimal IoT service.
IoT_SS = {service1, …, servicen} represents the candidate IoT service set for Usertarget.
HR = {histj − 1, …, histj − nj} denotes the historical record set of a candidate IoT service servicej. Here, we assume that each IoT service servicej (1 ≤ j ≤ n) owns nj historical records.
Contexthist = {timehist, locationhist}, where timehist and locationhist denote the service invocation time and location of each historical record hist, respectively.
Contexttarget = {timetarget, locationtarget}, where timetarget and locationtarget denote the service invocation time and location of target user, respectively.
With the above formalization, we can specify the historical records–based IoT service selection problem as follows: according to the historical record set HR (each historical record corresponds to a concrete Contexthist) of each candidate IoT service in set IoT_SS, select a quality-optimal IoT service from set IoT_SS based on the service invocation context Contexttarget of target user Usertarget and return it to Usertarget finally.
Motivation
Next, we demonstrate the article’s motivation with an example provided in Figure 1. In Figure 1, target user Tom is ready to select a quality-optimal IoT service on 6 September 2016 in the city of Peking, from the candidate service set IoT_SS = {service1, service2}. Here, service1 has three historical records, that is, hist1-1, …, hist1-3, whose context information (including invocation time and location) is presented in Figure 1, while service2 has 30 historical records, that is, hist2-1, …, hist2-30, whose context information is also shown in Figure 1.

Historical records–based IoT service selection: an example.
As can be seen from Figure 1, the invocation frequencies of service1 and service2 are different; therefore, an inaccurate and unfair service selection result would be generated, if we treat service1 and service2 equally without discriminating their respective invocation frequencies. Besides, for a candidate IoT service (considering service1, for example), its multiple historical records (i.e. hist1-1, hist1-2, and hist1-3) are varied in terms of invocation time and location; therefore, the service selection result would be inaccurate and unfair, if we treat hist1-1, hist1-2, and hist1-3 equally when the quality of service1 is evaluated.
In view of the above two challenges, we put forward a novel service selection approach TLF_SSA in this article. TLF_SSA discriminates each candidate IoT service as well as its multiple historical records, so as to pursue a more accurate service evaluation and selection result, by considering the service invocation time, location, and frequency. The details of our proposed TLF_SSA approach will be introduced in detail in the next section.
TLF_SSA
In this section, a novel IoT service selection approach TLF_SSA is introduced in detail. Concretely, TLF_SSA consists of three steps: in section “Weighting of historical records,” we weigh each historical record of an IoT service based on the service invocation time and location; in section “Weighting of candidate IoT services,” we weigh each candidate IoT service based on its invocation frequency; in section “Quality-optimal service selection,” we evaluate each candidate IoT service and return the quality-optimal one to the target user.
Weighting of historical records
Here, to ease the understanding of readers, we utilize a historical record hist whose context is Contexthist = {timehist, locationhist} for illustration. Next, we introduce how to weigh hist based on its invocation time timehist and location locationhist, respectively.
Time-aware weighting
Generally, the quality of an IoT service is not fixed and static but is varied with time. Here, we model the relationship between invocation time and weight based on the following two intuitive observations.
First, a recent historical record can reflect the up-to-date service quality better and hence contributes more to the service quality evaluation; therefore, a “new” historical record should be given a larger weight. Second, the load similarity between timehist (corresponding to historical record hist) and timetarget (corresponding to target user) should also be considered. For example, we consider a shipping service for illustration. Generally, the shipping speed is low in busy hours (e.g. 8:00 a.m.–8:00 p.m.) because of the heavy traffic load. Therefore, if a target user hopes to invoke the shipping service at 10:00 a.m. (i.e. timetarget = 10:00 a.m.), then a historical record hist-1 whose timehist-1 = 9:00 a.m. would contribute more to the shipping service quality evaluation; on the contrary, another historical record hist-2 whose timehist-2 = 4:00 a.m. would contribute less to the shipping service evaluation as its load similarity (with current service invocation time of target user) is low.
In view of the above analyses, we utilize formula (1) (the former part is based on work; 7 while the latter part is utilized to depict the influence of service load size, as a heavy service load at busy hour often leads to lower service performance) to depict the relationship between invocation time (i.e. timehist) of historical record hist and time-aware weight Wtime(hist) of hist. In equation (1), Dif (timehist, timetarget) denotes the difference between timehist and timetarget, while Simload(timehist, timetarget) is the load similarity between timehist and timetarget. α is a positive parameter, that is, α ≥ 0; Loadhist and Loadtarget denote the service loads corresponding to timehist and timetarget, respectively. Then, through equation (1), we can obtain the time-aware weight of historical record hist, that is, Wtime(hist)

Location-aware weighting
Generally, if the target user is close to IoT services, then the service running quality is high. Therefore, the user–service distance is an important indicator for service running quality. Namely, if the historical user–service distance is close to the target user’s user–service distance, then the historical record hist should be assigned a larger weight. Besides, if locationhist is near locationtarget, then historical record hist often contributes more to the service quality evaluation. 8
With the above analyses, we utilize formula (2) to depict the relationship between location (i.e. locationhist) of historical record hist and the location-aware weight Wlocation(hist) of hist. In equation (2), Dist (locationhist, locationtarget) denotes the distance between locationhist and locationtarget; Dist*( ) is utilized to transform Dist ( ) into range [0,1] (the larger Dist ( ) is, the smaller Dist* ( ) would be, vice versa); dhist-service and dtarget-service represent the historical user–service distance and target user’s user–service distance, respectively. Then, through equation (2), we can obtain the location-aware weight of historical record hist, that is, Wlocation(hist)

Weighting of candidate IoT services
Next, we weigh each candidate IoT service based on its invocation frequency. Generally, target user’s service selection preference follows “bandwagon effect” 9 in social psychology domain, namely, a target user is apt to select those popular services that were invoked frequently. 10 Apart from the invocation frequency, the success rate or failure rate of service invocations also play an important role in the service selection decision process of target user. In order to depict these correlations, we utilize formula (3) to specify the relationship between the candidate service’s invocation frequency and weight.
In equation (3), fre(servicej) denotes the invocation frequency of candidate IoT service servicej; here, the division operation is utilized to transform fre(servicej) into a value in range [0, 1], which is actually a simplification of our previous CSS_HR method in Qi et al.; 10 success_rate(servicej) (∈[0,1]) is the success rate of service servicej and could be calculated by the ratio of the number of successful invocations and the number of total invocations. Then, through equation (3), we can calculate the frequency-aware weight for candidate servicej, that is, Wfrequency (servicej)
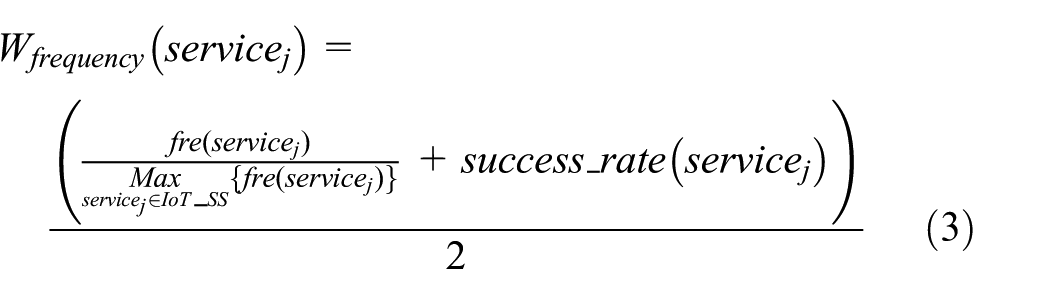
Quality-optimal service selection
With the above two sections, we have obtained the weight of candidate IoT service servicej, that is, Wfrequency (servicej) and the weights for each historical record hist of servicej, that is, Wtime(hist) and Wlocation(hist). Next, with the derived weights, we introduce how to evaluate candidate service servicej, based on its nj historical records.
Here, for simplicity, we assume that there is only a quality dimension q. Next, we utilize formula (4) to evaluate servicej’s quality value over q observed by target user, that is, qtarget-j. In equation (4), qhist-j is the service quality value over q in historical record hist, and nj is the number of historical records of servicej. Concretely,
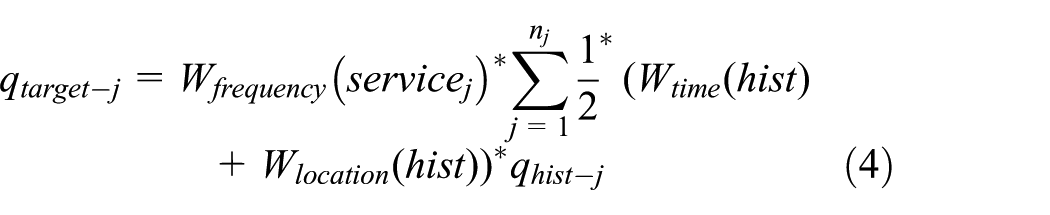
Experiments
In this section, a group of experiments are designed, deployed, and tested to validate the feasibility of our proposal.
Data set
Our experiments are based on a real service quality data set, that is, WS-DREAM. 11 The data set consists of the quality data (e.g. response time and throughput) of 4532 services collected by 142 users in 64 time intervals. The data set provides the sufficient data that are necessary in our approach, for example, service invocation time, user–service location, service load, invocation frequency, and successful rate. Concretely, the recruited users and services are selected randomly from WS-DREAM, so as to ensure the fairness of approach; besides, the historical service invocation time is available by considering the 64 time intervals in WS-DREAM; the triple (IP, Domain Name, Country Name) in WS-DREAM can be recruited as user–service location information in TLF_SSA. Besides, the service invocation whose response time is equal to “time out” is considered as a failed invocation, while the rest invocations are regarded as successful ones. There are 64 historical records for each service in WS-DREAM. So, in order to observe the effect of invocation frequency on service selection accuracy, we randomly drop some historical records for each service. Furthermore, we employ the quality value of 64th historical record as the evaluation benchmark and utilize the prior 63 (or less) historical records as the training data to predict the quality of 64th historical records. Through comparing the predicted quality and the real quality, the accuracy of service selection could be obtained.
In the experiments, we compare our proposal with another three related ones, that is, Average, 12 Last-K, 13 and CSS-HR, 10 in terms of selection accuracy and efficiency. The experiments were deployed on a Dell PC with 2.40 GHz CPU and 2.0 GB RAM. The software configuration environment is Windows XP + MATLAB 7.0. Each experiment was repeated 10 times, and their average results are registered finally.
Experiment results
In the experiments, three profiles are tested, respectively.
Profile 1: Evaluation accuracy comparison
Accuracy is a key metric to compare the performance of different service evaluation and selection methods. 14 So, in this profile, we test the accuracy of TLF_SSA and compare it with another three approaches, that is, Average and Last-K and CSS-HR. In the Average approach, all the historical records of an IoT service are treated equally; in Last-K approach, only the recent K records are recruited for service quality evaluation and treated equally; while in CSS-HR approach, each historical record and each candidate IoT service are weighed and recruited for service quality evaluation. Similar to work, 14 the accuracies of four approaches are calculated by equation (5), where qeva is the service quality evaluated by one of the four approaches, while qreal denotes the real service quality (here, q denotes a quality dimension, for example, response time or throughput). Parameter α = 0.09 holds in TLF_SSA
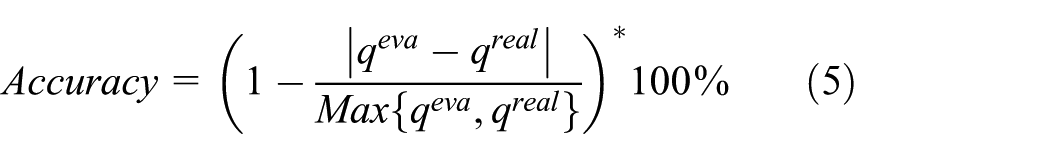
A total of 20 IoT services, that is, ws1, …, ws20 are randomly selected from WS-DREAM and are regarded as target services that are ready to be evaluated. Afterward, based on equation (5), we test the evaluation accuracy of four approaches over response time and throughput, respectively. The concrete experiment results are presented in Figure 2. As indicated in Figure 2(a), the accuracy (over throughput) of Last-K approach is not high, as it only considers the invocation time of historical records, while overlooking another important context factor, that is, invocation location. Similar to Last-K approach, the accuracy of Average approach is also low, as it adopts the “average” idea and does not discriminate the historical records of an IoT service.

Evaluation accuracy comparison of four approaches: (a) throughput and (b) response time.
The evaluation accuracy of CSS-HR is improved by considering more context information of historical records, such as time, location, and user input. However, the accuracy of CSS-HR is still not as high as expected because (1) it only considers the difference between historical invocation time and target user’s invocation time, without considering the invocation time similarity (e.g. busy hour or free hour in 1 day); (2) it only considers the historical user–service distance and target user’s user–service distance, without considering the similarity between historical user location and target user’s location; and (3) it only considers the invocation frequency of services, while overlooks the success rate of service invocations. As shown in Figure 2(a), our proposed TLF_SSA outperforms CSS-HR as our proposal overcomes the above three shortcomings. Similar experiment results could be observed in Figure 2(b) (for quality dimension response time), which will not be explained repeatedly here.
Profile 2: Execution efficiency comparison w.r.t. n
Next, we test and compare the execution efficiency of four approaches with respect to the number of candidate services, that is, n. Concretely, the parameters are set as follows: the number of candidate IoT services, that is, n is varied from 1000 to 5000; each service has 64 historical records; Parameter K = 4 holds in Last-K approach; Parameter α = 0.09 holds in TLF_SSA. The experiment results are shown in Figure 3.

Execution efficiency comparison w.r.t. n.
As shown in Figure 3, the time costs of four approaches all increase approximately linearly when n grows because each candidate IoT service should be evaluated for further quality-optimal service selection. Generally, the time cost of Last-K approach is the best as it only considers the K recent historical records of a service; the time cost of Average approach is also low as it only adopts the simple “average” idea that is easily calculated. The time costs of CSS-HR and TLF_SSA are close and larger than those of Last-K and Average. This is because more service invocation context information is considered in CSS-HR and TLF_SSA, such as invocation time, location, and frequency. However, as shown in Figure 3, the time cost of our proposal is often acceptable (at “second” level).
Profile 3: Execution efficiency comparison w.r.t. nj
In this profile, we test the execution efficiency of our proposed TLF_SSA approach with respect to the number of historical records of an IoT service, that is, nj, and compare it with other three ones. Concretely, the experiment parameters are set as follows: the number of candidate IoT services, that is, n = 1000 holds; the number of historical records of servicej, that is, nj is varied from 10 to 50; Parameter K = 4 holds in Last-K approach; Parameter α = 0.09 holds in TLF_SSA. The experiment results are shown in Figure 4.

Execution efficiency comparison w.r.t. nj.
As shown in Figure 4, the time cost of Last-K approach is the lowest and stays approximately stable with the growth of nj, as only the recent K historical records of a service are considered in Last-K. The time costs of rest three approaches all increase approximately linearly with the growth of n because all the historical records of a service are recruited for service quality evaluation. Besides, the time cost of Average approach is relatively low, as its adopted “average” idea requires little computation time. While the time costs of CSS-HR and TLF_SSA are close and larger than those of rest two approaches, more context information associated with service invocation needs to be considered. However, as shown in Figure 4, the time cost of our proposal is often acceptable (at “millisecond” level).
Evaluation
In this section, the time complexity of our proposal is analyzed first. Afterward, we introduce the related works and compare them with our proposal. Finally, we discuss the potential shortcomings of this article and point out the possible research directions in the future research.
Complexity analyses
We assume that there are n candidate IoT services and each service has nj historical records. Then, in Step 1, for each historical record, its time-aware weight could be calculated based on equation (1), whose time complexity is O(1); likewise, the location-aware weight of each historical record could be calculated based on equation (2), whose time complexity is O(1). As there are totally n*nj historical records, the time complexity of Step 1 (i.e. section “Weighting of historical records”) is O(n*nj). In Step 2 (i.e. section “Weighting of candidate IoT services”), we should first determine the maximal invocation frequency of all services, whose time complexity is O(n). Afterward, for each candidate service, its frequency-aware weight could be calculated based on equation (3), whose time complexity is O(nj). As there are totally n candidate services, the time complexity of Step 2 is O(n + n*nj) = O(n*nj). In Step 3 (i.e. section “Quality-optimal service selection”), each candidate service is evaluated based on equation (4), whose time complexity is O(nj); as there are totally n candidate services, the time complexity of Step 3 is O(n*nj).
With the above analyses, we can conclude that the total time complexity of our proposed TLF_SSA is O(n*nj). This means that our approach could be executed in polynomial time, which has been validated in the experiment part.
Related works and comparison analyses
Quality of service (QoS) plays an important role in discriminating and ranking IoT services. Fok et al. 15 introduce a series of QoS criteria associated with IoT services, for example, network-related criteria like latency and bandwidth, device-related criteria like battery power and memory, environment-related criteria like location and temperature, or application-related criteria like precision and responsiveness. However, some “fine-grained” quality criteria (e.g. battery power) are often varied with time and not easy to be captured; therefore, some coarse-grained quality criteria like service invocation time and location are often recruited to evaluate the quality of a service. 16
Due to the exaggerated quality propagation and unstable network environment, the service quality published by IoT service providers is not always trusted, which makes it necessary to evaluate the service quality based on its historical records. However, the service invocation context of multiple historical records of a service is often varied, which makes it a challenge to weigh each historical record for further accurate and fair service quality evaluation. Many researchers have investigated this problem and put forward various solutions.
In a study by Qi et al., 12 weight problem of multiple historical records of a service is discussed, and finally, a naive Average idea is adopted which does not discriminate the importance of different historical records. In order to discriminate the importance of different historical records, a time-aware weighting approach named Last-K is put forward in http://www.bestbuy.com/, 13 where only the recent K historical records regarded as useful and each recruited historical record is assigned a same weight 1/K. However, Last-K only considers some “new” historical records, while overlooks some “old” but important ones. Similarly, a weight model Partial-HR is proposed in Qi et al., 17 where only the recent 20% historical records are employed for service evaluation. Liu et al. 18 and Wu et al. 19 adopt “arithmetical progression” manner and “geometric progression” manner, respectively, for weight assignment of historical records. However, the above approaches only consider the service invocation time in weight assignment, while omit other important context information. Chen et al. 20 utilize user–service location information for service QoS evaluation and prediction, while neglect other key context factors that influence the IoT service quality, for example, service invocation time, service invocation frequency, and service invocation successful rate.
In view of the above shortcomings, a context-aware service selection approach, that is, CSS_HR is brought forth in a study by Qi et al. 10 CSS_HR combines many important context factors for weight assignment, for example, service invocation time, location, and frequency. However, there are still some shortcomings in CSS_HR approach: (1) it only considers the difference between historical invocation time and target user’s invocation time, without considering the invocation time similarity (e.g. busy hour or free hour); (2) it only considers the historical user–service distance and target user’s user–service distance, without considering the similarity between historical user location and target user’s location; (3) it only considers the invocation frequency of services, while overlooks the success rate of service invocations. In view of the above shortcomings, a novel “TLF”-aware IoT service selection approach, that is, TLF_SSA is put forward in this article, which makes full use of the service invocation context information, so as to achieve more accurate service selection results. Finally, through a set of experiments deployed on a real service quality data set WS-DREAM, we validate the feasibility and advantages of our proposal in terms of selection accuracy and efficiency.
Further discussions
In this paper, we put forward a multi-dimensional evaluation and selection approach for IoT services based on the weighting model of historical records. Generally, our proposed weighting model is generic and could be easily modified and applied in other weight-aware application domains, such as learning and classification,21–24 content searching,25–31 information detection,32–41 and performance optimization.42–49 However, there are still several shortcomings in our paper, which are discussed as below:
Our proposed weight model only considers three kinds of context information, that is, service invocation time, location, and frequency. While actually, the service invocation context information is very rich. Therefore, in the future, it is necessary to improve our proposal by including more context factors into our weight model.
In this article, we evaluate the IoT service quality based on some generic and “coarse-grained” quality criteria like service invocation time, location, frequency, and successful rate, while neglect some “fine-grained” quality criteria like actuating frequency, computational power, and network overheads of an IoT service. Therefore, in the future, we hope to refine our approach by including more “fine-grained” quality criteria and apply the approach in real service scheduling process of IoT workflows.
Conclusion
In this article, we put forward a novel IoT service selection approach TLF_SSA based on historical records, so as to achieve more accurate and fair service selection results. Concretely, we first weigh each historical record based on its service invocation time and location; afterward, we weigh each candidate IoT service based on its invocation frequency; finally, with the derived two kinds of weights, we evaluate each candidate IoT service and return the quality-optimal one to the target user. Through a set of experiments deployed on a real service quality data set WS-DREAM, we validate the feasibility of our proposal. In the future, we will further improve our proposal by introducing more context factors and more “fine-grained” quality criteria (e.g. computational power and network overheads) of IoT services into our weighting model.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper is partially supported by Natural Science Foundation of China (nos. 61402258, 61602253, 61373027, and 61672321) and Open Project of State Key Laboratory for Novel Software Technology (no. KFKT2016B22).