
Abstract
In modern times, it has been observed that Internet of things technology makes it possible for connecting various smart objects together through the Internet. For the effective Internet of things management, it is necessary to design and develop service models that ensure appropriate level of quality-of-service. Therefore, the design of quality-of-service management schemes has been a hot research issue. In this work, we formulate a new quality-of-service management scheme based on the IoT system power control algorithm. Using the emerging and largely unexplored concept of the R-learning algorithm and docitive paradigm, system agents can teach other agents how to adjust their power levels while reducing computation complexity and speeding up the learning process. Therefore, our proposed power control approach can provide the ability to practically respond to current Internet of things system conditions and suitable for real wireless communication operations. Finally, we validate the introduced concept and confirm the effectiveness of the proposed scheme in comparison with the existing schemes through extensive simulation analysis.
Keywords
Introduction
The Internet of things (IoT) is regarded as a new technology and economic wave in the global information industry after the Internet.1–3 In order to achieve anytime and anywhere functionality, the IoT equipment must connect, interact, and collaborate with the surrounding environment. For the effective IoT management, more quality of service (QoS) attributes must be considered, including information accuracy, coverage of IoT, required network resources, and energy consumption. Therefore, with regard to IoT services, QoS has been a popular research issue. Typically, different IoT applications have different QoS requirements. Nowadays, the requirement of QoS is considered to be an important non-functional element for the IoT system and must be guaranteed while implementing effective resource allocation and scheduling algorithms.4,5
In current methods, in order to provide QoS to applications, real-time QoS schedulers are introduced in the IoT structure. 3 A QoS scheduler is an IoT system component designed to control the IoT system resources for various application services. In each local area, QoS schedulers assign the system resources to contending agents based on a set of criteria, namely, transmitter power, transmission rate, and QoS constraint. 5 During IoT system operations, these QoS schedulers aim to maximize system utilization while providing QoS requirements to classes of applications that have very tight requirements such as bit rate and delay. However, it is challenging to practically balance between network availability and QoS ensuring.3,5,6
Game theory is a powerful tool to study situations of conflict and cooperation and is concerned with finding the best actions for individual decision makers, that is, players in these situations and recognizing stable outcomes. 7 It has been extensively used in microeconomics field, and only during the last years, it has received attentions as an effective method to design and model a distributed QoS control problems in telecommunications. 7 In this article, we develop a new game model called team game (TG). In our TG model, QoS schedulers are assumed as game players. All game players organize a team, and actions of all players are coordinated to ensure team cooperation by considering a combination of individual payoff as a team payoff. The main concept of TG is to extend the well-known Markov decision problem (MDP) to the multi-player case.
Traditionally, game theory assumes that players have perfect information about the game, enabling them to calculate all of the possible consequences of each strategy selection. 7 However, in real-world situations, a player must make decisions based on less-than perfect information. If a player does not have total information about the game, then it follows that the player’s reasoning must be heuristic. Therefore, to maximize IoT performance, the way in which agents learn network situations and make the best decisions by predicting the influence of others’ possible decisions is an important research issue in the field of IoT networking.8–10
In recent years, many learning algorithms have been developed in an attempt to maximize system performance in non-deterministic settings.8,11,12 Generally, learning algorithms guarantee that collective behavior converges to a coarse equilibrium status. In order to make control decisions in real time, QoS schedulers should be able to learn from dynamic system environments and adapt to the current network condition. Therefore, QoS schedulers using learning techniques acquire information from the environment, build knowledge, and ultimately improve their performance.3,8,10
In 1993, A Schwartz 13 introduced an average-reward reinforcement learning algorithm called R-learning algorithm. Like Q-learning, R-learning algorithm uses the action value representation. In addition, it also needs to learn the estimate of the average reward. Therefore, R-learning algorithm is performed by the two time-scale learning process. In contrast to the value-iteration-based learning algorithms, the decision-learning approach in the R-learning algorithm allows an agent to directly learn the stationary randomized policy and directly updates the probabilities of actions based on the utility feedback. 14
Recently, there has been increasing interest in research of various R-learning algorithms. However, in this field, many problems still remain open. Even though the R-learning algorithm has received strong attentions, designing a novel R-learning algorithm for real-world problems is still difficult. There are many complicated restrictions, which are often self-contradictory and variable with the dynamic real-world IoT environment.
Docitive paradigm is an emerging technology to overcome the current limitations of R-learning algorithm. 15 Not only based on the cooperation to learn but also on the process of knowledge transfer, this paradigm can significantly speed up the learning process and increase precision. The docitive paradigm can provide a timely solution based on knowledge sharing in a cooperative fashion with other players in the IoT system, which allows game players to develop new capacities for selecting appropriate actions.15,16
In this article, we develop a new IoT system power control scheme to ensure QoS provisioning. In the proposed scheme, we focus on how to integrate our TG game model and R-learning algorithm to tackle the QoS control problem in IoT systems. To implement the self-adaptability and real-time effectiveness, we adopt the docitive paradigm. Therefore, game players try to select optimal strategies in a distributed manner while approximating a common objective. According to the iterative TG game model, the proposed scheme attempts to ensure that individual decisions of players result in jointly optimal decisions for the players’ team. The main contributions of our study are as follows: (1) we develop a novel power control algorithm for IoT system, (2) we integrate the game theory and R-learning algorithm to tackle the power decisions, (3) we adopt the distributed learning approach to implement the self-adaptability and real-time effectiveness, and (4) we adopt the docitive paradigm to provide a timely solution. The most important novelty of our proposed scheme is the responsiveness to current IoT system conditions depending on the exchange of information and expert knowledge from other players, the so-called docitive players.
Related work
Over the years, a lot of state-of-the-art research work on the QoS control problem has been conducted. The QoS-based device-to-device communication (QDDC) scheme in the study of Dai et al. 17 was a novel device-to-device communication algorithm to enhance the spectrum efficiency. This scheme exploited the trade-off in power allocation of device-to-device transmitters while maximizing the number of allowed accessing device-to-device pairs under the QoS constraints. Then, the released communication resource would be separated into different device-to-device pairs. The QDDC scheme can be easily extended to the uplink case and the multiple channel case. 17
The deterministic sequencing of exploration and exploitation (DSEE) scheme 18 was developed as a new approach to the multi-armed bandit (MAB) problem, which is a class of sequential learning and decision problems with unknown models. Based on a DSEE, the DSEE scheme can find the minimum cardinality of the exploration sequence that ensures a reward loss in the exploitation sequence caused by incorrectly identified arm rank having an order no larger than the cardinality of the exploration sequence. 18
The non-Bayesian social learning (NBSL) scheme by Jiang et al. 19 studied how users in a dynamic system learned the uncertain system state and made multiple concurrent decisions by not only considering the current myopic utility but also taking into account the influence of subsequent users’ decisions. This scheme designed the recursive best response algorithms to find the subgame perfect Nash equilibrium for users and characterize special properties of the Nash equilibrium profile under homogeneous setting. 19
The multi-armed bandit with unknown dynamics (MBUD) scheme 20 also considered the restless MAB problem with unknown dynamics in which a player chose one out of N arms to play at each time. The reward state of each arm transited according to an unknown Markovian rule when it was played and evolved according to an arbitrary unknown random process when it was passive. The MBUD scheme constructed a policy with an interleaving exploration and exploitation epoch structure that achieved a regret with logarithmic order. 20 All the earlier work has attracted a lot of attention and introduced unique challenges to efficiently solve the QoS control problem. Compared to these schemes,17,18 the proposed scheme attains better performance during the IoT system operations.
The rest of this article is organized as follows. First, the traditional MDP and R-learning algorithm are introduced in section “Markov decision process and R-learning algorithm.” Next, we formulate and explain the proposed TG model to solve the QoS problem in section “Proposed QoS control scheme for IoT systems.” In section “Performance evaluation,” we verify the effectiveness and efficiency of the proposed scheme from simulation results. Finally, we draw conclusions in section “Summary and conclusion.”
Markov decision process and R-learning algorithm
MDP is a mathematical framework for modeling decision making in situations and is useful for optimization problems solved via reinforcement learning. Based on inputs to a dynamic system, MDP probabilistically determines a successor state and continues for a finite or infinite number of stages.7,8,12,21,22 Traditionally, MDP is defined as a tuple
The objective of the MDP is to find a policy that minimizes the cost of each state

where
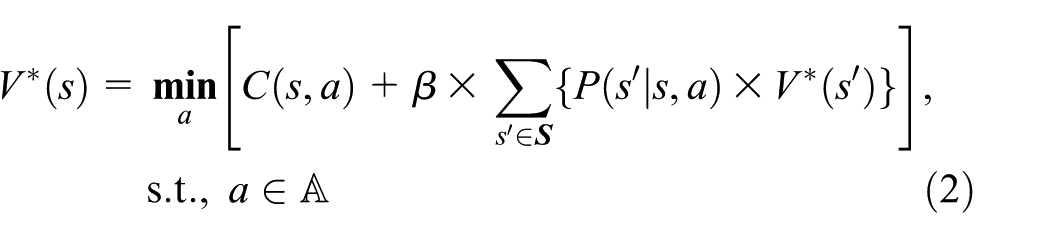
where
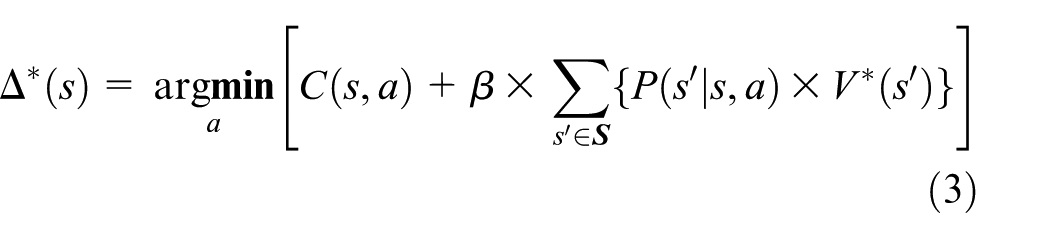
To solve equation (3), reinforcement learning algorithms are common way. There exists several reinforcement learning algorithms. In this study, we adopt a novel average-reward reinforcement learning algorithm called R-learning. Like other reinforcement learning algorithms, R-learning algorithm uses the action value representation.13,14 The action value

where
Proposed QoS control scheme for IoT systems
In this section, we examine the applicability of MDP to design a novel power control algorithm and develop a new TG model for IoT systems. The proposed model can significantly improve the success rate of IoT services.
QoS-aware service management in the TG model
To develop our QoS-aware service management scheme, we assume and simplify the real-world situation for practical implementations:
Power strategies in each QoS schedulers are quantified. Usually, practicality is decided based on the computation complexity. Therefore, power levels should be simplified.
We assumed four QoS schedulers’ system in a local area like a conference room or small office part. Therefore, the proposed scheme has been developed as a four-player game model.
Pre-defined minimum bound
Heterogeneous traffic services are categorized into two classes according to the required QoS: class I (real-time) traffic services and class II (non real-time) traffic services. Class I data services are highly delay sensitive, and strict deadlines are applied. However, some flexible data services are called as class II traffic services; they are rather tolerant of delays.
If our model is applied in the situation with hundreds or thousands of QoS schedulers in a huge area, each QoS schedulers must be grouped and clustered in a distributed manner. Using a locally distributed approach, the proposed scheme is applied iteratively in each cluster.
In this study, we consider a new power control mechanism for IoT systems. Under the multi-QoS schedulers’ environment, we formulate the multiple decision-making process as a new TG model based on the multi-agent R-learning approach. Mathematically, the TG model
N is the set of all QoS schedulers.
Usually, traditional solution concept of game theory is obtained with the following impractical assumptions: (1) fully rational players, (2) complete information, and (3) static game-model setting. These assumptions only hold in the theoretical and idealistic analysis. In the real-world IoT operations, it is impossible to transform the dynamic setting to static simulation setup. It means that the traditional solution with fully rational players is technically impossible to be obtained in the real world. To practically design the TG model, we develop a new solution concept called stable equilibrium (SE). Based on the R-learning and docitive paradigm, SE is applicable to the repeated choice in learning situations. For our TG, we assume that SE is a discrete set probability distributions over the available strategies chosen by all players.
Power control algorithm based on the R-learning algorithm
In the proposed power control scheme, we focus on how we can tackle the QoS control problem based on the R-learning algorithm approach. According to the self-adaptability, QoS schedulers in the proposed scheme can update the strategy based on the observations while responding to current IoT system conditions. Usually, the main interest of each QoS scheduler is to maximize the amount of transmitted data with the lower power consumption. However, there is a fundamental trade-off. To capture this conflicting relationship, a utility function
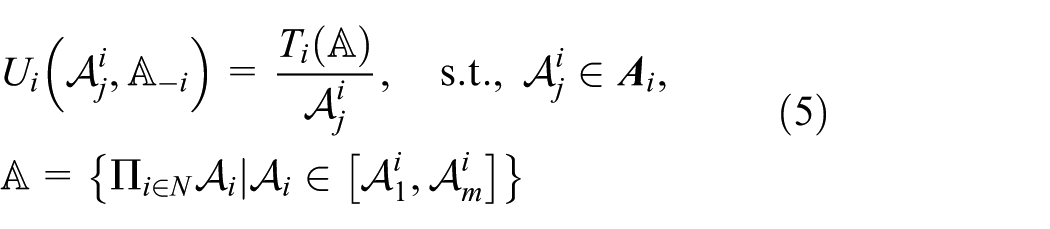
where

where W is the assigned channel bandwidth, and Ω (Ω ≥ 1) is the gap between uncoded M-ary quadrature amplitude modulation (M-QAM) and the capacity, minus the coding gain. 7 Finally, the ith scheduler’s utility is defined as follows

In the developed game model, different schedulers can receive different payoffs for the same state transition. Based on our TG approach, schedulers seek to choose their power levels self-interestedly to maximize their payoffs. According to the R-learning equation (4), the expected payoff of QoS scheduler is

In our TG game model, each QoS scheduler is interested in the goal of maximizing his utility function. In a distributed self-regarding fashion, each QoS scheduler in a dynamic IoT system learns the uncertain IoT situation and makes a power control decision by taking into account the online feedback mechanism. With an iterative repeating process, schedulers’ decision-making mechanism is developed based on the R-learning algorithm, which is an effective way for schedulers’ decision mechanism. Based on the dynamic learning mechanism, the developed algorithm can constantly adapt each QoS scheduler’s power level to get an appropriate performance balance between contradictory requirements.
Based on the feedback learning process, the proposed scheme can capture how schedulers adapt their power levels to achieve the better benefit. This procedure is defined as an online power control algorithm. In the proposed scheme, a selection probability for each power level strategy is dynamically changed based on the payoff ratio, which means the strategy convergence. Therefore, schedulers examine their payoffs periodically in an entirely distributed fashion. Without any impractical rationality assumptions, schedulers can modify their power levels in an effort to maximize their
In equation (9), defining of
Power levels chosen by the schedulers are given as input to the environment, and the environmental response to these power levels serves as an input to each scheduler. Therefore, multiple schedulers are connected in a feedback loop with its environment. When a scheduler selects a power level with his respective probability distribution
At every game round, all schedulers update their probability distributions based on the R-learning algorithm. If the scheduler i chooses

The QoS schedulers have to learn an effective action in a distributed fashion while achieving the common objective of IoT system. Known as multi-agent learning approach, we solve this problem using distributed R-learning algorithm and docitive paradigm. In the proposed TG model, the main challenge is how to ensure that individual decisions of each QoS scheduler approximate jointly optimal decisions for the team. As a docitive player, individual QoS schedulers cooperate with others by exchanging information while learning the action’s propensity from other team members, who are also performing power controls from the R-learning algorithm. In order to apply this approach, QoS schedulers periodically exchange their updated

where

The main steps of proposed scheme
In this work, we discuss a new perspective in IoT systems to design the QoS control algorithm. In the proposed scheme, QoS schedulers adaptively decide their power levels while satisfying the QoS needs in coverage areas. Based on past actions and environmental feedback, we consider the R-learning algorithm and docitive paradigm that attempt to find out optimal actions effectively. Until now, several game models have been developed to help game players to learn from the dynamic network environment. An important feature in our TG model is to enable game players to reach quickly a certain desired game outcome.
From the result of individual learning experiences, each scheduler can learn how to effectively play under the dynamic network situations. Therefore, the payoff estimation at each game iteration can be used to update the
Step 1. At the initial time,
Step 2. At the end of each game’s iteration, each QoS scheduler estimates independently its own payoff
Step 3. Based on the currently received information, each QoS scheduler periodically adjusts
Step 4. According to the docitive paradigm, each QoS scheduler receives the
Step 5. Using the proportion to each strategy’s propensity, each
Step 6. Iteratively, each QoS scheduler selects a strategy
Step 7. The sequential R-learning process is repeatedly operated in a distributed manner

where
Step 8. If all QoS schedulers reach the SE status, the game process is temporarily stopped. The SE status is formally defined as follows

Step 9. Constantly, each QoS scheduler is self-monitoring the current IoT situation. If the current system status is not the SE, it proceeds to Step 2 for the next iteration.
System parameters used in the simulation experiments.

QoS: quality of service; M-QAM: M-ary quadrature amplitude modulation.
Performance evaluation
In this section, we compare the performance of the proposed scheme with other existing schemes. As mentioned in section “Introduction,” we select the QDDC scheme 17 and the DSEE scheme 18 and can confirm the performance superiority of our approach through the simulation analysis. The QDDC and DSEE schemes have been recently published and introduced unique challenges to efficiently solve the system control problems. The assumptions of our simulation environment are as follows:
The simulated system consists of four QoS schedulers for a IoT system.
In each scheduler covering area, a new service request is Poisson with rate
The number of power levels (m) for QoS schedulers is three, and each strategy
System performance measures obtained on the basis of 100 simulation runs are plotted as a function of the offered traffic load.
The message size of each application is exponentially distributed with different means for different message applications.
For simplicity, we assume the absence of physical obstacles in the experiments.
To facilitate the development and implementation of our simulator, Table 1 lists the system parameters.
In this section, the performance of the proposed scheme is compared with two existing schemes: the QDDC scheme 17 and the DSEE scheme. 18 Even though these existing schemes are recently published novel protocols, there are several disadvantages. First, these existing schemes rely on the impractical assumption for real operations; inapplicable presumption can cause potential erroneous decisions. Second, they cause the extra control overhead. The increased overhead can exhaust the system resources and need intractable computation. Third, these schemes cannot adaptively estimate the current system conditions. Fourth, these schemes operate the system by some fixed system parameters. Under dynamic real-world environments, it is an inappropriate approach to operate the IoT system.
Performance measures obtained through the simulation are IoT system throughput, service success probability, normalized service delay, system power stability, and application incomplete ratio. In Figures 1–5, the x-axis (a horizontal line) marks the service load intensities, which is varied from 0 to 3.0. Based on each rate of offered service load, performance criteria are evaluated as a normalized value; y-axis (a vertical line) represents the normalized value for each performance criteria.

IoT system throughput.

IoT service success probability.

Normalized service delay in IoT systems.

System power stability.

Application incomplete ratio in IoT system.
Figure 1 shows the performance comparison of each scheme in terms of IoT system throughput. In this work, the IoT system throughput is measured as the normalized number of information bits that are transmitted without error per unit-time. Traditionally, it is one of the most critical aspects of the IoT management. The proposed TG-based approach adaptively decides power levels in an interactive-cooperative manner while monitoring the current system conditions. Therefore, the system throughput of the proposed scheme is better than the other schemes.
Figure 2 represents the service success probability of each IoT control scheme. In this work, service success probability is defined as the success ratio of service requests. In general, the excellent service success rate is a highly desirable property for actual IoT operations. As the offered traffic load increases, excessive service requests may lead to system congestion. Therefore, the service success probability decreases. This is intuitively correct. Under various application service requests, our game-based R-learning approach effectively handles the power control problem in IoT systems and leads to a better service success probability than other existing scheme.
Figure 3 reveals the normalized service delay in IoT systems. Usually, service delay is an important QoS metric and is able to reveal the fitness or unfitness of system protocols for different delay-sensitive applications. Due to the feedback-based repeated game approach, our proposed scheme can dynamically adapt the current situation and has much better accuracy than other existing schemes.
Figure 4 indicates the IoT system power stability of each scheme. In this study, the system power stability meant that the ratio of the actual power changes to the total power control periods. All the schemes have similar trends. However, our docitive paradigm–based power control policy can make the IoT network system more stable. Therefore, the proposed scheme can maintain the steady state under various network load intensities.
The curves in Figure 5 present the application incomplete ratio in the IoT System. As the offered traffic load increases, the IoT system will run out of the capacity for application service operations. Therefore, requested applications are likely to fail to meet the minimum QoS provisioning. Therefore, the application incomplete ratio increases linearly with the traffic load. From low to high traffic load intensities, the proposed scheme achieves a lower application incomplete ratio than other schemes.
The performance trends presented in Figures 1–5 are very similar. However, using the TG-based R-learning mechanism, the proposed scheme is flexible, adaptable, and able to sense the dynamic changing IoT system environment; it is essential in order to be close to the optimized system performance. Under diversified IoT traffic condition changes, the simulation result of proposed scheme is much better than the other schemes. Especially, the IoT system throughput, service success probability, normalized service delay, system power stability, and application incomplete ratio are improved by about 5%, 5%, 10%, 20%, and 10%, respectively, than the existing QDDC and DSEE schemes.17,18
Summary and conclusion
The IoT is emerging as one of the major trends shaping the development of technologies in the Internet paradigm. The IoT technology has been evolving due to a convergence of multiple technologies, ranging from wireless communication to the Internet and from embedded systems to micro-electromechanical systems. However, the diversity of applications causes the QoS control problem in IoT platform. This study provides a novel QoS control algorithm for IoT systems. Based on the R-learning algorithm and docitive paradigm, we develop a new TG model. In the proposed game model, QoS schedulers iteratively observe the current IoT system conditions and adaptively change their power levels to maximize the system performance. Due to the self-regarding feature, these control decisions are made by an entirely distributed fashion. In actual IoT system operations, the distributed learning approach is suitable for ultimate practical implementation. Compared with the existing schemes, the simulation results showed that our proposed scheme effectively handles the current IoT system to achieve the better benefit.
Footnotes
Academic Editor: Poh Chong
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the MSIP (Ministry of Science, ICT, and Future Planning), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2016-H8501-16-1018) supervised by the IITP (Institute for Information & communications Technology Promotion) and was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2015R1D1A1A01060835).