
Abstract
Energy is a scarce resource in real-time embedded systems due to the fact that most of them run on batteries. Hence, the designers should ensure that the energy constraints are satisfied in addition to the deadline constraints. This necessitates the consideration of the impact of the interference due to shared, low-level hardware resources such as the cache on the worst-case energy consumption of the tasks. Toward this aim, this article proposes a fine-grained approach to analyze the bank-level interference (bank conflict and bus access interference) on real-time multicore systems, which can reasonably estimate runtime interferences in shared cache and yield tighter worst-case energy consumption. In addition, we develop a bank-to-core mapping algorithm for reducing bank-level interference and improving the worst-case energy consumption. The experimental results demonstrate that our approach can improve the tightness of worst-case energy consumption by 14.25% on average compared to upper-bound delay approach. The bank-to-core mapping provides significant benefits in worst-case energy consumption reduction with 7.23%.
Introduction
Real-time embedded systems are becoming widespread, ranging from sensor networks, Internet of Things (IoT) systems,1,2 and surveillance systems to satellite subsystems. For real-time embedded systems, energy consumption are important design issues, since most of them operate on batteries or drain energy from limited sources. Several authors have argued that when energy plays an important role, it should also become a key factor when it comes to making scheduling decisions.3–5 That is, in addition to ensuring the deadline constraints, designers also consider whether or not there is enough energy available in the system for the task to complete execution. As a consequence, besides bounding worst-case execution time (WCET) of a task, designers need to analyze the worst-case energy consumption (WCEC) of the task for avoiding potential system failures due to inadequate energy supply at runtime.
Currently, real-time systems are increasingly moving toward multicore architectures. To mitigate the high latency of the off-chip memory, multicore architectures are usually equipped with the on-chip caches. The caches can significantly improve the performance, but its energy consumption is a concern, Several studies6,7 report that the cache energy consumption accounts for up to 50% of the overall chip due to its large on-chip area and high access frequency. Clearly, the caches are good candidates for energy optimization. Various techniques have been proposed over the years to reduce the energy consumption of the caches; however, in many of these works,8,9 cache energy models are not tailored to the worst case, and bank-level interference issues are not considered in all these works .
In multicore architecture, the shared cache consists of multiple banks, and cache requests to different banks can be serviced in parallel. However, a bank can only handle one cache request at a time. When two or more cache requests try to access the same bank at the same time, the bank conflict occurs. The bank conflict complicates system behavior, leading to difficulties for the WCET analysis and an important waste of energy. Therefore, its influence on WCET and WCEC has to be taken into account for ensuring safety of systems. To the best of our knowledge, only Paolieri et al.’s 10 work and Yoon et al.’s 11 work considered bank conflict on WCET estimation. But they all employ the upper-bound delay (UBD) approach to estimate the interference delay, in which a potential maximum delay (i.e. UBD) that each cache request suffers is bounded, then, this delay is added to each request during WCET analysis. However, not all requests can suffer from bank conflict, even though bank conflicts occur among a group of requests, the delay of bank conflict suffered by each request is different. This method will not only cause pessimistic WCET estimation, but also provide a conservative over-approximation of the WCEC of the task.
In this article, we investigate the impact of bank-level interference on WCEC for real-time multicore systems where the shared cache with multiple banks is used to improve performance. We assume that the target real-time embedded system is a hard real-time system where the deadline constraint of each hard real-time task (HRT) must be met. We make the following major contributions.
We model the WCEC of shared cache from the perspective of HRTs and analyze the WCEC of the HRT.
We present a fine-grained approach to analyze bank-level interference based on request timing, which can bring benefit for the tightness of WCEC. In our approach, we assume that the access to the shared cache is granted using a Interference-Aware Bus Arbiter (IABA). 10
We apply bank-to-core mapping to optimize interference delay and develop an algorithm for finding the best bank-to-core mapping according to the queue of cores, such that the impact of bank-level interference on the WCEC is minimized.
The rest of this article is organized as follows. Section “Related work” reviews the related work on the energy-optimization techniques of cache and bank-level interference analysis. Section “System model” introduces the system model, task model, and cache energy model. In section “Bank-level interference analysis and WCEC computation,” we analyze the delay of bank-level interference suffered by a HRT. In section “Bank mapping optimization for WCEC reduction,” we design an algorithm for finding the best bank-to-core mapping. Section “Evaluation” presents experimental results. Finally, we conclude this article in section “Conclusion and future work.”
Related work
In the existing works, various techniques have been proposed to reduce inter-core interference and optimize the energy consumption of the cache. Most of these techniques aim to improve the average case energy consumption of the cache. Furthermore, they mainly focus on the effect of cache storage interference on energy consumption. Here, we analyze some of the works that we have separated into two different categories: (1) works that focus on cache reconfiguration and (2) works that focus on cache partitioning.
Reconfigurable cache
Several reconfigurable7,13 cache have been proposed for performance improvement, energy saving, and contention reduction. Zhang et al. 7 proposed a highly reconfigurable cache architecture, where cache characteristics (such as cache way, block size, and associativity) could be tuned via hardware configuration registers. This cache architecture can achieve up to 40% energy saving, but which cannot guarantee the strict cache isolation among real-time applications. In Hajimiri et al., 14 inter-task dynamic cache reconfiguration (DCR) technique has been proposed to reduce the contention and optimize energy consumption of the cache in real-time systems. In Mittal et al., 15 a multicore cache energy saving technique using dynamic cache reconfiguration was proposed to save cache energy by periodically allocating suitable amount of cache space to each running programs.
Cache partitioning
Cache partitioning technique partitions the shared cache into separate regions and designates one or a few regions to individual cores, which can fully eliminate the cache storage interference. Many research works have been done to reduce the interference and optimize energy consumption by cache partitioning. Qureshi and Patt 16 presented a low-overhead cache partitioning technique based on online monitoring and cache utilization of each application. By leveraging configurable cache architecture, authors 17 proposed a technique to eliminate inter-task cache storage interference and optimize cache energy. Suhendra and Mitra 18 proposed the use of shared cache in a predictable manner through a combination of locking and partitioning mechanisms, and explored possible design choices and evaluated their effects on the worst-case application performance.
However, cache partitioning only eliminates cache storage interference and cannot avoid the bank conflict. Paolieri et al. 10 partitioned shared cache using bank-level partitioning or column-level partitioning. In bank-level partitioning, each task is assigned to private bank, and this partitioning requires as many banks as the number of tasks in the system. In column-level partitioning, the shared cache is partitioned into columns, allocating exclusively a subset of the total number of columns to each task, but tasks still experience bank conflict when accessing the same bank at the same time. In this case, they bound the UBD of the bank conflict to compute interferences delays. Yoon et al. 11 proposed harmonic round-robin bus arbitration and bank-column cache partitioning scheme, in which bank conflict can be limited in one bus round through optimizing the allocation of bus slots among cores. These approaches took the effect of bank conflict delay into consideration, where a potential maximum delay is added to the time that a request accesses L2 cache. In fact, not all requests can suffer from inter-core interference. Even though inter-core interferences occur among a group of requests, the interference delay suffered by each request is different due to the state of different interference. These approaches based on the maximum delay leads to significant overestimation on WCET, which has a negative impact on the schedulability analysis, performance checking and WCEC of the task.
Unlike the existing works, we investigate the impact of the bank-level interference. Such work is fundamental in establishing tighter WCEC bounds and providing the safety of energy.
System model
In this section, we introduce the basics of the system model, which is composed of architecture model and task model, and then we present the cache energy model from the perspective of HRTs.
Architecture model
We present our architecture model here. Our architecture model assumes a real-time multicore architecture shown in Figure 1, which consists of

A real-time multicore architecture.
In this multicore architecture, when tasks running on different cores send requests to access shared bus and shared cache, these requests will be handled by its corresponding ICBA, which selects the next request to be sent to the XCBA. Then, the XCBA is responsible for deciding which of those requests from different cores access the bus for avoiding inter-core bus conflict and bank conflict.
Real-time task model
This article considers a periodic task model, assuming that a real-time task sets
In bank-column cache partitioning, each HRT is assigned a subset of column of the shared L2 cache, the columns allocated to a HRT do not be accessed by any other HRT and remain the same through the system execution. This column-level cache partitioning can avoid cache storage interference since we mainly focus on bank conflict in this article. We use M to denote the all combinations of potential bank-to-core mappings. The jth mapping in M is denoted by
The WCET of a task in multicore architecture can be divided into two parts:
10
fixed execution time (also referred to as single-core bound) and interference delay. While the former is the maximum time duration that a task could take to execute the instruction over its critical path, which is analyzed in isolation and not affected by the other tasks. The latter is the sum of delays incurred for its cache access over the same path. For the multicore architecture adopting IABA, interference delay consists of conflict delay (i.e. bus access delay and bank conflict delay) of cache access in XCBA and bus waiting time of cache access in ICBA. Let

where
Let

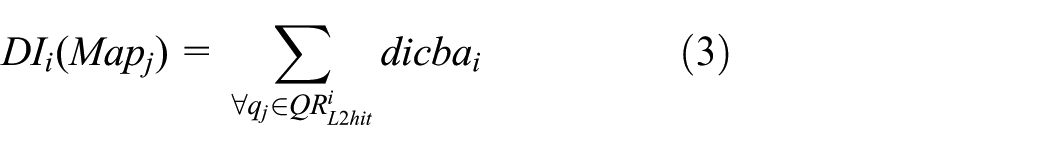
Cache energy model
The WCEC of L2 cache can be expressed as follows

where
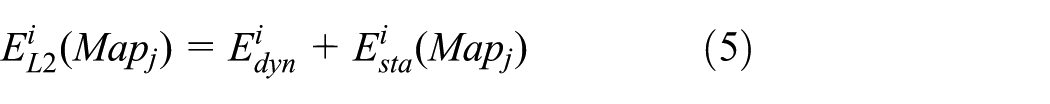
in equation (4),

where

where
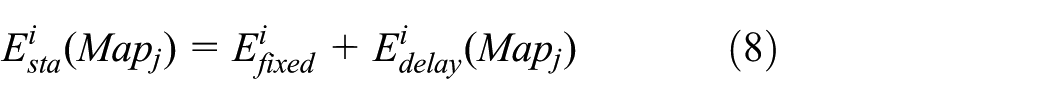


In equations (9) and (10),

The data for
Bank-level interference analysis and WCEC computation
In this section, first, an example is given to explain the working of our interference analysis. Next, we provide an analytical formula for calculating conflict delay and waiting time of request. Finally, we present a fine-grained approach to compute interference delay based on request timing, which is the base of bank-to-core mapping.
Example for interference analysis
In this example, as shown in Figure 2, we assume a four-core system with

The conflict delays and waiting delays of HRT.
The second round of XCBA starts at cycle 17 since all requests in first round of XCBA finish in this time point. The second request of
Analyzing conflict delay and waiting time
From the above examples, we can see that it is necessary to analyze the conflict delay in the XCBA and the waiting time in the ICBAs for accurately estimating WCEC of HRTs. Let us suppose there is a request

Let request

Based on equations (12) and (13), the total conflict delays that the


Algorithm 1 shows the outline of calculating the conflict delay suffered by a request in one XCBA round. This algorithm takes the current requests to access the XCBA per core, the start time of current XCBA round and a bank-to-core mapping as an input. The

As disscussed earlier, ICBA schedules among request from the same core in FIFO policy to access the XCBA. The delay (the bus waiting time) suffered by a request in the ICBA is the time interval between the time that the request reach the ICBA and the time that the request is selected to be sent the XCBA. Let us suppose that requests
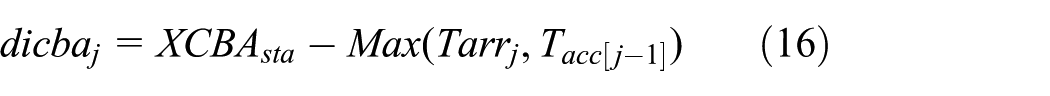
Based on the above analysis, we develop an algorithm to compute the total interference delays suffered by each HRT in the XCBA and ICBAs. Algorithm 2 presents the details of the algorithm. The

Computing the WCEC of HRTs
Algorithm 3 estimates the WCEC of HRTs. In the algorithm, we can see that lines 2–19 analyze all job instance of HRT in one hyper-period. For each job instance of HRT, we first call algorithm 2 to estimate the total conflict delays and waiting time suffered by it (line 5), then compute its WCET estimation based on equation (1). Line 7 judges if this job instance meet the timing constraints. If false, then this job instance is not schedulable. we set the WCEC of the job to infinity. Otherwise, we compute the energy consumption of this job instance in lines 10–14. The total energy consumption of HRTs is computed in line 16.

Bank mapping optimization for WCEC reduction
Problem formulation
In this section, we will present our bank-to-core mapping algorithm to optimize bank-level interference and improve the WCEC. This optimization problem can be formally defined as

where H denotes the hyper-period of all HRTs, and
The optimization problem is subject to the following several constraints

where
Let
Thus, the following conditional constraints is satisfied

The number of cache columns allocated to all HRTs must be less than or equal to the total number of cache columns in multicore system. Thus
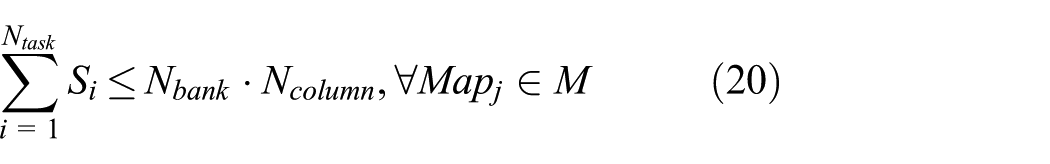
In bank-column cache partitioning, the column cannot be shared between any two HRTs. In other words, the columns of one bank allocated to HRTs must be less than or equal to the capacity of one bank, that is

Fore each

where
According to equation (1), we can estimate
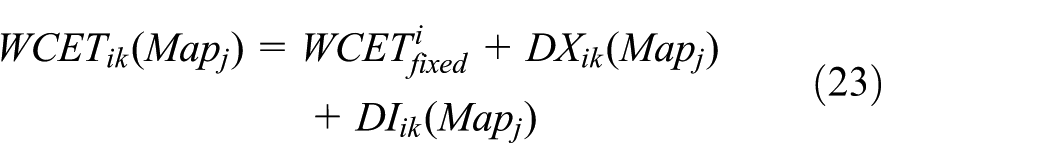
In equation (23),
Algorithm for bank-to-core mapping
We will present bank-to-core mapping for optimizing WCEC of HRTs. Intuitively, the bank conflict can be fully eliminated by exclusively mapping a task’s instructions and data to specific bank. But doing so requires as many banks as the number of HRTs in the system. When the number of banks is less than the number of HRTs, a proper method which can efficiently utilize the shared cache space while minimizing the energy consumption is needed. In this article, we optimize bank-to-core mapping for WCEC reduction. Bank-to-core mapping can be divided into three cases.
For Case 1, we eliminate the bank conflict, and the WCEC of the system is minimized. For Case 2 and Case 3, we develop the algorithm to find the best bank-to-core mapping with minimal WCEC when the columns are allocated to

Evaluation
In this section, we evaluate the effectiveness of interference analysis and bank-to-core mapping approach on energy saving. Before the results are presented, we first introduce the experiment setup.
Experimental setup
We assume our target architecture has six cores, each core has an in-order, five-stage pipeline. CPU clock speed is 500 MHz. The instruction fetch queue size is 4, fetch width is 2, and the instruction window size is 8. Private L1 instruction and data caches are set to 128 B (1-bank, 2-way associativity, 16-byte line, and 1-cycle access latency). The L2 cache is shared among all cores, and it is 8 KB, 4 banks, 4-way associativity, 32-byte line, and 4-cycle access latency(
The WCET analysis of the task is built on top of the open-source timing analysis tool Chronos, 21 Chronos is originally a single-core WCET analysis tool, and we extended it by adding support for IABA model. The task sets used in our experiment are shown in Table 1. All tasks are from Malardalen WCET benchmarks, 23 which are compiled with GCC cross-compiler for a MIPS-like instruction set. 24 The mapping of task to core is given in third column of Table 1. To obtain demanded column amount for each task, we use Chronos to measure the WCET of each task by varying the L2 cache size from 1 to 32 columns. According to the measured results, the demanded column amount for each task is listed in the fourth column of Table 1.
Characteristics of task sets.

Experimental results
Based on above experimental setup, we conduct four experiments. In the first experiment, the bank-to-core mapping is given in advance, and we show the impact of the bank-level interference on WCEC. The second experiment evaluates the impact of the bank-to-core mapping on WCEC saving. The third experiment compares our interference analysis approach to UBD approach. Finally, the final experiment investigates the effect of timing constraint on our approach.
Impact of the interference on WCEC
To quantify the impact of interference on WCEC, we assume the bank-to-core mapping is given as shown in Table 2, and the deadline of
A bank-to-core mapping.


Comparison of WCEC of task considering interference and not-considering interference: (a) task set 1 and (b) task set 2.
Impact of bank-to-core mapping on WCEC
It is valuable to disclose that the ability of bank-to-core mapping can affect the WCEC of HRTs. Using task set 2 in Table 1 as an example, Figure 4 shows that the total WCEC of HRTs in solution space of bank-to-core mapping, we can see that the solution space of bank-to-core mapping is 720 and the total WCEC of HRTs varies from 49076.36 to 52904.4 nJ. The difference in energy consumption of L2 cache is 3828.04 nJ between the best bank mapping and the worst bank mapping, namely, the bank-to-core mapping results in the 7.23% WCEC reduction. This is mainly due to the fact that the task suffers from different interference delays under different bank-to-core mappings, and these interference delays affect the static energy consumption of L2 cache.

The impact of bank-to-core mapping on WCEC.
Our interference analysis approach versus UBD approach
In this experiment, our focus is the effectiveness of interference analysis approach, the bank-to-core mapping is based on Table 2. We compare our approach with UBD approach where the UBD can be expressed as

Comparison of WCEC of two approaches: (a) task set 1 and (b) task set 2.
A bank-to-core mapping with minimum WCEC.

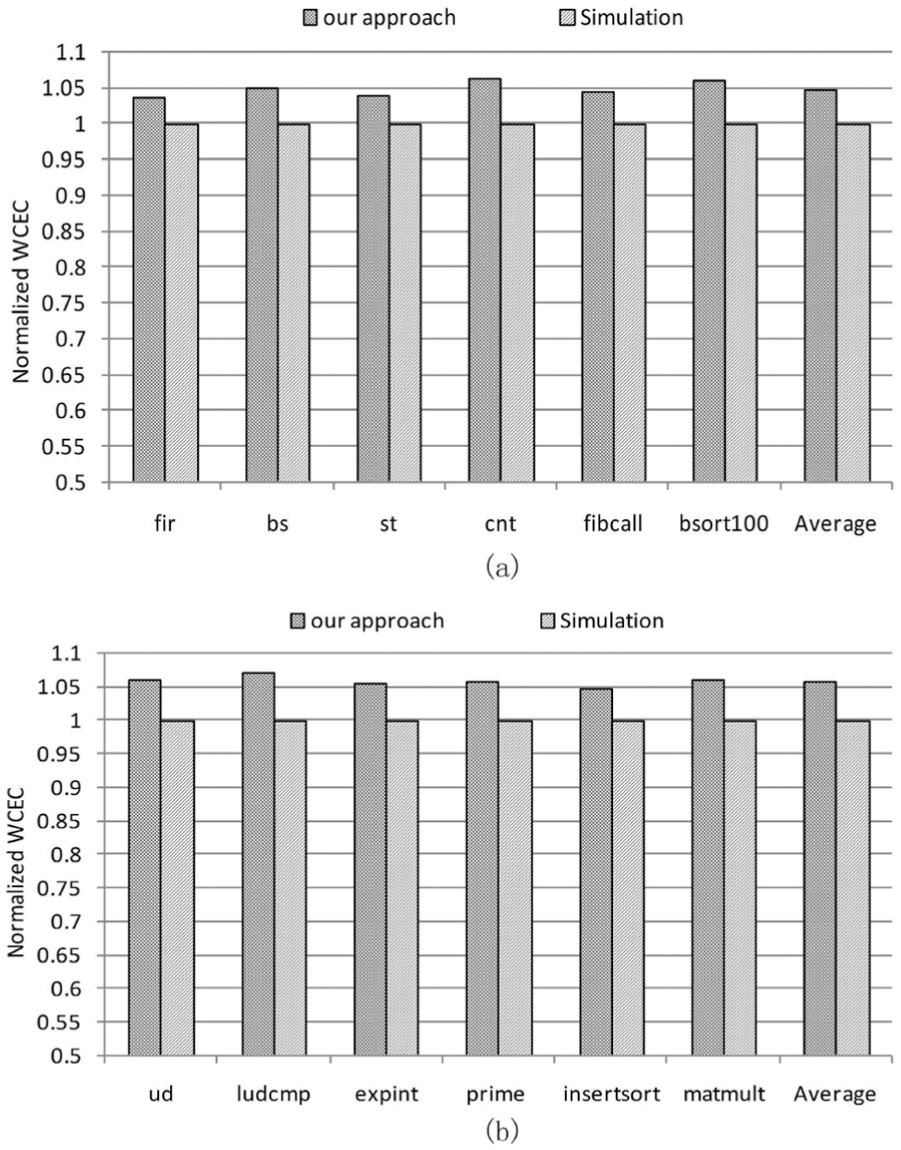
Comparing the WCEC results by our approach and simulation: (a) task set 1 and (b) task set 2.
Deadline effect
The final experiment shows the effect of deadline on WCEC. Using task set 2 in Table 1 as an example, we vary the deadline of each

Deadline effect on WCEC.
Conclusion and future work
In this article, we have presented an analysis for the bank-level interference (bank conflict and bus access interference) on a multicore platform with a shared cache, and our analysis approach can provide a tighter bound on the interference delay, which is crucial for WCEC. Experiment results show that our approach can improve the tightness of WCEC by 14.25% on average compared to UBD approach. Moreover, in order to reduce the negative impact of bank-level interference and improve WCEC, we propose to use bank-to-core mapping and develop an algorithm; the experimental results indicate that bank-to-core mapping yields significant benefits in WCEC, with the 7.23% WCEC reduction.
As multicore architecture are already ubiquitous, interference in shared resources should be seriously alleviated. We believe that our analysis and bank mapping can be effectively used for designing predictable real-time multicore systems for processing various complex jobs, e.g., performance optimization,12,25,26 learning & classification,27,28 and content searching.29–32 We believe that plenty of future work exists in this field. We plan to (1) extend our techniques for off-chip memory so as to leverage system-wide energy consumption and (2) explore the effect of hardware pre-fetchers on cache interference delay.
Footnotes
Acknowledgements
The authors thank the anonymous reviewers for their helpful comments and suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China under grant nos 61370062 and 61462004.