
Abstract
Phishing is a serious threat to online users, especially since attackers have tremendously improved their techniques in impersonating important websites. With websites looking visually the same, users are fooled more easily. Visual similarity algorithms may help to detect and counteract some phished websites. Through similarity algorithms, the phishers play with the colors and visual properties of the website in a way that cannot be noticed by the users. However, the phishers make the unnoticed changes to fool the similarity algorithms as well. In this article, we propose an efficient phishing website detection algorithm using three-step checking. The performance results are compared to the state-of-the-art approaches that show new kinds of phishing warnings with better outcomes and less false positives. Our approach provides similar accuracy to the blacklisting methods with the advantage that it can easily classify the phishing websites with less overhead and without being victimized.
Keywords
Introduction
Phishing attacks have affected many users through impersonating important official websites and, as a result, stealing personal information or financial data. To the help, visual similarity can be used to counteract phishing. Phishing attack is an undesirable common story. For instance, when someone follows a link to a website purporting to be his favorite social media website, he might get at a web page that looks like his favorite social media website. He finds the same logo he used to see at the social media. This phished website he visits was just published in the Internet within hours or days. As a result, it is most probably unknown to blacklists. Trusting the phished website, the visitor provides his credentials to the phisher. Perhaps, if the visitor knows that he should check for the domain name and indicators of a valid secure sockets layer (SSL) connection to ensure the integrity of the website, it would be fine, but most users are not aware of how to do this. Currently, some users use phishing detection tools and the browsers give various indications of a site’s authenticity. However, they only work if the phished website is recorded in the blacklist to assist the tools in detecting the phishing.
In this article, we introduce a new algorithm designed to overcome the phishing attacks. We explore some experiments on visual memory of the human to find how the person memorizes the website information when he comes back to it after a period. We try to simulate the user’s memory ability to help in strengthening the credential of the website in an implicit way to the user. We design our new model based on these experiments which is unprecedented and based on human behavior. This article is organized as follows. In section “Related work,” we show the related work. In section “Evaluating criteria,” we list the criteria to measure the performance of our new algorithm. Section “Experiments” discusses several experiments and facts that assist us in building our new model. Section “Result of experiments” shows the result of experiments and how to use them in our new model. In section “Our model,” we detailed our new model and its structure. In section “The superiority of our model,” we demonstrate the superiority of our model over the other comparable famous models and algorithms. Finally, section “Conclusion and future work” concludes the article and shows the future enhancement of this work.
Related work
Detecting phishing websites using visual similarity comparison has been proposed in several papers. Wenyin et al. 1 presented a concept that uses three types of similarity to detect phishing websites: “block level,” “layout,” and “total style similarity.” Medvet et al. 2 proposed a system that calculates a website signature using three features: a web page seen text sections, embedded images, and the overall visual appearance. Signatures can then be compared with the other signatures. They test their algorithm against a set of 140 phishing websites and 27 real websites performing very well. Chen et al. 3 used the rendered web page as input to a normalized compression distance compressor. They test that on a set of 320 phishing websites that target 16 different real banking sites, their work shows that phishing websites rated significantly closer to their originals.
Machine-learning techniques can also be used to detect phishing. By converting the content of website 4 or uniform resource locator (URL) and domain properties into a set of features or feature vectors, machine learning can look for websites that are similar, but having anomalous properties, such as “right” content in the “wrong” place.
Computer vision techniques 5 can also be used to visually match the images on visited webpages with the originals. While these techniques can detect new phish, their approximate matching risks many false positives, and their high computational requirements make them difficult to run on clients. We instead employ precise content matching using some other techniques, such as cryptographic hashing to avoid false positives and to provide lightweight detection that can run in a client end like browser without centralized support.
All the related works6–14 show the effect of phishing and the need to counterattack this security threat. In fact, detecting phishing websites through visual similarity works well in general. With our work, we further elaborate the idea by finding more efficient and faster detection algorithm through developing a three-step checking algorithm.
Evaluating criteria
In this section, we show how to evaluate the efficiency of phishing detection algorithms. Then, we apply this evaluation in our new algorithm in comparison to other algorithms. To show the big picture, let us suppose there is a phishing detection algorithm X. After X checks a website, it will give us a decision about the website. This decision can be any of four possible results for any tested website as described in Table 1.
Four status for the tested algorithm.

A: the website is phishing; B: the algorithm says that the website is phishing.
The first and fourth possibilities should be maximized by X as much as possible and should minimize the second and third possibilities as much as possible. Let us call the first and fourth possibilities as “desirable opportunity,” while the second and third possibilities as “undesirable possibility.” We can check the rate of each set to measure the efficiency of the phishing algorithm.
A common mistake we have to care while evaluating the algorithms is, we should need to check not only the possible scenarios but also the website being phished. As a result, we have to run the algorithm on a mixed group of phished and non-phished websites. By doing this, we can test the four possibilities. In reality, we do not know whether the website is phished or not; furthermore, if it is phished, we do not know which website the phisher tries to impersonate.
Continuously, the owner of the website is updating it. Wherefore, we cannot rely on taking a snapshot of the real website and save it in our database to recognize the trusted website. Some solutions may take a snapshot of the actual website in the same moment of testing. It seems fine, but this solution is impossible and impractical because we are not aware of the actual website that the phisher tries to impersonate at the real time of testing. The answer to this question is also the answer to the question of whether the website is phished or not as depicted in Figure 1.

The relation between two issues: A. Is it phishing or not and B. If it is phishing what is the original website.
Figure 2 describes the increasing amount of changes in the real website and how this affects the user behavior. These changes are done by the phisher to deceive the algorithm. These changes mostly unnoticed by the user and at the same time should deceive the detection algorithms to achieve the phisher goal. In the most left part of the arrow, there is not any change in the website, but just the URL. In that point, the user may ultimately be fooled and cheated, but any simple algorithm, such as pixel-by-pixel algorithms, can detect the phishing. As shown by perceptive hash (pHash) and radial hash (RADISH) algorithms, the middle part of the arrow is the most challenging because there are some differences between the phishing site and the real website where the simple detection algorithm cannot detect the phishing. Moreover, the user cannot notice that difference. The third part is not that critical because there are a lot of differences and as a result the user cannot be deceived.

As real website changes, the users being cheated increase, hence detection algorithms cannot detect it.
Experiments
Before designing an algorithm to detect the phishing, we have to enclose all the possibility changes the phisher is trying to do to put his phishing website in the most challenging region. The phisher tries to make changes in the sit, wherefore the user cannot notice it as well as cheat the algorithm at the same time. This guides to do some experiments to find how the user memorizes the original website and which detail the user will ignore. If the phisher changes this detail, he will reach his goal.
The Benton Visual Retention Test (BVRT) is an individually administered test for people aged between 8 years and adulthood that measures visual perception and visual memory. It can also use to help identify possible learning disabilities among other afflictions that might affect an individual’s memory. The person examined had been shown 10 designs, one at a time, and had been asked to reproduce each one as accurately as possible on plain sheet from memory. The test is untimed and the results scored professionally by the properties of form, shape, pattern, and arrangement on the sheet. The number error score is calculated based on the number and type of errors made for each design. The major categories of these errors are rotations, misplacements, and the size errors as shown in Figure 3. 15 From this test, we know all these changes can occur without the user attention. Wherefore, the hackers will try to do these changes to cheat the algorithm. Therefore, the first prosperity of our new algorithm is rotations, misplacements, and size errors carefree.
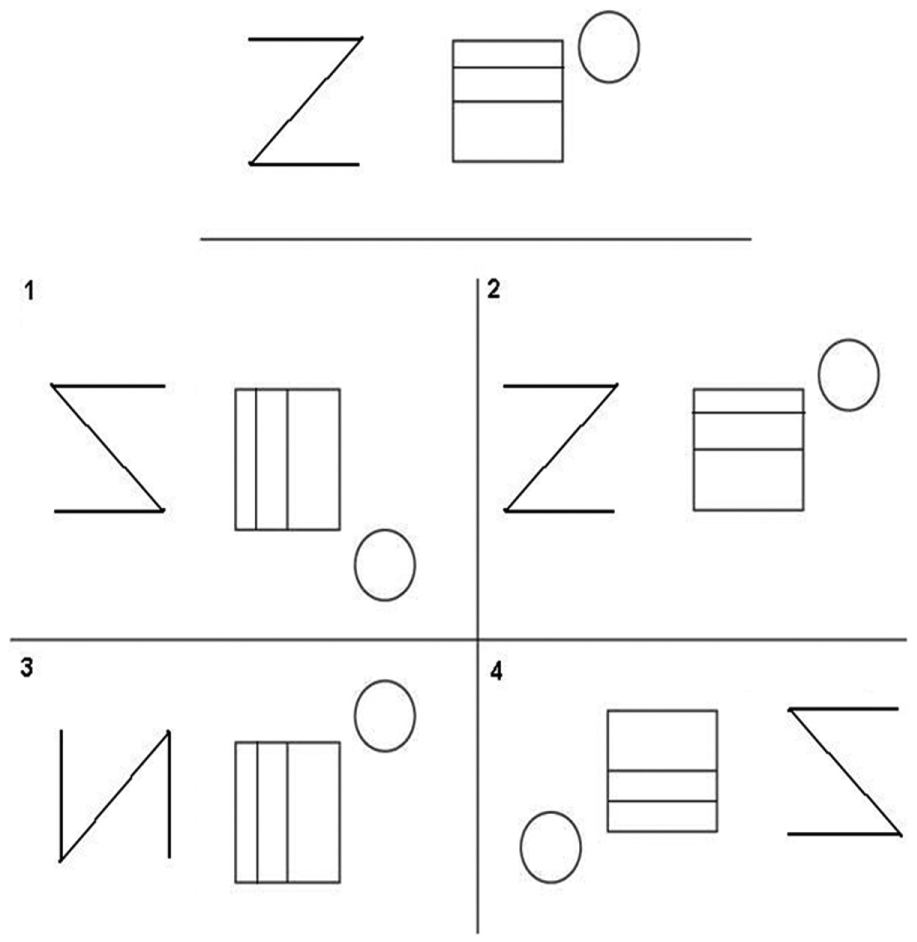
The Benton Visual Retention Test card as present in Rowley and Baer. 15
The number error score is calculated based on the number and type of errors made for each design. The major categories of these errors are rotations, misplacements, and size errors. 15 From this test, we know all these changes can make without user attention. Wherefore, the hackers will try to do these changes to cheat the algorithm. Wherefore, the algorithm should be carefree about these changes. So, the first prosperity of our new algorithm is rotations, misplacements, and size errors carefree.
The second test is about color. The target of this test is to find how often the user can remember the colors of a website. It is composed of four forms that measure the examinee’s visual and memory abilities to remember the color. The test is a multiple-choice question. After the examinee sees a color, we give him a card containing four colors, and he has to choose the correct one. The sample is 40 people divided into four groups. Each group contains 10 people as depicted in Figure 4. Moreover, each group has certain time and conditions as provided in Table 2, and the score of this test is shown in Table 3. In these tables, we can see that the users can differentiate and remember the color if the fake color has big changes whether it occurs recently or long time ago. However, they can only remember 65% of the color if the hackers make small changes.

Color test cards, each of them offered to one group.
Four groups of color test.

The score of the four groups of color tests.

Therefore, we can derive from that the algorithm should ignore the small changes in the color but not the big one.
Result of experiments
From the previous tests and positive phishing detection symptoms, we can design our optimal and new appropriate algorithm. Our design should include the following properties:
It must be carefree about rotations, misplacements, and size errors changes as depicted in Figure 5.
It should ignore the small changes in the colors but not the big one.

Examples of different types of impersonation with rotations, misplacements, and size errors.
It has been estimated that humans can distinguish roughly 100 thousand different colors. 16 Furthermore, the RGB model color in HTML can represent 17 million colors. 17 As a result, we can make our new model to ignore 17 colors because there are 17 sets where the user cannot distinguish but the algorithm can. Moreover, only about 25% of the population is tetrachromat. 18 Diana Derval performed an experiment to calculate that.
Figure 6 shows that there are 39 different colors. However, few people can distinguish between them and it gives us an indicator of how much a human can differentiate between colors.

A test to measure how people can differentiate between colors.
Our model
Our new model has three main steps as shown in Figure 7. The direction of the first step is from the unknown website to the database. Furthermore, the direction of the second step is from the database to the unknown website. After that the algorithm can decide whether the unknown website is a phishing website or not, as depicted in Figure 7 where the dynamic chart starts from the “start” square.
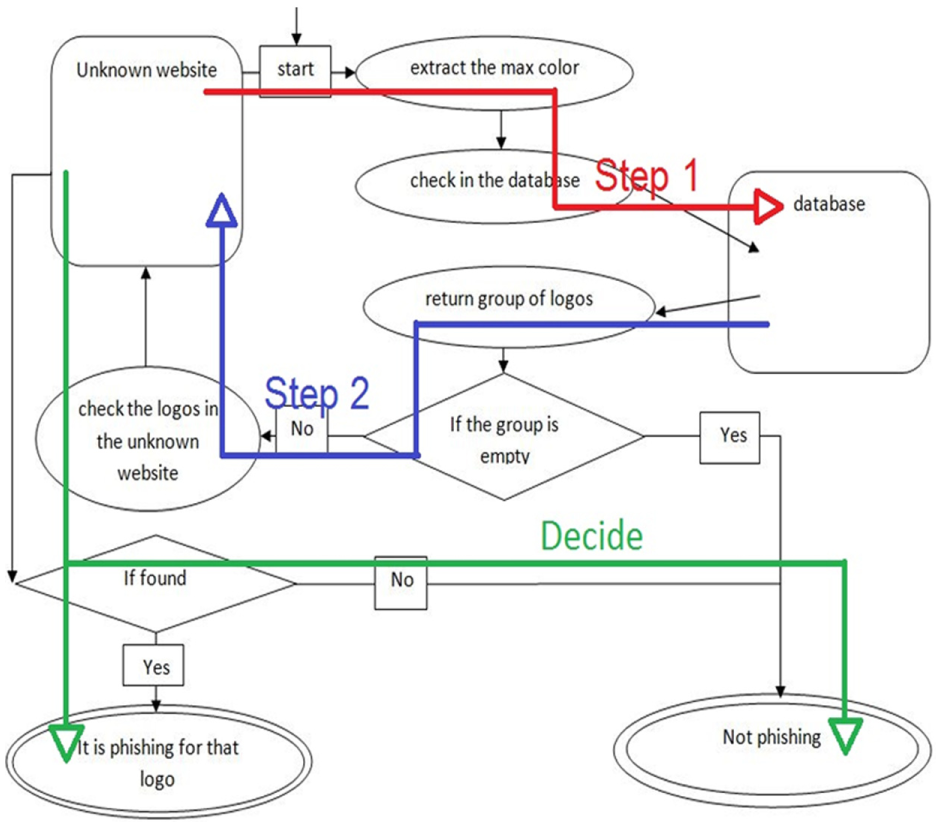
Three main steps of the algorithm.
As a prosperity step, we have a database that contains some information about the trusted websites as shown in Table 4 and Figure 8.
The prosperity step (a sample of the trusted websites database).


Prosperity step in our model.
After the prosperity step, we should have the names, URLs, and logos of each website stored in the database or the trusted websites array as the code.
Therefore, the first step is to extract the three max color occurrence as shown in Figure 9. And check them in the database; if it had found some similar website, it will return them as a set of a websites. Hence, there is a probability that the website is phished as shown in Figure 10.

Extraction of the max color from the unknown website using the same extracting algorithm.

Checking the max color in the database.
Therefore, we need more process to make sure whether those websites stored in the may-phish-me array are clean of phishing or not. Because of that we need the second step, which takes a logo of each site in the returned set from the database and check them in the unknown website. If a logo found and the URL is not similar, then the unknown website is a phishing website. Moreover, if any condition is not true, then the unknown website is not a phished website.
As Figure 11 describes, we use the most three max color occurrences in the website page to extract the max color. However, there are several choices like pHash or discrete cosine transform (DCT) hash algorithms that can be used. Actually, the DCT hash algorithm gives better accuracy because it is not affected with the small changes in the colors as depicted in Figure 12.

Checking the logo and URL in the unknown website.

DCT hash resistance five points.
Actually, we use five-point colors. However, we can use up to 17 points or more because not every human can detect the little difference in the color.
Figure 13 summarizes the three steps intended in our algorithm. We start our algorithm through registering a whitelist that contains all websites which we want to protect from phishing such as bank websites, social media websites, and governmental websites. At the end of our algorithm, we reach the judgment of whether the unknown website is phished or not.

A summary of our model (the three-step algorithm).
The superiority of our model
We tested our algorithm in 600 phished websites and we had 94.99% accuracy. First, we collected a random sample from PhishTank project. 19 The samples are 600 real phished websites. These samples are targeting 70 real websites. Through MATLAB using a machine vision toolbox to fetch the logos of the real website and the unknown website, we performed the testing.
As described in Table 5 and Figure 14, the Blacklist methods have the best accuracy, speed, and no phisher can cheat it by any of the phishers’ techniques, but it has a discomfiture issue. Blacklist algorithms depend on having victims. Those victims will report the blacklist system with the phished websites. The phished websites will be listed and stored to prevent having any more victims. However, the goal of the phisher is being achieved since he cracked one or two bank accounts. In the contrary, our algorithm has all blacklist algorithms’ advantages and no need to have victims. We designed our model to be fortified against most challenging area attacks. Moreover, our new model cannot be cheated by changing the extensible markup language (XML) code. For instance, if some phisher tries to change the XML code with another one to give the same interpreted page to cheat XML phishing detection algorithms, this will not deceive our algorithm because it takes a snapshot of the final interpreted result no matter what the XML code looks like. Our algorithm unlike whitelist algorithms compares each website listed in the whitelist with the unknown website. This high number of comparisons makes the whitelist model very slow and unusable at the end user point of view. However, our model also makes such comparisons, but utilizes the max-color hashing, and this makes the algorithm effective and has a complexity of log(n) efficacy.
Comparison between several algorithms.


Performance of our model, whitelists, and blacklists.
We propose to use our model as a plug-in with several Internet browsers to give the user a warning state if he enters a phishing website. It alarms the user when the website X is a phished website (X could be any trusted website). Certainly, before applying our new model, all the targeted websites (targeted websites are the websites that the phishers try to impersonate) should be retested in our database, and our database should be updated when there is a change in style or logos.
Conclusion and future work
This article presents the first step in a new approach of websites’ phishing detection using hyper vision techniques. We show results that defeat the vast majority of the current attack approaches. Nonetheless, we believe there are still more rooms to improve these outcomes. Max-color extraction improvement, Searching logos improvement, and Multi-logo website problems are our next future work to explore.
Footnotes
Academic Editor: Zubair M Fadlullah
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Deanship of Scientific Research at King Saud University (no. RGP-1437-35).