
Abstract
Many miraculous ideas have been proposed to deal with the privacy-preserving time-series data aggregation problem in pervasive computing applications, such as mobile cloud computing. The main challenge consists in computing the global statistics of individual inputs that are protected by some confidentiality mechanism. However, those works either suffer from collusive attack or require time-consuming initialization at every aggregation request. In this paper, we proposed an efficient aggregation protocol which tolerates up to k passive adversaries that do not try to tamper the computation. The proposed protocol does not require a trusted key dealer and needs only one initialization during the whole time-series data aggregation. We formally analyzed the security of our protocol and results showed that the protocol is secure if the Computational Diffie-Hellman (CDH) problem is intractable. Furthermore, the implementation showed that the proposed protocol can be efficient for the time-series data aggregation.
1. Introduction
The security and privacy issue in pervasive computing applications, such as mobile cloud computing, crowd sourcing, and smart metering, has long been a hot research topic in the field of applied cryptography. An adversary may infringe customers' privacy in pervasive computing environment since they are “smart” enough to record one's preferences or habits. For example, smart meters report consumption for users at high frequency (e.g., once per minute) and in real time. This level of monitoring can reveal much private information about users' habits and subject the users to many loathsome outcomes [1, 2], for example, whether they often watch TV (discriminating pricing of health insurance), or even stealthy surveillance in general [3]. For another example, mobile users report their locations, speeds, and mobility to a GPS service provider at real time. The aggregated data, for instance, the number of users at each region during each time period, can be mined for congestion patterns on the roads [4, 5]. However, the individual information above needs to be protected in the privacy consideration.
In this paper, we focus on the privacy-preserving aggregation problem of time-series data without a trusted third party. We use a new additive homomorphic encryption as the cryptographic primitive to handle this aggregation problem. Jung et al. had pointed out that the trusted or semitrusted key issuers could be a security hole since the security of those schemes relies on the assumption that keys are disclosed to authorized participants only [6]. Therefore, the proposed scheme is not initialized by requesting keys from trusted or semitrusted key issuers via secure channel. Meanwhile, we do not require that participants be able to communicate with their neighbors via wireless communication channel. This requirement is expensive and somewhat difficult to actualize in large area situations, so we simply assume that each participant only has a bidirectional communication channel with the aggregator. Besides the aforementioned drawbacks, a large number of aggregation protocols are proposed under the weak security assumption that all the participants are semitrusted and do not collude with the aggregator. To sum up, the goal of this paper is to design a privacy-preserving time-series data aggregation protocol which is robust against up to k colluding passive adversaries that do not try to tamper the computation.
The main contributions of this paper are as follows. (1) We propose a privacy-preserving time-series data aggregation protocol without trusted central key issuer and it only needs one initialization for the participants to acquire their encryption keys. (2) Security and complexity analyses of the proposed protocol are given and the proposed protocol is shown to be efficient and scalable and also it is proved to tolerate up to k colluding passive adversaries. (3) A method which allows the participant and aggregator to verify any individual input or the accumulation of inputs is proposed and the performance evaluations are given in this paper.
The remainder of this paper is structured as follows. The related work is detailed in Section 2. We present the system model and necessary background in Section 3. Subsequently, the construction of our scheme is described in Section 4 and, thereafter, security analysis is in Section 5. The complexity analysis and performance evaluation are reported in Section 6. Section 7 presents the conclusions of this research.
2. Related Work
Many papers have been done in the fields of privacy-preserving data aggregation for many application scenarios. We present the most relevant work to our contribution in this paper. A Paillier's encryption scheme based privacy-enhancing protocol was proposed by Li et al. [10]. Subsequently, Li and Luo introduced the use of homomorphic signature allowing verification to confirm that the data aggregation was correct in [11]. Garcia and Jacobs proposed an aggregation scheme for secure communication with smart meters [12], where a combination of Paillier's additive homomorphic encryption and additive secret sharing has been used. Danezis et. al. [13] proposed an aggregation scheme based on secret-sharing and secure multiparty computation techniques. Shi et al. [14] proposed a Diffie-Hellman based encryption scheme where participants periodically upload encrypted values to an aggregator, and the aggregator computes the sum of those values without learning anything else. It uses brute-force search or Pollard's lambda method to find the exact sum. This kind of brute-force decryption limits its usage restricted to small plaintext spaces due to the hardness of the discrete logarithm problem. Joye and Libert [15] proposed a solution to efficiently decrypt the sum based on the idea of splitting the exponent. Leontiadis et al. [16] introduced a secure protocol for aggregation of time-series data that is based on Joye's scheme [15] and the requirements for key updates and for the trusted dealer are eliminated. The main idea of it is to introduce a semitrusted collector which plays the role of an intermediary between the users and the aggregator.
Recently, Li et al. [8] introduced an efficient protocol to obtain the sum aggregate, which employs an additive homomorphic encryption to support large plaintext space. But this scheme relies on trusted key dealers that distribute the keys via secure channel. Mármol et al. [7] proposed a protocol in which each participant adds its key to its measurement and sends the result to the aggregator, but their scheme needs a previous aggregation before getting the exact sum. In [9], Borges and Muhlhauser proposed an efficient privacy-preserving protocol for smart metering systems based on Paillier's scheme. However, they assume smart meters in the neighborhood communicate with a collector through a wireless mesh network and the collector further communicates with the central management facility through wired communication in the initial setup. Their scheme has the common problem that it will fail if the collector device colludes with the aggregator. Jung et al. [6] presented an advanced protocol which tolerates up to k passive adversaries that did not try to tamper the computation without secure channel. Their protocol needs to initialize for every round of aggregation, so both the communication and computation overheads are too extravagant in time-series data aggregation. Table 1 summarizes our protocol with major related protocols in the literatures. Besides, there are also several works [17–22] on privacy-preserving aggregation of time-series data. Some of them leverage the differential privacy [23] in various ways to achieve privacy as well as collusion (or fault) tolerance. Our scheme can also achieve differentially privacy by simply adding the noises that follow diluted geometric distribution to each meter's data [14].
Comparison between the proposed protocols and related aggregation protocols.

In our scheme, the trusted key dealer in [8, 18, 21] is removed because of the aforementioned security loophole. Unlike [8, 17], we assume insecure channels between most participants, while the secure channels are established based on public key encryption among a small fraction of participants in the same subgroup, which enabled us to implement the proposed scheme in the real cloud environments easily. In this paper, we also take into consideration a small fraction of the participants colluding with the curious aggregator as [6, 17] do. Our scheme is also based on the hardness of the discrete logarithm problem like [14], and we employ an efficient method to calculate the sum instead of employing brute-force manner in decryption.
3. System Model
3.1. Problem Definition and Threat Model
Assume that there are N participants with equivalent number of IDs 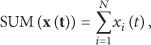
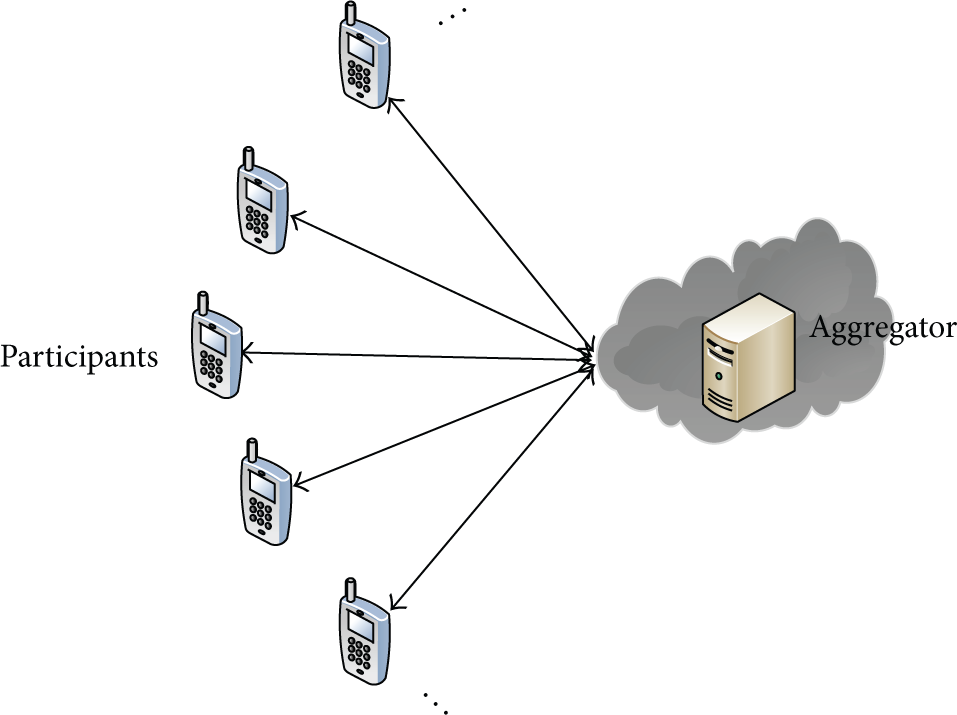
The system model.
We assume that participants have a bidirectional communication channel with the aggregator like [17]. The participants are not connected to each other directly, but they can exchange encrypted messages among themselves via the aggregator or intermediate routers. Similar to [6], the communication channels in the system are insecure. Anyone can easily eavesdrop them and/or intercept the data being transferred. In this paper, the aggregator is untrusted so that a curious aggregator may try to compromise someone's private information through the aggregation protocol. A small fraction of the participants may collude with the aggregator, say at most k participants. Similar to [14], we assume that the system has a priori estimate over the upper bound of k. Participants will in general hide the information they have before reporting it to the aggregator. To assist the curious aggregator, however, colluders may deviate from the protocol by providing their own information in the clear to the aggregator. We further assume the participants and aggregator may be passively adversarial; that is, they will not falsify the computation, but they may try to manipulate their calculation to infer others' private information.
3.2. Security Model
To address the challenges of insecure communication channel, we assume that the following CDH problem is computationally intractable; that is, any Probabilistic Polynomial Time Adversary has negligible chance to solve the following problem.
Definition 1 (CDH problem in G).
The Computational Diffie-Hellman problem in a multiplicative group
According to [6], we define the security of our proposed scheme as follows.
Definition 2 (CDH-security in G).
We say our privacy-preserving sum calculation is CDH-secure in
Informally, we opine that our calculation is CDH-secure in
3.3. Some Definitions
Group 

Subsequently we introduce the decryption mechanism behind the encryption function. Obviously, the 
Given the family of encryption functions from (3), each participant i encrypts its data 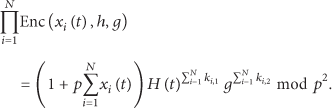
If the aggregator has capability 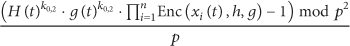
4. Our Construction
Jung and Li's scheme [6] includes an advanced protocol which tolerates up to k passive adversaries that do not try to tamper the computation. But the communication and computation overheads are large for participant since it needs to exchange
4.1. Jung and Li's Scheme
(i) Setup. The participant i picks a secret number
(ii) Encrypt. Every participant i calculates
(iii) Sum. After receiving the ciphertexts from all of the participants, the aggregator calculates
It is obvious that the randomizer
4.2. Protocol Description
Similarly, our scheme of privacy-preserving sum calculation for time-series data has the three phases: Setup, Encrypt, and Sum.
4.2.1. Setup
(A) Phase 1. In our construction, the aggregator needs to get the capability
At first, every participant and the aggregator choose a private number to set up the secure channel based on Diffie-Hellman key agreement protocol. Take participants in the mth subgroup as the example. Here each participant i has an auxiliary identity number
After the session keys in the subgroup are established, each participant i chooses a private number
Here we do not use the method that participant i slices its private number
(B) Phase 2. The capability 
4.2.2. Encrypt
The participants do not need to repeat the exchanges to get new random numbers to encrypt their data after setup, so our protocol is more communication and computation efficient than Jung and Li's scheme. For a queried timestamp t, each participant i calculates 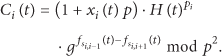
Note that a small fraction of participants (reused participants) will be divided into two subgroups; thus it has two permanent private keys 
4.2.3. Sum
The aggregator, after receiving the ciphertexts 
4.2.4. Leaving of Existing Participant
Suppose that participant i decides to leave the network with effect at timestamp t. The aggregator should assign a reused participant
4.2.5. Joining of New Participant
Assume that a participant, say i, joins just before time slot t and participants
5. Protocol Analysis
When p is chosen large enough to hold the inequality
5.1. Verification Properties
If a participant did not send its data or sent an invalid message, the aggregator cannot read consolidated summation, that is, the exact sum. Obviously, neighboring participants and participants in the same subgroup can cooperate to disclose the key of the damaged participant. But this can result in the privacy disclosure of the damaged one. A better solution is to generate new keys for nondamaged participants. As the benefits of our subgroup method, the aggregator can know the exact sum of one subgroup's permanent private keys. Therefore, only n participants need to change their permanent private keys and two participants need to regenerate their time-dependent private keys.
The aggregator can ask for verification when the sum is different from the expected. If the aggregator asks for verification to identify that something is wrong, a participant i can reveal its proof of the timestamp t without disclosing its actual reading. To perform verification over a sent encrypted value
5.2. Security Analysis
Since our aggregator scheme includes three steps: Setup, Encrypt, and Sum, and the Setup is the foundation of our construction, we will give the security proof of Setup at first.
Theorem 3.
Our Phase 1 of Setup in the aggregation scheme is CDH-secure in
Proof.
The symmetric cryptography AES is used in our Setup phase as well as Shamir's secret sharing scheme and Diffie-Hellman key agreement protocol. As mentioned in [25], a 128-bit AES key demands a DH key size of 3072 bits for equivalent security. Thus, the security level mainly depends on the DH key agreement protocol. In a nutshell, we show that any PPTA that has significant chance to infer private values in our Setup phase has nonnegligible advantage to solve the CDH problem, which is a contradiction to our security assumption that CDH problem is intractable.
Since the communication channel is insecure, any adversary has the same view unless it can collude with some adversarial participants. In the worst case, the aggregator can collude with
The time-dependent private key in Phase 2 of Setup is aimed not only at enhancing the security but also at reducing the probability that aggregator can get the sum of one subgroup. Without the time-dependent private key, it is easy for aggregator to compute the sum of one subgroup. As Enc is constructed, aggregator can get the sum of a subgroup only if the first and the last participants in its neighboring subgroups are colluded with the aggregator with a probability of
Theorem 4.
Our proposed aggregation protocol is CDH-secure in
Proof.
To infer
Theorem 5.
Our proposed aggregation protocol is aggregator obliviousness; that is, a party without the aggregator capability learns nothing.
Proof.
To infer 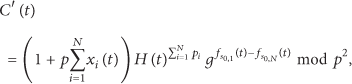
The security proof of the Leaving or Joining process is omitted. However, these two processes are CDH-secure in
6. Performance Evaluation
6.1. Complexity
In this section, we will discuss the computation and communication complexities of the proposed aggregation scheme. For the sake of simplicity, we denote that the computation complexity of encryption or decryption in 128-bit AES is
6.1.1. Setup Process
In Phase 1, it is easy to see that the participant needs to compute one public parameter, n symmetric session keys, and n secret shares and to encrypt and decrypt
In Phase 1, every participant exchanges public parameter with its groupmates in the subgroup via the aggregator, which incurs communication of
6.1.2. Encrypt and Sum Processes
In Encrypt process, it is easy to see that every participant has a communication overhead of
6.1.3. Leaving of Existing Participant
In this process, the assigned participant
6.1.4. Joining of New Participant
The joining participant has to compute its public parameter at first, and then it needs to compute n session keys and to decrypt and encrypt n messages. In addition, the joining participant needs to compute two equalities and two session keys to get its time-dependent private key. Thus, the computation complexity of i is
Complexity of our scheme.

6.2. Evaluation by Implementation
The Encrypt process may be run by the participant with constrained resources and the sum is run on the aggregation side. So the performance of encryption is more important in the aggregation protocols. As is pointed out, EPPP4SMS is much faster in encryption than many protocols that use Paillier's scheme [7]. Therefore, in this simulation, we only compare the performance of our protocol with other two existing aggregation protocols in [6] (specifically, Jung's advanced protocol) and [7] (EPPP4SMS). To simulate and measure the computation overhead, the aggregation protocols are all implemented in Java in a computer with Intel i3-2100 CPU @ 3.10 GHz and 3 GB of RAM, and each result is the average time measured in the 1,000 times of executions. Also, the input data
First of all, we compared the participant's computation overhead in setup of our sum protocol and Jung's protocol. We do not simulate the setup phase of EPPP4SMS for the reason that it does not cover the same security assumption with ours and Jung's protocol. It is clear that the computation overhead of each participant in Setup phase only depends on the number of colluders if the length of ciphertext is fixed. We measured the total computation time of each participant spent in calculating its final encryption keys with different number of colluders and the results are shown in Figure 2. As we can see in Figure 2(a), the setup time for each participant of our protocol in the first aggregation is almost the same as Jung's protocol. However, as aforementioned, Jung's protocol needs to set up for every round of aggregations, while our scheme only needs one setup during all of the aggregations. Obviously, our protocol is much more efficient for the time-series data aggregation and the conclusion is in accordance with the simulation results in Figure 2(b).
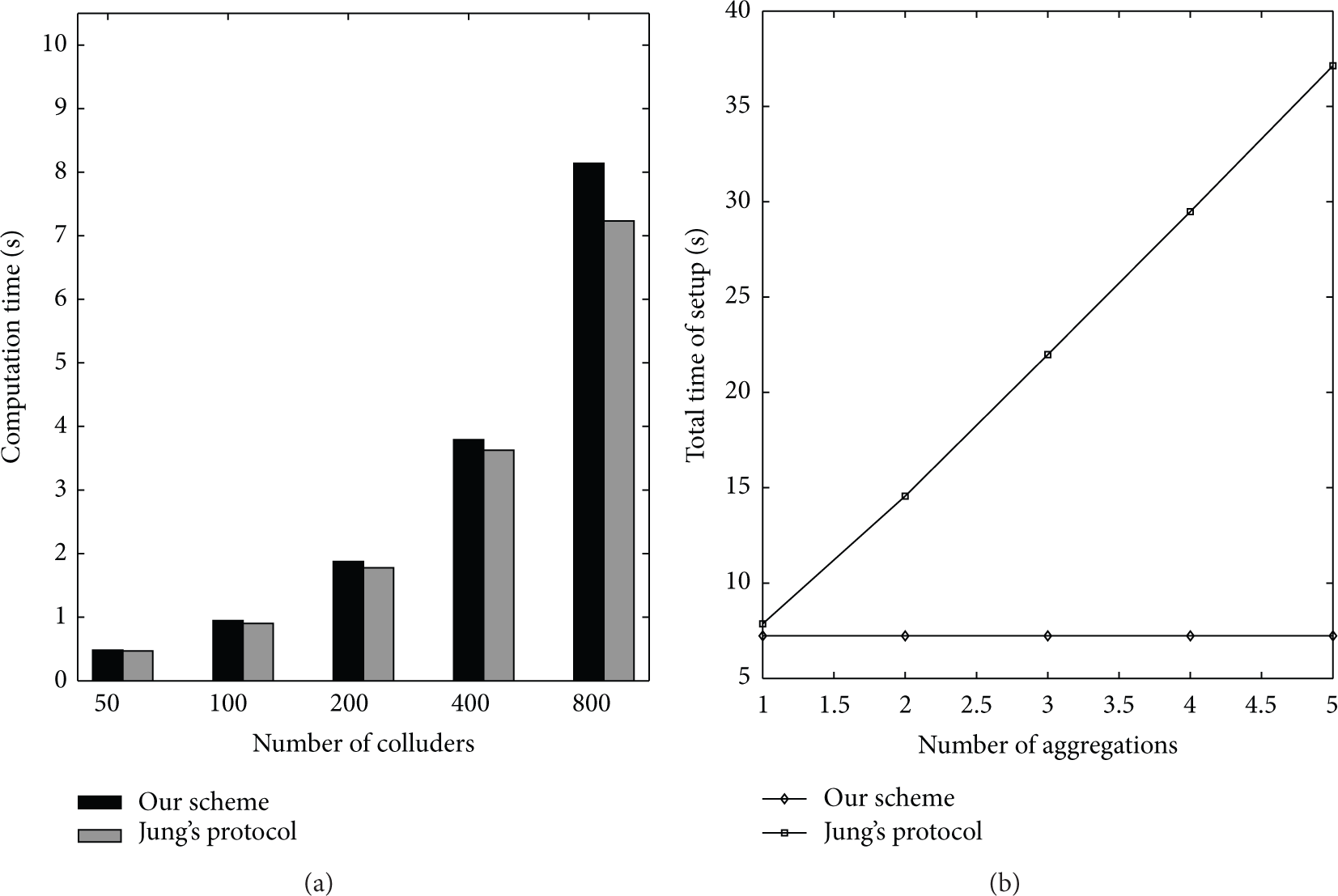
The time spent in setup phase. (a) The dependence of number of colluders and setup time for each participant in the first aggregation. (b) The dependence of number of aggregations and the total time for setup for each participant (here the number of colluders is set to 800).
The independence of computation time of encryption (decryption) for each participant (aggregator) and the number of colluders is shown in Figure 3. In Figure 3, we set the total number of participants to 2,000, while the number of colluders ranges from 50 to 400. Figure 3(a) suggests that the number of colluders has a negligible influence on the computation times of each participant spent in encryption and Figure 3(b) indicates that the number of colluders does not affect significantly the decryption time of aggregator. In addition, Figure 3 shows that the encryption efficiency can be improved by around 300 times (from about 15 ms to 0.05 ms) when exponentiations

The independence of computation time of encryption (decryption) for each participant (aggregator) and the number of colluders. (a) encryption; (b) decryption.

The dependence of total number of participants and decryption time for aggregator.

The independence of the total number of participants and encryption time for each participant. (a) The encryption time of our scheme and EPPP4SMS. (b) The “on-the-fly” encryption time and the encryption time of Jung's protocol.
7. Conclusion
In this paper, we proposed a privacy-preserving aggregation scheme for time-series data without trusted key dealers. Our proposed scheme is experimentally shown to be scalable and faster in the encryption and decryption compared to some Paillier's cryptosystem based protocols. The reason of the outwardly inefficient setup in our scheme is that no trusted or semitrusted key dealer is assigned in the system and the communication channels between the participants and the aggregator are not secure. However, our scheme is shown to be much more efficient than Jung and Li's protocol in [6] with the same security assumption because Jung and Li's protocol is not the time-series data and its initialization should be repeated every time when a new sum is desired. In the proposed scheme, the aggregation results can be calculated efficiently after setup and each participant takes the same processing time independent of the number of participants considered in the aggregation.
The scheme is proposed to tolerate up to k collusive adversaries that will not tamper the computation but try to manipulate their parameters to infer others' private values. And the security of our scheme is formally analyzed and it is shown that the scheme is secure if the CDH problem is assumed to be intractable. Our proposed scheme provides verification as well as scalable encryption because the processing time of the encryption does not depend on the number of participants. The implementations of our scheme suggest that the proposed aggregation protocol is efficient for time-series data.
Footnotes
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant no. 41371402), the National Basic Research Program of China (973 Program) (Grant no. 2011CB302306), and the Fundamental Research Funds for the Central Universities under Grant no. 2015211020201.