
Abstract
Cross-domain identity association of network entities is a significant research challenge and a vital issue of practical value in relationship discovery and service recommendation between things in the Internet of things, cyberspace resources surveying mapping, threat tracking, and intelligent recommendation. This task usually adds additional difficulty to the research in practical applications due to the need to link across multiple platforms. The existing entity identity association methods in cross-domain networks mainly use the attribute information, generated content, and network structure information of network user entities but do not fully use the inherent strong positioning characteristics of active nodes in the network. In this article, we analyzed the structural characteristics of existing relational networks. We found that the hub node has the role of identity association positioning, and the importance of identity association reflected by different nodes is different. Moreover, we creatively designed a network representation learning method. We proposed a supervised learning identity association model combined with a representation learning method. Experiments on the public data set show that using the identity association method proposed in this article, the ranking accuracy of user entity association similarity is about 30% and 25% higher than the existing two typical methods.
Keywords
Introduction
With the gradual expansion of the extension of cyberspace, mobile applications, Internet of things (IoT) applications, big data, and other applications are becoming more and more widely and have attracted more and more attention. A user entity usually has different identities or accounts in the IoT, social networks, e-commerce networks, and other networks, affecting people’s lives and work. For example, intelligent life centered on user entities in the IoT, social activities on Facebook, Twitter, Instagram, YouTube, Weibo, WeChat, TikTok, and other media, also online shopping activities such as Amazon, Tmall, and JD.com.
In practical application, the association analysis of network entities faces the problems of cross-platform and privacy protection, which brings difficulties to the relevant research. The association analysis of cross-domain network user entities has important practical significance in the fields of network behavior analysis and prediction,1–3 relationship discovery and intelligent service recommendation of the IoT, 4 network behavior traceability, cyberspace resources surveying mapping, 5 information dissemination, 6 viral marketing,7,8 cross-domain intelligent recommendation, and so on. Identity association is essentially the closest matching problem of network entities in multiple network domains. The final output of the identity association model is the similarity between network entities; the more significant the similarity, the greater the probability that they are the same physical entity (in the social media domain, the physical entity is a natural person). In the field of intelligent recommendation of the IoT, the greater the similarity means that, the higher the similarity of usage habits between users, the greater the significance of service intelligent recommendation.
Current research, such as in the social media domain, mainly focuses on combining supervised and unsupervised methods to realize the identity association of user entities using the attribute information, generated contents, and network structure information of network users. (1) Methods based on user attributes,9–12 such as Zafarani and Liu, 9 analyze some user identity links, use naive Bayesian classifier, support vector machine, and so on, and combine the behavior pattern constructed by the psychological analysis method to associate user identity. (2) Based on the user-generated content method,13–15 learn and extract the special representation of user identity by extracting user-generated content features, such as the characteristic vocabulary, emotion, expression mode, and track of message content recognition. (3) Previous works10–12 and others use information such as network structure features and user attribute features to learn the connectivity of network topology through graph structure, mine the similarity of identity features between and within network domains, and identify the identity of unknown cross-domain network user entities by comparing one by one and iterating many times.
Among the existing identity association methods, supervised and semi-supervised methods can obtain better correlation accuracy than unsupervised methods. In the identity association analysis method of network entities based on network structure,16–22 most of the existing studies focus on the user identity link based on user anchor node 16 and predict the associated users in the network through anchor node user detection and network identity link analysis.
Generally speaking, the current association analysis method of network entity identity mainly realizes the identity association of cross-domain network user entities based on representation learning method and end-to-end method based on deep learning. 23 The representation learning method maps the user identity to a unified space based on the deep extraction of user information and the accurate expression of user characteristics; determine whether the user identity is associated through the analysis of association degree. Based on the end-to-end method of deep learning, we use the characteristic information of identity association, such as the generated content of users, as well as attribute information such as nickname, network location, social relationship, and so on, input into the deep learning network, directly calculate the association similarity between users and give the probabilistic judgment result of identity association. Researchers have made many efforts to solve the cross-domain user identity association problem. However, there are still difficulties in effectively using the network structure to recognize the relationship between user entities.
According to the above analysis, to meet the requirements of accuracy, the association analysis of cross-domain network user entity identity based on network structure depends not only on the user’s attributes, neighbors, and interaction information with neighbors but also on the structural features of the cross-domain network. In essence, identity association is in opposition to privacy protection. In the field of privacy protection, hub nodes have intense identity exposure in structural features. 17 These hub nodes often have extensive and frequent interpersonal interactions and can form different social groups centered on these nodes. This phenomenon of the hub node has strong recognition in the field of entity identity association prediction. Still, the existing association methods based on network structure representation learning usually ignore this information. This article designs a representation learning method for network structure, which can learn the location characteristics and essential characteristics of nodes, set attention mechanisms to improve the representation ability, and propose an identity association model.
The main contributions of this article are summarized as follows:
We analyzed the structural features of the Twitter–Foursquare social network and found that (1) different nodes reflect different positioning functions, among which the nodes with a higher degree have stronger identity association positioning function; (2) different adjacent nodes reflect different importance degrees of identity association, and we creatively designed a network representation learning method, which uses nodes, respectively, location feature and importance feature are represented by two sets of vectors.
We propose an identity association model for supervised learning IFN-UIL (importance features of nodes and user identity linkage (UIL)); the model combines the essential features of nodes to improve the accuracy of user identity association analysis in complex networks.
Using Twitter and Foursquare data sets, we evaluate the effect of identity association through two methods: P@N and H@N, and compare them with existing identity association methods. The results show that the proposed identity association method has certain advanced nature.
The other parts of this article are organized as follows. The “Related work” section summarizes the related work. The “Problem definition” section formalizes the identity association in cross-domain networks. The “Methods” section analyzes the structural features of the Twitter–Foursquare social network and expounds on the details of the proposed network representation learning method and identity association model. The “Experiments” part is experimental evaluation. The “Conclusion” part is the conclusion of this article.
Related work
In recent years, network embedding has aroused extensive research interest. Network embedding aims to learn the low dimensional representation of network nodes and effectively retain the edge information such as network topology and node content. Cross-domain network embedding is a relatively new research problem at present. It has crucial research significance in intelligent recommendation of IoT services, abnormal network behavior analysis, intelligent recommendation of e-commerce network, network traceability, cyberspace resources surveying mapping, and so on.
In social and e-commerce networks, network structure information is a networked representation of social relations between different users, such as friend relationships, family friend relationships, colleague relationships, subordinate relationships, and follow-up relationships. The network structure information is easier to obtain than user attributes information. Existing studies have proposed many methods on network representation learning combined with identity association. Tan et al. 18 integrated two social networks into a complete network, mapped it to a hypergraph, and used multi neighborhood relations to learn more useful potential network features. Zhou et al., 19 based on the DeepWalk method, 20 encoded the user nodes in the network into vector representation to capture the local and global network structures. These structures can intensely train the user identity association model between different network domains based on semi-supervised methods. Translation-based technology has significant advantages in representing network nodes and edges in complex networks. It can embed the cross-domain network user information and the diverse interaction relationship between users into the low latitude vector space to establish the relationship representation model.21,24 Miao et al. 22 and Wang et al. 25 proposed a user identity association method based on representation learning based on the network structure information, and some anchor links are known. The observed anchor links are used to train the mapping function of identity association prediction and find more hidden anchor links between the two social networks.
In IoT, the discovery method of inter-entity relationship based on graph embedding, such as Yao and colleagues,26,27 maps the context information of nodes to a separate graph to capture the association relationship between different entities. Yao et al. 4 expressed the complex relationship between entities centered on events by constructing hypergraphs, in which vertices represent entities in the microdomain of the IoT and hyperedges define heterogeneous relationships among entities.
However, the current methods encounter bottlenecks in anchor user determination and identity association combination discovery.25,28,29 They lack sufficient association degree support conditions between nodes, resulting in the low accuracy of entity identity association prediction in complex networks. These methods focus more on preserving the generated embedding vector’s structure information and node proximity information. This information is used for the subsequent identity association mining tasks in the network. Whether the DeepWalk method or Node2Vec method is used in the node embedding, due to the inherent characteristics of these methods, they ignore the strong positioning characteristics of the central node in the network.
Problem definition
We first define and introduce the concepts and symbols used in this article.
Network
A network is represented as a graph
UIL
Given any two social networks

The binary function
Methods
Taking social networks as an example, this article discusses the entity identity association combined with hub nodes degree information in the Twitter domain and Foursquare domain.
Data set analysis
The purpose of data set analysis is to find the defects of current research methods, which is the basis of this research idea. We use the Twitter–Foursquare data set
30
in the social network to analyze the association of network user entity identity. The data set includes the number of user nodes, the number of user relationships, and the number of user combinations belonging to the same identity between the Twitter and Foursquare domains, as shown in Table 1. We use the overlap similarity calculation model. First, the degree distribution characteristics of user nodes in the Twitter–Foursquare data set are analyzed. The results show that the user nodes with a high degree have a strong role of identity association and positioning in cross-domain networks. Second, the similarity between different adjacent nodes of user node
Experiment and evaluation training data.

Analysis of degree distribution characteristics
In Twitter and Foursquare social networks, the user nodes in ground truth are sorted in degree characteristics from large to small and are divided into 10 groups of node-sets on average. Use the following formula to calculate the same natural person coverage of Twitter and Foursquare node-sets

where
In different degree ranking sets, As shown in figure 1. the coverage of the same natural person is distributed between 0.1 and 0.5, indicating that the degree ranking of the same natural person at the corresponding nodes of Twitter and Foursquare has a certain similarity. In the top 10% node-set, the same natural person coverage of Twitter and Foursquare reaches 0.5, this indicates that among the top 10% of the identity aligned nodes in the two data sets, 50% of their neighbor nodes correspond to the same natural person. In the node-set after the top 10%, the same natural person coverage is less than 0.3. The comparison results show that this degree ranking similarity is stronger in the top 10% node-set. Nodes with a higher degree are called hub nodes in the network. Such nodes usually have a higher identification degree in the network. Corresponding to the identity association scene, nodes with a higher degree have a stronger positioning effect.

Analysis results of ranking coverage of the same natural person.
Conclusion 1
In social networks, different nodes have different positioning functions, and the nodes with a higher degree have a strong identity association positioning function.
Similarity analysis of adjacent nodes
Generally, a natural person has similar friend groups in different social networks.
31
Given node
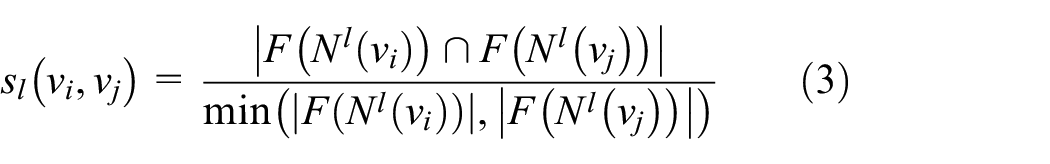
where
As shown in the abscissa positive part in the similarity comparison diagram of 1-hop adjacent nodes in Figure 2(a), the similarity of adjacent nodes belonging to the same natural person is scattered, most of which are distributed between 0 and 1, while most of the similarity of adjacent nodes not belonging to the same natural person is 0, and a few are scattered between 0.1 and 0.6. It can be seen from the comparison that the similarity of adjacent nodes belonging to the same natural person is significantly higher than that of adjacent nodes belonging to the non-same natural person.

Similarity comparison diagram of adjacent nodes belonging to the same natural person: (a) one-hop and (b) two-hop.
As shown in the similarity comparison diagram of two-hop adjacent nodes in Figure 2(b), when two-hop neighbor nodes belong to the same natural person and different natural persons, most of them are distributed between 0.5 and 1.0 (as shown by the positive and negative values of the horizontal axis in Figure 2(b)), and the distinction between the same natural person and non-same natural person is not high, The location advantage of this indirect neighbor node to identity association is not apparent.
The above comparative analysis shows that in the identity association scenario, the set of one-hop adjacent nodes of the same natural person has certain similarities (i.e. the similarity between neighbor nodes belonging to the same natural person in different domains), which indirectly shows that different adjacent nodes have additional support for identity association.
Conclusion 2
For a natural person, the importance of identity association reflected by different adjacent nodes from different domains is different, and its direct neighbors support identity association more.
Proposed method
According to the above two conclusions, this article proposes a supervised learning identity association method divided into two parts: the representation learning model and the identity association model. First, according to the important connectivity role of the hub node in the relational network, we use the representation learning method to make the user node in the relational network have the location features and importance features of the node at the same time (such as the analysis of the data set in section “Data set analysis”), and then through the identity association prediction model, Use the pseudo-Siamese network to calculate the similarity between user nodes. The details are as given below.
Representation learning model
In this article, to facilitate feature representation and the calculation of final identity association similarity, we first need to represent different users in the potential space. According to the two conclusions from the analysis in the previous section, the following problems need to be solved in the process of representation learning:
How to characterize the positioning effect of nodes with a large degree of identity association.
How to characterize the different vital roles of adjacent nodes on identity association.
For problem 1, the node needs to be represented by an eigenvector, which should reflect the node’s position in the social network. For problem 2, we need to use a mechanism to calculate the importance of adjacent nodes of this node adaptively. This importance is the support of adjacent nodes for the node’s identity association and the node’s location in the network.
In order to solve the above problems, this article designs a new network representation learning method, which uses two types of vectors to represent each node: location feature and importance feature. Combining questions 1 and 2, the representation learning objectives are as follows:
Objective 1 (O1): in the same network, learn the importance feature of node
Objective 2 (O2): in the cross-domain network, the location feature similarity of different nodes belonging to the same natural person is higher than that of different nodes not belonging to the same natural person. This target is used for identity association.
In social network

Feature representation learning of network nodes.
In order to effectively integrate the location features of adjacent nodes and calculate the similarity, this article first uses the attention mechanism.
32
It calculates the support of adjacent nodes combined with the importance feature, given the adjacent node
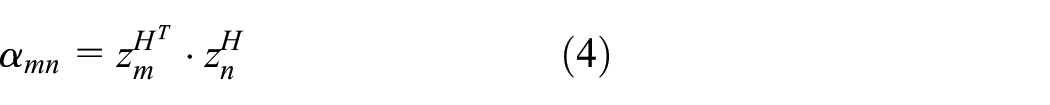
where the superscript

where

After calculating the aggregated features, we can optimize the training of node location features and importance features in representation learning. Corresponding to the target O1, the higher the similarity between the node location features and the aggregated location features of all adjacent nodes as follows

Corresponding to target O2, the higher the similarity of different node location features of the same natural person in different domains as follows

where activation function is
In order to avoid trivial solutions, we introduce the negative sampling term in the training and optimization process of the above formula. In the optimization process for target O1, we introduce the case of non-adjacent nodes, and in the process for target O2, we introduce the case of non-identical natural persons. Therefore, in the process of calculating node aggregation feature
For the binary classification problem of calculation formulas (7) and (8), the binary cross-entropy is used as the loss function for optimization
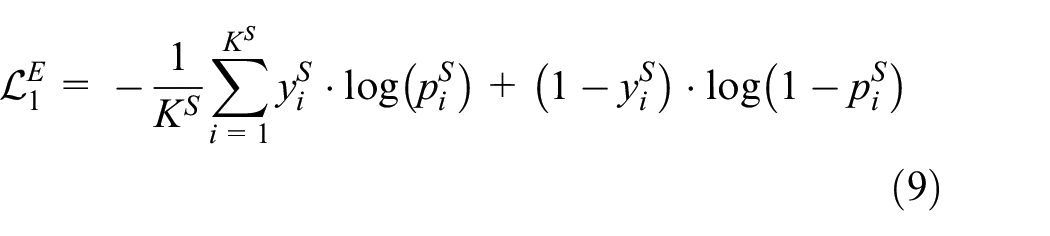


where
Identity association model
Given the social network

Identity association prediction model.
In this article, because the number of training set samples is small, and the identity association belongs to the nearest similarity matching problem, we use a pseudo-Siamese Network for transformation to avoid the result of overfitting. Moreover, the pseudo-Siamese Network itself is used to measure the similarity between the two inputs. In order to learn the linear relationship between features, we use a linear function in the activation function.
The input importance feature dimensions may differ for users from two different social networks. First, the two importance features are transformed into the same dimension through a perceptron layer. We define weight matrix


Finally, the identity association similarity of
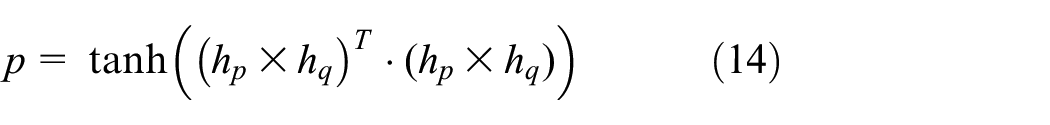
where
In order to avoid the trivial solution, we introduce the negative sampling term in the training optimization process of the above formula. If
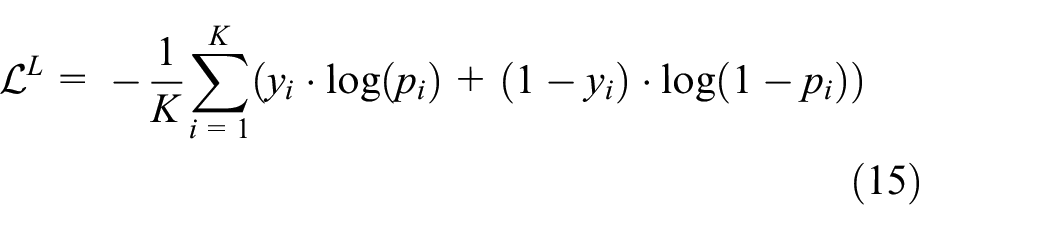
where
Method overview
Algorithm 1 gives the pseudo-code of the algorithm in this article.

Note that user identity association usually involves more than two network domains in practical applications. Most of the previous research and engineering development work focused on the user identity association of the two domains. In the application scenario of user identity association across more than two network domains, we usually need to retrain the model due to different user attributes, generated content, or network relationship dimensions in different network domains. Our model only considers the importance of the degree of nodes and neighbor nodes and does not involve user attributes and generated content. Therefore, our method can be easily extended to application scenarios such as user entity identity association across multiple network domains, IoT relationship discovery, behavior traceability, and resources surveying mapping.
Experiments
First, we evaluate the user entity association method in sections “P@N” and “H@N” in a cross-domain environment, then evaluate the effect of different training ratios in section “Comparison of effects of different training ratios,” and finally, evaluate the comparison between the effect in section “Comparison with other models” and other models on the same data set.
Evaluation method
We use P@N 33 and H@N 28 to evaluate the identity association model in this article. Among them, P@N is used to evaluate the ranking proportion of nodes that meet similar requirements in all nodes. H@N is used to evaluate the ranking proportion of association similarity after node association, which is the sum of the number of users entities successfully associated. In essence, the final output of identity association of entity users in a cross-domain network is the probability that users belong to the same natural person. In the cross-domain network environment, the higher the ranking of this probability, the greater the probability of belonging to the same natural person. The traditional method uses accuracy and recall to evaluate the effect of identity association. In essence, it is to find the similarity threshold through the model. When the output similarity is greater than this threshold, it belongs to the same natural person. The disadvantage of this method is that there may be many similarity outputs greater than the threshold; however, the larger the output value (i.e. the higher the similarity ranking), the greater the probability that two or more of them belong to the same natural person. Traditional methods ignore the key and strong identification role of ranking similarity values output by the model in entity identity association.
P@N
In many user entity identity association methods, a mature and widely used evaluation index is to compare the first n candidates of identity association. Given two social networks

Associate effects P@N indicate the proportion of identities ranked in the top n identity association similarity. The larger the value, the better the identity association effect.
H@N
Evaluation method P@N ignores the sorting relationship in the first N candidates. In this article,

where

Here, H@N is the proportion of the sum of nodes satisfying entity identity association in all N nodes. The higher the proportion, the better the effect of identity association. For example, given a test set
P@N and H@N are used to evaluate the effect of identity association. The similarity ranking N is the identity association threshold in the actual identity association prediction. When the identity association similarity ranking appears in the top N, it is generally considered that it may belong to the same identity.
Comparison of effects of different training ratios
In order to evaluate the model more comprehensively in this article, we set different proportions of training samples for cross-domain user identity association similarity and cross-domain user identity association effect and use Twitter–Foursquare data set to analyze the training effects of methods P@N and H@N in this article at different training ratios.
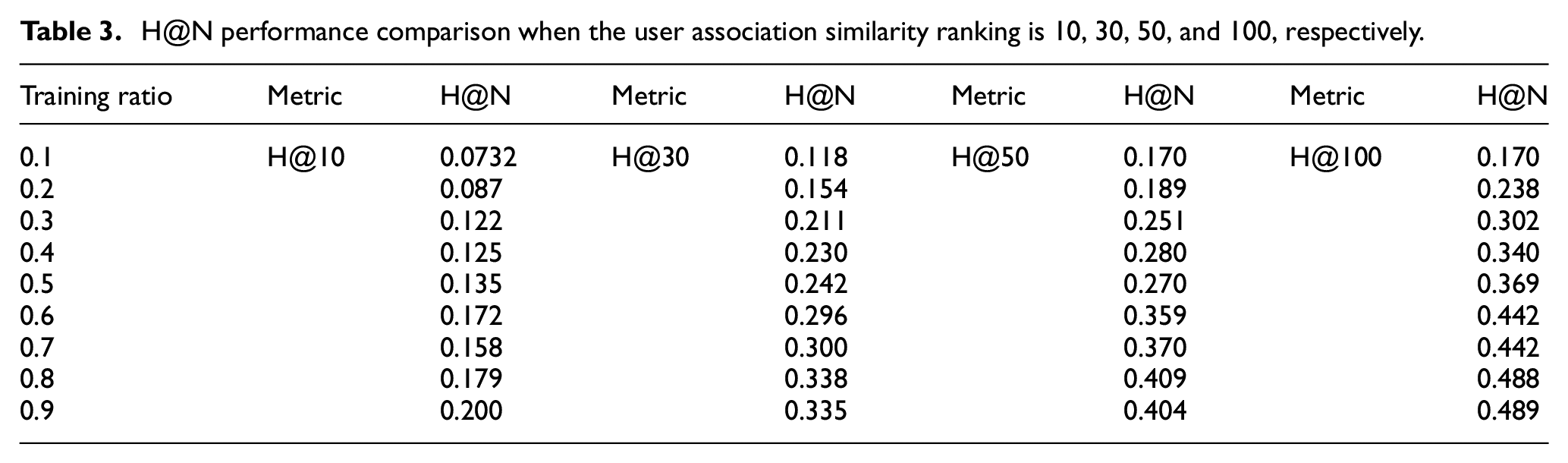
First, we set the training proportion of the number of users to be associated to 0.1–0.9. Under different candidate sets, we analyze the ranking of similar nodes and association similarity of cross-domain entity users. When analyzing the ranking P@N of user similar nodes, different similar node rankings are set to the top 10, 30, and 50, respectively. Because the ranking analysis requirements of H@N are more stringent than those of P@N and require smaller analysis granularity, so the ranking setting of 100 is added; that is, the association similarity ranking of different nodes is set to the top 10, 30, 50, and 100, respectively. The test results are shown in Tables 2 and 3 and Figure 5. The details of algorithm execution can be easily observed from the table, and the performance trend of the algorithm when the marked number changes can be easily judged from the figure.
P@N performance comparison when similar nodes rank 10, 30, and 50, respectively.

H@N performance comparison when the user association similarity ranking is 10, 30, 50, and 100, respectively.

Comparison of different training proportion methods: (a) P@N and (b) H@N.
The results in Table 2 show the comparison of P@N evaluation performance when the ranking of similar nodes is 10, 30, and 50, respectively. It can be noted that when the node similarity ranking value is the same, the proportion of identity association ranking in the test set increases with the increase of the proportion of training data set from 0.1 to 0.9. When the proportion of candidate sets is the same, as the node similarity ranking value gradually increases from 10 to 30, 50, the proportion of identity association ranking in the test set increases. According to the results of many tests, when the training proportion is 90%, and the similar nodes rank in the top 50, the number of nodes meeting the requirements of the identity association test accounts for 55.9%, and the effect is the best, as shown in Figure 5(a).
In Table 3 and Figure 5(b), we give a similarity evaluation method for user entity identity association in a cross-domain environment and compare the performance of H@N when similar nodes rank top 10, 30, 50, and 100, respectively. In the range of 0.1–0.9 of the proportion of the whole candidate set, the evaluation effect trend of each association similarity ranking shows obvious consistency; that is, the proportion of each association similarity ranking shows an increasing trend, which clearly shows that the representation learning method proposed in this article improves the effectiveness of entity identity association. When the metric is taken as 10, the increase of evaluation value is not obvious. When the metric is taken as the first 100, the increase of evaluation value is the most obvious and finally reaches 0.489.
Comparison with other models
We tested EUIA 22 and APAN 25 algorithms on the same test set, all based on network-embedding learning and using only network structure. EUIA is an identity association method based on LINE (large-scale information network embedding), 29 and APAN is an identity association method based on DeepWalk 20 network-embedding. They only use the network structure to analyze the association of network entity identity. Through comparative analysis, it is found that our method performs well on the whole.
First, we compare IFN-UIL, EUIA, and APAN algorithms when the proportion of similar nodes is P@50, the user entity association similarity is H@50, and we observe that when N = 50, the accuracy of the ranking of similar nodes of IFN-UIL is 45.5% and 30% higher than that of EUIA and APAN, respectively, and the ranking of user entity association similarity is about 30% and 25% higher than that of EUIA and APAN, respectively. The main reasons are as follows:
EUIA uses the first-order LINE network-embedding identity association method. This method only models the local adjacency of each node but ignores the global connection characteristics of nodes in the network. APAN uses truncated RandomWalk sequences to learn to embed and capture local and global structural attributes. However, the above two methods ignore the positioning role of the Hub Node in the whole network.
We propose a new network representation learning method in which each node is represented by location feature and importance feature. We finally selected the node importance feature with a better effect to calculate the identity association similarity of cross-domain network entity users. The output result is the ranking of the proportion of identity association similarity. This representation method of hit accuracy has finer granularity than the threshold discrimination method used by EUIA and APAN, so the accuracy of our results is better.
This conclusion can be verified by Figure 6. Figures 5(b) and 6(a) describe the performance changes of methods IFN-UIL, EUIA, and APAN, respectively. With the increase in the number of iterations, it can be found that there is a large gap in the results of various methods. IFN-UIL has achieved better results and obvious advantages than EUIA and APAN for the above reasons.

Comparison of existing methods and identity association results: (a) P@N compared with EUIA and APAN; (b) H@N compared with EUIA and APAN.
Conclusion
This article proposes an entity identity association model IFN-UIL based on supervised learning. Based on the association positioning function of hub nodes, this model is used to solve the probabilistic alignment problem of network entity identity in cross-network domain scenarios. IFN-UIL represents each node in multiple cross-domain networks through two low-dimensional vectors: node location feature and importance feature. We select the node importance feature which has a better effect on identity association for the final identity association prediction. This article uses real data sets to verify and evaluate the performance of the proposed IFN-UIL model. It verifies the effectiveness of our proposed model in the application scenario of entity identity association in cross-domain networks. The experimental results show that the effect of IFN-UIL has certain advantages in the situation of using only network structure information.
The association analysis method of inter-entity relationship based on the association positioning function of hub nodes proposed in this article can be easily extended to the fields of “human-thing” relationship discovery of IoT, network abnormal behavior analysis, cyberspace resources surveying mapping, and so on.
IFN-UIL has two limitations. First, since the IFN-UIL model depends on the results of representation learning, when the network structure changes, such as the addition and deletion of nodes, the model needs to be retrained. Second, because the node embedding vector generated by IFN-UIL is related to the network structure, the accuracy will be low when the network structure of the actual cross-domain application scenario is entirely different. Our subsequent work will try to solve the above problems and improve the efficiency and scalability of the model.
Footnotes
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key R&D Program of China under Grant 2020YFB1708600.