
Abstract
Despite the encouraging outcomes of machine learning and artificial intelligence applications, the safety of artificial intelligence–based systems is one of the most severe challenges that need further exploration. Data set poisoning is a severe problem that may lead to the corruption of machine learning models. The attacker injects data into the data set that are faulty or mislabeled by flipping the actual labels into the incorrect ones. The word “robustness” refers to a machine learning algorithm’s ability to cope with hostile situations. Here, instead of flipping the labels randomly, we use the clustering approach to choose the training samples for label changes to influence the classifiers’ performance and the distance-based anomaly detection capacity in quarantining the poisoned samples. According to our experiments on a benchmark data set, random label flipping may have a short-term negative impact on the classifier’s accuracy. Yet, an anomaly filter would discover on average 63% of them. On the contrary, the proposed clustering-based flipping might inject dormant poisoned samples until the number of poisoned samples is enough to influence the classifiers’ performance severely; on average, the same anomaly filter would discover 25% of them. We also highlight important lessons and observations during this experiment about the performance and robustness of popular multiclass learners against training data set–poisoning attacks that include: trade-offs, complexity, categories, poisoning resistance, and hyperparameter optimization.
Keywords
Introduction
Machine learning (ML) and artificial intelligence (AI) have transformed many industries and addressed many of humanity’s challenges. They permeate our daily lives; people use popular smart devices and services such as Alexa, Amazon, Google Maps, and smart wearable gadgets even without realizing, sometimes, how they have been built. ML and AI applications are revolutionizing the productivity and workflow of several fields throughout the world, such as healthcare,1,2 education,3,4 transportation and road safety,5–7 farming and agriculture,8,9 smart energy and manufacturing,10,11 clean environment and waste management,12,13 crime detection and policing,14,15 finance,16,17 pandemic management such as COVID-19,18,19 water quality and management,20,21 and many more. The data-driven and AI-enabled solutions have significantly increased the capacity to interpret enormous volumes of data created in today’s sensor-enabled environment. Due to the advancement in sensors and smart technology, we can now readily access numerous previously inaccessible areas and collect more data samples at an appealing price point.22,23
Despite the excellent findings and potential of ML and AI applications, one of the primary challenges that need additional exploration and experimentation is the safety and robustness of the AI-based systems. These applications have potential vulnerabilities that might result in severe consequences and possibly costly damage. 24 Today, advanced AI, Big Data solutions, data fusion techniques, and sensors technology facilitate the gathering process of data from different formats and sources. For example, in smart cities applications, data sources can be categorized into physical data sources such as sensors, cyber data sources such as social network data, participatory data sources, including crowdsensing and crowdsourcing, and hybrid data sources of the above. 25 Crowdsourcing and crowdsensing might be vital for attackers to achieve their objectives against the smart systems. Data contributors can share some of their devices’ data (smartphones, wearable devices, etc.) to build a general model(s) for some applications. Hence, there is an opportunity to share some fabricated data that affect the performance of the learning algorithms and thus predictive models; 24 this is known as a poisoning attack, which is the focus of this study.
The contribution of this work
Organizations, researchers, and AI developers cannot just sit back waiting for the attacks, to address the threat and evaluate the impact. Ongoing AI safety and robustness assessment through research and development may considerably impact businesses in identifying and mitigating vulnerabilities and possible damage before they are exploited and transformed into a breach and expensive loss. Due to the rapid evolution toward smart services and cities and the importance of safety issues, we believe exploring possible threats and weaknesses is no longer a luxury but a necessity to strengthen the AI immune systems.
In this study, we can summarize the contribution as follows
We propose, formulate, and evaluate a possible label-flipping poisoning method that depends on some distance-based algorithm to create poisoned samples that pass through outlier detectors possibly deployed in a data cleaning phase.
The study also evaluates the robustness of some commonly used ML algorithms, besides deep learning (DL), in response to fabricated data injected, somehow, into the training data set. The main objective is to study the behavior of the algorithms in rebuilding models using a mix of poisoned and benign data sets.
We also show any Euclidean distance-based data filter challenge when attackers inject poisoning data samples into the benign data repository. In addition, we evaluate the RKOF (Robust Kernel-based Outlier Factor) algorithm if applied to quarantine poisoned samples using the proposed method and random label method as anomaly data samples. This method is developed based on a variable kernel density estimate of an object’s neighborhood. It is implemented in the “OutlierDetection,” R library version 0.1.1.
The study provides the research and development (R&D) teams in AI safety with important lessons, insights, and observations in smart services and cities for further collaboration.
Related work
Attacks against ML
The attacker’s objective, knowledge, and tactics are frequently used to characterize attacks against AI and ML models. Attackers may use adversarial samples with a specific aim in mind, causing the model to incorrectly categorize samples into a particular class (label), known as a targeted attack. In an untargeted attack, the attackers aim to provide manipulated samples incorrectly categorized to any other class (label). A white-box scenario allows attackers to have complete access to the model, data set, and training parameters in terms of attacker knowledge. In contrast, a black-box scenario allows attackers to access the model. Attackers’ tactics (or strategy) involve the type of perturbations, the functions that create them, and how the attackers may launch the attack.24,26
Several strategies are discussed in the literature to attack smart systems such as poisoning attacks,27–32 evasion attacks,30,33–35 and model extraction.36,37 Interested readers are encouraged to refer to a recent publication. 24
The proposed method in this study is classified as a poisoning attack. Generally, attackers share some manipulated samples of data to be consumed by the learning algorithm when it is updating the model on new training data collected, for example, by crowdsensing or crowdsourcing systems from the physical world,38,39 that, in turn, could push the learning quality to the worst level. The manipulated data can be of different formats such as images,40,41 text, 42 or audio. 43 This could introduce a concern about the reliability and trustiness of the shared data.44,45 Moreover, despite the fact that majority of research focused on DL in studying the adversarial attacks, other algorithms are also evaluated, such as artificial neural networks (ANNs), 44 support vector machine (SVM),46,47 Random Forest (RF), and Naïve Bayes (NB).48,49
Label-flipping poisoning attack
One of the techniques used to poison a data set is creating adversarial examples by changing the true labels of the features vectors to other false labels selected from the set of labels of the data set (also known as Label-flipping attack). Thus, the classifier inaccuracy on the testing data samples will be maximized after any re-training session on the adversarial data. 50
In the study by Biggio et al., 47 the gradient ascent strategy is utilized to maximize the testing error of the support vector machine. The attack algorithm starts by cloning a random data sample and flipping its label, considering the sample is close to the boundary of the attacking class. Results showed that the poisoning algorithm significantly impacted the SVM’s binary classifier; two-class classification problems. On three different data sets of spam base used for binary classification, experiments by Zhang et al. 49 were conducted to evaluate five ML and two DL algorithms. The data sets were poisoned using three different label-flipping algorithms; random flipping, entropy method, and k-medoids. Results showed that the flipping attacks could increase the testing error of the NB classifier to around 30% by poisoning 20% of the data samples. The attack impact of the entropy approach becomes more visible as the noise level rises, and it outperforms other methods, according to the data. In Shanthini et al.’s study, 51 the robustness of three boosting learners was tested on three medical data sets under the effect of features and label noise. The findings of the experiments reveal that label noise does significantly more harm than feature noise. XGBoost has proven to be the most powerful algorithm under the label flipping attack in binary class data sets. The authors in the study by Xiao et al. 52 discussed and evaluated various types of label noise assault, even if the attacker alters just a tiny proportion of the training labels, methods that might considerably impair the SVM’s classification performance on new test data. In the study by Taheri et al., 53 the K-mean clustering algorithm is used to cluster the training data set into two main clusters. For each data sample and corresponding predicted label, the silhouette value (SV) is calculated. Since the values of SV range between 1 and −1, the data sample of SV close to 1 means it fits into that cluster, and the ones less than 0 are clustered incorrectly. The poisoning flipping algorithm most likely picked the samples that could be in the other cluster; SV values less than 0. This study uses K-mean to cluster the training data set into K clusters where the K values are picked as the best value based on the minimum validation error.
In this article, we suggest a clustering-based label-flipping attack that poisons data samples with distinct labels that are grouped in the same cluster. To poison the sample data, we suggest a strategy that promotes the notion of class label flipping. Instead of randomly flipping the labels of the collected samples, which are contributed to the data set repository by different users through crowdsensing systems, for example, this approach targets a specific set of samples that could balance between increasing the overall loss of the ML/DL model and the probability of detecting those poisoned samples by outlier detectors during the data cleaning phase.
Clustering-based label-flipping attack
These attacks happen early in the process, during the AI system’s creation and training. It frequently includes manipulating the data used to train the system. We consider a situation in which data samples are added in a continuous or online learning context. We consider the problem of learning multiclass classifiers over a data set
The clustering-based attack proposed and evaluated in this study shares the same steps as the randomly flipping attacks. It has the same ultimate goal of decreasing the performance of the classifiers. However, not all samples in the data set will be used in the flipping process. We formulate the clustering-based flipping attack as follows:
Given a benign training data set


where
1. ya≠yb, and
2.
to flip their classes in the form (
3.

We substitute the K-means clustering algorithm to the above function

where

An example of clustering-based label flipping.

The process of poisoning data samples based on clustering.
Method and data
This section describes the experiment environment and method to poison data samples usually collected by crowdsensing systems. It also describes the data set and the learning algorithms used in this study. Four primary metrics are used to evaluate the performance of all classifiers; namely, overall accuracy, Macro-precision, Macro-recall, and Macro-F1 score.
Multiclass learning algorithms
We evaluate commonly used multiclass learning algorithms used in ML/DL-based solutions. Namely, (1) ANN, (2) K-nearest neighbor (KNN), (3) boosted decision trees (BDT), (4) RF, (5) one-versus-rest support vector machine (6) one-versus-one support vector machine, (7) one-versus- rest NB, (8) one-versus-one NB, (9) one-versus- rest ANN, (10) one-versus-one ANN, (11) one-versus- rest BDT, (12) one-versus-one BDT, and (13) DL. The setting for each algorithm will be discussed in the subsequent sections. All classifiers are trained using 10-fold cross-validation and evaluated on an unseen testing data set.
ANN algorithm
The ANN has been trained on the default parameters, one hidden layer fully connected to both input and output layers. The hidden layer has 100 nodes. The learning rate was set to 0.4, the momentum was set to 0, and the shuffle example option was enabled (i.e. TRUE).
BDT algorithm
BDT is an ensemble ML of multiple weak learners, decision trees in this case. Each tree is dependent on the preceded tree during the learning process to improve the overall accuracy. BDT has been trained using 20 leaves per tree, a maximum of 10 samples per leaf node, the learning rate was set to 0.2, and the number of trees constructed is 100.
KNN algorithm
KNN is one of the popular supervised ML algorithms utilized in several ML-based applications. It mainly depends on the idea of objects’ similarity or proximity. Although it is simple to apply and use, KNN models’ performance could vary, sometimes significantly, using different values of K on other data sets. In this study, the “caret” R library has been utilized to find the best value of K for the benign (intact) training data set. Using 40 iterations and the accuracy values returned, “caret” suggested using K = 53. Note that the accuracy was collected using cross-validation of 10 folds repeated three times on the benign training data set. The testing data set is not part of the optimization process.
RF algorithm
RF, one of the popular ML algorithms, shows success stories in different domains. The RF method combines the predictions of several decision trees of various depths. Every decision tree is trained on a bootstrapped data set, which is a subset of the entire benign training data set, and the left subset is used for validation. The RF models in this study were built using the “randomforest” R library.
SVM (one-vs-rest)
SVM might be considered one of the most common ML algorithms used in different disciplines. For a two-class classification problem, SVM tries to find a decision boundary to separate the samples in n-dimensional space, where n is the number of features in the data set. One-versus-all is a heuristic method that uses binary classification algorithms to solve a multiclass classification problem. It entails breaking down the multiclass data set into many binary classification tasks. On each binary classification task, a binary classifier is trained, and prediction is made using the most confident classifier. It requires building one model for each class; in this study, and since the data set has six distinct classes, this method would create six models.
SVM (one-vs-one)
The one-versus-one heuristic method also splits the training data set into binary classification tasks. However, not for each class versus others, but for each class versus every other class. Every classifier would vote for a label, and the most predictions or votes will be returned by this method. This method would build (6×5)/2 = 15 classifiers for the voting phase for six distinct classes.
One-versus-one and one-versus-rest strategies
In this study, we evaluate these strategies with SVM, NB, and even with those learning algorithms supporting multiclass classification problems such as ANN and BDT. It could be helpful to evaluate the effect of poisoning attacks on models when they were built using these strategies.
DL algorithm
Compared to the afore-mentioned neural networks, DL utilizes multiple hidden layers. It can be seen that DL is a neural network that consists of more than three layers; an input layer, multiple hidden layers, and an output layer. DL shows many success stories, especially in the era of Big Data, in different domains. In this study, we utilize the “h2o” R library to train the model and study the effect of poisoning attacks on the DL models. While the DL algorithm has many parameters that could impact the performance of the DL-based system, we use particle swarm optimization 55 to find the number of layers and neurons to be used in building DL on benign data sets. PSO suggests two layers of 50 neurons each for the benign data set.
Data set
Training and testing data sets used in this study are publicly available. It is a benchmark human activity recognition collected from smartphones and smartwatches; 54 the features’ values are collected from two motion sensors in smartphones that represent six different activities, {“Biking,”“Sitting,”“Standing,”“Walking,”“Stair Up,”“Stair Down”}. In this study, we use the main features generated by smartphone sensors and ignore other features related to the original experiment, such as index, creation time, arrival time, user, model, and device. We focus on the three main readings; “x,”“y,” and “z” generated from Nexus smartphone sensors for one user; user “a.” The used data set consists of 218,178 training records and 72,722 testing records. Each record (sample) has three features and one activity label, which is a multiclass label for the six activities mentioned above.
Results and discussion
Algorithms performance
ANN performance
Figure 3 shows the four metrics used to evaluate the performance of ANN. The model loses its accuracy as the poisoning rate increases. Using the clustering-based method, the ANN model accuracy was affected and dropped when the poisoning rates were 40% and 50%, where the accuracy was 68.5% (∼5% loss) and 64.7% (∼9% loss), respectively. Flipping the labels of samples grouped in different clusters has more effect on the performance of ANN models. The accuracy dropped to below 50% (i.e. 42.8%, ∼31% loss) after increasing the poisoning rate to 50%.

ANN performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. ANN: artificial neural network.
BDT performance
BDT, in Figure 4, shows some sort of robustness against clustering-based poisoning till half of the training data set gets poisoning. The accuracy dropped significantly after the clustering-based method flipped 50% of the training data; the accuracy loss is almost 10%. The same poisoning rate (i.e. 50%) was applied using samples of different clusters, and the BDT model cannot achieve more than 41% accuracy (∼30% loss). However, the BDT model is also showing some stability in the accuracy even with this method of flipping till the poisoning rate exceeds 40%.

BDT performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. BDT: boosted decision tree.
KNN performance
In Figure 5, the KNN algorithm maintained a stable performance even with some distorted samples, up to 30% poisoning rate using both poisoning methods. KNN loses the ability to resist the poisoning when the poisoning rates get more prominent than 30%. In addition, KNN outperforms the other algorithms in this investigation, save from RF.

KNN (K = 53) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. KNN: K-nearest neighbor.
RF performance
Figure 6 depicts the performance of the RF. RF maintains an almost stable performance until 40% of the training data becomes poisoned. However, 50% of poisoned samples using the clustering-based flipping method decreased the model performance by 13.5%, while using random flipping has more effect on the 50% poisoning rate and dropped the accuracy by ∼33%. The impact of random flipping started since 30% of the training data are poisoned, while the effect of clustering-based flipping would need more poisoned samples than 30% to show some impact on the performance.

Random forest performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score.
SVM performance
Figures 7 and 8 show the performance of the support vector machine using both approaches; one-versus-rest and one-versus-one. SVM performance is comparable to RF and KNN in its resistance to poisoning rates of less than 30% using both poisoning methods. However, the SVM with the one-versus-one strategy improves when the poisoning rates increase, such as 30% and 50% poisoning rates using the clustering-based method. There is a slight difference in the accuracy and stability of the performance with increasing the poisoning rates between the one-versus-rest and one-versus-one approaches. This observation could be considered a starting point for more extensive experiments and evaluation on large data sets and different types of attacks, yet beyond the scope of this study.

SVM (one-vs-all) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. SVM: support vector machine.

SVM (one-vs-one) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. SVM: support vector machine.
NB performance
In this study, Figures 9 and 10 show that NB models are the most sensitive models compared to the random label-flipping poisoning attacks. The performance drops by around 8%, with every 10% rise in poisoning, similar to linear behavior. It is worth noting that, while utilizing the clustering-based method, performance rises and falls in proportion to the percentage of poisoning. On 50% of the poisoned data, accuracy rebounded to around 65%, with just a 5% reduction on the original benign data. This loss percentage may be unacceptable in some applications. Still, it is not significant if we know the data are not benign and has been modified to influence the model’s performance.

Naive Bayes (one-vs-all) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score.
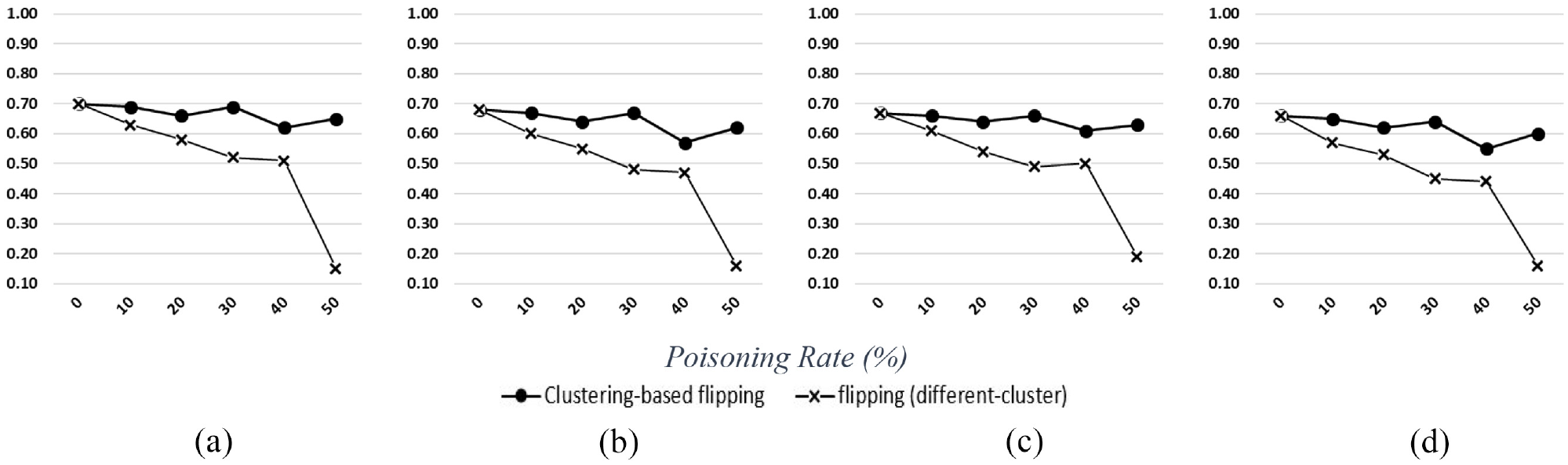
Naive Bayes (one-vs-one) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score.
One-versus-one and one-versus-rest strategies
Figures 11–14 show the performance of ANN and BDT if utilized as binary classification algorithms in one-versus-one and one-versus-rest strategies. The findings show no substantial difference in the outcomes when these strategies are used. Results also showed that, given the data set and poisoning methods in this study, there is no significant difference in reaction to the poisoning rates between one-versus-one and one-versus-rest on NB or SVM binary classification algorithms.

ANN (one-vs-all) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. ANN: artificial neural network.
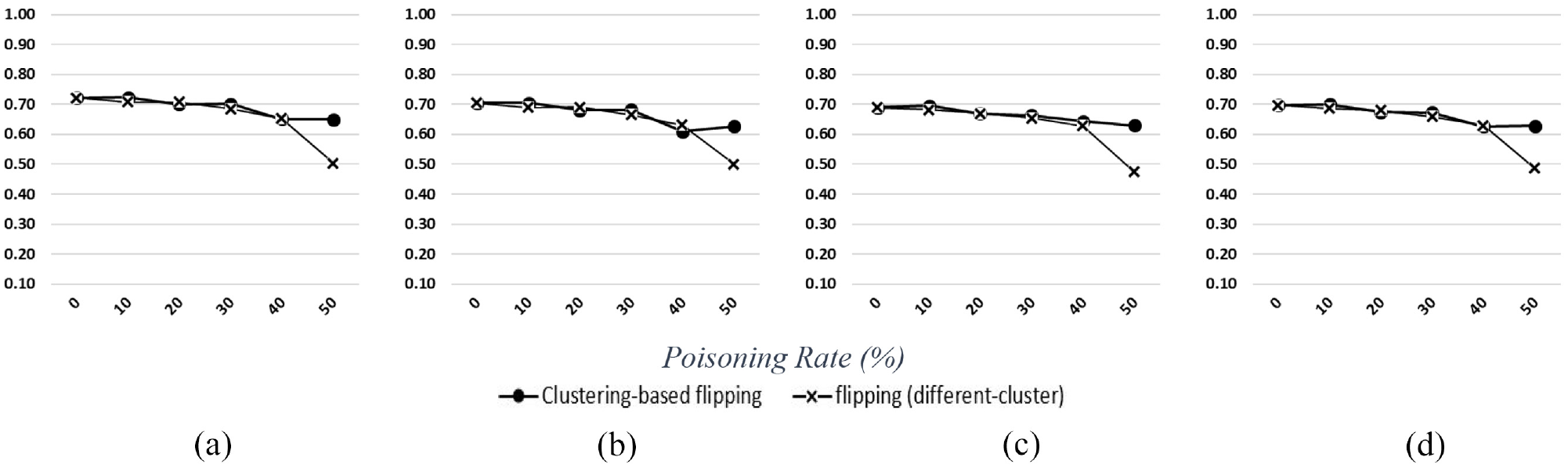
ANN (one-vs-one) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. ANN: artificial neural network.

BDT (one-vs-all) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. BDT: boosted decision tree.

BDT (one-vs-one) performance: (a) accuracy, (b) macro recall, (c) macro precision, and (d) F1-score. BDT: boosted decision tree.
The performance of the above algorithms in this experiment, which is a temporary situation with poisoning rates less than 30%, with newly collected samples could be considered as a justification to trust the data source, which, in turn, would allow the attackers to inject more fake samples. From another point of view, the clustering-based poisoning attack needs to flip more than 30% of training samples to be effective enough to mislead these algorithms. The injected manipulated samples are in dormancy time until the poisoning rate becomes enough to degrade the performance of the models. Sanitizing the data might be costly, especially after multiple re-training phases, and not simple unless the AI engineers decide to return to the starting point and forego the new data and its gathering cost. Whatever the taken decision at that point, the loss has already occurred.
DL performance
Figure 15 depicts the performance of the DL algorithm. Interestingly, as opposed to other algorithms evaluated in this study, the DL models behavior is not predictive of increasing poisoning rates either using clustering-based flipping or randomly flipping over different clusters. Randomly flipping 10% or 20% of samples labels is enough to drop the accuracy down to 60% (∼10% loss) and 51.8% (∼20% loss), respectively. However, the overall performance gets back to improve sometimes with more poisoning samples injected into the training data sets, such as from 20% to 30% and from 40% to 50% poisoning rates. On the contrary, the performance has gradually crashed with the increment of the poisoning rates using the clustering-based method. Sometimes, the model maintains the performance with more poisoning samples. However, the maximum loss with 50% of poisoned samples using the clustering-based method does not exceed 11%.

Deep Learning Performance: (a) Accuracy, (b) Macro Recall, (c) Macro Precision, and (d) F1-Score.
Compared to other algorithms used in this study, the results of DL reveal how sensitive the DL models are to the poisoning attacks. Although the findings revealed a pattern of diminishing performance with an increase in the proportion of poisoning, DL may return with unexpected results, necessitating a thorough examination of a variety of data in various forms and dimensions. Also, when using these algorithms in real-world applications, the periods required to re-evaluate the models may need to be adjusted anytime new data are introduced to the existing ones in the data store.
Lessons and insights
Distance measures and anomaly detection
We conducted experiments to evaluate the efficacy of distance-based outlier detectors, if utilized, in detecting the poisoned samples. We also show the results of the RKOF method on the poisoning training data sets.
Figure 17 depicts the distance among features’ vectors of different classes. We generate a mean vector for each class, which is simply the mean value of each feature, to summarize each class’ distribution of features’ values in one vector. After that, we applied the Euclidean distance algorithm to calculate the distance between the mean vector for each class and other classes’ mean vectors grouped in the same cluster and grouped in different clusters. The main objective is to show those data samples that the clustering-based attack can target to flip their labels to other labels. Figure 17 shows that attackers would pick the data samples of different classes belonging to the same cluster using the clustering-based attack to increase the probability of passing through any distance-based filter possibly applied in the data cleaning phase. Attackers might target the data samples clustered in cluster 1, “stair down,” for example, to flip their labels into “biking” to settle most of them in the training data set for any future re-training session of the model.
The above are unsurprising results since the K-mean clustering algorithm depends on the distance to group the data samples into clusters. However, it could be one of the attackers’ options to poison the data samples straightforwardly. The clustering algorithms are currently available even in drag and drop tools and can be easily applied without deep knowledge in programming or the AI field.
Table 1 shows the results of applying RKOF outlier detector algorithms. We pick a subset of the data set that contains 10% of poisoned samples once using the clustering-based poisoning attack and again using the second poisoning method; over different clusters. The RKOF was able to identify, on average, 25% of the poisoned data samples using the clustering-based method, and 7% of benign data samples were sacrificed. Using the second method of poisoning data samples over different clusters, RKOF was able to identify, on average, 63% of the poisoned data samples, and only 2.9% of benign samples were sacrificed.
Detection rates of RKOF where 10% of the samples are poisoned using both methods evaluated in this study.

RKOF: robust kernel-based outlier factor.
Detectability versus effectiveness
Based on the above results of the RKOF algorithm, attackers might successfully inject 75% of the poisoned samples using the clustering-based method into the training data set. In comparison, they might be able to inject 37% of the poisoned samples using flipping labels of samples grouped into different clusters. The above results probably encourage attackers, yet challenges for the defense system developers. The results show clear evidence of the trade-off between the attack’s detectability and its effectiveness on the AI models’ performance. The clustering-based poisoning method may be a decent alternative for attackers who want to insert some poisoned samples into the benign training data. Still, the effect on the learning algorithms and models’ performance may take some time until the proportion of poisoned samples is significant. In contrast, the second strategy to flip the labels of a sample belonging to different clusters may affect the performance with a lower percentage of poisoned samples but with a higher probability to be quarantined by outlier detectors or data filters.
Poisoning attacks complexity
From the attackers’ point of view, the clustering-based strategy might perform better in terms of detectability but on the costs of complexity and implementation. This would create another trade-off between complexity and detectability. Despite the availability of the clustering algorithm and the simplicity of some tools that offer ML/DL algorithm, such as Microsoft Azure ML studio, the process of data samples evaluation to be involved in the poisoning phase could consume some time and resources. The objectives are the ones that might have the maximum effect on the model’s performance and also can pass through the detectors if applied. In this study, random label flipping could be much cheaper in preparation and implementation than the clustering-based method. However, it could be easier for the detector to end up with a high percentage of poisoned samples in the quarantine. From another point of view, clustering-based poisoned samples that could pass through the detectors might not have immediate effects. Moreover, picking the candidate samples with multiclass data sets would add another complexity factor since the flipping is not random but should be done within a single cluster. At the same time, we might need to keep the balance of the classes similar to the original data set.
Furthermore, one noteworthy discovery is the ease with which clustering-based assaults may be applied in crowdsensing systems; clustering algorithms are accessible and often supplied as a service, for example, ML as a service (MLaaS), which could not need a profound grasp of how to develop a data poisoning technique; inexperienced or novice ML users may be potential attackers in this case.
Multiclass classification algorithms and strategies
Multiclass classification problems can be solved using a variety of algorithms that support this type of problem, such as ANN and DT, as well as algorithms that were initially developed for binary classification problems, such as SVM and NB, by dividing the multiclass classification problem into several binary classification problems, such as one-versus-one or one-versus-rest. This investigation discovered that utilizing one-versus-one or one-versus-rest with the original multiclass classification methods had no discernible influence on poisoning attacks or the learning process. ANN and BDT models behave similarly whether they were fitted directly on the poisoned data set or by a third party; binary models by using a one-versus-one or one-versus-rest approach. One more observation is that there is no preference for one when comparing one-versus-one and one-versus-rest on dealing with poisoned training data sets. Therefore, the decision is up to the ML developers to choose according to other criteria such as training time.
DL and hyperparameter optimization
Figure 15 shows DL models trained on data sets with varying poisoning rates but utilized the same learning parameter values as the benign data set. After gathering new data, ML engineers might consider and assess updating the learning parameters. Models of better performance might be achieved with a new data set and modified parameters. When it comes to poisoning assaults, though, this might be an issue. Figure 16 shows how the PSO technique in the study by Qolomany et al. 55 was used to optimize the performance of DL parameters. The findings revealed that using parameters tuning in DL, the effect of a poisoned data set added to the initial benign data set might be hidden or diminished. Regardless of the poisoning approach used, clustering-based or random, the PSO effectively identified alternative parameter values that improved the DL models’ performance, even though the poisoning rate is constantly growing. When comparing Figures 15 and 16, parameter tweaking might be a trap, causing the models to anticipate different things than they should. The performance measurements probably still show values within the user-defined performance boundaries.

Deep Learning Performance with PSO for each poisoning rate: (a) Accuracy (b) Macro Recall (c ) Macro Precision (d) F1-Score.
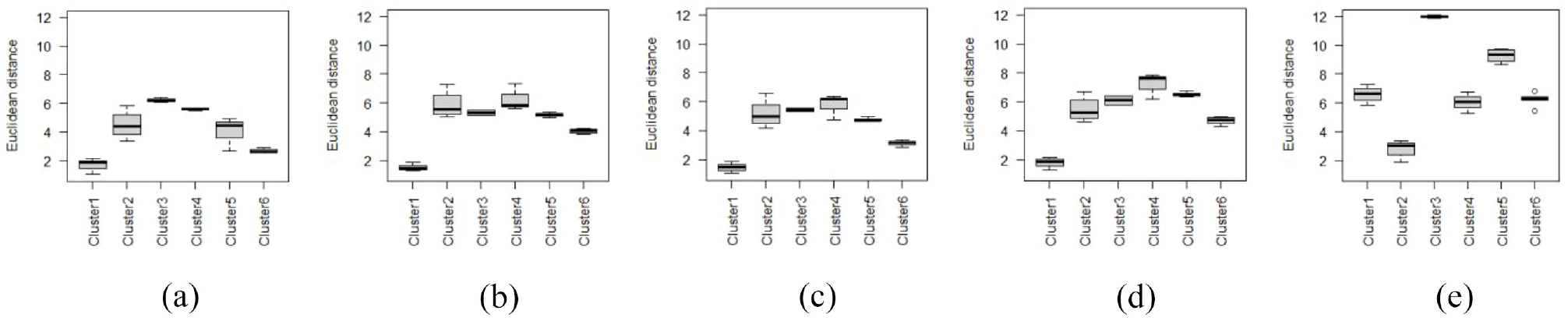
The Euclidean distance of the classes’ mean vectors among the clusters: (a) biking class in cluster 1 versus others, (b) stair-down class in cluster 1 versus others, (c) stair-up class in cluster 1 versus others, (d) walking class in cluster 1 versus others, and (e) sitting class in cluster 2 versus others.
Poisoning resistance
According to the results of the learning algorithms on the data set used in this study, we may categorize the effect of poisoning rates and models resistance into three categories: (1) steady then fail, such as KNN, BDT, and SVM (one-versus-one); (2) gradually fail, such as RF, ANN, SVM (one-versus-rest), and NB; (3) zigzag pattern or irregular fail, such as DL, and NB with the clustering-based method. The first category shows more robustness against poisoning attacks. It might be favored to be used with simple filters of poisoned data samples as they can resist almost 30% of the poisoning rate. The second and third categories show more sensitivity to poisoning data samples, which could need more advanced and efficient filters of poisoned data samples to protect the performance of the systems.
From another point of view, the algorithms in the second and third categories may consume extra data characteristics when building the model, causing the model to perceive different details on benign test data. In general, we cannot decide for sure whether algorithms are superior, whether they are more resistant, or more sensitive; more research in this area, we believe, is required.
Conclusion
We propose, define, and evaluate a feasible label-flipping poisoning approach based on clustering algorithms. The main objective is to produce poisoned training samples that affect the accuracy of the classifiers while passing through outlier detectors. Using popular multiclass learners and a benchmark data set, the proposed method results are compared to the extreme case of flipping labels of data samples belonging to different clusters. The clustering-based poisoning strategy may be a good option for attackers, but the effect on the learning algorithms and models’ performance may take some time before the proportion of poisoned samples becomes significant, whereas the random strategy, flipping the labels of samples belonging to different clusters, may affect the performance of the models with less amount of poisoned data. However, the clustering-based attack could increase the probability of passing through the outlier detectors while most of the data samples that are assigned random labels could be quarantined. This simply shows the trade-off between the effectiveness and detectability of label-flipping attacks. Moreover, one notable observation is the simplicity of applying clustering-based attacks in crowdsensing systems, which means inexperienced or beginner ML users could be potential attackers. We also identified three failure behaviors of multiclass learners in response to the poisoning rates, which, in turn, might help in identifying the complexity of data cleaners before injecting them into the training data sets. An important lesson was about the optimization of hyperparameters of DL models during the re-training phases. This optimization over the poisoned data set might cover the effect of poisoned data samples and mislead the AI engineer by improving the performance, even though the rate of poisoning is growing.
In general, when employing these algorithms in real-world applications, the time intervals for re-evaluating the models may need to be adjusted whenever new data are added to the data storage.
Footnotes
Acknowledgements
The Deanship of Scientific Research at the Hashemite University, Jordan provided resources supporting this work.
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.