
Abstract
Modern military decision-making emphasizes the efficient conversion of information to action under uncertainty. Canonical frameworks such as Boyd’s Observe–Orient–Decide–Act (OODA) loop and Endsley’s model of Situational Awareness (SA) describe this process. To supplement these models, a measure called the HIT score is proposed, which functions as a proxy for both OODA and SA. The HIT score is a quantitative, nonintrusive, post hoc metric for information-processing efficiency. It is domain-agnostic and measures how effectively a system compresses environmental uncertainty into context-appropriate action within time constraints or other domain-specific costs. HIT depends on three observable or inferable components: H (Shannon entropy of the environment), I (mutual information between context and response), and T (decision time or cost). Formalisms for computing HIT are presented for single agents and networked settings. Empirical examples, including an iterated prisoner’s dilemma simulation and command and control (C2)-like scenarios, illustrate that HIT distinguishes adaptive strategies from those exhibiting mere random variability. Moreover, the metric is expanded by Petri Net-based approaches that are computationally tractable and practically applicable in both simulations and real-world scenarios. The HIT score provides a minimal quantitative bridge between information theory and operational decision-making in information-rich environments.
Keywords
1. Introduction
Effective command and control (C2) in dynamic environments requires assessing the degree to which decision-makers process information. Seminal frameworks, such as Boyd’s 1 Observe–Orient–Decide–Act (OODA) loop and Endsley’s 2 three-level situational awareness (SA) model, qualitatively describe the cycle of observing, orienting to context, deciding, and acting under uncertainty. However, these canonical frameworks have notable shortcomings, namely that they do not provide any non-intrusive quantitative means for assessing decision-making either in near real-time or post hoc. Given two systems, which had a tighter OODA loop or higher SA in a given situation? The HIT score proposed in this paper can act as a proxy metric for such measurements, especially in simulations where ground truth is accessible. The proposed metric is, in essence, about timely compression of environmental entropy into actionable information. Hence, it can also be considered to be a metric of adaptive intelligence. In that regard also, the HIT score has certain advantages in comparison to other metrics. Many existing attempts to measure adaptive intelligence fix a suite of tasks and tally performance, 3 rely on detailed internal models of cognition, 4 or invoke theoretical constructs such as Kolmogorov complexity that are impractical to compute in practice. 5 Instead of necessitating modeling of internal processes, the HIT score is calculable using observable or inferable variables.
In this paper, the
Per Endsley’s
2
classic SA definition: “Situation awareness is the perception of the elements in the environment within a volume of time and space, the comprehension of their meaning, and the projection of their status in the near future.” HIT operationalizes core aspects of Endsley’s SA model through the lens of information theory. Perception, comprehension, and projection are directly and meaningfully reflected in
Intuitively, a high HIT score would indicate that a system is both informed and efficient—it encounters a wide variety of situations and reliably acts in context-appropriate ways with minimal delay. This formulation captures desirable adaptive behavior in line with OODA and SA. For example, an agent with a fast and contextually precise response cycle will score higher than one that either responds slowly or ignores important aspects of the situation. Conversely, an agent that reacts randomly or rigidly (ignoring context) will have a low score despite achieving possibly high action variability. In short, HIT distinguishes information-driven adaptability from mere activity.
The performance of the HIT score is tested in a sensitivity analysis and validated in game-theoretic and military decision-making-inspired simulated settings. In an iterated prisoner’s dilemma (IPD) tournament, 6 strategies that condition their actions on the opponent’s behavior (thus leveraging context) achieve higher HIT scores than unconditional or random strategies. A similar pattern is observed in simplified agent-based air-policing models and C2-like simulations: an autonomous agent that dynamically balances new information with timely action outperforms one that either rushes decisions or hesitates excessively. These in silico case studies illustrate HIT’s applicability and its alignment with intuitive notions of decision-making quality.
Contributions:
A novel metric—the HIT score—for adaptive information compression, grounded in Shannon entropy and mutual information with explicit costing, is proposed.
A formal definition of HIT is developed and applied for individual agents and networked systems.
It is demonstrated conceptually that HIT operationalizes key aspects of both OODA and SA and, thus, may be applicable as their post hoc proxy.
Examples showing how the HIT score can empirically distinguish effective strategies in dynamic simulated scenarios are provided.
2. Related work
In terms of situational awareness, Endsley’s model remains the dominant account of what must be known to act effectively in dynamic work domains, particularly in aviation. The model defines SA as the state of knowledge about the situation, organized into Level 1 (perception of elements), Level 2 (comprehension of their meaning), and Level 3 (projection of their future status). 2 It explicitly distinguishes SA (a state) from decision and action (processes), arguing that SA mediates performance in time-pressured domains such as aviation and air traffic control.
Two major families of SA measures have emerged: probe-based methods, chiefly SAGAT, 7 and self-report instruments, exemplified by SART 8 and SPAM. 9 Probe methods generally better predict performance but are intrusive, whereas self-ratings are lightweight yet noisier. 10 These instruments have also been used as post hoc techniques, exemplified, for example, by the use of SPAM in simulated maritime decision-making. 11
The main differences among these approaches stem from research design trade-offs: SAGAT can be intrusive because it requires task interruption, while self-report and post hoc measures (such as SART or SPAM) avoid disruption at the cost of higher variance.10,12 Further work has extended SA to the group level (Team SA) and to automated proxies (e.g. gaze-tracking or task-state estimation approaches), continuing a long-running debate about how to best quantitatively measure SA.13,14
The proposed HIT score acts as a novel post hoc metric—one especially suited to cybernetic systems, whether human or artificial. Because HIT relies on observable or inferable environmental entropy and employs temporal windowing for stable estimation, it is particularly applicable in simulation environments or after-action analysis. Moreover, in relation to Team SA, HIT’s networked extension yields insight into collective decision-making efficiency by attributing information leverage to adjacency structure. In sum, HIT provides an information-theoretic, nonintrusive proxy for situational awareness, most convenient in computerized settings rich in contextual data. As a potential proxy, it might complement other SA metrics with suitable operationalization—an important subject for future studies.
In parallel, Boyd’s OODA—a model concerning processes, not states—is treated more in doctrine and practice than in academia. The crux of OODA is in the feedback loop of Observe–Orient–Decide–Act, where the orientation phase is considered central to agents’ world-model building. 1 OODA is primarily a military scientific concept, but there is a scholarly line that places Boyd’s model inside cybernetics and control. 15 One notable example relevant for HIT is a C2-centric dynamic OODA model with delays and feedback proposed by Brehmer. 16 While not strictly related to OODA, recent relevant efforts to quantify decision tempo and quality with explicit information-theoretic 17 or network models 18 have been undertaken. On another note, Boyd and Endsley’s models have been abridged in information warfare (IW) literature, where a loose mapping between OODA phases and SA levels has been identified. 19
HIT relates to OODA in three principal ways. First, the HIT score’s context–action–latency triplets aptly map to OODA’s core concepts: where OODA is an indefinitely continuing feedback loop, HIT is a measure of ongoing entropy compression and timely reaction. The proposed HIT score thus operationalizes OODA’s phases and accounts for the latency (or cost function) inherent to dynamic decision-making. Second, HIT’s components also align to SA levels, thus supporting the view that OODA and SA can be bridged. Finally, and arguably most importantly, HIT provides a post hoc information-theoretic proxy for OODA-like decision-making performance in high-information contexts, like simulations.
Algorithmic Information Theory (AIT) is a classic proposal for a metric of agency. Solomonoff’s inductive inference and Hutter’s AIXI agent define optimal prediction via Kolmogorov complexity and algorithmic probability.5,20 While elegant in principle, these notions are in general uncomputable. 21 HIT retains AIT’s spirit of compression but replaces Kolmogorov complexity with Shannon estimators that require only observable or inferable modes. In a vein similar to AIT, Tononi’s Integrated Information Theory (IIT) gauges consciousness via the irreducible cause–effect power of a network.22,23 Tononi’s metrics are also notoriously hard to compute for anything beyond trivial networks.24,25 In contrast, HIT trades philosophical ambition for computational tractability.
The free-energy principle (FEP) as described by Friston models biological agents as Bayesian filters that minimize variational free energy—an information-theoretic upper bound on surprise.4,26 HIT mirrors the entropy-reduction motif yet abandons the need to specify the agent’s internal generative model, making it potentially applicable when internals are opaque (e.g., proprietary black-box AI). In the realm of behavioral benchmarks, general game-playing and reinforcement-learning (RL) benchmark suites excel at measuring achieved performance. They, however, generally remain silent on how efficiently agents process their inputs.27,28 HIT could diagnose two agents with identical scores but divergent information economies by contrasting
Finally, purely quantitative network-centrality metrics—like degree, betweenness, and eigenvector centralities—capture solely structural importance.29,30 They overlook semantic relevance and cost. 31 The HIT score supplies a complementary functional centrality rooted in information flow. In addition, HIT enables exploitation of traditional graph-theoretic metrics in its networked extension. Therefore, the analysis of multiagent environments can employ both current quantitative network metrics and the proposed information-theoretic HIT score.
3. Theoretical foundation
3.1. Single-agent formulation
Consider a single adaptive agent operating in a stochastic environment. Let
Only access to observable triplets
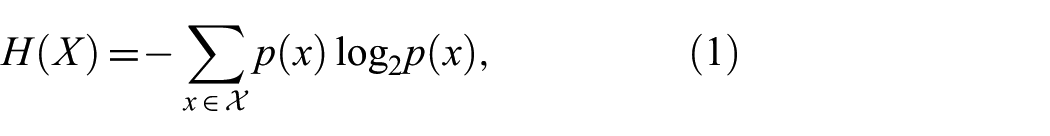
which, in bits, quantifies the uncertainty or variety in the situations the agent encounters.
33
Larger
Next,
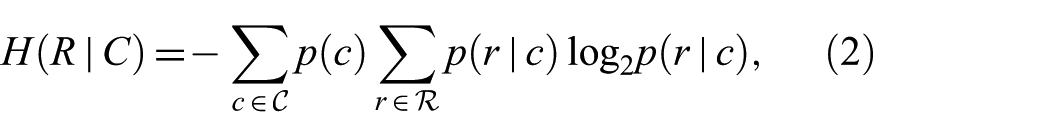
the expected residual uncertainty in the response once the context is known. The mutual information between context and response is then 32

which measures the expected reduction in uncertainty about
If actions are perfectly tailored to context (e.g., a unique action for each relevant context state),
Finally, the
To combine these elements into a single efficiency index, they need to be normalized to comparable scales. Normalized entropy, mutual information and time cost are here denoted as
Moreover, the time cost
The
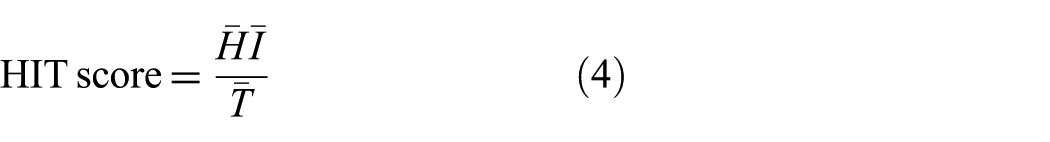
where
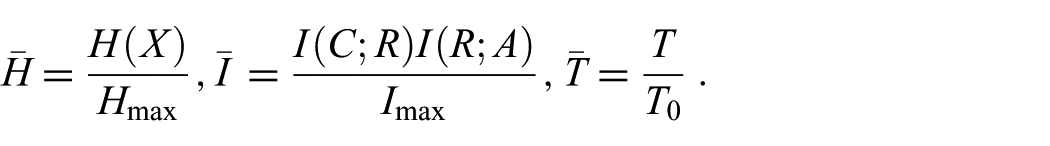
In essence,
Intuitively:
More potential variety (
More compression (
Less delay (
3.1.1. Rudimentary edge-case sanity checks
Deterministic environment: If
A high HIT score therefore requires jointly high environmental entropy
It is worth noting that the HIT score reflects efficiency rather than raw performance. For example, an agent dealing with a very low-entropy environment might solve its task easily, but
The metric therefore captures the balance emphasized by Ashby’s 34 law of requisite variety: to effectively control (or adapt to) a complex environment, an agent’s internal variety, as evidenced by its range of responses, must match the variety of the environment. The HIT score quantifies this match and adds the requirement of doing so efficiently in time. These limit properties ensure that the HIT score behaves monotonically with respect to each component: it increases with greater contextual information and environmental entropy, and decreases with increasing latency.
3.1.2. Relation to OODA and SA
The HIT score can be interpreted in terms of the OODA loop phases. High
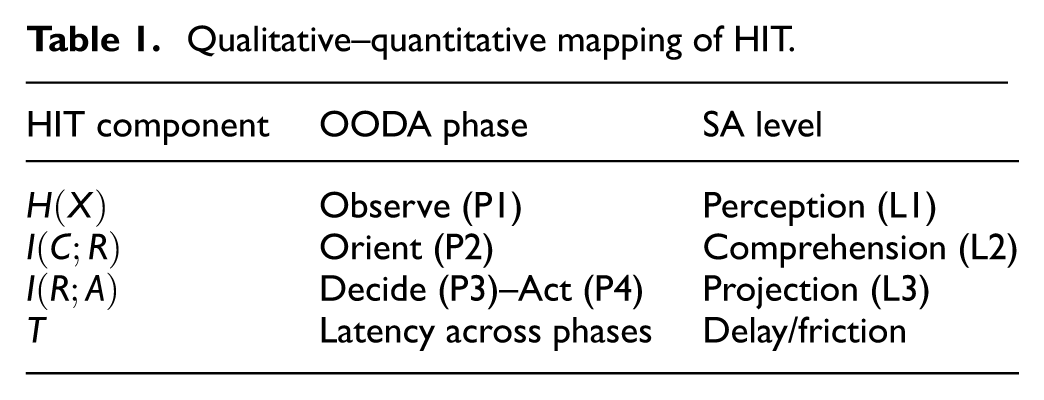
The HIT components are mapped onto OODA and SA constructs in Table 1. In brief, entropy relates to Observe (OODA phase 1/Perception (SA Level 1), mutual information to Orient (OODA phase 2)/Comprehension (SA Level 2), and policy consistency to Decide–Act (OODA phases 3 and 4)/Projection (SA Level 3).
Qualitative–quantitative mapping of HIT.
3.2. Networked extension
Many real-world systems consist of multiple interacting agents or components (e.g., teams of humans, human-machine interaction, distributed sensors, or swarms of autonomous drones). The HIT score is extended to such networked settings by accounting for information flow between agents.
Consider a network of
A leverage ratio for agent

When
For each agent

where
This extension aligns with intuitive C2 notions of force-multiplying agents or nodes that improve the whole network’s performance. A command node that quickly disseminates useful information to peers would achieve
3.3. Sensitivity analysis
Quantitative indices that combine several stochastic components, such as the proposed HIT score, require systematic examination of their numerical stability and interpretability under controlled variation of inputs. Sensitivity analysis serves this role by identifying how changes in model parameters influence outputs, thus revealing both robustness and latent fragility.35,36 In decision and control research, such analyses are a common prerequisite for establishing construct validity and operational reliability.37,38 For HIT, the purpose is twofold: first, to confirm that the metric behaves monotonically and proportionally with respect to its theoretical components—entropy
Given HIT’s formulation (Equation (4)), its stability depends on how each normalized component reacts to realistic variations in context diversity, policy reliability, and decision timing. Sensitivity analysis provides an empirical complement to the theoretical edge-case checks presented in Section 3.1. It also supports reproducibility and transparency: by reporting explicit parameter effects, researchers applying HIT to new domains (e.g., C2 experiments, adaptive autonomy, or simulated decision loops) can anticipate potential distortions arising from sparse or noisy data.
A sensitivity analysis of the HIT score was conducted, which synthesizes artificial context–response–latency triplets. The reproducible Python code—made available on GitHub 39 —computes the HIT score under controlled parameter sweeps, emulating the key variables that shape adaptive decision-making: environmental variety, response fidelity, and temporal cost. The objective was to examine numerical stability, locate potential fragility points, and provide guidance for practical use. The analysis examined the influence of (1) context and response space cardinality, (2) context distribution skew, (3) policy stochasticity, (4) latency variation, (5) sample size, and (6) network asymmetry on HIT and its normalized extensions. Together, these experiments establish the empirical boundaries within which HIT maintains its intended meaning as a tractable, information-theoretic efficiency measure.
Per Equation (4),
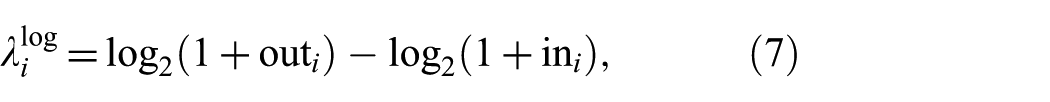
is used to prevent runaway scaling in asymmetric networks. When
Synthetic data were generated for parameter sweeps using
Context cardinality
Response cardinality
Context distribution: uniform, or Zipf-like with exponent
Policy accuracy
Latency mode: fixed, jittered (
3.3.1. Context space (
)
HIT remained effectively stable (<5% variance) across
3.3.2. Response space (
)
The empirical results show HIT to be approximately stable or mildly increasing with larger response alphabets. When
3.3.3. Context distribution skew
Switching from a uniform to a Zipf(
3.3.4. Policy noise/accuracy
HIT declines sharply and near-linearly with reduced policy accuracy. A 20% reduction in correctness (from 1.0 to 0.8) lowered mean HIT by about 45%, while a 40% reduction (1.0 to 0.6) reduced it by roughly 70%. This confirms that HIT is a faithful proxy for adaptive fidelity and discriminates stochastic or inattentive policies without parameter tuning.
3.3.5. Latency noise
Three latency modes were tested: fixed (
3.3.6. Sample size
For
3.3.7. Network asymmetry
The logarithmic leverage factor
The sensitivity risks and guidelines are summarized in Table 2. In summary, HIT remains interpretable, stable, and responsive under a wide range of conditions, particularly when paired with proper normalization and component reporting. These sensitivities should be considered when applying the HIT score in real-world environments.
Empirical sensitivity summary for HIT, as derived from the reproducible parameter sweep.

3.4. Petri nets as a HIT substrate
While the HIT score is by design substrate-agnostic, its interpretability and structural fidelity are highly dependent on the modeling framework used to represent system behavior. In this context, Petri nets (PNs) emerge as a particularly well-suited computational substrate for HIT. A PN consists of a finite set of places
As a computational substrate, PNs may potentially surpass traditional tools such as process mining, causal inference, or partial information decomposition (PID), 42 especially in tactical and cyber-physical environments. PNs model system dynamics as state-transition systems, driven by token flow across places and transitions. This structure inherently preserves causal ordering. Transitions cannot fire without required tokens—thus causality is enforced by construction. Furthermore, tokens are not implicitly duplicated or erased, ensuring data provenance and conservation. Finally, multiple transitions can compete or synchronize on shared places, capturing complex control logic and concurrency. In contrast, methods such as PID 41 or Granger causality 43 require statistical estimation of directed dependencies, which may become error-prone in sparse or highly dynamic systems.
The context–action–latency triplet needed for HIT could in simulations be directly and unambiguously extracted from PN firings, and no inference step is required. There are many ways by which latency could be encoded in PNs: structurally (the number of transitions fired from context observation to action), temporally (using timed or stochastic transitions), or compositionally (e.g., via intermediate decision places and fusion transitions). This allows HIT to faithfully reflect both tactical latency, like short reaction loops, and higher echelon latency, such as multiagent fusion cycles, while retaining traceability of delay sources. PNs also provide semantic anchoring—HIT’s denominator thus becomes more than a clock difference, and is structurally meaningful.
In addition, PNs have many compelling features for multiagent compositions. For example, each agent or subsystem can be modeled as a subnet, where interagent interactions are defined via shared places or message-passing arcs. Shared resources (e.g. bandwidth, tokens, and decision rights) can also be modeled explicitly. This supports granular measurement of HIT at multiple scales:
In summary, PNs potentially enable micro-, meso- and macro-level evaluation of information processing efficiency using HIT.
Tokens in PNs are inspectable, and transitions are observable. It follows that traditional PN metrics can be interpreted in relation to HIT: dead (unfired) transitions signal unused policy modes, overused arcs signal bottlenecks or load imbalance, and token traces reveal decision flow under specific contexts. Combined with HIT computation, this enables diagnosis of:
Why a node’s HIT is low—poor context diversity, low MI, or latency inflation,
Where in the system flow information is lost or delayed, and
How to restructure the decision loop for improvement.
Compared, for example, to the aforementioned PID, which attempts to quantify shared and unique information retrospectively, PNs do not require probabilistic modeling of latent variables. PNs also provide explicit, visual, and stateful representations of decision logic, and support simulation, verification, and replay—not just estimation. In terms of mathematical formulation, can adjacency matrices (as discussed in Section 3.2) be used as a basis for PN formulation. Therefore, the graph theoretic extensions of HIT elegantly provide means by which PN-based formalisms could be used. This avenue is computationally tractable, provided that the information flow in the system can be modeled meaningfully to derive the HIT score, or a perfect information ground state is available, as is the case in simulations. It is worth mentioning, however, that HIT and PNs do not compete with PID (or any other metric) but preempt it—they offer potentially similar insight with potentially greater transparency and lower inferential cost.
A summary of the discussion concerning PNs and HIT is presented in Table 3. PNs potentially offer a powerful, interpretable, and simulation-friendly substrate for computing and analyzing HIT in complex and distributed decision-making systems.
How PNs complement HIT.

4. Empirical evaluation
4.1. Seven-agent Iterated Prisoner’s Dilemma
To evaluate the practical behavior of the HIT score, a canonical environment from game theory was implemented: the IPD. 44 This testbed allows controlled comparison of strategic policies under uncertainty, repeated interaction, and incomplete knowledge. It is widely used to study adaptive and cooperative dynamics, and serves here as an ideal benchmark to investigate HIT in action. The IPD discussed here substantiates the single-agent formulation of HIT presented in Section 3.1.
A closed seven-agent tournament was constructed, where each agent plays a bilateral IPD with every other agent for
The simulation implements seven canonical strategies, selected to span different degrees of responsiveness, context sensitivity, and internal logic within the IPD framework:6,45
All strategies except Rand are deterministic. WSLS-R and WSLS-P differ in their conditioning variable: the former reacts to the symbolic match between moves, while the latter uses the payoff ordering
The 7-IPD results are presented in Table 4. It is evident that responsiveness drives HIT. TFT and both WSLS variants achieve the highest HIT scores by reliably mapping opponent behavior into predictable, context-sensitive responses. Their mutual information matches their observed entropy. It is also found that unconditional strategies are blind—as intuitively expected. All-C, All-D, and GT exhibit nonzero entropy due to diverse inputs, but respond identically regardless of context. Consequently, in these strategies,
Average normalized entropy (
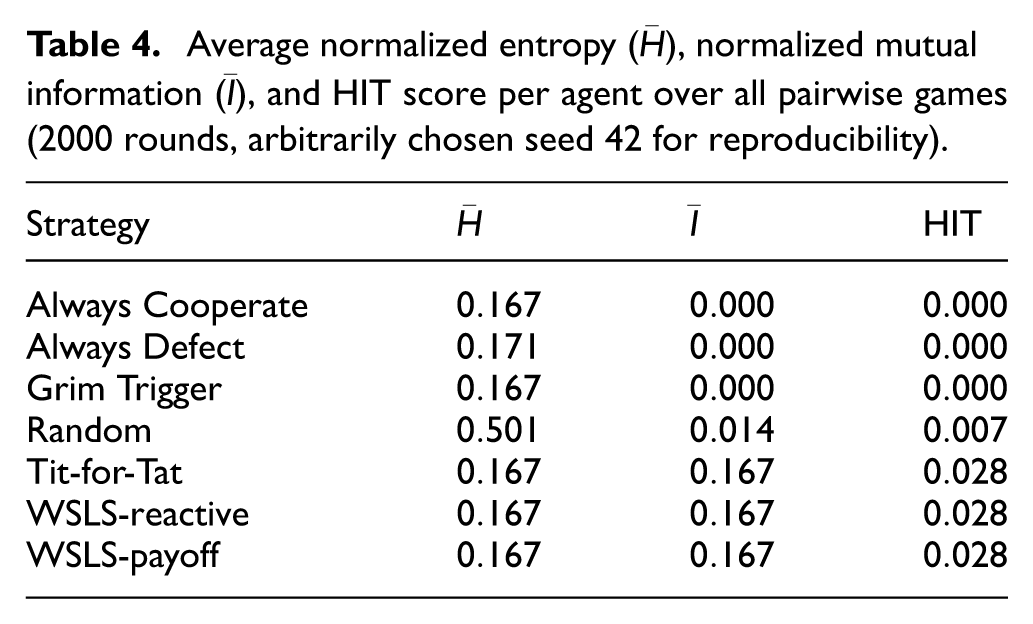
Despite differing logic, TFT and both WSLS variants achieve identical HIT scores. This illustrates a key property: the HIT score measures functional behavior, not internal code. If two strategies compress environmental entropy equally well into responses, they are equally “intelligent”—or more precisely, equally informed—under HIT.
The 7-IPD illustrates HIT’s ability to separate information-aware behavior from naïve or context-insensitive action. It further confirms HIT’s alignment with cybernetic and OODA principles: agents must both perceive variation and act on it in a timely, relevant manner. The fact that distinct policies converge to the same HIT when they exploit entropy identically suggests the metric is consistent, robust, and reflective of behavioral capacity rather than implementation detail.
4.2. Air policing toy models
To evaluate HIT in operationally flavored decision-making scenarios, two toy models inspired by air policing activities were designed. These simulations aim to illustrate HIT’s responsiveness to uncertainty, contextual reasoning, and delay under quasi-realistic constraints such as noise, adversarial spoofing, and network communication factors. The purpose of these simulations is to illustrate both the single-agent HIT and its networked extensions presented in Sections 3.1 and 3.2, respectively.
4.2.1. Single-agent air policing simulation
In the single-agent model, a rule-based autonomous agent interacts with sequential incoming air contacts. For each contact, the agent selects among graded actions based on noisy sensor features. The reproducible Python implementation is provided on GitHub. 39
Each contact possesses a hidden ground-truth identity
The agent updates a belief vector over
Ignore: minimal cost, permissible only if the contact appears clearly friendly.
Interrogate: incurs low cost but no engagement.
Intervene: a limited-action response appropriate to ambiguous situations.
Intercept: a full-force response intended for confirmed threats.
Each action incurs a cumulative cost determined by the contact’s apparent identity, its geographic context (own, international, or foreign airspace), and a Rules of Engagement (ROE) risk weighting, approximating the decision logic described in standing NATO air policing policies.
49
The agent continues probing until (1) the most probable class exceeds a confidence threshold of
The HIT score is computed via Equation (4), with
4.2.2. Results
Running the simulation on
Final classification accuracy is
4.2.3. Interpretation
These results reflect the expected limitations of a noisy, low-resolution sensor environment. The ground-truth entropy
In this simulation, realism was not an objective, but future work could examine how richer sensors, ensemble classifiers, or causal estimators influence
4.2.4. Multiagent air policing
In a multiagent air policing variant, four homogeneous agents observe the same stream of contacts but exchange their probabilistic belief vectors over intraflight communication links. Such shared-belief architectures are central to Network-Centric Warfare (NCW) concept and the broader notion of networked situational awareness.19,50 The Python implementation is available on GitHub. 39 Two network topologies are compared: a unidirectional ring—each node forwards its belief to its clockwise neighbor with a one-step delay—and a fully connected mesh, where all nodes broadcast to all peers each step with the same latency. This structure echoes Moffat’s 51 models of how network connectivity shapes information diffusion and decision quality.
At time
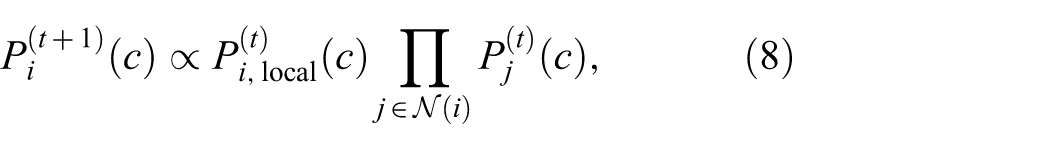
followed by normalization over all classes
A more conservative alternative is innovation (likelihood-increment) fusion: agents exchange only the new likelihood contribution since the previous step rather than full posteriors, or employ correlation-robust pooling (e.g. Kullback–Leibler average consensus or covariance intersection) to avoid double-counting.54,55 While such schemes prevent evidence reuse, they also converge more slowly in homogeneous networks. In the scope of this paper, for demonstration purposes, the simpler multiplicative form is retained to highlight the topological contrast captured by the HIT score.
Node-wise HIT is computed from each agent’s local observation, decision, and cost streams. The mean and standard deviation
Topology impact on normalized mean node metrics (

The multiagent simulation yields insightful interpretations related to previous discussions on degraded mutual information and distributed latency effects.51,56 In the ring topology, effective mutual information collapses to
Interpreted through OODA and SA, the mesh topology exemplifies the benefit of rapid, shared orientation, while the ring topology demonstrates how limited bandwidth throttles contextual coupling and drives down efficiency. Mesh architectures achieve higher HIT scores because they accelerate entropy reduction and lower decision cost—an effect generalizable to systems where contextual information must traverse multiple hops to reach all decision-makers.
The observed behavior aligns with NCW analyses that link robust networking to superlinear gains in situational awareness and operational tempo by expediting information flow and fusion.50,51,56 Formally, these gains manifest as faster entropy reduction across the force: connectivity compresses dispersed uncertainty into a shared operational picture. Conversely, degraded coupling in the ring topology recreates the friction described by Watts, reminding that bandwidth and topology bound the achievable rate of entropy reduction.33,57 Within this framing, the HIT score quantitatively expresses how efficiently a network converts distributed observations into coordinated, low-entropy action. HIT does not prescribe engagement decisions but diagnoses, post hoc, how well information was compressed into timely action.
4.3. PN of a five-agent C2 system
To empirically validate the HIT score using PNs within a realistic, interpretable, and structured decision environment, a simulation of a five-agent command and control (C2) system was implemented. This simulation substantiates utilizing PNs as discussed in Section 3.4. The scenario captures the adaptive and hierarchical nature of tactical decision-making under routine operational tempo. The simulation highlights how the HIT score can reveal role-dependent efficiency and information dynamics in a distributed multiagent system, with results grounded in quantifiable, observable system structure. Reproducible Python code is available on GitHub. 39
The modeled C2 system includes five agents organized in a classic military-style hierarchy. Alpha serves as the top-level command node. It does not perceive the environment directly, but synthesizes reports from subordinate agents and issues commands to all nodes in the system. Bravo and Charlie act as mid-tier echelons: both perceive their environment with some noise, fuse their own observations with upstream reports, and issue commands to one subordinate each. Delta and Echo are field agents with direct environmental access. They act immediately based on local context and receive commands from their respective mid-tier controllers.
The simulated environment produces one of three possible context states—calm, suspicious, or hostile—according to a discrete distribution, where calm occurs with probability
Latency is structurally embedded in the PN model: field agents act with a latency of one transition step, mid-tier nodes act with two steps (one for fusion and one for action), and Alpha acts with three steps, accounting for the additional fusion layer. Transitions are triggered by token firings, preserving the causal dependencies between observations and actions. The simulation runs for
PNs offer several compelling advantages in this setting—many of which were discussed in Section 3.4. First, they preserve causal structure by design. Transitions do not fire unless all required tokens are present, ensuring that actions are conditionally dependent on prior states and inputs. Second, latency is not inferred or timestamped, but instead emerges naturally from the transition structure. Each hop in the network introduces a delay by design, allowing HIT to reflect timing in semantically grounded ways. Third, PNs allow modular representation of each agent as a subnet, facilitating both localized HIT analysis and compositional modeling. Finally, PNs are replayable, inspectable, and support debugging and visualization—features particularly valuable when diagnosing performance anomalies or validating real-time decision systems. In sum, PN implementations are ripe for simulation implementations where ground truth and other HIT components are readily accessible.
Table 6 presents the HIT scores and associated metrics for each agent. HIT is calculated as the product of normalized entropy and mutual information, divided by normalized latency. To account for each agent’s role in the larger system, the network leverage terms are also computed using the log-scaled difference in upstream and downstream flow. These are denoted as
HIT results for the five-agent C2 PN simulation.
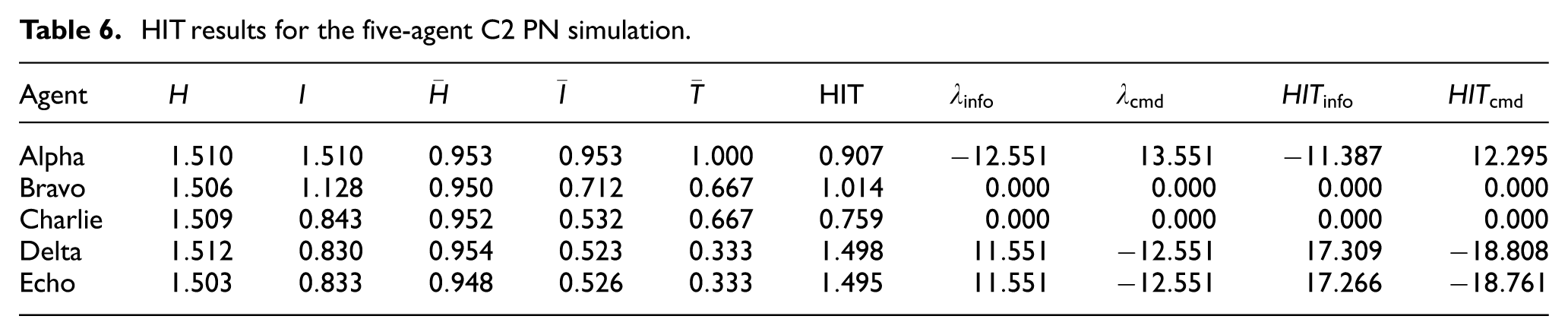
The results show a distinct stratification by role. Alpha demonstrates high internal HIT, with a score of
In contrast, Delta and Echo achieve the highest HIT scores at
In summary, the five-agent PN simulation illustrates that HIT, when paired with a structured substrate like a PN, offers a powerful diagnostic lens on distributed command and control. It captures both local efficiency and systemic contribution, enables comparative benchmarking across agents, and supports operational inference without requiring intrusive data collection (e.g. using network logs)—though these claims are only relevant in the context of the current simulation, and require further justification in real-life contexts. Still, the practical relevance of this simulation extends beyond abstract validation. Real-world systems such as air policing operations, C2-networks, distributed ISR cells, or autonomous swarm controllers could adopt a similar modeling approach. Constructing a PN from standard operating procedures, message routing logs, and mission trace data is feasible and non-intrusive—especially within simulations. The required information kernels include timestamped event logs, coarse context and action labels (e.g. procedural outcomes, mission state tags), and minimal routing metadata to approximate message flow. Crucially, the approach does not require deep packet inspection or intrusive instrumentation. HIT scores could be computed post hoc from existing audit trails or operational exercise logs, enabling quantitative assessment of decision efficiency at both the agent and system level.
5. Discussion
The proposed HIT score encompasses apparent limitations and caveats. A reliable MI estimation demands sufficient data, and so it is by necessity constrained by sample complexity. It may be practically achievable in simulation environments, in which ground truth is accessible. Moreover, all results in this paper treat
It is important to note that HIT, as formulated here, does not in itself imply directional causality. Mutual information (MI) is symmetric by definition:
An approach of using PNs as a substrate for HIT in modeling networked systems was proposed in Section 3.4 and demonstrated in Section 4.3. PNs offered structural clarity and composability for representing multiagent decision systems. Unlike statistical or machine-learned models, PNs embed latency and causality directly into their transition architecture. This allowed each token to represent a contextual update or decision trigger, flowing through well-defined transitions that respect policy logic, synchronization points, and concurrency structures.
In the simulated five-agent C2 system, the PN model enabled precise control over latency paths, fusion behavior, and interagent coordination. The use of modular subnets per agent allowed for clean separation of responsibilities and straightforward attribution of HIT and leverage values. This architectural alignment provided meaningful metrics that surfaced both internal efficiency (via HIT) and systemic contribution (via
Overall, the HIT score furnishes a computable, interpretable, and substrate-neutral measure of efficiency grounded in classic information theory. By uniting capacity, compression, and cost, it advances Ashby’s
34
cybernetic program and offers a diagnostic complementary to reward curves. HIT also appears to be an attractive quantitative OODA proxy. Across the empirical studies, drops in
Future work includes the following:
Extending HIT estimation to continuous observation and action spaces using nonparametric entropy estimators, such as
Formal exploration of PNs as a HIT substrate under various network topologies,
Incorporating energy costs for hardware and computational solutions,
Deploying HIT in real-world environments (C2, UAVs, sensor nets)—simulated or otherwise—to monitor emergent coordination, and
Testing HIT as a predictor of out-of-distribution robustness in deep reinforcement learning, thus extending the work by Sedlmeier et al. 61
6. Conclusion
The proposed HIT score was demonstrated to be a feasible quantitative proxy to qualitative canonical decision-making measures, namely OODA and SA. The sensitivity analysis and controlled simulations confirm that HIT quantifies the efficiency of information-driven decision loops in C2-like settings, especially within simulated environments where unambiguous ground truth is available. It neither guarantees correctness nor dictates doctrine, but it offers a transparent gauge of whether entropy is being compressed into action at a justifiable cost.
Incorporating PNs as a modeling substrate further strengthened HIT’s utility. The PN-based simulation of a five-agent command structure illustrated how HIT can expose both internal efficiency and systemic influence across roles. Simulation outcomes of PN-enabled HIT scores as OODA and SA proxies would be challenging to disentangle using traditional statistical metrics or unstructured simulations.
It is stressed that HIT is a quantitative diagnostic of informational efficiency not a normative framework for action selection. It does not override tactical judgment, rules of engagement, or higher-order mission objectives. As with all abstract metrics, its role could be to support, not supplant, decision-making in complex environments.
Future work should further couple HIT scores with temporal and causal metrics to capture richer aspects of OODA recursion, team cognition, and Team SA, as Boyd and Endsley intended in their seminal works. Nonintrusive real-world applications might yield further fruitful lines of inquiry in researching HIT.
Footnotes
Acknowledgements
The author wishes to thank several colleagues for their encouragement and insightful discussions. While most prefer to remain anonymous, special thanks go to Riitta Penttinen, Ph.D., Matti Puranen, Ph.D., and Kimmo Halunen, Ph.D. for their generous support throughout these unconventional endeavors.
Author Note
During the preparation of this work, the author used OpenAI’s language models in order to prepare parts of the simulation Python code. After using this service, the author reviewed and edited the content as needed, and takes full responsibility for the content of the published work.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.