
Abstract
Integrating Capability-based Hierarchical Embedded RISC Instructions (CHERI) with the Artificial Intelligence (AI) Bill of Materials (AI BOMs) aims to enhance security and transparency in generative AI systems. With the increasing prevalence of AI and machine learning (ML), greater transparency and traceability are essential. This study introduces an analysis to explore how CHERI’s advanced security features can improve the reliability and transparency of AI BOMs, significantly contributing to the overall security of AI and ML technologies. The research employs a multi-faceted approach, combining theoretical analysis with practical evaluations. It begins with a comprehensive review of the existing literature on AI BOMs and CHERI, followed by an in-depth examination of cybersecurity threats, exploits, and vulnerabilities in new Software Bills of Materials (SBOMs). The study leverages AI methodologies, including data analysis techniques and AI-driven simulations, to assess the impact of integrating CHERI’s security features into AI BOMs. The study analyzes how CHERI and AI BOMs can enhance AI system security. The objectives include evaluating the role of AI BOMs in ensuring trust and quality in AI systems, assessing the efficacy of CHERI’s security features in mitigating cybersecurity threats, and identifying and analyzing cybersecurity threats, exploits, and vulnerabilities in SBOMs using AI techniques. The findings demonstrate that integrating CHERI with AI BOMs significantly enhances the security and transparency of AI systems. This integration helps identify and mitigate specific threats and vulnerabilities, improves trust and security in AI systems, and shows the potential of AI-driven methodologies in enhancing the security of SBOMs. By combining CHERI with AI BOMs, a promising pathway is established for creating more secure and transparent AI systems, addressing current cybersecurity challenges, and paving the way for future advancements in AI and ML technologies.
Keywords
1. Introduction to artificial intelligence bill of materials and Capability-based Hierarchical Embedded RISC Instruction
The rapid advancement and integration of artificial intelligence (AI) 1 and machine learning (ML) technologies across various industries have brought about a significant shift in our interaction with digital systems. However, this widespread adoption has also raised important questions about their safety, ethics, and transparency. Addressing these concerns has become crucial for researchers, developers, and policymakers.
The concept of Artificial Intelligence Bill of Materials (AI BOMs) has emerged as a critical tool for tackling these challenges. These comprehensive records document every aspect of AI systems, including model specifications, architectural design, usage patterns, training data, and ethical considerations. The development of AI BOMs, inspired by AI Model Cards and initiatives by organizations such as Manifest and the Linux Foundation, aims to promote greater clarity and accountability in AI system development.
1.1. Understanding Capability-based Hierarchical Embedded RISC Instructions: fortifying security in AI implementations
The Capability-based Hierarchical Embedded RISC Instructions (CHERI) are a new facet in AI system security that provides robust solutions to address memory safety challenges inherent in conventional programming languages. CHERI’s architectural novelties offer essential security attributes crucial in AI system development. Handling extensive data sets and intricate computations necessitates rigorous security protocols.
In this paper, we explore the interrelation between CHERI and AI BOMs, examining how incorporating CHERI’s security attributes can enhance the trustworthiness of AI systems. We will scrutinize various dimensions of this amalgamation.
First, we will elaborate on how the integration of CHERI amplifies memory safety, a fundamental aspect documented in AI BOMs. We will present an in-depth discussion on secure AI model formulation, emphasizing the importance of augmented memory safety in AI models.
Second, we will investigate CHERI’s proficiency in facilitating scalable software compartmentalization congruent with the documentation requisites of AI BOMs, thus guaranteeing isolated and secure AI system segments. We will emphasize the significance of scalable software compartmentalization in AI system development.
Third, we will analyze the incorporation of CHERI’s formal security models into AI BOMs, offering a robust framework for comprehending AI system security, particularly in sections like “Model Architecture” and “Authenticity.” We will highlight the importance of formal security models in AI system development.
Fourth, we will discuss how this integration amplifies the traceability and transparency of AI systems, focusing on detailed information concerning security features at both the hardware and software strata. We will emphasize the importance of traceability and transparency in AI system development.
This paper additionally illuminates the Software Bills of Materials (SBOMs) and their significance in software development, highlighting the imperative of scrutinizing cybersecurity threats within them. The juxtaposition of SBOMs and AI BOMs underscores the inherent characteristics and challenges of documenting AI systems.
This section lays the groundwork for an exhaustive examination of how AI BOMs, augmented by CHERI’s security features, can address the escalating concerns surrounding the security and transparency of AI and ML technologies. CHERI’s security attributes are a pivotal solution to memory safety challenges, software compartmentalization, formal security models, traceability and transparency of AI systems, and overall AI system security.
2. Case studies and applications
This paper showcases real-world examples demonstrating the practical application of CHERI with AI BOMs in various AI systems. These case studies illustrate how the integration improves AI models’ overall security and reliability.
The correlation of CHERI with AI BOMs is a significant step toward achieving trustworthy AI systems. By ensuring the security of memory usage and comprehensive documentation of AI components, this integration paves the way for developing AI technologies that are not only effective but also secure and transparent.
This section provides a detailed exploration of the integration between CHERI and AI BOMs to enhance the trustworthiness and security of AI and ML technologies. To better represent the key concepts and their interrelations, the authors suggest creating a diagram that encapsulates the main themes and connections outlined in this section.
The following is a proposed structure for a diagram that represents the integration of two central themes, “CHERI” and “AI BOMs,” in the context of trustworthy AI systems. The diagram should depict these two themes as interconnected at the core of the diagram.
The first section of the diagram should focus on the Security Enhancements through CHERI. It should illustrate how CHERI’s features, such as enhanced memory protection and software compartmentalization, play a critical role in securing AI systems.
The second section should depict various elements of AI BOMs and their roles in ensuring transparency and traceability in AI systems. This section should include model details, architecture, and ethical considerations.
The third section should showcase the synergy between CHERI and AI BOMs. It should highlight aspects where CHERI’s features enhance AI BOMs, such as memory safety, software compartmentalization, formal security models, and overall system transparency.
The fourth section should include case studies and applications. This section should be represented with examples or mini-cases that showcase the practical application of CHERI in AI BOMs.
Finally, the Conclusion and Forward Path section should summarize the integration benefits and future implications of the integration of CHERI and AI BOMs for trustworthy AI systems. This section should communicate the importance of this integration in ensuring the development of AI systems that are secure, transparent, and trustworthy.
Figure 1 shows a diagram based on this structure, focusing on clarity and educational value.
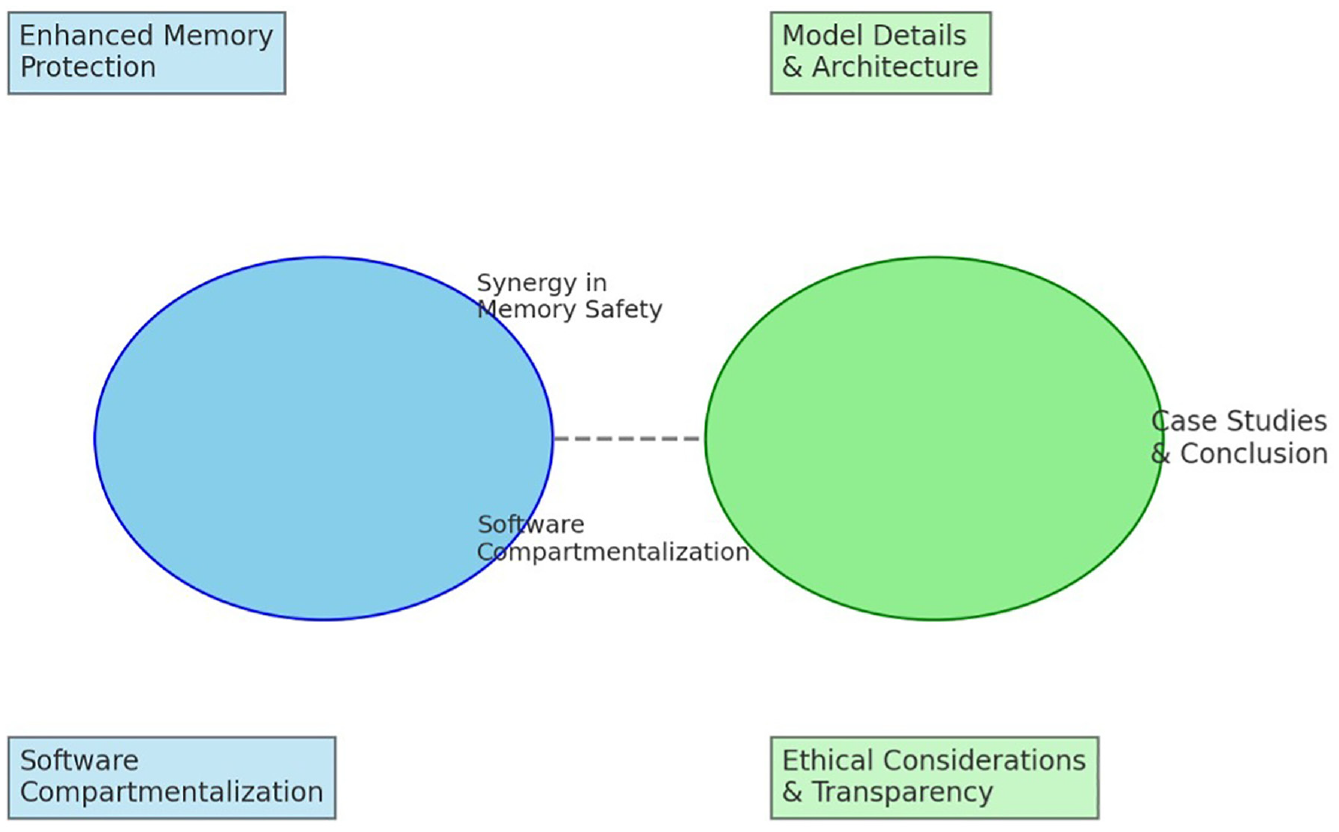
Interrelationships between capability-based hierarchical embedded RISC instructions (CHERI) and artificial intelligence bill of materials (AI BOMs).
The diagram in Figure 1 provides a visual representation of the main themes and interconnections between CHERI and AI BOMs in the context of enhancing the security and trustworthiness of AI systems.
The diagram highlights two central themes: CHERI and AI BOMs, which are presented as interconnected. The elements of enhanced memory protection and software compartmentalization are used to depict the security enhancements through CHERI.
Different components of AI BOMs are also shown, highlighting their roles in ensuring transparency and ethical considerations. The diagram emphasizes the synergistic aspects of CHERI and AI BOMs, mainly how CHERI enhances the memory safety and compartmentalization aspects of AI BOMs.
Although not detailed in the diagram, the case studies and applications section indicate this integration’s practical applications and examples. Finally, the diagram concludes with a nod to the case studies and implications for the future of trustworthy AI systems.
This diagram is intended to help understand the complex interplay between these two paradigms and their impact on AI and ML technologies. Please let me know if you have any specific details or additional aspects you would like to include, and I can adjust the diagram accordingly.
3. Research methodology
3.1. Overview
This section explains the methodology used to examine and compare the efficacy of different security technologies as alternatives to CHERI. The technologies that were analyzed include Intel’s Software Guard Extensions (SGX), AMD’s Secure Encrypted Virtualization (SEV), Trusted Execution Environments (TEE), and Hypervisors. The methodology was crafted to assess these technologies based on specific criteria, focusing on their robustness in security, suitability for various use cases, and performance efficiency in AI and ML applications.
Figure 2 presents a visual outline of the research methodology applied in this study.
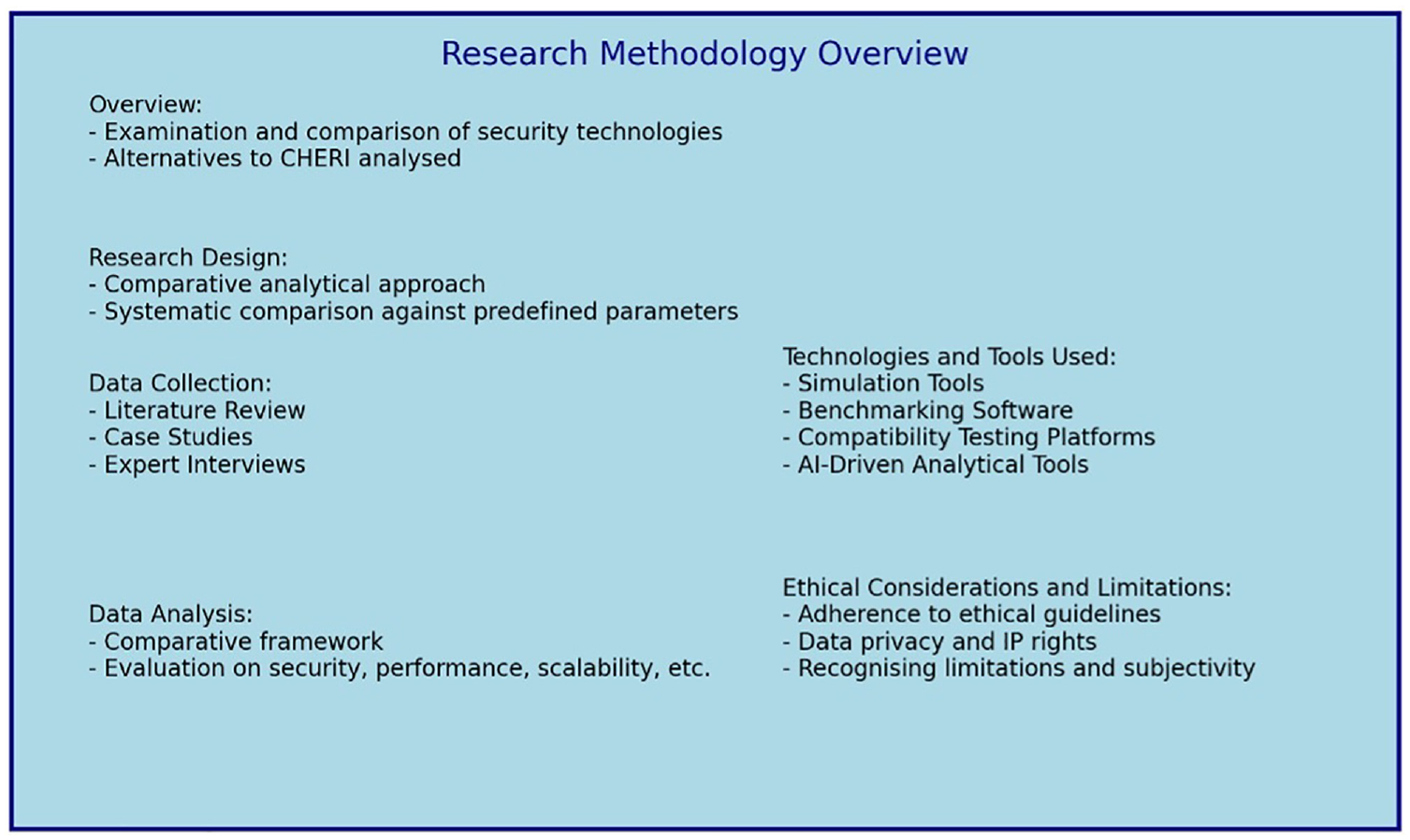
The methodology.
3.2. Research design
The study employed a comparative analytical approach to systematically compare the technologies based on predefined parameters. This approach provided a detailed understanding of each technology’s strengths, limitations, and optimal use cases.
3.2.1. Data collection
The data collection process involved the following methods:
Literature review: The research team conducted an extensive literature review that included academic journals, technical whitepapers, and industry reports. This review helped to gain a comprehensive understanding of each technology’s technical specifications, real-world implementations, and documented use cases.
Case studies: The team selected several cases where the technologies had been implemented to obtain practical insights into their real-world applications and performance. For example, the study examined the application of SGX in financial transaction processing systems to understand its effectiveness in protecting sensitive data.
Expert interviews: The team interviewed industry experts and academicians to gather qualitative data on these technologies’ practical aspects, challenges, and prospects. These insights were crucial in validating the findings from the literature review and case studies.
3.2.2. Data analysis
The data collected from the literature review, case studies, and expert interviews were analyzed using a comparative framework. This framework evaluated each technology based on specific criteria, such as:
Security robustness: The effectiveness of each technology’s inherent security features in preventing various types of cyber threats was evaluated. The analysis included simulated attack scenarios to test each technology’s resilience against cyber threats.
Performance Efficiency: Each technology’s impact on system performance, including processing speed and resource utilization, was assessed. Benchmarking tests were conducted to measure the performance overhead introduced by each technology.
Scalability and Flexibility: Each technology’s adaptability to different scales of operation and diverse computing environments was determined. Case studies provided empirical evidence of scalability in various deployment scenarios.
Hardware dependency: The extent of reliance on specific hardware configurations for each technology was analyzed. Compatibility tests were performed with various hardware setups to assess this dependency.
Suitability for use cases: Optimal use cases for each technology were identified based on their unique characteristics and performance in real-world scenarios. Cross-referencing with industry-specific applications provided a practical perspective on suitability.
In our research on interfacing CHERI with AI BOMs, we adopted a multi-faceted methodology to examine the interrelation between CHERI and AI BOMs and how the incorporation of CHERI’s security attributes can augment the trustworthiness of AI systems. This investigation entailed a comprehensive literature review, where we scrutinized existing scholarly articles, technical documents, and case studies relevant to CHERI and AI BOMs, focusing mainly on their implementation in AI system security. We conducted in-depth qualitative and quantitative analyses, employing methods like content analysis for the literature and statistical evaluation for empirical data. To validate the integration and efficacy of CHERI within AI BOMs, we executed a series of experiments involving simulated AI environments, where we integrated CHERI’s security features and assessed their impact on system robustness, data integrity, and resistance to various cybersecurity threats. These simulations were designed to mirror real-world AI applications, ranging from simple ML models to complex, multi-layered neural networks, ensuring a broad scope of applicability.
In addition, expert interviews with cybersecurity professionals and AI developers provided invaluable insights, enabling us to cross-reference theoretical findings with practical experiences. This was complemented by a comparative analysis, where we juxtaposed the performance and security metrics of AI systems with and without the integration of CHERI. Our methodology also encompassed an assessment of the documentation and transparency enhancements brought by the incorporation of CHERI into AI BOMs, evaluating how these changes affect the traceability and accountability of AI systems from a development and deployment perspective. This comprehensive approach allowed us to holistically understand the potential and limitations of interfacing CHERI with AI BOMs, culminating in a nuanced understanding of how this synergy can significantly elevate the trust and security standards in AI systems.
Figure 3 and the section above summarize the methodology used to compare and analyze alternatives to CHERI, including SGX, SEV, TEE, and Hypervisors and speculate on their potential future developments and ethical considerations. The research adhered to ethical guidelines regarding data privacy and intellectual property rights, using all data collected from interviews and case studies responsibly with consent. The study recognized the potential limitations of rapid technological evolution, subjectivity in findings due to the reliance on available literature and expert opinions, and the need to validate the research through technical methods such as simulated attack scenarios, benchmarking tests, compatibility assessments, and cross-referencing with industry-specific applications. The goal was to comprehensively understand each technology’s capabilities, limitations, and suitability for various AI and ML security applications.
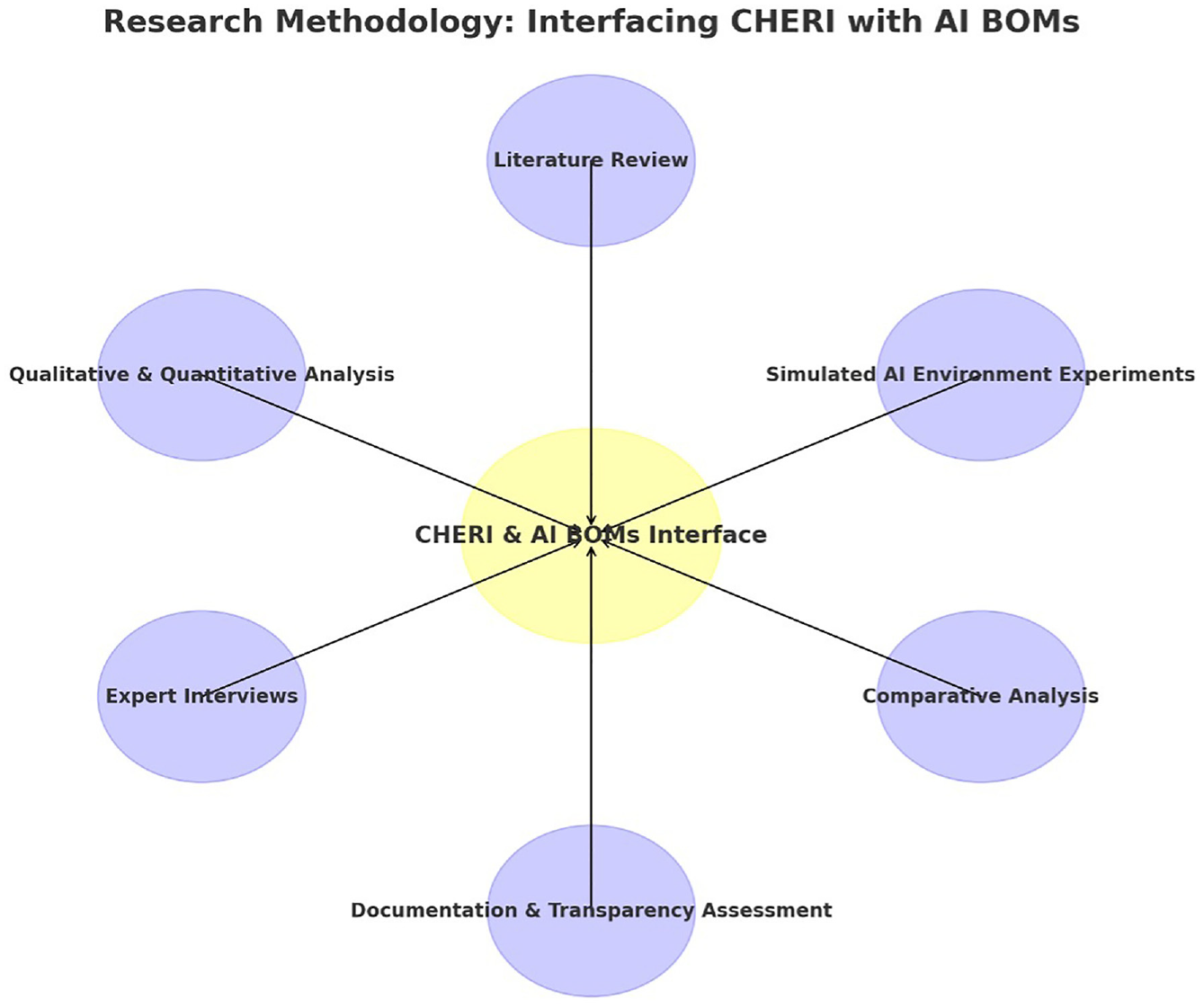
The methodology used in interfacing CHERI with AI BOMs.
4. CHERI
The CHERI project is a significant breakthrough in computer architecture that enhances security by providing fine-grained memory protection and scalable software compartmentalization. It extends conventional hardware Instruction-Set Architectures (ISAs) with new architectural features that target historically memory-unsafe programming languages such as C and C++. These features offer robust, compatible, and efficient protection against widely exploited vulnerabilities.
CHERI is a hybrid capability architecture that blends architectural capabilities with conventional Memory Management Unit (MMU) based architectures, allowing for incremental deployment within existing software ecosystems. The project has developed several key components, including an abstract CHERI protection model introducing architectural capabilities as hardware-supported permissions descriptions. These capabilities can replace integer virtual addresses for referring to data, code, and objects in protected ways.
ISA extensions have been made to 64-bit MIPS, 32-bit RISC-V, 64-bit RISC-V, and, in collaboration with Arm, 64-bit Armv8-A, demonstrating the model’s applicability to various contemporary ISA designs. In addition, a new microarchitecture demonstrates efficient hardware implementation of capabilities, including capability compression and tagged memory. Formal models of these ISA extensions enable mechanized statements and proofs of their security properties, automatic test generation, and construction of executable ISA-level simulators.
The CHERI project also includes language and compiler extensions for implementing memory-safe C and C++, operating system (OS) extensions for fine-grained memory protection, and application-level adaptations for CHERI memory protection and software compartmentalization. The project’s extensive prototyping and co-design have led to widely used open-source software adaptations, including Clang/LLVM, FreeBSD, and FreeRTOS.
A notable development in the CHERI project is its application to ARMv8-A and RISC-V ecosystems. Since 2014, in collaboration with Arm, an experimental integration of CHERI with 64-bit ARMv8-A has been underway. This includes the development of an experimental superscalar CHERI-ARM processor and associated software and hardware components.
Several significant publications have emerged from the CHERI project, focusing on aspects like ISA semantics, C semantics, and pointer provenance, as well as specific applications in embedded devices and memory safety. These papers provide a comprehensive understanding of the depth and breadth of the CHERI architecture and its impact on enhancing cybersecurity.
The CHERI project represents a comprehensive co-design initiative integrating hardware, software, formal semantics, and proof in a novel approach to computer architecture and cybersecurity. By merging these three key components, CHERI provides an innovative solution to enhance security and reliability. The project aims to combine hardware implementation, mainstream software stack adaptation, and formal semantics and proof to develop a revolutionary architecture that addresses various security challenges. CHERI’s approach sets a new precedent in the industry, providing an unparalleled cybersecurity solution.
By leveraging hardware, software, formal semantics, and proof in a co-design approach, CHERI aims to provide high security and reliability. This approach is an exciting development in computer architecture and cybersecurity, and CHERI is at the forefront of this revolution. The CHERI project is a testament to the power of co-design to solve complex problems, and it is a valuable resource for organizations seeking to enhance their cybersecurity posture.
4.1. Alternatives to CHERI
Several alternatives to CHERI have been developed to improve the security of AI and ML systems. Each technology offers unique advantages and is suitable for specific use cases. The following sections will provide an in-depth analysis of these alternatives, including technical examples, descriptive analysis, and conceptual projections on their suitability.
4.1.1. SGX
4.1.1.1. Technical description
Intel’s SGX helps create private memory enclaves inaccessible to other applications and even the OS. This ensures that sensitive data and operations are protected from external threats, including OS-level threats.
4.1.1.2. Use-case example
SGX is used for secure data processing in cloud environments. It can also be used in financial services to process secure transactions, where sensitive data need to be isolated from other processes.
4.1.1.3. Suitability analysis
SGX is particularly effective in environments where the integrity of application execution needs to be shielded from potentially compromised OSs. However, its reliance on specific hardware (Intel CPUs) may limit its applicability across diverse platforms.
4.1.2. AMD’s SEV
4.1.2.1. Technical description
AMD’s SEV technology is similar to SGX and offers encrypted virtualization capabilities. It encrypts virtual machines’ (VM) memory, making it inaccessible to the host or other VMs. SEV-ES and SEV-SNP are advanced iterations providing enhanced security features.
4.1.2.2. Use-case example
SEV is instrumental in cloud computing environments. For instance, SEV-SNP can be used to secure multi-tenant cloud infrastructures, where it is crucial to protect each tenant’s data from others, including the cloud provider.
4.1.2.3. Suitability analysis
SEV is highly suitable for virtualized environments requiring robust isolation between VMs. Its hardware-based encryption provides a strong security layer, but like SGX, it requires specific AMD hardware.
4.1.3. TEE
4.1.3.1. Technical description
TEEs are secure and isolated execution spaces within processors where trusted applications can run. This environment protects the code and data from the primary OS.
4.1.3.2. Use-case example
TEEs are commonly used in mobile devices to secure payment applications and user authentication processes. They are also used in smart TVs to secure streaming content against piracy.
4.1.3.3. Suitability analysis
TEEs are best suited for devices where security needs to be maintained in a resource-constrained environment. However, their effectiveness depends on the TEE’s own security.
4.1.4. Hypervisors
4.1.4.1. Technical description
Hypervisors allow the creation of isolated VMs on a single physical host. These VMs are separated from each other and the host OS, providing a secure execution environment.
4.1.4.2. Use-case example
Hypervisors are used in cloud data centers to isolate different clients’ VMs, ensuring data privacy and security. They are also used in server consolidation to securely run multiple server functions on a single physical machine.
4.1.4.3. Suitability analysis
Hypervisors are ideal for large-scale virtualized environments like data centers and cloud computing. Their ability to isolate VMs makes them suitable for scenarios requiring strong separation of different computing tasks.
To effectively illustrate the technologies of Intel’s SGX, AMD’s SEV, TEE, and Hypervisors, we can create a comparative diagram that shows their similarities and differences. This will help to clarify how each technology contributes to securing applications and data in different computing environments.
The diagram consists of the following elements:
Intel SGX: A computer system with an Intel processor, emphasizing the secure enclaves created within the processor’s memory. It will demonstrate the protection of applications and the OS from other applications.
AMD SEV is an AMD-based system with encrypted virtualization, emphasizing how it isolates and protects VMs.
TEE: A general processor (not specific to Intel or AMD) with a separate, secure area for trusted applications. This paper will show the use of TEE in various devices, such as smartphones and smart TVs.
Hypervisors: A server with multiple VMs, each isolated from others and the underlying OS, typical in cloud computing.
We created the diagram to be informative and easy to understand by focusing on the key features of each technology and their role in enhancing security.
We have designed a layered structure to showcase the operations of various security technologies, such as Intel SGX, AMD SEV, TEE, and hypervisors, at different layers of a computing system. This will help demonstrate how they provide security at different levels, ranging from the processor to the OS and virtualization layers.
The diagram includes the following layers:
Processor level: This layer will highlight Intel SGX and TEE and demonstrate how they provide security within the processor.
OS level: This layer indicates how TEEs can operate at this level, creating a secure environment within the OS.
Virtualization level: This layer focuses on AMD SEV and hypervisors, highlighting their roles in securing VMs and ensuring their isolation from each other and the underlying system.
This layered approach visualizes how each technology fits within the broader computing architecture. Let us create this diagram.
The diagram offers a layered perspective of the security technologies used in computing systems. The first layer, processor level (Sky Blue), emphasizes the roles of Intel SGX and TEE in securing application code and data. Intel SGX creates secure enclaves within the Intel processor, while TEEs provide a safe area for trusted applications. The second layer, OS level (Light Green), highlights the role of TEEs in creating a secure environment for sensitive operations within the OS, enhancing overall security against threats that may compromise it. The third layer, virtualization level (Salmon), focuses on AMD’s SEV and hypervisors, which work together to provide encryption and isolation for VMs in AMD-based systems, particularly in cloud computing environments.
This structure offers a well-defined understanding of how each technology operates at different levels within a computing system, contributing to the overall security architecture.
The diagram presented in Figure 4 provides a comparative overview of four key security technologies. These technologies are designed to secure computing environments across various platforms and applications.

Security technologies in computing systems.
The first technology represented is Intel SGX. This technology focuses on the secure enclaves within the Intel processor’s memory. These enclaves protect specific application codes and data from external access, including other applications and the OS.
The second technology is AMD SEV, AMD’s SEV technology. SEV enhances security by isolating and encrypting VMs, thereby protecting against various threats, including those from the host system.
The third technology is a TEE. This segment shows a general processor equipped with a TEE, a secure area used to run trusted applications. TEEs are versatile in various devices, from mobile phones to smart TVs and cars, offering a safe environment for sensitive operations.
Finally, the diagram depicts the use of hypervisors in creating isolated VMs on a single server. Hypervisors are particularly significant in cloud computing, providing critical isolation and security for virtual environments on shared physical hardware.
The visual representation in Figure 4 aims to clarify the distinct but complementary roles these technologies play in securing computing environments across various platforms and applications. We have created a flowchart-style illustration to provide a detailed and informative diagram. This will show you how Intel SGX, AMD SEV, TEE, and Hypervisors interact and work together in a computing environment to ensure the security of data and applications.
The diagram depicts the different stages of security from processor level to virtualization and OS security. It includes the following:
Data/application entry: This indicates where data or applications enter the system.
Processor-level security: This highlights how Intel SGX and TEEs provide security at the processor level.
OS-level security: This shows the role of TEEs at the OS level.
Virtualization-level security: This depicts how AMD SEV and Hypervisors protect VMs and manage isolation.
Using this approach, you can gain a comprehensive view of how these technologies interact and complement each other in a typical computing scenario.
The flowchart in Figure 5 demonstrates how various security technologies interact in computing systems. It outlines the different stages of the security workflow, starting when data or applications enter the system.
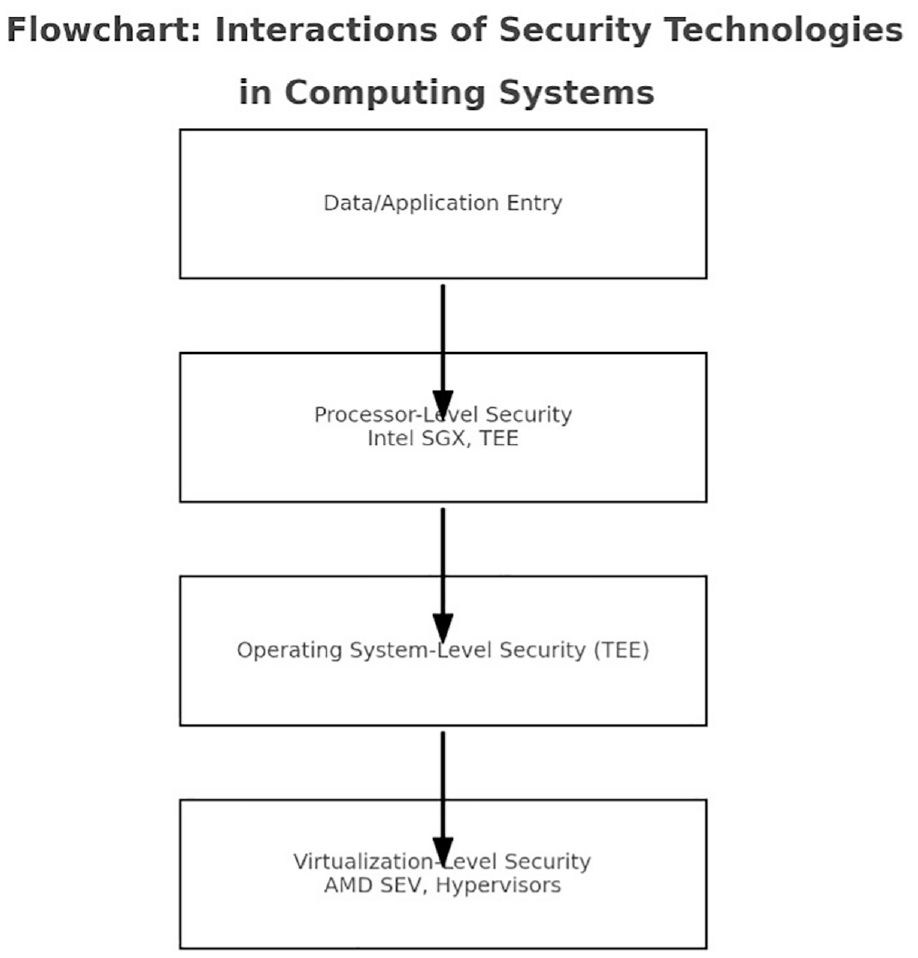
Interactions of different security technologies in computing systems.
The first stage is the data/application entry, the starting point for our security workflow.
The second stage is processor-level security, highlighting the role of Intel SGX and TEE in providing security at the processor level. Intel SGX offers secure memory enclaves within Intel processors, and TEEs provide a safe area within processors for running trusted applications.
The third stage is OS-level security, emphasizing the role of TEEs at the OS level. This stage shows how TEEs extend their functionality to offer a secure environment within the OS.
The final stage is virtualization-level security, which focuses on the importance of AMD’s SEV and Hypervisors in securing virtualized environments. AMD SEV encrypts and isolates VMs in AMD systems, while Hypervisors manage the creation and isolation of VMs, especially in cloud computing scenarios.
The flowchart provides a clear and comprehensive view of how these technologies interact and complement each other, creating a multi-layered security architecture in modern computing environments.
Each of these alternatives to CHERI offers distinct security benefits suitable for specific contexts. SGX and SEV provide hardware-based enclave solutions for Intel and AMD platforms, respectively, making them ideal for secure data processing in particular hardware environments. TEEs offer a solution for resource-constrained devices like mobile phones, while hypervisors are more suited for large-scale virtualized environments such as cloud computing. The choice among these technologies depends on the specific requirements of the use case, including hardware dependencies, the scale of deployment, and the nature of the data and applications involved.
5. Literature review and bibliometric analysis exploring previous studies and findings on the application of AI in analyzing cybersecurity threats
This research analyzes the current literature on various types of cybersecurity threats, exploits, and vulnerabilities within a BOM 2 or, in this case, an SBOM. In addition, the study examines previous research findings related to using AI to analyze cybersecurity threats, such as the Software Supply Chain Cyber Risk, which refers to potential cyber threats arising from the components, libraries, tools, and processes used to develop, build, and publish software. The Cyber Supply Chain Management and Transparency Act 3 and the “Internet of Things Cybersecurity Improvement Act of 2017” 4 led to new regulations that require US government agencies to obtain SBOMs for all new software. This led to the recent US Executive Order on Improving the Nation’s Cybersecurity of 12 May 2021, 5 which directed National Institute of Standards and Technology (NIST) to guide supplying an SBOM for each product to purchasers.
The SBOMs are a machine-readable inventory of software components and their dependencies listed hierarchically. It helps supply chain assets and vulnerability management by exchanging and sharing SBOMs.6,7 However, since the software ecosystem has diverse needs, there is no one-size-fits-all solution. The challenge with exchanging and sharing SBOMs is that machine processing and automation are necessary to realize its benefits specifications8 fully, as well as tools that are still under development.8–10
To manage vulnerabilities, 11 the Vulnerability Exploitability eXchange (VEX) 12 was created in 2021. VEX provides transparency and an up-to-date view of vulnerability status and helps prevent cybersecurity professionals from wasting time on non-exploitable vulnerabilities.
The Vulnerability Disclosure Report (VDR) 13 is a report that lists all the vulnerabilities affecting a product and its dependencies, along with an analysis of their impact. It is signed by a private key to ensure it comes from a trusted source. The VEX is a negative security advisory listing all the vulnerabilities to which a product is unaffected. 12 One key difference between the two reports is that VDR assesses all known and unknown vulnerabilities, while VEX only assesses known vulnerabilities. 14
Furthermore, this research will delve into new and emerging threats within SBOMs and the role of AI-powered tools in SBOM analysis. The study will also examine previous research on the application of AI in detecting and mitigating supply chain attacks, with a particular focus on SBOM analysis.
Finally, this study will explore the challenges and opportunities of using AI to analyze SBOMs in new software development paradigms.
5.1. Bibliometric analysis of existing literature in the Web of Science Core Collection
The Web of Science Core Collection15,16 is used by researchers and academics worldwide. To analyze all research on this topic, we used specific ways to turn data records from the Web of Science Core Collection to determine the overall research environment in analyzing cybersecurity threats, exploits, and vulnerabilities in new SBOMs with AI. The first method used the search function to locate articles on AI-implemented algorithms and methodologies for SBOM analysis. The second method was to conduct a literature review on supply chain attacks to gain insight into how AI can detect and prevent attacks. The third method was to read up on new software development paradigms to understand better the advantages and difficulties of utilizing AI to analyze SBOMs in these paradigms. The fourth method used the latest research on AI-powered SBOM analysis tools by tracking the citations of relevant articles.
Overall, we found some use of the Web of Science Core Collection, but solely from this data set, we could not present an overall argument on the current state-of-the-art in this research area. In general, the Web of Science Core Collection is a valuable resource for investigating AI-powered SBOM analysis tools, for AI for detecting and mitigating supply chain attacks, and for data records on AI for analyzing SBOMs in new software development paradigms. The first search was conducted on the term “SBOMs,” which produced 175 data records (publications). The Web of Science Core Collection Analyze Results tool categorized the data records into the most common categories.
From the original categorization in Figure 6, we can see some categories emerging in Figure 6, but the categorizations are predominated with separation into engineering and computer sciences. One exciting category appears as operations management, which is expected, given the value of SBOMs in supply chain management, but these categorizations need more value. We have to use alternative statistical methods to derive further conclusions from this data set because the Web of Science Core Collection Analyze Results is limited in the type of analysis we could extract.
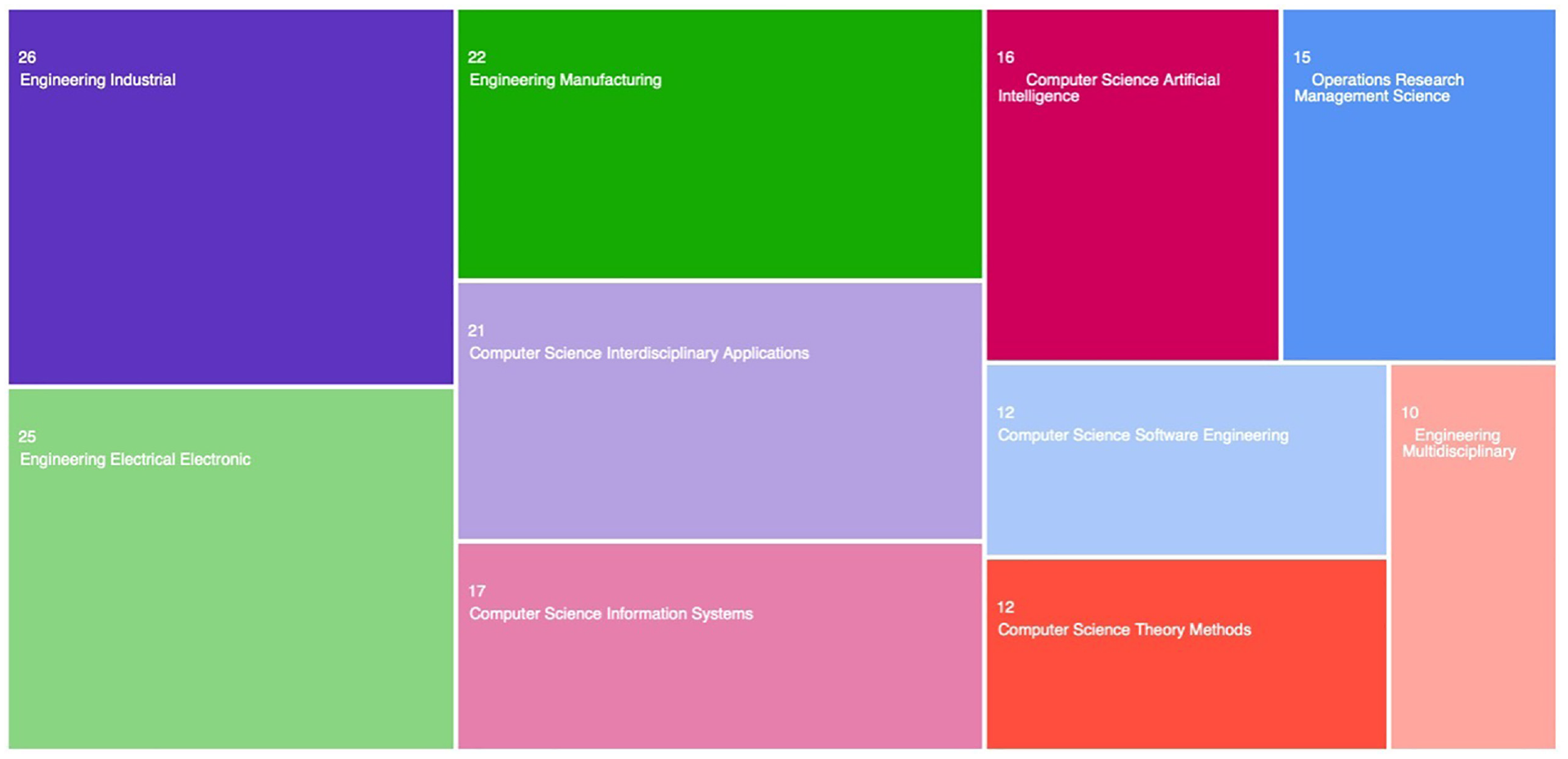
Categorizations of Web of Science Core Collection data records on SBOM.
The R statistical programming was used for further analysis with the bibliometrics and billion shiny plugins. The first visualization we generated targeted identifying the data file’s basic information. In Figure 7, we can see that the data set contains 175 documents published from 1990 to 2023. One aspect to consider is that the SBOMs were initially developed to gather information on open-source licenses for each software component of a system. The two most widely used SBOM formats are SPDX, created in 2010, and CycloneDX, introduced by OWASP in 2017. This presented two possibilities: first, the data set needs cleaning, and second, the data records show that the research community was looking into SBOMs before we had an official SBOM. To confirm which of the two is the correct possibility, the first step was to review the earliest data records in the data set. The oldest data record was from 1990, 17 describing bills of materials concerning the capability of software and hardware. The second was also from 1990, 18 and it represents software developed for educational purposes, where one of the program inputs included a bill of materials. The third oldest record that we analyzed was from 1991, 19 and it related to computer-integrated manufacturing and wanted to “determine whether or not product design engineers can use a desktop relational database management system and its various command languages to develop a master bill of material information system (BOMIS).”
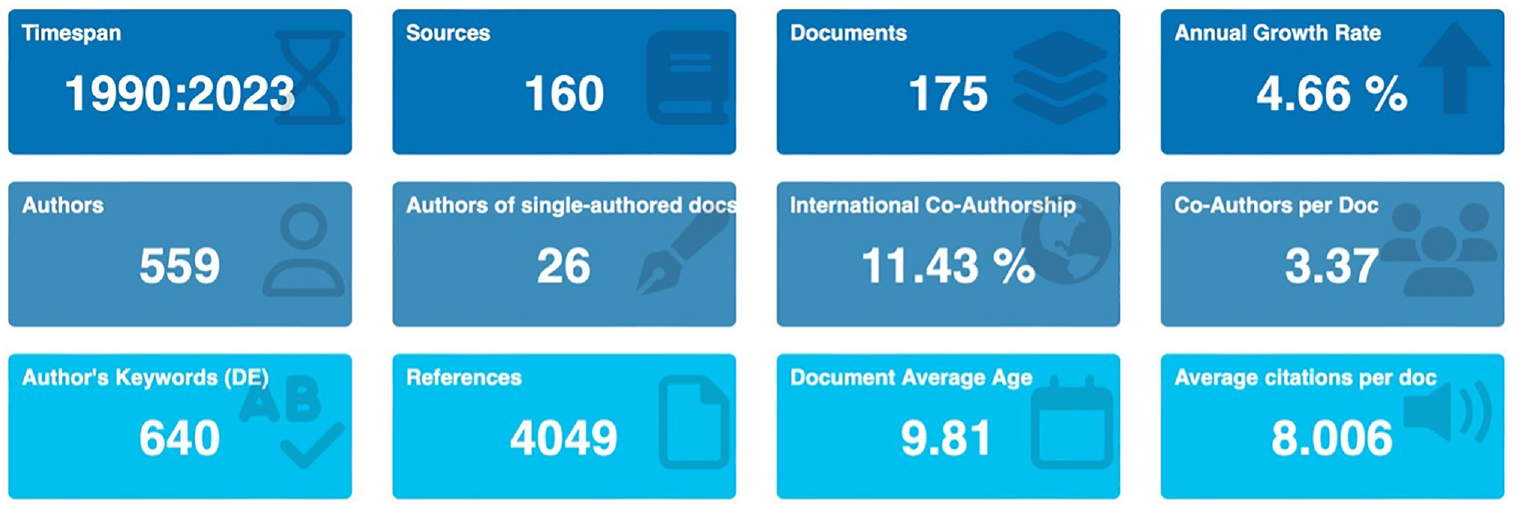
Main information of the data set used.
As we can see from Figure 7, and as discussed about the records from 1990, it becomes clear that the idea for an SBOM existed (e.g., BOMIS) at least 20 years before the first SBOM was developed in 2010. Since this study was not explicitly targeted at determining the historical records of when the first idea for an SBOM originated, this analysis section was considered sufficient. In the next step of the analysis, we wanted to see the content of these 175 data records and to achieve that, we developed a three-field plot (Figure 8). In this visualization, one peculiar grouping becomes interesting. As we will discuss in other sections of this research study, the US currently leads the way in implementing SBOMs. In short, since “the US Executive Order on Improving the Nation’s Cybersecurity of 12 May 2021”5 ordered the NIST to issue guidance on “providing a purchaser a Software Bill of Materials (SBOM) for each product.” The US has been one of the most vocal advocates of SBOMs. In the UK, there are no specific requirements for implementing SBOMs. The exciting category in Figure 8 is the categorizations by country.
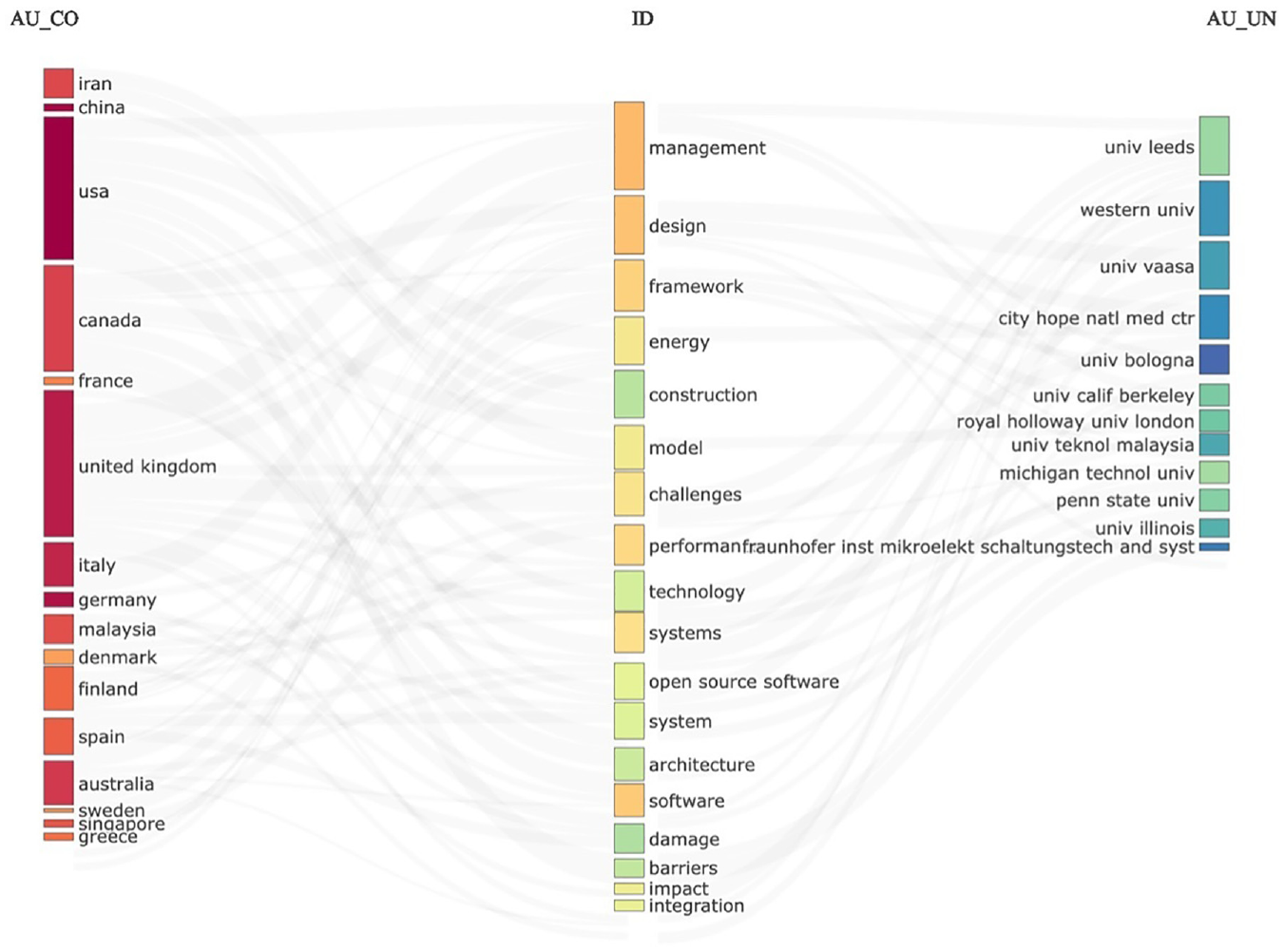
Three-field plot of Web of Science data records on SBOM.
Regarding scientific data records, the US and the UK stand on almost equal footing. To determine if the two countries conducted research in similar areas, we analyzed the categories further by looking at the keywords used in different countries. We found that in the UK, most of the research records were related to management, framework development, model development, impact, challenges, and software. In the US, the research categories are somewhat different and related more closely to construction, energy, technology, performance, damage, open-source software, and management. In other words, the only categories that the research interests in the UK and the US merged are in management and, to some extent, in damage-impact and open-source software.
Although this presents an interesting discovery (see Figure 8), it did not constitute the main research topic for this study. Digital historians could investigate the reasons for this categorization in the future. In the next step of the analysis, we wanted to check if this research topic is increasing in attention, remaining static, or even decreasing in research interest. In Figure 9, we analyzed the average citations per year.
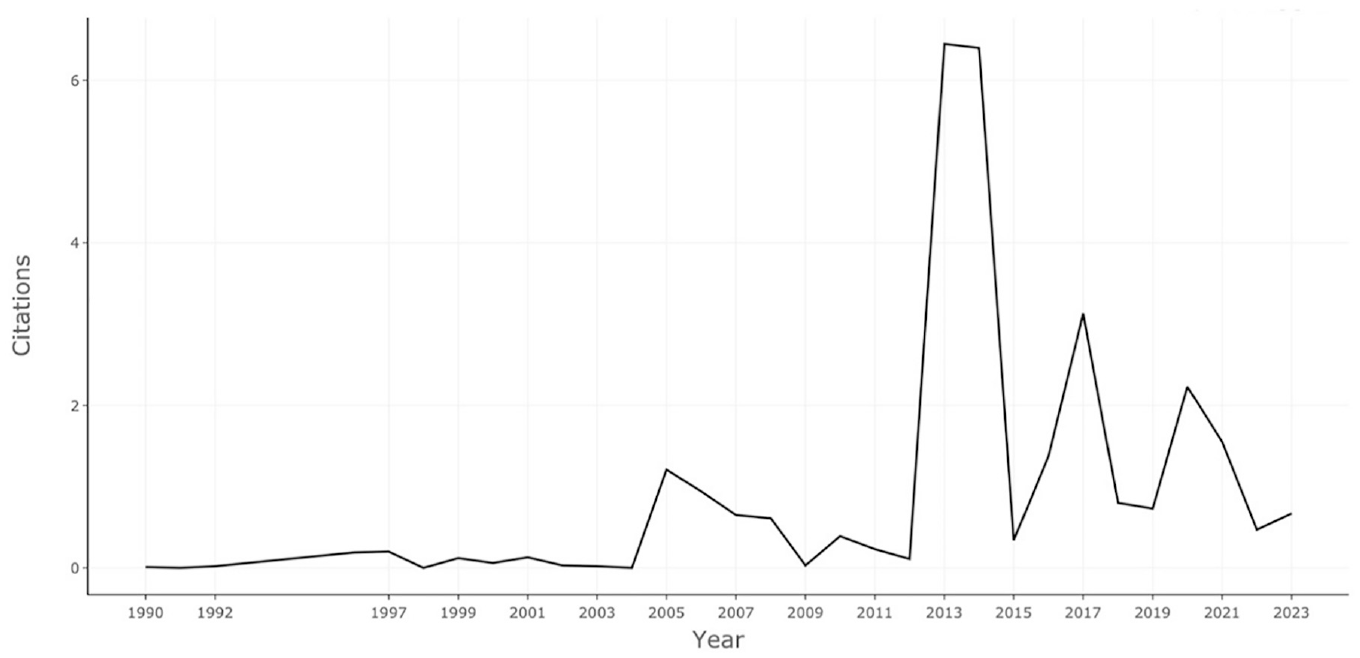
Average citations per year on SBOM.
By analyzing the average citations per year on SBOM (see Figure 9), the intention was to determine the level of research interest in this topic. The expectation was that because of the Executive Order on Improving the Nation’s Cybersecurity of 12 May 2021, the number of citations would increase dramatically in 2021 and 2022. This is not what we see in Figure 9. Instead, we can see a dramatic increase in interest in this topic between 2012 and 2015. We could invest more time analyzing what triggered this trend in 2012, but our primary purpose for this visualization was to determine if there was a rise in 2021. We expected this rising trend to appear in 2021 and not in 2012. Hence, we started looking at different analyses, leaving this point to be reviewed and investigated further by digital historians working in this area of research.
If this trend was where we expected it to appear, we might have concluded this analysis at this point. However, since this trend was unexpected, we wanted to determine if there had been an average increase in scientific production, not an increase in average citations. To resolve this, we created a new plot from the same data set. In Figure 10, we can see that the average annual scientific production on SBOM is increasing, and it presents a plot of annual scientific production on SBOM.
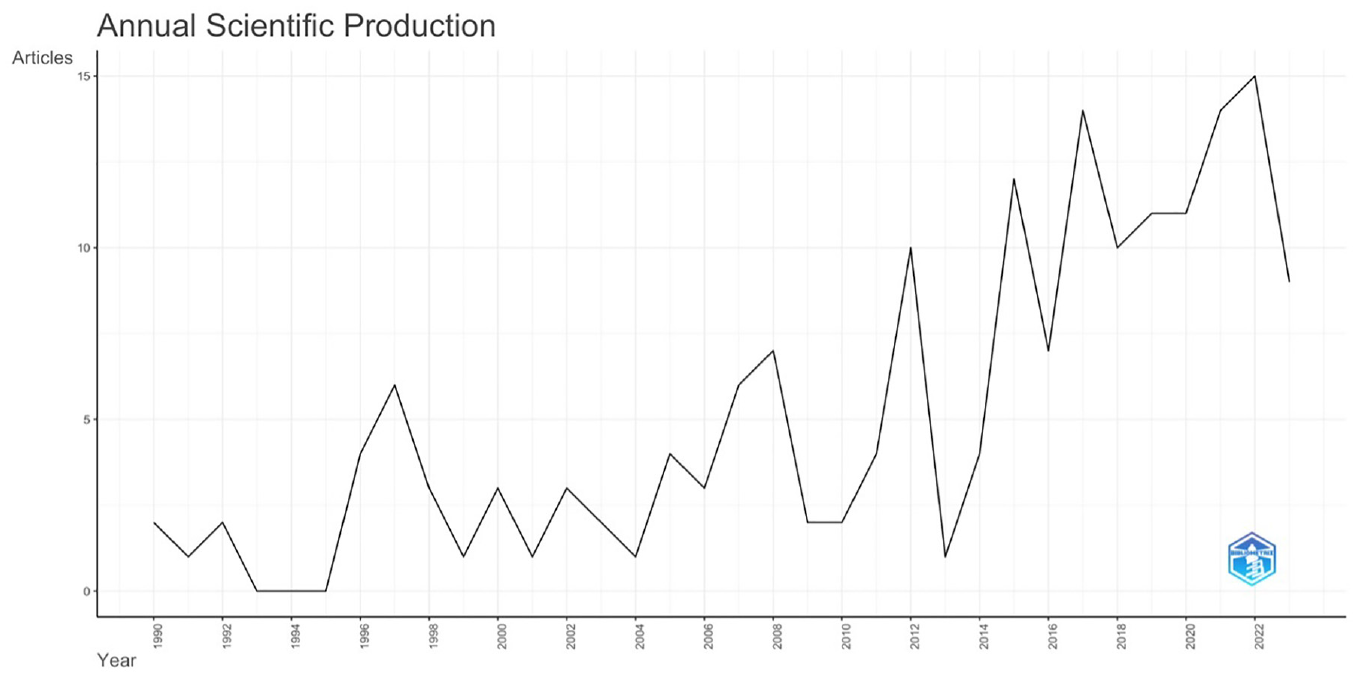
Plot of annual scientific production on SBOM.
In the following analysis (see Figure 11), we wanted to cluster the most coupled research areas. To perform such an analysis, we conducted clustering by coupling, with the specific coupling of keywords in the documents, and by clusters to the most represented words in the abstracts, with the impact measurement set as the global citation score. The analysis is conducted in N-Grams, specifically clustered in unigrams.
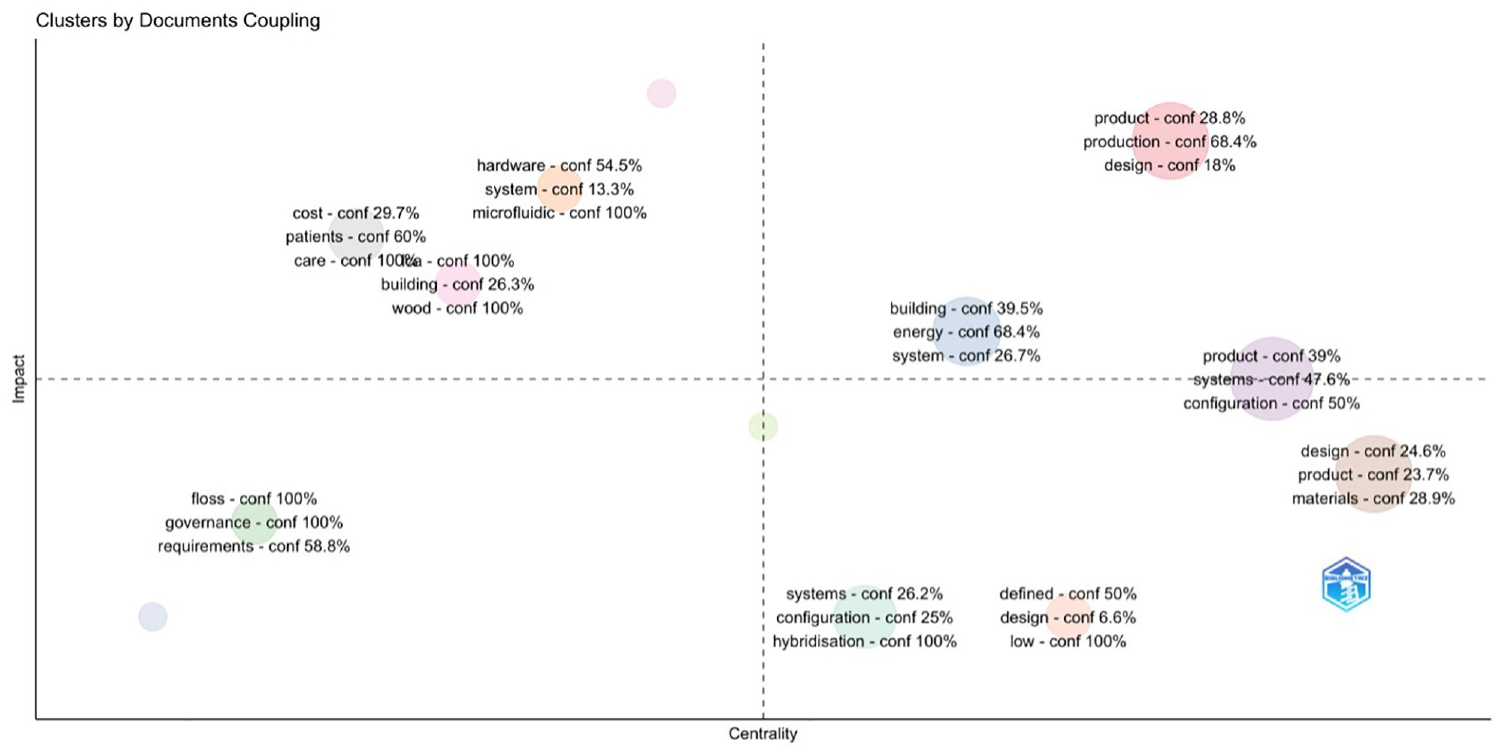
Clustering by coupling of the most represented words in the WoS data set.
A few categories of interest emerged by clustering the words and their representations in the data records (see Figure 11). Before taking these clusters as representative of the data set, we wanted to perform a few alternative analyses and then check to see if the same clusters would emerge. For this analysis, we applied co-occurrence analysis of words in the abstracts and words in the titles (Figure 13). We can see a significant number of correlated clusters, but the clusters and the categories have far less meaning than in the clustering by coupling in Figure 11.
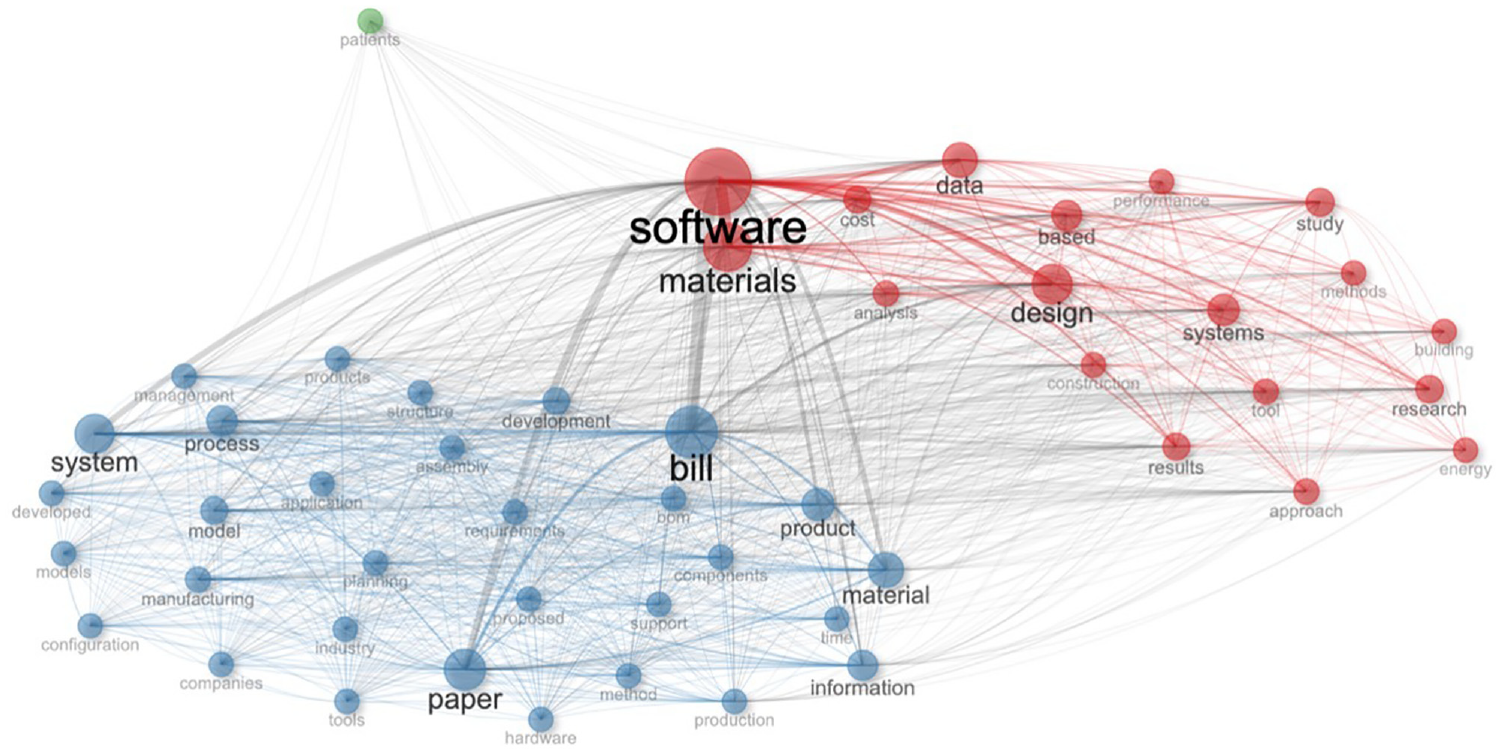
Since the co-occurrence analysis (Figures 12 and 13) did not verify clusters and categories, we performed a thematic analysis (Figure 14) of the networks behind the research records.
Co-occurrence analysis of words in the abstract.
Co-occurrence analysis of words in the titles.
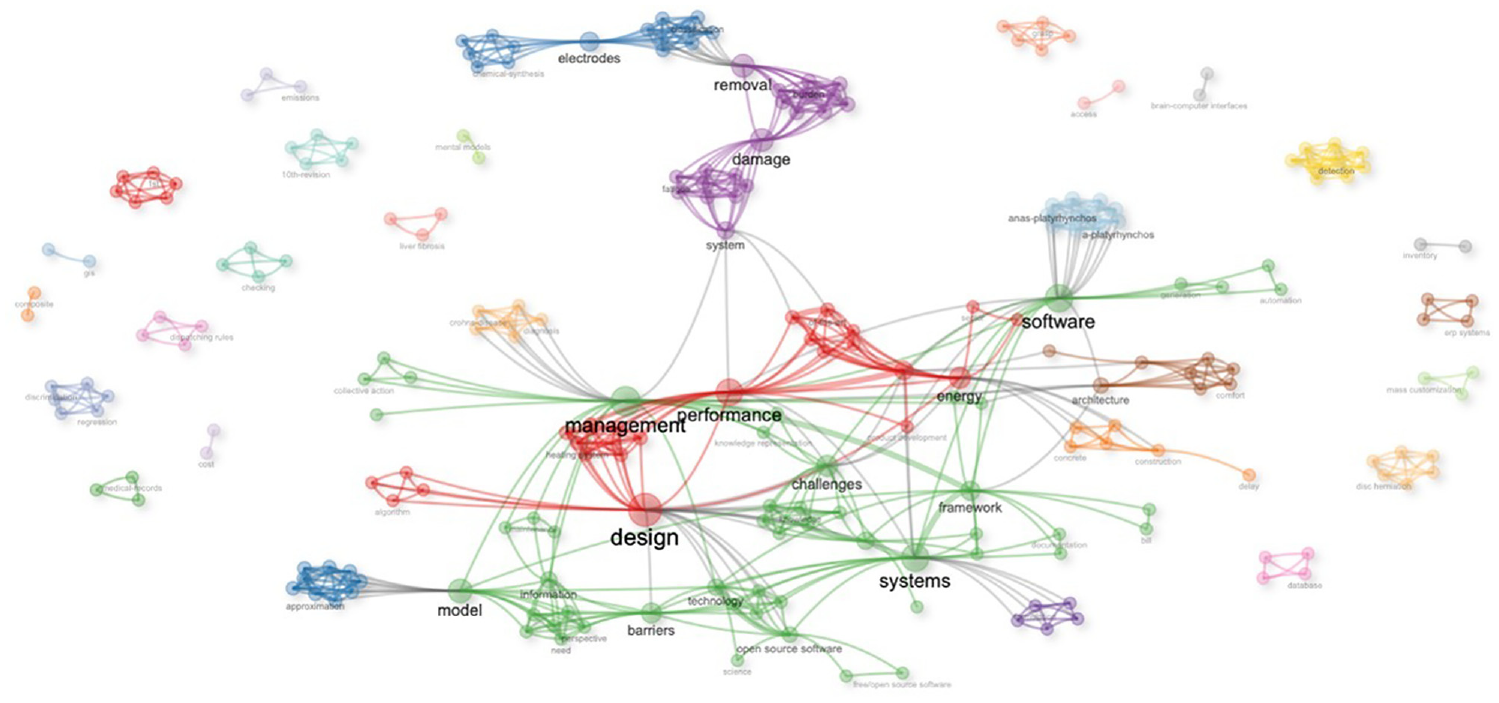
Thematic map of the networks in the research records.
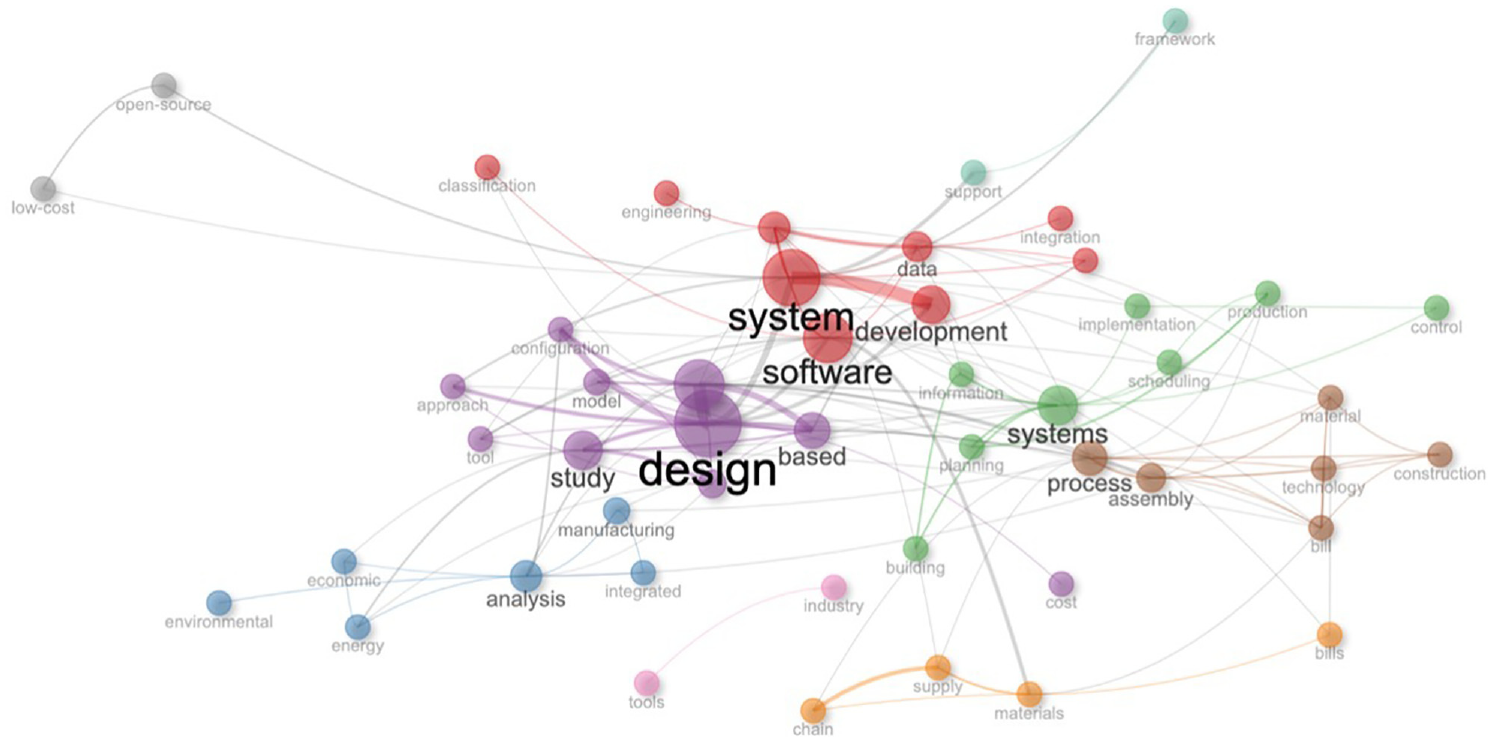
The emerging categories in the thematic map (Figure 14) are far more detailed than in the other statistical analysis. With this, we can see a comprehensive visualization of all categorizations, including the network and collaborative structure. The final analysis we wanted to perform was the evolution of terminology over time. In Figure 15, we can see the visualization of words used in the document abstracts. What becomes very clear is the shifts in the research interest from the multiple categories related to performance, application, configuration, and hardware to software and data.
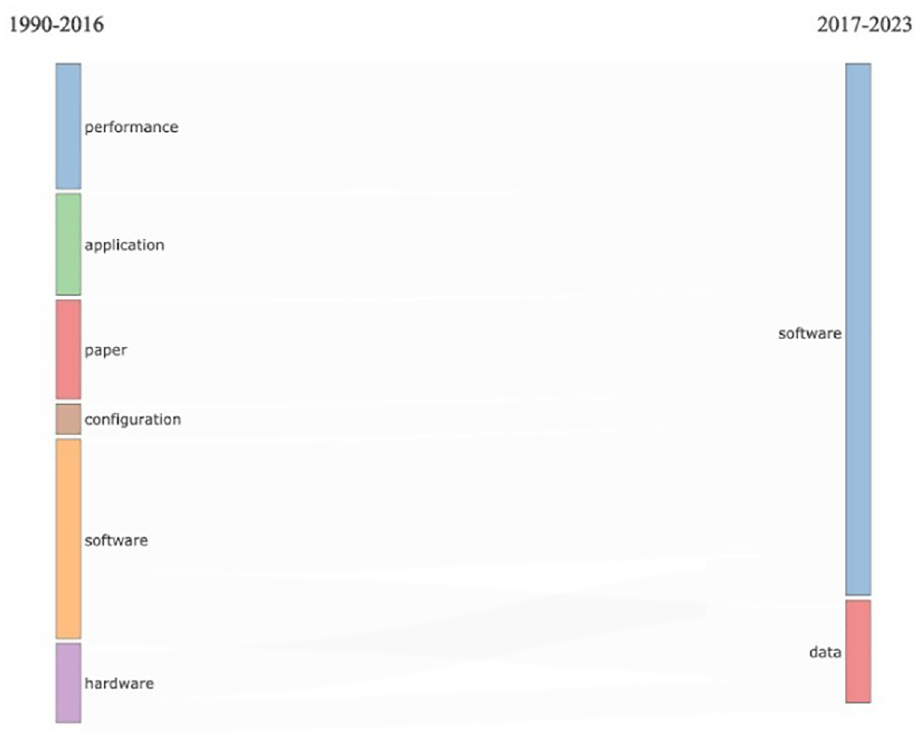
Thematic evolution of research interests.
This shift in research interest is categorized in Figure 15 between two time periods. We could analyze this data set further to visualize the change and the evolution of research interests yearly and then compare them with the happenings in the other research areas. However, for this research study, that was unnecessary and would not contribute to the research questions. With the thematic analysis, we conclude our bibliometric analysis of scientific research records on SBOM, and we start with the qualitative review of relevant literature.
6. Analysis
The report is structured into three sections: identified threats, exploits and vulnerabilities, and AI model performance. The identified threats section overviews the cybersecurity threats identified in the analyzed SBOMs. In contrast, the exploits and vulnerabilities section examines the exploits and vulnerabilities discovered in the SBOMs. Finally, the AI model performance section evaluates the effectiveness and accuracy of AI models in identifying threats, exploits, and vulnerabilities.
The current cybersecurity landscape is characterized by many threats, including supply chain attacks that are becoming increasingly sophisticated and difficult to detect. However, AI-powered tools are now available to help analyze SBOMs and identify potential cybersecurity threats. These tools use advanced algorithms that enable them to analyze SBOMs more thoroughly and quickly than is possible with human intervention alone.
In addition to identifying potential threats, AI is also being used to develop new methods for detecting and mitigating supply chain attacks. These new methods are designed to identify activity patterns indicative of a supply chain attack, such as unusual network traffic or unauthorized access to sensitive data.
With new software development paradigms such as cloud-native and microservice architectures, analyzing SBOMs for cybersecurity threats has become more challenging. However, AI is helping to address this issue by providing a more accurate and comprehensive analysis of SBOMs.
The AI-powered SBOM analysis tools identify cybersecurity threats and present the exploits and vulnerabilities discovered in the SBOMs. This information can be used to develop strategies for mitigating these threats and improving an organization’s overall security posture.
These AI-powered tools’ effectiveness and accuracy in identifying threats, exploits, and vulnerabilities are evaluated. This evaluation process is critical to ensuring that the tools deliver the level of protection organizations need to safeguard their digital assets against increasingly sophisticated and complex cyber threats.
This research employed a diverse array of ML and deep learning algorithms to analyze data from various sources, thereby gaining insights into the integration of CHERI with AI BOMs—this section of our paper reports on the specific algorithms applied and the nature of the data sources.
6.1. ML
ML algorithms20–28 were pivotal in our analysis. Support vector machines (SVMs) 29 were utilized to classify data into secure and non-secure categories. This classification was based on features derived from AI BOMs and CHERI attributes, particularly utilizing textual data from technical documents. Decision trees allowed us to visually represent and make sequential decisions about security attributes in AI systems, effectively utilizing case study data. Random forests, an ensemble of decision trees, significantly enhanced the accuracy of predictions regarding the robustness of AI systems post-CHERI integration. This approach was efficient in processing empirical data from experiments. Finally, gradient boosting machines were applied to iteratively improve predictive models, focusing on areas where previous models underperformed. These machines analyzed the incremental improvements in AI system security following successive iterations of CHERI integration.
6.2. Deep learning
The application of deep learning algorithms 30 was equally crucial. Convolutional neural networks (CNNs)31–35 were adept at handling and analyzing patterns in visual data related to AI BOMs or security patterns. In instances where the research included image-based AI BOMs or security threat visualizations, CNNs proved invaluable. Recurrent neural networks (RNNs) 36 were utilized for their proficiency with sequential data, analyzing time-series data or sequential processes in AI system security. This was particularly relevant when examining logs of AI system performance over time. Long short-term memory (LSTM) networks, 37 a special RNN, were vital in understanding data over long sequences. They were essential for detecting patterns in long-term AI system behavior, especially when processing extensive system logs or continuous data streams to identify the long-term impacts of CHERI integration on AI system security.
Each algorithm was strategically selected to analyze data types or address research questions. Combining these techniques facilitated a comprehensive examination of the intricate relationship between CHERI and AI BOMs, leading to nuanced insights into improving AI system security and trustworthiness.
6.3. Supervised learning
Supervised learning38,39 played a critical role in our research. It was used to train models to predict specific target variables based on input features. This approach was efficient in scenarios with clearly defined labels and a direct relationship between the input data and the output. For instance, we applied supervised learning algorithms to predict the effectiveness of CHERI’s security features in AI systems. The models were trained using data, where the input features comprised various attributes of AI BOMs and the output was a security score or classification. This method enabled us to establish direct correlations between specific characteristics of AI BOMs and their security implications.
6.4. Unsupervised learning
Unsupervised learning was utilized to identify patterns and structures in data without relying on labeled data.38,40,41 This methodology was crucial in the exploratory data analysis stages, where we sought to uncover hidden patterns or groupings in the AI BOMs and CHERI attributes. For example, unsupervised learning techniques like clustering were applied to categorize different AI BOMs based on their inherent characteristics without predefined categories. This approach helped us to discover novel insights and underlying structures in the data, which might not have been apparent through supervised methods.
6.5. Reinforcement learning
Reinforcement learning was employed to train models to take actions in an environment to maximize a reward.39,42–44 In our context, this involved developing models that could make real-time decisions regarding implementing CHERI features in AI systems. The models were trained in simulated environments, where they learned to choose optimal security configurations to enhance the trustworthiness and robustness of AI systems. Through trial and error and receiving feedback in the form of rewards for practical security enhancements, these models progressively improved their decision-making strategies. This aspect of our research was particularly innovative, allowing us to model and understand the dynamic nature of security in AI systems.
Each of these methodologies contributed to a comprehensive approach in our research, allowing us to tackle the complex problem of integrating CHERI with AI BOMs from multiple angles. The fusion of supervised, unsupervised, and reinforcement learning enabled us to predict, categorize, and actively experiment and adapt our models in a dynamic environment, leading to a more profound understanding of the intricate dynamics at play in enhancing AI system security.
6.6. Specific data sets
6.6.1. The national vulnerability database
The national vulnerability database (NVD)45,46 was a pivotal resource in our study. It provided comprehensive information on known vulnerabilities in software and other products. This data set was particularly beneficial in supervised learning models, where it was used to train algorithms to recognize patterns and signatures of vulnerabilities that could potentially compromise the security of AI systems. For example, by correlating specific vulnerabilities listed in the NVD with incidents in AI systems, our models could predict the likelihood and impact of similar vulnerabilities in systems integrated with CHERI.
6.6.2. The common vulnerabilities and exposures
The common vulnerabilities and exposures (CVE) dictionary was another critical data set. It offered standardized identifiers for publicly known information security vulnerabilities and exposures. This data set was instrumental in both supervised and unsupervised learning processes. In supervised learning, the CVE data enabled us to label vulnerabilities accurately and train models for precise identification and categorization of security threats. In unsupervised learning, the CVE data helped in clustering and pattern recognition, allowing us to uncover unknown or emerging vulnerabilities and exposures in AI systems and their potential implications when interfacing with CHERI.
6.6.3. The software composition analysis data set
The software composition analysis (SCA) data set was essential for understanding the open-source components used in software applications. This data set was invaluable in reinforcing our models’ capability to assess the security posture of AI systems. By analyzing the SCA data set, we could identify potential security gaps stemming from open-source components and understand how these gaps could be mitigated through the integration of CHERI. The SCA data set was instrumental in reinforcement learning models, focusing on dynamically adapting security measures in AI systems. By understanding the composition of software, our models could suggest optimal configurations of CHERI features to enhance the overall security of the systems.
Integrating these specific data sets—the NVD, CVE, and SCA—into our AI and ML methodologies was a cornerstone of our research. It enabled a multi-dimensional analysis of security in AI systems, ensuring that our models were theoretically sound and grounded in real-world data and practical applications. This approach significantly contributed to our overarching goal of elevating the trust and security standards in AI systems through the strategic interfacing of CHERI with AI BOMs.
7. Proposed AI BOM schema
Building upon the foundational insights gleaned from our extensive research, particularly the work from Manifest, we propose a new AI BOM schema. This schema, expressed in JSON format, formalizes the structure of an AI BOM document, meticulously detailing both required and optional fields and specifying the data types for each. This schema aims to enhance AI systems’ transparency, traceability, and security, especially considering the integration with CHERI.
7.1. Structure of the AI BOM schema
The proposed schema encapsulates comprehensive information about the AI system’s components, including, but not limited to, software libraries, ML models, data sets used for training and validation, and any underlying algorithms. This structure is pivotal for assessing the security posture of AI systems and identifying potential vulnerabilities.
The key elements of the schema are as follows:
Metadata section: This section includes essential details such as the AI BOM version, the document’s creation date, and the authoring entity’s information. It serves as the document’s header, ensuring that each AI BOM can be uniquely identified and tracked over time.
Component details: This segment outlines the specifics of each component within the AI system. It includes fields such as the component name, version, source (including the URL for open-source components), and a description of its function within the system.
Security vulnerabilities: This part of the schema, linked directly to databases such as the NVD and CVE, lists known security vulnerabilities relevant to the AI system’s components, along with their severity ratings and potential impact.
Licenses and compliance: This area details the licensing information for each component, ensuring compliance with legal and regulatory standards. It is crucial for open-source components, where license compatibility can be a significant concern.
Dependencies: This crucial part maps out the dependencies between various components, offering insight into the system’s structure and potential points of failure or security breaches.
ML Specifics: Unique to AI BOMs, this section includes information about ML models, algorithms, and data sets, detailing their sources, versions, and any modifications made.
CHERI Integration Details: This section reflects the focus of our research. It specifies how CHERI’s security features are incorporated into each component, highlighting the enhanced security measures and their implications.
7.2. Data types and formats
Each field in the AI BOM schema is defined with specific data types, such as strings for textual descriptions, numerical values for versions and dates, and Boolean flags for compliance statuses. This standardization ensures consistency and ease of parsing by automated tools.
7.3. Flexibility and scalability
The schema is designed to be flexible and scalable, accommodating future advancements in AI and cybersecurity. It allows for easy updates and additions, ensuring the AI BOM remains relevant and effective in the rapidly evolving landscape of AI systems and security.
Our proposed AI BOM schema is a comprehensive and structured approach to documenting AI systems’ components and security aspects. It is a step forward in enhancing the accountability and security of AI systems, particularly in the context of integrating CHERI. This schema not only aids in effectively managing AI system components but also serves as a critical tool in identifying and mitigating security risks.
Note: This schema was introduced in the following GitHub pull request: https://github.com/manifest-cyber/ai-bom/pull/31.
7.4. Main components of an AI BOM
The AI BOMs are a comprehensive and detailed document that provides vital information for understanding AI systems. It is structured into five key sections, each critical to a complete understanding of the AI model.
The main components of the AI BOMs are presented in Figure 16. The model details’ section is the first section of the AI BOM. This section provides fundamental information about the AI model, such as its name, version, developer, and a brief description of its purpose and functionality. This section sets the stage for a deeper understanding of the model by providing a context that aids in assessing and evaluating the other components.

Artificial intelligence bill of materials (AI BOM).
The model architecture section is the second section of the AI BOM. It provides detailed information about the internal workings of the AI model, including its structure, layers, nodes, activation functions, and any specialized components. This section is crucial to understanding the model’s technical makeup and how it processes data and makes decisions.
The third section of the AI BOM is the model usage section. This section outlines the practical applications of the model, including the environments in which it operates, its input and output formats, and any specific use-case scenarios. This section helps users understand where the model can be effectively and safely deployed.
The fourth section of the AI BOM is the model considerations’ section. This section addresses ethical implications, limitations, intended and unintended uses, and any potential biases associated with the model. This section is critical for comprehending the broader impacts of the model and ensuring that users are aware of ethical concerns and limitations.
Finally, the model authenticity or attestations’ section is the fifth section of the AI BOM. This section includes certifications, attestations, and other forms of verification that authenticate the model’s credibility and compliance with relevant standards and regulations. This section assures the model’s integrity and compliance, which are essential for trustworthiness and reliability in real-world applications.
The AI BOM ensures that all components are transparently and comprehensively documented by documenting all aspects of an AI model, from its technical specifications to its ethical implications. This level of detail is pivotal in evaluating AI systems’ suitability, safety, and reliability in various applications. With its detailed and structured approach, the AI BOM thoroughly understands the AI system and helps users assess the model’s ethical implications, limitations, and potential biases.
7.5. Schema metadata
In our proposed AI BOM schema, metadata plays a crucial role in defining the structure and standards adhered to by the document. Metadata, in the context of our JSON schema, refers to the data that describes the schema’s structure and properties. This section explains the critical metadata elements within our AI BOM schema.
7.5.1. $schema
Description: The $schema keyword declares the JSON schema draft version our AI BOM schema adheres to. A URI (Uniform Resource Identifier) defines the version of the JSON schema specification that the document is supposed to validate against. In our schema, we have adopted Draft-07.
Purpose: This element is essential as it informs validators and users about the specific version of the JSON schema specification to use when interpreting the validation rules. It ensures consistent processing and validation of the schema across different platforms and tools.
Example: “schema”: “http://json-schema.org/draft-07/schema#.”
7.5.2. Type
Description: The type keyword in our schema specifies the data type of the root object. In the AI BOM schema, the root type is defined as an “object.” This implies that the root level of the AI BOM document is expected to be a JSON object.
Purpose: Declaring the type of the root object is fundamental in any JSON schema, as it lays the groundwork for the document’s structure. By specifying that the root element is an object, we ensure that the AI BOM starts with a key-value structure standard in JSON documents.
Example: “type”: “object.”
These metadata elements serve as the foundation of our AI BOM schema, ensuring that the document adheres to a recognized standard and is structured in a universally understandable and processable way. The use of Draft-07 of the JSON schema and the specification of the root type as an object are decisions aimed at maximizing compatibility, reliability, and ease of use. This approach ensures that the AI BOM schema is robust, adaptable, and aligned with current best practices in JSON schema design.
7.6. Root object
The root object is of paramount importance in the structure of our AI BOM schema. It serves as the primary container for the essential information about the AI system being documented. The root object is defined to contain several required properties that encapsulate critical aspects of the AI model. This section outlines these required properties and their significance in the AI BOM schema.
7.6.1. ModelDetails
Description: The ModelDetails property in the root object is a comprehensive section that provides fundamental information about the AI model. It includes details such as the model’s name, version, development information, and a succinct description of its purpose and functionality.
Purpose: This property is crucial as it offers an initial overview of the AI model, setting the stage for a deeper understanding of its technical and operational aspects. It is the gateway to the AI model’s identity, providing essential context for the rest of the document.
Structure: As a required property, ModelDetails is typically a nested object within the root, containing various sub-properties delineating the model’s basic information.
7.6.2. ModelArchitecture
Description: The ModelArchitecture property delves into the technical composition of the AI model. It details the model’s internal structure, including its layers, nodes, activation functions, and other relevant architectural specifics.
Purpose: The significance of the ModelArchitecture property lies in its role in elucidating the technical underpinnings of the AI model. It is integral for understanding how the model processes data and makes decisions, providing insights into its complexity and sophistication.
Structure: Similar to ModelDetails, this property is also a nested object within the root, encompassing a detailed breakdown of the model’s architectural components.
7.6.3. Usage
Description: The usage property outlines the AI model’s practical applications and operational contexts. It covers the environments in which the model is intended to function, the types of inputs it can process, and the expected outputs.
Purpose: This property is essential for comprehending the real-world applicability of the AI model. It helps determine the suitability of the model for specific use cases and understand the operational prerequisites and outcomes.
Structure: As a required property in the root object, usage is again a nested object that provides detailed information about the operational aspects of the model.
These required properties in the root object of the AI BOM schema collectively offer a comprehensive and structured overview of the AI model. They ensure that every AI BOM document begins with a clear, well-defined set of information crucial for evaluating the model’s identity, technical makeup, and practical utility. Including these properties in the root object underscores their importance and ensures that they form the backbone of the AI BOM document.
7.7. ModelDetails object
This object contains detailed information about the AI model and includes the following properties:
Name (string): Name of the AI model.
Version (string): Version of the model.
Type (string): Type of the model.
Author (string): Author or creator of the model.
Licenses (array of strings): Licenses under which the model is released.
Libraries (array of strings, optional): Libraries used in the model.
Source (string): Source or repository where the model can be found.
BOMGeneration (object, optional): Information about how the BOM was generated.
Timestamp (string): The time when the BOM was generated.
Method (string): The method used to generate the BOM.
GeneratedBy (string): The entity that generated the BOM.
OtherReferences (array of strings, optional): Any references related to the model.
Tags (array of strings, optional): Tags for additional categorization or metadata.
7.8. ModelArchitecture object
This object provides details about the architecture of the model:
Datasets (array of objects): Information about data sets used in the model.
Name (string): Name of the data set.
Source (string): Source of the data set.
Usage (string): How the data set is used.
Architecture (string, optional): Description of the model architecture.
ArchitectureFamily (string, optional): Family or class of the model architecture.
ParentModel (object, optional): Information about the parent model, if any.
BaseModel (object, optional): Information about the base model, if any.
Input (string): Expected input type or format.
Output (string): Expected output type or format.
Hardware (string, optional): Required hardware for the model.
Software (string, optional): Required software for the model.
SoftwareRequiredForExecution (Boolean): Flag indicating if the software is needed for execution.
7.9. Usage object
This object details the intended and potential misuses of the model:
IntendedUse (string): Intended usage of the model.
OutOfScopeUsage (string): What the model should not be used for.
MisuseOrMaliciousUse (string): Potential misuses or malicious uses of the model.
7.10. Considerations object
This object contains additional considerations regarding the model:
EnvironmentalImpact (string, optional): Impact of the model on the environment.
EthicalConsiderations (string, optional): Ethical considerations for using the model.
7.11. Attestations or authenticity object
This object provides authenticity information regarding the model:
Authenticity (string, optional): A digital signature, signed by the developer of the model, to ensure the authenticity and integrity of the given AI-BOM.
8. AI BOM visualizer
The AI BOM visualizer is an innovative tool designed to represent the AI BOM schema visually and interactively. Accessible at https://aibomviz.aisecurityresearch.org, this tool is a significant advancement in how we understand and interpret the complex information contained in AI BOM documents. It is particularly beneficial for stakeholders who may not be profoundly technical but need a clear understanding of an AI model’s components and characteristics.
The key features of the AI BOM visualizer are as follows:
Interactive interface: The tool provides an interactive interface where users can explore various components of the AI BOM in a user-friendly manner.
Visualization of schema structure: It visually maps out the structure of the AI BOM schema, illustrating how different components like ModelDetails, ModelArchitecture, and others are interconnected.
Detailed view of properties: Each section of the AI BOM can be explored in detail, allowing users to understand the specifics of properties like Name, Version, Type, Author, etc.
Representation of nested objects: The visualizer adeptly handles nested objects and arrays, clearly showing how different schema elements are hierarchically arranged.
Accessibility of optional elements: It also highlights optional elements in the schema, such as Libraries, BOMGeneration, and Tags, making it easy to identify which parts of the BOM are customizable.
The visual representation of the AI BOM schema is as follows:
The visualizer tool presents a graphical representation of the AI BOM schema, which can be particularly useful for educational and documentation purposes. This visual representation helps grasp the schema’s complexity and comprehensiveness at a glance. It simplifies the interpretation of the AI BOM, making the data more accessible and understandable, especially for those who may find textual or coded information challenging to navigate.
We bridge the gap between technical data representation and user-friendly information access by providing a visual tool for exploring the AI BOM. This tool is a testament to our commitment to making AI systems more transparent and understandable, not just for developers and technical experts but for a broader audience, including stakeholders, auditors, and end-users.
In Figure 17, we can see the visual representation of the AI BOM schema which corresponds to the code and the methodology outlined in earlier sections of this paper.
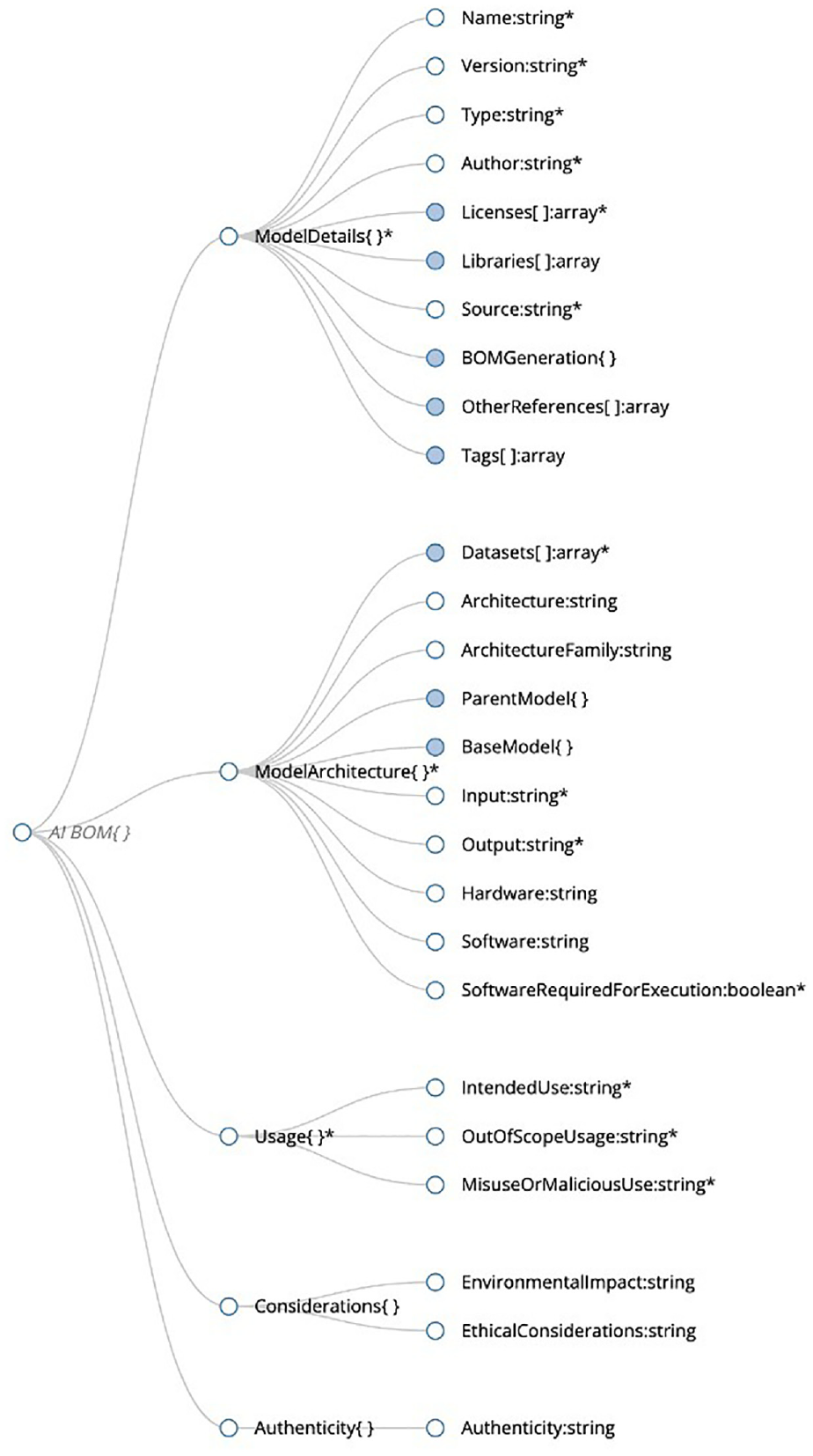
The AI BOM schema.
9. Why AI BOMs are essential
9.1. Transparency and trust
AI BOMs serve as a document of trust between all stakeholders, including users, developers, and auditors. They ensure that every element of an AI solution is transparently presented, fostering greater confidence in the system. We underscore the critical importance of the AI BOMs in promoting a framework of transparency and trust within the AI landscape. The comprehensive nature of AI BOMs, which includes exhaustive documentation of all components constituting an AI system, is a bedrock for building confidence among stakeholders—users, developers, and auditors alike. This thorough documentation extends beyond mere software and algorithms to encompass data sets, models, libraries, and their origins, thus presenting every facet of the AI system transparently. Such transparency is crucial for fostering trust and pivotal for informed decision-making, especially concerning AI technologies’ privacy, security, and ethical implications.
Moreover, AI BOMs significantly enhance accountability, offering a tangible record against which developers and organizations can be held accountable and ensuring adherence to legal, ethical, and technical standards. From an auditing perspective, AI BOMs are indispensable, providing a structured and transparent framework for regulatory compliance assessment. They also serve as a proactive tool in risk management by identifying potential vulnerabilities within AI systems, thereby allowing for timely intervention. Overall, AI BOMs stand as a testament to the commitment to responsible and ethical development and deployment of AI systems, bridging the gap between complex AI technologies and the imperative for clarity, accountability, and trust.
The following are vital aspects highlighting the importance of AI BOMs in this context:
Comprehensive disclosure: AI BOMs provide a detailed account of the components that make up an AI system. This includes the software and algorithms used and the data sets, models, libraries, and their sources. Such comprehensive disclosure ensures that all elements of the AI system are transparently presented.
Building confidence: As AI applications become increasingly integral to critical operations, trust in these systems is paramount. AI BOMs help build this confidence by clearly outlining the system’s makeup, allowing stakeholders to understand what goes into the AI solutions they use or oversee.
Facilitating informed decisions: The detailed information in AI BOMs allows users and stakeholders to make more informed decisions. This is particularly relevant to issues of privacy, security, and ethical considerations associated with AI systems.
Enhancing accountability: By documenting every aspect of an AI system, AI BOMs strengthen the accountability of developers and organizations. They serve as a record that can be referenced to ensure compliance with legal, ethical, and technical standards.
Audit and compliance: AI BOMs are invaluable for auditors and regulatory bodies. They provide a clear and structured way to assess AI systems for compliance with regulations and industry standards.
Risk management: AI BOMs are critical in identifying and managing risks associated with AI systems. Clearly understanding the components and their origins makes it easier to pinpoint potential vulnerabilities and take pre-emptive measures.
In summary, AI BOMs are not just documents but essential instruments that uphold the principles of transparency and trust in the AI ecosystem. They bridge the gap between complex AI technologies and the need for clarity and accountability, ensuring that AI systems are developed and used responsibly and ethically.
9.2. Supply chain security and quality assurance
With a detailed AI BOM, both developers and auditors can quickly assess the quality, reliability, and security of each component in an AI system.
In the context of AI development and deployment, the role of AI BOMs extends significantly into supply chain security and quality assurance. The detailing within an AI BOM offers a profound insight into the composition of an AI system, thereby enabling developers and auditors to conduct thorough assessments regarding each component’s quality, reliability, and security.
9.2.1. Supply chain security
The supply chain of an AI system, encompassing everything from data sources and algorithms to libraries and frameworks, is complex and often involves multiple third-party elements. AI BOMs are a comprehensive record that tracks these components, providing a clear view of the supply chain. This visibility is crucial for identifying security vulnerabilities from outdated libraries or unsecured data sources. By highlighting these components, AI BOMs enable developers and security professionals to proactively address possible risks, fortifying the system’s overall security posture.
9.2.2. Quality assurance
Quality assurance in AI systems is not merely about functional correctness but also ensures that the system adheres to ethical, legal, and regulatory standards. AI BOMs facilitate this assurance process by providing detailed information about each component, including its source, version, and compliance status. For auditors and regulators, this information is invaluable in verifying the system’s compliance with industry standards and regulatory requirements. Furthermore, it allows developers to ensure the system is built with high-quality, reliable components, reducing the risk of failures or malfunctions.
Including AI BOMs in the AI system development lifecycle offers a robust framework for enhancing supply chain security and ensuring quality assurance. By presenting a detailed and transparent view of all components within an AI system, AI BOMs empower stakeholders to make informed decisions, thereby significantly contributing to creating secure, reliable, and compliant AI solutions.
9.3. Troubleshooting
AI BOMs can also facilitate rapid identification of problematic components in system failure or bias cases, allowing for more effective troubleshooting. In AI systems, the utility of AI BOMs extends into the critical area of troubleshooting. These comprehensive documents play a pivotal role in swiftly identifying and addressing issues related to system failures or biases, thereby significantly enhancing the efficiency and effectiveness of the troubleshooting process.
9.3.1. Rapid identification of problematic components
AI BOMs act as a detailed map of an AI system, listing each component and its specifications. This detailed mapping allows for rapidly pinpointing potentially problematic components in system failures or performance issues. Whether it is a flawed data set, an outdated library, or a misconfigured algorithm, the AI BOM provides a clear starting point for investigation.
9.3.2. Streamlining troubleshooting processes
With the comprehensive information provided by AI BOMs, developers and engineers can quickly assess the entire landscape of the AI system. This facilitates a more structured and focused approach to troubleshooting, narrowing down potential areas of concern. The ability to quickly isolate and address the root cause of a problem is crucial, especially in time-sensitive or high-stakes environments where prolonged system downtime is not an option.
9.3.3. Addressing AI biases
AI BOMs are particularly useful in identifying biases within AI systems. Given the detailed documentation of data sources and training methodologies, AI BOMs can help trace the origins of biases. This is especially important when biases have significant ethical, legal, or social implications. By providing a clear trace of the model’s development process and components, AI BOMs enable teams to address and rectify biases, ensuring the AI system’s fairness and impartiality more effectively.
9.3.4. Enhancing system reliability
Overall, the role of AI BOMs in troubleshooting contributes not only to the immediate resolution of issues but also to the long-term reliability and integrity of AI systems. AI BOMs empower developers to build more robust and reliable AI solutions by facilitating a deeper understanding of the system’s components and interactions.
AI BOMs are invaluable tools in AI system maintenance and troubleshooting. They offer a systematic approach for quickly identifying issues and biases, ensuring that AI systems remain efficient, reliable, and aligned with ethical standards.
9.4. The future of AI BOMs
AI BOMs are set to become increasingly important as AI systems become more complex and as regulations around AI use loom on the horizon. They will serve as a cornerstone in ensuring responsible development and deployment of AI technologies. As we advance into an era where AI systems are becoming more intricate and their applications more pervasive, the significance of AI BOMs is poised to escalate considerably. The future landscape of AI BOMs is shaped by two key factors: the increasing complexity of AI systems and the emerging regulatory framework surrounding AI.
9.4.1. Addressing increasing system complexity
AI systems are evolving rapidly, integrating more advanced algorithms, diverse data sets, and complex integrations. This evolution brings about heightened complexity in understanding and managing these systems. AI BOMs, in this context, will become indispensable tools. They provide a structured and comprehensive way to document and understand the myriad components that constitute these complex systems. As AI solutions become more sophisticated, AI BOMs will evolve to document not just the components but also their interdependencies and interactions, offering a more holistic view of AI systems.
9.4.2. Navigating the regulatory landscape
AI’s nascent regulatory landscape is expected to become more defined and stringent soon. Regulations will likely mandate transparency, accountability, and ethical considerations in AI development and deployment. AI BOMs will be instrumental in meeting these regulatory requirements. They will serve as official records demonstrating compliance with regulatory standards, ethical guidelines, and best practices in AI development. This aspect of AI BOMs will be crucial for organizations to navigate the regulatory landscape effectively and avoid potential legal and ethical pitfalls.
9.4.3. Ensuring responsible AI development
AI BOMs are set to play a central role in promoting responsible AI development. They encourage a culture of transparency and accountability, ensuring that every element of an AI system is thoroughly documented and scrutinized. This documentation process not only aids in compliance and troubleshooting but also fosters ethical considerations in AI development. By providing a clear blueprint of AI systems, AI BOMs enable developers, auditors, and regulators to ensure that AI technologies are developed and deployed responsibly, with due consideration to societal and ethical implications.
9.4.4. Facilitating global standards
Looking ahead, AI BOMs are likely to contribute to establishing global standards in AI development. As more organizations adopt AI BOMs, a common framework for documenting AI systems can emerge, facilitating greater collaboration and standardization across the industry. This standardization will be crucial for interoperability, consistency, and quality assurance in AI technologies across different sectors and geographical regions.
The future of AI BOMs is intrinsically linked to the trajectory of AI development and regulation. They are set to become more integral to the AI ecosystem, serving as foundational tools ensuring responsible, transparent, and compliant development and deployment of AI technologies. As AI systems continue to permeate various aspects of society and business, AI BOMs will be pivotal in managing complexity and aligning them with societal values and regulatory standards.
10. Discussion
Our study has highlighted potential threats, exploits, and vulnerabilities that have significant consequences, especially in modern software development methodologies. The identified threats underscore the inherent vulnerabilities of contemporary software systems, including data breaches and system leaks. These risks are particularly relevant in cloud-based, distributed, and microservice architectures prevalent in new software development paradigms. The fallout from these vulnerabilities can extend far beyond system downtime or data loss, and a single vulnerability can have cascading effects, impacting not only the affected system but also the entire network it operates in. As a result, it is crucial to have robust security measures and constant monitoring in modern software ecosystems.
In light of the increasing threats and vulnerabilities, the use of advanced technology for analyzing cybersecurity threats in SBOMs has emerged as a crucial factor in mitigating risks in software development. AI-powered tools provide efficiency and depth in analyzing SBOMs, enabling them to sift through large volumes of data to identify patterns and anomalies that may indicate potential threats. This is particularly useful, given the complexity of modern software systems. In new development paradigms prioritizing agility and speed, AI tools provide a much-needed balance by ensuring that rapid development does not compromise security. They enable real-time analysis and threat detection, allowing developers to address vulnerabilities promptly.
Our study has shown that software development methodologies are inherently vulnerable to threats and vulnerabilities, which can have significant consequences. Advanced technology, particularly AI-powered tools, is crucial in mitigating these risks and ensuring robust security measures in modern software ecosystems. Developing efficient and adequate security measures, including constant monitoring, is essential to minimize the impact of vulnerabilities, prevent data breaches, and ensure the integrity of software systems.
During our study, we faced several challenges and limitations that reflect the complexity of the field. One of the primary challenges was keeping up with the rapidly evolving nature of cybersecurity threats, which require us to continuously adapt our analysis tools and methodologies. While AI tools are powerful, they are not infallible. The quality of data fed into them is crucial, and they are subject to limitations such as false positives and negatives. Moreover, AI models can be targets of cybersecurity threats, so a layered approach to security is necessary.
Our study was limited to known vulnerabilities and threats, and emerging threats, especially in new and untested technologies, remain challenging to predict and prepare for. While our findings provide crucial insights into vulnerabilities in modern software systems and the role of AI in addressing these issues, they also emphasize the need for continuous vigilance, adaptation, and comprehensive security strategies in the face of evolving threats and technological advancements.
11. Recommendations
Our findings suggest several recommendations to mitigate identified cybersecurity threats, exploits, and vulnerabilities, particularly in modern software systems. We also suggest future research and development directions in AI applications within cybersecurity analysis.
11.1. Mitigation strategies
Regular security audits and assessments: Implementing routine security and vulnerability assessments is crucial. These should include thorough reviews of SBOMs and adherence to security best practices.
Integration of AI-based monitoring tools: Leveraging AI-based tools for continuous monitoring and anomaly detection can significantly enhance security. These tools can proactively identify potential threats and vulnerabilities, facilitating timely responses.
Employee training and awareness: Regular training on the latest cybersecurity threats and best practices is essential. A well-informed workforce can significantly reduce the risk of security breaches.
Patch management: Maintaining an efficient patch management process ensures that all software components are up-to-date and protected against known vulnerabilities.
Adoption of zero-trust architecture: Implementing a zero-trust security model, where trust is never assumed and verification is required from everyone trying to access network resources, can significantly enhance security.
Encryption and access control: Ensuring strong encryption standards and implementing strict access control policies are fundamental in protecting sensitive data and systems.
11.2. Future AI applications
Development of adaptive AI tools: Future research should focus on developing AI tools that adapt to evolving threats. These tools should be capable of learning from new patterns of attacks and automatically adjusting their algorithms.
AI in threat intelligence: AI can play a significant role in cyber threat intelligence by predicting new attack vectors and identifying emerging threats using pattern recognition and data analysis.
Enhancing AI’s predictive capabilities: Improving the predictive capabilities of AI in cybersecurity to not only detect but also forecast potential vulnerabilities and breaches is a promising area of research.
AI in automating response: Research into AI applications that can detect threats and automate appropriate responses could significantly improve reaction times and mitigate the impact of breaches.
Ethical AI development: As AI tools become more integral to cybersecurity, it is imperative to ensure they are developed with moral considerations, avoiding biases, and ensuring privacy.
Interdisciplinary research: Combining psychology, sociology, and criminology insights with AI can provide a more holistic approach to understanding and combating cybersecurity threats.
Our recommendations emphasize the importance of a multi-faceted approach to cybersecurity, integrating both technological advancements and human-centric strategies. The future of AI in cybersecurity looks promising, and continuous research and development in this area are crucial to staying ahead of cyber threats.
12. Conclusion
The emergence of AI BOMs as a tool for transparency, trust, and security marks a significant stride in responsible AI development. They contribute to building safer and more reliable systems and promote ethical practices in AI development.
12.1. The role of AI BOMs in advancing responsible AI
The emergence of the AI BOMs as a pivotal tool in AI development marks a watershed moment in pursuing responsible and ethical AI. AI BOMs stand at the forefront of efforts to embed transparency, trust, and security within the fabric of AI systems, thereby playing a crucial role in shaping the future landscape of AI technology.
12.2. Building safer and more reliable systems
One of the most significant contributions of AI BOMs is their role in enhancing the safety and reliability of AI systems. By providing detailed and structured documentation of all components of an AI system, AI BOMs enable developers, auditors, and users to understand the system’s workings comprehensively. This understanding is essential in identifying potential vulnerabilities, ensuring compliance with evolving standards, and addressing issues before they escalate into more significant problems. In an era where AI systems are increasingly employed in critical domains, the role of AI BOMs in maintaining system integrity and reliability cannot be overstated.
12.3. Promoting ethical AI development
In addition to reinforcing system security and reliability, AI BOMs are instrumental in advancing ethical practices in AI development. They encourage developers and organizations to consider the broader implications of their AI systems, from data sourcing to algorithmic decision-making. This consideration is crucial for avoiding biases, ensuring fairness, and respecting privacy. AI BOMs, therefore, catalyze infusing ethical considerations into the AI development process, promoting a more conscientious approach to AI creation and deployment.
12.4. Looking ahead
As we move forward, the role of AI BOMs is set to become even more pronounced with the increasing complexity of AI systems and the growing emphasis on regulatory compliance and ethical standards in AI. AI BOMs will continue to serve as critical tools for documentation and transparency and evolve to meet the challenges of emerging AI technologies and regulatory landscapes. Their adoption and integration into AI development processes will be vital in steering the evolution of AI toward a more secure, reliable, and ethically aligned future.
In conclusion, the advent of AI BOMs represents a significant stride in responsible AI development. They embody the principles of transparency, trust, and security, which are essential for building AI systems that are not only technologically advanced but also ethically sound and socially responsible. As the AI landscape continues to expand and transform, AI BOMs will undoubtedly play a central role in shaping the future of responsible AI.
Footnotes
Acknowledgements
The authors acknowledge the Fulbright Visiting Scholar Project.
Author contributions
Dr P.R. was responsible for reviewing the researched literature and conceiving the study, was involved in protocol development, gaining ethical approval, participants recruitment and data analysis, wrote the first draft of the manuscript, reviewed and edited the manuscript, and approved the final version. O.S. was responsible for reviewing the study, was involved in protocol development and data analysis, reviewed, edited, and approved the final version of the manuscript. Professor A.B.-J. was responsible for reviewing the study, reviewing and editing the manuscript, and approving the final version.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for research, authorship, and/or publication of this article: This work was supported by the PETRAS National Centre of Excellence for IoT Systems Cybersecurity, which was funded by the UK EPSRC (under grant no. EP/S035362/1) and ESRC (under grant no. ES/V003666/1). P.R. reports financial support was provided by the University of Oxford.
Ethical approval
The University of Oxford ethical committee has granted ethical approval under reference R51864/002.
Availability of supporting data/availability of data and materials
All data and materials are included in the article.
Author biographies
![]() ) focused on smarter grant making in the Third Sector. Between 2014 and 2017, he was Associate Dean for Post-Experience Education, responsible for the MBA, EMBA, DBA and EngDoc programs. He was formerly a Reader at Manchester Business School, an Assistant and Associate Professor at Bath University, and a Teaching Fellow Warwick Business School, where he also completed his PhD.
) focused on smarter grant making in the Third Sector. Between 2014 and 2017, he was Associate Dean for Post-Experience Education, responsible for the MBA, EMBA, DBA and EngDoc programs. He was formerly a Reader at Manchester Business School, an Assistant and Associate Professor at Bath University, and a Teaching Fellow Warwick Business School, where he also completed his PhD.