
Abstract
Background
Movement disorders in children and adolescents with dyskinetic cerebral palsy (CP) are commonly assessed from video recordings, however scoring is time-consuming and expert knowledge is required for an appropriate assessment.
Objective
To explore a machine learning approach for automated classification of amplitude and duration of distal leg dystonia and choreoathetosis within short video sequences.
Methods
Available videos of a heel-toe tapping task were preprocessed to optimize key point extraction using markerless motion analysis. Postprocessed key point data were passed to a time series classification ensemble algorithm to classify dystonia and choreoathetosis duration and amplitude classes (scores 0, 1, 2, 3, and 4), respectively. As ground truth clinical scoring of dystonia and choreoathetosis by the Dyskinesia Impairment Scale was used. Multiclass performance metrics as well as metrics for summarized scores: absence (score 0) and presence (score 1-4) were determined.
Results
Thirty-three participants were included: 29 with dyskinetic CP and 4 typically developing, age 14 years:6 months ± 5 years:15 months. The multiclass accuracy results for dystonia were 77% for duration and 68% for amplitude; for choreoathetosis 30% for duration and 38% for amplitude. The metrics for score 0 versus score 1 to 4 revealed an accuracy of 81% for dystonia duration, 77% for dystonia amplitude, 53% for choreoathetosis duration and amplitude.
Conclusions
This methodology study yielded encouraging results in distinguishing between presence and absence of dystonia, but not for choreoathetosis. A larger dataset is required for models to accurately represent distinct classes/scores. This study presents a novel methodology of automated assessment of movement disorders solely from video data.
Keywords
Introduction
Within healthcare settings, the use of artificial intelligence (AI) is being increasingly explored to decrease costs and professionals’ workload, enhance accuracy, and expedite diagnoses. 1 One significant application of AI in healthcare involves image-based diagnostic methods in radiology and pathology. 2 Input for image-based applications to detect or classify abnormalities are typically plain radiographs, computed tomography (CT) scans or magnetic resonance imaging (MRI) scans in radiology. 3 In pathology, images captured from digital cameras or smartphones are employed, such as those for AI-driven skin cancer detection. 4 Deep learning methods, in particular, are gaining attention in this domain. 2
While the use of AI for video recording evaluations is less prevalent than image-based applications in radiology and pathology, there has been a recent surge of interest in its potential within neurology and rehabilitation medicine, especially in pediatrics.5-9 Video recordings have a long history of being used in prediction, diagnosis, classification, and monitoring of neurodevelopmental and movement disorders. Key point detection by markerless motion analysis—also referred to as human pose estimation in the field of computer vision—can be used to process video data as an input for subsequent machine learning or deep learning models.10-14 Several open-source toolbox codes facilitate key point detection based on convolutional neural networks. 15 Examples of these toolbox codes are OpenPose 16 and DeepLabCut.17,18 DeepLabCut is flexible, allowing users to define own key points (eg, anatomical landmarks) and train models with a relatively small amount of labeled data using transfer learning. A customizable approach is especially interesting when video-based approaches are employed to assess small populations—such children and adolescents with dyskinetic cerebral palsy (CP).
Dyskinetic CP has an estimated global prevalence of 0.2 to 0.4 in every 1000 live births.19,20 Children and adolescents with dyskinetic CP experience severe functional problems during activities of daily living, such as mobility. Functional mobility ranges from walking to wheeled mobility with a head-foot steering system. 21 For mobility—be it walking or using a head-foot steering system—there is a need for controlled movements of the lower leg, ankle, and foot. These controlled movements are often disturbed in children and adolescents with dyskinetic CP through the presence of dystonia and choreoathetosis.22-24
With the current research we aim to advance the state-of-the-art in automated video-based movement analysis in dyskinetic CP by classifying dystonia and choreoathetosis during an active task. Clinically, in dyskinetic CP, experts assess amplitude and duration of distal leg dystonia and choreoathetosis from video recordings, which capture a combination of abnormal postures and involuntary movements. 25 However, this expert knowledge has not yet been translated into the clearly defined kinematic, frequency-, and time-domain features13,26 that are needed for a classical supervised machine learning approach.
As the extracted X,Y coordinates of key points from videos are time series data, a time series classification (TSC) method could be an effective method for the classification of distal leg dystonia and choreoathetosis. To train models, leveraging available retrospective data from international multi-center partnerships is crucial to achieve sufficiently large samples, given the small overall population of people with dyskinetic CP.
Against this background, the objective of the current study was to explore applying an ensemble TSC method to classify the amplitude and duration of distal leg dystonia and choreoathetosis in children and adolescents with dyskinetic CP. X,Y coordinates of key points for this classification task were extracted from videos recorded in previous studies during a heel-toe tapping task. In addition, within this study the pre- and post-processing steps necessary for the use of retrospective video data were explored.
Methods
Retrospective video data was assembled from 4 studies over the past 17 years. The primary studies (S66778, S60575, S66357, and S66834) as well as the secondary use of the data (S66544) was approved by the Medical Ethics Committee of the University Hospitals Leuven/KU Leuven. Written informed consent was obtained from participants and/or their parents for the primary studies, the secondary analysis was waivered for informed consent from the Medical Ethics Committee.
Participants
The initial available data set consisted of 86 videos of a heel-toe tapping task with the left and right leg, collected from 43 individuals. The group consisted of 38 participants with dyskinetic CP (ages 6-24 years) with varying functional levels as well as 5 typically developing peers, covering the entire spectrum from typical motor development to severely impaired. The inclusion and exclusion criteria of the primary studies are provided in the Supplemental Material Table S1. For the current analysis the only inclusion criteria was: an available video of the heel-toe tapping task in the 4 above mentioned studies. Please note that during data processing more data were removed from the data set due to following criteria. Videos were removed from the key point extraction step in DeepLabCut if any key point was either (1) occluded by clothing or (2) entirely out of the frame at any point in the video. Videos were removed from TSC (3) if no score for dystonia and choreoathetosis was available or (4) if any key point was not extracted beyond the set threshold in DeepLabCut for the entire duration of the video (eg, due to occlusion not recognized during visual inspection of the videos). Participants characteristics including age, gender, and Level of Gross Motor Classification System (GMFCS) were registered. 27
Protocol of Videos Recording and Clinical Scoring
Videos of the heel-toe tapping task were collected in previous studies as items of the Dyskinesia Impairment Scale (DIS). 25 The participants were asked to perform 5 repetitions of alternating heel-to-toe taps with the right leg (task 11 of the DIS) and with the left leg (task 12 of the DIS). The instruction of the DIS protocol is to film these tasks as a close-up of the lower limbs using a tripod 25 (Figure 1). Videos were recorded with a single RGB camera at a frame rate of 25 frames per second. There was variation in video resolution (720 × 576-1080 × 1920 pixels), length (00:05-01:16 minutes), camera angle, and the participant’s position in the frame. These differences, typical for a compiled retrospective video dataset, were addressed in the video preprocessing and post-processing phases.

Position of the camera. Participants were filmed from the front with a close-up of the lower limbs during the heel-toe taps using a tripod.
The videos were scored by 4 different raters within the original studies. All raters were either physiotherapists or occupational therapists and had undergone training for scoring using the Dyskinesia Impairment Scale (DIS). These raters scored dystonia and choreoathetosis according to the definitions: (1) distal leg dystonia including dystonia of the lower leg, ankle, and foot: that is, sustained muscle contractions causing abnormal posturing and/or distorted voluntary movements of the distal leg 25 and (2) distal leg choreoathetosis including choreoathetosis of the lower leg, ankle, foot: that is, constantly changing fragmented or contorting movements of the distal leg (chorea: jerky, stormy, and/or athetosis: wriggling and contorting). 25 The videos were scored on duration and amplitude on a scale 0 to 4 (Table 1).
Definition of Duration and Amplitude Factor of Dystonia (D) and Choreoathetosis (CA) Following the Dyskinesia Impairment Scale.
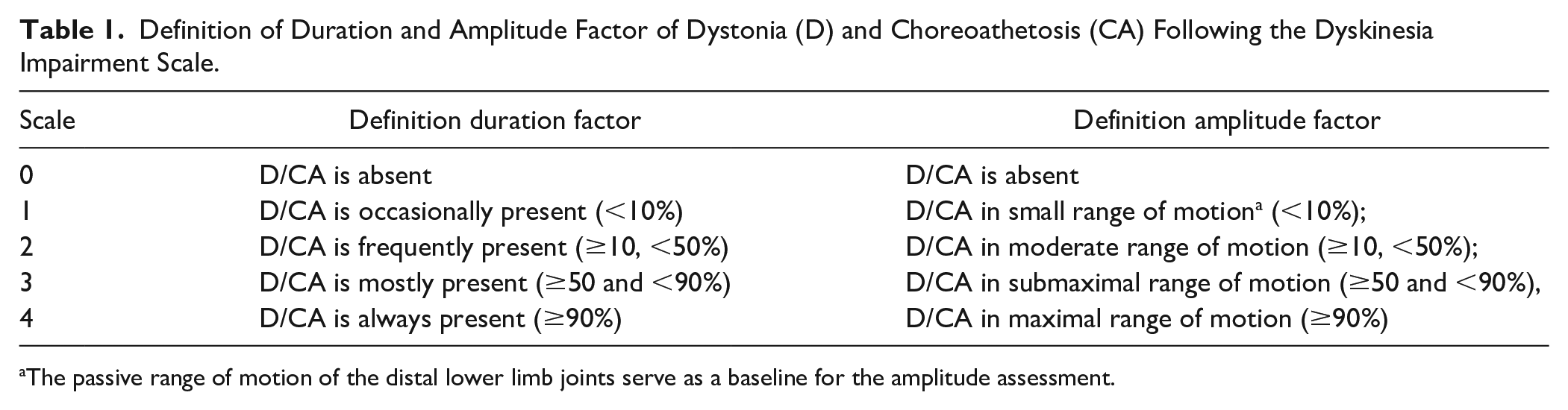
The passive range of motion of the distal lower limb joints serve as a baseline for the amplitude assessment.
Video Data Preprocessing
Video preprocessing was performed using commercial video editing software Adobe Premiere Pro 23.4 (Adobe Inc., San Jose, USA). First, all videos were visually inspected to ensure that all key points were visible for the full duration of each video. Inspection revealed several shaky and unstable videos, which may have been caused by a faulty tripod or incorrect tripod use. This camera motion is undesirable because it creates the illusion of participant motion and represents statistical noise that is difficult to correct in post-processing. Additionally, in 1 study the videos of individual tasks were combined into single, longer videos with transition effects (intros and outros) between individual tasks. These transition effects usually consisted of text on a black background and contained no useful information for markerless motion analysis. Another issue was that an assisting person was sometimes in the frame, usually early or late in the videos. Frames with helpers might confuse the markerless motion analysis algorithm.
The cleaning process involved (1) trimming, (2) stabilizing, and (3) cropping (Figure 2).
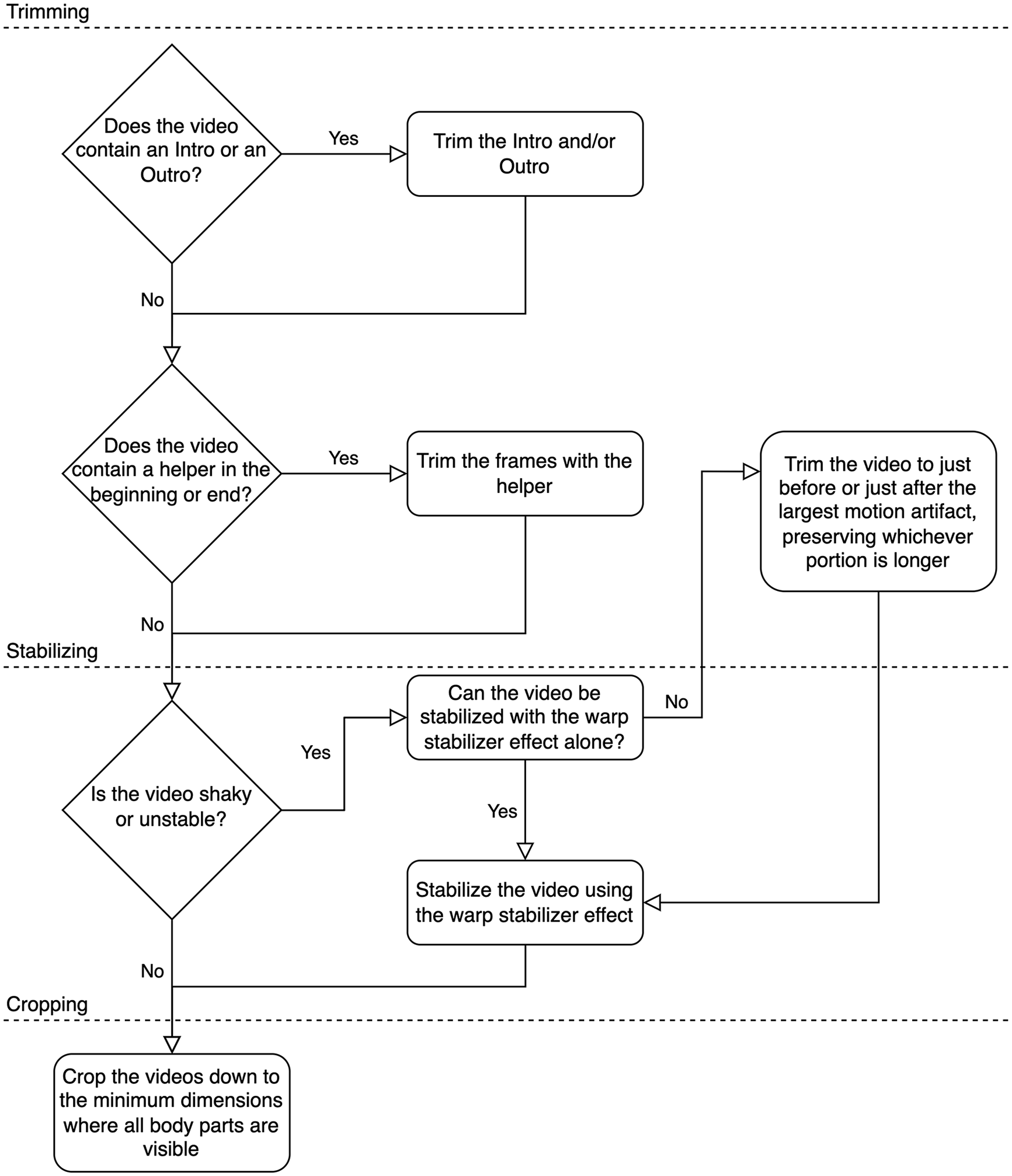
Steps of pre-processing of videos. Video preprocessing involved trimming (shortening), stabilizing (removing shakiness), and cropping (reducing the dimensions). These steps were applied algorithmically to ensure consistency.
(1) trimming: Intros and outros were trimmed, along with any frames in the beginning or end of a video containing helpers.
(2) stabilizing: Shaky videos were stabilized using a 2-step process, based on the extent of camera movement. For shaky videos with relatively small camera movements, the warp stabilizer effect in Adobe Premiere Pro was employed. The warp stabilizer could effectively negate small camera movements. Some videos contained a single large camera movement. In these cases, the video was trimmed to either end just before the large movement or begin just after the camera movement. The longer section of the video was always retained. If there were still small camera movements after single large movements were eliminated, the warp stabilizer effect was employed.
(3) cropping: The videos were cropped to the smallest possible dimensions that contained all key points. Removing much of the background, which contains no relevant information, decreased the training times for the markerless motion analysis algorithms by reducing the data the algorithms had to process during the training phase. Additionally, the warp stabilizer effect sometimes distorts or adds motion to stabilized videos’ backgrounds. Cropping the videos negated this undesirable effect. The fully processed (trimmed, stabilized, and cropped) videos were exported using the H.264 codec. We provide several recommendations in the discussion for future data collection of the heel-toe tapping task. These recommendations could eliminate certain pre-processing steps.
Key Point Extraction Using DeepLabCut
Markerless motion analysis was performed using DeepLabCut (version 2.3.0).17,18 Ten key points (ie, anatomical landmarks) on the knee, ankle, first metatarsal, third metatarsal, and hallux on both legs were labeled in 10 images of each video (Figure 3). The images were selected algorithmically by a k-means clustering algorithm included in the DeepLabCut toolbox. Approximately 95% of the labeled data was used for training, which is the default. The base neural network was ResNet-152 with default parameters. Three models were trained on 3 different shuffles of train-test data. Each model was trained for 1 000 000 iterations.
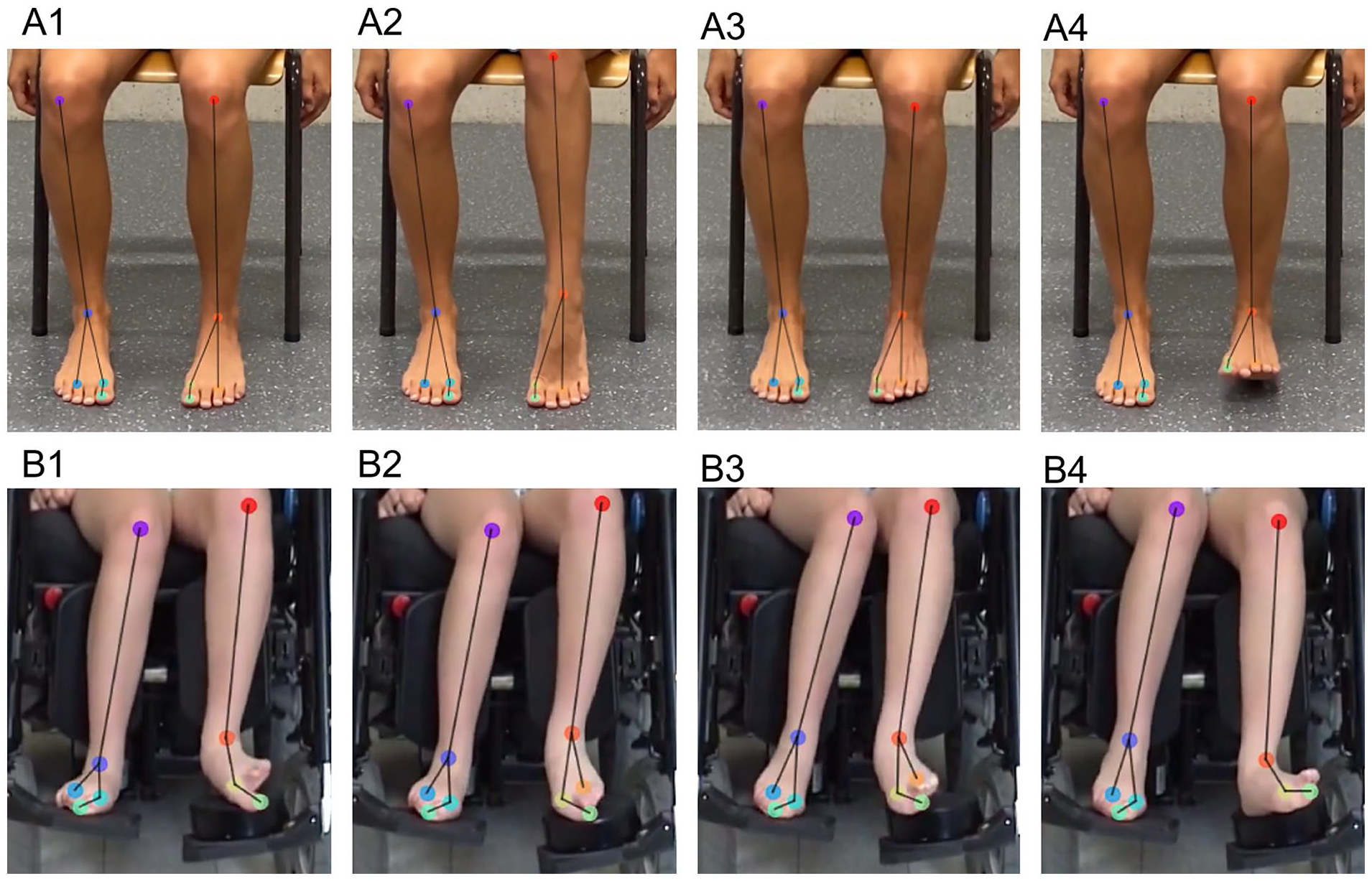
Key points within the preprocessed video overlayed by extracted X,Y coordinates. X,Y coordinates are extracted by markerless motion analysis on videos of the heel-toe-tapping task—applied to assess distal lower leg dystonia and choreoathetosis (A1 and B1 is neutral position, A2 and B2 is toe tapping, A3 and B3 is neutral position, and A4 and B4 is heel tapping). The task is repeated 5 times. A1 to A4: a participant with a scoring 0 for both dystonia and choreoathetosis amplitude and duration B1 to B4: a participant with a dystonia score of 4 and amplitude score of 4 and a choreoathetosis score of 1 and amplitude score of 1. Tracked key points were: knee (KNE), ankle (ANK), first metatarsal l (D1M), third metatarsal (D3M), and hallux (HLX), on the left and right legs. Skeleton data as segment are: KNE-ANK (lower leg), ANK-D3M (foot lateral), ANK-D1M (foot medial), and D1M-HLX (Dactyl).
The accuracy of key point tracking was assessed via mean absolute error (MAE; ie, Euclidean distance between the human and machine labels, in pixels). A P-cutoff of .8 was used to condition the X,Y coordinates for future analysis. A model was considered accurate if the MAE within the train and test dataset were similar before applying the P-cutoff. A low difference between the training and test datasets was used as indication that the model is not negatively impacted from excessive variance (over-fitting). The most accurate model was used to analyze the videos and extract X,Y coordinates and the skeleton data (segment lengths and orientations). Postprocessing (described below) was consecutively applied to these extracted X,Y coordinates and skeleton data. The trained DeepLabCut model and extracted data are provided and can be used to start markerless motion analysis of new heel-toe-tapping task data. 28
Post-Processing
The purpose of post-processing was to further clean X,Y coordinates and skeleton data of the key points and to transform the data into a format that could be used by the TSC algorithm. There were 5 main post-processing steps: (1) mirroring, (2) gap-filling, (3) filtering, (4) spatial normalization, and (5) temporal normalization. The steps are described in detail below; the post-processed dataset is available online as well as the customized python code to perform the post-processing steps 28 :
(1) Mirroring: The first step in post-processing was to mirror the X trajectories and skeleton orientations in the left-leg videos to mimic the videos of the right leg. By mirroring the left-leg videos to resemble the right-leg videos, we halved the number of models to be trained, while doubling the amount of data available to train the models. Concretely, each participant had 2 sets of X,Y coordinates and skeleton data in the final data set for TSC.
(2) Gap-filling: When DeepLabCut analyzes a video, it returns an X,Y coordinate for each key point in each video frame along with a corresponding likelihood value, which is the network’s confidence in its output. We removed coordinates with a likelihood less than 0.8. This relatively high likelihood threshold, or P-cutoff, was selected a-priori based on previous studies using DeepLabCut for human movement analysis13,29 and because false positives were deemed to be more detrimental than false negatives. However, a high P-cutoff can result in gaps, which were addressed with a gap-filling algorithm. In the current dataset 4% ± 10% (mean ± Standard deviation; range:0%-67%) of data points were lost due to the P-cut off. These gaps in the data were filled using multivariate iterative imputation, 11 which predicts missing values based on all the other values in a multivariate dataset. This approach was robust and could realistically fill gaps in the cyclical and irregular data. In detail, the Iterative Imputer function used was built into the scikit-learn library, 30 which is based on the multivariate imputation of Chained Equation (mice) package in R. 31 For an example of gaps filled with multivariate imputation, see Supplemental Material Figure S1. The gap-filling algorithm was effective but sometimes resulted in local spikes in the data (see example Supplemental Material Figure S2).
(3) Filtering: To remove these local spikes (sometimes generated during gap-filling)), a second-order Savitzky-Golay filter 32 from the SciPy Signals library 33 was used. By using a relatively small moving window (10 frames or 0.4 seconds), this filter effectively removed the spikes while largely preserving the complexity of the data (see as example S2).
(4) Spatial normalization: Differences in camera resolution and participant positioning led to wide variations in the scale of movement and skeleton data extracted from the videos. To transform the data into a common spatial reference frame, the X,Y coordinates and the segment lengths in each video were scaled based on the longest length of the active lower leg (segment length knee-ankle)
(5) Temporal normalization: The TSC algorithm required each time series to be of equal length. After cropping, the videos ranged in length from 6 to 55 seconds. Each video was elongated to 1 minute (1500 frames) using a 2-step process. First, the data was time-mirrored, then concatenated to the original data. This process continued until the video exceeded 1500 frames, at which point it was trimmed to exactly 1500 frames (Supplemental Material Figure S3). Time-mirroring the data allowed the time series to remain continuous without large jumps. The effect would be like watching the videos forwards then backwards until 1 minute elapsed.
Time Series Classification Using HIVE-COTE 2.0
A time- and computationally-efficient ensemble method for TSC, namely Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE 2.0) has been recently developed. 34 HIVE-COTE 2.0 is a meta-ensemble of 4 TSC algorithms: (1) Shapelet Transform Classifier, 35 (2) Arsenal (itself an ensemble of ROCKETs), 36 (3) Diverse Canonical Interval Forest Classifier, 37 and (4) Temporal Dictionary Ensemble. Each model is fitted to the data and assigned a weight. The final prediction is based on a weighted average of the predictions of each sub-model. HIVE-COTE 2.0’s main advantage is that it utilizes an entire multivariate time series to classify data rather than relying on summary statistics. The data was divided into training and test splits using 5-fold subject-wise stratified cross-validation (ie, heel-toe tapping task with the left and right leg right and left were stratified to the same fold) .Separate HIVE-COTE 2.0 models were fitted to each train-test split for each outcome measure (dystonia duration, dystonia amplitude, choreoathetosis duration, choreoathetosis amplitude of the lower leg), meaning 20 models were trained (4 outcome measures × 5-fold validation). The models were trained using the default parameters for each sub-model. Training times for each model were approximately 3 hours using an AMD Ryzen 5950x CPU (AIME GmbH, Berlin, Germany). The python environment, demonstration code, and anonymized datasets are available. 28 Models are evaluated by calculating false and true positives and negatives for each of the folds of the 5-fold cross-validation (FP, FN, TP, and TN) for all classes (ie, DIS-score 0, 1, 2, 3, and 4; Supplemental Material Figure S4A-E). A confusion matrix of the predictions was made and evaluated by the calculation of multiclass classification metrics. Overall accuracy was calculated (equation (1)).
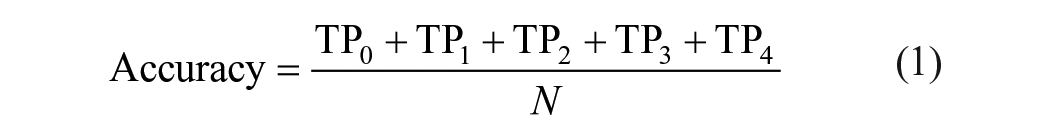
Precision, sensitivity (also known as recall), and F1-score were calculated for each class (k; k is 0, 1, 2, 3, and 4; equations (2-4)) 38 :
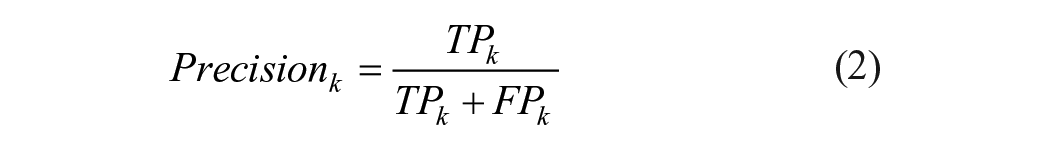
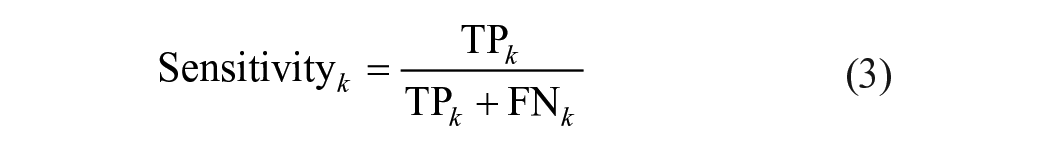
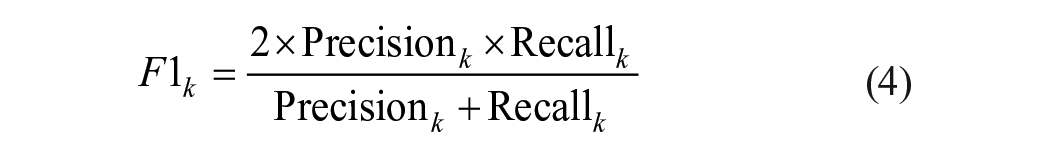
To gain information about the presence or absence of dystonia or choreoathetosis, the DIS score was also summarized to “dystonia/choreoathetosis is present” (ie, DIS score: 1-4) or “dystonia/choreoathetosis is absent” (ie, DIS score: 0; Supplemental Material Figure S4. F). From these summarized scores also the accuracy, precision, sensitivity, and F1 score as well as specificity were calculated (equations (1-5)).
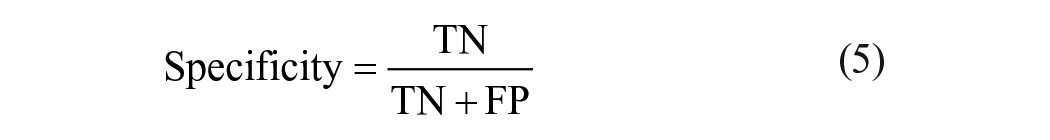
Results
Participants
From the initial dataset of 43 participants (86 videos), 5 participants were removed before key point extraction. Four participants with dyskinetic CP were removed because at least 1 key point was not in the frame at some point during the video (ie, video was recorded below the knees). One typically developing participant was removed due to occlusions by clothing (ie, a dress that covered the knees). Prior to TSC, 5 more participants were removed. Four participants with dyskinetic CP were removed because their videos were not scored for dystonia and choreoathetosis in the original study. Finally, 1 participant with dyskinetic CP was removed due to a postural occlusion; due to extreme ankle inversion, a key point on the foot was not visible for the entire duration of the video. The inclusion of videos/participants in the final data set is summarized in a flow diagram (Figure 4).
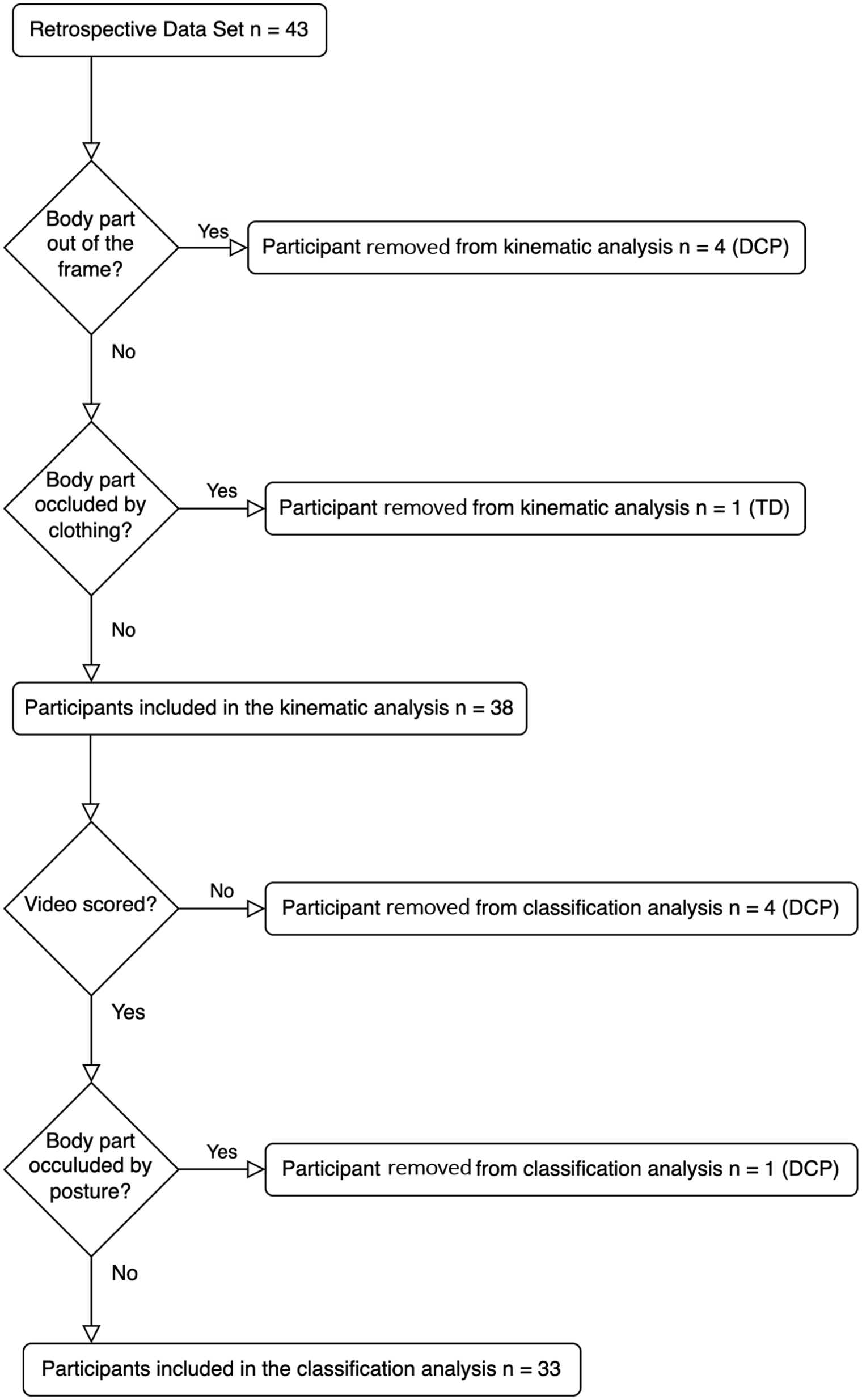
Flow diagram of inclusion. From an initial retrospective video dataset of 43 participants, 38 were included in the key point extraction step using DeepLabCut and 33 were included in Time Series Classification (TSC). In total, 9 participants with dyskinetic cerebral palsy (DCP) and 1 typically developing (TD) participant were removed from the initial dataset.
Characteristics of the 33 participants (29 with dyskinetic CP/4 typically developing) within the final dataset for the classification analysis were: age 14 years:6 months ± 5 years:1 months (mean ± Standard deviation(SD)), 13 females/20 males, GMFCS: no CP (n = 4) that is, typically developing, GMFCS I (n = 7), GMFCS II (n = 6), GMFCS III (n = 5), GMFCS IV (n = 3), and GMFCS V (n = 8).
Videos and Clinical Scores
DIS scores were available for 66 videos (33 of the left leg, 33 of the right leg). The median (inter-quartile range) of dystonia duration and amplitude were 4 (1) and 4 (2), respectively and for choreoathetosis duration 1 (2) and amplitude 1.5 (2). The distribution of scores is plotted in the Supplemental Material Figure S5.
Keypoint Extraction DeepLabCut
The most accurate DeepLabCut model had a MAE of 2.88 pixels within the test dataset (Shuffle 2), this model was consequently used to extract the X,Y key point coordinates for in further analysis. Results of all 3 shuffles are available in the Supplemental Material Table S2.
Performance HIVE-COTE 2.0 to Predict Low Leg Dystonia and Choreoathetosis
Calculating the summarized metrics for absent or present of dystonia (ie, DIS score 0 vs DIS score 1-4) revealed an accuracy of 81% for dystonia duration and 77% for dystonia amplitude. Precision, sensitivity, F1 Score, and specificity were above 0.90 for both dystonia duration and amplitude; low specificity was only observed in dystonia duration (0.64). Accuracy of the absent/present choreoathetosis score was 53% for both duration and amplitude and revealed scores between 0.50 and 0.80 for precision, sensitivity, F1 score, and specificity (Table 2).
Performance Metrics.
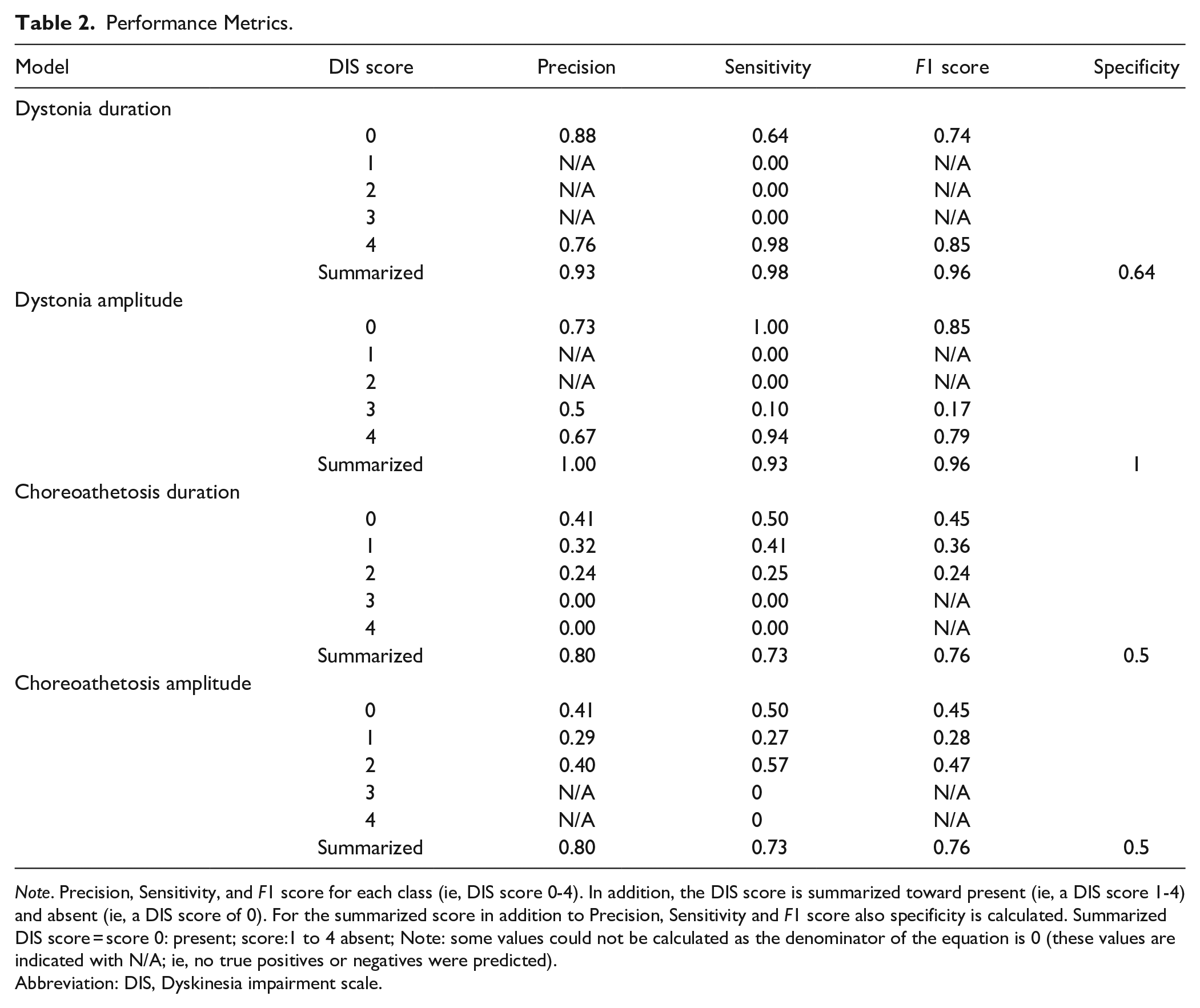
Note. Precision, Sensitivity, and F1 score for each class (ie, DIS score 0-4). In addition, the DIS score is summarized toward present (ie, a DIS score 1-4) and absent (ie, a DIS score of 0). For the summarized score in addition to Precision, Sensitivity and F1 score also specificity is calculated. Summarized DIS score = score 0: present; score:1 to 4 absent; Note: some values could not be calculated as the denominator of the equation is 0 (these values are indicated with N/A; ie, no true positives or negatives were predicted).
Abbreviation: DIS, Dyskinesia impairment scale.
The confusion matrices of dystonia duration and amplitude as well as choreoathetosis duration and amplitude for all classes are given in Figure 5. The accuracy results for multiclass prediction of lower leg dystonia measures were 77% for duration and 68% for amplitude. The accuracy results for lower leg choreoathetosis were 30% for duration and 38% for amplitude.
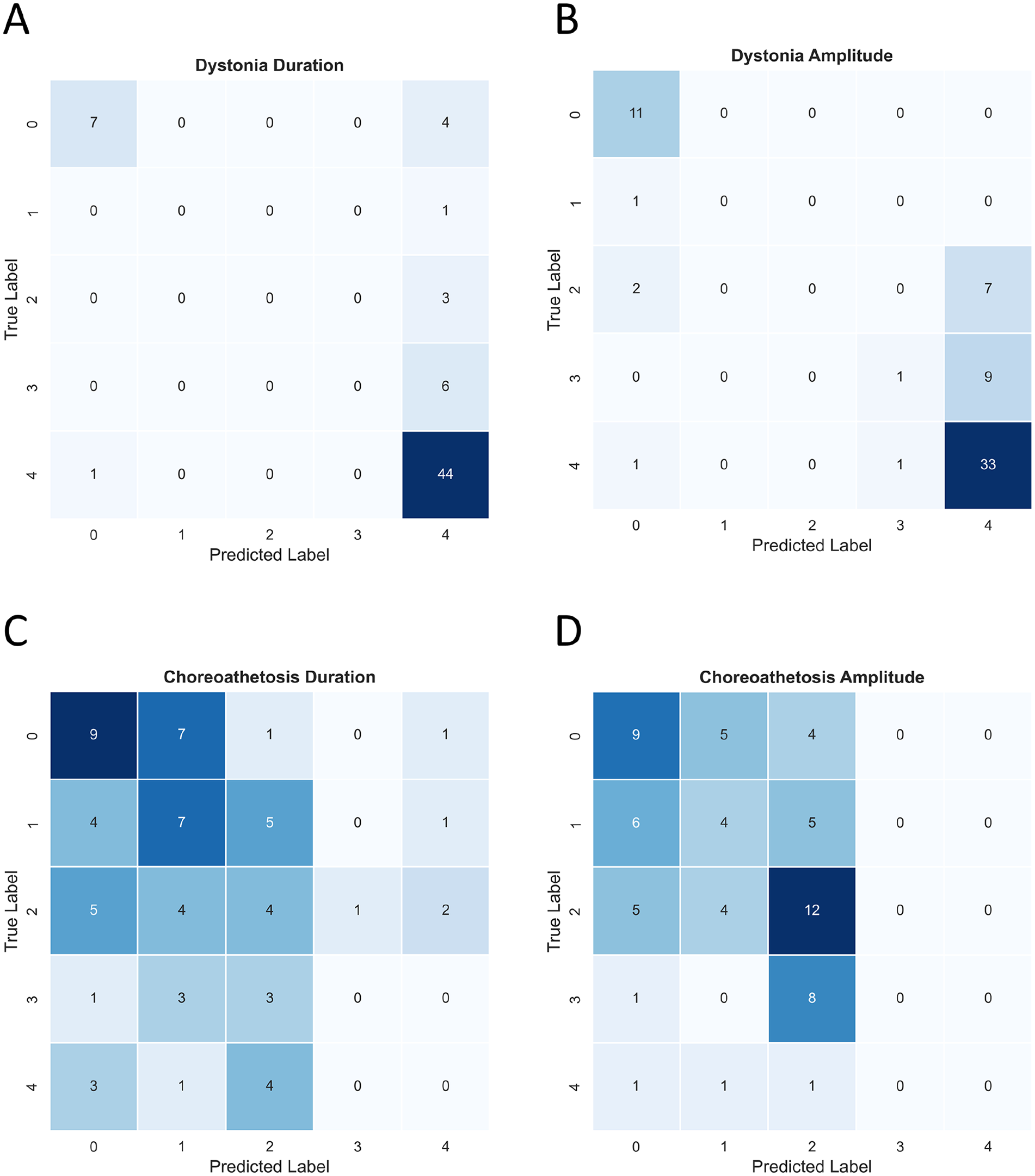
Confusion matrices for Time Series Classification (TSC) of dystonia and choreoathetosis duration and amplitude classification on the Dyskinesia Impairment Scale (DIS). (A) dystonia duration; (B) dystonia amplitude; (C) choreoathetosis duration; and (D) choreoathetosis amplitude. The confusion matrix results from 5-fold cross-validation. Each participant is represented twice in the final dataset, for a total of 66 predicted labels.
Performance metrics for dystonia duration and amplitude ranged for precision from 0.50 to 0.88, for sensitivity from 0.00 to 0.98, and F1 score from 0.17 to 0.85, with the highest values always corresponding to score 0 and score 4 (Table 2). Overall, performance metrics for choreoathetosis were lower than for dystonia. Choreoathetosis duration and amplitude ranged for precision from 0.24 to 0.41, for sensitivity from 0.25 to 0.57, and F1 score from 0.24 to 0.47.
Discussion
The objective of this study was to explore the feasibility of applying an ensemble TSC method to classify amplitude and duration of distal leg dystonia and choreoathetosis in children and adolescents with dyskinetic CP using a retrospective dataset assembled from different studies. To our knowledge, this is the first study that shows the potential of a TSC algorithm to classify movement disorders from time series data extracted from common videos. Overall, the results are encouraging especially for the summarized scores of dystonia.
In more detail, among the summarized dystonia duration scores metrics specificity of dystonia amplitude was very high with a value of 1, meaning that no participants without dystonia were predicted as having dystonia by the model on amplitude. On the other hand, specificity was low for dystonia duration (0.6), meaning that 40% of participants without dystonia were predicted. as having dystonia by the model on duration. Reflecting the results for all classes, accuracy was considered acceptable (about 70%) and had promising results especially within the classes 0 and 4. However, the results for the classes in the middle of the scoring system (1, 2, and 3) were low. This low performance was likely due to the scarcity of data within these classes, raising the question of the usefulness predicting these classes with the current dataset. This interpretation also applies to the classification of choreoathetosis, with very low performance metrics for the distinct classes. For choreoathetosis, only the summarized scores (ie, present/absent) lead to results for precision, sensitivity and F1 Score that can be considered acceptable, but a low specificity (ie, 0.50), meaning that 50% of participants without choreoathetosis were predicted as having choreoathetosis by the model.
Concerning clinical applicability of the proposed approach, a simple model only classifying presence or absence of movement disorders might be useful as a first screening instrument in a clinical context. The development of such an application is feasible, especially given the high precision and sensitivity of the current explorative models. If dystonia or choreoathetosis is detected by the model, a human could assess the classes (ie, 1-4) and re-score false positive findings. Such an approaches of combining human and AI have been recently proposed for the classification of dermoscopic images within skin cancer diagnostics 39 or image-based diagnostics of breast, lung, gastrointestinal and endocrine cancer from ultrasound, X-ray, CT, or MRI. 40
This methodology study utilized the TSC method HIVE-COTE 2.0. 34 An advantage of algorithm is that it automatically extracts features from multivariate time series, thus obviating the need for feature engineering. However, this on the other hand means that the automated generate features cannot be clinically validated for their usefulness. To overcome this disadvantage, options for knowledge distillation from the TSC should be explored for the current use case 41 for example understanding features or shapelets used by the algorithm for classification of dystonia and choreoathetosis duration and amplitude. Previous comparable studies made use of classical supervised machine learning approach such as k-Nearest Neighbors, Support Vector Machine, Random Forests, and Quadratic Discriminant Analysis using handcrafted features as well as deep learning approaches.10-13 A comparison between HIVE-COTE 2.0 and the use of different algorithms on the current use case is deemed necessary in the future.
Apart from pilot results, the current work provides a working methodology for retrospective video data. The provided pipeline includes a methodology to pre-process videos, a trained DeepLabCut model to use on a new dataset for a heel-toe-tapping task (note that for tracking challenging cases, the addition of extra manual labels and retraining of the model might be necessary) and a code for post-processing the extracted X,Y coordinates of key points from DeepLabCut for the ensemble TSC algorithm. 28 The pipeline can be easily adapted to other X,Y coordinates of key points and skeleton data and thereby applied to other DIS items assessing other body region (eg, upper extremity and trunk) or even to other clinical scales for assessment of movement disorders from video recordings.
Limitations
An important limitation of the study was the relatively small sample size, however even this small dataset allowed us to train a model that can automatically assess the absence or presence of dystonia of the lower leg with a high precision and sensitivity and an acceptable specificity. To account for the small dataset size, 5-fold cross-validation, effectively using the whole dataset as test set, was applied. To prevent an overestimation of performance, subject-wise stratification was applied. Future models for automated classification of dystonia and choreoathetosis should additionally be tested on holdout datasets or newly collected datasets. 42 Furthermore, the explorative analysis was limited to 1 body region (ie, lower leg distal) and to the active task. In clinical practice the rest and activity score of several body regions would be aggregated to calculate a global score for dystonia and choreoathetosis to increase validity of classification. 25 Also, the imbalanced nature of the dataset likely affected the model’s performance. By including videos of participants across all functional levels (GMFCS I-V) and typically developing peers, we anticipated an equal distribution of dystonia and choreoathetosis scores across the classes. However, there was a scarcity of data for classes 1, 2, and 3 for dystonia and limited scores within classes 3 and 4 for choreoathetosis. As imbalanced medical datasets are common in real-world problems, techniques to balance these datasets, such as creating synthetic samples, 43 are increasingly studied and should be taken into account within the next step of the proposed approach. Finally, pre- and postprocessing of the data may have potentially affected the results of the TSC. For example, trimming the videos may have led to the omission of proportions of the video that were relevant for human raters, but which were not used to the training of the model. However, this effect is estimated to be low as the movement disorder is mostly quite consistent over a short time periods. Possible also temporal normalization might have induced low frequent oscillations. These potential negative effects of pre- and postprocessing steps can be minimized within future data collection by standardizing video length (see “Recommendations to facilitate prospective video data” section).
Future Perspectives
To improve model performance, a larger and more representative dataset is needed. One barrier to obtaining a large video dataset of patients with movement disorders from different institutions is privacy issues. A possible solution is to use federated learning 44 for the key point extraction with DeepLabCut, meaning that only trained models are transferred and pre-processing of videos and markerless motion analysis is performed locally. Then only extracted X,Y coordinates and skeleton data of key points (containing no privative sensitive information) can be aggregated for further analysis.
Another issue is that the scoring of the videos is quite time consuming. Ideally, videos should be scored by several experienced raters to compensate for inter-rater differences. Semi-supervised outlier detection could possibly be valuable in this context. 45 For example, a model could be trained on healthy subjects performing a task, then anomaly detection could be performed on the clinical dataset, 46 where anomalies would be expected to correlate with the severity of the movement disorder.
Recommendations to Facilitate Prospective Video Data
To facilitate prospective video data collection for automated classification of movement disorders, video protocols should be further standardized. The recommendations are: (1) a standardized camera placement concerning stability and a horizontal camera’s shooting angle (ie, camera fixated horizontally with a very stable tripod see Figure 1), (2) a well-defined body section (for the heel-toe-tapping task, we recommend a section just distal of the hip, with the knee, ankle and toes visible as presented in the cropped section in Figure 3), (3) a constant video resolution and a known distance in the video to make the tracking error interpretable (ie, not using the zoom of the camera but adjusting the distance between the participant and the camera to reach the optimal section as presented in Figure 3), (4) the same video length for all participants, and (5) standardization of the speed of performance of 5 repetitions. This needs to be a low speed that all participants can perform the task within the same time. These recommendations would increase the validity and reliability of future analyses.
Conclusion
In summary, a new way to automatically score movement disorders is proposed, namely to use data extracted by markerless motion capture from videos with an ensemble TSC algorithm to predict dystonia and choreoathetosis scores. The TCS method used represents a fully automated approach, where features are learned directly from the data, rendering them particularly well suited for a future use in a large dataset. In the current methodology study, the ensemble TSC achieved promising results concerning the classification of the absence and presence of dystonia (but less for choreoathetosis). The method thereby shows the potential to assist classification and monitoring of movement disorders in childhood in the future.
Supplemental Material
sj-pdf-1-nnr-10.1177_15459683241257522 – Supplemental material for A Novel Video-Based Methodology for Automated Classification of Dystonia and Choreoathetosis in Dyskinetic Cerebral Palsy During a Lower Extremity Task
Supplemental material, sj-pdf-1-nnr-10.1177_15459683241257522 for A Novel Video-Based Methodology for Automated Classification of Dystonia and Choreoathetosis in Dyskinetic Cerebral Palsy During a Lower Extremity Task by Helga Haberfehlner, Zachary Roth, Inti Vanmechelen, Annemieke I. Buizer, Roland Jeroen Vermeulen, Anne Koy, Jean-Marie Aerts, Hans Hallez and Elegast Monbaliu in Neurorehabilitation and Neural Repair
Footnotes
Acknowledgements
The authors want to acknowledge the contribution of Thomas Van Eeckhoven through discussions of the topic within the research group.
Author Contributions
Helga Haberfehlner: Conceptualization; Data curation; Formal analysis; Funding acquisition; Investigation; Methodology; Project administration; Software; Supervision; Validation; Visualization; Writing—original draft; Writing—review & editing. Zachary Roth: Formal analysis; Investigation; Methodology; Software; Validation; Visualization; Writing—original draft; Writing—review & editing. Inti Vanmechelen: Methodology; Writing—original draft; Writing—review & editing.
Annemieke Buizer: Conceptualization; Data curation; Funding acquisition; Resources; Writing—review & editing. R. Jeroen Vermeulen: Conceptualization; Data curation; Resources; Writing—review & editing. Anne Koy: Conceptualization; Data curation; Resources; Writing—review & editing. Jean-Marie Aerts: Conceptualization; Methodology; Supervision; Validation; Writing—review & editing. Hans Hallez: Conceptualization; Methodology; Supervision; Validation; Writing—review & editing. Elegast Monbaliu: Conceptualization; Data curation; Funding acquisition; Methodology; Project administration; Supervision; Writing—review & editing.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Helga Haberfehlner is funded by the Research Foundation Flanders (FWO; SoE fellowship_12ZZW22N).
Data Availability Statement
Supplementary material for this article is available on the Neurorehabilitation & Neural Repair website along with the online version of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.