
Abstract
In this article, we describe a computational implementation of the synthetic difference-in-differences (SDID) estimator of Arkhangelsky et al. (2021, American Economic Review 111: 4088-4118) for Stata. SDID can be used in many circumstances where treatment effects on some particular policy or event are desired and repeated observations on treated and untreated units are available over time. We lay out the theory underlying SDID both when there is a single treatment adoption date and when adoption is staggered over time, and we discuss estimation and inference in each of these cases. We introduce the sdid command, which implements these methods in Stata, and provide several examples of use, discussing estimation, inference, and visualization of results. Along with SDID, the sdid command allows for the implementation of standard synthetic control and difference-in-differences methods in an identical framework, permitting estimation, inference, and the generation of graphical output in a computationally efficient way.
Keywords
Introduction
There has been a recent explosion in advances in econometric methods for policy analysis. A particularly active area is estimating the impact of exposure to some particular event or policy when observations are available in a panel or repeated cross-section of groups and time (see, for example, recent surveys by de Chaisemartin and D’Hault-fauille [2022], Roth et al. [2022], and Arkhangelsky and Imbens [2023] for reviews of these methods). A modeling challenge in this setting is determining what would have happened to exposed units had they been left unexposed. Should such a counterfactual be estimable from underlying data, causal inference can be conducted by comparing outcomes in treated units with those in theoretical counterfactual untreated states under the potential-outcome framework (Holland 1986; Rubin 2005).
Many empirical studies in economics and the social sciences more generally seek to estimate effects in this setting using difference-in-differences (DID) designs. Here impacts are inferred by comparing treated units with control units, where time-invariant-level differences between units are permitted as well as general common trends. However, the drawing of causal inferences requires a parallel-trends assumption, which states that in the absence of treatment, treated units would have followed parallel paths to untreated units. Whether this assumption is reasonable in a particular context is an empirical issue. Recently, several methodologies have sought to loosen this assumption. These include procedures in which counterfactual trends can be assumed to deviate from parallel, leading to partial identification (Manski and Pepper 2018; Rambachan and Roth 2023), flexible procedures to adequately control for any prevailing differences between treated and control units (Bilinski and Hatfield 2018) often based on pretreatment periods only (Bhuller et al. 2013; Goodman-Bacon 2021), and instrumental-variables methods that explicitly consider dynamics in pretreatment periods (Freyaldenhoven, Hansen, and Shapiro 2019).
In many cases, parallel trends may be a questionable modeling assumption. One particular solution to the challenge has been the application of synthetic control (SC) methods. Early work in SC methods explores the setting of comparative case studies, where a single treated unit is observed and one wishes to construct a matched SC from a larger number of potential donor units (Abadie and Gardeazabal 2003; Abadie, Diamond, and Hainmueller 2010, 2015). These methods seek to generate a single SC from a unique convex weighting of underlying control units such that this SC is as closely matched as possible to the treated unit in pretreatment outcomes and potentially other covariates. These weights are optimally generated and fixed over time, potentially assigning zero weight to certain control units and larger weights to others. This has attracted considerable attention in both empirical applications and theoretical extensions, with recent advances including debiasing procedures (Ben-Michael, Feller, and Rothstein 2021) that can additionally house multiple treatment units (Abadie and L’Hour 2021), more flexible weighting schemes, or constant fixed differences between treated and SC units (Doudchenko and Imbens 2016; Ferman and Pinto 2021).
A recent particularly flexible modeling option that can be applied in panel-data settings seeks to bridge the DID and SC procedures. Arkhangelsky et al. (2021) propose the synthetic difference-in-differences (SDID) estimator, which combines strengths from both the DID and SC methods. Like DID models, SDID allows for treated and control units to be trending on entirely different levels prior to a reform of interest. And like SC methods, SDID seeks to optimally generate a matched control unit that considerably loosens the need for parallel-trends assumptions. Correspondingly, SDID avoids common pitfalls in standard DID and SC methods—namely, an inability to estimate causal relationships if parallel trends are not met in aggregate data in the case of DID and a requirement that the treated unit be housed within a “convex hull” of control units in the case of SC. Arkhangelsky et al. (2021) propose estimation and inference procedures, formally proving consistency and asymptotic normality of the proposed estimator. Furthermore, the authors briefly discuss several important applied points such as how their estimator can incorporate covariates and how their estimator can be applied to both multiple treatment units and even multiple treatment units that adopt treatment in different time periods.
In this article, we describe the sdid command, which implements the SDID estimator in Stata. This command allows for the simple implementation of the SDID estimator provided that a strongly balanced panel or repeated cross-section of data is available covering groups and time periods. The command, written principally in Mata, seamlessly incorporates cases where there is a single treated unit, multiple treatment units, and multiple treatment periods. It reports treatment effects laid out in Arkhangel-sky et al. (2021), additionally implementing their proposed bootstrap, jackknife, and placebo inference procedures. Several graphical output options are provided to examine the generation of the SDID estimator and the underlying optimal weight matrices. While principally written to conduct SDID estimation, the sdid command (and the SDID method) nests SC and DID as possible estimation procedures that can be easily generated to allow comparison of estimation procedures and estimates. 1 The sdid command is written in a computationally efficient way, largely implemented in Mata and adopting effective optimization algorithms. Thus, although its main use is likely in implementing SDID methods, it is potentially a useful tool for standard SC estimation and inference.
Stata provides a rich environment for panel-based analysis in DID and SC settings, and it is useful to understand how
In introducing the
Methods
The canonical SDID procedure
The SDID procedure was developed in Arkhangelsky et al. (2021), and we lay out its principal details here. As input, SDID requires a balanced panel of N units or groups, observed over T time periods. An outcome, denoted Yit, is observed for each unit i in each period t. Some (but not all) of these observations are treated with a specific binary variable of interest, denoted Wit. Wit = 1 if observation i is treated by time t; otherwise, Wit = 0 if observation i is untreated at time t. Here we assume that there is a single adoption period for treated units, which Arkhangelsky et al. (2021) refer to as a “block treatment assignment”. In section 2.3, we extend this to a “staggered adoption design” (Athey and Imbens 2022), where treated units adopt treatment at varying points. A key element of both of these designs is that once treated, units are assumed to remain exposed to treatment thereafter. In the particular setting of SDID, no always-treated units can be included in estimation. For estimation to proceed, we require at least two pretreatment periods off of which to determine control units. In practice, for generating good matched controls, more pretreatment periods are required (refer to the discussion in section 5).
The goal of SDID is to consistently estimate the causal effect of receipt of policy or treatment Wit (an average treatment effect on the treated, or ATT), even if we do not believe in the parallel-trends assumption between all treatment and control units on average. Estimation of the ATT proceeds as follows:
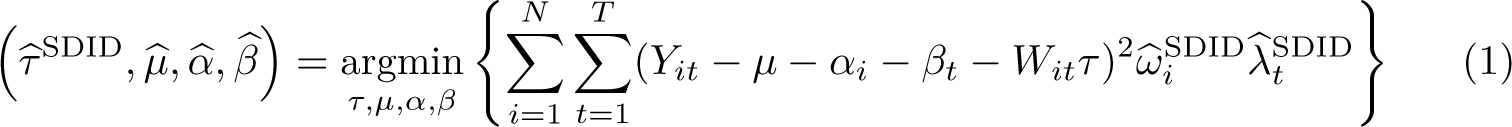
In this setting, it is illustrative to consider how the SDID procedure compares with the traditional SC method of Abadie, Diamond, and Hainmueller (2010), as well as the baseline DID procedure. The standard DID procedure consists of precisely the same twoway fixed-effects ordinary least-squares (OLS) procedure, simply assigning equal weights to all time periods and groups:
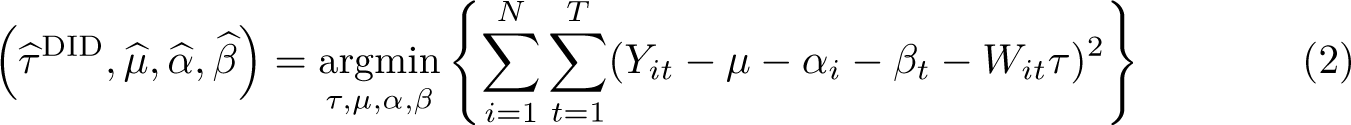
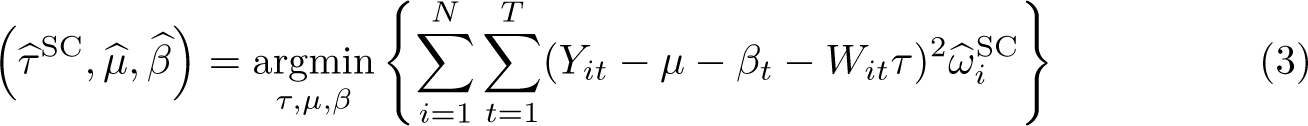
The selection of unit weights, ω, as inputs to (1) [and (3)] seeks to ensure that comparison is made between treated units and controls that were approximately following parallel trends prior to the adoption of treatments. The selection of time weights, λ, in the case of SDID seeks to draw more weight from pretreatment periods that are more similar to posttreatment periods in the sense of finding a constant difference between each control unit’s posttreatment average and pretreatment weighted averages across all selected controls. Specifically, as laid out in Arkhangelsky et al. (2021), unit-specific weights are found by resolving
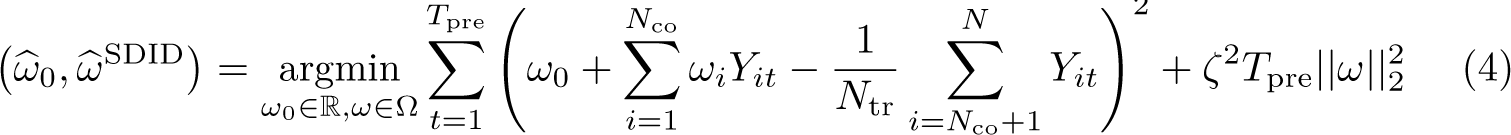
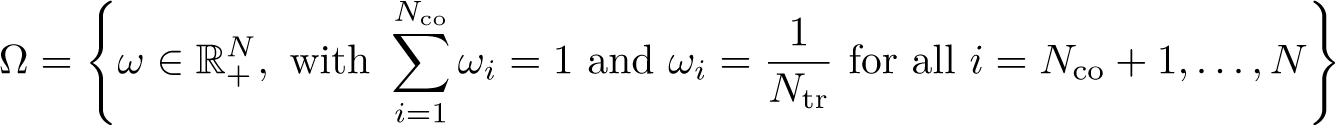
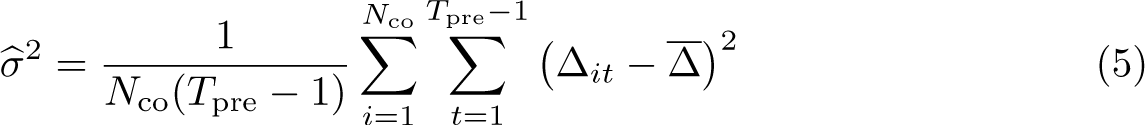
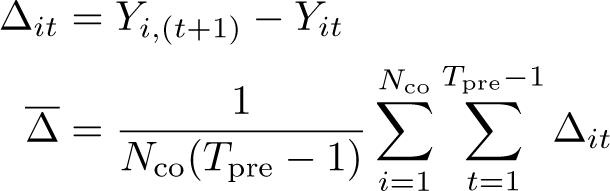
This procedure leads to a vector of Nco nonnegative weights plus an intercept ω0. The weights ωi for all
For time weights, a similar procedure is followed, finding weights that minimize the objective function
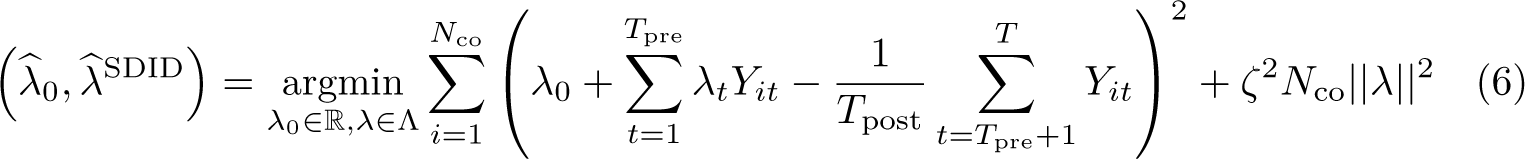
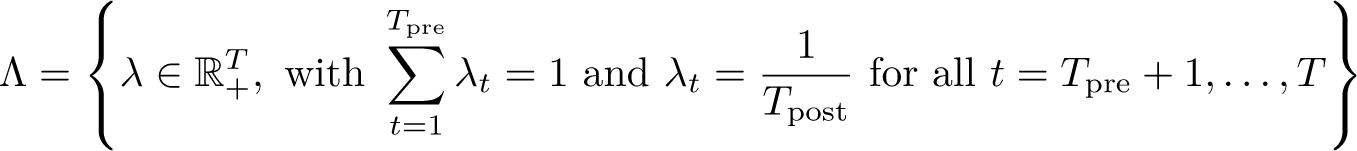
This estimation procedure is summarized in Arkhangelsky et al. (2021, algo. 1), reproduced in online appendix A1 for ease of access. Arkhangelsky et al. (2021) also prove that the estimator is asymptotically normal, suggesting that confidence intervals on τ can be constructed as
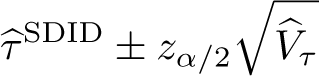
The block (also known as clustered) bootstrap approach consists of taking some large number, B, of bootstrap resamples over units, where units i are the resampled blocks in the block bootstrap procedure. Provided that a given resample does not consist entirely of treated or control units, the quantity
An alternative method that significantly reduces the computational burden inherent in the bootstrap is estimating a jackknife variance for
Given limits to these inference options when there are few treated units, an alternative placebo (or permutation-based) inference procedure is proposed. This consists of first conserving just the control units and then randomly assigning the same treatment structure to these control units as a placebo treatment. Based on this placebo treatment, we then reestimate
So far, we have limited exposition to cases where one wishes to study outcomes Yit and their evolution in treated and SC units. However, in certain settings, it may be of relevance to condition on exogenous time-varying covariates Xit. Arkhangelsky et al. (2021) note that in this case, we can proceed by applying the SDID algorithm to the residuals calculated as

A first potential issue is purely numerical. In the Frank-Wolfe solver discussed above, a minimum point is assumed to be found when successive iterations of the solver lead to arbitrarily small changes in all parameters estimated.
2
Where these parameters include coefficients on covariates, the solution found for (1) can be sensitive to the scaling of covariates in extreme cases. Particularly, this occurs when covariates have very large magnitudes and variances. In such cases, the inclusion of covariates in (1) can cause optimization routines to suggest solutions that are not actually globally optimal, given that successive movements in
A second (and potentially more complicated) point is described by Kranz (2022). He notes that in certain settings, specifically where the relationship between covariates and the outcome vary over time differentially in treatment and control groups, the procedure described above may fail to capture the true relationship between covariates and the outcome of interest and may subsequently lead to bias in estimated treatment effects. He proposes a slightly altered methodology of controlling for covariates. Namely, his suggestion is to first estimate a two-way fixed-effects regression of the dependent variable on covariates (plus time- and unit-fixed effects) using only observations that have yet to be exposed to treatment, that is, subsetting to observations for which Wit = 0. Based on the regression
We document these methods based on several empirical examples in the following section. Note that regardless of which procedure one uses, the implementation of SDID follows the suggestion laid out in Arkhangelsky et al. (2021, n. 4) and (7) above. What varies between the former and the latter procedures discussed here is the manner with which one estimates coefficients on covariates,
The design discussed up to this point assumes block assignment or that all units are either controls or treated in a single unit of time. However, Arkhangelsky et al. (2021, app. A) note that this procedure can be extended to a staggered adoption design, where treated units adopt treatment at varying moments of time. Here we lay out the formal details related to the staggered adoption design, focusing first on estimation of an aggregate treatment effect and then on extending the three inference procedures laid out previously into a staggered adoption setting. This proposal is one potential way to deal with staggered adoption settings, though there are other possible manners to proceed—see, for example, Ben-Michael, Feller, and Rothstein (2021) or Arkhangelsky et al. (2021, app. A). When there are few pure control units, this proposal may not necessarily be very effective given challenges in finding appropriate counterfactuals for each adoption-specific period.


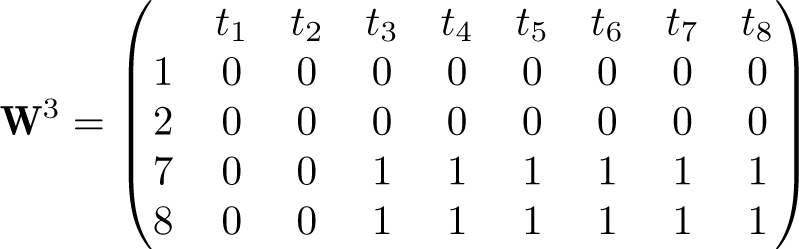
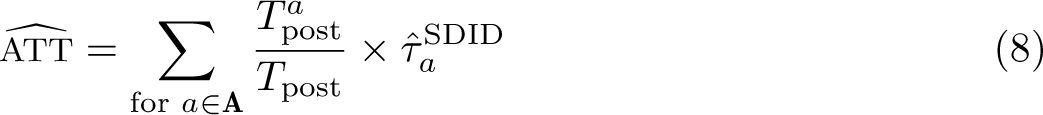
Note that in this case, while the parameter interest is likely the treatment-effect ATT or adoption-specific

Consider first the case of bootstrap inference. Suppose that one wishes to estimate standard errors or generate confidence intervals on the global treatment-effect ATT. A bootstrap procedure can be conducted based on many clustered bootstrap resamples over the entire initial dataset, where in each case, a resampled ATT estimate

Note that as in the block treatment design, this bootstrap procedure requires the number of treated units to grow with N within each adoption period. Thus, if very few treated units exist for certain adoption periods, placebo inference is likely preferable. Similarly, as laid out in the block treatment design, the bootstrap procedure reestimates optimal weight matrices in each resample and can be computationally expensive in cases where samples are large.
An alternative inference procedure is the jackknife, which is less computationally intensive but similarly based on asymptotic arguments with many states and treated units. Here optimal weight matrices calculated for each adoption-specific estimate

Finally, when there are few treated units and concerns related to the validity of the previous variance estimators exist, the placebo inference procedure defined in algorithm 4 can be used. Here this is defined for the staggered adoption case, generalizing algorithm 4 of Arkhangelsky et al. (2021). To conduct this procedure, placebo treatments are randomly assigned based on the actual treatment structure but only to the control units. Based on these placebo assignments, placebo values for ATT are generated that can be used to calculate the variance as laid out in algorithm 4. Note that such a procedure will be feasible only when there are strictly more control units than treated units (or, hence, placebo assignments will not be feasible) and, as laid out in Arkhangelsky et al. (2021) and Conley and Taber (2011), such a procedure relies on homoskedasticity across units. Otherwise, the variance of the treatment effect on the treated could not be inferred from variation in assignment of placebo treatments to control units.

Syntax
sdid requires that data be in Stata’s long format, organized with a single line per group and time period. If data are in wide rather than long format, they should be reshaped using Stata’s reshape command prior to implementing sdid. Once data are in long format, SDID can be implemented in Stata using the following command syntax:

depvar describes the dependent variable in a balanced panel of units (groupvar) and time periods (timevar). The variable that indicates units treated at each time period, which accumulates over time, is indicated as treatment. Note that it is not necessary here for users to specify whether the design is a block or staggered adoption design, because this will be inferred based on the data structure. Optionally, if and in can be specified, provided that they do not result in imbalance in the panel. Required and permitted options are discussed below, followed by a description of objects returned by sdid.
Options
vce(vcetype) is required. vcetype must be one of bootstrap, jackknife, placebo, or noinference, where in each case, inference proceeds following the specified method. For bootstrap, this is permitted only if more than one unit is treated. For jackknife, this is permitted only if more than one unit is treated in each treatment period (if multiple treatment periods are considered). For placebo, this requires at least one more control than treated unit to allow for permutations to be constructed. In each case, inference follows the specific algorithm laid out in Arkhangelsky et al. (2021). We allow the noinference option should one wish to simply generate the point estimator. This is useful if you wish to plot outcome trends without the added computational time associated with inference procedures.
covariates(varlist[, type]) specifies that covariates should be included as a varlist. If it is specified, treatment and control units will be adjusted based on covariates in the SDID procedure. Optionally, type may be specified, which indicates how covariate adjustment will occur. If type is specified as optimized (the default), this will follow the method described in Arkhangelsky et al. (2021, n. 4), where SDID is applied to the residuals of all units after regression adjustment. However, this has been observed to be problematic at times (refer to Kranz [2022]) and is also sensitive to optimization if covariates have high dispersion. Thus, an alternative type is implemented (projected), which consists of conducting regression adjustment based on parameters estimated only in untreated units. This type follows the procedure proposed by Kranz (2022) (xsynth in R) and is observed to be more stable in some implementations (and at times, considerably faster). sdid will run simple checks on the covariates indicated and return an error if covariates are constant to avoid multicollinearity. However, prior to running sdid, you are encouraged to ensure that covariates are not perfectly multicollinear with other covariates and state- and year- fixed effects in a simple two-way fixed-effects regression. If perfectly multicollinear covariates are included, sdid will execute without errors. However, where type is optimized, the procedure may be sensitive to the inclusion of redundant covariates.
seed(#) defines the seed for pseudo-random numbers.
reps(#) sets the number of repetitions used in the calculation of bootstrap and placebo standard errors. The default is reps(50). Larger values should be preferred where possible.
method(type) allows you to change the estimation method. type must be sdid, sc, or did, where sdid refers to SDID, sc refers to SC, and did refers to DID. The default is method(sdid).
zeta_lambda(#) specifies the value used when defining the regularization term for time weight calculations. This value is the scalar prior to the r term used to calculate ζ in (6). The default is zeta_lambda(1e-6) as discussed in section 2. This is relevant only when method(sdid) is used; otherwise, time weights are not used.
zeta_omega(#) specifies the value used when defining the regularization term for unit weight calculations. This value is the quantity prior to the r term used to calculate ζ in (4). The default is (NtrTpost)1/4, as discussed in section 2 when method(sdid) is implemented. For other methods, the default is zeta_omega(1e-6).
min_dec(#) specifies that the estimation of optimal weights occurs iteratively until a sequential stopping rule is met. By default, a minimum is assumed when consecutive iterations move by no more than the value specified in min_dec(). The default is min_dec(1e-5).
max_iter(#) defines the maximum number of iterations to be performed when calculating optimal weights. By default, a maximum of 10,000 iterations will be performed. Larger values can be set to ensure that a minimum is reached.
level(#) specifies the confidence level, as a percentage, for confidence intervals. The default is the level set by set level (which by default is level(95)).
graph specifies that graphs will be displayed showing unit and time weights as well as outcome trends as per figure 1 from Arkhangelsky et al. (2021). If graph is specified, graphs will be produced and displayed on screen for all versions of Stata except Stata(console). Additionally, if graphs should also be saved to disk, the graph_export() option should be used.
Proposition 99 example from Abadie, Diamond, and Hainmueller (2010), Arkhangelsky et al. (2021)
glon activates the unit-specific weight graph. By default, this option is off because the graph can take considerable time to generate when many control units are present.
g1_opt(graph_options) modifies the appearance of the unit-specific weight graph. The options adjust the underlying scatterplot, so they should be consistent with two-way scatterplots.
g2_opt(graph_options) modifies the appearance of the outcome trend graphs. The options adjust the underlying line plot, so they should be consistent with two-way line plots.
graph_export([stub], type) specifies graphs will be saved as weights YYYY and trends YYYY for each of the unit-specific weights and outcome trends, respectively, where YYYY refers to each treatment adoption period. Two graphs will be generated for each treatment adoption period provided that g1on is specified. Otherwise, a single graph will be generated for each adoption period. If this option is specified, type must be specified, which refers to a valid Stata graph type (for example, .eps, .pdf, or any other options permitted by graph_export()). Additionally, if type is specified as .gph, the graph is saved on disk in Stata’s .gph format, which permits editing of the graph. Optionally, stub can be specified, which will then be prepended to exported graph names. msize(markersizestyle) allows you to modify the size of the marker for graph 1.
unstandardized specifies controls will simply be entered in their original units. This option should be used with care. If controls are included and the optimized method is specified, controls will be standardized as z scores prior to finding optimal weights. This avoids problems with optimization when control variables have very high dispersion.
mattitles requests labels be added to the returned e(omega) weight matrix providing names (in string) for the unit variables that generate the SC group in each case. By default, the returned weight matrix (e(omega)) will store these weights with a final column providing the numerical ID of units, where this numerical ID is either taken from the unit variable (if this variable is a numerical format) or arranged in alphabetical order based on the unit variable if this variable is in string format.
verbose requests additional output, such as warning messages if the number of iterations specified in max_iter() is reached.
returnweights indicates that estimated weights ω and λ should be returned directly in the dataset corresponding to each unit. By default, these will be returned as variables named omega YYYY and lambda YYYY, where YYYY is replaced by treatment adoption periods.
generate(string) specifies that the variables containing omega and lambda weights returned if the returnweights option is specified should be named starting with string. If returnweights is specified but generate() is not, variables will simply follow default naming.
sdid stores the following in e() :

The matrices e(b) and e(V) are included to facilitate the exportation of results from sdid with commands such as estout (Jann 2004).
Examples based on an empirical application
In the sections below, we provide several illustrations of the usage and performance of the sdid command, which operationalizes the SDID estimator in Stata. We consider both a block treatment design (with a single adopting state) and a staggered adoption design, noting several points covering estimation, inference, and visualization.
A block design
In the first case, we consider the well-known example, also presented in Arkhangelsky et al. (2021), of California’s “Proposition 99” tobacco control measure. This example, based on the context described in Abadie, Diamond, and Hainmueller (2010) and the data of Orzechowski and Walker (2005), is frequently used to illustrate SC-style methods. Proposition 99, which was passed by California in 1989, increased the taxes paid on a pack of cigarettes by 25 cents. The impact of this reform is sought to be estimated by comparing the evolution of sales of cigarettes in packs per capita in California (the treated state) with those in 38 untreated states, which did not significantly increase cigarette taxes during the study period.
The data used in this analysis cover each of these 38 states over the period of 1970-2000, with a single observation for each state and year. Adoption occurs in California in 1989, implying Tpre = 19 pretreatment periods and Tpost = 12 posttreatment periods. There are NC0 = 38 control states and 1 treated state, so Ntr = 1. Using the sdid command, we replicate the results from Arkhangelsky et al. (2021). In the code example below, we first download the data and then conduct the SDID implementation using a placebo inference procedure with (the default) 50 placebo iterations.
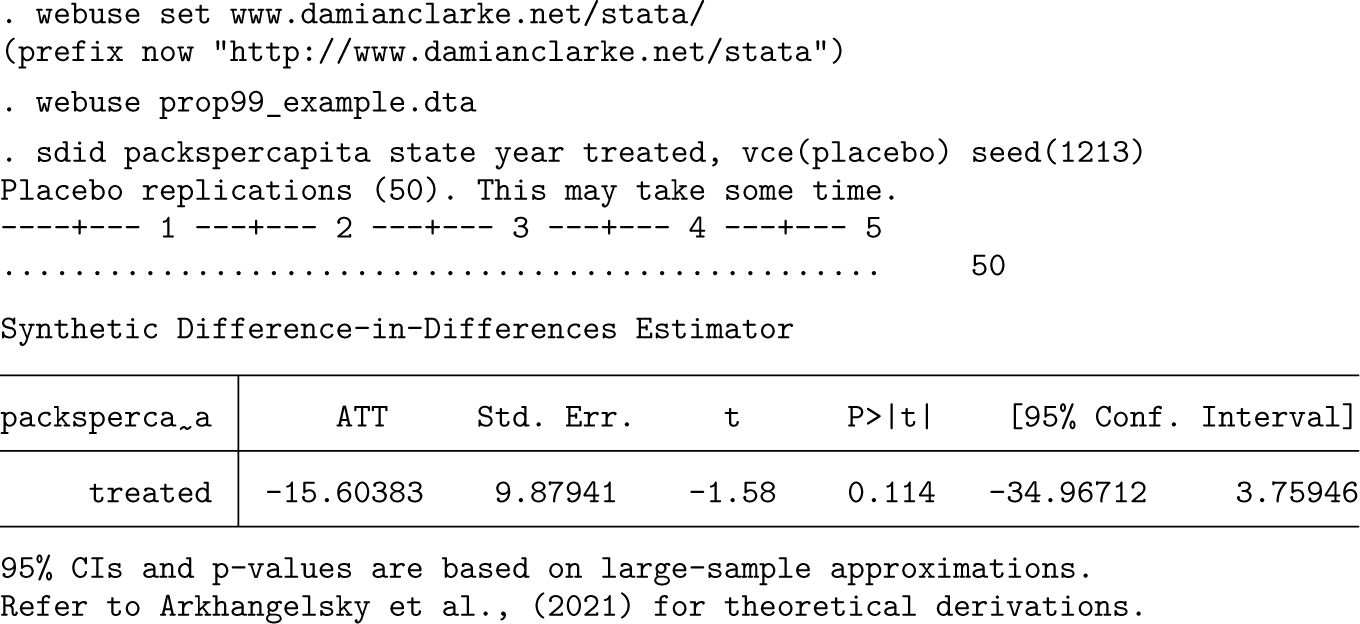
The third line of this code excerpt simply implements the SDID estimator, returning identical point estimates to those documented in table 1 of Arkhangelsky et al. (2021). Standard errors are slightly different because they are based on pseudo-random placebo reshuffling, though they can be replicated as presented here provided that the same seed is set in the seed() option. Note that in this case, given that only one treated unit is present, placebo inference is the only appropriate procedure, as specified in the vce() option.
Tabular output following sdid
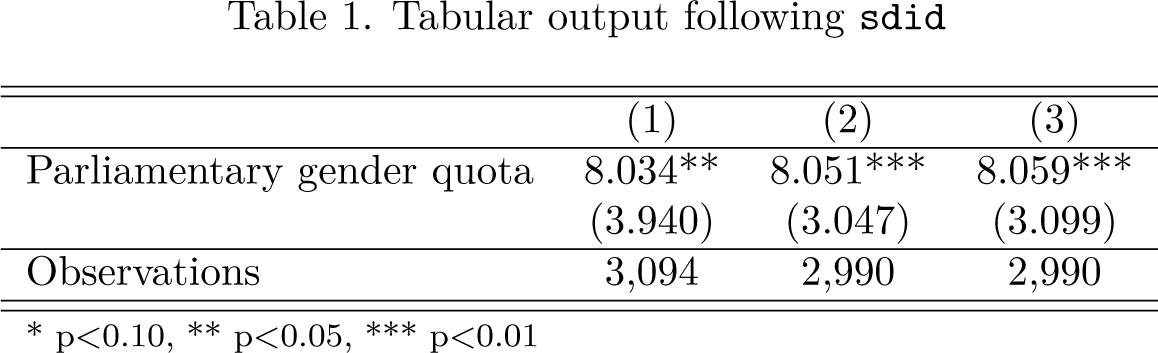
Tabular output following sdid
* p < 0.10, ** p < 0.05, *** p < 0.01
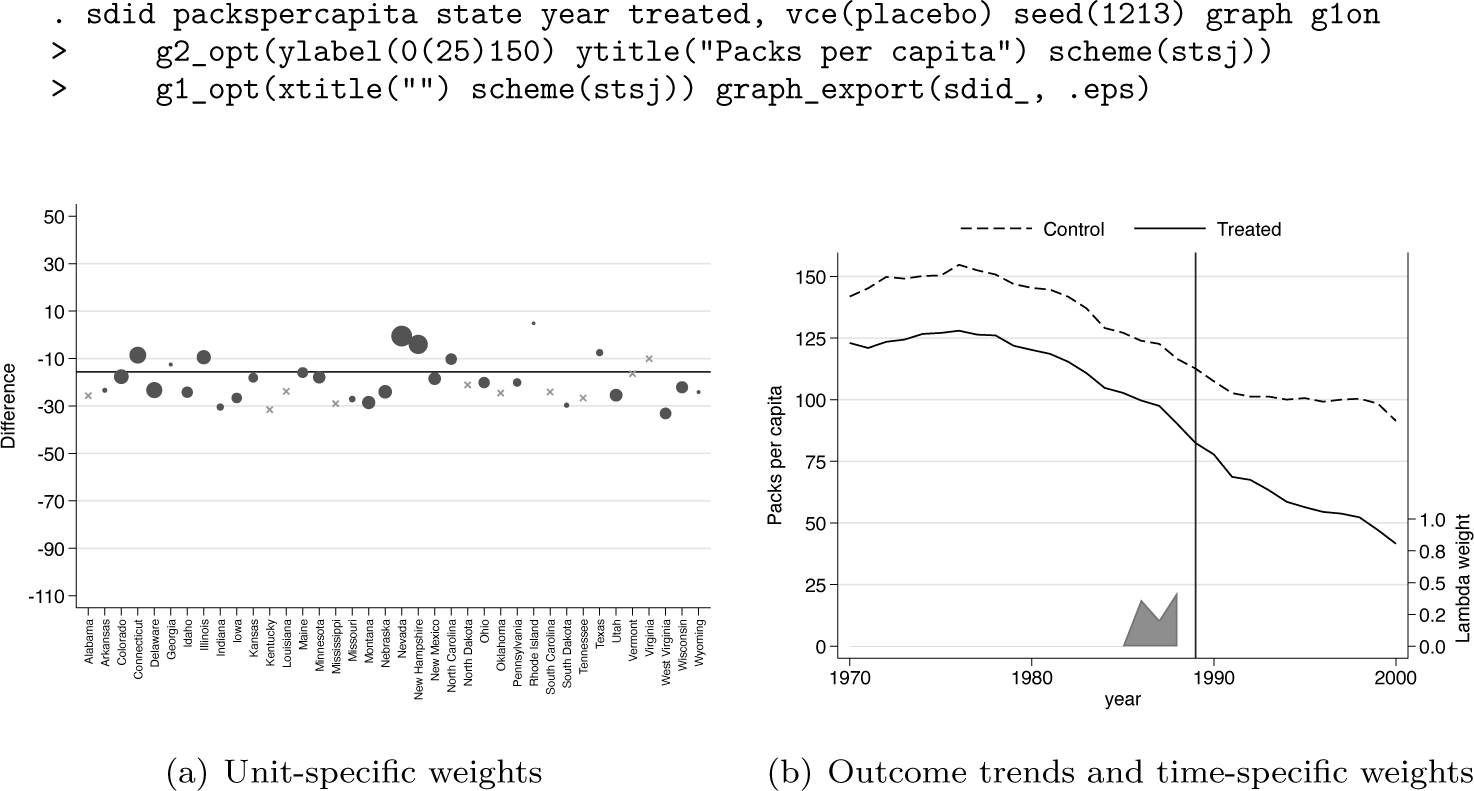
We may wish to generate the same graphs as in Arkhangelsky et al. (2021), summarizing both 1) unit-specific weights and 2) treatment and SC outcome trends along with time-specific weights. This can be requested with the graph option. This is displayed below, where we additionally modify plot aesthetics via the g1_opt() and g2_opt() options for weight graphs [figure 1(a)] and trend graphs [figure 1(b)], respectively. Finally, generated graphs can be saved to disk using the graph_export() option, with a graph type (.eps below) and optionally a prepended plot name. Output corresponding to the command below is provided in figure 1.
It is illustrative to compare the output of SDID estimation procedures with those of standard SC methods of Abadie, Diamond, and Hainmueller (2010) and unweighted DID estimates. Using the method() option, one can request a standard DID output with method(did) or an SC output with method(sc) . In the interest of completeness, method(sdid) is also accepted, although this is the default behavior when method() is not included in the command syntax. In each case, the resulting graph will match treated and control or SC trends, as well as weights received by each unit and time period. These are displayed in figure 2, with plots corresponding to each of the three calls to sdid displayed below. In the left-hand panel, identical SDID plots are provided as those noted above. In the middle plot, corresponding to method(did), a DID setting is displayed. Here, in the top panel, outcomes for California are displayed as a solid line, while mean outcomes for all control states are documented as a dashed line, where a clear divergence is observed in the pretreatment period. The bottom panel shows that in this case, each control unit receives an identical weight, while time weights indicated at the base of the top plot note that each period is weighted identically. Finally, in the case of SC, output from the third call to sdid is provided in the right-hand panel. In this case, treated and SC units are observed to overlap nearly exactly, with weights in figure 2f noted to be more sparse and placing relatively more weight on fewer control states. We note that in each case, the vce(noinference) option is used because here we are simply interested in observing exported graphs, not the entire command output displaying aggregate estimates, standard errors, and confidence intervals.
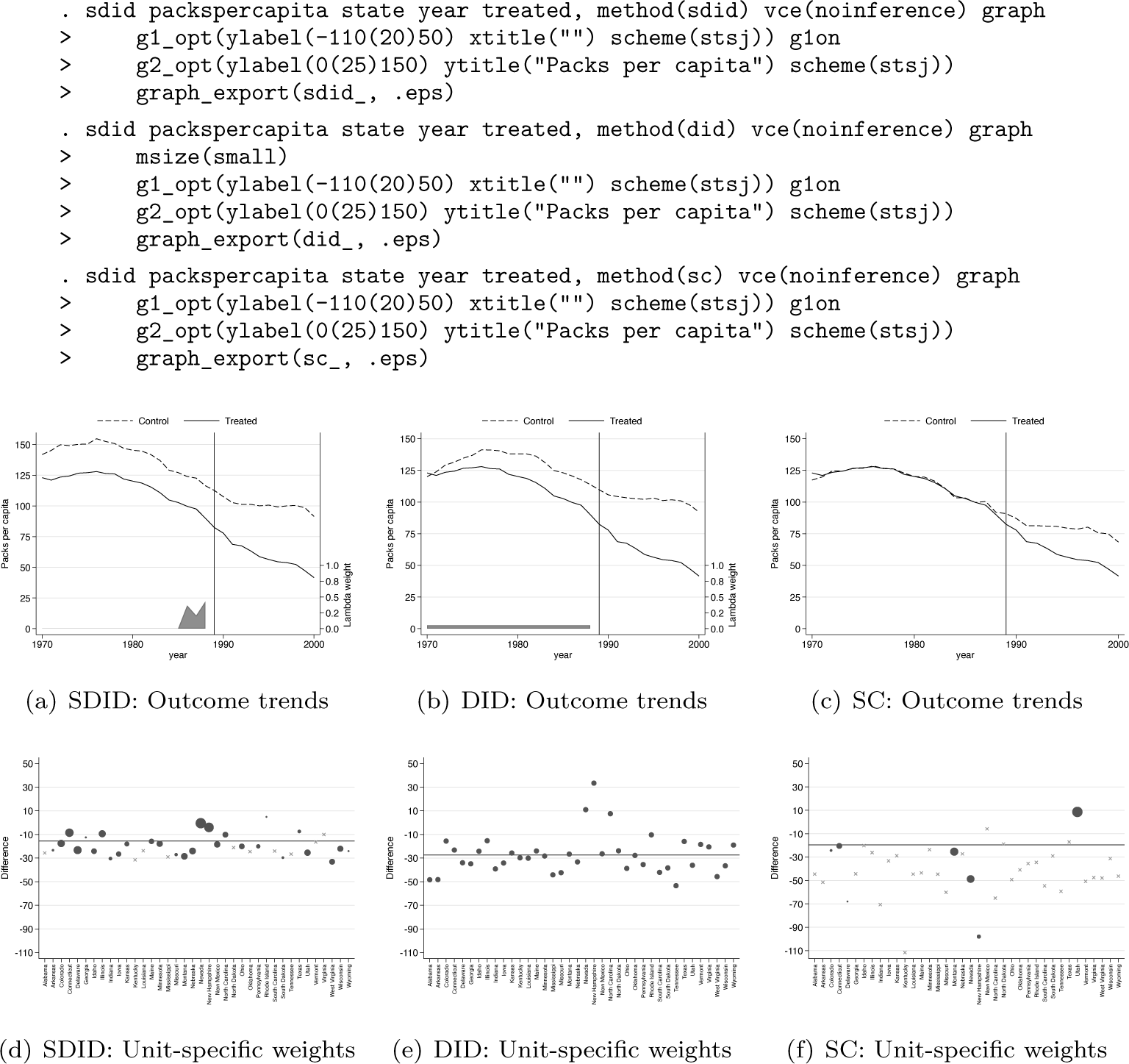
Comparison of estimators
The sdid command returns multiple matrices containing treatment and control outcome trends, weights, and other elements. These elements can be accessed for use in postestimation procedures or graphing. As a simple example, the following code excerpt accesses treatment and SC outcome trends (stored in e(series)) and time weights (stored in e(lambda)) and uses these elements to replicate the plot presented in figure 1b. The resulting graphical output is presented as figure 3, which is virtually identical to figure 1b but omits the second y axis in line with the plots originally presented in Arkhangelsky et al. (2021). In this way, if one wishes to have further control over the precise nature of plotting beyond that provided in the graphing options available in sdid’s command syntax, one can simply work with elements returned in the ereturn list command. In online appendix A2, we show that with slightly more effort, returned elements can be used to construct the unit-specific weight plot from figure 1a.
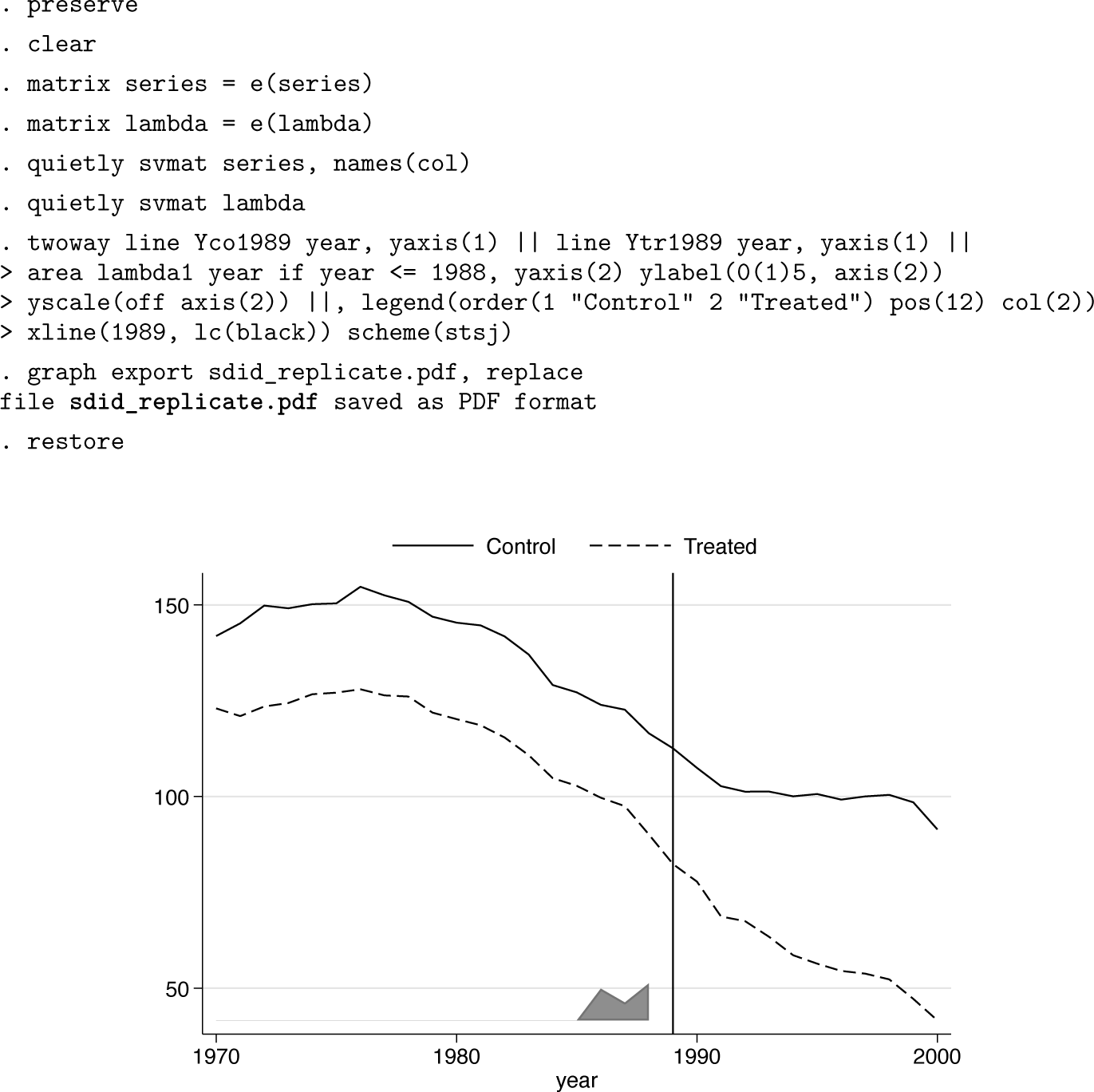
Outcome trends and time-specific weights
We present an example of a staggered adoption design based on data and the context studied in Bhalotra et al. (2023). In this case, the impact of parliamentary gender quotas that reserve seats for women in parliament is estimated, first on rates of women in parliament and second on rates of maternal mortality. This is conducted on a country-by-year panel, where for each year of 1990-2015, 115 countries are observed, 9 of which implement a parliamentary gender quota. 4 For each of these countries, data on the rates of women in parliament and the maternal mortality ratio are collected, as well as several covariates.
This example presents a staggered adoption configuration, given that in the period under study, quota adoption occurred in seven different yearly periods between 2000 and 2013. sdid handles a staggered adoption configuration seamlessly without any particular changes to the syntax. In the code below, we implement the SDID estimator using the bootstrap procedure to calculate standard errors. By default, the output reports the weighted ATT, which is defined in (8) above. However, as laid out in (8), this is based on each adoption-period-specific SDID estimate. These adoption-period-specific estimates are returned in the matrix e(tau), which is tabulated below the standard command output.
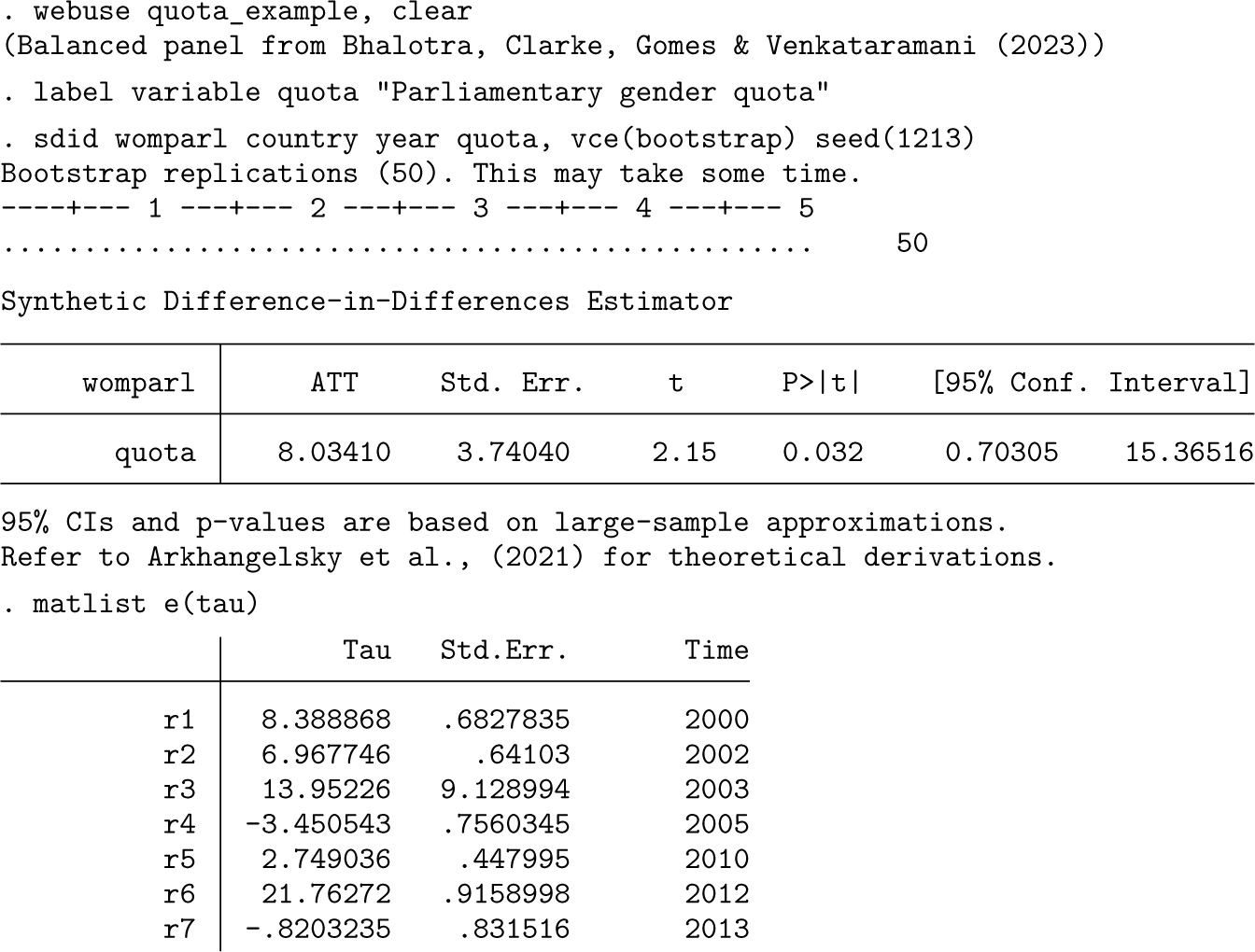
All other elements are identical to those documented in the case of a single adoption period but are generalized to multiple adoptions. For example, if one is requesting graphical output, a single treatment versus SC trend graph and corresponding unit-level weight graph is provided for each adoption date. Similarly, matrices returned with ereturn, such as e(lambda), e(omega), and e(series), provide columns for each particular adoption period.
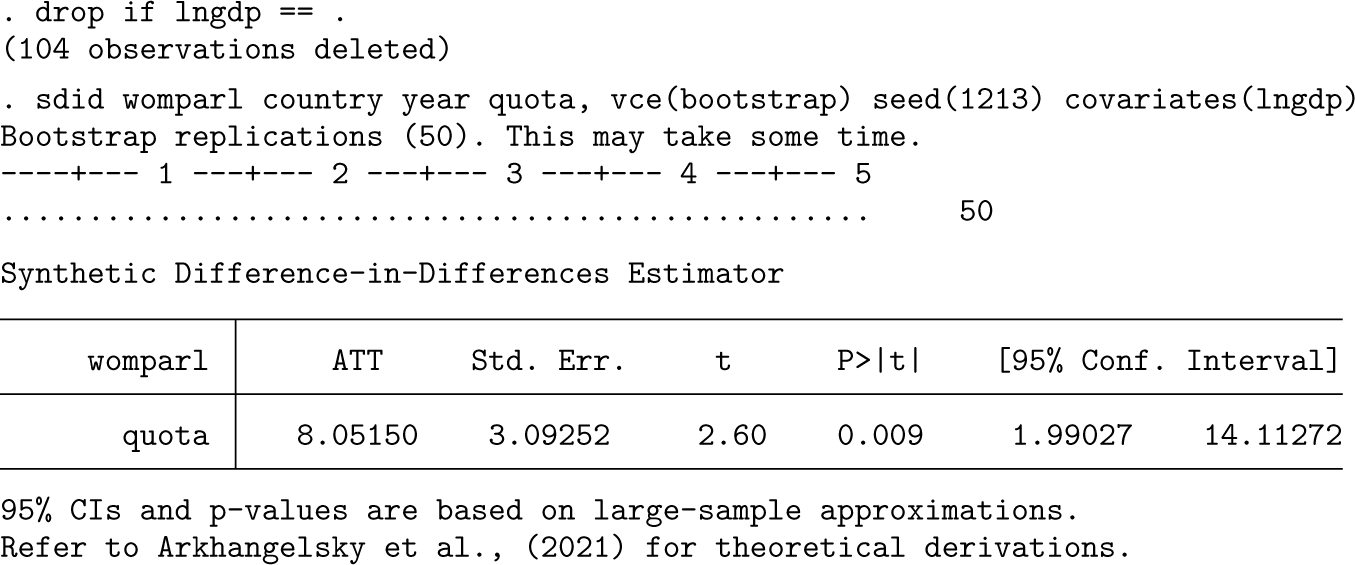
The inclusion of covariates in the previous implementation adds considerably to the computational time because it increases the complexity of the underlying optimization routine; this is conducted in each adoption period and each bootstrap replicate. An alternative way to capture covariates described in section 2.2 above is that of Kranz (2022), where the impact of covariates is projected out using a baseline regression of the outcome on covariates and fixed effects only in units where the treatment status is equal to zero. This is implemented as below with covariates(, projected).
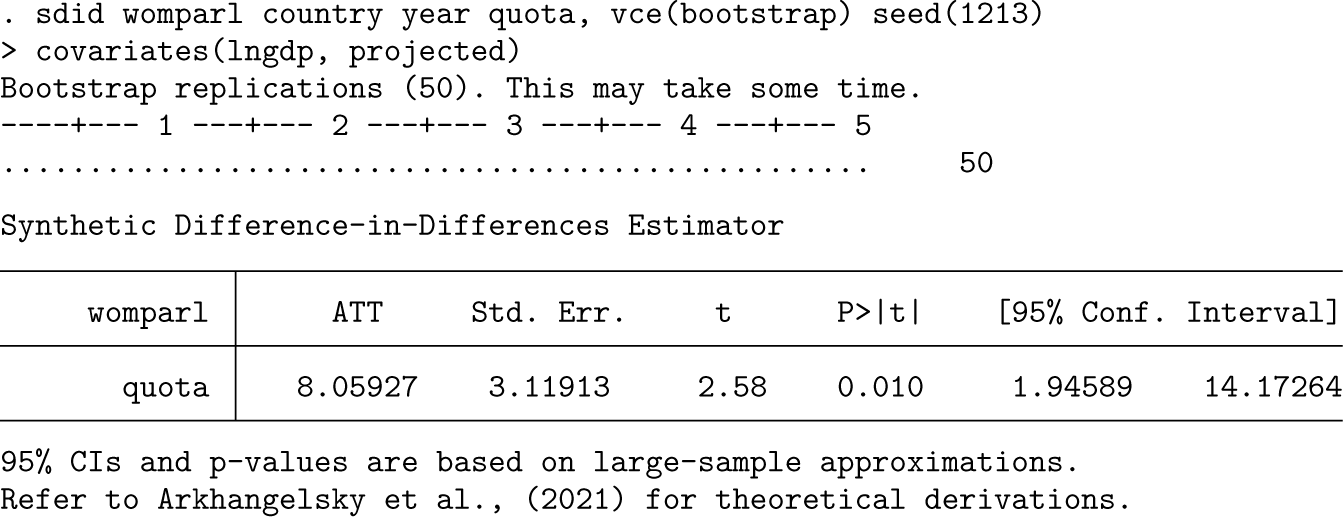
Here results are slightly different but quantitatively comparable with those when using alternative procedures for conditioning out covariates. In this case, if examining the e(beta) matrix, only a single coefficient will be provided because the regression used to estimate the coefficient vector is always based on the same sample. This additionally offers a nontrivial speedup in the execution of the code. For example, on a personal computer with Stata/SE 15.1 and relatively standard specifications, using the optimized method above required 324 seconds of computational time while using projected required 61 seconds (compared with 58 seconds where covariates were not included in sdid).

Inference options
In this section, we provide examples of the implementation of alternative inference options, as laid out in algorithms 2-4. For this illustration, we will keep only treated units that adopt gender quotas in 2002 and 2003. Otherwise, adoption periods will exist in which only a single unit is treated, and jackknife procedures will not be feasible.

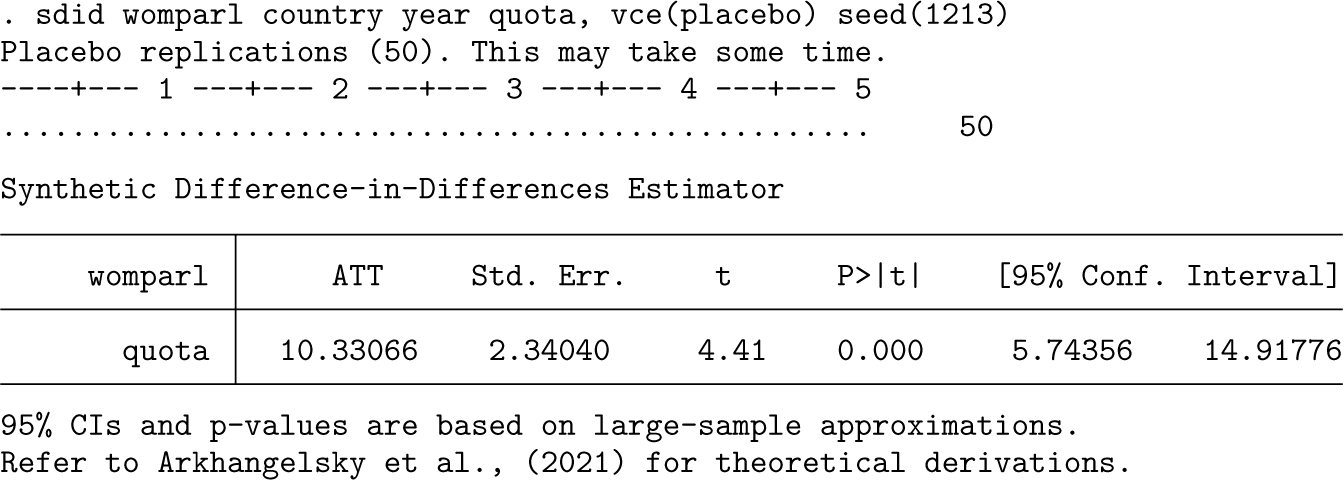
In the following three code blocks, we document bootstrap, placebo, and jackknife inference procedures. The difference in implementation in each case is very minor, simply indicating bootstrap, placebo, or jackknife in the vce() option. For example, for bootstrap inference, where block bootstraps over the variable country are performed, the syntax is as follows:

By default, only 50 bootstrap replicates are performed, though in practice, substantially more should be used; this can be specified in the reps() option. For placebo, the syntax and output are virtually identical. The suitability of each method depends on the underlying structure of the panel, and in this particular case, given the relatively small number of treated units, placebo procedures may be preferred.
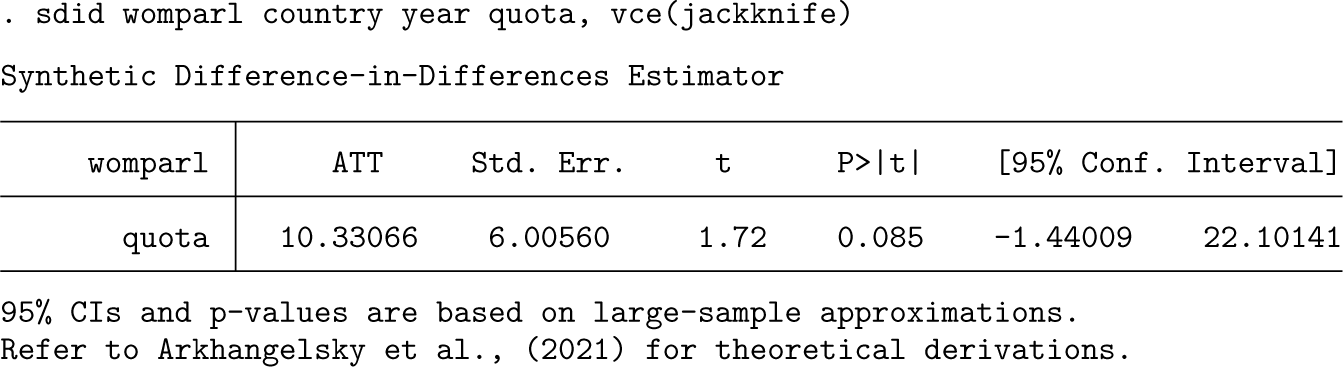
Finally, in the interest of completeness, the jackknife procedure, which is by far the fastest of the three to execute,5 is provided below. Note that unlike the case with placebo or bootstrap inference, it is not necessary (or relevant) to set a seed or indicate the number of replications because the jackknife procedure implies conducting a leave-one-out procedure over each unit. In this particular case, jackknife inference appears to be more conservative than bootstrap procedures, in line with what may be expected based on the demonstration of Arkhangelsky et al. (2021) that jackknife inference is generally conservative.
Event-study-style output
While sdid offers a simple implementation to conduct standard SDID procedures and provide output, results can also be visualized in alternative ways with some work. For example, consider the standard “panel event-study”-style setting (see, for example, Freyaldenhoven, Hansen, and Shapiro [2019]; Schmidheiny and Siegloch [2019]; and Clarke and Tapia-Schythe [2021]), where one wishes to visualize how the dynamics of some treatment effect evolve over time, as well as how differences between treated and control units evolve prior to the adoption of treatment. Such graphs are frequently used to efficiently provide information on both the credibility of parallel pretrends in an observational setting and the emergence of any impact owing to treatment once treatment is switched on.
What such an analysis seeks to document is the differential evolution of treated and (synthetic) control units, abstracting away from any baseline difference between the groups. As an example, refer to figure 4a, which is based on the adoption of gender quotas laid out in section 4.2, particularly quota adoption in the year 2002. This is standard output from sdid, presenting trends in rates of women in parliament in countries that adopted quotas in 2002 (solid line) and SC countries that did not adopt quotas (dashed line). We will refer to the values plotted in these trend lines as
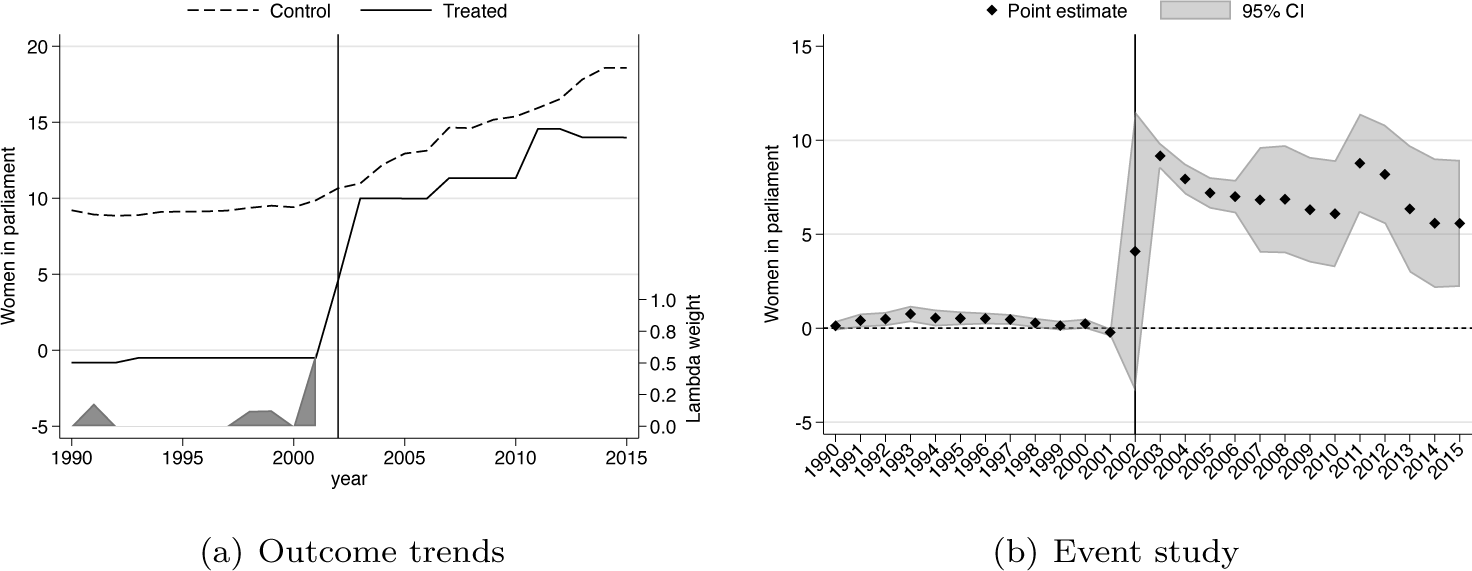
Outcome trends and event-study-style estimate of the impact of quotas on percent women in parliament
For this to resemble the logic of an event-study analysis, we wish to consider, for each period t, whether differences between treated units and SCs have changed when compared with baseline differences. Namely, for each period t, we wish to calculate
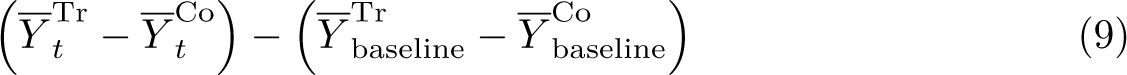
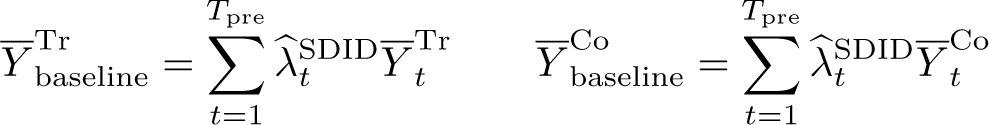
An example of such an event-study-style plot is presented in figure 4b. Here black points present the quantity indicated in (9) for each year. In this case, t ranges from 1990 to 2015. While all of these points are based on a simple implementation of sdid comparing outcomes between treated and control units following (9), confidence intervals documented in gray-shaded areas of figure 4b can be generated following the resampling or permutation procedures discussed earlier in this article. Specifically, for resampling, a block bootstrap can be conducted, and in each iteration, the quantity in (9) can be recalculated for each t. The confidence interval associated with each of these quantities can then be calculated based on its variance across many (block)-bootstrap resamples.
Figure 4b, and graphs following this principle more generally, can be generated following the use of sdid. However, by default, sdid simply provides output on trends among the treated and SC units (as displayed in figure 4a). In the code below, we lay out how one can move from these trends to the event study in panel (b). Because this procedure requires conducting the inference portion of the plot manually (unlike most other procedures involving sdid where inference is conducted automatically as part of the command), the code is somewhat more involved. Thus, we discuss the code below in several blocks, terminating with the generation of the plot displayed in figure 4b.
In the first code block, we will open the parliamentary gender quota data that we used in section 4.2 and keep the particular adoption period considered here (countries that adopted quotas in 2002), as well as untreated units:

We can then implement the standard SDID procedure, additionally exporting the trend graphs, which is displayed in figure 4a. This is done in the first line below, after which several vectors are stored. These vectors allow us to calculate the quantity

Perhaps the most complicated portion of code is that which implements the bootstrap procedure. This is provided below, where for ease of replication, we consider a relatively small number of bootstrap resamples, which is set as the local B = 100. In each bootstrap resample, we first ensure that both treatment and control units are present (using the locals r1 and r2) and then reestimate the sdid procedure with the new bootstrap sample generated using Stata’s bsample command. This is precisely the same block bootstrap procedure laid out by Arkhangelsky et al. (2021) and that sdid conducts internally. However, here we are interested in collecting, for each bootstrap resample, the same quantity estimated above with the main sample as d, which captures the estimate defined in (9) for each t. To do so, we simply follow an identical procedure as that conducted above but save the resulting resampled values of the quantities from (9) as a series of matrices d'b’ for later processing to generate confidence intervals in the event study.
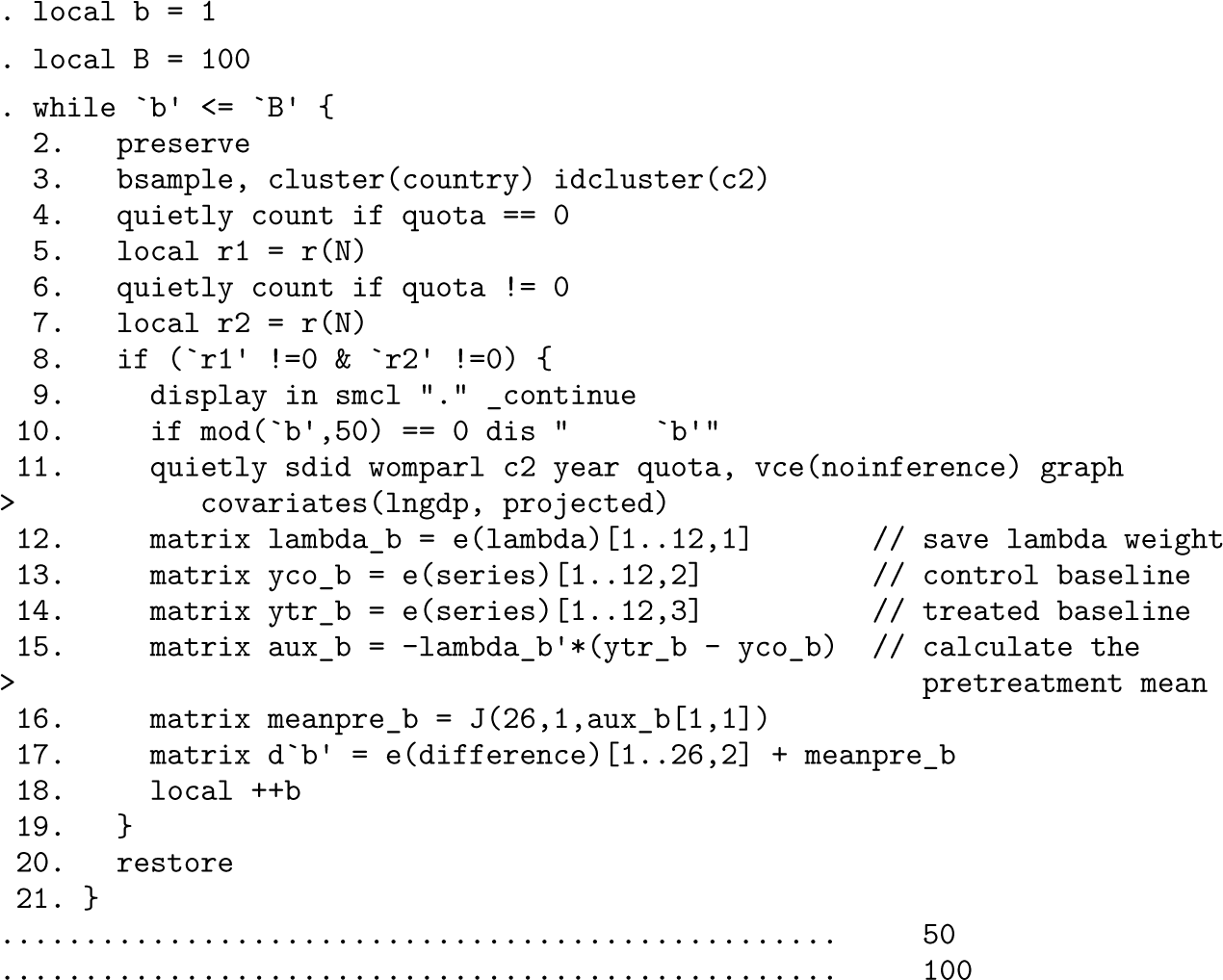
The final step is to calculate the standard deviation of each estimate from (9) based on the bootstrap resamples and then to generate confidence intervals for each parameter based on the estimates generated above (d), as well as their standard errors. This is conducted in the first lines of the code below. For each of the B = 100 resamples conducted above, we import the vector of resampled estimates from (9) and then, using rowsd(), calculate the standard deviation of the estimates across each time period t. This is the bootstrap standard error, which is used below to calculate the upper and lower bounds of 95% confidence intervals as [LCI; UCI]. Finally, based on these generated elements (d as black points on the event study and LCI and UCI as the endpoints of confidence intervals), we generate the output for figure 4b in the final lines of code.

As noted above, the outcome of this graph is provided in figure 4b, where we observe that, as expected, the SDID algorithm has resulted in quite closely matched trends between the SC and treatment group in the pretreatment period, given that all pretreatment estimates lie close to zero. The observed impact of quotas on women in parliament occurs from the treatment year onward, where these differences are observed to be large and statistically significant.
This process of estimating an event-study-style plot is conducted here for a specific adoption year. For a block adoption design where there is only one adoption period, this will be the only resulting event study to consider. However, in a staggered adoption design, a single event study could be generated for each adoption period. Potentially, such event studies could be combined, but some way would be required to deal with unbalanced lags and leads, and additionally, some weighting function would be required to group treatment lags and leads where multiple such lags and leads are available. One such procedure has been proposed in Sun and Abraham (2021) and could be a way forward here.
In general, estimation and inference for synthetic DID is concerned with the ATT, or adoption-specific treatment effects
In practice, once unit- and time-specific weights are calculated, there are several ways in which one can proceed to estimate the ATT. In the implementation of sdid, given that the main estimand of interest is the ATT, a direct approach is taken where
To see this, note that (1) is simply a weighted regression where weights for each unit are defined as
To see how this works, we return to the case of Proposition 99, first estimating SDID. By default, when
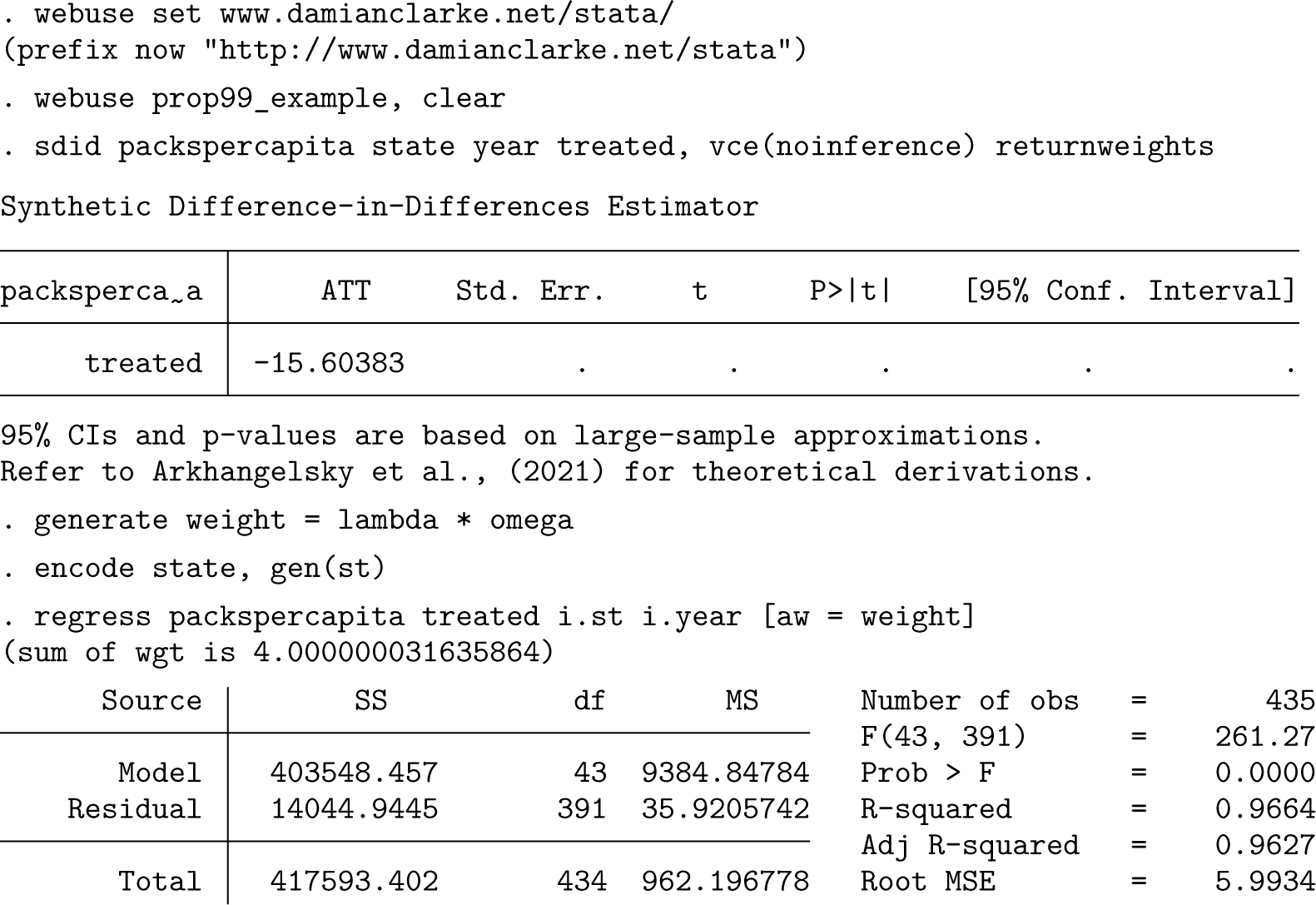
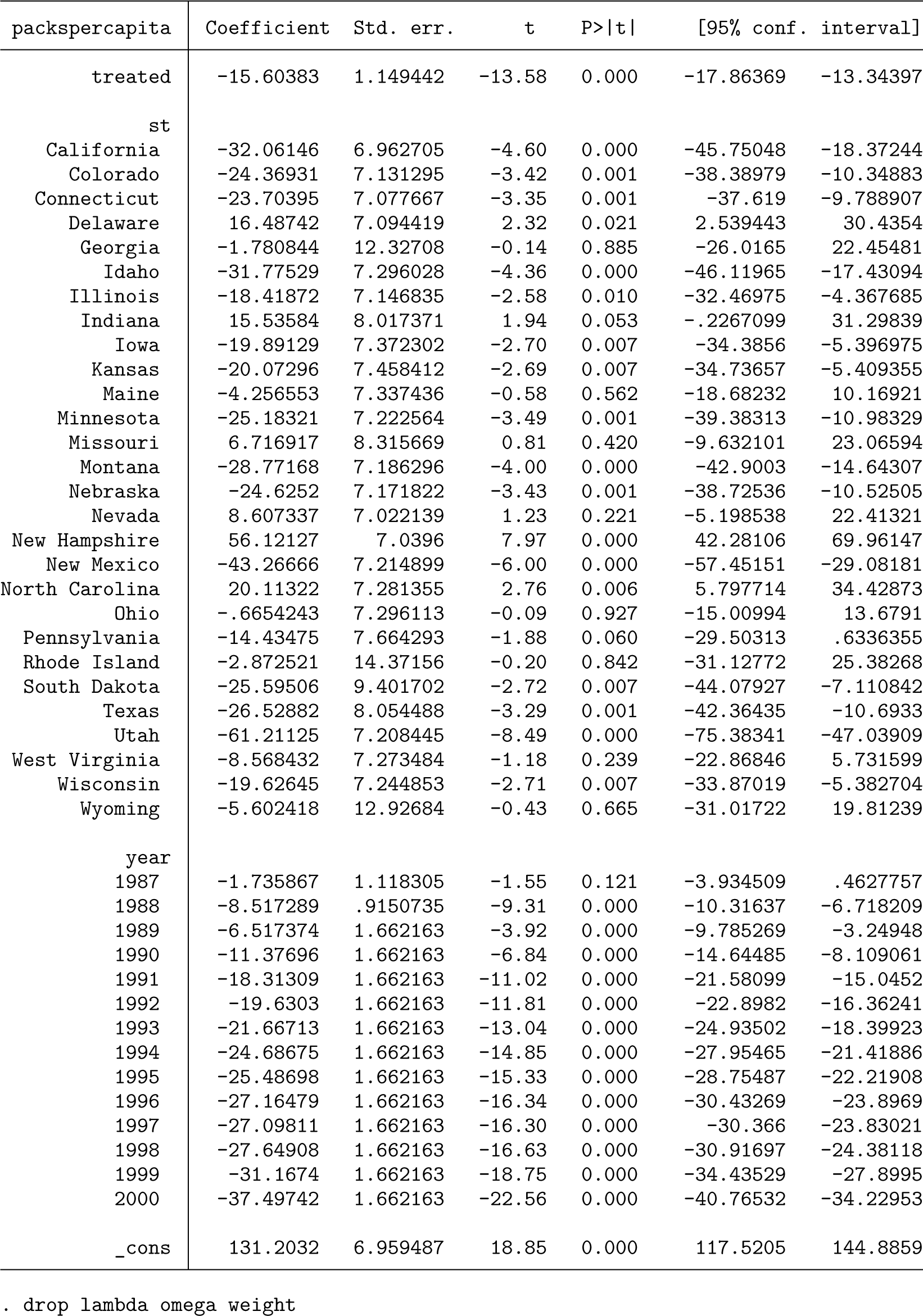
Note that this regression does not give valid inference for the estimated ATT or for any fixed effects or constants, because it treats weights as known rather than estimated. More generally, the variance derivations in Arkhangelsky et al. (2021) are valid only for the ATT, so any inference considerations on fixed effects are not theoretically founded at present. Nevertheless, if we do wish to consider valid inference in a regression-based framework following sdid, we can follow procedures similar to those laid out in the bootstrap, jackknife, or placebo procedure described previously. To consider a simple illustration, below we implement a permutation-based procedure that is virtually identical to the internal permutation routine of sdid, where in each iteration, an ATT estimate is produced for a randomly permuted (untreated) state assuming treatment occurs in 1989. We once again estimate weighted regression using the weights returned from sdid, in each iteration storing the estimated ATT in the variable Taus. Finally, at the end of this code block, we inspect estimated Taus, which provides an estimate of the standard error (the standard deviation of permutations) and similarly would allow for the calculation of confidence intervals based on empirical quantiles of this variable. We observe that the standard error is in line with that reported previously when estimating sdid directly.
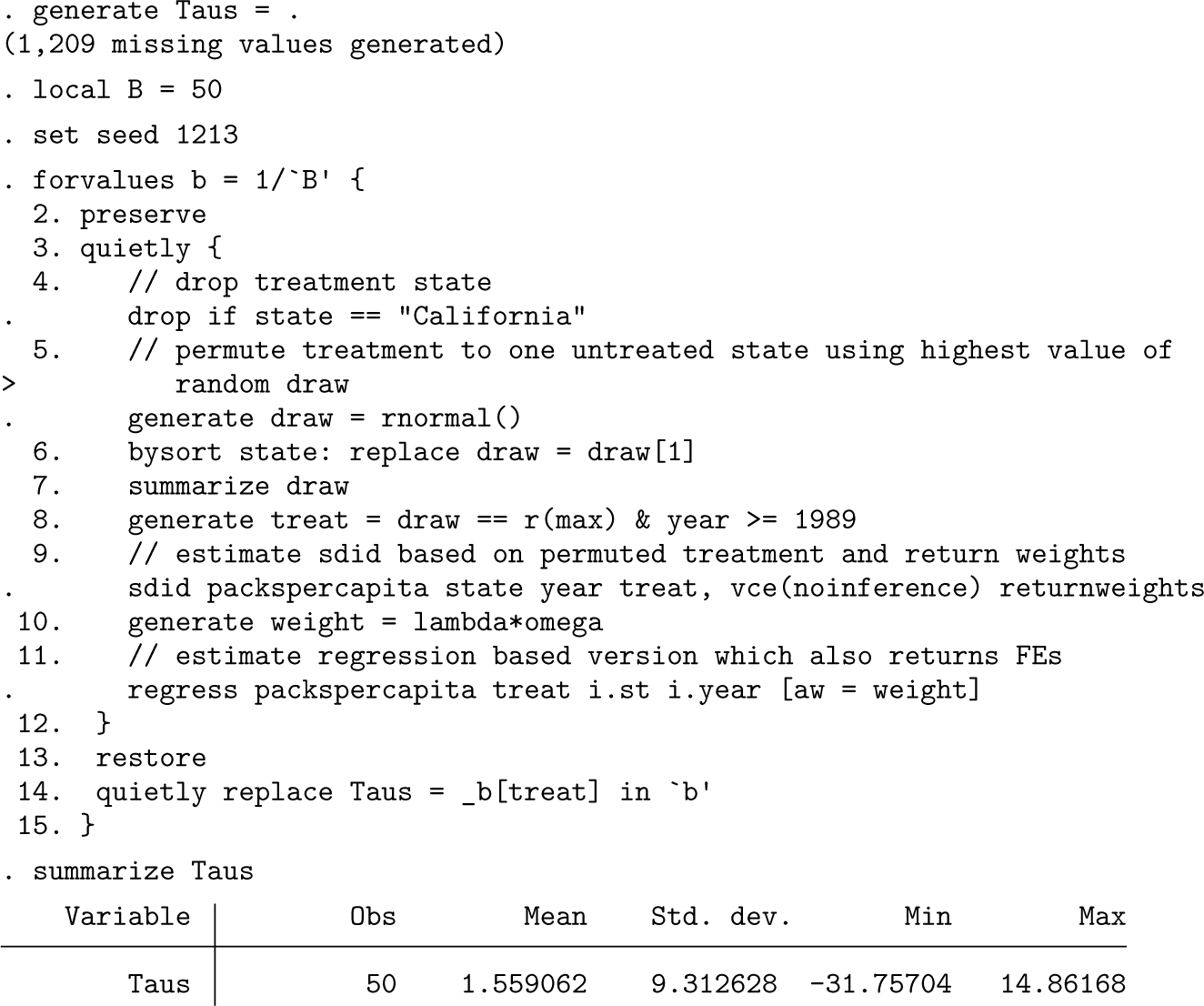
This procedure is documented because it is illustrative to note that other parameters from (1) can be simply estimated by weighted regression. Given the lack of valid standard errors directly from regression, this procedure should be implemented with care, though as we document in the permutation procedure above, one can implement valid inference directly via regression if desired, though this is less direct than implementing procedures directly in
Conclusions
Recent advances in panel-data methods have resulted in a rich set of tools that can be used to conduct policy and other analyses. Such methods, combined with a growing emphasis on formal identification and broadening availability of large datasets and computing power available to researchers (Currie, Kleven, and Zwiers 2020) suggests we will see an increasing adoption of these tools in applied research in the social sciences. Two particularly common approaches to analysis in a panel-data or repeated cross-sectional settings are DID and SC methods. While both are sharply increasing in frequency in applied research (Currie, Kleven, and Zwiers 2020), they are often used in different cases: DID is commonly employed with many treated units and potentially fewer time period, while SC is often implemented with fewer treatment units, many controls, and longer pretreatment periods. Furthermore, both settings have particular assumptions that may not be met in practice: DID requires parallel trends between treated and control units, while SC requires a convex hull assumption that is not met if treatment outcomes are more extreme than control outcomes.
In this article, we have laid out the details behind the SDID method of Arkhangelsky et al. (2021), which allows for the relaxation of assumptions required in both DID and SC settings while also maintaining desirable properties if these assumptions are met. We have discussed its implementation in Stata using the
Nevertheless, despite the ease of implementation of
From a theoretical standpoint, there are additional considerations that are important to keep in mind for the implementation of SDID procedures. In particular, note that normality results underlying the generation of variance estimates and confidence intervals hold asymptotically. Specifically, these results require that the entire panel size grow without limit, as well as the number of control units and the number of pretreatment periods. However, these results do not require for the number of treatment units to grow without limit; they require that either the number of posttreatment periods or the number of treated units grows without limit (see Arkhangelsky et al. [2021, 4016]). Reassuringly, simulation results from Arkhangelsky et al. (2021) suggest the SDID estimator has good properties even with as few as one treatment unit and with panels consisting of 50 states and 40 time periods. This raises the general question of what types of data properties are required for SDID estimation. A key element of estimation, as in the case of SC estimation (Ben-Michael, Feller, and Rothstein 2021; Abadie, Diamond, and Hainmueller 2010), is the adequate modeling of pretreatment trends. This requires a sufficient number of periods off of which to model the generation of synthetic cohorts but also the avoidance of periods in which structural breaks occur in treatment outcomes (see, for example, practical discussion related to SCs in Abadie [2021]). While there is not yet a method to determine the precise number of required pretreatment periods for SDID modeling, simulation results in Arkhangelsky et al. (2021) show good behavior in settings with 30 pretreatment periods. In practice, considerably fewer pretreatments are likely to be required, and indeed, the canonical example of SC methods based on California’s Proposition 99 is based on 19 pretreatment periods. Additionally, SDID generally requires fewer pretreatment periods than SC implementations given that SDID’s optimal weighting of years and states in generating estimates has a double robustness property, while SC does not have this property (Arkhangelsky et al. 2021). Future work could further clarify data requirements in terms of minimum required preperiods in SDID modeling.
In general, this is a quickly evolving field (Roth et al. 2022; Arkhangelsky and Imbens 2023), and there is substantial work of interest beyond the synthetic DID methods described in this article. Among other things, SC has been shown to gain from regularization (Ben-Michael, Feller, and Rothstein [2021]; Chernozhukov, Wüthrich, and Zhu [2021]; and Abadie and L’Hour [2021], among others), debiasing methods (Ferman and Pinto 2021), and distributional considerations (Gunsilius 2023). Overall, though, should a balanced panel of data be available, the SDID method and the sdid command described here offer flexible, easy-to-implement, and robust options for the analysis of impacts of policies or treatments in certain groups at certain times. These methods provide clear graphical results to describe outcomes and an explicit description of how counterfactual outcomes are inferred. These methods are likely well suited to a large body of empirical work in social sciences, where treatment assignment is not random, and offer benefits over both DID and SC methods.
Supplemental Material
sj-pdf-1-stj-10.1177_1536867X241297914 - Supplemental material for On synthetic difference-in-differences and related estimation methods in Stata
Supplemental material, sj-pdf-1-stj-10.1177_1536867X241297914 for On synthetic difference-in-differences and related estimation methods in Stata by Damian Clarke, Daniel Pailañir, Susan Athey and Guido Imbens in The Stata Journal
Footnotes
6
We are grateful to Asjad Naqvi for comments relating to this code, and we are grateful to many users of the sdid ado-file for sending feedback and suggestions related to certain features implemented here. We thank the editor Stephen P. Jenkins and an anonymous referee for many useful comments.
7
To install the software files as they existed at the time of publication of this article, type
Notes
About the authors
Damian Clarke is an associate professor at the Department of Economics of the Universidad de Chile and the University of Exeter and a research associate at the Millennium Institute for Market Imperfections and Public Policy.
Daniel Pailañir is a senior analyst at Ministry of Economics, Development and Tourism of Chile.
Susan Athey is the Economics of Technology Professor at Stanford Graduate School of Business.
Guido Imbens is the Applied Econometrics Professor and Professor of Economics at Stanford sGraduate School of Business.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.