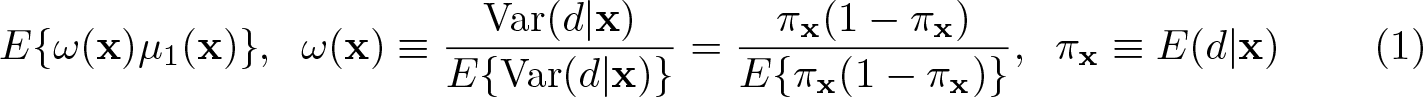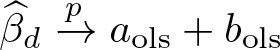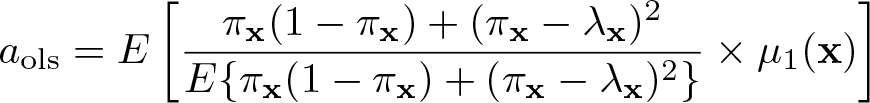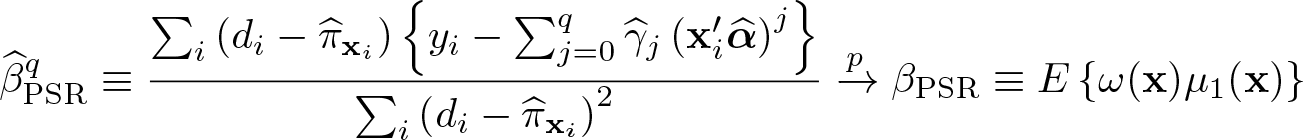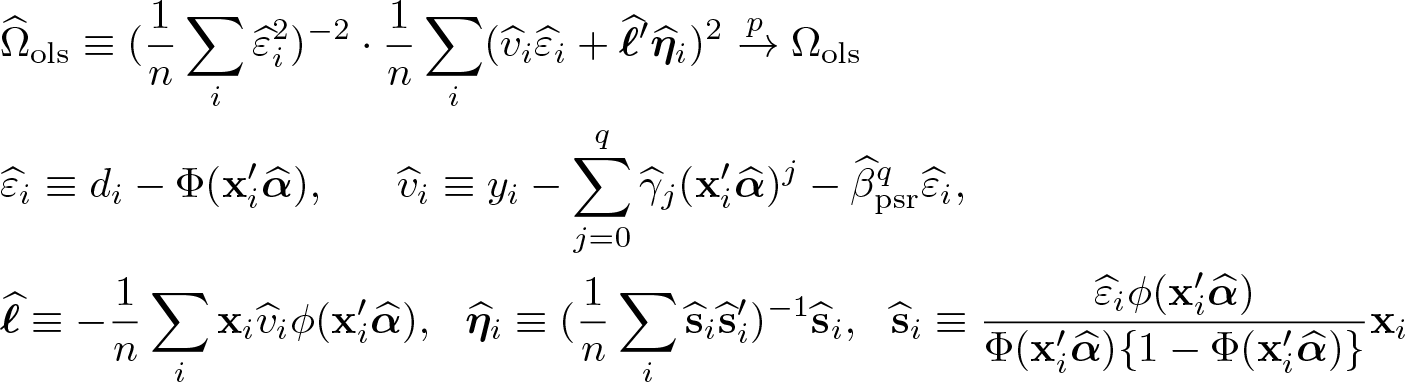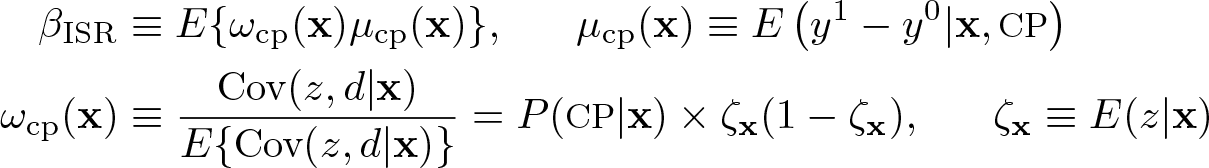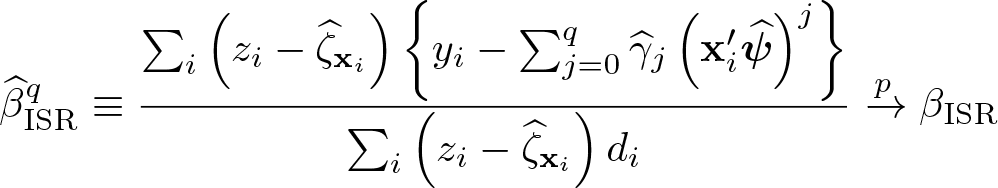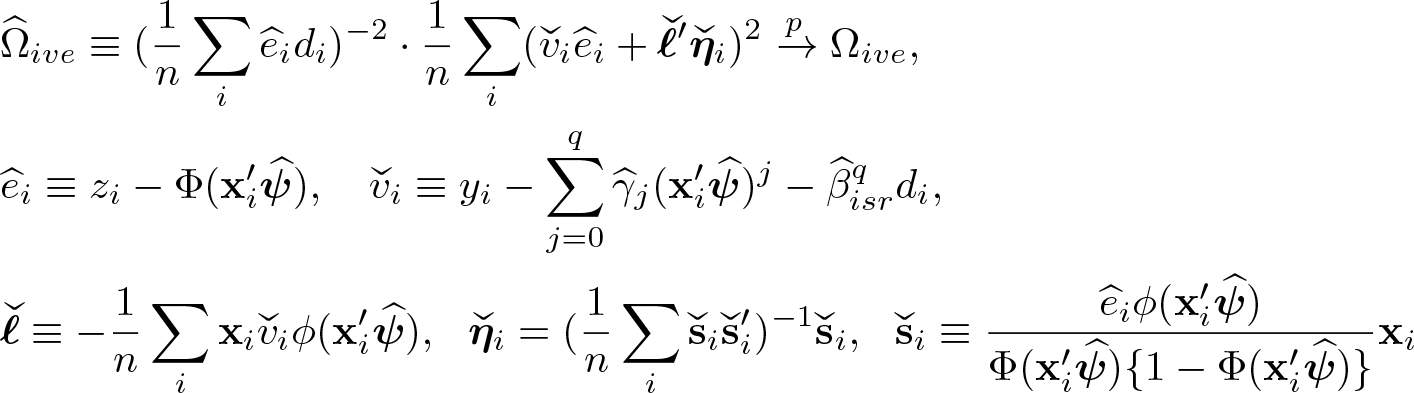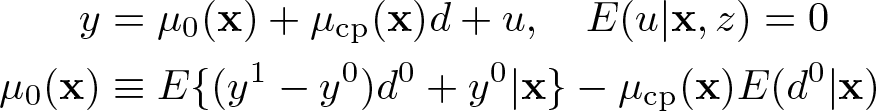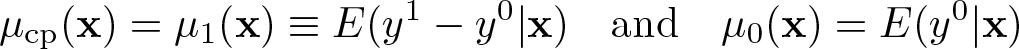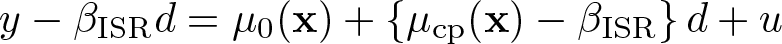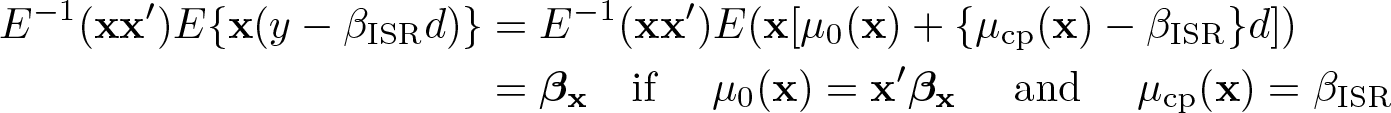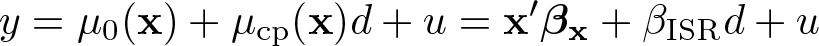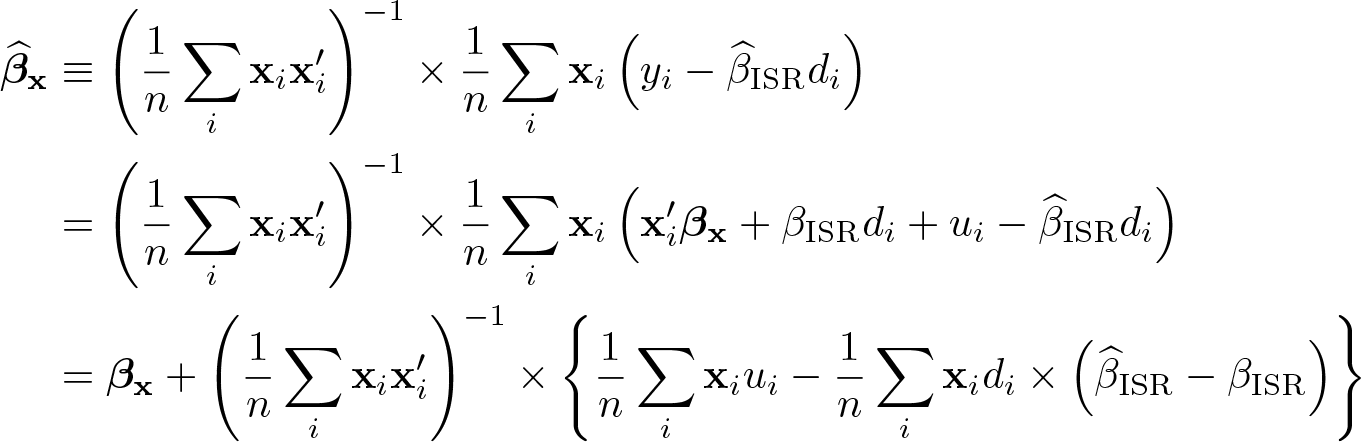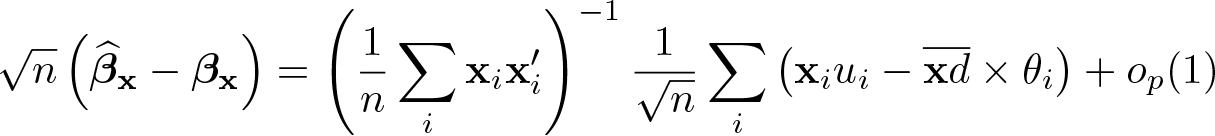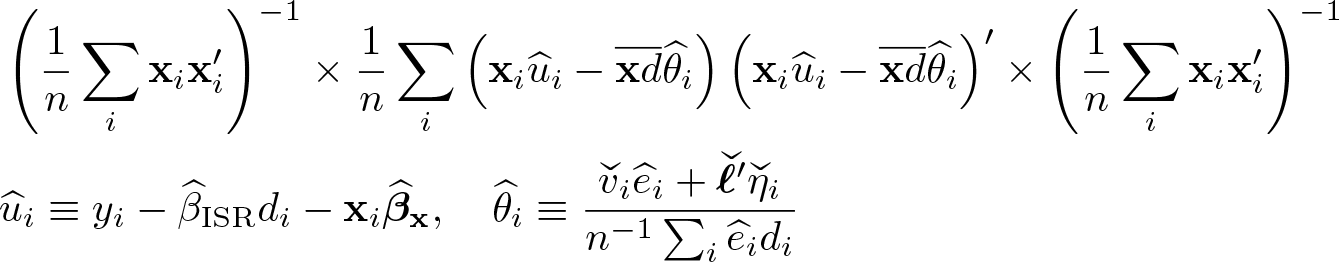Given an exogenous treatment d and covariates x, an ordinary least-squares (OLS) estimator is often applied with a noncontinuous outcome y to find the effect of d, despite the fact that the OLS linear model is invalid. Also, when d is endogenous with an instrument z, an instrumental-variables estimator (IVE) is often applied, again despite the invalid linear model. Furthermore, the treatment effect is likely to be heterogeneous, say, µ1(x), not a constant as assumed in most linear models. Given these problems, the question is then what kind of effect the OLS and IVE actually estimate. Under some restrictive conditions such as a “saturated model”, the estimated effect is known to be a weighted average, say, E{ω(x)µ1(x)}, but in general, OLS and the IVE applied to linear models with a noncontinuous outcome or heterogeneous effect fail to yield a weighted average of heterogeneous treatment effects. Recently, however, it has been found that E{ω(x)µ1(x)} can be estimated by OLS and the IVE without those restrictive conditions if the “propensity-score residual” d − E(d|x) or the “instrument-score residual” z−E(z|x) is used. In this article, we review this recent development and provide a command for OLS and the IVE with the propensity- and instrument-score residuals, which are applicable to any outcome and any heterogeneous effect.
Given an exogenous binary treatment d, an outcome y, and covariates x, consider the ordinary least-squares (OLS) estimator of y on (x, d) for a linear model , where βx and βd are parameters. In reality, the treatment effect may not be a constant (βd), as is assumed in the linear model, but an unknown heterogeneous function, say, µ1(x), that results in µ1(x)d instead of βdd. This is clear if one thinks of the COVID-19 vaccine effects, which can be highly heterogeneous; some individuals suffer from extremely negative effects (that is, death), while others benefit from fully positive effects. It is sometimes possible to account for µ1(x) using interaction terms dx, but approximating µ1(x) with dx would generally be inadequate. Hence, an important question arises: What kind of effect does the OLS slope of d estimate when the true effect is an unknown function µ1(x) of x?
An answer is that the OLS d-slope is consistent for a Var(d|x)-weighted average of µ1(x), where Var(d|x) denotes the variance of d conditional on x (Angrist 1998; Angrist and Krueger 1999; Angrist and Pischke 2009; and Aronow and Samii 2016). Unfortunately, however, this answer requires that E(d|x) be the same as the linear projection L(d|x), that is, the “population OLS predictor” of d using x.
Because E(d|x) = L(d|x) hardly holds in reality unless the model is saturated (that is, x is discrete, and a full set of dummy variables is used for all possible values of x), another question emerges: What effect does the OLS d-slope estimate under E(d|x) ≠ L(d|x), when the true effect is µ1(x)? In addition to this effect-heterogeneity problem, y is often a limited dependent variable (LDV) for which the linear model does not hold in general. This raises yet another question: What effect does the OLS d-slope estimate under E(d|x) ≠ L(d|x), when the true effect is µ1(x) or y is an LDV?
Going one step further, when d is endogenous with a binary instrument z, an instrumental-variables estimator (IVE) is often applied to an LDV y. Then an analogous question emerges: What effect does the IVE d-slope estimate under E(d|x) ≠ L(d|x), when the true effect is µ1(x) or y is an LDV? Instead of simply raising the “passive” or “negative” questions on the (biased) estimands of OLS and the IVE in difficult situations, a more “active” or “positive” question might be, Is there any way to do a valid OLS or IVE without E(d|x) = L(d|x) to estimate a meaningful treatment effect when the true effect is µ1(x) or y is an LDV?
This article reviews the answers to the above questions as presented in Lee (2018, 2021) and Lee, Lee, and Choi (Forthcoming) and provides the command psr, which implements the positive approaches in Lee (2018) for OLS and Lee (2021) for the IVE. In essence, the approaches are that modified versions of OLS and the IVE are consistent for some specific weighted averages of µ1(x) for any form of y. The generality of the approaches is that they allow for an arbitrary µ1(x) and an arbitrary form of y, either of which would invalidate the usual linear model.
The approach by Lee (2018, 2021) is related to, but more generally applicable than, that of Angrist (2001), who advocates declaring the effect of interest first and then finding ways to identify and estimate it—a point also made by van der Laan and Rose (2011) later in the name “targeted learning”. Angrist (2001) argues that simple linear estimators such as the IVE can be appropriately used even with noncontinuous outcome variables. However, such linear model estimators may exhibit bias unless E(d|x) = L(d|x), which hardly holds for general nonsaturated models. Lee, Lee, and Choi (Forthcoming) derive the bias in the context of linear probability models. Though Angrist (2001, 10) mentions the use of nonlinear least squares as a solution for LDVs, the implementation is practically inconvenient and often challenging because it may involve nuisance infinite weights. Readers are referred to the comments by Moffitt (2001), Imbens (2001), and Todd (2001) for other concerns.
In contrast, the approach by Lee (2018, 2021) presented below yields estimators that are always a weighted average of heterogeneous treatment effects, regardless of whether E(d|x) = L(d|x). Furthermore, their approach is applicable to any form of y and is straightforward to implement because it involves only linear regressions (for OLS and IVE) and widely used probit or logit.
In the remainder of this article, section 2 closely examines the above questions and answers in Lee (2018, 2021) and Lee, Lee, and Choi (Forthcoming). Section 3 presents the command psr, which performs the modified OLS and IVE for any y (continuous, binary, count, etc.) and estimates weighted averages of µ1(x). Section 4 provides two empirical illustrations. Finally, section 5 concludes this article.
2 OLS and IVE valid for any outcome
2.1 Effect estimated by OLS
For the heterogeneous effect, µ1(x) ≡ E(y1− y0|x), where y1 and y0 are the potential outcomes, Angrist and Pischke (2009, eq. 3.3.7) show that the slope estimator of d in the OLS regression of y on (x, d) is consistent for the weighted average
if πx = λx≡ L(d|x) ≡ L(dx′){E(xx′)}−1x, where πx is the propensity score (PS) and Var(d|x) is the variance of d conditional on x.
The quadratic function πx(1 − πx) reaches its maximum at πx = 0.5 and its minimum at πx = 0, 1. Considering the popular “PS matching” targeting for E{E(y1− y0|πx)}, because those subjects with πx ≃ 0.5 overlap well with subjects in the opposite group, whereas those with πx ≃ 0, 1 do not, Li, Morgan, and Zaslavsky (2018) called ω(x) the overlap weight (OW). That is, those subjects close to being randomized receive high weights in OW (Thomas, Li, and Pencina 2020). PS matching avoids the poor overlap problem by removing those with πx≃ 0, 1, which amounts to targeting for E{ωuni(x)E(y1− y0|πx)}, where ωuni(x) is a step-shaped “uniform weight” equal to 0 for πx ≃ 0, 1 and a positive constant otherwise. In this context, OW ω(x) can be viewed as a smoothed version of ωuni(x).
Using E{ω(x)µ1(x)} instead of E{µ1(x)} as one marginal effect accords many benefits in causal analysis, such as 1) stabilizing “inverse probability weighting” estimators (Li and Greene 2013), 2) making “regression adjustment/imputation” estimators robust to misspecified outcome regression models (Vansteelandt and Daniel 2014), and 3) automatically ensuring the exact covariate balance when πx is logistic (Li, Morgan, and Zaslavsky 2018). More advantages of OW can be seen in Choi and Lee (2023), who provide a review on OW.
Turning back to the Angrist and Pischke (2009) derivation, we see the convergence of the OLS estimator to the weighted average in (1) requires restrictively πx = λx, where λx is the linear projection of d on x as defined above. To ensure πx = λx, Angrist and Pischke (2009) assume a saturated model, but saturated models are rare.
In general, πx ≠ λx (for example, probit for πx) and the OLS slope estimator may not converge to a weighted average of µ1(x). For example, for binary y, Lee, Lee, and Choi (Forthcoming) show that
where is the OLS d-slope estimator,
is a weighted average of µ1(x), and bols is a bias term. If πx = λx, aols reduces to E{ω(x)µ1(x)} in (1) and bols = 0. Otherwise, aols + bols is hard to interpret. The weighting function in aols makes little sense if πx ≠ λx, and the bias term bols involves E(y0|x) and µ1(x) (see Lee, Lee, and Choi [Forthcoming, eq. 11]) for the exact formula of bols. In contrast, the methods proposed by Lee (2018, 2021) presented in the following sections always yield estimators that are consistent for a specific weighted average of treatment effects for any outcome and heterogeneity.
2.2 OLS with PS residual
For exogenous d, Lee (2018) shows that the OLS of y on d − πx is consistent for E{ω(x)µ1(x)} for any form of y regardless of whether πx = λx, as long as y1− y0 makes sense. y1− y0 makes sense for continuous, count, or binary y; for categorical y, turn each category to a dummy variable to use each dummy variable as an outcome. In fact, Lee’s (2018) OLS was suggested much earlier by Robins, Mark, and Newey (1992) for a constant-effect semilinear model y = µ0(x) + βdd + error with a continuous y and an unknown function µ0(x).
Although πx can be estimated nonparametrically, to make the OLS practical, Lee (2018) uses the probit πx and proposed the OLS of y − E(y|πx) on d − πx. Using y − E(y|πx) instead of y makes the OLS robust to misspecifications in πx to the extent that the OLS of y − E(y|πx) on d − πx is close to the OLS of y − E(y|x) on d − πx, which is “double debiased/orthogonalized” (Chernozhukov et al. 2017, 2018, 2022). Denote the OLS of y − E(y|πx) on the PS residual (PSR) d − πx “OLSPSR”, and denote the OLS as “”; q in is explained shortly.
To implement OLSPSR, 1) obtain the probit of d on x to get the estimator , where Φ(·) is the standard normal distribution function and x′α is the probit regression function with a parameter α, 2) obtain the OLS of y on to get the predicted value for E(y|πx)—Lee (2018) suggested q = 2 or 3—and 3) do the OLS of on :
Because Φ(·) is one to one, E(y|πx) = E(y|x′α) holds, which implies that step 2 above can be done equivalently by the OLS regression of y on the polynomials of the predicted probability instead of the linear index . Although using and using are theoretically equivalent, they can differ in practice. On one hand, if there are outliers in , then it is better to use because the outlier problem would be more subdued in . On the other hand, if is too small, then and would be almost zero, in which case it is better to use .
For some Ωols and an independent and identically distributed sample of size n, we have,
The probit score function involves h(t) ≡ ϕ(t)/[Φ(t){1 − Φ(t)}], which can be difficult to evaluate numerically when |t| is large. In our experiments, h(t) seems difficult to obtain precisely when t < −20 or t > 5. Hence, using the symmetry of h(t), we compute h(t) by h(−|t|) so that h(t) can be found reliably for |t| < 20. For extreme t values outside the range |t| > 20, using h(t)/|t| → 1 as |t| → ∞, we replace h(t) with |t|. If logit were used for πx, then this kind of numerical problem would not appear, because the part in logit corresponding to h(t) is equal to 1.
2.3 IVE with instrument-score residual
Generalizing Lee (2018), Lee (2021) allowed d to be endogenous with a binary instrument z. Defining the “instrument score” (IS) ζx≡ E(z|x), Lee (2021) proposed the IVE of y − E(y|ζx) on d with the IS residual (ISR) z − ζx as the instrument.
Let (d0, d1) be the potential treatments of d for z = 0, 1, and define “compliers” (CPs) as those with d0 = 0 and d1 = 1. The IVE, dubbed “IVEISR”, is consistent for
The weight is high for subjects with a high Cov(z, d|x), avoiding the “weak instrument problem” in the IVE. More importantly, the weight becomes an OW when z is taken as the underlying treatment, as in the “intent-to-treat effect” in clinical trials with an assignment z and the actual (not well complied) treatment d. Note that βISR becomes E{ω(x)µ1(x)} for exogenous d because then d = z and everybody is a complier.
To implement IVEISR, 1) obtain the probit of z on x to get the estimator for ζx; 2) obtain the OLS of y on to get the predicted value for E(y|ζx) with q = 2 or 3; and 3) do the IVE of on d with the instrument ,
As was the case for OLSPSR, the linear index in step 2 can be replaced with the probability .
For some ΩIVE, where
2.4 Finding covariate slopes
After linear ISR is obtained, one may desire to find the slopes of x, as is typically done in models. The following shows what could be provided for the slopes of x, although they are irrelevant for the treatment effect of interest.
Note the “linear-in-d representation” for y in Lee (2021),
which holds under d0≤ d1 for any y as long as y1− y0 makes sense, where µ0(x) is an unknown function of x and u is an error term. For exogenous d, set d = d0 + (d1− d0)z equal to z to obtain (d0 = 0, d1 = 1) (that is, everybody is a complier for exogenous d) and
The linear-in-d representation is a “causal reduced form (RF)” because it is an RF, not an structural form (that is, the data-generating model), which contains a causal parameter µcp(x) of interest. The causal RF holds for any form of µcp(x) and y.
Rewrite the above linear-in-d representation as
Then the estimand of the OLS of y − βISRd on x is, with E−1(·) ≡ {E(·)}−1,
which is a sufficient condition for the slopes of x to be consistent for βx. Note that under the sufficient condition, we have a linear model because
Denote the OLS of on x as . Under the sufficient condition just mentioned, it holds that, with q in omitted,
Be aware that here is not the same as the x-slope in the OLS of y on (x, d), because the slope estimator of d in this OLS is not .
Let the influence function of be θi: ; the form of θi is shown shortly. Then, using the preceding display, we obtain
where . Hence, is asymptotically normal with the variance estimated with
Bear in mind that is not of primary interest. Rather, and its asymptotic distribution derived under the restrictive conditions [µ0(x) = x′βx and µcp(x) = βISR] are just to give some idea on the contribution of x to µ0(x) because having only one estimate at the end of data analysis may leave the researcher feeling somewhat “unfulfilled”.
3 The psr command
The command psr implements OLS with a PSR and an IVE with an ISR.
when the endogenous binary treatment variable is instrumented by an exogenous binary instrument. The covariates should be exogenous always.
3.2 Options
logit specifies to use logit instead of probit for propensity or IS regression.
order(#) specifies the maximum polynomial order q for predicting the dependent variable by the fitted linear index or the fitted probability. The default is order(2).
useprob uses the fitted probability for the prediction of the dependent variable instead of the fitted linear index. By default, the linear index is used.
auxiliary reports results from auxiliary regression for covariate slopes with the standard errors.
verbose displays all intermediate step results.
vverbose is the same as the auxiliary and verbose options used together.
3.3 Stored results
psr stores the following in e():
4 Applications
We present two applications in this section: flu vaccine effect on hospitalization or not (Lee 2021; Ding and Lu 2017) and education effect on wage (Lee 2021).
4.1 Flu vaccine effect on hospitalization
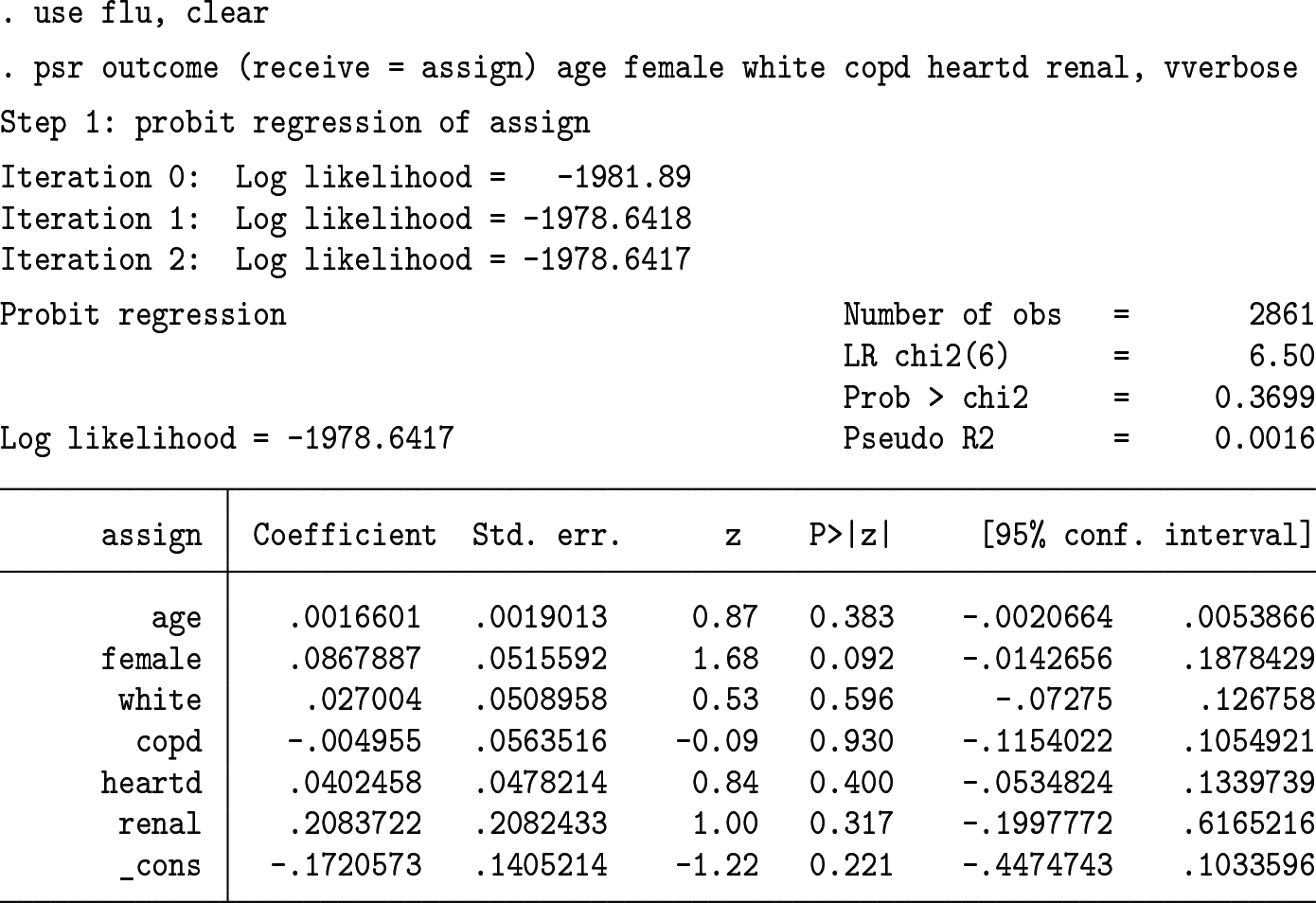
The first application is flu vaccine effect on hospitalization or not. flu.dta is prepared using the Ding and Lu (2017) data. The outcome variable is outcome, the treatment variable is receive, and the exogenous covariates are age, female, white, copd, heartd, and renal. Lee (2021) allows the treatment to be endogenous and instruments it with assign. We consider exogenous and endogenous treatments for the sake of illustration.
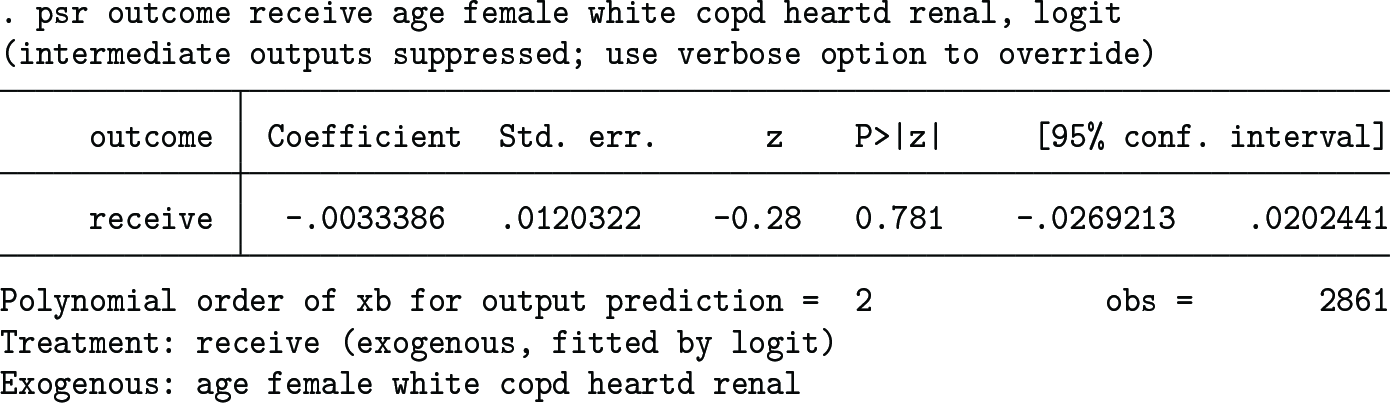
With the treatment assumed to be exogenous, the psr command invoked with the default options gives the following results, where the OW average treatment effect is small in magnitude and is statistically insignificant:
In this OLS result, the treatment effect (−0.0033608) is obtained as follows: The treatment variable (receive) is regressed on the covariates (age, female, white, copd, heartd, and renal) by probit, and the outcome prediction error is obtained by regressing the outcome variable (outcome) on the linear index (xb) and its square. The OW average treatment effect is then obtained by the OLS regression of the outcome prediction error on the PSR.
A third-order polynomial of the linear index can be added to the outcome prediction regression, which yields the following result:
The results change only marginally.
Logit can replace probit by using the logit option, as the following example illustrates:
The results are almost identical to those by the probit regression.
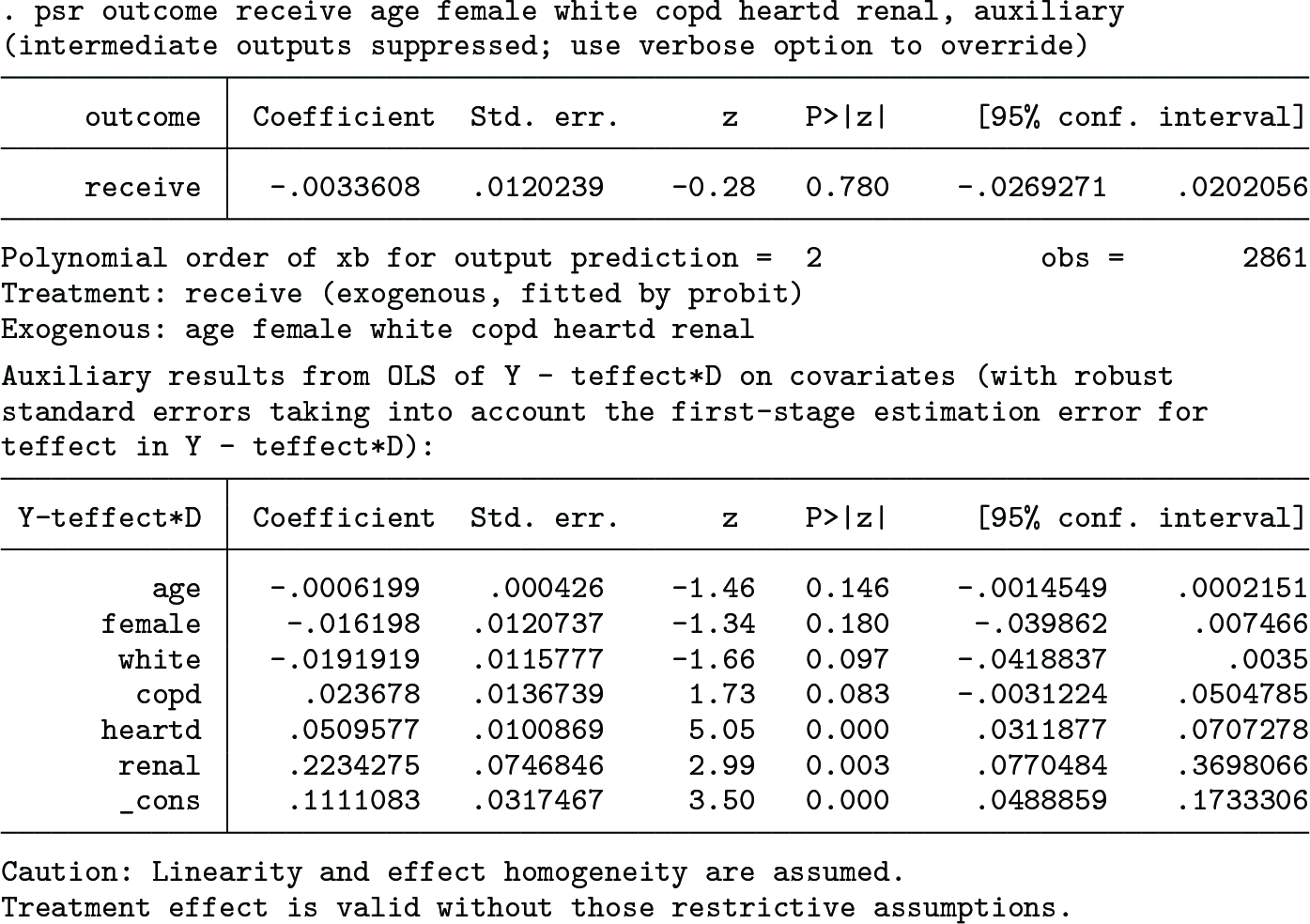
The auxiliary covariate slopes (derived under restrictive conditions in section 2.4 to make the y model linear) are reported as follows when the auxiliary option is used:
The results from the auxiliary regression of on the covariates are displayed after the estimated OW treatment effect. The reported standard errors are corrected for the first-stage estimation error, and cautionary warnings are noted.
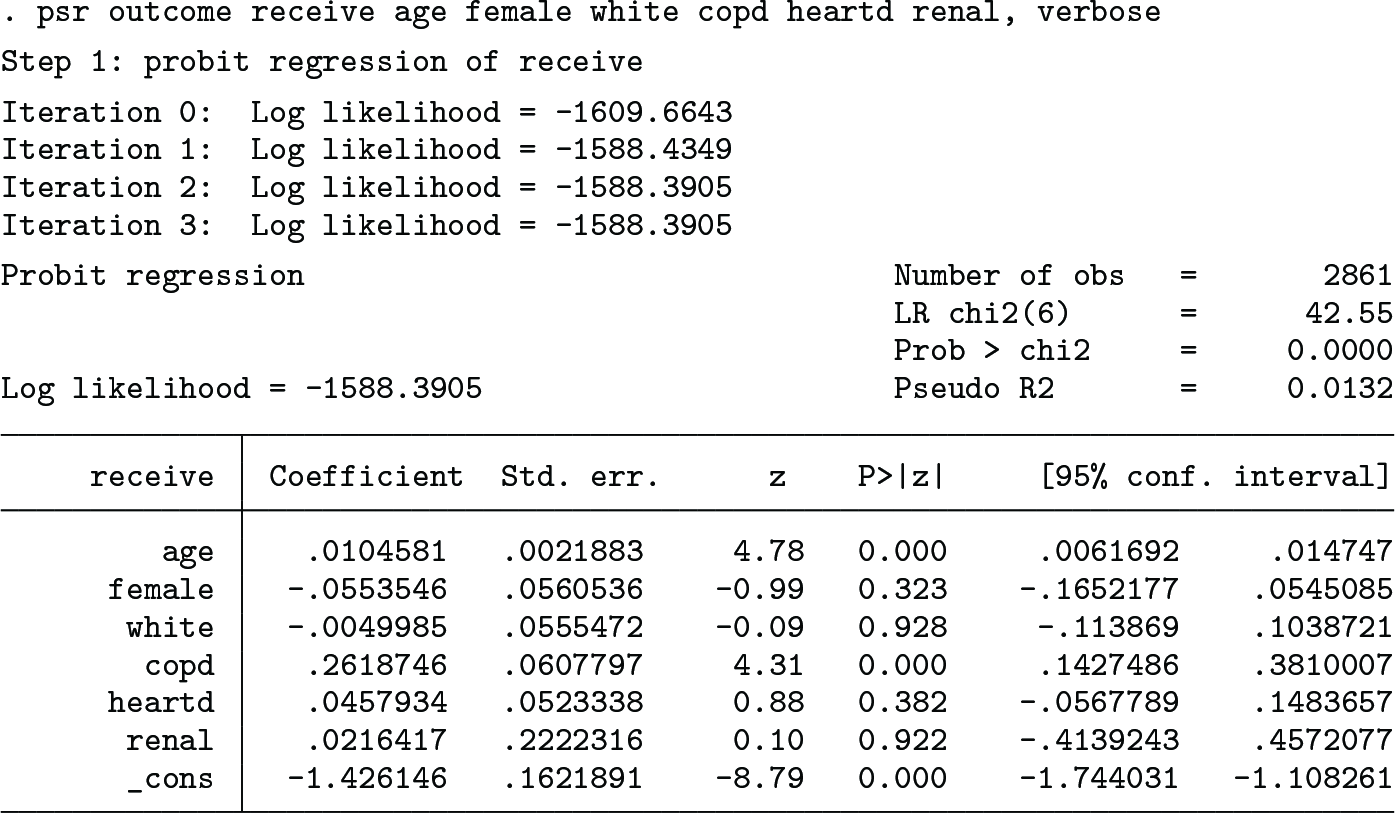
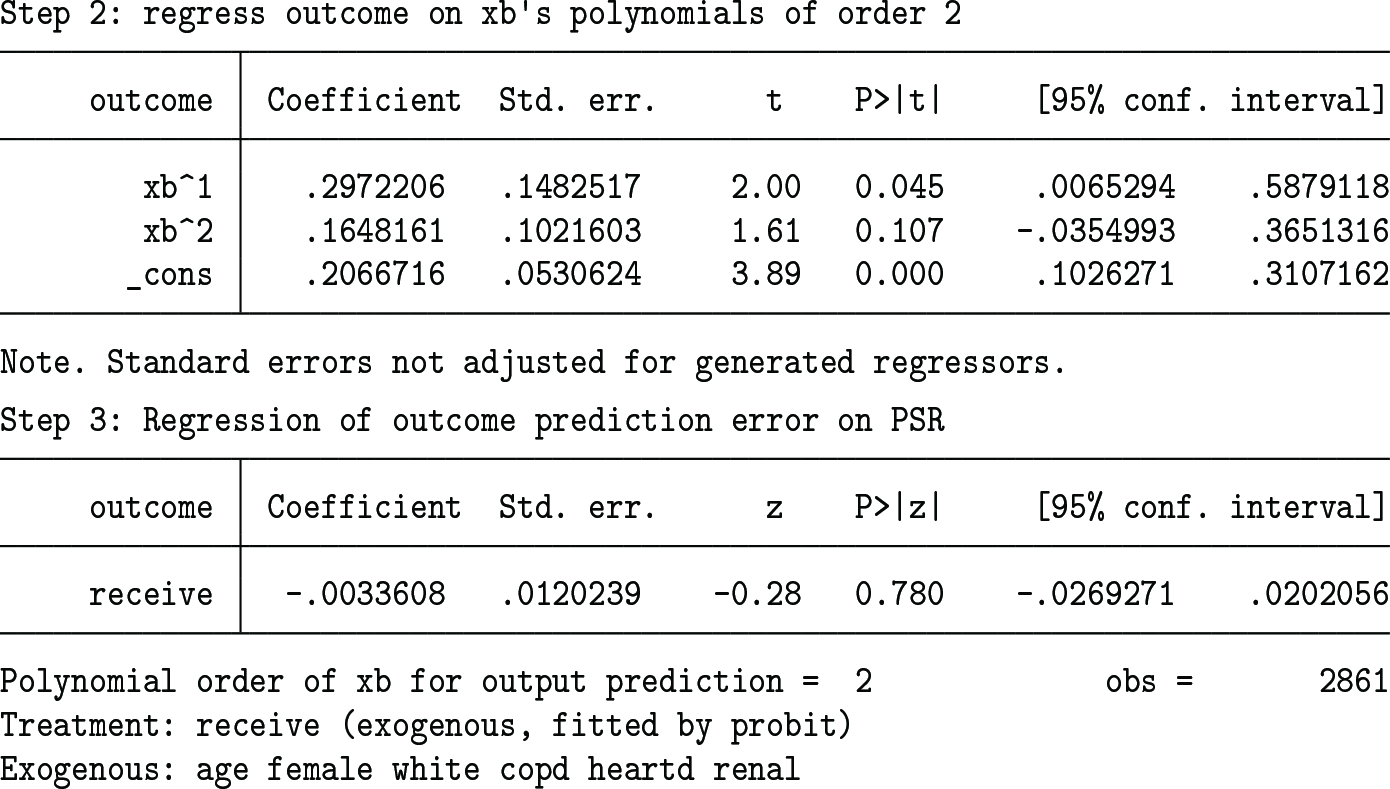
All the intermediate-step results are displayed if the verbose option is used:
The displayed results are self-evident. The vverbose option is identical to verbose and auxiliary used together.
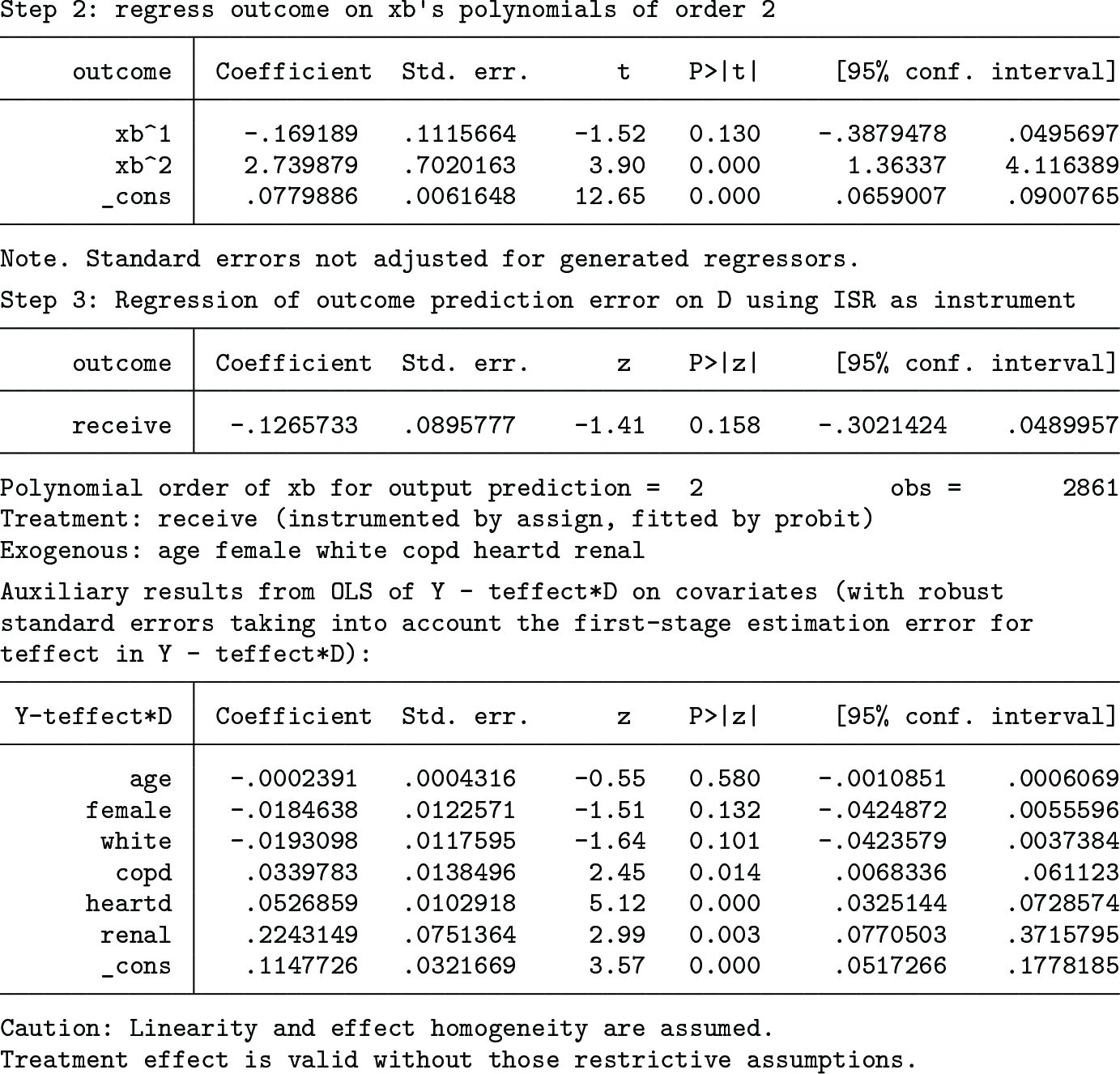
We have so far assumed that the treatment (receive) is exogenous. When it is possibly endogenous and is instrumented by assign, the results (using the vverbose option to display all intermediate steps and the auxiliary covariate slopes) are as follows:
First, the instrument (assign) is regressed on the covariates. Second, the outcome variable (outcome) is fit using the polynomials of the linear index up to the second order. Finally, the outcome prediction error is regressed on the treatment variable (receive) using the ISR as the instrument. The estimated OW average treatment effect is −0.1265733, which is much larger than the one obtained under the treatment exogeneity assumption, though it is still statistically insignificant at the 10% level (p-value = 0.158). Lee (2021, 626) shows that the usual linear-model IVE yields almost the same effect estimate, −0.13, with or without x controlled for. The estimated covariate slopes are presented as the final output.
4.2 Education effect on wage
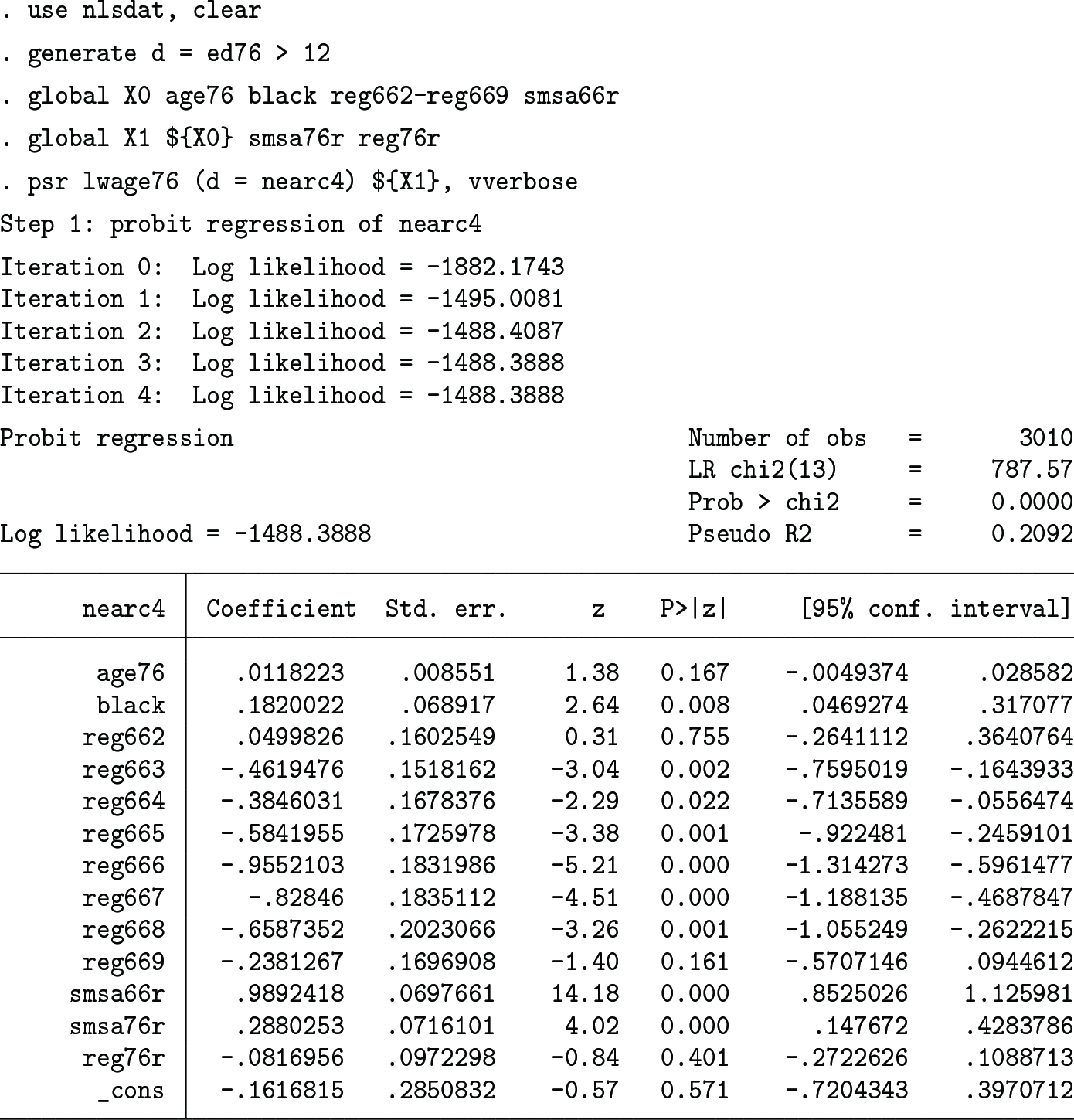
Our second empirical analysis is for education effect on wage (Lee 2021) based on Card (1995). nlsdat.dta is prepared using files at https://davidcard.berkeley.edu/data_sets.html. The variable names to appear below are taken from the codebook provided in this URL.
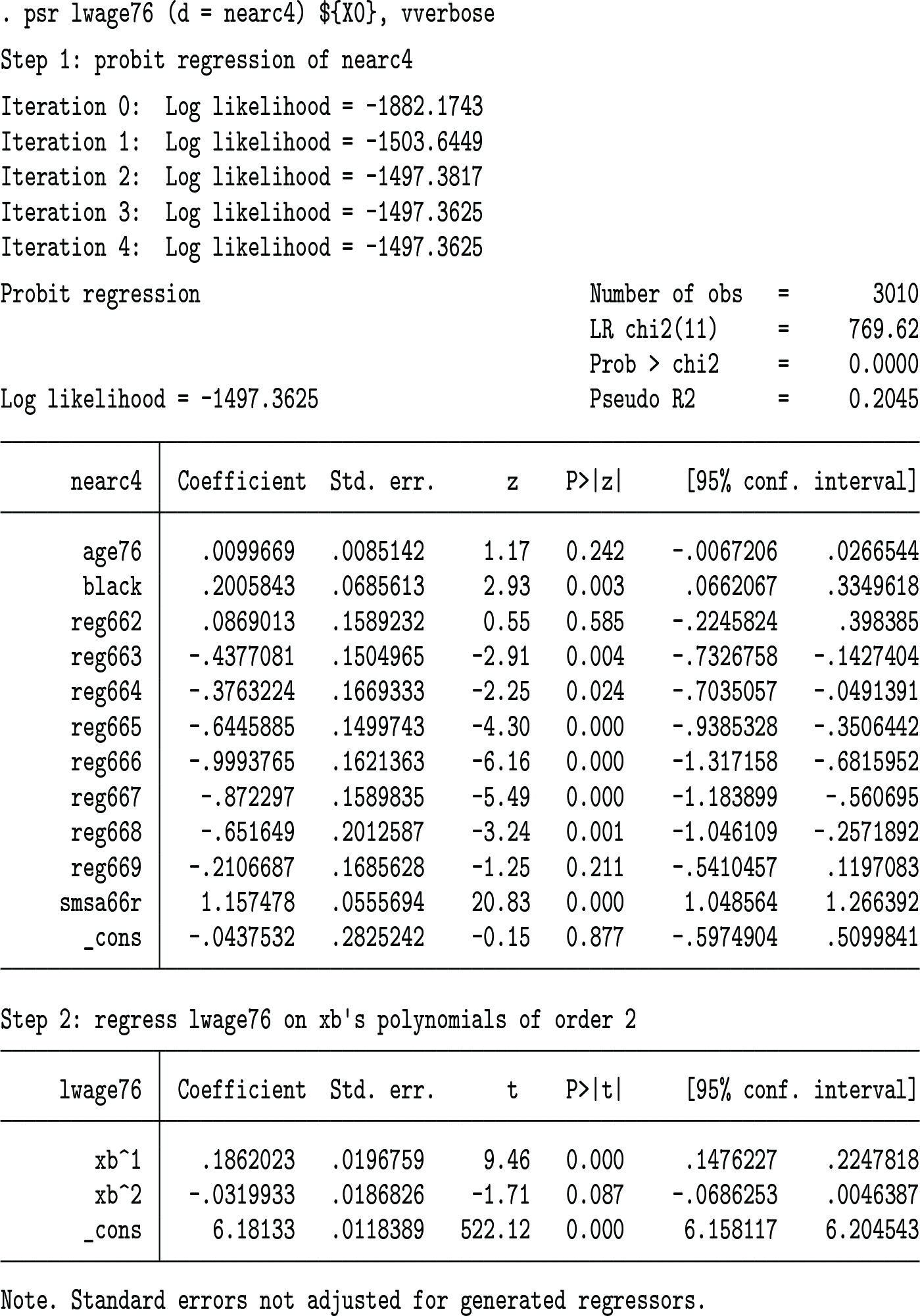
The outcome variable is ln(wage) in 1976 (lwage76), the treatment variable (d) is the binary indicator for the schooling years in 1976 (ed76) to exceed 12, the instrument (z) is for whether one grew up near a four-year college (nearc4), and the covariates (x) consist of 1, age (age76), dummy for black (black), dummies for nine residence regions in 1966 (reg662–reg669, with reg661 as the base category), dummy for living in a standard metropolitan statistical area in 1966 (smsa66r), dummy for living in a standard metropolitan statistical area in 1976 (smsa76r), and dummy for living in the South in 1976 (reg76r).
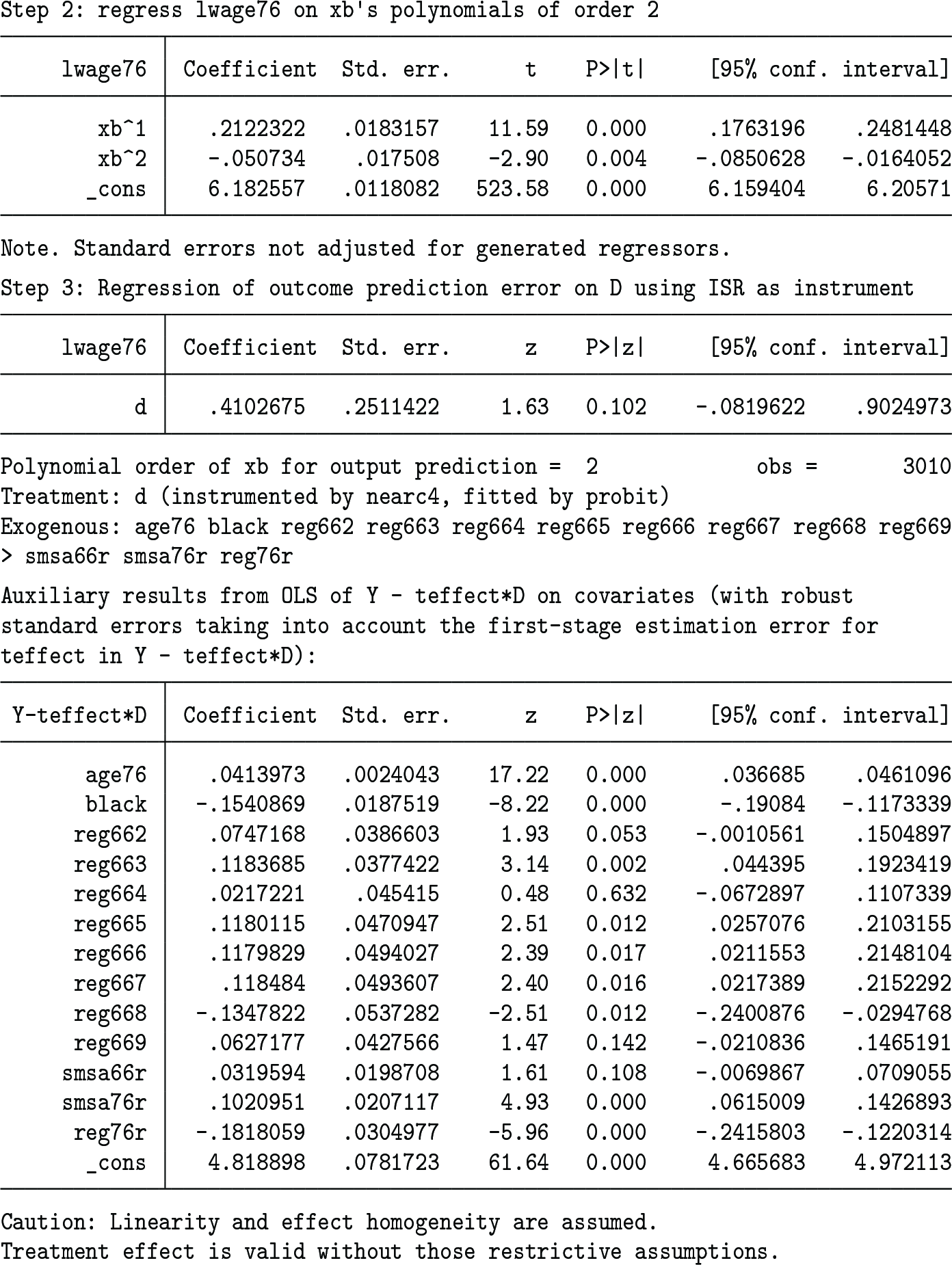
Lee (2021) presented two results with and without smsa76r and reg76r because of the possibility of them being affected by d. With smsa76r and reg76r included, the IVE regression of the outcome prediction error on the treatment using the instrument propensity residual as the instrument gives the following results (with the vverbose option used to show all the intermediate-step results and the auxiliary covariate slopes):
The OW average treatment effect is estimated to be 0.4102675 (with the robust standard error 0.2511422), as is shown in the Step 3 part of the output. Lee (2021, 628) shows that the usual linear-model IVE with x controlled yields the effect estimate 0.43 (with the robust standard error 0.24), which differs little from the OW average treatment effect result.
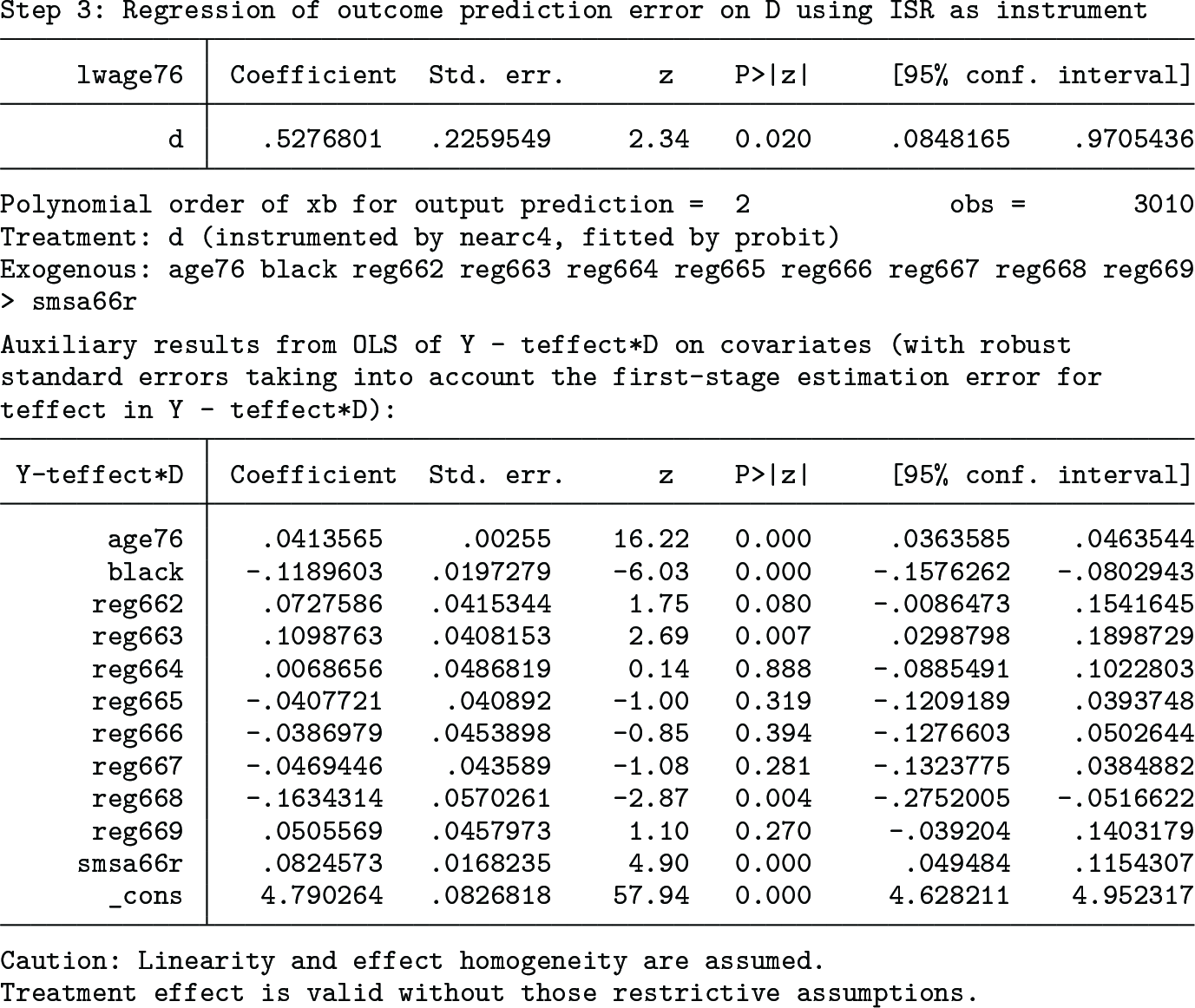
With smsa76r and reg76r excluded from the covariate list, the results change to the following:
The estimated OW average treatment effect is 0.5276801 (with the robust standard error 0.2259549), which is statistically significant at the 5% level (p-value = 0.020). Lee (2021, 628) shows that the usual linear-model IVE with x controlled yields the effect estimate 0.55 (with the robust standard error 0.22), which differs little from the OW average treatment effect result.
5 Conclusions
In finding the effect of a binary treatment d, practitioners often apply OLS to LDVs y, despite the fact that the linear model is untenable. Also, COVID-19 recently demonstrated how heterogeneous treatment effects can be, yet linear models typically assume a constant effect. This brought up an important question: What does the OLS estimate when the effect is x-heterogeneous, being a function µ1(x) of x, and the linear model is invalid?
The answer in the literature is that the effect estimated by the OLS is a weighted average E{ω(x)µ1(x)}, where the weight ω(x) is high for those with their PS πx ≡ E(d|x) ≃0.5 and low for those with πx ≃ 0, 1; ω(x) is called the OW. However, this answer requires that πx be equal to the linear projection of d on x, which unfortunately rarely holds in reality. Without this condition, the OLS can be consistent for a nonzero number even when µ1(x) = 0. This brought up another question: Can E{ω(x)µ1(x)} be estimated without the restrictive condition?
To this question, Lee (2018) showed that the OLS of y on d − πx (“OLSPSR”) is consistent for E{ω(x)µ1(x)} without the restrictive condition. Going further, Lee (2021) showed that when d is endogenous with a binary instrument z, the IVE of y on d with instrument z − ζx (“IVEISR”), where ζx ≡ E(z|x) is the instrument score (IS), is consistent for a modified OW average of µ1(x). This article reviewed OLSPSR and IVEISR and then provided the command psr to implement OLSPSR and IVEISR, which are applicable to any µ1(x) and any y (continuous, count, binary, etc.).
Because both OLSPSR and IVEISR are implemented by specifying πx and ζx as probit (or logit), one concern in OLSPSR and IVEISR is misspecifications in the probit or logit for πx or ζx. To make OLSPSR and IVEISR robust to such misspecifications, the actually implemented version of OLSPSR and IVEISR uses, respectively, y − E(y|πx) and y − E(y|ζx) instead of y. This idea is closely related to the recent “double debiasing” idea for robustness to misspecifications in nuisance functions such as πx or ζx, where y − E(y|x) is used instead of y and then a machine-learning method estimates E(y|x).
In our two empirical illustrations where one outcome is binary and the other is continuous, OLSPSR and IVEISR yielded estimates very close to those of the usual linearmodel OLS and IVE. This demonstrates that OLSPSR and IVEISR reduce to the usual linear-model OLS and IVE when πx is the same as the linear projection; otherwise, OLSPSR and IVEISR would still provide the OW average treatment effect. By providing the command, we hope that OLSPSR and IVEISR are more widely applied because they require neither any linear approximation argument nor constant effect assumption.
As far as we can see, there are two remaining issues in OLSPSR and IVEISR; one is easy to address, but the other is not. The first issue is the robustness to misspecifications in πx and ζx because it is not “full” yet. If the x-centered variables {y − E(y|x), d − πx, z − ζx} are used in the OLSPSR and IVEISR, then OLSPSR and IVEISR will be fully double debiasing. This will be done in the near future, and a command will become available before long because the research is underway. The other issue is the OW: If one objects to OW, are there any other sensible weighting schemes to adopt? The answer would be yes, but it is unlikely that any sensible weighting scheme other than OW is compatible with OLS- and IVE-based approaches.
7 Programs and supplemental material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X241233645 - Ordinary least squares and instrumental-variables estimators for any outcome and heterogeneity
Supplemental Material, sj-zip-1-stj-10.1177_1536867X241233645 for Ordinary least squares and instrumental-variables estimators for any outcome and heterogeneity by Myoung-jae Lee and Chirok Han in The Stata Journal
Footnotes
6 Acknowledgments
The authors thank the editor and an anonymous referee for helpful comments. The research of Myoung-jae Lee has been supported by the National Research Foundation of Korea grant funded by the Korea government (MSIT) (2020R1A2C1A01007786).
7 Programs and supplemental material
To install the software files as they existed at the time of publication of this article, type
References
1.
AngristJ. D.1998. Estimating the labor market impact of voluntary military service using social security data on military applicants. Econometrica66: 249–288. https://doi.org/10.2307/2998558.
2.
AngristJ. D.2001. Estimation of limited dependent variable models with dummy endogenous regressors. Journal of Business and Economic Statistics19: 2–28. https://doi.org/10.1198/07350010152472571.
3.
AngristJ. D.KruegerA. B.. 1999. Empirical strategies in labor economics. In Vol. 3A of Handbook of Labor Economics, ed. AshenfelterO.CardD., 1277–1366. Amsterdam: Elsevier. https://doi.org/10.1016/S1573-4463(99)03004-7.
4.
AngristJ. D.PischkeJ.-S.. 2009. Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton, NJ: Princeton University Press. https://doi.org/10.2307/j.ctvcm4j72.
5.
AronowP. M.SamiiC.. 2016. Does regression produce representative estimates of causal effects?American Journal of Political Science60: 250–267. https://doi.org/10.1111/ajps.12185.
6.
CardD. E.1995. Using geographic variation in college proximity to estimate the return to schooling. In Aspects of Labour Market Behaviour: Essays in Honour of John Vanderkamp, ed. ChristofidesL. N.GrantE. K.SwidinskyR., 201–222. Toronto, Canada: University of Toronto Press.
7.
ChengC.LiF.ThomasL. E.LiF.. 2022. Addressing extreme propensity scores in estimating counterfactual survival functions via the overlap weights. American Journal of Epidemiology191: 1140–1151. https://doi.org/10.1093/aje/kwac043.
8.
ChernozhukovV.ChetverikovD.DemirerM.DufloE.HansenC.NeweyW.. 2017. Double/debiased/Neyman machine learning of treatment effects. American Economic Review: Papers and Proceedings107: 261–265. https://doi.org/10.1257/aer.p20171038.
9.
ChernozhukovV.ChetverikovD.DemirerM.DufloE.HansenC.NeweyW.RobinsJ.. 2018. Double/debiased machine learning for treatment and structural parameters. Econometrics Journal21: C1–C68. https://doi.org/10.1111/ectj.12097.
ChoiJ.-Y.LeeM.-J.. 2023. Overlap weight and propensity score residual for heterogeneous effects: A review with extensions. Journal of Statistical Planning and Inference222: 22–37. https://doi.org/10.1016/j.jspi.2022.04.003.
12.
DingP.LuJ.. 2017. Principal stratification analysis using principal scores. Journal of the Royal Statistical Society, B ser., 79: 757–777. https://doi.org/10.1111/rssb.12191.
13.
ImbensG. W.2001. Comment: Estimation of limited dependent variable models with dummy endogenous regressors. Journal of Business and Economic Statistics19: 17–20. https://doi.org/10.1198/07350010152472571.
14.
LeeM.-J.2018. Simple least squares estimator for treatment effects using propensity score residuals. Biometrika105: 149–164. https://doi.org/10.1093/biomet/asx062.
15.
LeeM.-J.2021. Instrument residual estimator for any response variable with endogenous binary treatment. Journal of the Royal Statistical Society, B ser., 83: 612–635. https://doi.org/10.1111/rssb.12442.
16.
LeeM.-J.LeeG.ChoiJ.-Y.. Forthcoming. Linear probability model revisited: Why it works and how it should be specified. Sociological Methods and Research. https://doi.org/10.1177/00491241231176850.
17.
LiF.LiF.. 2019. Propensity score weighting for causal inference with multiple treatments. Annals of Applied Statistics13: 2389–2415. https://doi.org/10.1214/19-AOAS1282.
18.
LiF.MorganK. L.ZaslavskyA. M.. 2018. Balancing covariates via propensity score weighting. Journal of the American Statistical Association113: 390–400. https://doi.org/10.1080/01621459.2016.1260466.
19.
LiF.ThomasL. E.LiF.. 2019. Addressing extreme propensity scores via the overlap weights. American Journal of Epidemiology188: 250–257. https://doi.org/10.1093/aje/kwy201.
20.
LiL.GreeneT.. 2013. A weighting analogue to pair matching in propensity score analysis. International Journal of Biostatistics9: 215–234. https://doi.org/10.1515/ijb-2012-0030.
21.
MaoH.LiL.. 2020. Flexible regression approach to propensity score analysis and its relationship with matching and weighting. Statistics in Medicine39: 2017–2034. https://doi.org/10.1002/sim.8526.
22.
MaoH.LiL.GreeneT.. 2019. Propensity score weighting analysis and treatment effect discovery. Statistical Methods in Medical Research28: 2439–2454. https://doi.org/10.1177/0962280218781171.
23.
MaoH.LiL.YangW.ShenY.. 2018. On the propensity score weighting analysis with survival outcome: Estimands, estimation, and inference. Statistics in Medicine37: 3745–3763. https://doi.org/10.1002/sim.7839.
24.
MlcochT.HrnciarovaT.TuzilJ.ZadakJ.MarianM.DolezalT.. 2019. Propensity score weighting using overlap weights: A new method applied to regorafenib clinical data and a cost-effectiveness analysis. Value in Health22: 1370–1377. https://doi.org/10.1016/j.jval.2019.06.010.
25.
MoffittR. A.2001. Comment: Estimation of limited dependent variable models with dummy endogenous regressors. Journal of Business and Economic Statistics19: 20–23.https://doi.org/10.1198/07350010152472571.
26.
RobinsJ. M.MarkS. D.NeweyW. K.. 1992. Estimating exposure effects by modelling the expectation of exposure conditional on confounders. Biometrics48: 479–495. https://doi.org/10.2307/2532304.
27.
ThomasL. E.LiF.PencinaM. J.. 2020. Overlap weighting: A propensity score method that mimics attributes of a randomized clinical trial. Journal of the American Medical Association323: 2417–2418. https://doi.org/10.1001/jama.2020.7819.
28.
ToddP.2001. Comment: Estimation of limited dependent variable models with dummy endogenous regressors. Journal of Business and Economic Statistics19: 25–27. https://doi.org/10.1198/07350010152472571.
29.
van der LaanM. J.RoseS.. 2011. Targeted Learning: Causal Inference for Observational and Experimental Data. New York: Springer. https://doi.org/10.1007/978-1-4419-9782-1.
30.
VansteelandtS.DanielR. M.. 2014. On regression adjustment for the propensity score. Statistics in Medicine33: 4053–4072. https://doi.org/10.1002/sim.6207.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.